UCPE: Unified Camera Positional Encoding for Controlled Video Generation¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:Unified Camera Positional Encoding for Controlled Video Generation
- 作者:Cheng Zhang¹²、Boying Li¹(通讯)、Meng Wei¹、Yan-Pei Cao³、Camilo Cruz Gambardella¹²、Dinh Phung¹、Jianfei Cai¹ — ¹Monash University, ²Building 4.0 CRC, ³VAST
- arXiv 编号:2512.07237(2025-12 提交,CVPR 2026 模板,源码含 rebuttal 图,2026-03 更新版)
- 代码:
https://github.com/chengzhag/UCPE(宣称将开源) - 关键词:camera-controllable video generation、relative ray encoding、Plücker encoding、PRoPE/GTA、lens distortion、Unified Camera Model (UCM)、Lat-Up map、attention adapter、Wan2.1
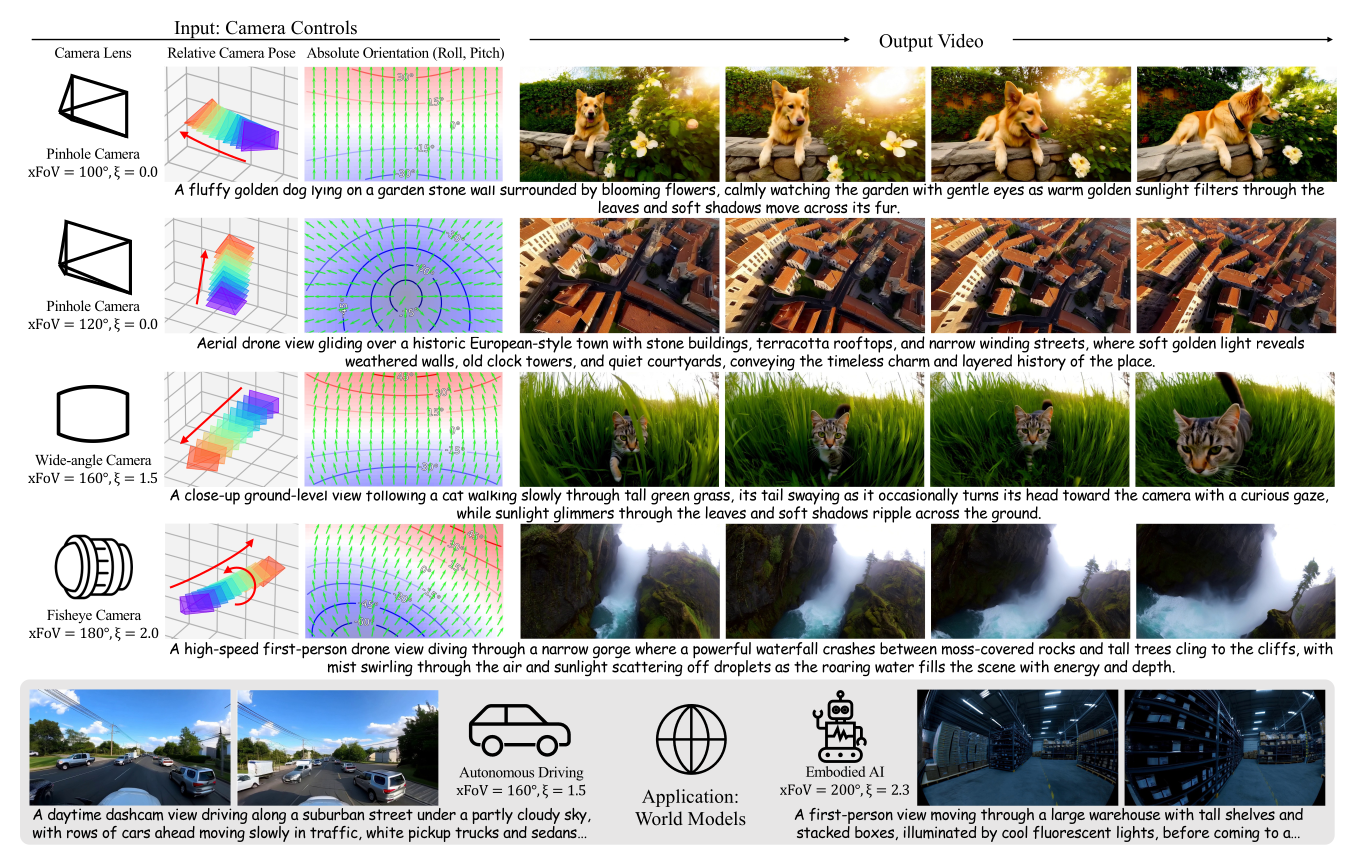 Figure 1:UCPE 同时控制三类相机自由度——镜头(FoV + 畸变 ξ,从 pinhole 到 fisheye)、初始绝对朝向(pitch/roll,经 Lat-Up map 指定)、相对 6-DoF 轨迹——这是之前 camera-conditioned T2V 方法没有任何一个能同时做到的组合。
Figure 1:UCPE 同时控制三类相机自由度——镜头(FoV + 畸变 ξ,从 pinhole 到 fisheye)、初始绝对朝向(pitch/roll,经 Lat-Up map 指定)、相对 6-DoF 轨迹——这是之前 camera-conditioned T2V 方法没有任何一个能同时做到的组合。
2. 文章介绍¶
2.1 解决的领域和问题¶
相机可控的 text-to-video 生成(更广义地说,Transformer 里的相机几何编码)。现有 camera-conditioned 方法几乎全部建立在理想 pinhole 假设上:要么直接把外参数值喂进网络,要么用 Plücker ray map,要么用 GTA/PRoPE 这类 attention 级 relative encoding——但真实应用(自动驾驶、机器人、全景内容)大量使用 fisheye、catadioptric、equirectangular 等强畸变、非线性投影的镜头,这些方法都覆盖不了。
此外还有一个被长期忽略的具体问题:现有 T2V 相机控制把 pose 全部定义为相对第一帧,导致首帧的绝对 pitch/roll 两个自由度悬空——你无法指定"低角度仰拍"还是"俯视",生成结果的初始朝向不可复现。
2.2 Motivation¶
