SimDist (Simulation Distillation): 在仿真中预训练世界模型以实现真机快速自适应¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
- 作者: Jacob Levy*¹, Tyler Westenbroek*², Kevin Huang², Fernando Palafox¹, Patrick Yin², Shayegan Omidshafiei³, Dong-Ki Kim³, Abhishek Gupta†², David Fridovich-Keil†¹(*共同一作,†共同指导)
- ¹University of Texas at Austin ²University of Washington ³FieldAI
- arXiv 编号: 2603.15759(submitted 2026-03,project page:
sim-dist.github.io,含开源代码) - 关键词: world model, sim-to-real, model-based RL, online planning (MPPI/MPC), system identification, quadruped locomotion, contact-rich manipulation
 Figure 1:左列是 zero-shot sim-to-real 策略的失败(peg 插不进、桌腿拧不上、teflon 斜坡打滑、泡沫塌陷);右列是 SimDist 只用 15–30 分钟真机数据后的稳定改进。核心卖点是"真机数据极少 + 单调提升"。
Figure 1:左列是 zero-shot sim-to-real 策略的失败(peg 插不进、桌腿拧不上、teflon 斜坡打滑、泡沫塌陷);右列是 SimDist 只用 15–30 分钟真机数据后的稳定改进。核心卖点是"真机数据极少 + 单调提升"。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 sim-to-real 机器人学习 / 真机在线自适应。问题是:机器人在新环境里只能拿到少量、混合质量的交互数据(演示、失败、探索动作、旧策略 rollout),如何用这点数据可靠地提升性能。难点集中在 long-horizon、contact-rich 的任务上——小误差会累积,成功需要对多种可能的未来做推理。
现有两条路都不好走: - 端到端策略 finetune(RLPD/IQL/SAC 这类 model-free,以及 OpenVLA/π 这类大策略)在新域上常常崩——表征、奖励、价值、动作选择全部纠缠在一起,自适应时整个决策过程被一起改写,同时还要解 long-horizon credit assignment,于是出现灾难性遗忘。 - 从零学世界模型(Dreamer/TD-MPC)需要 action-conditioned、覆盖广的真机数据,规模上真机采集不起。
2.2 Motivation¶
作者主张 world model 才是利用先验经验做高效自适应的正确抽象:世界模型把决策模块化(环境预测网络 vs. credit assignment 网络分开),于是新数据可以只去精修"动作后果"的模型,而不覆盖掉预训练学到的整套决策结构;再用 online planning 把更准的预测转化为更好的行为,去评估那些机器人没直接经历过的 counterfactual 未来。
但训练可用于规划的世界模型需要海量、覆盖广的 action-conditioned 数据。核心 insight:这些组件不必和真机精确对齐就能支撑规划——
- reward / value 模型只需要给真机状态一个正确的"排序"(ranking),让 planner 区分有希望的未来和糟糕的未来即可。这比估计精确 return 要弱得多、也更可迁移。例(peg 插孔):模型只要把"peg 离孔更近 / 对齐更好 / 已部分插入"排在更前面就够了。
