DeFI: Disentangled Robot Learning via Separate Forward and Inverse Dynamics Pretraining¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Disentangled Robot Learning via Separate Forward and Inverse Dynamics Pretraining
- 作者: Wenyao Zhang¹³*, Bozhou Zhang²⁴*, Zekun Qi⁵, Wenjun Zeng³, Xin Jin³‡, Li Zhang²⁴‡(*equal contribution, ‡corresponding;¹上海交大 ²复旦 ³宁波东方理工 EIT ⁴上海创智学院 ⁵清华)
- arXiv 编号: 2604.16391(2026-04 提交,ICLR 2026 投稿格式)
- 代码 / 模型: GitHub: LogosRoboticsGroup/DeFi · HuggingFace: zbzzbz/DeFI
- 关键词: VLA, forward dynamics, inverse dynamics, video diffusion (SVD), latent action, VQ-VAE, action-free human video, decoupled pretraining, CALVIN, SimplerEnv
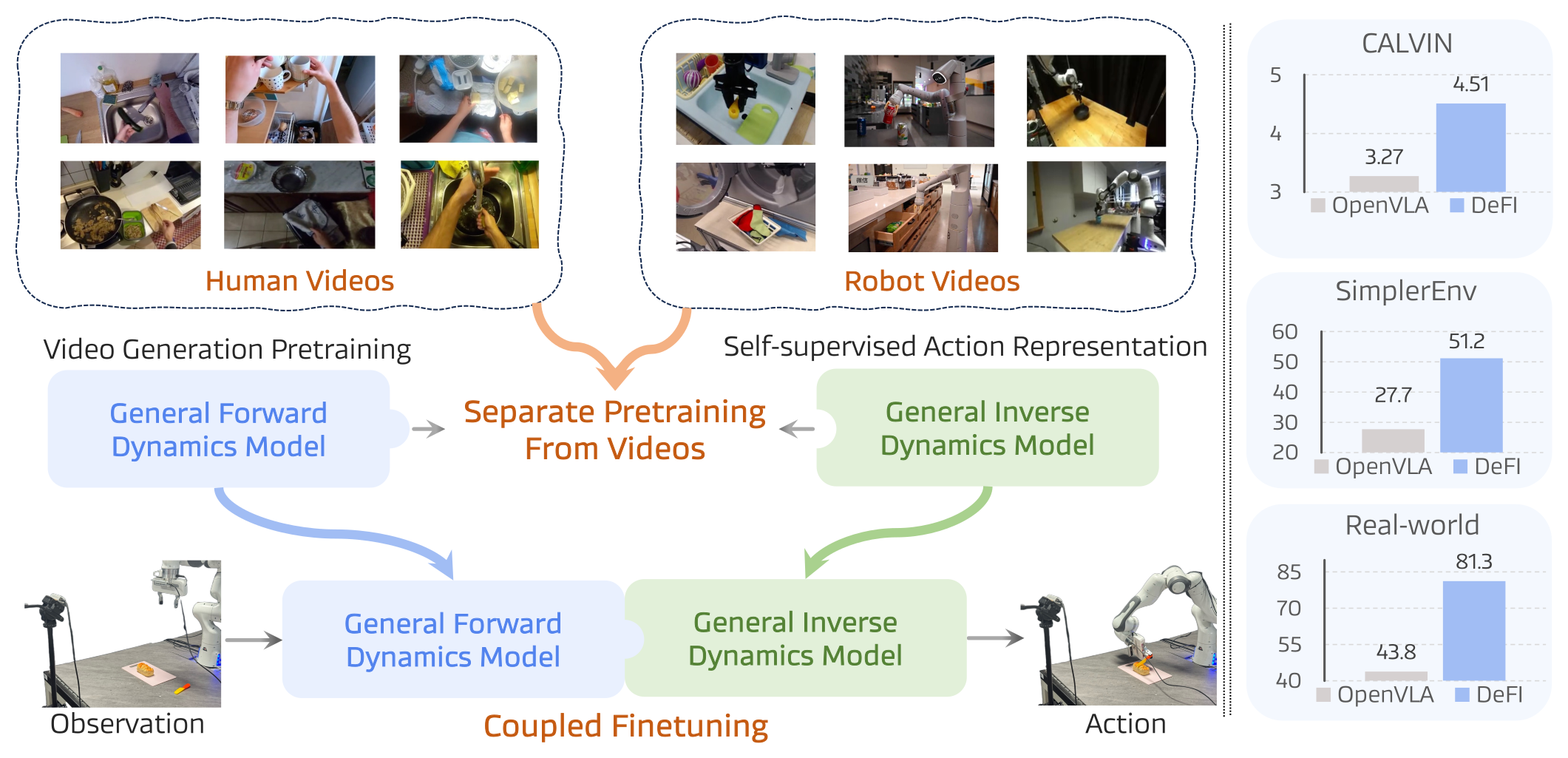 Figure 1:核心范式 — human videos + robot videos 先「分开」预训练 GFDM(视频生成)与 GIDM(自监督 latent action),再在下游「耦合」端到端微调。右侧三个柱状图是相对 OpenVLA 的提升:CALVIN 4.51 / SimplerEnv 51.2% / Real-world 81.3%。
Figure 1:核心范式 — human videos + robot videos 先「分开」预训练 GFDM(视频生成)与 GIDM(自监督 latent action),再在下游「耦合」端到端微调。右侧三个柱状图是相对 OpenVLA 的提升:CALVIN 4.51 / SimplerEnv 51.2% / Real-world 81.3%。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 vision-language-action (VLA) / 机器人操作策略学习 子领域。具体针对当前主流 VLA 的一个内在矛盾:把 2D 视觉预测(forward dynamics) 和 3D 动作预测(inverse dynamics) 缠绕在同一个端到端框架里训练时,二者目标互相竞争(competing objectives)导致训练不稳;更要命的是,这种 vision-action 耦合的训练方式让模型无法吃下海量 action-free 的人类 / 网络视频——因为这些视频根本没有动作标签。论文要回答的是:怎样既享受端到端的好处,又能分别用最合适的数据规模化地学好 forward 和 inverse 两套动力学知识?