核心观察:所有相机模型,无论投影类型,都可以统一成一个 ray-mapping 函数 \(\Phi_\psi:(u,v)\mapsto(\mathbf{o},\mathbf{d})\)——把像素映射到 3D 射线。既然如此,与其在 camera 级别编码(一个 view 共享一个变换矩阵,等于假设整张图是一个线性投影的刚体),不如把 positional encoding 下沉到 ray 级别:每个 token 自带一个局部射线坐标系,attention 直接在 ray space 里推理。畸变、宽 FoV 这些"intra-camera 的投影空间变化"就自然地被表示出来了。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 绝对编码 / 原始参数 | MotionCtrl、ReCamMaster | 直接喂数值化外参(+内参),依赖特定 world frame,跨场景泛化差,畸变只能当作额外标量贴上去 |
| 绝对编码 / Plücker ray map | CameraCtrl、AC3D | 物理可解释,但仍是 world-frame 敏感的绝对量;只在 pinhole 下推导使用 |
| 相对编码 / camera 级 | CaPE (EscherNet)、GTA、PRoPE | attention 级注入相对 SE(3)(PRoPE 进一步乘入 intrinsics 投影矩阵),world-frame 无关,但一个 view 一个矩阵,无法表达像素位置相关的非线性畸变;PRoPE 明确仅限 pinhole;且未验证与预训练 video DiT 的兼容性 |
| 3D 表示引导 | ViewCrafter、TrajectoryCrafter 等 | 依赖深度/点云/3DGS 等重建,重建质量差或大运动时崩;运动多样性受限 |
| 首帧相对 pose 范式(所有 T2V 方法共有) | CameraCtrl、AC3D 等 | 首帧 pitch/roll 不可指定、不可复现 |
2.4 论文解决方案(一句话)¶
把 relative camera encoding 细化为 relative ray encoding(每个 token 一个 ray-to-world 变换,GTA 式作用在 Q/K/V 上,统一编码 pose+内参+畸变),再配一个 Lat-Up map 绝对朝向编码(gravity-aligned 的 latitude 角 + up 向量,补上首帧 pitch/roll 控制),通过零初始化的并行 attention adapter(<1% 参数,35.5M)注入冻结的 Wan2.1 DiT。
2.5 与前序工作的关系¶
- 直接推广 PRoPE(Li et al., 2025, "Cameras as Relative Positional Encoding"):PRoPE 把 GTA 的相对 SE(3) 换成 camera projective matrix(含 intrinsics),UCPE 再往下走一步——从 per-camera 矩阵到 per-token ray frame;hybrid(一半维度 ray 变换 + 一半 RoPE)的设计也沿用 PRoPE 的最优配置。
- attention 作用形式沿用 GTA(Miyato et al., 2023):Q/K/V 三者都做几何变换(式 (8))。
- Lat-Up map 来自相机标定谱系:PerspectiveFields、GeoCalib、PrecISEcam 用它做单图标定,本文反过来把它当生成条件。
- 底座:Wan2.1-T2V-1.3B(含文本编码器与 3D VAE 整个 stack 7.3B 参数);I2V 可行性实验用 Wan2.1-I2V-14B。
- 数据源:Wallingford et al. (2024) 的 24.1k 个 4K YouTube 360° 视频语料(360-1M 谱系)。
