Pelican-Unified 1.0: A Unified Embodied Intelligence Model for Understanding, Reasoning, Imagination and Action¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Pelican-Unified 1.0: A Unified Embodied Intelligence Model (UEI) for Understanding, Reasoning, Imagination and Action
- 作者: WFM System Group, Beijing Innovation Center of Humanoid Robotics (X-Humanoid)。署名为团队级 placeholder,core contributors 含 Yi Zhang / Yinda Chen / Che Liu / Zeyuan Ding(VLM+Action)、Jin Xu / Shilong Zou(World-model),corresponding 为 Jian Tang、Xiaozhu Ju,tech lead Yong Dai
- arXiv 编号: 2605.15153(2026-05 提交,技术报告形态,未注明会场)
- 关键词: unified embodied model, VLM + world model + action, chain-of-thought 作为 latent 条件, joint video-action flow matching, shared DiT backbone, RoboTwin, WorldArena
 Figure 1:一张图概括卖点 —— 同一个 checkpoint 同时做 understanding(左侧 cognitive/grounding 任务)、reasoning(中上 CoT)、imagination(action-conditioned 未来帧预测)与 action(底部 UR5e 真机插拔),并在 VLM 64.5 / RoboTwin 93.6 / WorldArena 66.0 三个榜上同时拿分。
Figure 1:一张图概括卖点 —— 同一个 checkpoint 同时做 understanding(左侧 cognitive/grounding 任务)、reasoning(中上 CoT)、imagination(action-conditioned 未来帧预测)与 action(底部 UR5e 真机插拔),并在 VLM 64.5 / RoboTwin 93.6 / WorldArena 66.0 三个榜上同时拿分。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 embodied foundation model(具身基础模型)子领域。核心立场问题:物理智能应该靠"把 understanding / reasoning / imagination / action 分别做大的专家拼起来",还是"把它们当作同一个自适应闭环一起训练"?论文旗帜鲜明选后者,并给出一个具体实现 Pelican-Unified 1.0。
它要解决的不是某个单点任务,而是当前具身模型"能力碎片化"的结构性问题:VLM 会理解会推理但不能执行、VLA 能执行但缺乏对未来后果的想象、world model 能想象未来但难以被语言/任务逻辑 steer、WAM(world-action model)连接了想象与动作但没有可解释、可纠错的推理。
2.2 Motivation¶
论文用一段哲学+认知科学引子(亚里士多德"灵魂离不开意象"、William James、《中庸》"博学审问慎思明辨笃行")来包装一个工程主张:在 embodied cognition 里,推理、想象、动作本来就不是可分离的能力 —— motor planning 会调用运动模拟系统,感知围绕"身体能做什么"组织,未来想象支撑动作选择。因此 foundation model 也应该让这四者共享内部表示、互为条件、在同一训练过程中共演化,而不是分开训练再事后拼接。
关键论据图(Fig. 3,见 §5):从一个 base VLM 出发,标准 VLA 训练会削弱 grounding 与 attention(感知退化),而 Pelican-Unified 在学会输出动作的同时保住了感知能力 —— 这是"为什么需要联合训练"最直观的证据。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| VLM (embodied) | Gemini Robotics-ER, Pelican-VL | 强语义/空间理解,但不是可执行策略:不能行动、不能用物理后果检验自己的推理 |
