FRS: Improving Robotic Generalist Policies via Flow Reversal Steering¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Improving Robotic Generalist Policies via Flow Reversal Steering
- 作者: Andy Tang*¹, William Chen*², Andrew Wagenmaker², Chelsea Finn¹, Sergey Levine² — Stanford University¹, UC Berkeley²(*共同一作;Wagenmaker 即 DSRL 一作,Finn/Levine 是 π 系列背后的 PI)
- arXiv 编号: 2606.13675 (submitted 2026-06, CORL 2026 preprint 模板)
- 项目页: flow-reversal-steering.github.io
- 关键词: flow matching, policy steering, noise-space policy, VLA, DSRL, VLM guidance, behavioral cloning, sample-efficient RL
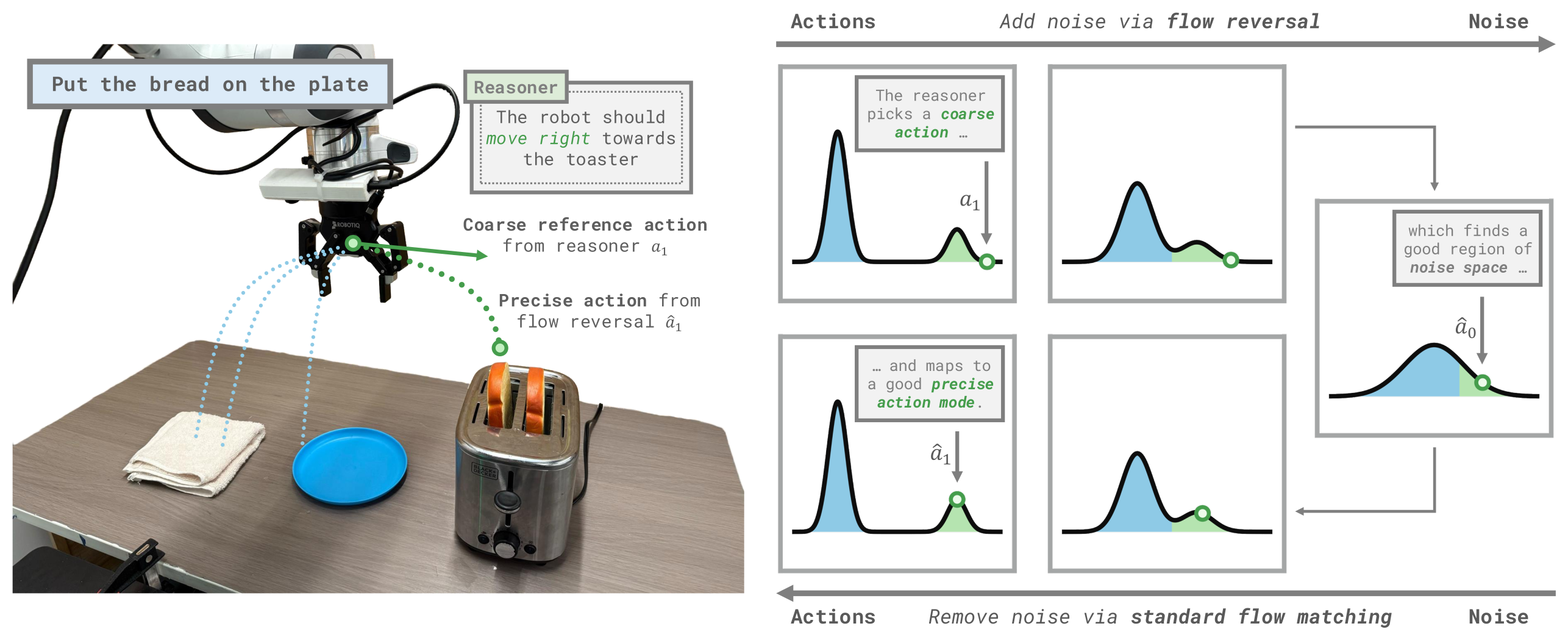 Figure 1:FRS 的核心机制 — reasoner(人或 VLM)给一个粗糙的方向性参考动作 a₁,沿 flow ODE 反向积分找到对应噪声 â₀,再正向去噪得到 â₁。â₁ 落在 generalist 的「合理动作 mode」上,方向与参考一致但细节由 VLA 补全。
Figure 1:FRS 的核心机制 — reasoner(人或 VLM)给一个粗糙的方向性参考动作 a₁,沿 flow ODE 反向积分找到对应噪声 â₀,再正向去噪得到 â₁。â₁ 落在 generalist 的「合理动作 mode」上,方向与参考一致但细节由 VLA 补全。
2. 文章介绍¶
2.1 解决的领域和问题¶
机器人 flow matching generalist policy(π₀.₅ 这类 VLA)的 test-time steering 与快速适应问题。Generalist 在预训练里见过大量技能,对新任务往往「会做但不知道该做」——直接按指令执行时失败,但正确的行为其实就在它的 behavioral prior 里。问题是:当直接 prompt 失败时,如何从这个 prior 里调出语义上正确的动作,并把这种引导变成可学习、可改进的信号?