- dynamics 模型把动作和未来状态绑定,对 sim-to-real 的 dynamics gap 最敏感——但只要初始化得当,这个 gap 可以用简单的监督式 finetune(在真机数据上)高效修正。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Model-free 真机 RL | RLPD, SERL, IQL, SAC | 激进复用 off-policy 数据 + 频繁 critic 更新 → value 过估计、训练不稳;端到端 finetune 易灾难性遗忘 |
| Model-based RL(从零 bootstrap) | Dreamer, TD-MPC | 需在稀缺 in-domain 数据上同时 bootstrap 表征 / 价值 / 策略;planner 会主动 exploit 模型误差 |
| 经典自适应控制 / MPC / 神经物理引擎 | adaptive control, ContactNets, neural physics engines | 依赖简化低维状态、物体位姿或接触标签,在 partial-obs、contact-rich 下脆弱 |
| 仿真价值迁移 | SGFT, Lyapunov value transfer | 只迁移价值函数,仍依赖低维状态观测;不做完整 world-model 规划 |
| 生成式视频世界模型 | Genie, UniPi, GR-x | 预测像素、需 demo/inverse model 落地;训练在窄的 expert-like 动作分布上,受真机数据约束、难超越数据 |
2.4 论文解决方案(一句话)¶
在仿真里用 privileged 专家 + 多样化(含次优 / 失败)数据蒸馏出一个 planning 导向的 latent 世界模型,真机部署时冻结 encoder / reward / value / base policy,只用监督式 system identification 微调 dynamics,再配 MPPI 在线规划——把真机自适应从"不稳定的 RL"降维成"稳定的监督学习"。
2.5 与前序工作的关系¶
- 直接建立在 TD-MPC(planning-oriented latent WM + MPPI、用 base policy 的噪声扰动输出 warm-start 采样)和 Dreamer 系的世界模型谱系上。
- 数据生成管线建立在
yin2026emergent("Emergent" 学生-教师 sim-to-real 管线,也直接提供了本文 manipulation 的专家策略 \(\pi^e\) 与价值 \(V^e\))。 - 最近的"兄弟"工作是 SGFT(
yin2025rapidly)——只迁移仿真价值函数;SimDist 把它推广成完整世界模型自适应,并在实验里用 SGFT-SAC 隔离"只迁价值"的收益。 - 单次前向的 chunked dynamics 预测借鉴了 AnyCar(
xiao2025anycar)。 - 复用现成件:ImageNet 预训练 ResNet-18、IsaacLab PPO、Unitree Go2、UR5e。
3. 方法介绍¶
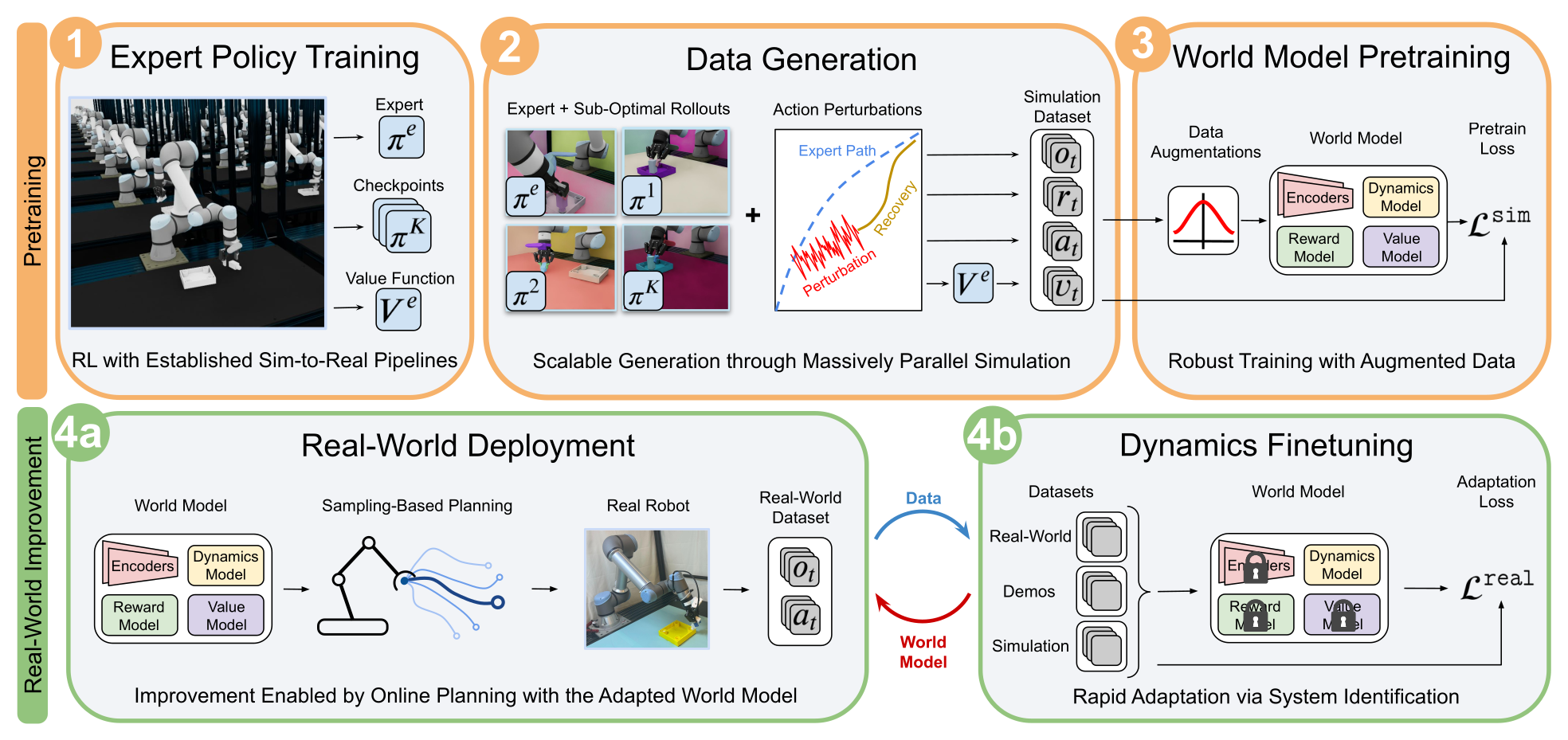 Figure 2:SimDist 全流程。①仿真里用 RL 训出专家策略 + checkpoints + 价值函数;②混合专家/次优策略 + 时序连续动作扰动,生成带 dense reward 与 value 监督的多样化数据;③在原始观测上预训练 planning 导向的 latent 世界模型;④a 部署时迁移表征 + 冻结的 reward/value 做规划,④b 只对 dynamics 做监督式 system identification,部署与微调交替迭代。
Figure 2:SimDist 全流程。①仿真里用 RL 训出专家策略 + checkpoints + 价值函数;②混合专家/次优策略 + 时序连续动作扰动,生成带 dense reward 与 value 监督的多样化数据;③在原始观测上预训练 planning 导向的 latent 世界模型;④a 部署时迁移表征 + 冻结的 reward/value 做规划,④b 只对 dynamics 做监督式 system identification,部署与微调交替迭代。
3.1 形式化¶
