ABot-PhysWorld: Interactive World Foundation Model for Robotic Manipulation with Physics Alignment¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: ABot-PhysWorld: Interactive World Foundation Model for Robotic Manipulation with Physics Alignment
- 作者: Yuzhi Chen, Ronghan Chen, Dongjie Huo, Yandan Yang, Dekang Qi, Haoyun Liu, Tong Lin, Shuang Zeng, Junjin Xiao, Xinyuan Chang, Feng Xiong, Xing Wei, Zhiheng Ma, Mu Xu (AMAP CV Lab, Alibaba)
- arXiv 编号: 2603.23376 (submitted 2026-03,technical report / workshop format)
- 关键词: world model, embodied video generation, Diffusion Transformer, Diffusion-DPO, physics alignment, cross-embodiment, action-conditioned generation, zero-shot benchmark
- 代码 / 项目页: https://github.com/amap-cvlab/ABot-PhysWorld
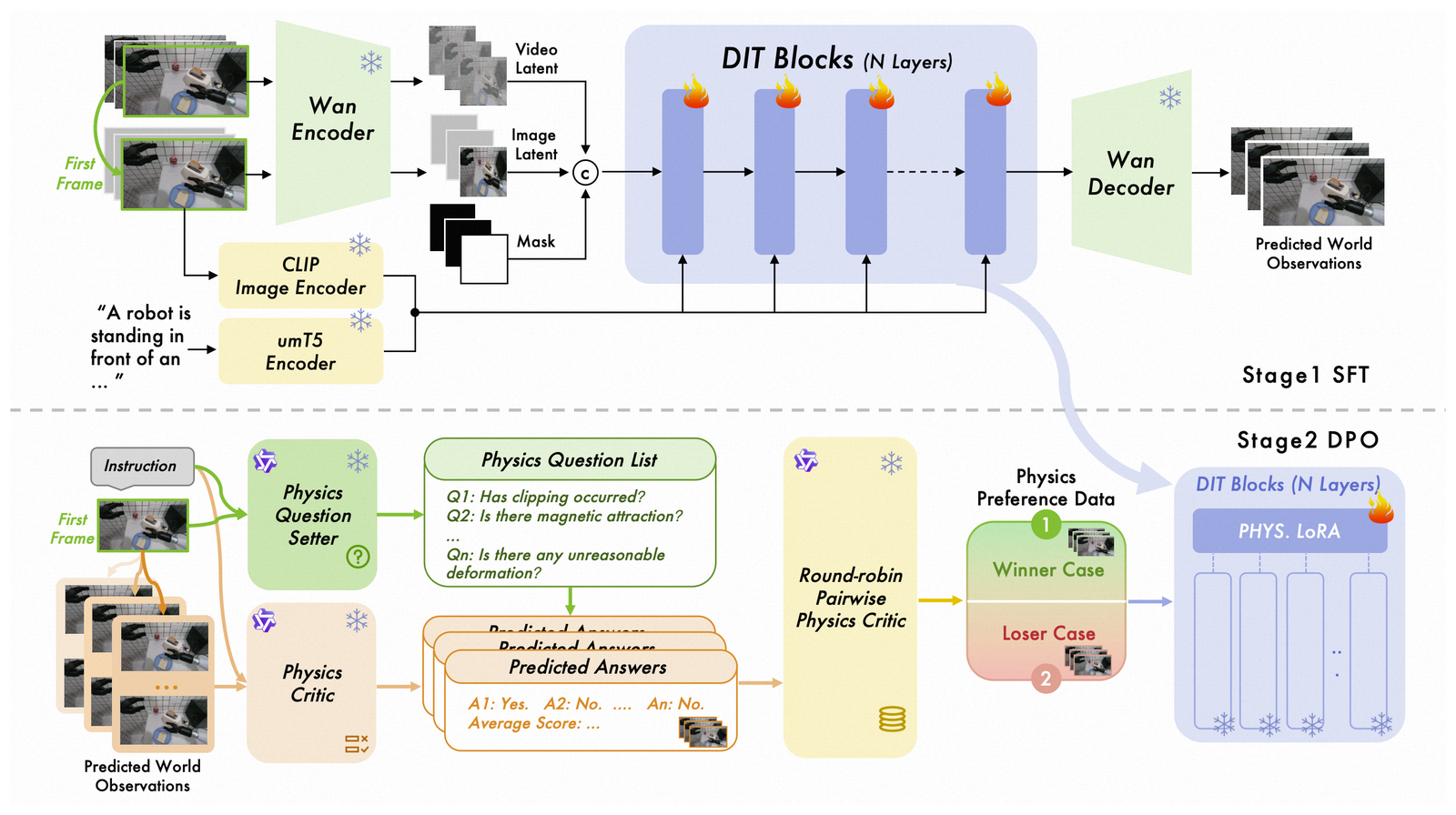 Figure 1:两阶段训练流水线。Stage 1 在 Wan2.1-I2V-14B 上做 SFT 学到未来帧预测;Stage 2 固定 backbone,用 LoRA + 解耦 VLM 判别器跑 Diffusion-DPO,把"物理违法"样本的 denoise loss 推高、把"物理合规"样本的 loss 拉低。整张图的关键信息是——physics alignment 是后训练阶段,而不是从头改 loss。
Figure 1:两阶段训练流水线。Stage 1 在 Wan2.1-I2V-14B 上做 SFT 学到未来帧预测;Stage 2 固定 backbone,用 LoRA + 解耦 VLM 判别器跑 Diffusion-DPO,把"物理违法"样本的 denoise loss 推高、把"物理合规"样本的 loss 拉低。整张图的关键信息是——physics alignment 是后训练阶段,而不是从头改 loss。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 embodied world model(以视频生成方式建模未来观测) 这一子方向。论文聚焦于一个具体痛点:当前最强的通用视频生成模型(Veo 3.1、Sora v2 Pro)在操控类视频上仍然会出现 物体穿模 (penetration)、反重力悬空 (anti-gravity motion)、非接触式抓取 (contactless grasping) 等明显违反物理常识的伪影。这些不是渲染瑕疵,而是物理推理能力的系统性缺失,直接导致 world model 无法作为 VLA 仿真器或 World Action Model (WAM) 使用。
2.2 Motivation¶
作者把问题归结为两个根因:
- 训练数据偏向通用视觉数据,缺乏带有 contact / friction / mass 等物理信号的具身交互数据;
- 训练目标是 likelihood-based(flow matching、MSE 等),所有预测误差被一视同仁,物理违法和单纯像素抖动得到同样的梯度。
因此他们的核心 angle 是:用 preference alignment(DPO)显式区分"物理合规"与"物理违法"的轨迹,而不是再去精修像素 loss;同时配上专门为具身领域设计的数据 curation 流水线提供高质量先验。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 通用视频生成 SOTA | Veo 3.1、Sora v2 Pro、Wan 2.5 | 视觉漂亮,但 contact-rich 场景频繁穿模、悬空;Domain Score 显著低于 Quality Score |
