Octo: An Open-Source Generalist Robot Policy¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Octo: An Open-Source Generalist Robot Policy
- 作者: Octo Model Team — Dibya Ghosh*, Homer Walke*, Karl Pertsch*, Kevin Black*, Oier Mees*, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, Sergey Levine — UC Berkeley + Stanford + CMU + Google DeepMind 等
- arXiv 编号: 2405.12213 (submitted 2024-05, RSS 2024)
- 项目页: https://octo-models.github.io
- 关键词: generalist robot policy, Open-X Embodiment, ViT-based policy, diffusion action head, multi-task pretraining, language + goal image conditioning
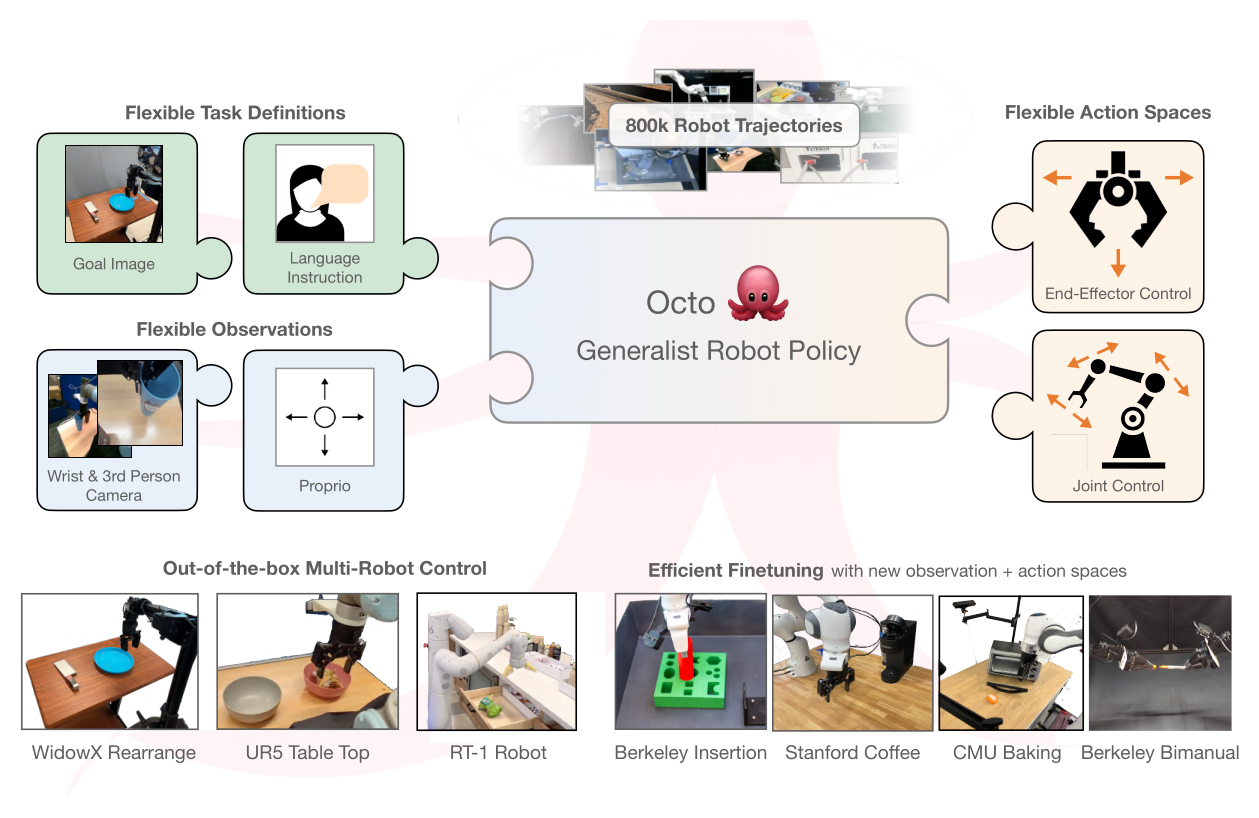 Figure 1:Octo 是首个完全开源的 generalist robot policy — pretrained checkpoints、训练 pipeline、数据 loader 全部公开,可以下游 finetune 到新本体、新观测(如力矩感知)、新动作空间(如关节位置控制)。
Figure 1:Octo 是首个完全开源的 generalist robot policy — pretrained checkpoints、训练 pipeline、数据 loader 全部公开,可以下游 finetune 到新本体、新观测(如力矩感知)、新动作空间(如关节位置控制)。
2. 文章介绍¶
2.1 解决的领域和问题¶
构建跨本体的「通用机器人策略」(generalist robot policy, GRP)。NLP 和 CV 已经有了 GPT-4 / SAM 这样的通用基础模型,但机器人领域还没有同等地位的「通用控制器」——主要因为机器人本体异构(不同自由度/末端执行器/相机配置)、动作空间各异、任务规范不统一(语言指令 vs 目标图像)、且每个团队的硬件预算和场景都不同。
Octo 想做的事是:在 Open-X Embodiment(OXE)这个最大的跨本体真机数据集(800K trajectories)上预训练一个灵活的、可下游 finetune 到全新观测/动作空间的 transformer policy,并把所有权重和代码开源。
2.2 Motivation¶
之前的 GRP 工作(RT-1-X、RT-2-X、RoboCat、GNM 等)已经在跨本体训练上有进展,但有几个共性的限制:
- 输入输出空间被锁死:预训练时定义了相机配置、动作维度、任务规范,下游用户没法换;
- 不支持 finetune 到全新的传感器/动作空间(比如下游需要力矩、需要关节位置控制);
- 最大的模型(RT-2-X 55B)完全闭源——没法本地部署、没法二次开发。
Octo 的核心 design choice:让 transformer 处理「任意 token 序列」(任务 token + 观测 token + readout token),所有模态走 modality-specific tokenizer,block-wise causal mask 让缺失模态可以被 mask 掉。这样下游加新观测/动作只是改 tokenizer 和 head,transformer 主干完全不需要重训。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 跨本体 transformer policy | RT-1-X (35M)、RT-2-X (55B) | 输入输出锁死单相机;离散动作精度差;RT-2-X 闭源;都不支持加新传感器 |
| 单本体通用策略 | RoboCat、PaLM-E、GATO | 限制在已见 embodiment / sensor 配置内 |
| 预训练视觉表征 | VC-1、R3M | 只提供 vision encoder,不是 policy;finetune 时整套 head/decoder 要从头训 |
| Diffusion Policy(单任务) | DP | 不跨本体、不支持语言指令 |
2.4 论文解决方案(一句话)¶
一个完全开源的 transformer-based generalist robot policy:输入是模块化的 token 序列(语言/目标图像/多相机观测),中间是 block-wise masked ViT-style transformer + 可插入的 readout tokens,输出端是一个轻量级 diffusion action head 做连续多模态 action chunk 预测;在 OXE 800K trajectory 上预训练,下游可在单卡 A5000 5 小时内 finetune 到带新观测(力矩)/新动作空间(关节位置)/新本体(双臂)的设置。
2.5 与前序工作的关系¶
- 数据集:Open-X Embodiment 的 25 个数据集(其中 9 个标为 "more diverse" 权重翻倍,几个重复性强的 down-weight)。OpenVLA 后来直接沿用了 Octo 的数据混合权重。
- 动作头:diffusion head 借鉴 Diffusion Policy(Chi et al. 2023);action chunk 借鉴 ACT(Zhao et al. 2023);DDPM 训练目标用 cosine noise schedule(Nichol & Dhariwal 2021)。