把控制建模为 POMDP \((\mathcal{S},\mathcal{A},\mathcal{O},p,r,\gamma)\),真实动力学 \(s_{t+1}\sim p(\cdot|s_t,a_t)\),但真机只能拿到原始观测 \(o_t\),目标是最大化折扣回报 \(\mathbb{E}[\sum_t \gamma^t r]\)。
关键假设:存在一个近似物理仿真器 \(p_\mathtt{sim}(\cdot|s_t,a_t)\),并提供对底层状态 \(s_t\) 的 privileged 访问。
世界模型结构(planning-oriented latent WM):
| 组件 | 公式 |
|---|---|
| 隐表征 | \(z_t = E_\theta(o_t)\) |
| 历史表征 | \(h_t = C_\theta(o_{t-H:t-1}, a_{t-H:t-1})\) |
| 隐动力学 | \(\hat z_{t+1:t+T} = f_\theta(z_t, a_{t:t+T-1}, h_t)\) |
| 奖励预测 | \(\hat r_{t:t+T-1} = R_\theta(\hat z_{t:t+T}, a_{t:t+T-1})\) |
| 价值预测 | \(\hat v_{t+1:t+T} = V_\theta(\hat z_{t:t+T})\) |
| Base policy | \(\hat a_{t:t+H} = \pi_\theta(z_t, h_t)\) |
规划(MPPI):每个控制步采一批候选动作序列,用世界模型评估其轨迹回报 \(\mathcal{R}(a_{t:t+T-1}) = \gamma^T\hat v_{t+T} + \sum_{s=t}^{t+T-1}\gamma^{s-t}\hat r_s\),再按回报做 importance weighting 算出执行动作。和 TD-MPC 一样,用 base policy \(\pi_\theta\) 的噪声扰动输出去 warm-start 一部分候选序列。
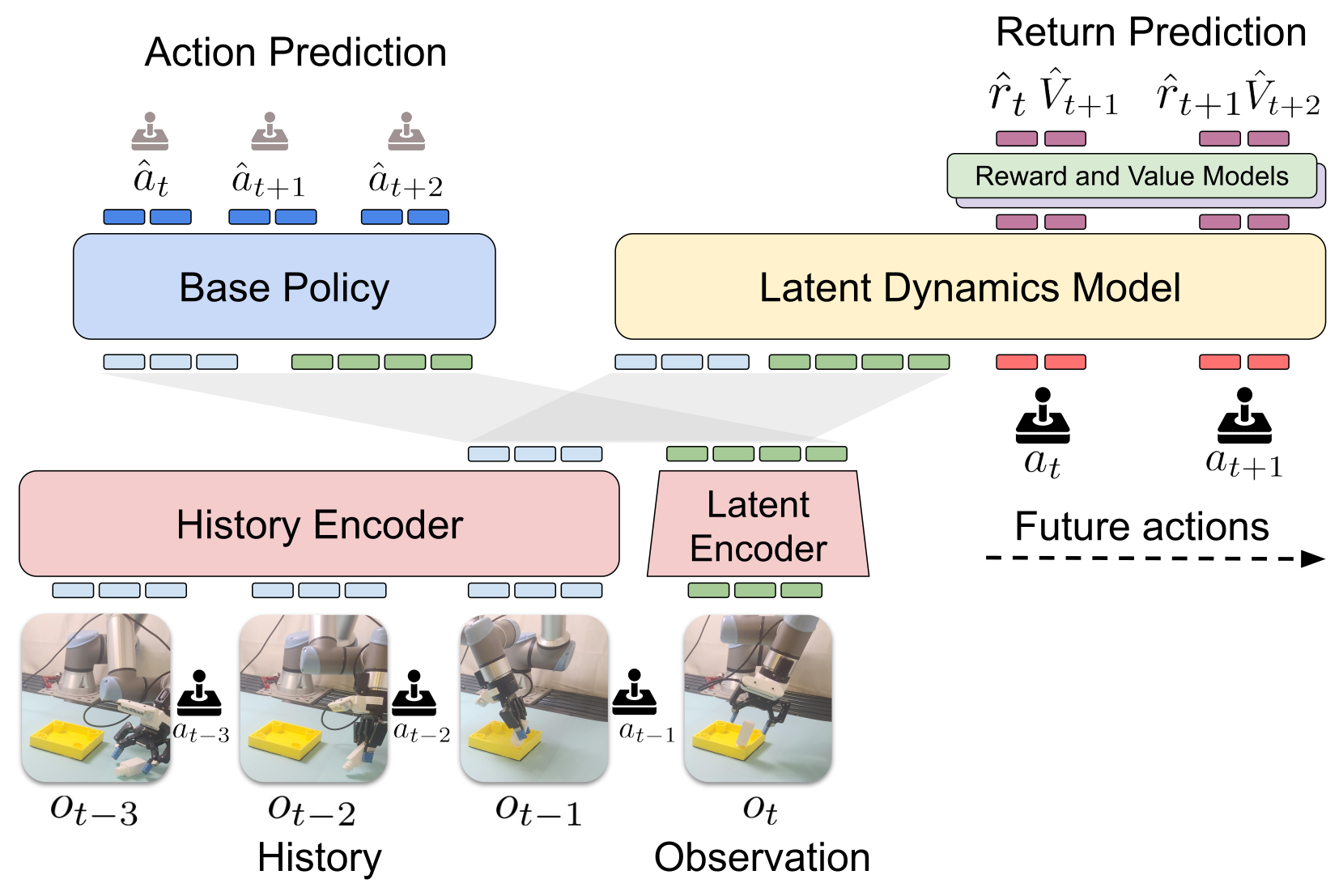 Figure 3:世界模型架构。最新观测进 Latent Encoder,历史观测+动作进 History Encoder,两者共同条件化一个 transformer latent dynamics,单次前向预测整段未来 latent;transformer 的 reward/value 头在整条预测轨迹上做评估;base policy 头出 action chunk 用来 warm-start 采样。
Figure 3:世界模型架构。最新观测进 Latent Encoder,历史观测+动作进 History Encoder,两者共同条件化一个 transformer latent dynamics,单次前向预测整段未来 latent;transformer 的 reward/value 头在整条预测轨迹上做评估;base policy 头出 action chunk 用来 warm-start 采样。
3.2 仿真预训练:多样化数据生成¶
SimDist 建立在"用 privileged state-based 专家收集大规模数据"的管线上,但 planning-based 自适应对模型的要求更强:planner 会主动搜索高价值动作序列、在覆盖薄弱处 exploit 模型误差,所以模型必须在专家分布和真机分布之外都可靠。为此刻意注入次优动作来覆盖错误、修正、失败。
- 专家训练:先用现成 sim-to-real 管线训出 state-based 专家 \(\pi^e(s_t)\),同时保存最优价值 \(V^e(s_t)\) 和训练中间 checkpoints \(\{\pi^k\}_{k=1}^K\)。
- 多样轨迹 + dense 监督(
alg:datagen):每个并行环境随机分一个 checkpoint(或专家),采样对角动作噪声协方差 \(\Sigma_j\),并在重置时采样连续的加噪时间区间(contiguous noise intervals),在这些区间里给动作加高斯噪声。这样产生大量"偏离最优 manifold 的失败 + 恢复"行为。每步还查询 \(V^e(s_t)\) 得到价值目标 \(v_t\),并记录 expert flag \(b^e_t\)(区分纯专家动作 vs. 加噪/旧 checkpoint 动作)。得到数据集 \(\mathcal{D}_\mathtt{sim}=\{(o_t,a_t,r_t,v_t)\}\)。 - 预训练损失(对每个 \(t\) 的预测累加 \(i=0..T\)):