2.2 Motivation¶
两个关键观察的交汇:
- Flow matching 的 noise→action 映射是确定性的。DSRL(Wagenmaker et al., 2025)已经证明可以把输入噪声 a₀ 当成 latent action,训练一个小的 noise policy 来 steer 冻结的 VLA。但 DSRL 靠 RL 盲目试错找好噪声,噪声空间没有显式结构,探索很贵。
- VLM/人类擅长粗粒度语义推理,不擅长输出精细动作。VLM 知道「擦桌子该去拿海绵」,但发不出灵巧的低层 action chunk;过去的 zero-shot VLM 控制(PIVOT、MOKA 等)受限于此。
FRS 的洞察:既然 flow 是确定性可逆的 ODE,那就把粗糙参考动作反向积分回噪声空间——得到的噪声去噪后会落在 generalist prior 内、且与参考方向一致的精细动作上。这一下打通了「语义 reasoner 出粗动作 → 噪声空间 → generalist 出细动作」的管道,而且不需要任何训练。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| VLM zero-shot 控制 | PIVOT, MOKA, Code-as-Policies | VLM 只能组合高层 primitive,发不出精细低层动作;性能与灵活性 tradeoff |
| Partial noising steering | ITPS, To-Noise-and-Back | 对加噪程度极度敏感:噪声太少改不动,太多丢光参考信息,难调且无效(实验里 92 任务只 +0.6%) |
| Sample-and-rank | ITPS, V-GPS, RoboMonkey | 只能从 base policy 已有的高概率样本里挑;当好行为概率接近 0 时无样本可挑 |
| Noise-space RL | DSRL | 噪声空间无显式结构,只能 RL 随机试错找好噪声;base policy 成功率近 0 时几乎学不动 |
| 残差 RL | PLD | 需要 base VLA 先收集 50 个成功 rollout 做预训练阶段——在 base 成功率 ≤2% 的任务上不可行 |
| VLM reward | RoboMeter 等 | VLM 细粒度视觉评估能力弱,dense reward 噪声大;且依赖 base policy 本身能撞上好动作 |
2.4 论文解决方案(一句话)¶
把人或 VLM 给出的粗糙方向性参考动作沿冻结 flow VLA 的 ODE 反向积分得到对应噪声,去噪后即得「方向一致但 in-distribution」的精细动作(zero-shot steering);这些 (o, â₀) 对又可以直接监督训练一个 ~1 GB、一分钟练完的 noise policy(DSBC),或作为 prior data + BC 辅助 loss 引导 noise-space RL(DSRL + FRS),在 base policy 几乎全挂的任务上也能起步。
2.5 与前序工作的关系¶
- 直接构建在 DSRL 之上(共同作者 Wagenmaker):复用「noise 即 latent action」的框架和 SAC 实现,贡献在于用 flow reversal 替代随机探索来发现好噪声,并新增 BC-only(DSBC)这条更便宜的路径。
- Base policy 全部是 π₀.₅ 系:LIBERO 用 OpenPi 的 π₀.₅-LIBERO 和 Polaris 微调版,真机用 π₀.₅-DROID。方法本身不改 VLA 一行权重。
- VLM reasoner 用 Gemini-ER-1.6,输出结构化 JSON(embodied CoT + 三轴方向 + 幅度 + 是否 defer)。