- 架构:transformer-first(shallow CNN patch encoder + 大 transformer 主干),与 ViT/MAE 一脉,区别于 RT-1 那种「大 ResNet + 小 transformer」。
- task spec:语言走冻结 T5-base (111M) 出 token,目标图像走和观测一样的 patchify。
- 是 OpenVLA 的直接前作:OpenVLA 沿用了 Octo 的数据混合,但换了 LLM 主干(Llama 2 7B)和动作输出方式(discrete tokens)。
3. 方法介绍¶
3.1 架构总览¶
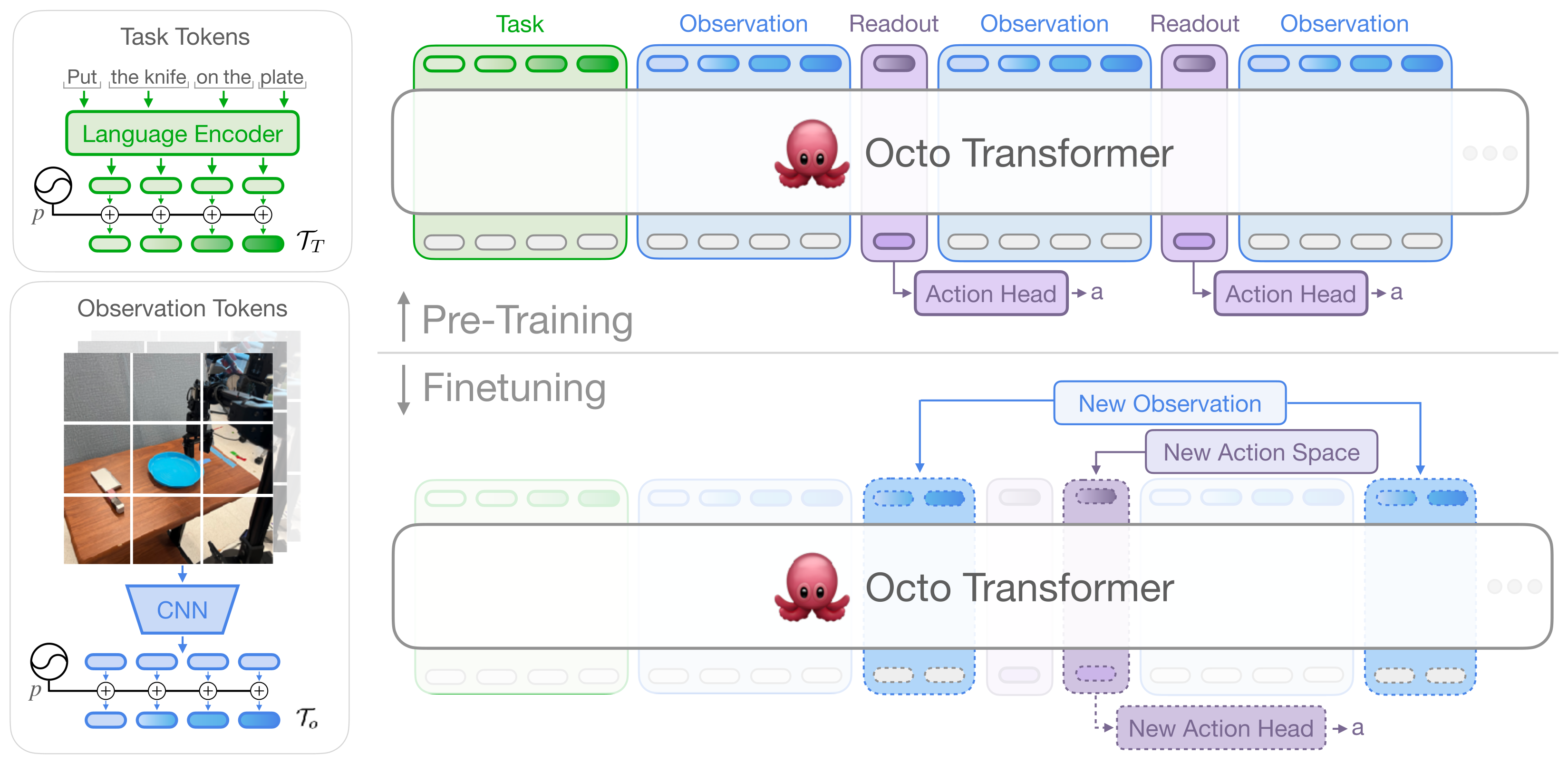 Figure 2:Octo 的「输入 token + transformer + readout head」三段式。上:预训练时 task token / observation token / readout token 沿时间轴串成序列,block-wise causal attention(observation 只看同时间/更早的 + task token),轻量 diffusion action head 挂在 readout token 上。下:finetune 时可以直接加新 observation tokenizer / 新 readout head,不动主干。
Figure 2:Octo 的「输入 token + transformer + readout head」三段式。上:预训练时 task token / observation token / readout token 沿时间轴串成序列,block-wise causal attention(observation 只看同时间/更早的 + task token),轻量 diffusion action head 挂在 readout token 上。下:finetune 时可以直接加新 observation tokenizer / 新 readout head,不动主干。
三部分:
1. Input tokenizers:语言走 t5-base 出 token;图像(含 wrist / 第三视角 goal image)走 shallow CNN patch encoder + flatten。每个 token 加 learnable position embedding。
2. Transformer backbone:block-wise masked attention—— observation token 只 causal attend 到同/更早时间步的 observation 和所有 task token;缺失模态完全 mask 掉(比如某数据集没语言)。引入 readout tokens(类比 BERT 的 [CLS]):它们 attend 所有更早的 token,但任何 token 都不 attend 它们,所以是「被动 read-only」聚合器,下游加 head 不会影响主干表征。
