ABot-M0:用 Action Manifold Learning 训练一个开源数据的通用 VLA Foundation Model¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
- 作者: AMAP CV Lab(阿里高德地图 CV 实验室)— Yandan Yang, Shuang Zeng, Tong Lin, Junjin Xiao, Xinyuan Chang, Feng Xiong, Mu Xu 等
- arXiv 编号: 2602.11236(submitted 2026-02-11)
- 关键词: VLA foundation model, action manifold learning, DiT, flow matching, cross-embodiment, open-source dataset, dual-arm, Qwen3-VL
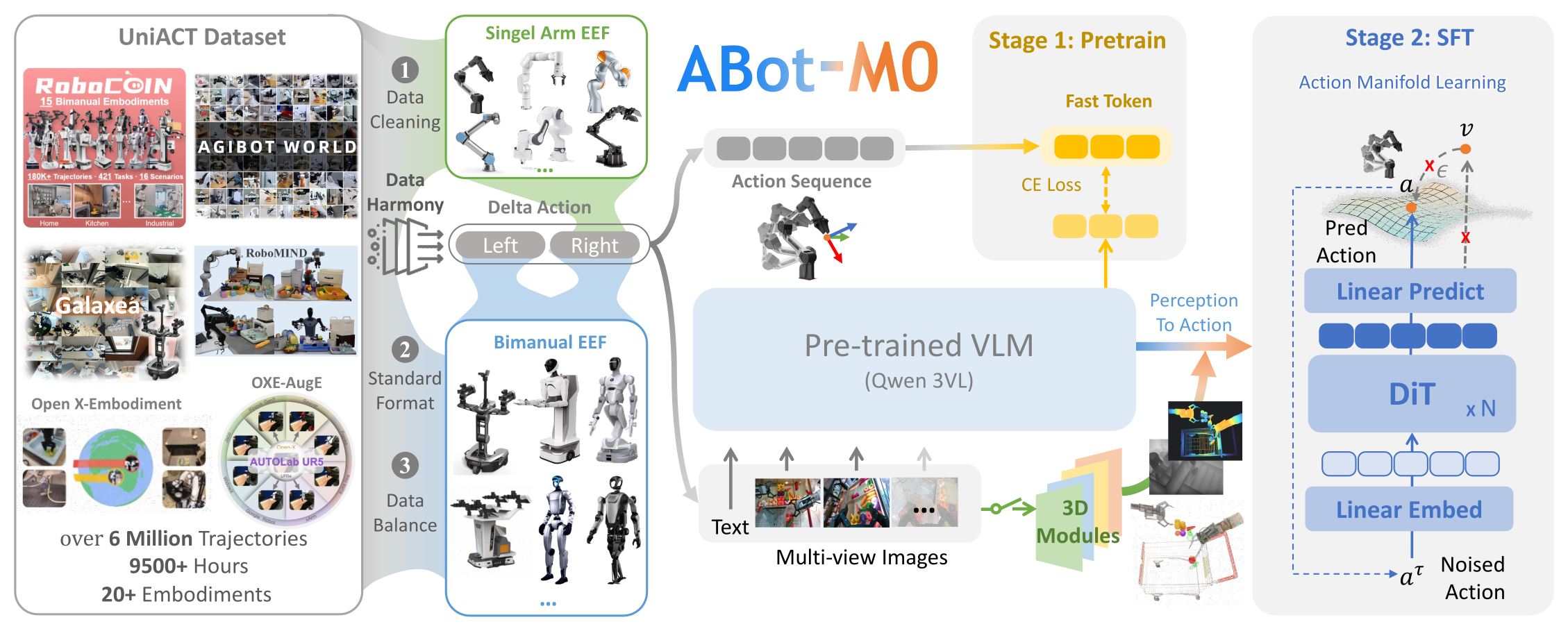 Figure 1:整体框架。左侧 UniACT-dataset 把六个开源数据集做清洗、动作格式统一、采样平衡后送入预训练;中间 Qwen3-VL backbone 输出文本特征供 Fast-Token CE-loss(Stage 1 预训练)与连续动作的 DiT action expert(Stage 2 SFT)双路使用;右侧的 3D module 是可插拔的几何特征注入入口,AML 是 DiT 内部直接预测干净动作而非噪声/速度的设计。
Figure 1:整体框架。左侧 UniACT-dataset 把六个开源数据集做清洗、动作格式统一、采样平衡后送入预训练;中间 Qwen3-VL backbone 输出文本特征供 Fast-Token CE-loss(Stage 1 预训练)与连续动作的 DiT action expert(Stage 2 SFT)双路使用;右侧的 3D module 是可插拔的几何特征注入入口,AML 是 DiT 内部直接预测干净动作而非噪声/速度的设计。
2. 文章介绍¶
2.1 解决的领域和问题¶
构建跨硬件、跨任务的通用机器人操作策略("one brain, many forms")。具体到本文,挑战拆成三个层面:
- 数据:高质量带 action label 的机器人轨迹采集昂贵,单一数据集规模/形态都不足以支撑 foundation model;
- 表示:跨数据集动作维度、坐标系、控制频率、采样率都不一致,模型把容量浪费在记忆 idiosyncrasies;
- 预训练范式:VLA 通常基于 VLM 初始化,但 VLM 的视觉 encoder 关注语义识别而非 3D 结构与物理动力学,CoT 等 reasoning-level 机制无法弥补底层感知缺陷。
2.2 Motivation¶
作者想回答一个工程问题:只用公开数据(不依赖私有大规模采集),系统化地做"数据清洗+架构改进+训练设计"的三者正交叠加,能否得到一个 SOTA-level 的通用 VLA?最大的赌注押在两个新东西上:
- UniACT-dataset:当前非私有领域最大的整理过的具身数据集合,6M+ 条轨迹、9500+ 小时、20+ 种 embodiment;
- Action Manifold Learning (AML):把 diffusion/flow-matching 的预测目标从噪声/速度改为直接预测干净 action chunk,论据是"有效的机器人动作天然落在低维流形上,预测噪声等于在高维空间大海捞针"。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 单数据集预训练 VLA | OpenVLA, \(\pi_0\), OpenVLA-OFT | 数据来自单一平台或少量 embodiment,cross-embodiment 泛化弱 |
| 多源 VLA 但无统一表示 | RT-2, RDT-2, GR00T 系列 | 动作格式异构、需要 dataset-specific head;私有数据不可复现 |