| Embodied world model | GigaWorld-0、WoW-wan 14B、Cosmos-Predict 2.5、UnifoLM-WMA-0 | 大都做 SFT,没有物理对齐的 post-training;评测多在 in-distribution,generalization 未充分检验 |
| Action-conditioned 生成 | EnerVerse-AC、Genie-Envisioner | 直接把 action map 拼到 noisy latent 上做 full fine-tune,灾难性遗忘 pre-trained 物理先验;或者用 AdaLN 注入 MLP-encoded action,跨 embodiment 难泛化 |
| Embodied 评测 benchmark | PAI-Bench / PBench | 测试样本与训练分布同源,几乎全部 in-distribution,无法测真实的 zero-shot |
2.4 论文解决方案(一句话)¶
在 14B Wan2.1-I2V DiT 上,用 physics-aware Diffusion-DPO(LoRA + 解耦 Qwen3-VL/Gemini3 判别器) 做后训练抑制物理违法,再用 VACE-style 并行 context block 注入 2D action map 实现跨 embodiment 控制,并配套发布首个 OOD 的具身视频 zero-shot benchmark EZSbench。
2.5 与前序工作的关系¶
- 骨干 直接复用 Wan2.1-I2V-14B(阿里 Wan 系列),不重新训练 DiT;
- DPO 框架 来自 Diffusion-DPO(Wallace 等),但首次系统性用于具身物理对齐;判别器借鉴 RDPO/PhyGDPO/PhysCorr 的思路,但把 proposer/scorer 解耦给两个不同厂商的 VLM(Qwen3-VL Thinking + Gemini 3 Pro)以缓解 self-evaluation 偏差;
- Action injection 直接照搬 VACE 的 parallel context block 设计,把视频编辑领域的"参考分支 + 零初始化卷积"机制迁移到 action conditioning;
- 数据来源 五个公开数据集的并集:AgiBot、RoboCoin、RoboMind、Galaxea、OXE,~3M clips;
- Caption 标注 用 Qwen3-VL 32B 做 perception、Qwen3 32B FP8 做 writing;
- EZSbench 初始观测 用 Nano Banana T2I 合成 + VLM 引导的真实图编辑。
3. 方法介绍¶
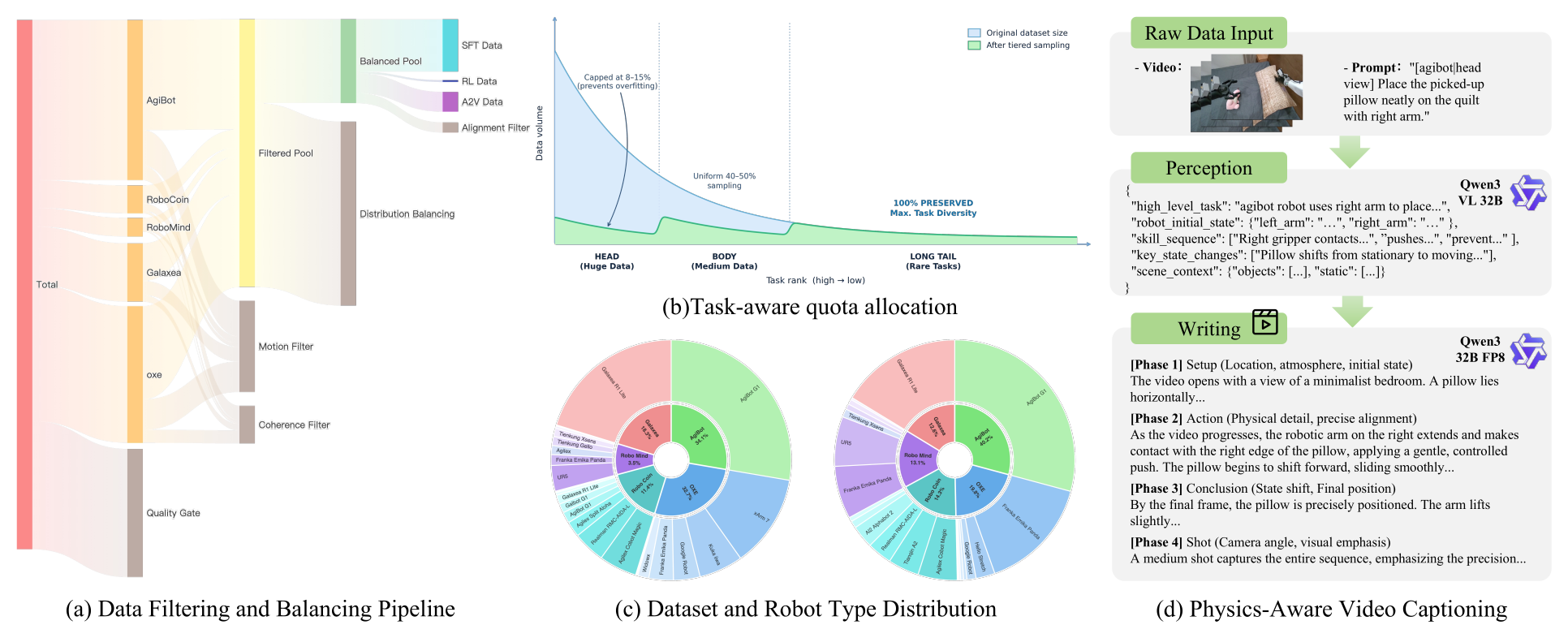 Figure 2:数据流水线。从 ~3M 原始片段经过 video-level + optical-flow + CLIP + vision-action 四道过滤进到 SFT/RL/A2V 三个训练集;下方的 ring 图是按 robot 类型重新平衡前后的对比——OXE 与 AgiBot 被压缩,长尾被保留。注意 (d) 部分的两段式 caption(Qwen3-VL 抽属性 → Qwen3 文字写作)。
Figure 2:数据流水线。从 ~3M 原始片段经过 video-level + optical-flow + CLIP + vision-action 四道过滤进到 SFT/RL/A2V 三个训练集;下方的 ring 图是按 robot 类型重新平衡前后的对比——OXE 与 AgiBot 被压缩,长尾被保留。注意 (d) 部分的两段式 caption(Qwen3-VL 抽属性 → Qwen3 文字写作)。
3.1 形式化¶
模型是一个 image-to-video DiT \(\epsilon_\theta(z_t, t, c)\),其中:
- \(z_t\) 是经 VAE 编码、加噪到时间步 \(t\) 的视频 latent;
- 条件 \(c\) 包括:首帧 VAE 编码 + 二值 mask(指示首帧位置)、T5-XXL 编码的文本指令、3D RoPE 位置编码;
- 训练目标在 SFT 阶段是 flow matching,DPO 阶段是物理偏好对齐的 sigmoid log-ratio loss;