3. Action head:轻量 conditional diffusion head 挂在 readout embedding 上。一次 transformer forward 出 readout embedding,diffusion 多步去噪全部在 head 内部完成。输出是 action chunk(多步连续动作)。
3.2 训练目标:Diffusion + Action Chunk¶
用标准 DDPM:从 Gaussian 噪声 x^K 开始,K 步去噪到干净 action chunk。head 学的是 ε_θ(x^k, e, k),e 是 transformer 的 readout embedding。cosine noise schedule。
为什么不直接 MSE 或离散 token?消融里给了答案(§4 ablation table):
| 训练目标 | 聚合成功率 |
|---|---|
| Discretized action prediction(RT-1/2 风格) | 18% |
| Continuous MSE | 35% |
| Diffusion | 83% (Small) / Octo-Small full |
Diffusion 同时拿到「能模 multi-modal」(不像 MSE 会平均掉)和「连续精度高」(不像离散)两个好处。
3.3 模块化输入:finetune 才是真本事¶
预训练时所有数据都是 RGB + 末端执行器 delta 控制。但下游想要的可能完全不一样:
- Berkeley Insertion 任务需要力矩观测(force-torque),就加一个新 proprio tokenizer,main transformer 不变;
- Berkeley Pick-Up / Bimanual 任务用关节位置控制(而非 delta EE),就加一个新 action head;
- Berkeley Bimanual 是双臂,动作维度翻倍——同样只换 head;
- 缺失语言时自动用目标图像 condition(hindsight goal relabeling)。
这种模块化是 Octo 的最大卖点,也是 RT-X 系列做不了的事。
3.x Implementation Details¶
| 项目 | 数值 |
|---|---|
| 模型规模 | Octo-Tiny ~27M / Octo-Small ~27M / Octo-Base 93M |
| 主干 | ViT-S / ViT-B 等深,shallow CNN patch encoder |
| 语言编码器 | 冻结 t5-base (111M) |
| 训练数据 | OXE 中 25 个数据集,共约 800K 轨迹(论文标 \ntrajs{} ≈ 800K) |
| 观测历史长度 | 2 帧(更多帧 diminishing returns) |
| 预训练 | TPU v4-128,300K 步,batch 2048,14 小时(Octo-Base) |
| Finetune | 单卡 A5000 24GB,~100 demo,50K 步,约 5 小时 |