2.2 Motivation¶
作者的核心论点有两条:
- 人类视频对 scaling VLA 是必需的:它们比机器人 demo 大几个数量级、覆盖跨 embodiment / 跨任务的丰富 motion prior,但因为没有动作标签,被现有耦合式 VLA 浪费掉了。
- inverse dynamics 和 forward dynamics 一样重要,但长期被轻视。作者直接点名两条「video-as-policy」路线的代表:VPP 干脆没有 inverse dynamics 模块;Vidar 虽然有 IDM 但「contemptuously」对待它,没有可扩展的预训练 recipe——它的性能主要来自一个强大的视频生成器(Vidu),而非有原则的 action reasoning。结果就是 IDM 成了瓶颈,吃不下 forward model 的预测能力。
所以解法的角度是:先分离、后耦合(first separate, then cooperate)。让两个模块各自用最适合的数据源和目标函数预训练到位,再在下游耦合做端到端微调。
2.3 之前工作的问题¶
论文把「用视频做机器人学习」归纳为四条路线,并指出各自缺陷:
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 耦合式 forward+inverse 端到端 VLA | Seer, CoT-VLA, DreamVLA, UP-VLA | 2D 预测与 3D 动作目标竞争 → 训练不稳;vision-action 缠绕 → 无法吃 action-free 人类视频 |
| 显式人手 / motion 标签迁移 | EgoMimic, H-RDT 等 | 标签干净但昂贵、难规模化,对 embodiment / 相机变化脆弱 |
| 从人类视频抽 latent action 来预训练大 VLA | LAPA, Moto, GR00T, UniVLA | 路线间接:latent 必须喂给庞大且昂贵的 policy 去预训练 / 微调,且学到的 code 不保证对齐可执行的 action manifold |
| video-as-policy(预测未来再追踪) | VPP, Vidar, SuSIE, CLOVER, Track2Act | 利用了 action-free 视频学 forward dynamics,但遗留 prediction-to-control 鸿沟——IDM 弱(VPP 无 IDM、Vidar IDM 不 scalable)成为瓶颈 |