- 推理时用 Classifier-Free Guidance 解码。
输入分辨率 \(480\times832\),每段视频 81 帧(uniform sampling)。
3.2 数据策划流水线(§3 of paper)¶
Stage 1: Embodied-specific filtering —— 四道过滤替代通用 curation(Cosmos-Curate、VideoX-Fun): 1. Quality gate:分辨率/移动相机过滤;80–500 帧的长度约束;超长视频按任务序号切分; 2. Optical-flow motion filter:2 FPS 抽帧,Farnebäck dense flow 求像素位移幅度均值,去除静止或异常震荡片段; 3. CLIP temporal coherence:8 帧等距采样,768D 特征余弦相似度检测黑屏 / 拼接错位; 4. Vision-action alignment:把校准好的 action map(joint pose + EE pose + gripper)渲染叠加到视频帧,Qwen3-VL 判断是否一致,过滤标定/同步错误。
Stage 2: Hierarchical balancing(四层):dataset-内、robot-type 间、task-tier、macro-dataset 配额。其中 task tier 配额最具体——head tasks 8–15%、body tasks 40–50%、long-tail 全保留。
Stage 3: Physics-aware captioning(两阶段): - Perception (Qwen3-VL 32B):抽 robot morphology / object attributes / spatial layout / contact events,输出结构化中间表示; - Writing (Qwen3 32B FP8):基于结构化中间表示生成四段叙事 — scene setup → action detail → state transition → camera summary。 - 用 few-shot 正反例 + dynamic grasp-type vocabulary + visible-fact baseline 三个机制压制 hallucination。
3.3 Physical Preference Alignment(核心贡献)¶
3.3.1 解耦 VLM 判别器(Decoupled Discriminator)¶
对每个 prompt \(x\) 和首帧,模型采 \(N\) 个候选视频。判别分两个独立 VLM 完成:
- Proposer = Qwen3-VL 32B Thinking:观察首帧 + 指令,动态生成 task-specific 物理 checklist,遵循 hierarchical scoring system:
- Tier 1(fatal violation, single-vote veto):penetration / anti-gravity;
- Tier 2(micro-physical fidelity):contact dynamics 等。
- Proposer 显式构造正负问题平衡,避免 scorer 全猜"无违法"得高分(sycophancy)。
- Scorer = Gemini 3 Pro:用显式 CoT(global scan → mark suspicious frames → backtrack confirm)对 \(N\) 个候选打分。
为了在 \(\mathcal{O}(N)\) 复杂度内挑出 best \(y_w\) 与 worst \(y_l\)(避免全排列对比 \(N^2\)),用两阶段淘汰赛:先单淘汰得到 winner,再 loser bracket 找最差。最后产出 \((x, y_w, y_l)\) 三元组喂给 DPO。
3.3.2 Diffusion-DPO 损失¶
给定三元组 \((c, v_w, v_l)\),对应 latent \(z_w, z_l\)。注入高斯噪声 \(\epsilon \sim \mathcal{N}(0, I)\) at \(t \sim \mathcal{U}(0, T)\) 得到 \(z_t\),单步 denoising MSE:
物理偏好对齐损失:
直觉:相对于 SFT reference model,把 winner 的 denoising loss 推低、loser 的推高。
关键工程 trick:LoRA 复用为 reference model。Standard DPO 要在显存里同时保两个完整 14B 计算图(policy + reference),直接 OOM。作者把 backbone 冻住,只往 self-attention (q,k,v,o) + FFN (ffn.0, ffn.2) 注入 rank-64 LoRA;计算 \(L_{ref}\) 时临时关闭 LoRA 权重就等价于 SFT baseline,零额外显存。
3.4 Action-Conditioned Generation¶
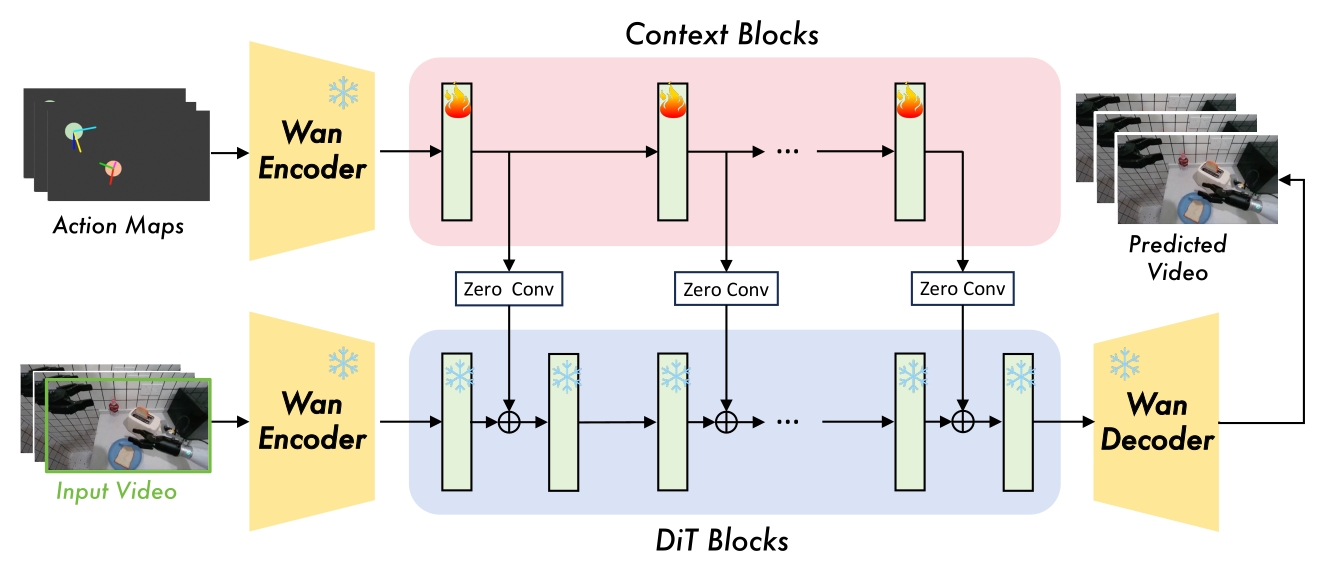 Figure 3:A2V 架构。主 DiT block 被冻结,每隔 5 层(0/5/10/15/20/25/30/35)复制一份做 parallel context block 处理 action map。context block 输出经过零初始化卷积 \(W_{\mathrm{zero}}\) 残差加回主 DiT。零初始化保证训练初期主分支被"零打扰"。
Figure 3:A2V 架构。主 DiT block 被冻结,每隔 5 层(0/5/10/15/20/25/30/35)复制一份做 parallel context block 处理 action map。context block 输出经过零初始化卷积 \(W_{\mathrm{zero}}\) 残差加回主 DiT。零初始化保证训练初期主分支被"零打扰"。
Action Map Construction¶
action 是一个 7D 向量:3D position \((x,y,z)\) + 3D orientation + gripper openness。dual-arm 扩展到 14D。
把 3D position 用相机内外参投影成 2D \((u,v)\) 中心点;orientation 渲染为旋转矩阵三个主轴的 2D 投影箭头,箭头长度编码 depth;gripper 渲染为以 \((u,v)\) 为中心的圆形 mask,opacity 线性指示 openness;dual-arm 用红蓝两个通道区分左右臂。最终得到一张多通道 action map 图。
Action Injection¶
其中 \(\mathbf{h}_i\) 是第 \(i\) 个 context block 的输出,\(W_{\mathrm{zero}}\) 是零初始化卷积,\(\alpha\) 是控制强度。Context block 选第 \(\{0,5,10,15,20,25,30,35\}\) 层复制,只占 1/5 层数。零初始化保证训练初期主 DiT 权重不被扰动,后续逐步学到 action controllability。
3.x Implementation Details¶
| 阶段 | 起点 | 主要超参 | 训练成本 |
|---|---|---|---|
| TI2V SFT | Wan2.1-I2V-14B-480P | bs 128, lr 1e-5, 6000 steps, \(480\times832\) × 81 帧 | — |
| Physics DPO | TI2V 输出 | LoRA rank 64 (q,k,v,o,ffn.0,ffn.2), AdamW lr 1e-6, warmup 10 步, β=5000, BF16, per-device bs 1, gradient checkpointing, 500 steps/epoch × 100 epochs | — |
| A2V (VACE) | DPO 后的模型 | duplicate 8 个 DiT block (0,5,...,35) 做 context branch, backbone 冻结, bs 16, lr 5e-5, 20000 steps | — |
硬件:128 张 H20 GPU。模型规模 14B(DiT 部分)。
4. 结果对比¶
4.1 PBench (PAI-Bench Robot Domain Subset, 174 clips)¶
| Model | Quality | Domain | Avg |
|---|---|---|---|
| Wan 2.5 | 0.7548 | 0.8644 | 0.8096 |
| GigaWorld-0 | 0.7591 | 0.8583 | 0.8087 |