- 评测工具链:ViPE(pose)、GeoCalib(FoV/畸变/pitch/roll)、Q-Align(画质)。
3. 方法介绍¶
3.1 形式化:相机 = ray-mapping¶
任意相机定义为 \(\Phi_\psi:(u,v)\mapsto(\mathbf{o}^{cam},\mathbf{d}^{cam})\),central camera 所有 ray 共享原点,non-central(catadioptric/全景)则每像素一个原点。配合 pose \(\mathbf{T}^{wc}\) 得到 world-space ray \((\mathbf{o}_t,\mathbf{d}_t)\)。论文用 Unified Camera Model (UCM) 作代表性实现(参数:xFoV + 畸变 ξ),覆盖 pinhole / 广角 / fisheye。
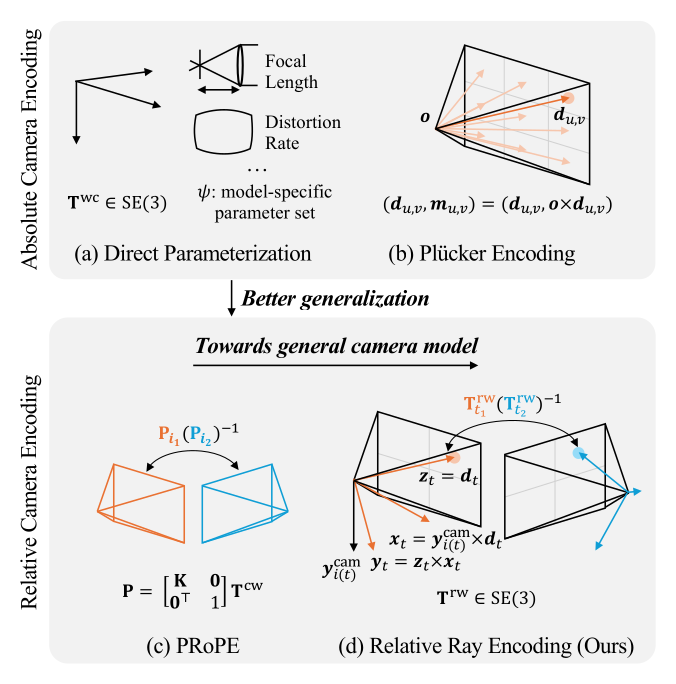 Figure 2:四种编码的对比——(a) 原始参数、(b) Plücker map(绝对、逐像素)、(c) PRoPE(相对、逐相机)、(d) 本文 Relative Ray Encoding(相对、逐射线)。关键差别:(d) 中每个 token 有自己的局部 ray 坐标系,畸变带来的逐像素投影差异不再被"整图一个矩阵"抹平。
Figure 2:四种编码的对比——(a) 原始参数、(b) Plücker map(绝对、逐像素)、(c) PRoPE(相对、逐相机)、(d) 本文 Relative Ray Encoding(相对、逐射线)。关键差别:(d) 中每个 token 有自己的局部 ray 坐标系,畸变带来的逐像素投影差异不再被"整图一个矩阵"抹平。
3.2 Relative Ray Encoding(RRE)¶
对每个 token \(t\),以其 ray 方向为局部 z 轴、用相机"向下"方向 \(\mathbf{y}^{cam}\) 定出正交基:
加上平移 \(\mathbf{o}_t\) 构成 ray-to-world 变换 \(\mathbf{T}^{wr}_t\in SE(3)\)。attention 时按 GTA 形式作用其逆 \(\mathbf{T}^{rw}_t\):
于是 \(Q_{t_1}^\top K_{t_2}\) 变成经 \(\mathbf{T}^{rw}_{t_1}(\mathbf{T}^{rw}_{t_2})^{-1}\)(ray-to-ray 相对变换)调制的交互——attention 在射线空间推理,畸变就是"相邻 token 的 ray frame 旋转得快"这件事本身。
3.3 Absolute Orientation Encoding(AOE / Lat-Up map)¶
RRE 是纯相对量,首帧朝向仍然悬空。利用"真实视频基本都是重力对齐拍摄"这一先验,给每个 ray 计算:
- Latitude map:ray 相对水平面的仰角 \(\mathrm{Lat}_t=\arctan2(-d_{t,y},\sqrt{d_{t,x}^2+d_{t,z}^2})\);
- Up map:把 ray 朝 world-up 微旋 δ 后重投影回像素平面,归一化位移向量即"图像里的上方向"。
两者拼接后线性投影、作为 bias 加到输入 token 上(可选通道)。这同时编码了 pitch/roll 和部分镜头畸变线索(up 向量场在 fisheye 下弯曲)——消融显示它顺带改善 lens control。
3.4 Spatial Attention Adapter¶