- 与本库已读论文的关系:GenPO(2505.18763)也做 diffusion/flow 反演,但用途是估计 likelihood 做 on-policy RL 更新;ZPRL(2605.19919)同样走「小 latent policy steer 冻结大模型」路线,但 latent 是学出来的 bottleneck 而非 flow 噪声。Concurrent 工作 UniSteer 几乎同机制(反演人类动作 + noise RL 加 BC 项),FRS 的差异化在 (1) 反演的是粗糙动作(VLM 可发),(2) 证明纯 BC 即可(不必 RL),(3) 证明可以 bootstrap 几乎零成功率的 RL。
3. 方法介绍¶
 Figure 2:三段式 pipeline — (1) reasoner 推断粗参考动作;(2) flow reversal 找到附近的好 action mode;(3) 三种用法:zero-shot 直接执行 / DSBC 监督学习 noise policy / DSRL+FRS bootstrap RL。
Figure 2:三段式 pipeline — (1) reasoner 推断粗参考动作;(2) flow reversal 找到附近的好 action mode;(3) 三种用法:zero-shot 直接执行 / DSBC 监督学习 noise policy / DSRL+FRS bootstrap RL。
3.1 形式化¶
Flow matching VLA 学一个速度场 v_θ(a_t, t | o),从噪声 a₀ ~ N(0, I) 经 Euler 积分去噪到动作 a₁:
记为 a₁ ← μ_θ(a₀, o)。DSRL 框架下,noise policy π_φ^noise(a₀ | o) 输出噪声而非动作,VLA 充当冻结的「噪声解码器」。
3.2 Flow Reversal:核心机制(零训练)¶
由于 flow 去噪对给定输入是确定性的,ODE 可以反着积分,由参考动作 a₁ 求出对应噪声:
记为 â₀ ← μ_θ⁻¹(a₁, o)。计算量与一次标准去噪完全相同(10 次 forward),不改模型。再正向去噪 â₁ ← μ_θ(â₀, o):
- h→0 时 â₁ 精确重建 a₁;
- 有限步数(论文用 10 步)下积分误差使 â₁ ≈ a₁ 但被「拉回」VLA 的 in-distribution 流形——方向跟随参考,细节(抓取时机、旋转、夹爪)由 VLA 按场景 affordance 补全。
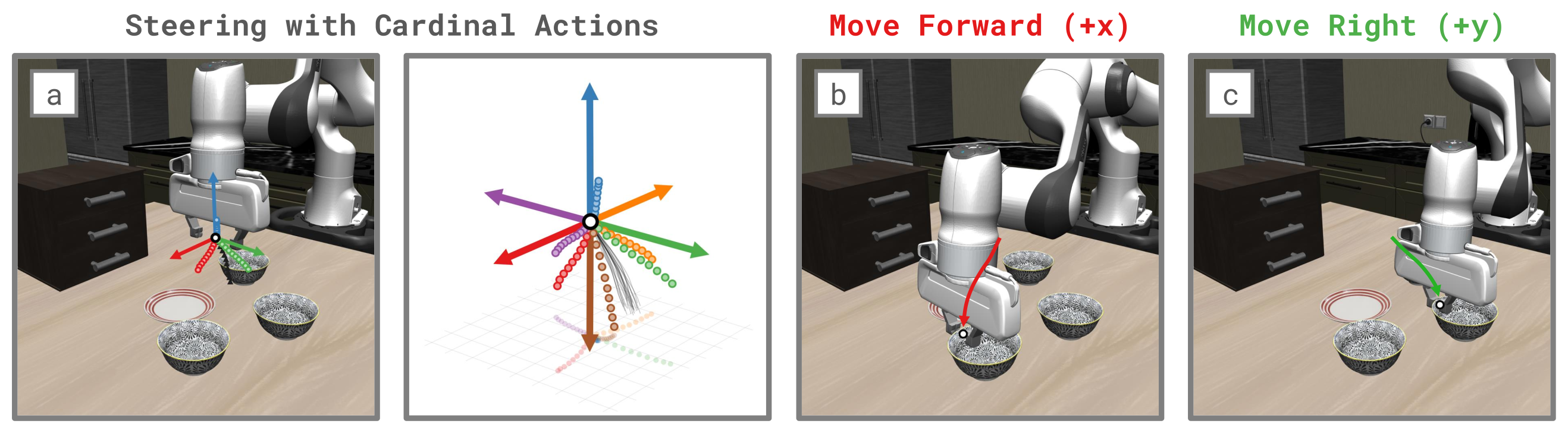 Figure 3:π₀.₅ 在 LIBERO 上的实测效果。实线箭头是方向性参考动作,同色点是 steered 后的采样动作——方向大体跟随参考,但被场景 affordance 偏置(空夹爪在桌上方时倾向往下伸向物体)。黑色是无 steering 的 base policy 样本。
Figure 3:π₀.₅ 在 LIBERO 上的实测效果。实线箭头是方向性参考动作,同色点是 steered 后的采样动作——方向大体跟随参考,但被场景 affordance 偏置(空夹爪在桌上方时倾向往下伸向物体)。黑色是无 steering 的 base policy 样本。
关键区分:flow reversal ≠ forward diffusion 加噪。后者是 a_t = t·a₁ + (1−t)·a₀ 的线性插值,t→0 时参考信息全部丢失;前者是确定性的 data↔noise 双射。这就是 partial noising baseline 难调而 FRS 稳定的原因。
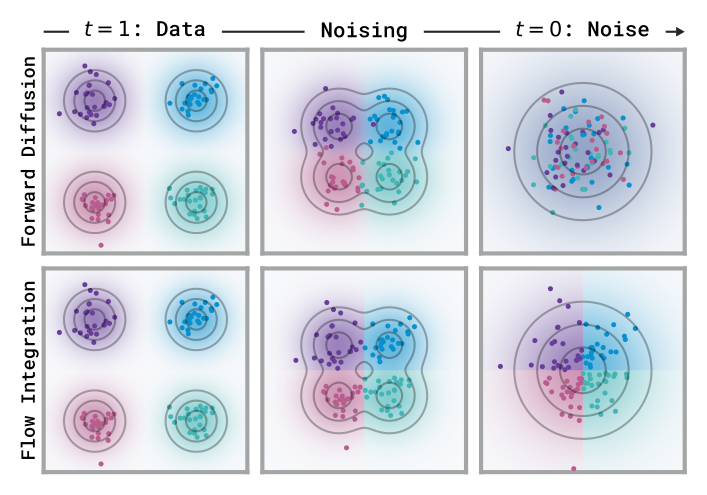 Figure 4:二者边缘分布相同,但 forward diffusion(上排)靠噪声插值、信号迅速湮灭;flow integration(下排)是确定性映射,每个数据点对应唯一噪声。
Figure 4:二者边缘分布相同,但 forward diffusion(上排)靠噪声插值、信号迅速湮灭;flow integration(下排)是确定性映射,每个数据点对应唯一噪声。
3.3 Steering 接口:人和 VLM 怎么给参考动作¶
两种 reasoner 都只发笛卡尔方向性动作(粗到不能再粗):