其中 sg 是 stop-grad,\(\mathds{1}_e\) 只在动作来自未加噪专家时为 1,\(c_{1:3}\) 由各目标 range 归一化得到。注意:因为行为生成 offload 给了 privileged 专家,预训练变成一个简单、平稳的监督目标,不需要 TD learning / bootstrap(区别于在线 MBRL)。
- 不用 reconstruction loss:理由有二——(1) 多样化数据本身就逼迫 encoder 学到鲁棒表征,不必再付像素重建的算力;(2) sim-to-real 需要大量视觉随机化,像素重建会逼 latent 去编码被刻意随机化的纹理/光照/渲染 artifact(与任务无关),反而伤害迁移。
3.3 真机迁移与高效 dynamics 自适应¶
关键 insight:全局任务结构对底层 sim-to-real dynamics gap 基本不变。例(Peg Insertion):有意义的 latent 捕捉 peg 和孔的位置,value 编码"到目标的距离"和"通向成功插入的运动"——这些跨 sim-to-real 仍然成立,即便实现它们所需的底层动作在两个域里不同。
于是 SimDist 只 finetune dynamics \(f_\theta\),冻结 \(C_\theta, E_\theta, R_\theta, V_\theta, \pi_\theta\):
- encoder 冻结 → 提供一致的 latent target,不需要 bootstrap 表征;并把适配后的 dynamics 锚定在 \(R_\theta/V_\theta\) 被训练去评估的那个 latent 空间上,避免漂移。
- 冻结的 reward/value 头提供即时的 long-horizon 规划信号,使一个相对短 horizon 的 planner 也能随 dynamics 变准而提升性能——无需在真机做 reward/value bootstrap。
- 迭代改进(
alg:method):反复"用 planner 收集 \(M\) 个 on-policy rollout → 加入 \(\mathcal{D}_\mathtt{real}\) → 最小化 \(\mathcal{L}^\mathtt{real}\) 微调 \(f_\theta\)"。因为 system ID 能从任意真机轨迹学习,SimDist 天然支持 off-policy,可吸收 demo/play 等异构数据。
Remark:标准 MBRL 必须从稀缺 in-domain 数据里同时 bootstrap 表征、价值、策略;SimDist 把这些难目标 offload 到仿真(数据廉价且充足),从而把真机自适应降维成 dynamics 的监督式 finetune。
3.4 World Model 设计决策(为实时规划服务)¶
planner 要采大量 off-policy rollout 并准确建模 return,下面三点是实时决策的关键:
- 极简历史表征:把观测拆成 proprioceptive \(o^p\) 和 exteroceptive \(o^e\),history encoder 只吃 \((o^p_{t-H:t}, a_{t-H:t}, o^e_t)\)——即只保留最新一帧高维(图像/height map)观测。大幅降规划延迟,且经验上缩短 context 反而提升训练稳定性。
- Chunked 预测:自回归世界模型要沿规划 horizon 逐步展开,评估大量 rollout 时是并行瓶颈。\(f_\theta\) 改用 transformer(history token 与候选动作序列做 cross-attention + causal mask),单次前向预测 \(T\) 步未来,吃满 GPU 并行,规划吞吐大幅提升。
- Seq2seq return 建模:reward/value 不用 per-timestep MLP,而用 transformer 在整条预测 latent 轨迹 \(\hat z_{t:t+T}\) 上做 attention,聚合轨迹级信息 → 更准的 return 估计(ablation 验证)。