| Optimizer | AdamW,weight decay 0.1,grad clip 1.0,inverse sqrt decay lr |
| Hindsight goal relabeling | 是(随机从 future 选 goal frame)+ 随机 dropout language/goal 让模型学单边 condition |
| Action chunk | 是;diffusion DDPM cosine schedule |
4. 结果对比¶
4.1 Zero-shot 跨本体控制(与 RT-1-X / RT-2-X 同台)¶
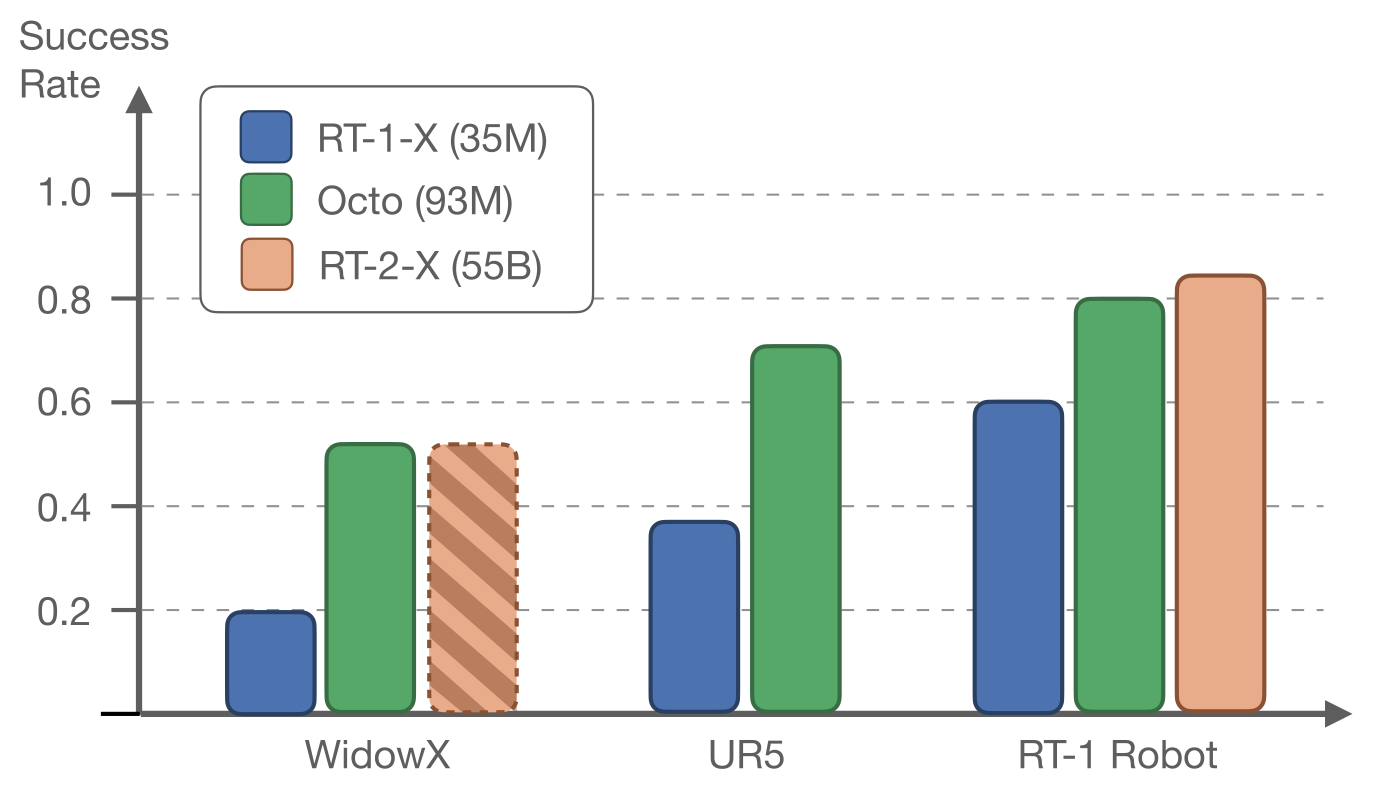 Figure 3:在三个机器人(WidowX BridgeV2、RT-1 robot、其他)上 zero-shot。Octo 平均比 RT-1-X (35M) 高 29 个点;和 RT-2-X (55B) 大致持平——后者是 1571 倍参数量。所有任务都是 in-distribution(OXE 训练数据见过),考察的是 generalization 到新物体位置/光照/干扰物。
Figure 3:在三个机器人(WidowX BridgeV2、RT-1 robot、其他)上 zero-shot。Octo 平均比 RT-1-X (35M) 高 29 个点;和 RT-2-X (55B) 大致持平——后者是 1571 倍参数量。所有任务都是 in-distribution(OXE 训练数据见过),考察的是 generalization 到新物体位置/光照/干扰物。
| 方法 | 参数 | 备注 |
|---|---|---|
| RT-1-X | 35M | 平均掉队 29 个点 |
| RT-2-X | 55B | 闭源,仅 WidowX / RT-1 robot 上对比 |
| Octo-Base | 93M | 与 RT-2-X 持平 |
WidowX 上用目标图像 condition 比语言 condition 还高 25%(目标图明确告诉策略要达到什么状态)。
4.2 Finetune 到新观测/动作空间(核心卖点)¶
 Figure 4:六个 finetune setup 覆盖 dual-arm、力矩输入、关节位置控制、不同实验室——单一 finetune 配方全部跑通。
Figure 4:六个 finetune setup 覆盖 dual-arm、力矩输入、关节位置控制、不同实验室——单一 finetune 配方全部跑通。
| Setup | ResNet+Transformer (scratch) | VC-1 (pretrained vision) | Octo (finetuned) |
|---|---|---|---|
| Berkeley Insertion* | 10% | 5% | 70% |
| Stanford Coffee | 45% | 0% | 75% |
| CMU Baking | 25% | 30% | 50% |
| Berkeley Pick-Up† | 0% | 0% | 60% |
