WALL-WM: Carving World Action Modeling at the Event Joints¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: WALL-WM: Carving World Action Modeling at the Event Joints
- 作者: X Square Robot Team(核心贡献者 Shalfun Li 等,详见报告 Contributors 页;∗ 核心、† 项目负责人、‡ 通讯)
- 发布: 2026-05-29 技术报告(无 arXiv 编号,仅官网 PDF)
- 代码: https://github.com/X-Square-Robot/wall-x
- 关键词: world-action model (WAM), event-grounded pretraining, semantic event, video-action denoiser, Wan T2V prior, multi-view DiT, staircase latent CoT, flow matching
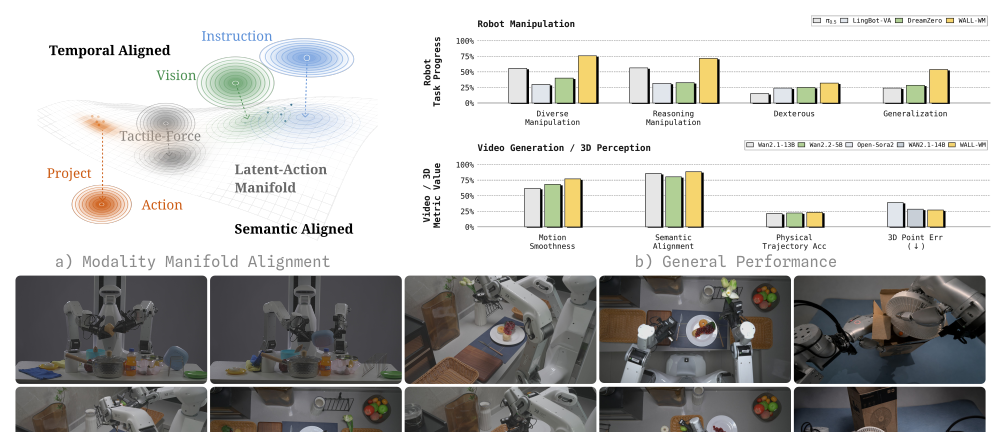 Figure 1:左 — modality manifold,text 只给粗粒度语义对齐、vision 给稠密时空 grounding、action 要最细的接触级精度;tactile-force 是可选信号。右 — WALL-WM 在 manipulation 与 video-generation 两侧同时领先。下 — 真机任务快照。
Figure 1:左 — modality manifold,text 只给粗粒度语义对齐、vision 给稠密时空 grounding、action 要最细的接触级精度;tactile-force 是可选信号。右 — WALL-WM 在 manipulation 与 video-generation 两侧同时领先。下 — 真机任务快照。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 embodied world-action model(WAM) 子领域 — 即显式耦合「未来观察建模」与「动作预测」的具身基础模型。论文要解决的核心痛点是当前 VLA/WAM 几乎都采用的 chunk-centric 范式:从当前观察 + 指令直接预测一段固定长度的 action chunk。作者指出这个范式藏着一个结构性的 granularity mismatch:
- 语言描述的是语义目标和事件("把刀放到盘子右边");
- 视觉通过连续的场景动力学演化;
- 动作在控制级时间尺度上运行,对接触、时序、微小扰动敏感。
把三者强行塞进同一个由"外部时钟"切出的固定窗口,会把 VLA 训练退化成短时程相关性拟合,不仅没用好预训练的 visual-semantic prior,反而可能用 chunk-specific 的动作捷径覆盖掉它,削弱 compositionality 和 long-horizon 泛化。
2.2 Motivation¶
一句话的 slogan 是:"Fixed chunks cut by clock; semantic events cut by embodied dynamics."(固定 chunk 按时钟切,语义事件按具身动力学切。)
作者把 video 视作连接 language 和 action 的天然脚手架:互联网级 video 预训练捕获了丰富的视觉动力学,video 在 event 边界处足够语义化以对齐语言,又足够时间稠密以暴露 action 执行需要的时序/转换/状态变化。把 video foundation model 提升成 WAM 不是一个短的 adaptation 阶段,而是一次 prior-preserving lift:既要继承大规模 video 学到的语义与时序结构,又要获得 embodied control 需要的可控性、接触敏感性和因果 grounding。这就要求一个对语言有意义、在 video 中可见、通过 action 可执行的统一对齐单元 —— 而固定 chunk 三者都不满足。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 反应式 VLA(observation→action) | π0.5 (36), OpenVLA 系 | 底层 VLM 主要在静态图文上预训练;teleop 微调学到的是 action imitation 而非"世界如何在干预下演化",无 action-conditioned future prediction |