| VLA | RT-2, π₀, π₀.₅, OpenVLA, Helix | 把语言/感知映射到动作,但缺显式未来想象 → 实质是 imitation mapping,难泛化到未见组合、long-horizon、contact-rich |
| World Model / 视频生成 | Cosmos-Predict, LeWorldModel, WoW | 能想象未来,但想象停留在像素层、难用任务逻辑/语言推理 steer |
| World Action Model (WAM) | 各类 WAM | 把想象的未来接到动作,但没有统一推理 → 不可解释、rollout 中难纠错、long-horizon 误差累积 |
一句话:领域不缺强组件,缺的是"让四种能力互为条件一起学"的那个闭环模型。
2.4 论文解决方案(一句话)¶
用一个 VLM(Qwen3-VL-4B)把场景/指令/历史观察/历史动作编码进共享语义空间并自回归产出 CoT,再把 CoT 末端 hidden state 投影成一个 dense loop state \(z\);一个统一 Future Generator(Wan2.2-5B 的 DiT)在同一去噪过程里、以同一个 \(z\) 为条件,联合生成未来视频与未来动作;文本、视频、动作三个 loss 全部回传到这个共享表示 —— 把"理解-推理-想象-行动"训练成单个对象而非三段流水线。
2.5 与前序工作的关系¶
- Qwen3-VL-4B:unified encoder/reasoner 的初始化 backbone,也是 VLM benchmark 的直接 baseline。
- Wan2.2-5B:Unified Future Generator(diffusion transformer)的初始化。
- 整体可以看成 WAM + 显式 CoF/CoT 推理前缀:相比单纯的 WAM(video+action 联合去噪),多了"先推理出 \(z\) 再去噪"的一步,把语言推理塞进生成条件里(见 Fig. 2 三种范式对比)。
- 在 RoboTwin 上的主要对手是一批 2026 年的 WAM/world-model(MotuBrain、AIM、LingBot-VA、Fast-WAM、Motus 等),其中 MotuBrain 实际上在 RoboTwin 上超过本文(95.9 vs 93.5)。
3. 方法介绍¶
 Figure 2:(a) VLA 直接 obs+指令→动作,监督只塑造 "act" 一面;(b) WAM 联合预测未来视频与动作,但 latent 不含显式推理;(c) Pelican-Unified 先用 VLM reasoner 产出 CoT + loop state \(z\),再用统一 DiT 在 \(z\) 条件下联合去噪未来视频 token 与动作 token。文本/视频/动作三路 loss 都回传到同一个 \(z\)。
Figure 2:(a) VLA 直接 obs+指令→动作,监督只塑造 "act" 一面;(b) WAM 联合预测未来视频与动作,但 latent 不含显式推理;(c) Pelican-Unified 先用 VLM reasoner 产出 CoT + loop state \(z\),再用统一 DiT 在 \(z\) 条件下联合去噪未来视频 token 与动作 token。文本/视频/动作三路 loss 都回传到同一个 \(z\)。
3.1 形式化¶
给定历史观察 \(o_{\leq t}\)、历史动作 \(a_{<t}\)、语言指令 \(l\),模型一次前向产出三元组:
其中 \(\tau_t\) 是 CoT 推理 trace,\(\hat{v}_{t:t+H}\) 是想象的未来视频,\(\hat{a}_{t:t+H}\) 是可执行动作 chunk。模型由两个紧耦合组件构成:构造任务状态 + 生成推理 trace 的 VLM,和复用该状态联合去噪未来视频 latent 与动作轨迹的 Unified Future Generator。
3.2 Unified Encoder + Reasoning:从多模态上下文到 loop state \(z\)¶
VLM 先对交互历史 \(c_t = (o_{\leq t}, a_{<t}, l)\) 编码,自回归产出 CoT:
关键点:这条 CoT 不是事后解释,而是关于任务意图、物理约束、未来后果、动作选择的中间表示。CoT 末端的 VLM hidden state \(h_{\tau_t}\) 经投影 \(P_\phi\) 得到 dense loop state:
\(z\) 是全文的核心耦合表示:它既要承载未来视频生成需要的信息,又要承载动作预测需要的信息。它不只被语言建模 loss 优化,还会被下游生成 loss"反向施压",逼它编码"世界会怎样演化"和"该执行什么动作"。
3.3 Unified Future Generator:共享 DiT 同时生成视频与动作¶
视频序列经 video VAE 编码成 latent \(x^v = \mathcal{E}_{\text{vae}}(v_{t:t+H})\),动作轨迹归一化成连续表示 \(x^a = \text{Norm}(a_{t:t+H})\)。关键设计:不用独立 world model + 独立 policy head,而是把视频和动作嵌入同一个 transformer 宽度:
DiT backbone 跨模态共享。视频 token 与动作 token 在去噪中通过 self-attention 相互作用,\(z\) 通过 cross-attention 注入,diffusion 时间步 \(s\) 通过 adaptive norm 调制。最后只用 modality-specific 的输出头映射回各自的 velocity:\(\hat{u}^v_s = d_v(h^v_L)\),\(\hat{u}^a_s = d_a(h^a_L)\)。也就是说,modality-specific 参数只用于输入/输出转换,去噪计算本身完全共享。
3.4 联合 Flow Matching 目标¶
连续时间 flow matching。采样 \(s \sim \mathcal{U}(0,1)\) 与高斯噪声 \(\epsilon^v, \epsilon^a\)。
视频:只对未来区域去噪,观察前缀固定。用 mask \(M_{\text{cond}}, M_{\text{fut}}\): $\(x^v_s = M_{\text{cond}} \odot x^v + M_{\text{fut}} \odot ((1-s)x^v + s\epsilon^v)\)$ target velocity \(u^v_s = M_{\text{fut}} \odot (\epsilon^v - x^v)\),loss 为未来区域上的 L2: $\(\mathcal{L}_{\text{video}} = \mathbb{E}_{s,\epsilon^v}\big[\|M_{\text{fut}} \odot (\hat{u}^v_s - u^v_s)\|_2^2\big]\)$
动作:在同一连续空间扩散 \(x^a_s = (1-s)x^a + s\epsilon^a\),target \(u^a_s = \epsilon^a - x^a\),但 loss 用 SmoothL1(robust regression) 而非 L2: $\(\mathcal{L}_{\text{action}} = \mathbb{E}_{s,\epsilon^a}\big[M_a \odot \text{SmoothL1}(\hat{u}^a_s, u^a_s)\big]\)$
文本:标准自回归 NLL \(\mathcal{L}_{\text{text}} = -\sum_i \log p_\phi(\tau_{t,i} \mid c_t, \tau_{t,<i})\)。
总目标是三者加权和: $\(\mathcal{L} = \lambda_{\text{text}}\mathcal{L}_{\text{text}} + \lambda_{\text{video}}\mathcal{L}_{\text{video}} + \lambda_{\text{action}}\mathcal{L}_{\text{action}}\)$
论文反复强调:这三个 loss 全挂在同一个 task-conditioned 表示上,才是"unification"在优化层面的真正含义 —— text loss 让表示语义化,video loss 让它对未来动态有预测性,action loss 让它可执行。
3.5 Action-conditioned 变体¶
除了"动作作为输出",模型也支持"动作作为条件输入",做 action-conditioned video prediction(Fig. 4 / §4.3 想象能力)。动作经 MLP、视频经 3D VAE 进入同一 Unified Future Generation,配合文本提示("Robot type: aloha-agilex, Camera: head camera, Task: pick dual bottles"),输出与输入动作指令逐帧对齐的预测视频。