| Noise-prediction 训练范式 | GR00T, Octo, CogACT, Flower | \(\epsilon\)-pred / \(v\)-pred 目标在高维 off-manifold 空间,模型容量被去噪而非动作语义占用,动作维度上升时崩塌(实验上 action chunk 30 时 GR00T 掉 23.6 pt) |
| 离散动作 VLM 直输出 | \(\pi_0\)-Fast, OpenVLA discrete | 控制频率受限于自回归解码;连续控制精度差 |
| 仅用 VLM 特征 | VLA-Adapter 等 | 缺乏 metric-level 3D 感知,对相机视角扰动鲁棒性差(OpenVLA 在 LIBERO-Plus Camera subset 仅 0.8%) |
2.4 论文解决方案(一句话)¶
用统一格式的 6M 公开数据预训练一个 Qwen3-VL + 0.16B DiT 的双流架构 VLA,并把 DiT 的预测目标从噪声改成"投影到 action manifold 上的干净动作",再插拔式接入 VGGT / Qwen-Image-Edit 提供 3D 先验。
2.5 与前序工作的关系¶
- VLM backbone:直接复用 Qwen3-VL-4B,未做模型层修改;
- AML 的灵感:明示来自 JiT(Just-in-Time)compilation paper,把"预测目标在 manifold 上"的思想从 image generation 搬到 robot action;
- 3D 模块:复用 VGGT 与 Qwen-Image-Edit,未联合训练(plug-and-play);
- 训练框架:基于 StarVLA;
- 数据:吸纳 OXE / OXE-AugE / AgiBot-Beta / RoboCoin / RoboMind / Galaxea 六个公开集合。
3. 方法介绍¶
3.1 形式化¶
策略接收多视角 RGB(前视、腕部、俯视)和自然语言指令,输出长度为 \(H\) 的动作 chunk。每个时间步动作为:
其中 \(\mathbf{r} = \theta \mathbf{k}\) 是 axis-angle 形式的 3D 旋转向量(避免欧拉角奇点 / 四元数归一化)。双臂 stack 成 14 维;单臂数据按 pad-to-dual-arm 策略把另一臂位置补零,并统一视为右臂。
3.2 UniACT-dataset:数据清洗与统一¶
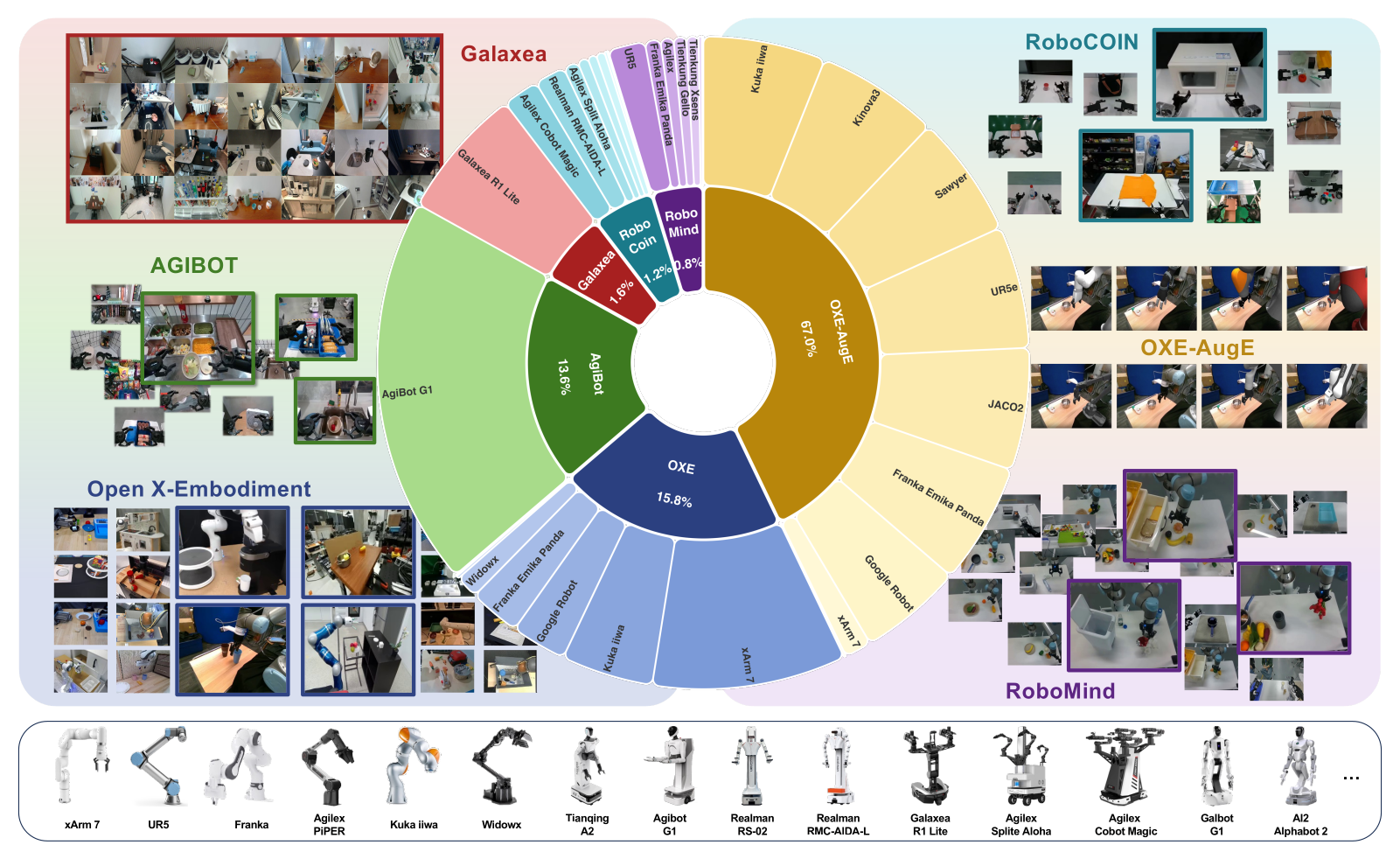 Figure 2:六大开源数据源在 UniACT-dataset 中的比例分布。中央饼图:OXE-AugE 67%、OXE 占次席、其余四个双臂数据共 17.2%;底部展示 20+ 种 embodiment 形态。注意单臂数据严重过采(≈83%),双臂只能靠重加权拉到合理曝光。
Figure 2:六大开源数据源在 UniACT-dataset 中的比例分布。中央饼图:OXE-AugE 67%、OXE 占次席、其余四个双臂数据共 17.2%;底部展示 20+ 种 embodiment 形态。注意单臂数据严重过采(≈83%),双臂只能靠重加权拉到合理曝光。
清洗 pipeline 处理四类问题:
| 问题类型 | 处理策略 |
|---|---|
| Invalid instructions | 删掉空指令、乱码序列;混合语言用 MT 归一化 |
| Frame-instruction misalignment | 重新计算时序对齐;从 episodes.jsonl 提取 action_text 注入帧级子任务指令 |
| Visual anomalies | 滤掉全黑/模糊/严重遮挡帧;移除无效相机视角(如 wrist cam 视野不覆盖操作区) |
| Abnormal actions | 滤掉异常长度轨迹、连续 delta 过大的 jitter 段、frame rate ↔ action update rate 严重不匹配的样本 |