| Chunk-centric WAM | LingBot-VA (44), DreamZero (83), 各类 unified denoising | 固定长度 chunk 既可能太短装不下完整语义事件,又可能太长破坏 context/target 的因果分离;KV-cache streaming 只能部分缓解 V-A 时间对齐漂移,仍是 fixed-horizon |
| Latent-action / 无显式动作 WAM | AdaWorld, Motus, LDA-1B 等 | 动作表征不可解释或粒度太粗;latent 维度/codebook 宽度要事先猜 |
| 推理高效化 | Fast-WAM (86, 本仓已有笔记) | 靠避免显式 video 解码提速,但仍在 fixed-horizon 框架内 |
2.4 论文解决方案(一句话)¶
把固定长度 chunk 换成 action-grounded semantic event(reach/grasp/lift/move/place 这类可执行行为段),在 event 层面做 prior-preserving 的 video-action 联合去噪预训练 —— 一个从 Wan T2V 继承的 video tower 与一个随机初始化的 action DiT 逐层耦合,同一个 event 预训练 backbone 支持 event mode(变长执行)和 unified mode(固定 chunk + Staircase latent CoT)两种推理。
2.5 与前序工作的关系¶
- Wan2.2-5B (72):video tower 直接继承 Wan Series T2V 的单视角 DiT,扩展成多视角、多本体;within-view 计算保持不变,只 graft 三个增量(多视角适配、Camera RoPE、cross-view 几何 mask)。
- π0.5 (36) / DreamZero (83) / LingBot-VA (44):真机评估的三个主要 baseline;DreamZero、LingBot-VA 也是 §9.4 讨论 KV-cache streaming 的对照对象。
- Qwen3.5-9B (80,71):语言推理模块 backbone;Staircase decoder 以 MoT 形式耦合在冻结 backbone 上。
- T5 (62):DiT 的原生文本 conditioner;VLM 阶段把 Qwen 的 hidden states 对齐到 T5 特征空间,作 drop-in 替换。
- 与 Wall-OSS-0.5 是姊妹工作(本仓已有 Wall-OSS 笔记):同属 X Square Robot,共用 Muon/DMuon、XRZero-G0 采集系统、真机 Task Progress 协议与 π0.5/DreamZero baseline;WALL-WM 是 video+action 的大 WAM,Wall-OSS 是开源 4B 的纯 VLA。
3. 方法介绍¶
3.1 形式化¶
WALL-WM 建模 \(p_\theta(\mathbf{V}_e, \mathbf{a}_e \mid \mathbf{V}_0, \mathbf{s}, c_e)\):
- \(\mathbf{V}_0\):当前多视角观察(每相机一个 keyframe);
- \(\mathbf{s}\):当前 proprioceptive state;
- \((\mathbf{V}_e, \mathbf{a}_e)\):event 对齐的未来多视角 video 与 end-effector 轨迹(长度随 event 变化);
- \(c_e\):描述同一语义事件的 per-event caption。
每个训练样本是从长 episode 里按动作边界切出的一个原子 event \((\mathbf{V}_e, \mathbf{a}_e)\),而不是固定长度 chunk。
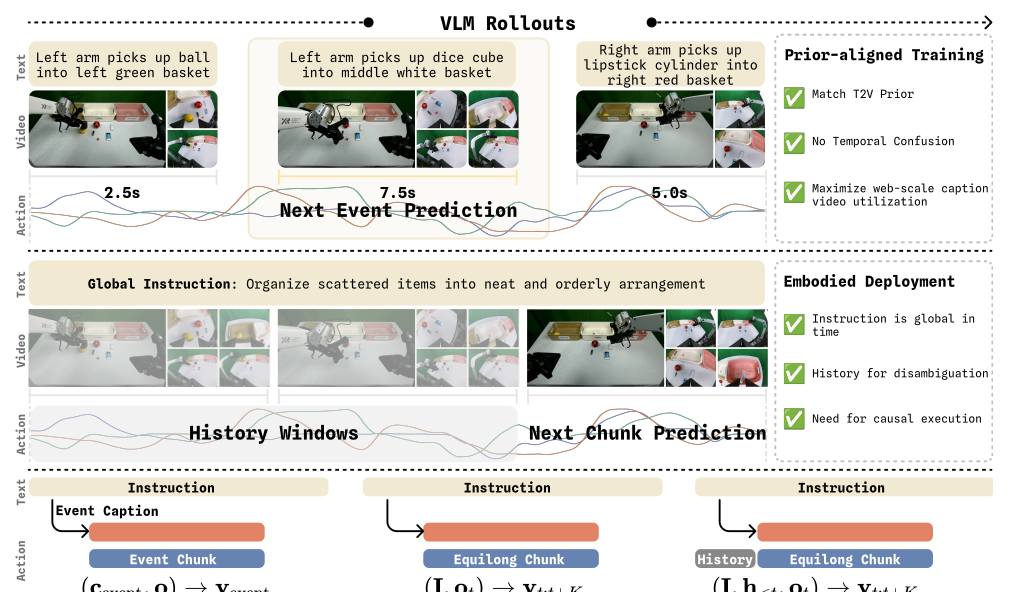 Figure 2:上 — prior-aligned 训练里 event caption / event video / event action 描述同一语义区间,给出 well-posed 的 caption→video/action target。下 — equilong chunk 模式下单靠全局指令对局部 chunk 是 ambiguous 的,必须加 history window 才能 well-posed。
Figure 2:上 — prior-aligned 训练里 event caption / event video / event action 描述同一语义区间,给出 well-posed 的 caption→video/action target。下 — equilong chunk 模式下单靠全局指令对局部 chunk 是 ambiguous 的,必须加 history window 才能 well-posed。