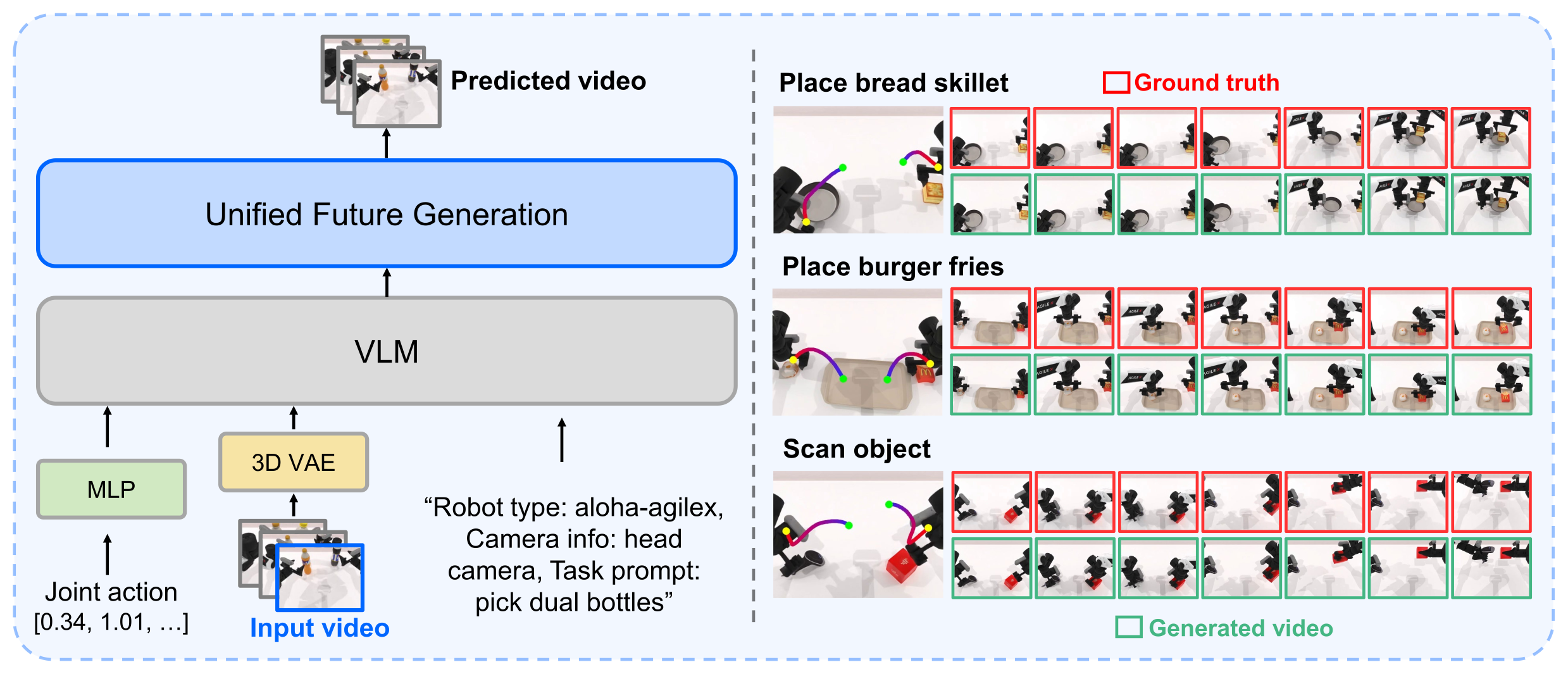 Figure 3:以动作为条件输入的未来帧预测。右侧红框 = ground truth,绿框 = 生成视频,在 place bread/burger、scan object 三个任务上做到 action 与帧的细粒度对齐。这是把"想象"显式接受动作 steering 的接口。
Figure 3:以动作为条件输入的未来帧预测。右侧红框 = ground truth,绿框 = 生成视频,在 place bread/burger、scan object 三个任务上做到 action 与帧的细粒度对齐。这是把"想象"显式接受动作 steering 的接口。
3.x Implementation Details(可复现性相关)¶
- Backbone:VLM = Qwen3-VL-4B-Instruct;Generator = Wan2.2-5B DiT。合计参数量约 9B 级,但论文未给出精确总参数、训练步数、batch size、学习率、训练硬件。
- 训练数据:大规模真实机器人交互数据(用于让 generator 隐式学到空间结构与物理动态),具体规模/来源未披露。
- 真机平台:UR5e 机械臂 + Tienkung(天工)人形机器人;UR5e 用于工业控制面板(RJ45、香蕉插座、防水套等)插拔。
- 延迟 / 控制频率:全文未给出任何推理延迟、控制频率、video-DiT 去噪步数等数字 —— 对一个每步要去噪未来视频的闭环系统,这是关键缺口(见 §5.2)。
- 发布:无 code / checkpoint,作者署名为团队 placeholder,待内部审批后替换为个人名。
注:原 LaTeX 里关于 inference 部署的"五种 readout 模式表"(action-only / reason-then-act / action+imagination / reason-then-imagine / all-three)以及 receding-horizon 闭环更新公式全部被注释掉了,正文只保留训练侧描述。
4. 结果对比¶
论文的核心实验逻辑是"先证明拆开看不掉链子(三个专家榜),再讲整体闭环的好处(真机)"。但真机部分的定量表格在正文里几乎全被注释删除,只剩定性图(见 §5.2)。
4.1 Understanding —— 8 个 VLM Benchmark(Tab. 1)¶
| Method | MMMU | MMBench | MMStar | InfoVQA | ChartQA | Where2Place | PhyX | RefSpatial | Avg |
|---|---|---|---|---|---|---|---|---|---|
| OpenVLA | 26.3 | - | - | - | - | - | - | - | 3.3 |
| ECoT | 26.6 | 3.7 | - | - | - | - | 10.1 | - | 5.0 |
| MolmoAct | 28.4 | 55.1 | 1.2 | 41.9 | 55.9 | 8.2 | 29.7 | - | 27.5 |
| π₀.₅ | 24.0 | 6.8 | 21.7 | 7.7 | 5.1 | - | 16.2 | - | 10.2 |
| Gemma3-4B-IT | 39.3 | 68.6 | 37.1 | 40.9 | 50.3 | 7.5 | 17.2 | 2.2 | 32.9 |
| Qwen3-VL-4B-Instruct(base) | 52.6 | 84.5 | 62.9 | 78.4 | 81.1 | 17.0 | 41.1 | 48.0 | 58.2 |
| Pelican-Unified | 53.0 | 84.9 | 63.3 | 78.4 | 81.5 | 45.2 | 61.7 | 49.3 | 64.7 |
观察:相对 base 的提升几乎全部来自 embodied 子集(Where2Place +28.2、PhyX +20.6、RefSpatial +1.3),通用 benchmark(MMMU/MMB/MMStar/InfoVQA/ChartQA)基本是噪声级别的 +0.4 上下。这更像"在机器人数据上做了 domain 微调",而不一定是"unification"本身的功劳(缺一个只 fine-tune VLM、不加 video/action 头的对照,见 §5.2)。VLA baseline(OpenVLA/π₀.₅)在 VLM 榜上崩盘是预期内的 —— 它们本就不为这些任务设计。
4.2 Action —— RoboTwin 50 任务双臂(Tab. 2)¶