3.x Implementation Details¶
| Manipulation (UR5e) | Quadruped (Unitree Go2) | |
|---|---|---|
| 动作 | 6D 相对 EE 位姿 + 二值夹爪 | 12 关节位置目标 |
| 观测 | 关节状态 + 3×224×224 RGB(腕/俯视/侧视),各过 ImageNet ResNet-18 → 拼 proprio → MLP → 64 维 \(z\) | proprio + 局部地形 height map(CNN)+ MLP → \(z\);额外条件化于命令前向/侧向/yaw 速度 |
| 数据规模 | 100k 轨迹(约 36% 纯专家动作) | ~100M data points(55.7% 纯专家);4096 环境 × 25000 步,数据生成 ~7h(RTX 4500 Ada) |
| 专家 | yin2026emergent 的 \(\pi^e, V^e\) |
PPO @ IsaacLab,MLP 3×512,4096 环境 × 5000 iter = 490M steps |
| H, T / 控制频率 | H=T=5 / 5 Hz | H=T=25 / 50 Hz(部署在 RTX 4090M 笔记本) |
| 预训练 | 2 epoch,batch 256,~200k 更新,Adam 2e-4→1e-4 cosine,10k warmup | 2 epoch,batch 512,~3.69e5 更新,~28h(RTX 4500 Ada) |
| MPPI | 250 候选 + 100 噪声 base policy,3 solver iter,elites 64,temp 0.4,γ=0.99 | 450 候选 + 22 base policy,8 solver iter,elites 64,temp 0.25,γ=0.99 |
- dynamics transformer:manipulation 3 层 / 4 头;reward、value 各 1 层 / 1 头;base policy 4 层 / 8 头;embedding 维度 64。
- 数据增强:proprio 加零均值高斯噪声;视觉 color jitter / 高斯模糊 / 随机裁剪。
- 真机更新节奏:manipulation 每 20 episode 更新一次 dynamics(baseline 每 episode 更新)。
4. 结果对比¶
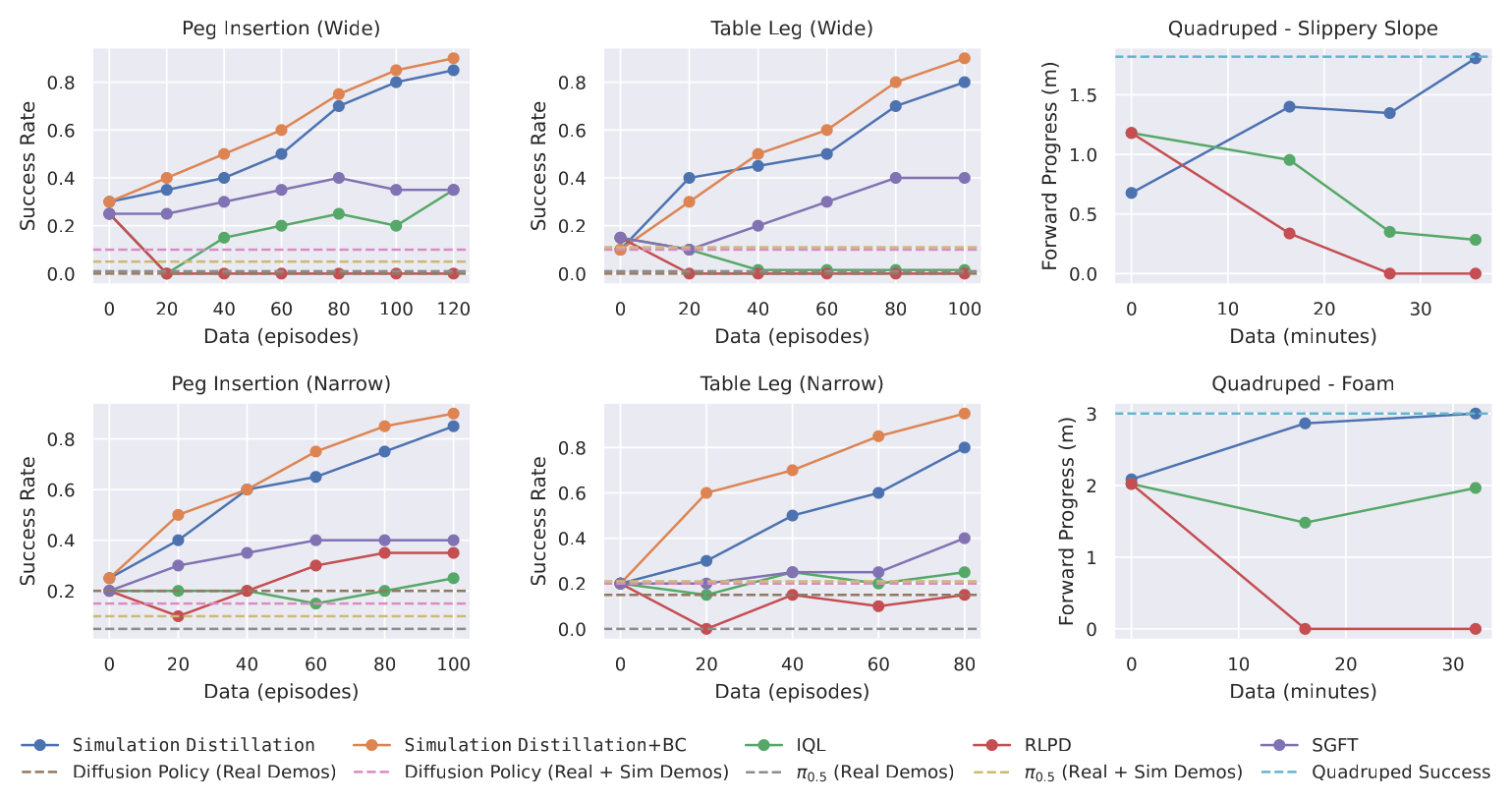 Figure 4:四个任务的真机学习曲线(横轴=真机数据量)。SimDist(深蓝)随数据快速且单调提升;model-free baseline(IQL/RLPD)几乎不动甚至崩塌;BC(Diffusion Policy / π₀.₅)是固定水平线被反超。manipulation 任务从 Narrow→Wide 初始分布变难时,SimDist 与 baseline 的差距进一步拉大。
Figure 4:四个任务的真机学习曲线(横轴=真机数据量)。SimDist(深蓝)随数据快速且单调提升;model-free baseline(IQL/RLPD)几乎不动甚至崩塌;BC(Diffusion Policy / π₀.₅)是固定水平线被反超。manipulation 任务从 Narrow→Wide 初始分布变难时,SimDist 与 baseline 的差距进一步拉大。
总体:SimDist 在所有任务上普遍约 2× 于任意 baseline;标准 RL finetune 经常灾难性遗忘、训练中性能崩塌,SimDist 则单调稳步提升。SGFT(迁价值)避免了崩塌但样本效率显著更差。给 SimDist 加 demo(+BC)只会更好,体现它能吸收异构、混合质量数据。吞吐(success/min)相比 zero-shot 提升约 1.5×–2×。
4.1 四足真机详细结果(每速度 5 trial)¶
微调用数据:Slippery Slope 35.7 min,Foam 32.1 min。RLPD 在 Foam 上把机器人弄失稳,未报告。