3.2 多视角视觉世界事件建模(Video Tower)¶
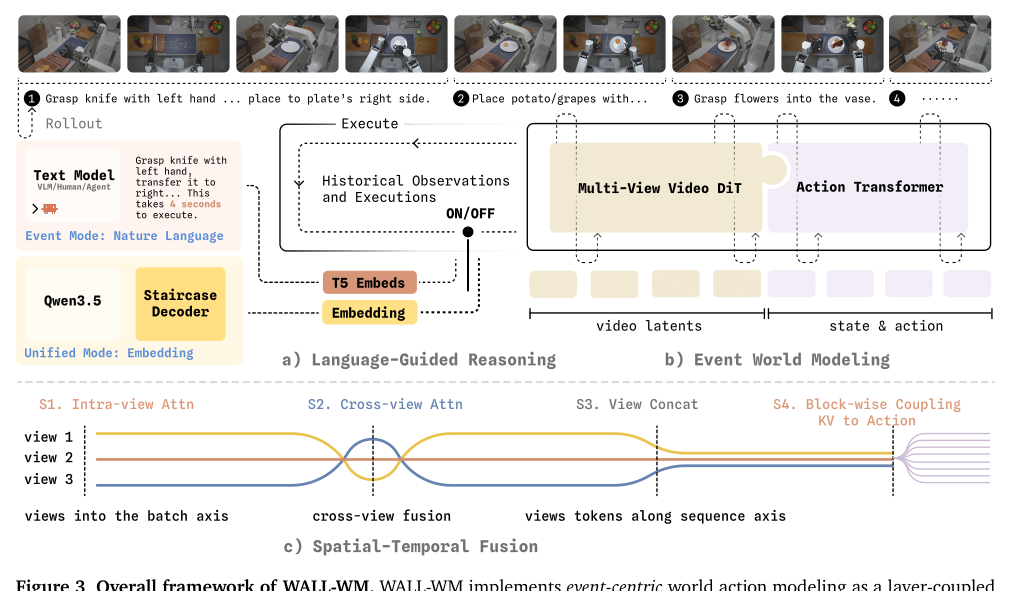 Figure 3:layer-coupled video-action denoiser。(a) 语言路径:event mode 走 T5 embeds,unified mode 走 Staircase decoder 出 CoT latents。(b) event world model:Multi-View Video DiT 去噪 video latents,Action Transformer 去噪 action。(c) spatial-temporal fusion 四步 — S1 intra-view、S2 cross-view、S3 ViewConcat、S4 block-wise coupling(video KV → action)。
Figure 3:layer-coupled video-action denoiser。(a) 语言路径:event mode 走 T5 embeds,unified mode 走 Staircase decoder 出 CoT latents。(b) event world model:Multi-View Video DiT 去噪 video latents,Action Transformer 去噪 action。(c) spatial-temporal fusion 四步 — S1 intra-view、S2 cross-view、S3 ViewConcat、S4 block-wise coupling(video KV → action)。
video tower 在 Wan 单视角 DiT 上嫁接三个增量:
-
多视角适配(S1→S2):当 \(N_v>1\),每个 DiT block 在 Wan 原生 within-view self-attention 之后加一条 cross-view 分支,把各相机同一 latent frame 的空间 token 拼成一个序列做 self-attention,输出经零初始化 projector + AdaLN gate 加回 per-view 流(公式 1)。零初始化保证初始时这条分支不贡献,cross-view 交换随训练才打开 → 不破坏 Wan 的外观/语言对齐先验。
-
Camera RoPE:在 RoPE 上加一个 view 轴,view 旋转由可学习的 per-view embedding 产生。加/减相机只改 embedding table → 免标定、支持异构多本体相机配置。
-
Cross-view 几何 mask(仅训练):
- Sight-cone attention mask:把每个 patch 的视锥近似成 cone,只有两个 token 的视锥在景深带内相交(co-visible)才允许 cross-view attention(公式 2–6),其余加 \((1-M_{sc})\cdot(-\infty)\) bias。作用在注意力拓扑。
- Tube patch masking:以概率 \(p_{tube}\) 挑一个视角的 \(k\times k\) 时空 tube 替换成纯噪声,强迫模型必须从其他视角恢复。作用在输入内容。
- 二者互补:前者让 cross-view 图反映物理可见性、后者制造对 cross-view attention 的真实需求。推理时全部丢弃,runtime 保持免标定。
视频侧用 Wan-style v-prediction flow matching(公式 7–8),并始终用 border masking 排除画面外/合成黑边区域。
3.3 事件中心的动作动力学建模(Action Tower)¶
action tower 是与 video tower 等深的 action DiT。每个 action block 做四件事:(a) action token 间 self-attention;(b) 对 state token 的专属 cross-attention(让绝对本体感知在每一层都直达,不被长 video KV 稀释);(c) 对配对 video block 特征的 cross-attention(公式 9,单向耦合,video tower 不被改);(d) gated FFN。
-
Video-Action 时间对齐:用两个可学习 lookup \(E_\tau\)(窗口内 frame index)和 \(E_{abs}\)(哪个窗口)。Event-centric window(预训练)禁用 \(E_{abs}\)、按 frame 给整数索引(公式 10);Observation-centered window(unified 部署)扩成 \(M\) 历史帧 + 1 anchor + \(N\) 未来帧并激活两个 embedding(公式 11)。3D VAE 是 \(1+4N\) 时间 codec,一次编码整段 \(1+4M+4N\) raw buffer 得到 \(1+M+N\) 个 latent,无 history/future 接缝(Figure 5)。动作流用 relative-pose:所有非 anchor token 编码相对观察 pose 的位移,anchor=0 固定时间原点。