| Berkeley Coke | 20% | 10% | 100% |
| Berkeley Bimanual† | 20% | 50% | 80% |
| 平均 | 20% | 15% | 72% |
* = 新观测(力矩输入);† = 新动作空间(关节位置控制)。Octo 平均比次优 baseline 高 52%。所有 finetune 用同一套超参——这是「default config that works」的关键卖点。
4.3 关键消融(WidowX 设置,40 trials)¶
| 维度 | 配置 | 聚合成功率 |
|---|---|---|
| Data | OXE 25-dataset (default) | 83% |
| RT-X 11-dataset mix | 60% | |
| Single-robot (Bridge Data) | 43% | |
| Policy head | Diffusion (default) | 83% |
| Continuous MSE | 35% | |
| Discretized (RT-1/2 风格) | 18% | |
| Arch | ViT (default) | 83% |
| ResNet-50 + Transformer | 70% |
三个维度的结论非常清晰:更多数据 > 更少数据、diffusion > MSE > discrete、ViT-first > ResNet-first。Diffusion vs Discrete 的 65pp gap 后面也是 OpenVLA-OFT 这篇要重新打的官司。
4.4 模型 Scaling¶
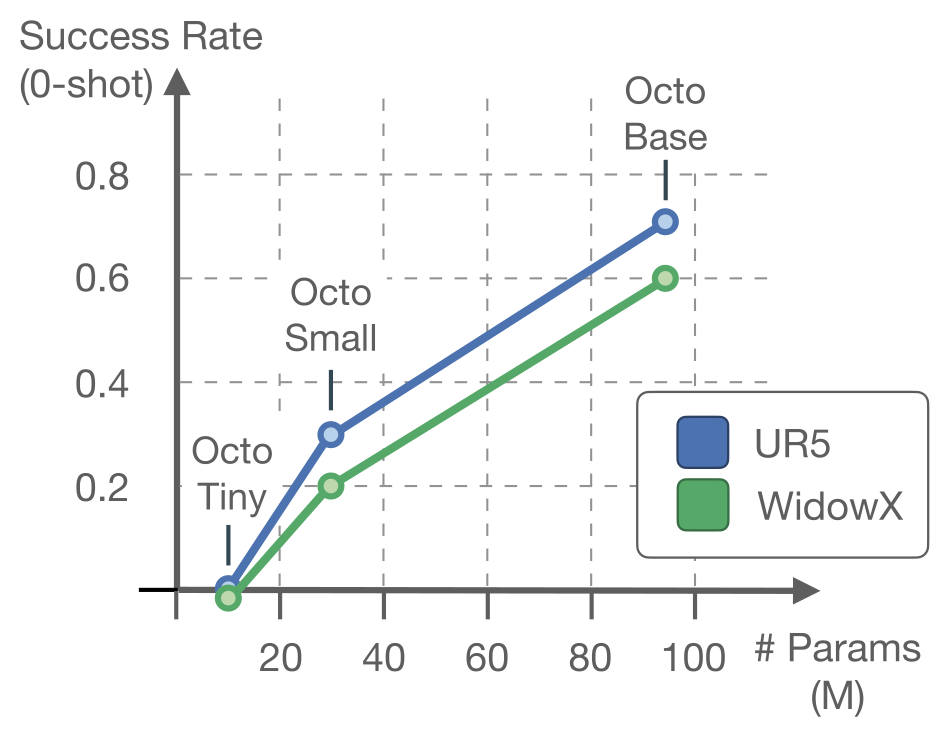 Figure 5:Tiny → Small → Base,UR5 和 WidowX 上 zero-shot 单调上升。Base 显著比 Small 更稳(不轻易过早 grasp),说明视觉感知能力随规模提升。
Figure 5:Tiny → Small → Base,UR5 和 WidowX 上 zero-shot 单调上升。Base 显著比 Small 更稳(不轻易过早 grasp),说明视觉感知能力随规模提升。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- Modular tokenizer + readout token 设计是真正解决「下游加新模态/新动作空间」这个工程痛点的方案。下游用户只动 tokenizer/head,不动 transformer 主干,这是 RT-X 系列做不到的。readout token 不被 attend 的「被动只读」设计很巧,把任务相关的聚合从主干表征里隔出来。
- Block-wise masking 让多源异构数据可以混训:某数据集没 wrist camera?mask 掉。没 language?切到 goal-image 模式。这让 25-dataset 混合不需要任何对齐预处理。