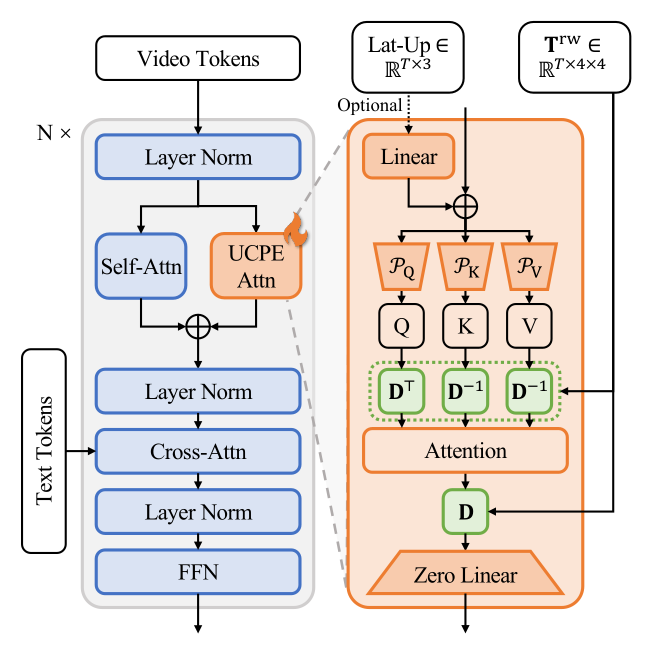 Figure 3:注入方式——每个 DiT block 保留原 self-attention,旁挂一条并行的 UCPEAttn 分支:token 先线性降维到 1/C(默认 1/8,192 维 × 1 头),做带 blkdiag(D^Ray, D^RoPE) 混合编码的 attention(各占一半维度),再经零初始化线性层投影回去。初始化时模型行为与预训练完全一致。
Figure 3:注入方式——每个 DiT block 保留原 self-attention,旁挂一条并行的 UCPEAttn 分支:token 先线性降维到 1/C(默认 1/8,192 维 × 1 头),做带 blkdiag(D^Ray, D^RoPE) 混合编码的 attention(各占一半维度),再经零初始化线性层投影回去。初始化时模型行为与预训练完全一致。
直接替换 Wan 的 3D RoPE 会破坏预训练先验,所以选择 LoRA 式并行分支 + 零初始化输出投影。消融对比了 Pre-Attn / Post-Attn 串行插入,并行设计在相机控制与画质上都更好。
3.5 数据集构建(合成 ~48k clips)¶
真实多镜头配对数据采集成本过高,论文用 360° 全景视频当"可任意投影的探索空间",三阶段合成:
- 全景视频清洗:24.1k 个 4K YouTube 360° 视频 → 转场检测 + 全景 SLAM "tracking-lost" 信号切分 → 400k 个 10s clips → SLAM localization 二次跑 pose(300k 有效)→ rotation score 剔除非重力对齐 → Q-Align 画质分 + 水印检测 + vLLM(Qwen2 系)过滤非 ERP/低质/贴片 → 光流推近平面深度做轨迹尺度归一化(中位近平面深度 =1)。
- 真实感旋转模拟:合成匀速旋转太假,核心洞察是"平移模式相似的视频,旋转动态也相似"——从 perspective 视频库里按平移轨迹匹配,把真实 pan/tilt/roll 转移到全景轨迹上。
- 多相机合成:在 UCM 下随机采样 xFoV 与畸变 ξ,从全景投影出 pinhole/广角/fisheye 视频。
最终 ~48k clips,FoV 覆盖 60°–110°+(RealEstate10K 集中在 60°、几乎无畸变);测试集对齐 CameraBench 官方 test split,272 clips。
3.6 Implementation Details¶
- 底座:Wan2.1-T2V-1.3B(全 stack 7.3B),全部冻结;只训 adapter,35.5M 可训练参数(0.5%)。
- 训练:AdamW,lr 1e-4,10k steps,batch 8,8×A800,约 1 天。
- 推理:81 帧 @ 480×832、16 fps;184 s / 视频(单 A800),与 ReCamMaster (179s)、Wan CameraCtrl (177s) 相当。
- 基线适配:ReCamMaster(354M 可训练)与 Wan CameraCtrl(1.5B 全参,lr 1e-5)由作者扩展出 FoV+ξ 通道、在同一数据同一底座上微调;CameraCtrl/AC3D 用官方权重,只在其训练域 RealEstate10K 上评。
4. 结果对比¶
4.1 自建合成 benchmark(272 test clips)¶