-
Video-Action 去噪步映射(关键设计):
- Symmetric 1-to-1(验证/小数据):action step \(j\) 配 video step \(j\),两塔端到端联合去噪。
-
Asymmetric 1-to-\(N_d\)(默认/大规模):固定一个中等噪声 anchor \(s^\star\),所有 action step 都读这同一个 anchored video forward 的 cross-attention KV(公式 12)。主 recipe 里 video tower 冻结,每个 optimizer step 只跑一次 video forward + \(K\) 次 action forward(\(K=6\) 纯属吞吐 trick,推理不用)。理由:高噪声 video 特征不必匹配 GT,近 clean 特征又留不下足够结构来指导控制,所以 pin 在一个平衡点 \(s^\star=45\)(50 步 schedule)。
-
Action objective:默认 v-prediction flow-matching MSE(公式 13)。接触密集数据可选 x-prediction(直接出 clean action,避免 v-prediction 在高噪声下给少数接触帧权重过低),以及 Type-II DCT 辅助强调整体运动形状、抑制逐帧抖动(公式 14)。
3.4 Language-Guided Reasoning(Staircase 解码)¶
推理模块建在 Qwen3.5-9B 上。给定多视角观察 + 指令,VLM 产生 hidden states,文本 token 经投影注入 DiT cross-attention(公式 15)。
Staircase latent CoT decoding:把 reasoning 建模成 \(K_c\) 个连续 latent reasoning state,用一个耦合在冻结 backbone 上的轻量 Mixture-of-Transformers(MoT) 实现。在 relay depth \(N_r\) 处分割 Transformer:只有第一个 latent 位置走下层、产生共享 relay 表示供所有 reasoning 位置复用;其余 latent 在上层并行生成(公式 16–17)。相比逐 token 自回归 latent CoT,避免对每个 reasoning step 重复计算低层 visual-language 特征,大幅降时延,且 latent 全程可微、直接注入 cross-attention(无离散采样)。Figure 6(原文)对比了三种 CoT 调度:传统 CoT 自回归出离散 token;latent CoT 换连续向量但仍串行依赖;Staircase 在错开的层深之间 relay 中间 hidden state,经共享 projector 产生并行连续 CoT latents。
监督:不直接蒸馏自回归 hidden states,而是把 latent 经 prefix projector 投到一个冻结的 Qwen3.5-0.8B 嵌入空间,让它自回归重建对应的文本 CoT trace(公式 18–19)。只训 staircase 分支 + prefix projector → latent 被鼓励编码紧凑高层语义而非逐 token 解码轨迹。
两种推理模式:event mode 由人/VLM/agent 提出 next-event 描述,模型执行变长 video-action 段;unified mode 由 staircase decoder 单次并行出 \(K_c\) 个 CoT latent,slot 进 cross-attention 的 atomic-instruction 位置。
3.x 训练数据与 Implementation Details¶
- 数据生态(五轴):①来源 — OpenVID 1.2M clip + HD-VILA(通用网视)、Ego4D/EPIC-KITCHENS(第一人称)、XRZero-G0 等 UMI-style 非本体、DROID/AgiBot World/自采(异构 teleop);②部署对齐的时间同步与后处理;③四级 + 可选人工的层级 caption(Task/Subtask/Action/Segment + Human),按动作边界切分而非均匀切窗,专门让 regrasp/失败恢复等短矫正行为可被定位;④Cluster-balanced sampling — VL 聚类 + action 聚类双平衡,把长尾的 recovery/re-grasp 变成显式采样单元;⑤Recovery 数据 — 在接触事件附近的 geodesic ball 里扰动初始化再重放/重采,主动制造接触空间覆盖。