- Diffusion head 的选择有 65pp 量级的消融证据(83% vs 18% vs 35%)——不是 marketing,是实证的最优选择。Diffusion 的多模态性 + 连续精度同时拿到。
- Hindsight goal relabeling + 双模式 condition(语言 OR 目标图)让大量没标语言的数据集也能利用。后续 Octo 团队多人转去做 π₀ / OpenVLA,这套数据使用方式被普遍继承。
- 真正全开源——code、checkpoints、data loader、JAX 实现都放出来,OXE 加载脚本独立可用。这是后续整个开源 VLA 生态(OpenVLA、π₀ 开源版、LeRobot)的实际基础。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 规模偏小(93M):Octo-Base 只有 93M 参数,在 OpenVLA (7B) / RT-2-X (55B) 跟前是「小机器」。OpenVLA 后来证明大 LLM backbone 在 generalization 任务(尤其语义泛化)上明显更强。Octo 的 ViT-from-scratch 路线没充分利用 Internet 预训练。
- diffusion head 的多步去噪:虽然 transformer 只 forward 一次,但 head 内部要去噪 K 步——这个延迟没在主论文公平对比。后续 OpenVLA-OFT 显示 L1 regression 几乎打平 diffusion 但快 26×,把这个 trade-off 翻案。
- 「跨本体」证据偏弱:所谓 zero-shot 跨本体其实都是「OXE 训练数据里见过的机器人在 IN-distribution 场景」上跑——真正的「新本体 zero-shot」没测(Octo 自己也承认)。table 1 的精细 generalization 分析显示新场景就开始降,新行为(flip/precise insertion)就明显垮。
- 离散动作 18% 这个数字疑似低估:RT-1/2 的离散动作是在 50B 量级 LLM 上验证过有效的,Octo 用 93M 主干 + 离散动作只拿 18% 更可能反映「小模型 + 离散表征」的局限,而非 discrete vs diffusion 的本质差距。OpenVLA 在 7B 上拿离散 token 拿到 76.5% LIBERO 平均,说明这事跟 backbone 容量强相关。
- single-robot baseline (Bridge only) 43% 反映训练数据规模而非配方差异——表里没控制 epochs 总训练步数,混合数据集自然见过更多次梯度更新。
- VC-1 baseline 不太公平:VC-1 只是 vision encoder,配 MLP head 直接 MSE 训,本质上是 single-task scratch policy,跟「pretrained policy」不在同一档比较,15% 这个数字主要说明 visual encoder 单独不够,policy-level pretraining 才有用。