- 人类:键盘 W/A/S/D/Q/E 控制三个平移轴 + 夹爪键(开/关/「noise 模式」= 让 VLA 自己决定)+ defer 键。每次按键经 DROID IK 转成 5 步关节动作,tile 到 chunk 长度 15,tile 部分的噪声置为 N(0,I)(噪声空间的 in-painting)。每 episode 最多 40 次按键,对比连续遥操作便宜得多。
- VLM(Gemini-ER-1.6):输入第三人称视图 + 一条从桌面到夹爪的「铅垂线」标注(弥补单目深度感知),输出 JSON:embodied CoT → 是否 defer → 三轴 +/0/− 方向向量 → 幅度(大/小)。旋转全部置 0、夹爪置半开——但去噪后 VLA 仍会按场景输出合理的旋转和夹爪值。
在线推理循环:每个 chunk 查询一次 reasoner → 方向转参考动作 → flow reversal → 去噪 → 执行前 10 步。
3.4 DSBC:噪声空间的行为克隆¶
把 FRS 产生的 (o, â₀) 当「专家噪声动作」做监督学习:π_φ^noise ← argmax E[log π(â₀|o)]。两种数据来源:
- Online:zero-shot FRS rollout 的成功轨迹(噪声已被执行验证过);
- Offline:对任意现成的标准演示数据(只有动作没有噪声)逐帧跑 flow reversal,凭空造出噪声标签——这把任何 demo 数据集变成 noise-action 数据集,绕开了 DSRL 用 prior data 需要 Q-function 蒸馏的麻烦。
最有意思的实证性质:DSBC 对 compounding error 隐式鲁棒。noise policy 在 OOD 状态输出的「烂噪声」会被 VLA 当成接近噪声先验的输入,仍解码成 in-distribution 的合理动作——相当于自动 fallback 到 VLA 的 behavioral prior。这解释了真机上同数据量的标准 BC 全军覆没而 DSBC 能到 80%。
3.5 DSRL + FRS:bootstrap 噪声空间 RL¶
对标准 DSRL(SAC)做两处小改动:
- actor loss 加 BC 辅助项:
L = L_DSRL + β·L_BC(β=1,BC batch 只从成功的 FRS 轨迹采样); - replay buffer 用 FRS 轨迹 prefill(含失败轨迹)。
在 base policy 成功率近 0 的任务上,只要一条 FRS 成功轨迹(可能要试 50 次才撞出一条)就足以解决稀疏奖励的探索冷启动。这一档实验还把 tanh clipping 换成无 clip + 0.1 KL-to-N(0,1) 正则,让 policy 能表达 OOD 噪声。
3.x Implementation Details¶
| 项目 | 数值 |
|---|---|
| Flow reversal / 去噪积分步数 | 10 步(h=0.1,OpenPi 默认;更多步重建更准但噪声更 OOD) |
| Noise policy 规模 | MLP (128,128,128)(LIBERO);DSRL 小 CNN + (256,256,256)(真机) |
| LIBERO noise policy 输出 | 单个 7D 向量(chunk 平均噪声),重复到 chunk 长度 + padding 维填 N(0,I) |
| 真机 noise policy 输出 | 完整 15×8 噪声 chunk(不平均) |
| DSBC 训练 | 12,500 步,batch 128,Adam,<1 分钟,~1 GB GPU(VLA 不参与训练) |
| DSBC 数据量 | LIBERO 平均 18 条成功 rollout/任务;真机 10 条/任务 |
| DSRL+FRS | SAC,critic ensemble 10,UTD 10–20,γ=0.999,200k–250k 梯度步 |
| Tanh clip | ±5(比 DSRL 原版 ±1 宽,为拟合 OOD 动作的噪声) |
| 评测 | LIBERO 50 trials/任务,真机 20 trials/任务,Wilson CI |