w/ Absolute Orientation Control 设置(GT 由对真实视频跑 GeoCalib/ViPE 得到):
| 方法 | FoV误差(°)↓ | k₁↓ | k₂↓ | Pitch(°)↓ | Roll(°)↓ | RotErr(°)↓ | TransErr↓ | CamMC↓ | FVD↓ | FID↓ | CLIP↑ | 可训参数 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ReCamMaster | 10.04 | 0.183 | 0.136 | 6.62 | 5.29 | 9.23 | 28.95 | 33.88 | 605.83 | 67.07 | 24.84 | 354M |
| Wan CameraCtrl | 9.86 | 0.230 | 0.162 | 6.25 | 6.01 | 17.92 | 39.16 | 50.32 | 554.43 | 65.73 | 25.01 | 1.5B |
| UCPE | 8.22 | 0.129 | 0.102 | 4.35 | 3.74 | 4.12 | 15.21 | 17.59 | 495.14 | 63.37 | 25.12 | 35.6M |
w/o AOC 设置下结论相同(RotErr 4.29 vs 10.89/17.04)。相对 pose 控制是代差级领先(RotErr 不到对手一半),lens/orientation 是 20–35% 量级改善,参数比 ReCamMaster 少 90%。
4.2 RealEstate10K(zero-shot,100 clips,100° pinhole)¶
| 方法 | RotErr(°)↓ | TransErr↓ | CamMC↓ | Q-Align IQ↑ | Q-Align IA↑ | Q-Align VQ↑ |
|---|---|---|---|---|---|---|
| ReCamMaster | 1.10 | 5.64 | 6.15 | 0.9492 | 0.5185 | 0.9720 |
| Wan CameraCtrl | 2.22 | 7.42 | 8.67 | 0.9822 | 0.5691 | 0.9885 |
| CameraCtrl(官方,在 RE10K 上训过) | 1.17 | 3.96 | 4.59 | 0.6877 | 0.3306 | 0.7338 |
| AC3D(官方,在 RE10K 上训过) | 0.62 | 2.11 | 2.43 | 0.7699 | 0.3651 | 0.8211 |
| UCPE(未在 RE10K 训练) | 0.56 | 1.25 | 1.58 | 0.9480 | 0.4686 | 0.9694 |
未见过 RE10K 的 UCPE 在 pose 控制上超过在 RE10K 上训练的 AC3D;画质(Q-Align)排第三,低于同底座的两个 baseline。
4.3 关键消融(合成 benchmark,w/ AOC)¶
| 配置 | FoV↓ | RotErr↓ | TransErr↓ | FVD↓ | FID↓ | 参数 |
|---|---|---|---|---|---|---|
| 1/2-dim (128×6) | 8.39 | 3.69 | 14.03 | 534.44 | 64.88 | 141M |
| 1/4-dim (128×3) | 8.47 | 3.43 | 14.26 | 512.85 | 62.86 | 71.0M |
| 1/8-dim (192×1,默认) | 8.22 | 4.12 | 15.21 | 495.14 | 63.37 | 35.6M |