| Veo 3.1 | 0.7740 | 0.8350 | 0.8045 |
| Wan2.1_14B | 0.7672 | 0.8391 | 0.8032 |
| WoW-wan 14B | 0.7605 | 0.8301 | 0.7953 |
| Cosmos-Predict 2.5 | 0.7574 | 0.8021 | 0.7797 |
| Sora v2 Pro | 0.7679 | 0.7626 | 0.7652 |
| UnifoLM-WMA-0 | 0.7593 | 0.6693 | 0.7143 |
| Our Model (SFT only) | 0.7678 | 0.8785 | 0.8232 |
| Our Model + DPO | 0.7676 | 0.9306 | 0.8491 |
读图重点:
- DPO 主要拉的是 Domain Score(0.8785 → 0.9306, +5.2 pt),Quality Score 几乎不变(0.7678 → 0.7676),说明对齐没有以视觉质量为代价;
- Veo 3.1 拿到最高 Quality,但 Domain 落后 ~9.5 pt——这是论文 motivation 的最大实证支撑;
- Sora v2 Pro 的 Domain Score(0.7626)甚至是表中最差的,对应作者强调它"contactless grasping"的失败。
4.2 EZSbench(OOD Zero-shot Benchmark)¶
| Model | Quality | Domain | Avg |
|---|---|---|---|
| WoW-wan 14B | 0.7609 | 0.7951 | 0.7780 |
| GigaWorld-0 | 0.7272 | 0.7826 | 0.7549 |
| Cosmos-Predict 2.5 | 0.7089 | 0.7698 | 0.7394 |
| UnifoLM-WMA-0 | 0.7355 | 0.5232 | 0.6294 |
| Our Model | 0.7694 | 0.8366 | 0.8030 |
⚠️ 注意此表中作者只列了 Our Model(SFT 后?DPO 后?)一个版本,并未给出 DPO ablation 的 EZSbench 数字——也没有 Veo 3.1 / Sora v2 Pro 的 EZSbench 对比,文中没说明缘由。
4.3 Action-Conditioned Generation(200 个 A2V 样本)¶
| Model | PSNR | SSIM | Traj. Consis. |
|---|---|---|---|
| Enerverse-AC | 20.42 | 0.7542 | 0.8157 |
| Gen-Sim | 18.05 | 0.7413 | 0.6195 |
| Ours | 21.09 | 0.8126 | 0.8522 |
trajectory consistency 用细调过的 YOLO gripper detector + nDTW 计算。
4.4 关键消融 / 缺失的消融¶
论文没有正式的 ablation table。可以从 §4.1 间接读出的对照:
| Configuration | PBench Domain Score |
|---|---|
| Wan2.1_14B(原始 backbone) | 0.8391 |
| + 数据策划 SFT | 0.8785 (+3.94 pt) |
| + Physics DPO | 0.9306 (+5.21 pt) |
也就是说 "数据 curation 单独贡献 ~4 pt,DPO 单独贡献 ~5 pt"——但论文没有给出 e.g. 不带 vision-action alignment 滤波 / 不带 hierarchical balancing 的版本,也没有 DPO LoRA rank、β、checklist Tier 数量的消融。
4.5 EZSbench 构造¶
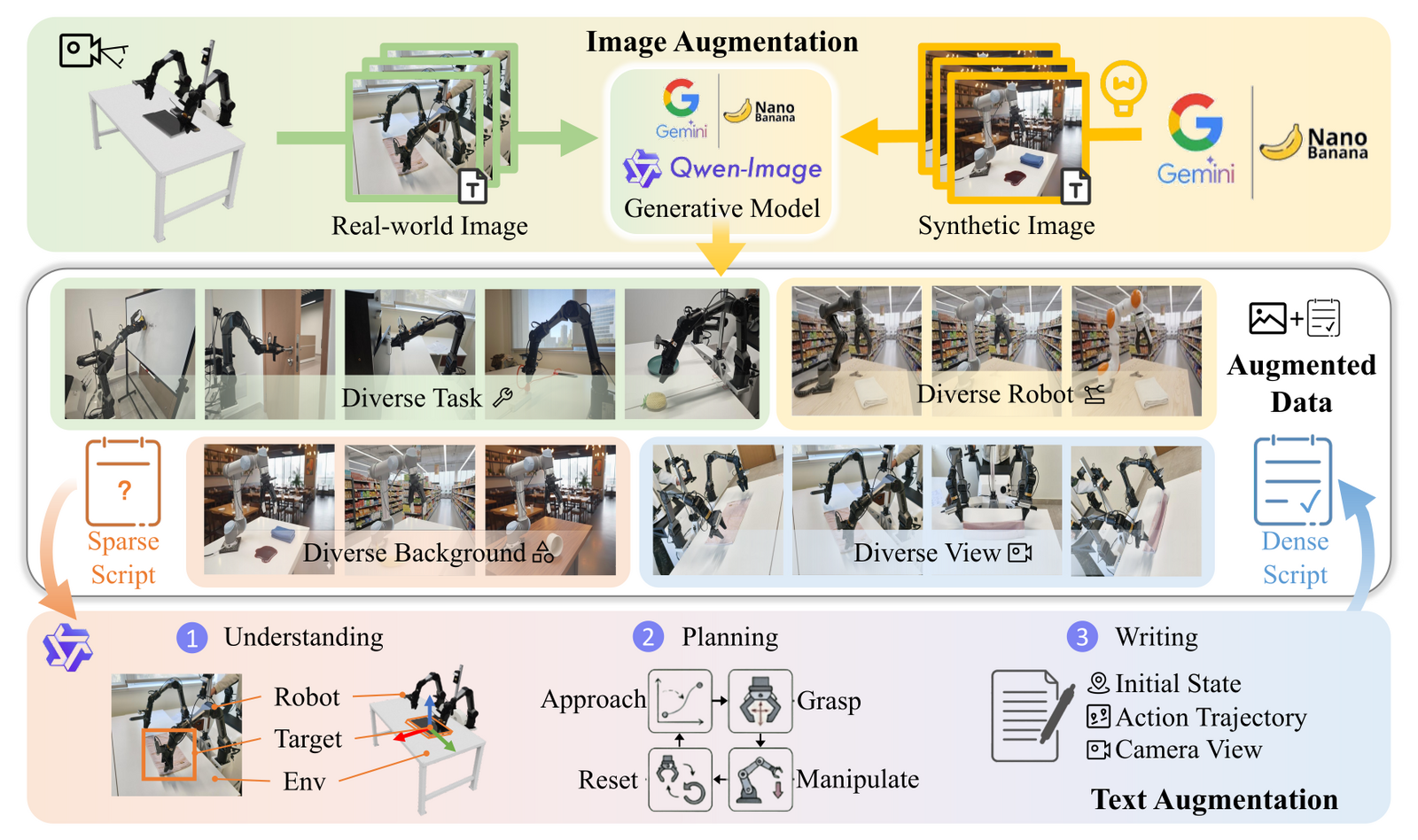 Figure 4:EZSbench 构造。Top:双源图像增强 — Nano Banana 合成 + VLM 引导的真实图编辑。Down:三阶段 dense description 合成 — visual anchoring(场景布局/坐标)→ action simulation(kinematic 推断)→ narrative synthesis。整套 pipeline 是 完全用 LLM/VLM 合成的,没有人工标注,作者强调 30–50% 是 negative question 用来防 shortcut。