噪声空间分析(appendix C)的几个实用结论:(1) flow reversal 噪声的 L2 范数是参考动作 OOD 程度的 proxy(ID 动作映到小范数噪声);(2) 积分步数 ↑ → 重建 MSE ↓ 但噪声范数 ↑(更 OOD);(3) 给 FRS 噪声加 σ=1~2 的高斯扰动反而涨点——FRS 找到的是好的噪声区域而非单点;(4) 噪声沿 chunk 轴平均再重复,性能不掉。
4. 结果对比¶
4.1 Zero-shot steering(92 个 LIBERO 任务,VLM 引导)¶
| 方法 | 平均成功率 | 困难任务提升数* |
|---|---|---|
| Base policy (π₀.₅) | ~8.6% | — |
| VLM 动作直接执行 | ~7.6%(低于 base) | 8 |
| Partial noising w/ VLM | ~9.2% | 4 |
| Sample-and-rank w/ VLM | ~10.3% | 3 |
| Zero-shot FRS w/ VLM (Ours) | ~13.3% | 11 |
* base ≤2%(50 次 0–1 成功)的 42 个任务中,绝对提升 ≥10% 的任务数。VLM 动作直接执行能救 8 个任务但整体掉点;FRS 是唯一整体和困难任务双赢的。
Oracle 上限实验(appendix):把 VLM 换成 LIBERO-90 专家 VLA(93.9%)做 steering,FRS 在全 LIBERO-90 从 base 30.8% → 50%(困难子集 4.5% → 33.7%,VLM 引导只有 11.1%)——参考动作质量直接决定 steering 上限,当前 VLM 接口远没榨干方法潜力。
4.2 DSBC(15 个 LIBERO-90 任务 + 6 个真机 DROID 任务)¶
LIBERO(每任务平均 18 条 FRS 成功轨迹,<1 分钟训练):
| 方法 | 平均成功率 |
|---|---|
| Base policy (π₀.₅) | ~10% |
| Standard BC(同数据、同架构、学 robot action) | ~28% |
| DSBC(学 noise action) | ~37% |
| Zero-shot FRS w/ VLM(上界参考) | ~37% |
真机 DROID(每任务 10 条人类 steered 成功轨迹):
| 方法 | 6 任务平均 |
|---|---|
| Base policy (π₀.₅-DROID) | ~20% |
| Standard BC(flow policy,同数据) | ~0%(完全失败) |
| Zero-shot FRS w/ Human | ~87% |
| DSBC | ~80% |
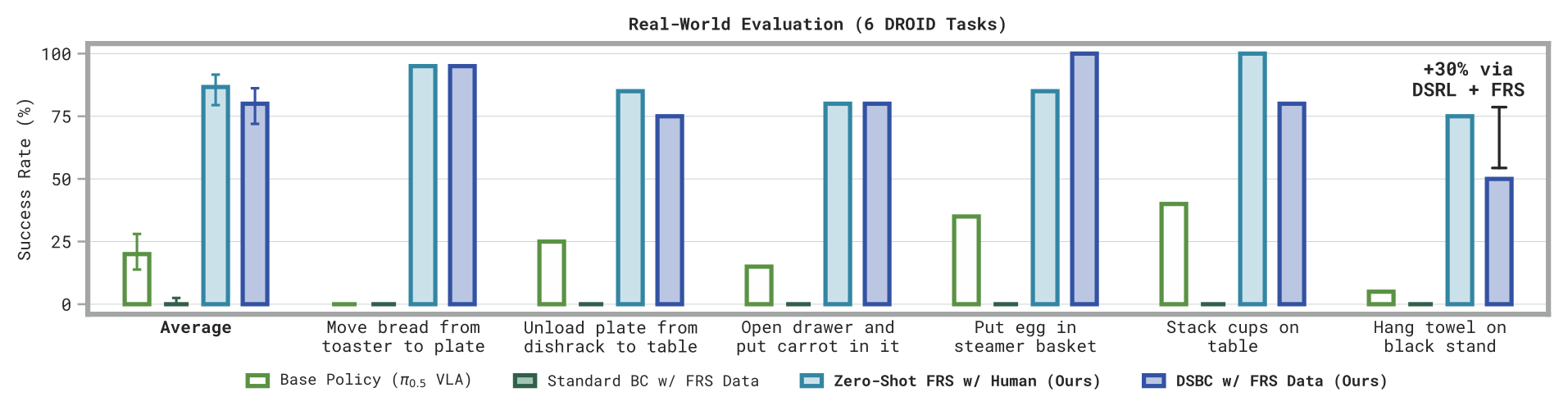 Figure 5:六个真机任务逐项结果。注意 standard BC(深绿)全部贴零 — 10 条轨迹的低数据量下只有能 fallback 到 VLA prior 的 noise policy 学得动。最右 towel hanging 任务再叠 DSRL+FRS 可从 50% 提到 80%。
Figure 5:六个真机任务逐项结果。注意 standard BC(深绿)全部贴零 — 10 条轨迹的低数据量下只有能 fallback 到 VLA prior 的 noise policy 学得动。最右 towel hanging 任务再叠 DSRL+FRS 可从 50% 提到 80%。
单任务最大提升:「move bread from toaster to plate」base 0% → DSBC 95%(摘要里 "95% absolute boost" 即此)。Towel hanging:base 5% → DSBC 50% → 简单 policy-gradient RL 后 80%。
Offline DSBC:对整个 LIBERO-90 标准数据集(无噪声)跑 flow reversal 造标签,89 任务平均 30% → 40%;真机 tape-hanging 任务用 20 条普通遥操作演示,DSBC 超过 base 和标准 flow BC。