| 1/12-dim (128×1) | 8.96 | 5.13 | 14.54 | 487.54 | 62.98 | 23.8M |
| Pre-Attn 串行 | 8.47 | 4.03 | 15.77 | 502.73 | 63.62 | 35.6M |
| Post-Attn 串行 | 8.91 | 4.68 | 17.47 | 515.32 | 64.65 | 35.6M |
| 换成 PRoPE(保留 Lat-Up) | 8.84 | 5.35 | 17.52 | 516.59 | 65.00 | 35.6M |
| 换成 GTA(保留 Lat-Up) | 8.80 | 5.27 | 17.07 | 497.19 | 64.91 | 35.6M |
- RRE vs PRoPE/GTA:同参数同 Lat-Up 下,ray 级编码在 lens + pose 控制全面占优(RotErr 4.12 vs 5.35/5.27),absolute orientation 三者接近(说明朝向控制主要由 Lat-Up 完成);PRoPE 甚至略差于 GTA——内参乘进投影矩阵的方式在畸变域反而帮倒忙。
- 并行 > 串行:Pre/Post-Attn 两个串行变体在控制与画质上都明显退化。
4.4 鲁棒性 / 泛化 / 失败(补充材料)¶
- 文本-相机冲突:prompt 写"flat telephoto portrait"但给 180° fisheye 参数,模型遵循相机几何而非文本。
- 未见相机模型:推理时直接换 Brown-Conrady ray-mapping(OpenCV 实标模型),无需微调即生成正确桶形畸变——ray 表示选对了的直接红利。
- 失败案例:换 ERP(360° 全景)ray-mapping 直接崩——训练分布外的极端投影。
- I2V 可行性:微调 Wan2.1-I2V-14B,RRE 单独驱动后续帧(首帧像素已锚定 lens 与朝向,不需要 AOE)。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 把"统一相机"问题归约到 ray-mapping 抽象:encoding 与具体相机模型解耦(训练用 UCM,推理可换 Brown-Conrady),这是表示层面的真贡献,Brown-Conrady zero-shot 实验是全文最有说服力的一个证据。
- ray 级 relative encoding 是 PRoPE 的自然但非平凡的推广:camera 级矩阵抹掉了畸变的逐像素差异,下沉到 token 级后非线性投影"免费"可表示;消融(同参数、同 Lat-Up)干净地把增益归到这一步。
- Lat-Up map 填了 T2V 相机控制的一个真空:首帧 pitch/roll 在"相对首帧"范式下原则上不可控,用重力对齐先验 + 标定领域的现成表示解决,且给 ReCamMaster/Wan CameraCtrl 也补了 w/ AOC 变体作对照(没有只让自己吃这个增益)。
- <1% 参数的并行零初始化 adapter 工程上很经济:8×A800 一天训完,画质指标(FVD/FID/CLIP)还略好于 1.5B 全参微调的 Wan CameraCtrl——几何条件该用结构化编码而不是靠堆可训练参数。
- 数据合成 pipeline 完成度高:SLAM 二次定位、rotation transfer("平移相似 → 旋转相似"的匹配式增广)、近平面深度尺度归一化,每一步都在解决全景重投影的真实痛点;顺带产出一个 lens 多样性远超 RealEstate10K 的 benchmark。