| 任务 | 速度 (m/s) | Pretrained (zero-shot) | Single-step BC | SimDist | IQL | RLPD |
|---|---|---|---|---|---|---|
| Slippery Slope | 0.1 | 0/5 | 2/5 | 4/5 | 0/5 | 0/5 |
| 0.3 | 0/5 | 1/5 | 5/5 | 0/5 | 0/5 | |
| 0.5 | 0/5 | 0/5 | 5/5 | 0/5 | 0/5 | |
| Foam | 0.2 | 3/5 | 1/5 | 5/5 | 1/5 | — |
| 0.7 | 2/5 | 1/5 | 5/5 | 2/5 | — | |
| 1.2 | 0/5 | 2/5 | 5/5 | 3/5 | — |
(forward progress 同样几乎全部满格,如 Slope 0.3/0.5 达 1.82±0.00 m,Foam 全部 3.00±0.00 m。)
4.2 Manipulation¶
- 任务:Peg Insertion(仿 Factory 16mm 方 peg)、Table Leg(FurnitureBench,桌腿对齐拧入),各从 Narrow (2×2cm) / Wide (35×35cm) 初始网格起。20 次试验/数据点,成功定义为 45 秒内完成。
- baseline:RLPD、IQL(稀疏奖励,offline-to-online)、SGFT-SAC(迁仿真价值)、Diffusion Policy、π₀.₅(100 demo BC,含 real-only 与 real+sim co-train 变体)。
- SimDist 两个变体:纯 SimDist(只调 dynamics、无 demo);SimDist+BC(额外用 teleop demo 的动作标签 finetune base policy)。
- 趋势:任务从 Narrow→Wide 变难,SimDist 与 baseline 的差距扩大;scatter 图显示 SimDist 在整个初始条件空间上比 Diffusion Policy 鲁棒得多。
4.3 关键消融(仿真,manipulation 报成功率 / 四足报每 episode 平均奖励)¶
| 配置 | Peg (SR) | Table Leg (SR) | Quadruped (Reward) |
|---|---|---|---|
| SimDist | 0.90 | 0.85 | 22.78 |
| 50% 数据 | 0.72 | 0.61 | 22.73 |
| 10% 数据 | 0.06 | 0.02 | 19.38 |
| 仅专家数据(等量) | 0.10 | 0.05 | 16.68 |
| MLP reward+value 头 | 0.82 | 0.60 | 19.47 |
| 加 raw obs reconstruction | 0.32 | 0.21 | 23.34 |
要点:
- 数据规模与多样性是命门:缩到 10% 直接崩(Peg 0.90→0.06);"仅专家、等量"也崩(0.90→0.10)——说明真正起作用的是覆盖错误/恢复的多样性,不是单纯数据量。
- seq2seq transformer 头 > per-step MLP(Peg 0.90→0.82,Table Leg 0.85→0.60)。
- reconstruction 对 manipulation 有害(0.90→0.32),对四足略有帮助(22.78→23.34)——印证"像素重建逼 latent 编码被随机化的视觉细节"。
- 解冻消融(真机,fig:unfreeze):解冻 encoder → 完全失效(冻结的 reward/value 收到分布外 latent);解冻 value → 重新引入 long-horizon credit assignment → 灾难性遗忘。reward 头因真机拿不到 dense 标签而根本不解冻。
4.4 机制证据¶
- value 迁移(