4.3 DSRL + FRS(RL 实验)¶
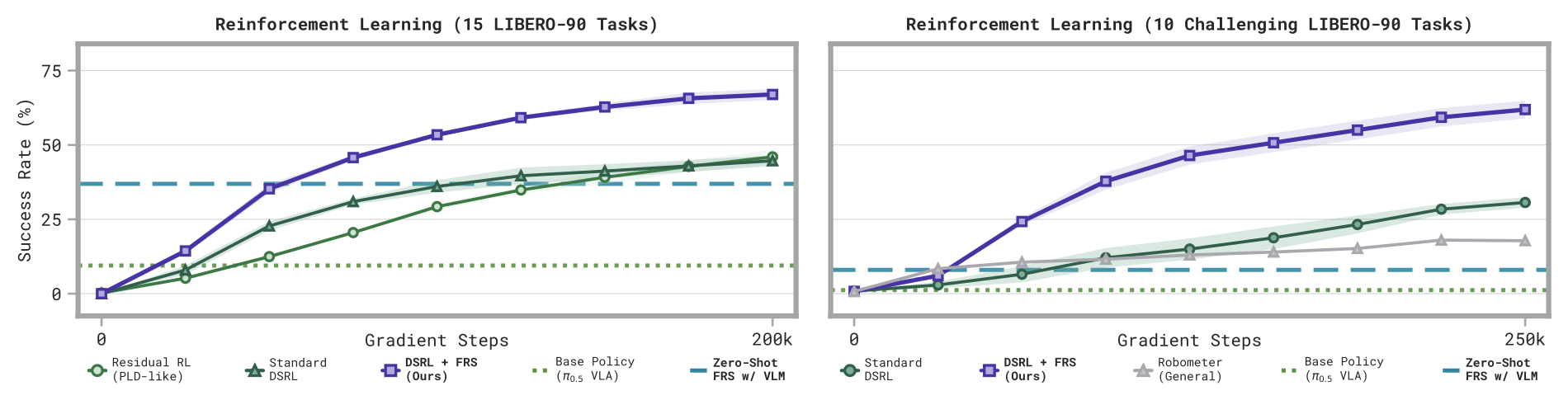 Figure 6:左 — 15 任务上 prefill 20 条 FRS rollout 的 DSRL+FRS(紫)全程压制 standard DSRL 与 residual RL,最终 ~67% vs ~45%。右 — 10 个 base 近 0% 的困难任务,仅 prefill 一条 FRS 成功轨迹即可 ~62%,而 DSRL ~30%、RoboMeter reward ~18%、zero-shot FRS 本身只有 8%。
Figure 6:左 — 15 任务上 prefill 20 条 FRS rollout 的 DSRL+FRS(紫)全程压制 standard DSRL 与 residual RL,最终 ~67% vs ~45%。右 — 10 个 base 近 0% 的困难任务,仅 prefill 一条 FRS 成功轨迹即可 ~62%,而 DSRL ~30%、RoboMeter reward ~18%、zero-shot FRS 本身只有 8%。
| 设定 | DSRL + FRS | Standard DSRL | Residual RL (PLD-like) | RoboMeter reward |
|---|---|---|---|---|
| 15 任务(prefill 20 条) | ~67% | ~45% | ~46% | — |
| 10 困难任务(prefill 1 条成功) | ~62% | ~30% | 不可行* | ~18%(1 seed) |
* PLD 预训练阶段需要 base VLA 的 50 条成功 rollout,在 ≤2% 成功率任务上不可行。
第二个设定是论文最强的卖点:zero-shot FRS 自己只有 8%,但它把「第一次成功」的发现成本从 RL 的随机探索压缩成 ~50 次 steered 尝试,一条成功轨迹就足以解锁 RL。
4.4 关键消融(appendix)¶
| 设定 | 结果 |
|---|---|
| FRS 噪声 + σ·N(0,I),σ=0.1 | 持平 |
| FRS 噪声 + σ·N(0,I),σ=1 或 2 | 反而显著涨点(好噪声是区域不是点) |
| 噪声沿 chunk 轴平均+重复 | 持平(所有 LIBERO noise policy 因此只预测 7D 平均噪声) |
| Padding 维噪声置 N(0,I) | 不影响(全文采用) |
| 积分步数 5→100 | 重建 MSE 单调降,噪声范数单调升;选 10 折中 |
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 机制零成本且不动模型。Flow reversal 与一次标准去噪计算量完全相同(10 次 forward),不改权重、不加模块、不需训练。相比 partial noising 多一个噪声量超参、sample-and-rank 多 16 倍采样,FRS 是这一族方法里最干净的。
- 「积分误差即正则化」的设计直觉被消融反向证实。10 步粗积分的重建误差不是 bug 而是 feature——它把 OOD 参考拉回 VLA 流形。σ=1~2 扰动反而涨点、平均+重复噪声不掉点,说明方法依赖的是噪声空间的区域级结构,鲁棒性有实证支撑,这也是 DSBC 能用小 MLP 学会的根本原因。
- DSBC 的 OOD fallback 机制是真发现。标准 BC 在 OOD 状态输出烂动作 → compounding error;DSBC 在 OOD 状态输出的烂噪声被 VLA 解码成 prior 内的合理动作。真机上同数据同架构 standard BC 全部 0% vs DSBC 80% 是非常干净的对照,这个机制对所有「冻结大模型 + 小 latent policy」路线(含 ZPRL)都有借鉴意义。
- 分工切中两边的能力边界:VLM 出它擅长的粗语义方向(+x/−y 这种三值输出,几乎不可能错得离谱),VLA 出它擅长的精细动作。对比直接执行 VLM 动作整体掉点(7.6% < 8.6%),证明增益确实来自「投影回 prior」而非 VLM 本身。