- 失败案例诚实:ERP 崩溃、依赖 pose 标注、不建模 zoom/focus/DoF 都写在了补充材料里。
5.2 做得不够好 / 值得质疑的地方¶
- 评测器与被测量高度耦合:absolute orientation 和 lens 指标的"GT"与预测都来自 GeoCalib 对视频帧的估计(GT = GeoCalib(真实视频),pred = GeoCalib(生成视频)),pose 指标依赖 ViPE。指标实际测的是"两次估计器输出的一致性",GeoCalib/ViPE 在生成内容、强畸变下自身的误差与偏好没有标定,也没有任何人工评测兜底。
- pose 指标与 lens 控制耦合:评测先用 GT 畸变参数把生成帧矫正成 pinhole 再跑 ViPE——若模型生成的畸变本身就错了,矫正就是错的,pose 误差被连带放大。这对 lens 控制最好的 UCPE 系统性有利,RotErr 的代差领先里有多少是这个耦合贡献的,无法从论文里分离。
- 基线是作者改造版且训练预算可疑:ReCamMaster/Wan CameraCtrl 的 lens 通道(concat FoV+ξ)是作者自己加的;Wan CameraCtrl 1.5B 全参、lr 1e-5、与 35M adapter 同样只训 10k steps(batch 8 ≈ 1.7 epoch)——全参微调在这个预算下大概率欠拟合,"adapter 更优"部分可能是训练预算设定的产物。
- 272 clips 上的 FVD/FID 统计意义薄弱:FVD 在小样本下偏差和方差都很大(文献常用 ≥2048 clips),495 vs 554 的差距未必稳定;FVD 绝对值 ~500 也说明合成域画质离 RE10K 水平(文献 FVD<200)很远。
- "lens control" 只是几何 warp 控制:训练数据是 360° 全景的重投影,只有几何畸变,没有真实镜头的 photometric 特性(暗角、眩光、色差、景深、近焦呼吸效应);真实 fisheye footage 的这些线索全部 OOD。说"统一物理相机镜头与 attention"有点超卖。
- ray frame 存在奇异性:\(\mathbf{x}_t=\mathbf{y}^{cam}\times\mathbf{d}_t\) 在 ray 与相机 down 方向平行时退化(xFoV→180° 的 fisheye 边缘、或大 pitch 朝天/朝地的 ray),此处局部坐标系不连续/数值不稳,论文完全没讨论——而这恰恰发生在它最引以为傲的宽 FoV 区域。
- 1/8-dim "最佳 trade-off" 是按参数预算反推的说法:1/4-dim 在 RotErr(3.43 vs 4.12)、TransErr、FID 上都更好,1/8 赢在 FoV/FVD/CLIP 和参数减半。从控制精度优先的角度,默认配置并非最优,正文表述有挑指标之嫌。
- AOE 的贡献与 RRE 部分重叠且更"廉价":消融里 PRoPE/GTA + Lat-Up 的 absolute orientation 误差与 UCPE 几乎一样(4.18/4.21 vs 4.35),说明朝向控制基本由 Lat-Up bias(本质是 dense per-pixel conditioning,技术上与 Plücker map 注入同类)完成,与"attention 级 ray 编码"这一核心叙事无关;两个组件是拼盘关系而非协同。