| Ambiguous actions | 严格策略:旋转表示不明确(不知道是 axis-angle/Euler/quaternion)直接丢弃 |
最终丢弃约 16% 轨迹,剩下 6M+ 高置信度轨迹、9500+ 小时、20+ embodiment,统一为 LeRobot v2 格式 + delta EEF action。
3.3 模型架构:双流 VLM + Action Expert¶
- VLM:Qwen3-VL-4B(4B 参数)。多视角图像 stack 后与指令 tokenize 拼接,输出最后一层 hidden state 作为语义流。
- Action expert:0.16B 16-layer DiT,接 Linear Embed→DiT→Linear Predict 的结构(见 Figure 3b)。
- 3D 模块(可选):
- VGGT:单图前馈推 3D-aware feature;
- Qwen-Image-Edit:fine-tune 后从单视角合成额外 view(隐式多视角 3D),LIBERO + Bridge 各 50 对样本做轻量微调。
- 融合:3D feature 与 VLM 最后一层特征 cross-attention(VLM 当 query,3D 当 K/V)后输入 DiT。Concatenation / Q-Former 作为对比都被消融比下去。
3.4 Action Manifold Learning:核心创新¶
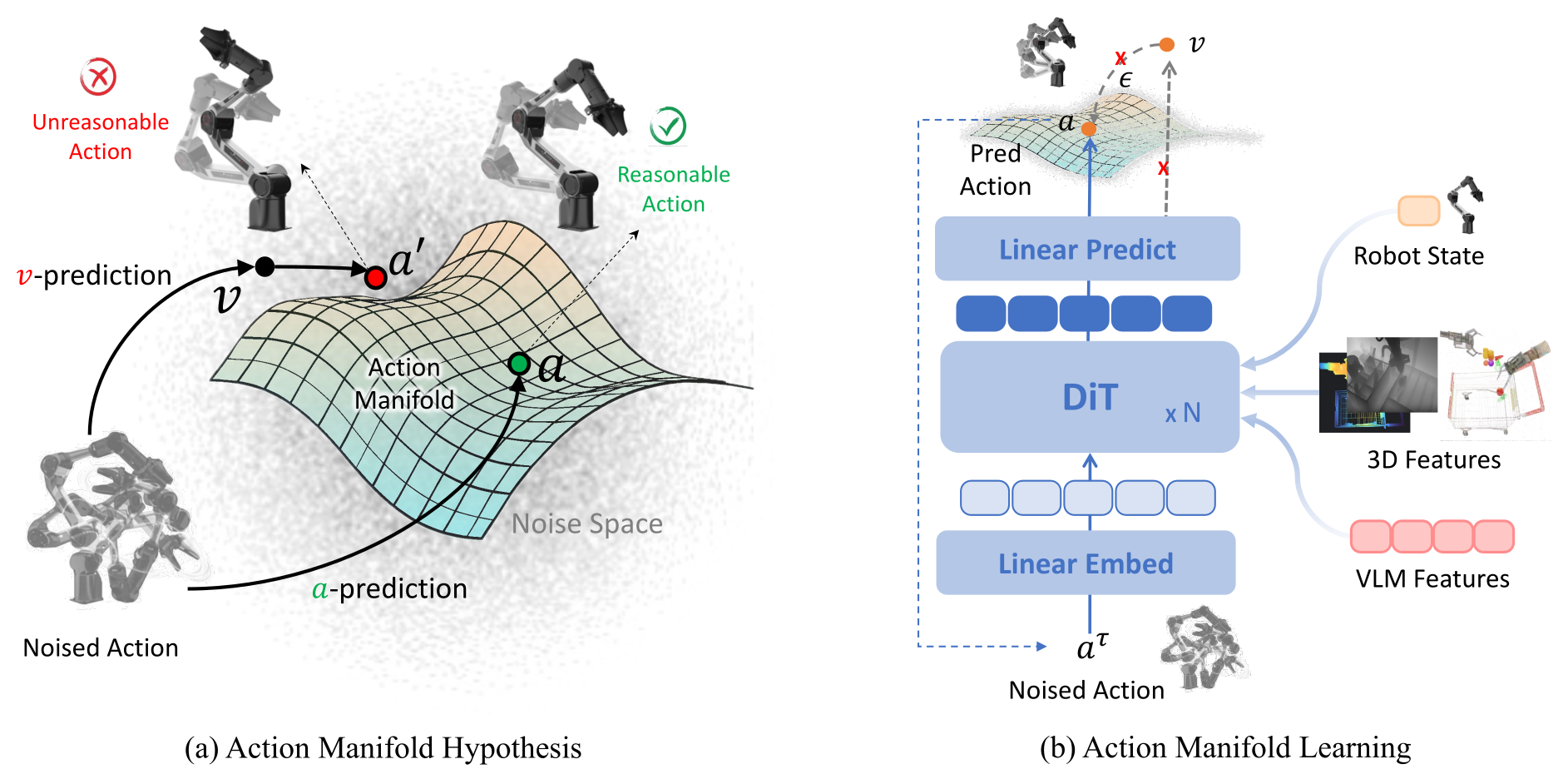 Figure 3:(a) 假说示意 — 有效动作(绿勾,绿点)落在嵌入高维空间中的低维 action manifold 上;ε-pred / v-pred 的预测目标在 manifold 之外的灰色噪声空间,预测错误一点点就跌出 manifold 形成 unreasonable action(红叉)。(b) AML 的 DiT 直接吃噪声动作 \(a^\tau\)、机器人状态、VLM/3D 条件,输出 \(\hat{A}_t\) 估计干净动作。
Figure 3:(a) 假说示意 — 有效动作(绿勾,绿点)落在嵌入高维空间中的低维 action manifold 上;ε-pred / v-pred 的预测目标在 manifold 之外的灰色噪声空间,预测错误一点点就跌出 manifold 形成 unreasonable action(红叉)。(b) AML 的 DiT 直接吃噪声动作 \(a^\tau\)、机器人状态、VLM/3D 条件,输出 \(\hat{A}_t\) 估计干净动作。
机制:仍用 flow matching 训练框架,但 DiT \(V_\theta\) 的输出从 velocity 改成估计的干净动作 chunk。给 ground-truth \(A_t\)、时间步 \(\tau \in [0,1]\)、标准高斯噪声 \(\epsilon\),加噪样本:
模型预测:
虽然预测目标是动作,loss 仍写在 velocity 上(作者实验和 JiT 都验证比 action-MSE 更稳):
权重 \(w(\tau)\) 来自 action→velocity 的雅可比,使 \(\tau \to 1\)(低噪声)时学习信号强 → 精细修正;\(\tau\) 小时弱信号 → 大幅去噪。
推理:依然走 ODE 路径,从 \(A^0_t \sim \mathcal{N}(0,I)\) 出发,每步先预测 \(\hat{A}_t\) 再算瞬时速度 \(\hat{v} = (\hat{A}_t - A^\tau_t)/(1-\tau)\),Euler 积分推进。默认 4 步去噪、action chunk = 16。
3.5 两阶段训练¶
Stage 1 — 大规模预训练:UniACT-dataset 全量,附带 fast-token CE-loss 离散动作头作为辅助监督(保留 gradient flow)。Task-Uniform 采样(按任务粒度均匀),单臂数据固定占 50% 采样预算,双臂按任务/构型双层重加权。