- Offline DSBC 是个被低估的副产品:任何标准演示数据集跑一遍 flow reversal 就变成 noise-action 数据集,绕开 DSRL 的 Q-蒸馏。LIBERO-90 全集 30%→40%、真机 tape-hanging 都验证了。这给 noise-space 方法接入存量数据提供了通用入口。
- 「一条成功轨迹 bootstrap RL」精准打击稀疏奖励冷启动。困难任务上 DSRL 卡在 30% 的原因就是 base policy 几乎采不到成功;FRS 把找第一条成功的成本从不可控的随机探索变成 ~50 次 steered 尝试。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 摘要的 "95% absolute boost" 是单任务最佳情况(真机 bread-toaster 任务 0%→95%),而方法的 zero-shot 主结果是 92 任务平均 8.6%→13.3%(+4.7%)。两个数字相差 20 倍,摘要的呈现方式有 cherry-picking 之嫌。
- 理论解释基本缺位。「为什么 OOD 参考动作反向积分会落到好的噪声区域」全靠 appendix 一个 2D 高斯混合玩具例子 + 经验观察。核心机制依赖有限步积分误差这个未被控制的量:appendix 自己显示步数 ↑ 则噪声更 OOD、步数 ↓ 则重建更差,10 步是经验折中。方法的成立条件(什么样的 VLA、什么样的参考动作分布下有效)完全没有刻画——换一个去噪步数不同或流形更尖锐的 base policy,结论是否迁移未知。
- VLM steering 系统含隐藏的特权信息。铅垂线标注需要桌面高度、末端位姿和相机标定;VLM 只看第三人称视图是因为「VLM 融合腕部视图能力差」。论文声称这些在真实 setup 里也易获取(ChArUco 标定),但这套系统工程没有任何消融——去掉铅垂线 VLM steering 还剩多少?不知道。
- 「一分钟训练」的宣传掩盖了数据收集成本。DSBC 的数据是每任务 50 条 zero-shot FRS rollout(每 chunk 查一次 Gemini API)或真机每任务 20 次人类试验。人类 steering 虽比遥操作便宜(每 episode ≤40 次按键),但本质仍是 human-in-the-loop 监督,与 HG-DAgger 一族可比——而论文没有和任何 intervention-based 基线(HG-DAgger、HIL-SERL)对比。
- Partial noising baseline 只测了一个设定(t=0.5、5 步)。论文正文说这类方法「对噪声量高度敏感、难调」,却没有展示扫超参的结果——用一个未调优的点来代表整族方法,对比偏弱。Sample-and-rank 用 cosine 相似度做打分也偏 naive(V-GPS 等原方法用学习的 value function)。
- Residual RL 基线被简化:去掉了 PLD 的 probing 阶段和预训练阶段。后者在目标任务上确实不可行(需 base 50 条成功),但这意味着「PLD-like」严格弱于真 PLD,左图 residual RL ~46% 的数字应打折扣看。RoboMeter 基线只跑 1 seed。
- 与 concurrent 工作 UniSteer 的边界很薄。UniSteer 同样是 flow reversal 人类动作 → noise RL + BC 项。FRS 的差异化(粗动作/VLM 可发、BC-only 路径、单成功轨迹 bootstrap)是真实的,但核心技术机制相同,方法论新颖性主要在应用方式而非机制本身。
- LIBERO 上 DSBC vs standard BC 的差距(37% vs 28%)说服力有限,论文自己承认 LIBERO 随机化少、小数据死记硬背也能活。真机对照(80% vs 0%)干净得多,但只有 6 任务 × 20 rollouts,Wilson CI 不小。另外 LIBERO noise policy 预测 7D 平均噪声即可,真机却必须预测完整 15×8 噪声 chunk——这个不一致暗示 chunk 平均技巧在更难的任务上失效,但论文没有讨论。