| Type | Model | Clean | Randomized | Avg |
|---|---|---|---|---|
| VLA | π₀ | 65.9 | 58.4 | 62.2 |
| VLA | X-VLA* | 72.9 | 72.8 | 72.9 |
| VLA | π₀.₅ | 82.7 | 76.8 | 79.8 |
| VLA | starVLA | 88.2 | 88.3 | 88.3 |
| VLA | ABot-M0 | 81.2 | 80.4 | 80.8 |
| VLA | LingBot-VLA | 86.5 | 85.3 | 85.9 |
| WM | JEPA-VLA | 73.5 | – | – |
| WM | Motus | 88.7 | 87.0 | 87.9 |
| WM | LingBot-VA | 92.9 | 91.6 | 92.3 |
| WM | Fast-WAM | 91.9 | 91.8 | 91.9 |
| WM | Being-H0.7 | 90.2 | 89.6 | 89.9 |
| WM | AIM | 94.0 | 92.1 | 93.1 |
| WM | MotuBrain | 95.8 | 96.1 | 95.9 |
| Unified | Pelican-Unified 1.0 | 93.6 | 93.3 | 93.5(第 2) |
观察:93.5 是第二名,被 MotuBrain(一个纯 WAM,没有显式推理)以 95.9 明确超过;clean 上也输给 AIM(94.0)。提升广度上还行:31/50 任务 ≥95%、39/50 ≥90%、15 个满分;失败集中在 hanging mug、put bottles dustbin 这类几何敏感/long-horizon 任务。结论是"unification 不削弱低级控制"成立,但"unification 带来 SOTA 控制"并不成立。
4.3 Imagination —— WorldArena(Tab. 3,0–100)¶
| Model | EWM Score | Rank | Visual | Motion | Content | Physics | 3D Acc | Control |
|---|---|---|---|---|---|---|---|---|
| Pelican-Unified | 66.03 | 1 | 63.43 | 62.69 | 60.33 | 61.51 | 98.13 | 59.28 |
| WorldScape v0.2 | 64.24 | 2 | 62.65 | 42.34 | 65.18 | 73.29 | 96.28 | 59.38 |
| FlowWAM-FiveAges | 64.12 | 3 | 63.29 | 41.05 | 66.92 | 67.82 | 97.84 | 60.28 |
| MotuBrain | 64.07 | 4 | 60.69 | 62.21 | 59.57 | 61.18 | 91.64 | 57.35 |
| … | … | … | … | … | … | … | … | … |
| Veo3.1 | 57.77 | 15 | 57.44 | 30.26 | 68.34 | 46.43 | 86.96 | 63.15 |
观察:总分第一但领先第二仅 1.8 分,而且这个第一完全由 Motion Quality(62.69 vs 多数 ~40)与 3D Accuracy(98.13)撑起来;在 Physics Adherence(61.51 vs WorldScape 73.29)和 Content Consistency(60.33,接近垫底)上都偏弱。榜单里大量是匿名内部条目(WorldScape / FlowWAM / FAW / Goose_Egg / Z-WM / RunWorld),所以"超越专用 world model"的含金量有限。
4.4 Imagination —— WorldArena 人类盲评(Tab. 4,0–2)¶
| Model | Task Success | Controllability | Temporal | Physical | Average |
|---|---|---|---|---|---|
| Pelican-Unified 1.0 | 1.81 | 2.00 | 2.00 | 1.23 | 1.76 |
| Seedance2.0 (API) | 1.21 | 1.87 | 1.98 | 1.15 | 1.55 |
| Happyhorse-1.0 (API) | 1.65 | 1.81 | 2.00 | 0.13 | 1.40 |