- goal image vs language 提升 25pp 这个数字虽然 expected,但暗示语言条件下 Octo 的 language grounding 其实有限——后续 OpenVLA 的语义泛化优势正好打中这个软肋。
5.3 值得继续探讨的方向¶
- scale up 主干:Octo 验证了 ViT-first 架构 + diffusion head 的配方,但 93M 太小。把这套配方搬到 1B+ 规模会怎样?(这条路被 π₀ 走了,且确实超过了 OpenVLA)
- 更精细的数据 curation:Octo 自己说 "future work should perform a more thorough analysis of data mixture quality"——RT-2 用人工 expert weighting、Octo 用启发式 doubling、π₀ 用 cross-embodiment weighting,至今没有公开的系统对比。
- 离散 vs 连续 action 在大主干上的真正对照:OFT 后续证明了在 7B 上 L1 regression(连续)能打平 diffusion,但 diffusion vs discrete 在大规模上的差异仍未完全清楚。
- 更长 horizon / 更稀疏 reward 任务:Octo 主要测短期 manipulation,长 horizon(Stanford Coffee 是少数)效果有所下降,加 memory 或者 hierarchical 结构是自然延伸(见 π₀.₆-MEM 这条线)。
- finetune 更新策略:当前是「整模型 finetune」,没探索 LoRA、adapter、freeze-half 这些 efficient 方案。OpenVLA 后续给了 LoRA 答案。
- 跨本体的真正 zero-shot 评估:换个 OXE 没见过的本体(比如奇怪的多指手),Octo 还剩多少能力?没测,但很关键。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页: octo-models.github.io
- 关键相关论文:
- Open X-Embodiment (RT-X) (open_x_embodiment_rt_x_2023) — Octo 的训练数据基础
- RT-1 / RT-2 (brohan2022rt / zitkovich2023rt) — Octo 的主要对照点
- Diffusion Policy (chi2023diffusionpolicy) — diffusion action head 来源
- ACT (zhao2023learning) — action chunking 来源
- OpenVLA (kim2024openvla) — Octo 的直接后继,沿用了 Octo 的数据混合(本库有 OpenVLA 笔记)
- OpenVLA-OFT (kim2025oft) — 反过来重新审视 diffusion vs L1 的选择(本库有 OFT 笔记)