Stage 2 — Space-aware SFT:在 LIBERO/RoboCasa/RoboTwin 等下游集合上 joint fine-tune VLM + action expert,使用小学习率、dropout、动作噪声扰动。3D module 在此阶段插入。
3.x Implementation Details¶
| 项目 | 数值 |
|---|---|
| VLM backbone | Qwen3-VL-4B |
| Action expert | 0.16B DiT(16 层) |
| 3D module | VGGT(单图)/ Qwen-Image-Edit(多视图合成) |
| 输入图像分辨率 | 224 × 224 |
| Action 维度 | 单臂 7、双臂 14、RoboCasa GR1 全身 29 |
| Action chunk size | 16(默认) |
| 去噪步数 | 4(默认) |
| 预训练 lr | 1e-5 |
| Batch size | 1024 |
| 预训练 step 数 | 100K |
| 训练框架 | StarVLA |
| 数据规模 | 6M+ trajectories / 9500+ hours / 20+ embodiments |
4. 结果对比¶
4.1 LIBERO(fine-tuned,SR%)¶
| Method | L-Spatial | L-Object | L-Goal | L-Long | Average |
|---|---|---|---|---|---|
| Diffusion Policy | 78.5 | 87.5 | 73.5 | 64.8 | 76.1 |
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| \(\pi_0\) | 98.0 | 96.8 | 94.4 | 88.4 | 94.4 |
| GR00T-N1.6 | 97.7 | 98.5 | 97.5 | 94.4 | 97.0 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| \(\pi_{0.5}\) | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| X-VLA | 98.2 | 98.6 | 97.8 | 97.6 | 98.1 |
| ABot-M0 (Ours) | 98.8 | 99.8 | 99.0 | 96.6 | 98.6 |
4.2 LIBERO-Plus(zero-shot,SR%)¶
只用标准 LIBERO 训练,在 7 种扰动子集上测:
| Method | Camera | Robot | Lang | Light | BG | Noise | Layout | Total |
|---|---|---|---|---|---|---|---|---|
| OpenVLA | 0.8 | 3.5 | 23.0 | 8.1 | 34.8 | 15.2 | 28.5 | 15.6 |
| \(\pi_0\) | 13.8 | 6.0 | 58.8 | 85.0 | 81.4 | 79.0 | 68.9 | 53.6 |
| \(\pi_0\)-Fast | 65.1 | 21.6 | 61.0 | 73.2 | 73.2 | 74.4 | 68.8 | 61.6 |
| OpenVLA-OFT | 56.4 | 31.9 | 79.5 | 88.7 | 93.3 | 75.8 | 74.2 | 69.6 |
| RIPT-VLA | 55.2 | 31.2 | 77.6 | 88.4 | 91.6 | 73.5 | 74.2 | 68.4 |
| ABot-M0 (Ours) | 60.4 | 67.9 | 86.4 | 96.2 | 91.6 | 86.4 | 82.6 | 80.5 |
Robot 扰动子集 +36 pt 是最显眼的提升,作者归因于 cross-embodiment 预训练。