2.4 论文解决方案(一句话)¶
把 robot learning 解耦成两个独立预训练的知识模块——一个在混合人类+机器人视频上用 video generation 学 forward dynamics 的 GFDM,一个在 action-free 视频上用自监督代理任务学 latent action 的 GIDM——再用一个轻量 diffusion adapter 把二者耦合起来端到端微调成完整 policy。
2.5 与前序工作的关系¶
- VPP (Video Prediction Policy, Hu et al. 2024):最直接的前序。DeFI 沿用了 VPP 的「single-step denoising 的视频生成特征已足够指导动作」洞见,也复用了 VPP 的 video former 抽 GFDM 中间层特征。区别:VPP 没有 IDM,DeFI 把可规模化的 GIDM 当成一等公民。数据效率实验里 DeFI 全程对标 VPP。
- LAPA (Ye et al. 2024):GIDM 的训练目标直接「Following LAPA」,用 VQ-VAE 把 latent action 量化成离散 token。
- UniVLA (Bu et al. 2025):GIDM 在 DINO 特征空间训练「following prior work」即指 UniVLA;同时 UniVLA 也是 CALVIN 上的对照(把 latent action 当伪标签预训练 VLA),DeFI 论证「解耦预训练 > 单纯抽 latent action 当伪标签」。
- 现成组件复用:GFDM backbone = 开源 Stable Video Diffusion (SVD) + CLIP 文本;GIDM 视觉编码 = DINOv2,文本 = T5;action adapter = 30M DiT-B。
- 数据:GFDM 训练于 Fractal/Bridge/CALVIN-ABC(robot)+ Something-Something-v2/Ego4D(human);GIDM 训练于 OXE 单臂子集 + Ego4D。评估在 CALVIN ABC-D、SimplerEnv-Fractal、真机 Franka。
3. 方法介绍¶
整体两阶段:Stage I 解耦预训练(GFDM 与 GIDM 各练各的)→ Stage II 耦合微调(冻结 GFDM,训 GIDM + adapter)。
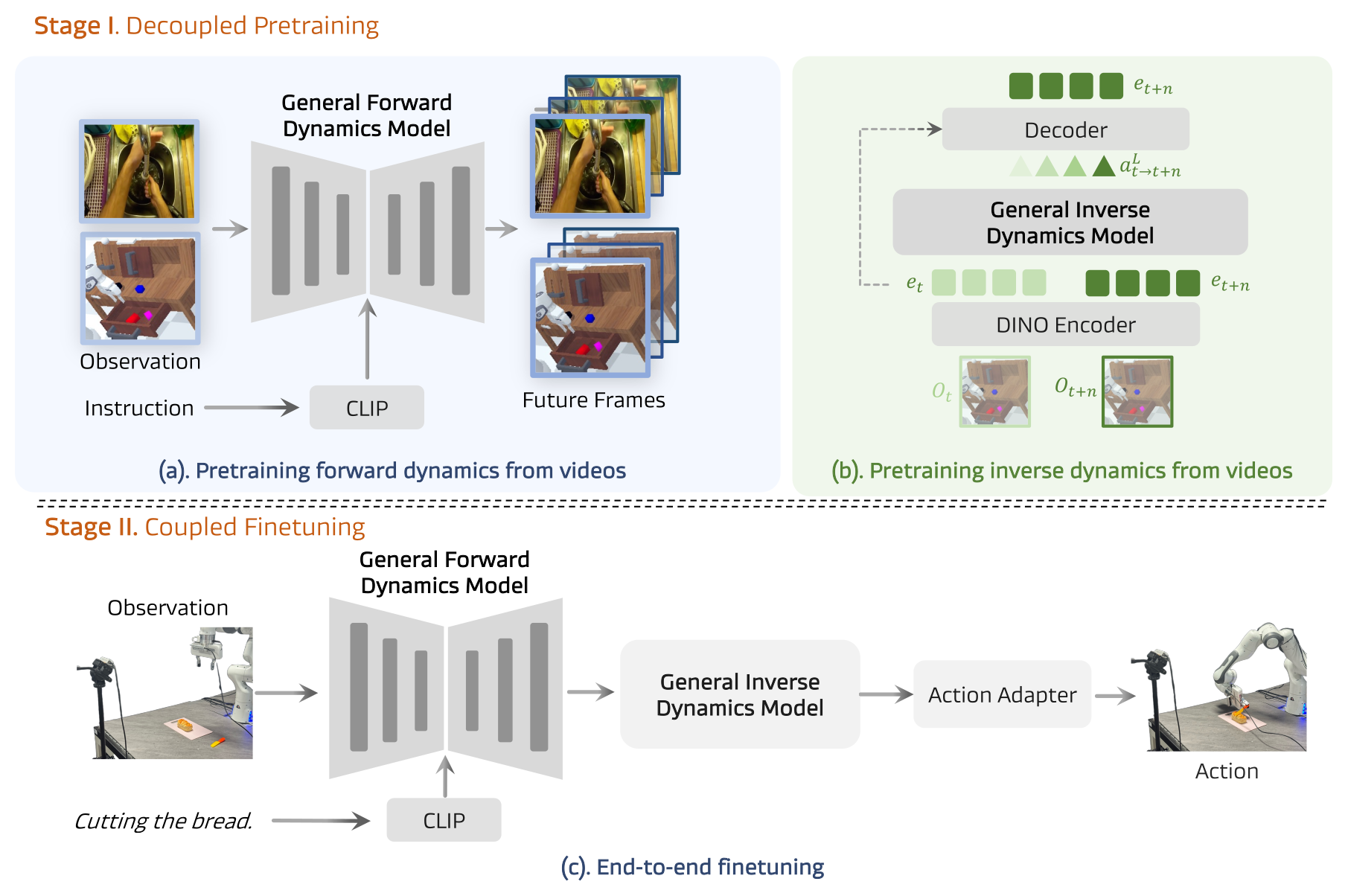 Figure 2:(a) GFDM 用 video generation 目标在人+机器人视频上学 forward dynamics;(b) GIDM 自监督地把 \((o_t, o_{t+n})\) 映射成 latent action(DINO 编码 → 时空 Transformer + VQ-VAE → Decoder 重建未来 DINO 特征);(c) 下游冻结 GFDM,把 future 特征经 MLP 投到 GIDM 输入空间,GIDM 推 latent action,diffusion adapter 解码成可执行动作。