| EnerVerse-AC | 0.00 | 1.84 | 2.00 | 1.64 | 1.37 |
| Wan2.7 (API) | 1.19 | 1.68 | 2.00 | 0.29 | 1.29 |
| Cosmos-Predict2 | 0.63 | 1.85 | 1.79 | 0.35 | 1.16 |
| GigaWorld-0 | 0.33 | 1.94 | 1.98 | 0.13 | 1.09 |
| UnifoLM-WMA-0 | 0.05 | 1.48 | 2.00 | 0.11 | 0.91 |
观察:总均分第一(1.76),靠 Task Success(1.81,唯一 >1.7)和满分 Controllability(2.00)。论文设计这个盲评的动机很好 —— 自动指标会奖励"画面干净但跑题"的 rollout(如 Happyhorse、EnerVerse-AC 的 Task Success 接近 0 却 Temporal 满分)。但 Pelican 在 Physical Plausibility 上输给 EnerVerse-AC(1.23 vs 1.64),论文的辩护是"不动作的模型不会违反物理"—— 修辞上漂亮,实质上承认自己生成的物理更不可信。
4.5 Real-World(§6)—— 定性为主,几乎无定量¶
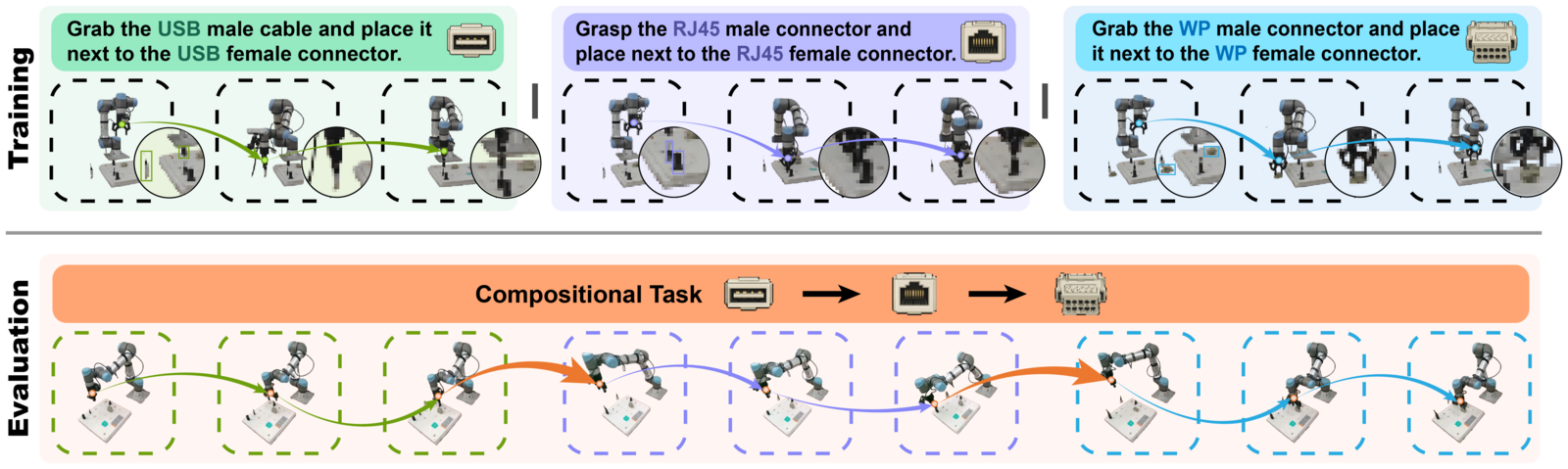 Figure 4:训练时只单独学原子技能(grab USB / grasp RJ45 / grab WP),测试时给一条自然语言指令要求把 A+B 串成 compositional task(如"插好 RJ45 再做防水"),全程无任何 A+B 组合演示。
Figure 4:训练时只单独学原子技能(grab USB / grasp RJ45 / grab WP),测试时给一条自然语言指令要求把 A+B 串成 compositional task(如"插好 RJ45 再做防水"),全程无任何 A+B 组合演示。
- Compositional generalisation:原子技能 \(\mathcal{A}\)(plug RJ45)与 \(\mathcal{B}\)(waterproof)分别单独训练,测试时一句话要求连续完成 A→B。论文论点:失败集中在 A→B 的衔接处,VLA baseline 在此崩是因为其动作分布不含"A 完成后该发生什么",而 imagination 面可以渲染 post-A 场景再 re-condition。但正文没有给出任何成功率数字或 baseline 对照表(相关表如 78.6%/75.0%/58.0% 那组、emergent 能力的 41% 等全在 LaTeX 里被注释掉了)。
- Zero-shot generalization:5 个 seen 任务(各 ~300 episode)+ 3 个 unseen 任务(各仅 50 video)联合训练;正文这一节误引 WorldArena 人类盲评表(Tab. 4)当作真机结论,真正的真机 zero-shot 成功率没有出现。
5. 引申问题 / 讨论¶
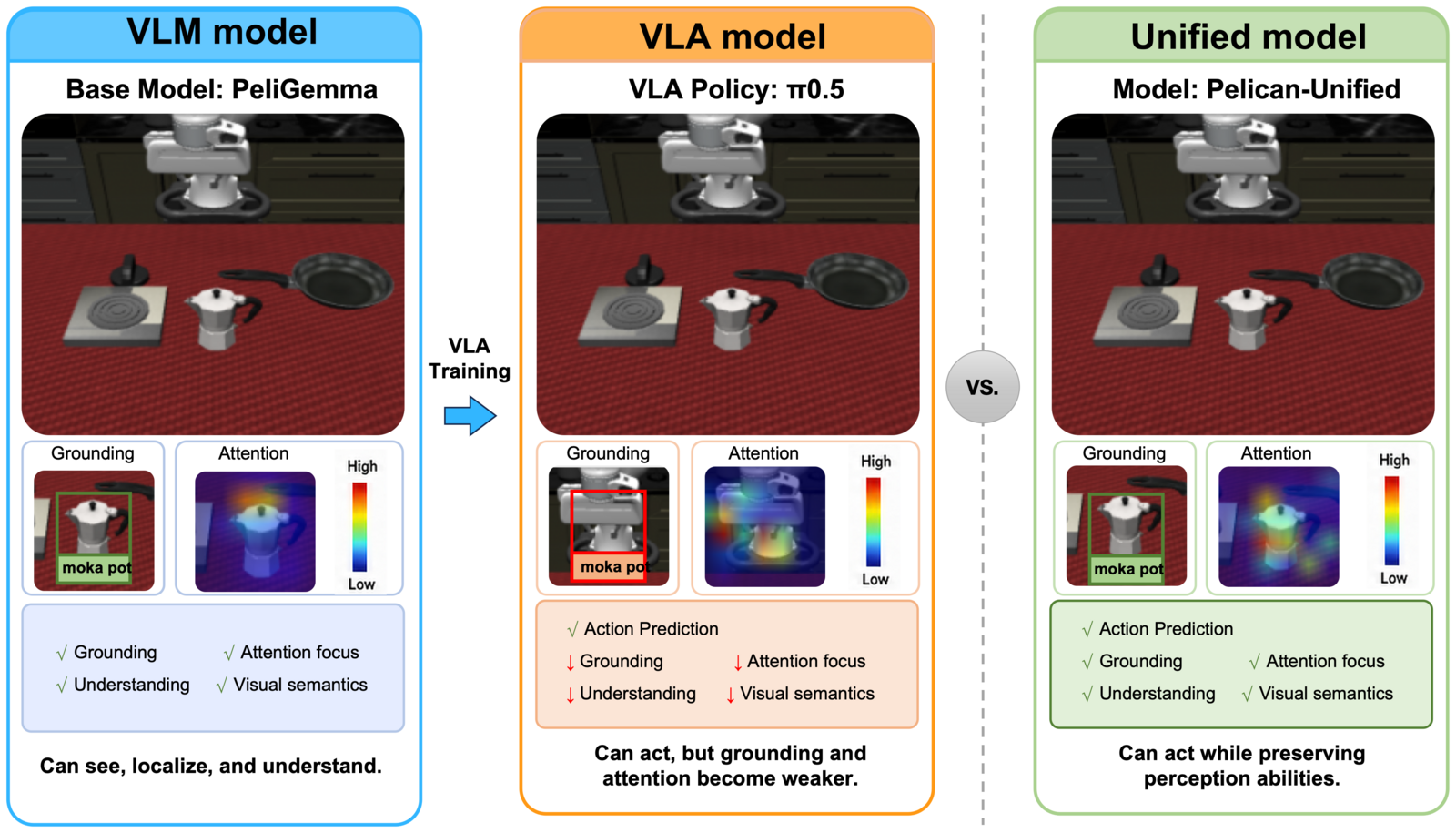 Figure 5:核心 motivation 图。Base VLM 会"看懂+定位";标准 VLA 训练后 grounding/attention 明显退化(红框 attention 散乱);Pelican-Unified 在学会输出动作的同时保住了感知。这是"为什么要联合训练而非先 VLM 后 VLA"最有力的单张证据。
Figure 5:核心 motivation 图。Base VLM 会"看懂+定位";标准 VLA 训练后 grounding/attention 明显退化(红框 attention 散乱);Pelican-Unified 在学会输出动作的同时保住了感知。这是"为什么要联合训练而非先 VLM 后 VLA"最有力的单张证据。
5.1 做得好的地方¶
- 真正共享 DiT 宽度,而不是"world model + policy head"拼接:video token 与 action token 进同一个 transformer,只在输入/输出 embedder 上 modality-specific,去噪计算共享(§3.3)。这让"想象约束动作、动作约束想象"在 attention 层面真实发生,是比一般 WAM 更彻底的耦合。
- CoT → dense \(z\) → cross-attention 条件:把语言推理的末端 hidden state 当作生成条件,而不是把 CoT 文本再 tokenize 喂回去。这让"任务逻辑/人类知识 steer 生成"有了一个可微接口,也是它相对纯 WAM(如 MotuBrain)的主要结构差异。