Figure 4:EZSbench 构造。Top:双源图像增强 — Nano Banana 合成 + VLM 引导的真实图编辑。Down:三阶段 dense description 合成 — visual anchoring(场景布局/坐标)→ action simulation(kinematic 推断)→ narrative synthesis。整套 pipeline 是 完全用 LLM/VLM 合成的,没有人工标注,作者强调 30–50% 是 negative question 用来防 shortcut。
4.6 PBench 定性对比¶
 Figure 5:PBench 定性对比。每行一个 case,每列一个模型。重点看 Sora v2 Pro 与 Veo 3.1 在 contact-rich 抓取瞬间出现 gripper / object 变形;GigaWorld-0 与 Cosmos 出现"抓穿";WoW 出现"非接触抓取";UnifoLM 与 Wan 2.5 抓错目标(铲子 vs 抹布)。最后一行 Our Model 是这套图里唯一保持几何完整 + 目标识别正确的。
Figure 5:PBench 定性对比。每行一个 case,每列一个模型。重点看 Sora v2 Pro 与 Veo 3.1 在 contact-rich 抓取瞬间出现 gripper / object 变形;GigaWorld-0 与 Cosmos 出现"抓穿";WoW 出现"非接触抓取";UnifoLM 与 Wan 2.5 抓错目标(铲子 vs 抹布)。最后一行 Our Model 是这套图里唯一保持几何完整 + 目标识别正确的。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- LoRA 复用为 reference model 是真的优雅。把 14B DiT 的 DPO OOM 问题从"需要 2× 显存"降到"零额外显存"——只用一个开关 LoRA on/off 就同时拿到 \(\pi_\theta\) 和 \(\pi_{ref}\)。这是该论文最有迁移价值的工程 trick,凡是大模型 DPO 都能用。
- Proposer / Scorer 跨厂商解耦确实压低了 self-evaluation 偏差。把 "出题人 Qwen3-VL"和"打分人 Gemini 3 Pro"硬性分开比同一个 VLM 两次推理更合理,再加 30–50% negative question 的硬性配额防 sycophancy——这是 §3.3.1 真正非平凡的设计。
- Tier 1 single-vote veto + Tier 2 区分对应物理违法的二元性:穿模/反重力是绝对错误,micro-friction/contact-noise 是程度问题。普通的连续打分会让 fatal violation 被中等错误"稀释",hierarchical scoring 能让 worst-of-N 真正抓到 worst。
- Parallel context block 用每 5 层一份而不是每层一份,是显存与控制力之间的合理 trade-off;零初始化卷积保证训练初期主 DiT 完全无干扰,这是 ControlNet/VACE 一贯的好传统,但迁移到具身 action 仍然有效。
- Tournament-based \((y_w, y_l)\) 选取把 N 候选下需要 \(O(N^2)\) 的对比降到 \(O(N)\),对 14B 视频模型这种 inference 昂贵的设定很关键。
- 数据策划的 task-tier 配额(head 8–15%、body 40–50%、long-tail 全保留)比 "uniform 截断"或"按比例采样"更细,且和"diversity > volume"的实证结论对齐。
5.2 做得不够好的地方 / 值得质疑的地方¶
-
没有正式 ablation table。整篇论文最重要的设计是"data curation + DPO + parallel context block"三件套,但只能从表 1 间接拼出 SFT-vs-DPO 的对比;缺失的关键 ablation 至少包括:
- 不带 vision-action alignment filtering(§3.2 Stage 1 Step 4)的 SFT
- 不带 hierarchical balancing 的 SFT
- DPO 单 VLM proposer+scorer(不解耦)的 Domain Score
- \(\beta \in \{500, 5000, 50000\}\) 的扫描
- LoRA rank ∈ {8, 32, 64, 128} 的扫描
- parallel context block 复制比例(每 1/3/5/10 层)
-
β = 5000 异常高。常见 Diffusion-DPO(Wallace et al.)的 β 在 100–1000 量级,5000 提示 reward signal 极弱、需要被大幅放大才能 push 梯度。这意味着 winner/loser 之间的 denoising loss 差异在 latent space 是非常微弱的,DPO 信号被反向硬拉——容易过拟合到判别器 quirks(包括 Gemini 3 Pro 的 CoT bias)。
-
EZSbench 用 LLM/VLM 全自动构造,再用 VLM 评测,存在系统性回路。
- Proposer (Qwen3-VL Thinking) + Scorer (Qwen2.5-VL-72B-Instruct) 都是 Qwen 系;
- Dense description 也是 LLM 写的,模型生成的视频是否"对齐 description"很大程度上反映的是 VLM 之间的语言一致性,不一定是物理一致性;
- "training-independent" 的承诺被 Nano Banana T2I 合成图打了折扣——合成图的分布特征(如背景物体随机化、机械臂渲染质感)和某些 baseline(如训练在大量 sim 数据上的)天然契合度不同。
-
EZSbench 表里只有自家模型一个版本。SFT vs SFT+DPO 都没分开列,Veo 3.1/Sora v2 Pro 干脆没有 EZSbench 数据。如果 DPO 真的能 generalize 到 OOD,这应该是最有说服力的对比,却被回避了——可能的原因要么是 Veo/Sora API 调用成本/license 问题,要么是 OOD 上 DPO 增益不如 in-distribution。
-
PBench Domain Score 是同家族 VLM 评分。Qwen2.5-VL-72B-Instruct 做 binary VQA,而作者的 Proposer 也是 Qwen3-VL Thinking。即使他们"显式解耦"了 proposer/scorer,但都在 Qwen 家族里 —— 真正的端到端 metric circular 仍然存在。
-
Action map 用 2D 投影 + "箭头长度编码 depth"过于工程化。
- 长度→深度的映射在相机近距/远距时会失真(透视压缩),论文没说映射是否 normalize;
- 旋转的"三个主轴投影"在 axis-aligned 视角下会退化(轴重合时长度恰好为 0),但论文也没讨论 degenerate case;
- 7D 单臂 action vector 不含 force / joint torque,所以"physically plausible"在 contact 过程中根本无从控制接触力——这与 §1 强调的 "friction, mass distribution" 是有 gap 的。
-
完全没有 closed-loop policy evaluation。论文反复强调可以做 VLA simulator 与 WAM,但实际只评了视频生成质量。一个 world model 真正有用是滚动推理时仍然合理(rollouts > 5s),而 81 帧 ~3.4s @ 24fps 的单次生成无法验证 rollout 稳定性,也没接 policy 做 closed-loop。结论里"future work"承认了这一点,但这是 world model 论文里最大的空缺。
-
算力门槛极高,难以复现。128 张 H20 + 14B DiT + 6000 SFT + 20000 A2V + 100 epoch DPO,加上 Gemini 3 Pro API 打分的 token 成本,整条流水线不是学术界可重复的。论文宣称 "release EZSbench",但没承诺放出 SFT/DPO 模型权重(GitHub 链接里目前是占位符)。
-