- 旋转不可 steer。人类接口六个键全是平移,VLM 输出旋转恒置 0,全靠去噪「顺便」补全旋转。对 LIBERO/DROID 这类 top-down 抓取够用,但对需要主动控制姿态的任务(开门把手、拧瓶盖、工具使用)这个接口天花板很低;oracle 实验已经显示参考动作质量是主要瓶颈。
- 正文 Discussion/limitation 一句带过("some parts are limited" 然后就没了),CORL 模板下显得仓促。VLM 查询延迟(每 chunk 一次 Gemini-ER API 调用对真机控制频率的影响)、失败模式分析(FRS 什么时候把好参考带坏)全文未报告。
5.3 值得继续探讨的方向¶
- 更强的参考动作来源:oracle 实验显示 11.1% → 33.7% 的 headroom。用 MOKA 式 keypoint/waypoint、VLM 输出轨迹 sketch、甚至视频生成模型的预测帧 + 逆动力学来产生参考动作,应该能直接抬 zero-shot 上限。
- 旋转与夹爪的 steering 接口:当前三值平移向量是信息量下限。一个自然扩展是让 VLM 在 SO(3) 上发粗旋转方向(如「绕 z 转」三值),或对夹爪用论文已有的「noise 模式」做逐维选择性 steering。
- 噪声范数作为 OOD 检测器:appendix 发现 flow reversal 噪声的 L2 范数是参考动作 OOD 程度的 proxy。这可以反过来用——部署时实时监控 â₀ 范数,超阈值就拒绝执行或请求人类介入,把 FRS 变成带置信度的 steering。
- 与精确 likelihood 的关系:flow 的 instantaneous change-of-variables 可以算精确 log-prob(GenPO 正是这么用的)。FRS 用范数做粗 proxy,二者结合或许能给「好噪声区域」一个可计算的刻画,补上理论缺口。
- 蒸馏回 VLA:DSBC policy 是外挂的,论文提到可以把成功轨迹蒸馏回 VLA 但嫌贵。值得探讨 LoRA 级别的轻量蒸馏,对比「外挂 noise policy」vs「内化进权重」的长期 scaling——这正好与 RECAP/π*₀.₆ 的 advantage conditioning 路线形成对照。
- 多任务/语言条件 noise policy:当前每任务训一个 DSBC 小 MLP。把 noise policy 做成语言条件的(吃 VLA 的中间特征),一个模型 steer 所有任务,是走向实用的必经一步。
- 失败轨迹的利用:DSRL+FRS 的 buffer prefill 已经塞了失败轨迹,但 BC 项只用成功的。困难任务上 FRS 失败轨迹往往「方向对但差最后一步」,advantage-weighted 或 hindsight relabel 也许能从中再榨一截。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页: flow-reversal-steering.github.io
- 关键 baseline / 相关论文:
- DSRL (Wagenmaker et al., 2025) — 本文直接构建的 noise-space RL 框架
- π₀.₅ (Physical Intelligence) — 全部实验的 base VLA,本库笔记
- GenPO (2505.18763) — diffusion 反演估 likelihood 做 RL,本库笔记
- ZPRL (2605.19919) — bottleneck latent RL steering,本库笔记
- UniSteer (Lu et al., 2026) — concurrent,flow reversal 人类动作 + noise RL
- PLD (Probe-Learn-Distill) — residual RL 基线;ITPS / To-Noise-and-Back — partial noising 基线