- 采集:结构化(命名任务 + reset 协议)与非结构化(自由操作的长多事件流)两种协议,后接同一 caption-then-cluster 管线。XRZero-G0 可穿戴免机器人装置(VR 跟踪 + 手持 gripper,几何标定到部署机器人末端,IK 重定向到 URDF)→ 采集吞吐不再受机器人时间束缚。
- 本体平台:tabletop bimanual arms、QUANTA X1 / X1 Pro(移动)、QUANTA X2 轮式人形(高 DoF 灵巧手)。
- 训练阶段(Table 1):① video PT(只训 video DiT)→ ② action PT(冻结 video DiT,\(s^\star=45\)、\(N_d=50\)、\(K=6\))→ ③ VLM text-conditioner(只训 project-out + next-event head + remaining-time regressor,对齐到 T5 特征空间)→ ④ Staircase distillation(只训 MoT 分支 + prefix projector)→ ⑤ 可选 next-chunk adaptation(observation-centered 窗口,两塔都更新)。
- 基础设施:Muon 优化器 + 自研 DMuon(分布式 Newton-Schulz,把 optimizer step 从近 2× fwd+bwd 降为次要开销);TVM-FFI kernel 库;fine-grained overlap 隐藏 view attention 引入的 all-to-all;multi-event sequence packing(打包多 event 成长序列 + 防泄漏 mask,保证满 batch)。
- 模型压缩与时延:DMD 蒸馏(few-step 学生,联合保留 action loss,否则 action MAE 退化 53%)+ FP8 per-block 量化(~2× over BF16)+ CUDA Graph → 端到端 10Hz 闭环控制。
- 模型规模:family 从 <10B 到 tens-of-billions。
4. 结果对比¶
4.1 Embodied Video Generation(自建 benchmark,WorldArena 协议)¶
| Models | Image Aesthetic | Motion Smooth. | Subject Consist. | Semantic Align. | Interaction Quality | Instr. Following | Traj. Acc |
|---|---|---|---|---|---|---|---|
| Wan2.1-1.3B | 0.577 | 0.619 | 0.476 | 0.857 | 0.219 | 0.308 | 0.214 |
| Wan2.2-5B | 0.527 | 0.683 | 0.769 | 0.805 | 0.226 | 0.298 | 0.223 |
| WALL-WM | 0.503 | 0.771 | 0.795 | 0.886 | 0.434 | 0.391 | 0.234 |
WALL-WM 在 Motion Quality / Semantic Consistency / Physical Plausibility(尤其 Interaction Quality 0.434 vs 0.226,近 2×)领先,但 Visual Quality(Image Aesthetic 0.503)反而略低于 Wan。Baseline 是未经具身训练的通用 T2V,所以这张表更多衡量的是 domain adaptation。
4.2 3D Awareness(CO3Dv2,Table 3)¶
| Probed Feature | Point Err↓ | Depth Err↓ | AUC@5↑ |
|---|---|---|---|
| DINOv2 | 0.559 | 0.209 | 0.051 |
| V-JEPA | 0.439 | 0.214 | 0.076 |
| WAN2.1-14B | 0.284 | 0.151 | 0.200 |
| WALL-WM | 0.271 | 0.132 | 0.210 |
4.3 真机评估(Task Progress 0–100,四个 suite)¶
主策略为 event mode(WALL-WM-E);WALL-WM-U-Scratch 是去掉 event 预训练、直接 fixed-length 从头训的对照。