- 三 loss 同挂一个表示的论证清晰:text 让 \(z\) 语义化、video 让它可预测、action 让它可执行 —— "unification 在优化层面的定义"这个 framing 本身是干净且可证伪的(虽然支撑它的 ablation 被删了,见 5.2)。
- Fig. 5 的 grounding 退化观察:用 attention/grounding 可视化说明"标准 VLA 训练牺牲感知",给"联合训练"提供了一个直观且少见的动机证据,比纯口号有力。
- WorldArena 人类盲评的设计动机:明确指出自动指标会奖励"画面干净但跑题"的 rollout,并用 Task Success / Controllability / Temporal / Physical 四轴 0-2 盲评把"条件保真"和"任务完成"拆开 —— 这个评测哲学是对的,也确实抓到了 Happyhorse/EnerVerse 这类反例。
- single-checkpoint 三栖:同一权重在 VLM(64.7)、RoboTwin(93.5)、WorldArena(66.0) 同时不掉队,"unification 不必然牺牲专家能力"这个必要性命题确实被支持了。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 核心论点("闭环带来增益")的证据基本被删空。论文的真正卖点是"整体闭环 > 三专家之和",但支撑它的所有东西 —— 真机定量表(zero-shot 78.6% / compositional 75.0% / long-horizon 58.0%)、关键 ablation(去掉 video loss / 去掉 loop-closed data / 冻结 VLM 各掉多少)、三个 emergent 能力的具体数字 —— 在 LaTeX 源码里全部被注释掉。正文里 §7 讨论还在引用"our ablations 显示破坏闭环会掉 compositional",但读者根本看不到这些 ablation。如published 形态,三个专家榜只能证明"unification 不掉链子"(必要性),证明不了"闭环有正收益"(充分性)。
- "action-refine read" 名义存在、实际缺席。Contribution #2 和 Fig. 2 caption 都强调"action 读出前会 attend 回想象的视觉未来再 refine"(\(\tilde{h}_a = \text{Refine}_\psi(h_a, h_v)\))。但正文方法(§3.3)里 DiT 直接 \(h^a_L \to d_a\) 输出,refine 的公式恰恰在被注释掉的段落里。也就是说这个被当作亮点的机制,在最终模型描述里并不存在 —— 要么没做,要么没写清楚。
- 延迟/控制频率完全不谈,对闭环部署是致命缺口。系统每个控制步都要让一个 Wan2.2-5B 视频 DiT 去噪未来帧,这在真机控制频率下几乎必然太慢。原文里那张"五种 readout 模式(action-only 最便宜 / all-three 最贵)"的表本来是用来回应这个问题的,却被注释删了。全文没有一个延迟数字、去噪步数、控制 Hz。
- VLM 增益更像 domain fine-tune,不是 unification。Tab. 1 的提升集中在 embodied 子集(Where2Place/PhyX),通用子集基本不动。缺一个最该做的对照:Qwen3-VL 在同样机器人数据上只 fine-tune(不加 video/action 头) 能拿多少分?没有这个,无法把"unification 的功劳"从"在机器人数据上训过"里剥离出来。
- RoboTwin 不是 SOTA,且被无推理的 WAM 超过。MotuBrain(纯 WAM)95.9 明确 > 本文 93.5。如果"显式推理耦合"真有用,至少在这个控制 benchmark 上应该体现优势,但事实相反 —— 这对论文中心论点是反例,正文却未正面讨论。
- WorldArena 第一的稳健性存疑。EWM Score 领先第二仅 1.8 分,且几乎全靠 Motion Quality 与 3D Accuracy 两项;Physics Adherence、Content Consistency 偏弱。EWM Score 的加权方式不透明,榜上又多为匿名条目,"超越专用 world model"的说服力打折。
- 人类盲评在 Physical Plausibility 上输给 baseline。1.23 vs EnerVerse-AC 1.64。论文用"不动的模型不会违反物理"开脱,但这恰恰说明它生成的接触/重力一致性还不够好。