fig:value):成功 rollout 的预测 value 随时间上升,失败(掉 peg)时骤降——冻结 encoder+value 能可靠区分成功/失败。 - dynamics 微调有效(Slippery Slope):latent 预测损失从 pretrained 的 0.076 降到 0.019;解码到前左脚轨迹,pretrained 模型错误地预测 PTFE 面上稳定接触、预测不到打滑,微调后能准确预判 slip。
- planning 行为被重塑:微调 dynamics 的采样轨迹反映真实接触动力学,使 planner 选出能应对打滑的方案;pretrained 模型的方案与真实动力学定性不符。
 Figure 5:真机相机观测 vs. 从冻结 encoder 的 latent \(z_t\) 用辅助 probe 重建出的图像。世界模型本身并没有用重建损失训练——这说明仅靠多样化预训练,encoder 的 latent 已经捕捉了真实场景的底层状态。
Figure 5:真机相机观测 vs. 从冻结 encoder 的 latent \(z_t\) 用辅助 probe 重建出的图像。世界模型本身并没有用重建损失训练——这说明仅靠多样化预训练,encoder 的 latent 已经捕捉了真实场景的底层状态。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 把"自适应"精准切到 dynamics gap 上。核心洞察——reward/value 只需 ranking 正确(序关系),不需估计精确 return——是这篇文章成立的支点。冻结 E/R/V、只监督式微调 \(f\),绕开了真机 TD bootstrap 与 long-horizon credit assignment,这正好解释了为何 baseline 崩而 SimDist 单调升。解冻消融是强证据:解冻 encoder 直接归零,解冻 value 立刻灾难性遗忘。
- 刻意制造次优数据才是真正的 workhorse。policy checkpoint 混合 + 时序连续动作噪声,给 planner 提供"错误—恢复—失败"的覆盖;ablation 里"仅专家数据"把 Peg 从 0.90 砸到 0.10,比缩数据量更致命。这把"数据多样性"从一句口号变成了可量化的设计点。
- 论证并实证了"不需要 reconstruction"。sim-to-real 要做大量视觉随机化,像素重建会逼 latent 去编码这些被故意随机化的、与任务无关的纹理光照——ablation 里它把 manipulation 砸到 0.32;而 probe 又证明不用重建损失 latent 仍能还原场景。这个 argument 既有道理又有数据。
- 为实时规划做的工程是真刀真枪的。chunked 单次前向 dynamics(cross-attention + causal mask,借鉴 AnyCar)让 450 候选 / 8 solver iter 的 MPPI 能在笔记本 4090M 上跑到 50 Hz;极简历史表征(只留最新一帧高维观测)砍延迟。没有这些,sampling-based MPC 在控制频率上根本不可行。
- seq2seq return 头的收益是被量化的,不是直觉:换回 per-step MLP,Table Leg 从 0.85 掉到 0.60。轨迹级 attention 对"给候选 plan 排序"确实重要。
- 机制证据链构造得好:value-overlay(value 跟踪进度并区分成败)+ 脚部打滑预测(loss 0.076→0.019、微调后能预判 slip)+ planning 可视化,构成了"为什么有效"的完整故事,而不只是堆 headline 数字。
5.2 做得不够好 / 值得质疑的地方¶
- 整套框架硬依赖一个高保真仿真器 + 已解任务的 state-based 专家 + dense reward + 价值函数。"降维成监督式 system ID"的前提,是你已经在仿真里把任务解掉了。对没有可信仿真、或仿真里都拿不到专家/dense reward 的任务(很多真实 contact-rich 操作),这套方法直接不适用。作者也承认"依赖足够广的仿真覆盖"。
- reward/value 永久冻结,性能有天花板。conclusion 自己承认:当迁移来的 value 饱和、或不再能区分高水平真机轨迹时,性能会被 cap。要冲到近完美成功率就得更新 value——而那恰好会重新引入它极力规避的灾难性遗忘问题。这是结构性张力,不是小 caveat。