| Suite | WALL-WM-E | U-Scratch | π0.5 | DreamZero | LingBot-VA |
|---|---|---|---|---|---|
| Diverse Manipulation | 75.86 | 63.00 | 55.64 | 39.97 | 29.71 |
| Reasoning Manipulation | 71.60 | 59.50 | 56.40 | 32.70 | 31.60 |
| Dexterous Manipulation | 32.00 | 31.25 | <32 | <32 | <32 |
| Generalization | 53.75 | 18.50 | 24.00 | 28.50 | — |
注意 Dexterous 上 event mode 仅 32.00 vs U-Scratch 31.25,几乎打平,且绝对分都很低 —— 作者诚实承认这里瓶颈是低层 pose 精度/接触时序,不是高层事件分解。
4.4 关键消融(Event + VI-SA,Table 4)¶
| Suite | Base(无 VI-SA,固定 unified) | Event |
|---|---|---|
| Reasoning Manipulation | 32.6 | 71.6 |
| Generalization | 22.0 | 53.75 |
作者明确声明:这个 ablation 同时改了 VI-SA 和执行格式,应解读为两者的合并效应,不能拆给单一组件。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- Event 作为原子单元解决了 granularity mismatch:caption / video / action 描述同一语义区间,给出 well-posed 的 caption→video/action target;变长执行让 horizon 跟着任务走而不是时钟走。这是全文最干净的 framing,也直接对应 Plato "carve nature at its joints" 的标题。
- Prior-preserving 贯穿到底:cross-view projector 零初始化、AdaLN gate、action PT 阶段冻结 video tower、VLM 对齐到 T5 特征空间做 drop-in —— 每个增量都设计成"初始不破坏 Wan 先验,随训练才打开",而不是 append 一个 action head 就指望它不覆盖视觉语义。
- Asymmetric 1-to-\(N_d\) 去噪步映射:把"frozen video 单 anchor 供 KV、action 跑完整 schedule"这件事讲清楚了 —— 既避开 symmetric 配对下高噪声/近 clean 两难,又把每步成本压到一次 video forward。是工程与建模权衡都站得住的设计。
- Sight-cone × tube 双 mask 互补:一个改注意力拓扑(物理可见性)、一个改输入内容(制造 cross-view 需求),且都只在训练用、推理免标定。比单纯堆 cross-view attention 有道理。
- Staircase latent CoT 并行化:relay depth 分割让低层 grounding 算一次、高层 reasoning 并行展开,摊薄了 latent CoT 的层成本;frozen latent-to-text 重建监督(而非蒸馏 hidden)逼 latent 编码紧凑语义。
- §9.1 的 dual-tower ≈ emergent latent action 论证:把"latent-action vs dual-tower"从对立改写成连续谱 —— 收紧 cross-tower shared 子块就退化成显式 bottleneck,放松就留余量。这是对自己设计空间最诚实、也最有洞察的一段。
- 数据侧把 recovery 当一等公民:层级 caption 按动作边界切 + cluster-balanced 双聚类 + 接触空间随机初始化,三件事一起把长尾矫正行为变成显式采样单元,而不是被成功 episode 的全局 caption 平均掉。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 主对比 confound 严重:WALL-WM-E vs U-Scratch 同时差了 event 预训练 + event-mode 执行 + 语言推理模块 + VI-SA 四个变量,作者自己在 Table 4 也承认只能测"合并效应"。真正的"event 单元本身贡献多少"始终没被隔离。