4.3 RoboCasa GR1 Tabletop(29-DoF 全身,SR% 平均)¶
| Method | Average SR |
|---|---|
| GR00T-N1.6 | 47.6 |
| Qwen3-GR00T (从同基座) | 47.8 |
| Qwen3-\(\pi\) | 43.9 |
| Qwen3-OFT | 48.8 |
| Qwen3-FAST | 39.0 |
| ABot-M0 (Ours) | 58.3 |
29 维 high-DoF 是 AML 真正发挥的场景:相比同 backbone 的 noise-prediction 版本(Qwen3-GR00T)高 10.5 pt。
4.4 RoboTwin 2.0(50+ 任务多任务训练)¶
| Method | Clean | Random. |
|---|---|---|
| \(\pi_{0.5}\) | 42.98 | 43.84 |
| X-VLA | 72.80 | 72.84 |
| ABot-M0 (Ours) | 86.06 | 85.08 |
Random. 列是引入背景/桌面杂物/桌高/光照扰动后的版本,掉点只有 1 pt,泛化稳定。
4.5 关键消融 — AML vs Noise-prediction(LIBERO-Plus Total,SR%)¶
| Setting | Qwen3-VL-GR00T (noise) | ABot-M0 (AML) | Δ |
|---|---|---|---|
| Chunk 8, Steps 4 | 69.3 | 71.0 | +1.7 |
| Chunk 8, Steps 2 | 67.2 | 69.7 | +2.5 |
| Chunk 8, Steps 10 | 68.6 | 70.2 | +1.6 |
| Chunk 10, Steps 4 | 69.3 | 72.4 | +3.1 |
| Chunk 30, Steps 4 | 45.7 (−23.6) | 62.8 (−8.2) | +17.1 |
最重要的对比是最后一行:把 action chunk 从 8 拉到 30(更长 horizon、动作序列维度更高),baseline 直接崩 23.6 pt,AML 只掉 8.2 pt。这是 "Action Manifold Hypothesis" 最直接的证据。
4.6 关键消融 — VLM 特征选层¶
| Layers | Feature | Query | LIBERO-Plus Total |
|---|---|---|---|
| Last | ✓ | – | 71.0 |
| Last | – | ✓ | 70.0 |
| Intermediate | ✓ | – | 69.0 |
| Last 16 | ✓ | – | 67.4 |
| Last 16 | ✓ | ✓ | 63.8 |
结论:经过机器人数据预训练的 Qwen3-VL,最后一层 hidden state 已经把动作语义内化了 → 直接取最后一层、不要额外 action query、不需要聚合多层。
4.7 关键消融 — 3D 模块(LIBERO-Plus Total)¶
| Method | Camera | Total |
|---|---|---|
| Baseline | 32.9 | 66.4 |
| VGGT (cross-attn) | 45.8 | 71.1 |
| VGGT (concat) | 41.2 | 68.9 |
| VGGT (Q-Former) | 44.3 | 69.6 |
| Qwen-Image-Edit (1 view) | 38.5 | 68.0 |
| Qwen-Image-Edit (2 views) | 46.7 | 70.2 |
Camera 扰动子集是 3D 信息最直接相关的,cross-attention 形式的 VGGT 注入 +12.9 pt,再加 2 view 合成 +13.8 pt。