跨 embodiment 泛化只是定性图。论文宣称 "cross-embodiment control",但 A2V 表只有 3 行(Ours / Enerverse-AC / Gen-Sim),没有按 embodiment 划分的 break-down(e.g. 在 AgiBot 数据上训练后到 Franka 单臂上的迁移数字),dual-arm 案例只出现在 qualitative figure。
-
DPO 训练数据规模没说。500 steps × 100 epoch、bs 1 的具体训练样本数?三元组 \((x, y_w, y_l)\) 各采了多少个?文中没披露,对评估 DPO 的真实贡献是个 blocker。
5.3 值得继续探讨的方向¶
- 把 DPO 替换成 GRPO / RLHF-style 多样本 reward,让 reward 不是 binary winner/loser,而是 hierarchical 物理 checklist 的连续打分——可能比 N=2 的 DPO 信号更稠密。
- 用 differentiable physics simulator(如 PhysGaussian、PhysGen)替代 VLM 判别器做 reward,把 "Qwen3-VL + Gemini 3 Pro" 的 LLM-as-judge 换成真物理引擎的 contact / penetration / gravity 残差。
- Closed-loop policy roll-in:把 ABot-PhysWorld 接到 VLA policy(π0、OpenVLA)做长时段 rollout 评估;Gemini 3 Pro 在 long-horizon 上能否一致打分本身就是一个独立问题。
- β 与 LoRA rank 的扫描:β=5000 离常见 DPO 配置太远,需要看 reward landscape 是不是真的需要这么大;rank-64 vs full DPO 的差距值得测。
- Action 表示重设计:把 2D action map 换成 3D pose volume(NeRF / Gaussian splat) 或 explicit depth channel,避免 "箭头长度编码 depth" 的不稳定性。
- EZSbench 评测器多样化:换 evaluator 模型族(Gemini → GPT-5-V → Claude Vision)跑同一套样本,看模型间一致性,剥离 evaluator-specific noise。
- 数据策划单变量消融:vision-action alignment filter 删掉后,physics violation 率上升多少?这是支撑数据 curation 价值的最关键实验。
- 跨 embodiment 量化:dual-arm trajectory consistency / 真实 Franka 数据上的 zero-shot 数字,verify "cross-embodiment" 不只是口号。
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:source/
- 项目页 / 代码:https://github.com/amap-cvlab/ABot-PhysWorld(截至 2026-03 占位)
关键 baseline 与相关论文:
- Backbone:Wan2.1-I2V-14B / Wan2.5(Alibaba Wan team)
- Diffusion-DPO:Wallace et al., "Diffusion Model Alignment Using Direct Preference Optimization"
- Action injection 借鉴:VACE(视频编辑),ControlNet(零初始化卷积)
- Baselines:Veo 3.1(Google)、Sora v2 Pro(OpenAI)、GigaWorld-0、Cosmos-Predict 2.5(NVIDIA)、UnifoLM-WMA-0(Unitree)、WoW-wan 14B、Enerverse-AC、Genie-Envisioner
- Benchmark:PAI-Bench / PBench(zhou2025paibench)
- 判别器 VLM:Qwen3-VL 32B Thinking、Gemini 3 Pro、Qwen2.5-VL-72B-Instruct
- T2I:Nano Banana(Google 2025)