- Event mode 的语言优势被算进了"event 预训练"账上:真机 event mode 用一个单独 fine-tune 的 Qwen3.5-VL-9B 把全局指令转成 per-event 描述,等于 WALL-WM-E 拿到了比 baseline(只给全局指令)更丰富的测试时任务分解。Reasoning/Generalization 的大幅领先里,有多少来自更好的 test-time decomposition 而非 backbone?没有控制。
- Dexterous 几乎打平(32.00 vs 31.25):恰恰在最需要"executable causality"的精细接触任务上,event 叙事失效 —— 说明 event-centric 增益主要在语义分解/grounding 层,低层接触精度没被它解决。这点作者诚实,但也直接削弱了把 event 当"通往精细操作"卖点的力度。
- Video gen benchmark 自建 + baseline 不对等:held-out 来自自己的数据混合,baseline 是没做具身训练的通用 Wan,所以"超过 Wan"主要测的是 domain adaptation;而且 Visual Quality 反而掉了(0.503 vs 0.527),论文一笔带过。
- 时延与精度的配置含糊:10Hz 是 DMD 蒸馏 + FP8 之后才达到的;真机那些 Task Progress 到底跑在 full multi-step teacher 还是 distilled student 上没说清。10Hz 对接触密集闭环本就偏紧,蒸馏后 action MAE 的实际损失(除了"去掉 action loss 退化 53%")没给。
- "larger is better" 只是断言:§8 说 <10B→tens-of-billions 一致提升精度与 OOD,但全文没有任何 scaling 曲线或表,无法判断收益斜率与饱和点。
- \(s^\star=45\) "selected empirically":整个 cross-attention 证据都压在这一个 anchor 噪声层上,敏感性分析缺失 —— 换 \(s^\star\) 会怎样?这是核心超参却没 ablate。
- 主管线无 force/tactile:动作只是 end-effector 轨迹 + state token,tactile-force 被明确标为"optional"。对灵巧/插入这类任务这是真实限制(与 dexterous 打平的结果一致)。
- 无任何标准 benchmark 对照:所有真机评估都在自家平台、自家 Task Progress rubric 上,无 LIBERO/SimplerEnv 等公共对照 → 外部不可比、复现门槛高(代码开源但数据与评估协议私有)。
- Unified mode 复杂度高却仍是弱者:要额外的 next-chunk adaptation(5.4)+ staircase distillation 才能跑常规 VLA 路径,加了一堆复杂度,结果这条"传统兼容"路反而是较弱的模式。
5.3 值得继续探讨的方向¶
- Event 边界检测的质量上限:整套方法依赖"按动作边界自动切分 + 四级 caption",但这个分割/标注管线的准确率从未被量化,它实际是 silent 的性能天花板。能否给 event segmentation 单独的质量评估?
- 把语言分解从 backbone 里拆出来量化:固定同一个 Qwen3.5-VL-9B next-event 提供器,对 WALL-WM-E 和各 baseline 都喂 per-event 描述,才能干净测 backbone 贡献。
- Force/tactile 注入:在 dexterous suite 上接入 tactile-force 作为非可选模态,看能否突破 32 分天花板。
- Scaling law:补 <10B / 10B+ / tens-of-billions 的精度-OOD 曲线,验证 §8 的核心主张。
- 闭环 replan 频率 vs event horizon:event mode 一次执行一整段,遇到扰动如何中途打断/重规划?与 DreamZero/LingBot 的 KV-cache streaming 在 long-horizon 上做显式对照(§9.4 只定性讨论)。
- 蒸馏对接触帧的影响:DMD few-step 学生在 x-prediction + DCT 辅助下,接触帧精度损失的定量评估。
参考资源¶
- 论文 PDF: paper.pdf
- 代码: https://github.com/X-Square-Robot/wall-x
- 姊妹工作: Wall-OSS-0.5(同 X Square Robot,开源 4B VLA)
- 关键 baseline / 相关论文: π0.5 (36)、DreamZero (83)、LingBot-VA (44)、Fast-WAM (86, 本仓已有笔记)、Wan2.2-5B (72)、Qwen3.5-9B、Muon/DMuon、DMD 蒸馏 (84,85)