4.8 关键消融 — 采样策略(Libero Plus,SFT 后)¶
| Strategy | SR% |
|---|---|
| Trajectory-Uniform | 71.3 |
| Embodiment-Uniform | 71.6 |
| Task-Uniform | 72.4 |
Task-Uniform 在 Lorenz 曲线、Gini 系数、Coverage@T 三个指标上均胜出。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- AML 的高 chunk-size 鲁棒性是真正的卖点。Action Chunk 30 时 noise-pred baseline 掉 23.6 pt 但 AML 只掉 8.2 pt(§4.5),这个对比在论文里被放在很显眼的位置且重复了三遍,是 "Action Manifold Hypothesis" 唯一一个真正可量化的证据。这暗示了"未来 long-horizon + dexterous + 全身控制"场景下 AML 的扩展曲线会更平。
- 数据清洗 pipeline 写得非常细。指令乱码 / 帧错位 / 视觉异常 / 动作 jitter / 旋转表示模糊这五类问题各自配处理策略(§3.2 表)— 这是把多源公开数据真正"工程化"到能 pretrain 的程度的关键,比纯模型创新更稀缺。
- Pad-to-dual-arm + 统一 EEF delta + axis-angle rotation 的表示选择是经过推敲的。Delta 比 absolute 容易学;EEF 比 joint 跨 embodiment 更通用;axis-angle 避开 Euler 奇点和 quaternion 归一化(§3.1)— 三个细节叠加才换来 cross-embodiment 的零样本能力(LIBERO-Plus Robot 子集 +36 pt vs OFT)。
- Velocity-loss + action-prediction 这个 "decoupling" 设计很狡猾。虽然 DiT 输出动作,loss 仍套在 velocity 上(\(w(\tau) = 1/(1-\tau)^2\) 权重),既享受了 flow matching 在不同噪声 level 的动态学习信号强度,又把模型负担转到 manifold projection 上。这一手作者说是借鉴 JiT,但在 robot policy 上推广是新工作。
- Task-Uniform 采样的论证完整(§4.8 + Figure 在 sec4_pretraining)。从 Lorenz / Gini / Coverage@T 三个角度论证,并在 cross-embodiment、cross-dataset、downstream Libero-Plus 三个评估维度上验证一致性,比"我们随便选一个最好的"扎实得多。
- VLM 特征只用最后一层这个结论很反直觉但说服力强。预训练后 VLM 各层已经"职能分化"了(intermediate 表征多模态、deep 层接近 action semantics),所以 action query / 多层聚合都是冗余甚至有害(§4.6)— 这个发现实用价值高,能为 follow-up 工作省掉一堆架构设计代价。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "Action Manifold" 始终是一个 hypothesis,没有任何直接证据。作者从未试图可视化或量化"动作流形"的维度、曲率、连通性,全部论据是间接的:"chunk 30 时 baseline 掉得更厉害 → 所以动作在低维流形上"。但同样的结果也可能由其他原因解释:noise prediction 在 chunk 30 时数值放大、训练目标和推理目标差距更大、reweighting \(w(\tau)\) 在长 chunk 上方差更大等。一个真正的 hypothesis 验证应该展示 latent space 的内在维度估计、或在 action manifold 上做插值的可视化。