- \(z\) 的信息瓶颈无分析。把整条 CoT 的末端 hidden state 压成一个 dense 向量,要同时支撑像素级未来视频 + 精确动作,容量是否够?没有 \(z\) 维度的 ablation,也没有"\(z\) 里到底编码了什么"的探针实验。
- 真机一节存在 mis-reference。§6.2 "Zero Shot Generalization" 引用的是 WorldArena 人类盲评表(Tab. 4,那是仿真视频生成的人评),却当成真机 zero-shot 结论来写。要么是写作疏忽,要么真机本来就没有可报告的定量结果。
- Tienkung 人形机器人只有图、没有数。abstract 声称在 UR5e 与 Tienkung 上都有"significant improvements",但人形部分只有一张 seen/unseen timeline 图(Fig. 6 /
image_manipulation_sample_tiangun.pdf),无任何成功率。 - 可复现性为零。无 code/checkpoint,参数量/数据规模/训练配置全缺,作者署名是 placeholder。作为 "1.0" 技术报告可以理解,但当前无法独立验证任何 claim。
- action loss 用 SmoothL1 而非 L2 的 flow matching:把 robust regression 套在 velocity 上,与视频侧的 L2 flow matching 不完全同构。能 work,但"两模态共享同一去噪过程"的对称性叙事在 loss 层面其实有裂缝,论文没解释为什么动作要换成 SmoothL1。
5.3 值得继续探讨的方向¶
- 补上被删的 ablation 才是论文真正该有的样子:去 video loss / 去 loop-closed data / 冻结 VLM 三组,加上"VLM-only fine-tune"对照,才能把 unification 的边际贡献量化出来。
- 延迟拆解 + readout 模式:把那张被注释的"五模式表"做实,给出 action-only / reason-then-act / all-three 各自的延迟与成功率,回答"闭环能不能真机实时跑"。
- 为什么 MotuBrain 在 RoboTwin 上更强:纯 WAM 超过带推理的 unified,是推理 token 在仿真短任务上没用、还是 \(z\) 瓶颈拖累了控制精度?这个反例值得正面解剖。
- \(z\) 的容量与结构:扫 \(z\) 维度、做 probing,看它对视频质量 vs 动作精度的 trade-off 曲线;或改成多 token / 结构化 \(z\)。
- long-horizon 闭环的真实测试:被删掉的 long-horizon(120s 多步维修、occlusion 后 re-grounding、dream-rollout 预筛)才是闭环最有说服力的场景,应补真机闭环成功率而非离线指标。
- 动作扩散目标的统一:把 SmoothL1 换回 L2 flow matching、或反过来给视频也用 robust loss,验证"对称去噪"叙事。
- 公平的 VLM 对照与更大规模:Qwen3-VL-4B base、+robot-FT、+full-unified 三档,画出 unification 在理解能力上的净增益曲线。
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:GitHub: docs/2605.15153/source/
- 关键 backbone / baseline:
- Qwen3-VL-4B-Instruct — unified encoder/reasoner 初始化 + VLM baseline
- Wan2.2-5B — Unified Future Generator (DiT) 初始化
- MotuBrain — RoboTwin 第一名、WorldArena 第四名,纯 WAM,本文最强对手
- AIM / LingBot-VA / Fast-WAM / Motus — RoboTwin 上的 WAM/world-model 对手
- π₀ / π₀.₅ / OpenVLA / MolmoAct — VLA baseline
- EnerVerse-AC / Seedance2.0 / Cosmos-Predict2 — WorldArena 人类盲评对手
- Pelican-VL / Gemini Robotics-ER — embodied VLM 前序工作