- zero-shot 泛化叙事有选择性:RE10K 上画质(Q-Align aesthetic 0.4686)明显低于同底座 baselines(0.5691/0.5185),论文用"comparable with fewer parameters"轻轻带过;且 RE10K 只测了 100 clips、固定 100° FoV 单一设置,"strong generalization"的证据面较窄。
- "通用相机表示"的主张未在生成之外验证:摘要与结论都展望 multi-view / 3D 任务,但论文没有任何 NVS/重建实验——PRoPE 在 NVS 上是有数字的,UCPE 若想取而代之,至少该在 LVSM 类任务上对一次。
5.3 值得继续探讨的方向¶
- 在 NVS / feed-forward 重建 backbone(LVSM、RayZer、π³ 类)上替换 PRoPE 实测——验证"通用相机编码"主张的最直接路径,也是这个表示真正的潜在影响面。
- 奇异性修复:用 parallel transport / quaternion frame 替代 cross-product 构造局部基,或在 ±90° 仰角附近做 frame blending;可以直接量化 fisheye 边缘 token 的 attention 稳定性。
- photometric lens 维度:把暗角/眩光/景深作为与几何解耦的条件通道,数据侧用光学仿真增广,看几何 ray 编码与 photometric 条件是否干净可组合。
- 评测去耦:用合成 3D 场景渲染(已知完美 GT)替代 GeoCalib/ViPE 估计链,分离"畸变错→pose 估计错"的耦合;补人工评测。
- non-central 相机实测:formulation 里说支持 per-pixel ray origin(catadioptric),但没有任何实验;这是该表示相对所有先前工作的独有能力,值得做实。
- ERP/全景生成:在全景数据上微调后,UCPE 能否统一 perspective 与 panoramic 生成(与 PanoWan 类工作对接)。
- 去 pose 标注:用自标定(GeoCalib 伪标签)或自监督几何一致性损失放松"训练需要 SLAM pose"的前提,扩展可用数据规模。
- V2V re-rendering:ReCamMaster 任务上换 UCPE 编码,理论上 lens 也能在 re-render 时改——"后期换镜头"是内容创作侧最有商业价值的应用。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 关键相关论文:
- PRoPE: "Cameras as Relative Positional Encoding" (Li et al., 2025) — 被推广的直接前作
- GTA: "Geometric Transform Attention" (Miyato et al., ICLR 2024)
- CaPE: EscherNet (Kong et al., 2024)
- CameraCtrl (He et al., 2024) / AC3D (Bahmani et al., 2025) — Plücker 编码路线
- ReCamMaster (Bai et al., 2025) — 原始参数注入路线
- UCM: Mei & Rives 单视点统一相机模型 (2007)
- GeoCalib (Veicht et al., 2024)、ViPE (Huang et al., 2025) — 评测工具链
- Wallingford et al. (2024) — 360° 视频语料来源