- AML 在 chunk 8、step 4 默认配置下只比 noise-pred 高 1.7 pt(§4.5)。论文的核心 selling point 在最常用的配置上几乎打平,作者用 "extreme cases" 论证优越性 — 但 chunk 30 是不是产业里真实需要的设定?大多数操作任务 chunk 16 已经够长。这把 AML 的实际意义打了折扣。
- 跟同期 SOTA 的对比口径不完全公平。LIBERO 表中 X-VLA 拿到 98.1 / L-Long 97.6,ABot-M0 是 98.6 / L-Long 96.6 — 平均略胜但 L-Long(最难的子集)反而输了 1 pt。RoboCasa 表面上 SOTA 58.3% > GR00T-N1.6 47.6%,但 24 个任务里 ABot-M0 在第一名的只有 12 个,其他 12 个被对手胜出;这种 setting-specific tuning 嫌疑没解释清楚。
- 3D 模块根本没有联合训练。VGGT 和 Qwen-Image-Edit 都是冷接到 cross-attention 后面(论文的 Limitations 也承认了,但被搬到注释里)— 这意味着 3D feature 的语义和 VLM hidden state 不在同一表示空间,cross-attention 是在做"feature alignment as side-effect"。一个公允的做法应该 joint fine-tune,或者至少做 representation alignment loss。
- Qwen-Image-Edit "合成 2 个新视角" 的设定可疑。合成视图本质是把 Qwen-Image-Edit 的 generative prior 走了一遍,相当于隐式调用一个 8B+ 参数的模型 — 这部分的计算 / 时延成本在 §4.7 完全没披露。"两步推理" 听起来轻量,但 8B 模型每步合成的延迟可能比整个 ABot-M0 还慢。这一招更像 "把额外算力洗成 3D 感知改进"。
- Stage 2 SFT 部分的方法描述薄弱。§3.5 里只有一段:"we fine-tune both with a small learning rate, dropout, and action noise perturbation",但具体 lr、dropout rate、噪声 magnitude 都没给。同时 RoboCasa / RoboTwin 用的 SFT 是 task-specific 还是 multi-task?数据量呢?这些都直接影响结果可复现性。
- 缺乏真实机器人实验。所有 benchmark(LIBERO、LIBERO-Plus、RoboCasa、RoboTwin)都是模拟环境。一个声称 "general-purpose embodied intelligence" 的工作,最重要的 sim-to-real gap 完全没碰。考虑到 UniACT-dataset 里 OXE-AugE 本身是 synthetic(67% 占比),这意味着模型其实长时间训练在"合成 → 模拟"的双层 sim 信号上。
- Pad-to-dual-arm 看似优雅但有副作用。所有单臂数据被强制视为右臂、动作输出永远 14 维,这意味着每次推理浪费一半计算在零 padding 上。对于单臂 deployment 是显著浪费;同时 single-arm 数据占 OXE+OXE-AugE 约 83%,意味着大部分预训练在做 "永远预测左臂为零" 的近-trivial 任务。
- Action manifold 假说与 noise prediction 的兼容性论述不充分。如果动作真的在低维流形上,那 noise prediction 路径上的所有"中间状态"也应该被流形约束 — 而不是像 §3.4 的 Figure 3a 那样把 \(\epsilon\)-pred / \(v\)-pred 直接画到 noise space 外面去。实际上从 ODE 解的角度看,动作 manifold 与 velocity field 是 dual 的关系(梯度场),作者的论证有 strawman 的嫌疑。