- "ranking 跨 sim-to-real 不变"被当公理用,但测试面很窄。支撑它的是一个 peg 例子 + 一张 value-overlay 图。当真机的奖励地形与仿真定性不同(新失败模式、改变"哪些状态好"而非"如何到达"的接触现象)时,这个假设会破。而他们测的任务恰恰是全局结构天然守恒的(peg 几何、locomotion 前进进度)——最该被压力测试的地方反而最没被测。
- dynamics 微调损失只是 latent 自一致损失(预测 \(z\) 对齐 stop-grad 的真机 encoder),并不直接保证"plan 的 return 排序变好"。\(f\) 单独自适应理论上可能把预测 latent 分布推到 R/V 没被校准的区域。作者用"冻结 encoder 锚定"来辩护,但没有分析 \(f\) 能漂移多远、R/V 在 \(f\) 的输出上还可靠多久。
- 只能闭合 dynamics gap,无法获得仿真里没有的新技能。planner 从冻结 base policy + 噪声 warm-start,如果冻结的 reward/value 区分不出某个需要的新行为,MPPI 在 base policy 周围采样也发现不了它。它改进的是"仿真已会排序的行为的执行",不是任务级泛化。
- baseline 公平性存疑。manipulation 的 RLPD/IQL 用稀疏奖励,而 SimDist 用 dense 蒸馏 reward+value——这等于把"world-model 自适应"和"有没有 dense 信号"混在一起比。SGFT-SAC(同样迁价值)是更干净的对照、SimDist 也确实赢;但 DP/π₀.₅ 拿 100 demo 走 BC,监督范式完全不同,"2×"很难干净归因。
- 真机探索安全性没量化。RLPD 在 Foam 上把机器人弄失稳(不报告)——这既说明在线 RL baseline 不安全,也意味着四足对比有一部分是"别人不安全"。但 SimDist 自己在 15–30 分钟"用一个可能错的 dynamics 模型"探索时摔了多少次、是否安全,并没有给数据。
- "15–30 分钟"掩盖了巨大前置成本。这是在 100k–100M 仿真轨迹 + 专家 RL + 每个平台 ~28–35h 预训练/数据生成之后的真机时间。真机效率是真的,但"快速自适应"是相对这笔重投资而言。
- 数据配方像是逐平台手调、且无敏感性分析。噪声区间分布、checkpoint 选取(manipulation 100k vs 四足 100M、专家占比 36% vs 55.7%)都没给 sensitivity,而"仅专家"ablation 已表明这些旋钮是决定性的。
- 评测规模偏小:manipulation 20 trial/点,四足 5 trial × 3 速度。"单调提升"曲线在这么少试验下方差可能不小;我看到的 manipulation 成功率曲线没有 error bar(只有四足的 forward progress 给了 std)。
5.3 值得继续探讨的方向¶
- 有选择/保守地更新 value 以突破天花板:trust-region / EWC 式正则、或只在新访问区域更新 value,在不灾难性遗忘的前提下打破 cap——作者点名的 next step。
- 不确定性感知的 dynamics(或 LAPO 式 latent-action IDM)来 gate 规划:在自适应 dynamics 不可靠处不让 planner 信任 \(f\),而不是处处信任。
- 替换冻结 base-policy warm-start,引入更广探索以获得仿真没有的新行为,而非只做 dynamics 修正。
- 量化"ranking 到底多不变":专门设计一个 sim 与 real 对"哪些状态好"产生分歧的任务,找出核心 insight 的破裂点。
- 接入互联网规模视频先验(作者明说没用)——在仿真薄弱处补表征/覆盖。
- 在线/持续 dynamics 自适应(vs. 现在"每 20 episode"批量更新)+ 真机数据收集阶段的 safety-aware 探索。
- 退化到粗糙仿真器 时 SimDist 衰减多少:把 dense sim reward / 高保真接触仿真拿掉,测方法的鲁棒边界。