- 6M trajectories 的有效 token / 有效信息量没给。9500 小时听起来吓人,但很多 OXE 子集 5 FPS、动作非常重复(pick/place 占 60%+ 任务类别)。和 RT-2 的 13M 多模态 + Web 数据比,UniACT 的"等效信息密度"可能差一个数量级。论文一直强调"开源数据 SOTA"但没正面回应这个问题。
5.3 值得继续探讨的方向¶
- 真正的 manifold 可视化 / 验证:用 PCA / UMAP / probing classifier 在 action chunk space 上估计内在维度,或者在 manifold 上做 trajectory interpolation 的失败案例分析。这才是验证 Action Manifold Hypothesis 的正确方式。
- AML 与 RL fine-tune 的兼容性:RL 的 policy gradient 在 manifold projection 输出上是否自然?如果动作只能落在 manifold 上,exploration 怎么做?是不是天然适合 latent-action policy?
- 3D module 的 joint training:作者承认 limitations 但没尝试。可以在 SFT 阶段对 VGGT 做小幅 LoRA fine-tune,或加 contrastive alignment loss。
- 取代 Qwen-Image-Edit 的合成视图:换 NVS(如 Cat3D、Free3D)做单步合成,对比延迟/质量 trade-off。Qwen-Image-Edit 8B+ 的成本被刻意藏起来很可疑。
- 跨控制频率的 manifold 学习:UniACT 里 5 FPS - 30 FPS 数据并存,AML 是不是隐式在 down-sample?显式建模 control frequency adaptation 应该能再涨点。
- AML 在 force/tactile 多模态扩展上的表现:当前只有 RGB+proprioception。加入 force-torque 后 manifold 维度会膨胀,AML 的优势是放大还是缩小?
- Long-horizon planning 与 AML 的结合:能否把"动作 chunk 30 时 AML 才显著优于 baseline"的优势用在 hierarchical policy 上 — high-level planner 输出 subgoal,low-level AML 做 100+ step chunk?
- Embodiment-agnostic 真实测试:找几个 UniACT 没见过的 platform(例如 unitree H1、Galaxea G1-new generation)做 zero-shot 实机测试,才是 "one brain many forms" 的真考验。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- Code: github.com/amap-cvlab/ABot-Manipulation
- Project Page: amap-cvlab.github.io/ABot-Manipulation
- 关键 baseline / 相关论文:
- JiT (Just-in-Time):AML 的灵感来源
- \(\pi_0\) / \(\pi_{0.5}\):主要 VLA baseline
- GR00T-N1 / N1.6:noise prediction 对照
- OpenVLA / OpenVLA-OFT:单源 baseline
- VGGT、Qwen-Image-Edit:3D 模块复用
- OXE / OXE-AugE / AgiBot-Beta / RoboCoin / RoboMind / Galaxea:UniACT 来源