Figure 2:(a) GFDM 用 video generation 目标在人+机器人视频上学 forward dynamics;(b) GIDM 自监督地把 \((o_t, o_{t+n})\) 映射成 latent action(DINO 编码 → 时空 Transformer + VQ-VAE → Decoder 重建未来 DINO 特征);(c) 下游冻结 GFDM,把 future 特征经 MLP 投到 GIDM 输入空间,GIDM 推 latent action,diffusion adapter 解码成可执行动作。
3.1 形式化¶
给定当前观察 \(o_t\) 和指令 \(l\):
- GFDM \(\mathcal{F}_\theta\) 合成长度 \(H{+}1\) 的短视频 \(\hat{o}_{t:t+H}\)(实际 \(H{=}16\) 帧)。
- GIDM \(\mathcal{I}_\theta\) 从一对相隔 \(n\) 帧(约 1 秒)的观察推出 latent action \(\hat{a}^L_{t\to t+n}\)。
- Action adapter 把 latent action 解码成 7-DoF 可执行机器人指令。
3.2 GFDM:用 video generation 学 forward dynamics¶
基座是 SVD,三件套:(i) video VAE \((\mathcal{E}, \mathcal{D})\) 定义 latent 空间;(ii) 去噪器 \(\epsilon_\theta\)(带 temporal attention 的 U-Net)。latent-diffusion 加噪过程:
条件 \(c_t = (z_t, f_{\text{text}}(l))\),\(z_t = \mathcal{E}(o_t)\)。训练用 noise-prediction loss:
关键工程点 — 单步去噪:完整去噪整段视频太贵,且大部分算力浪费在跟操控无关的像素细节上;控制真正需要的是 motion 而非 appearance。沿用 VPP / unified 的发现「生成模型单步去噪后的特征已含足够 motion 信息」,DeFI 冻结 GFDM 并把去噪限制为单步,直接产出未来 latent embedding。多相机(第三视角 + wrist)时各视角独立预测。
3.3 GIDM:自监督学 inverse dynamics(latent action)¶
这是论文最强调的「被低估的另一半」。流程(对应 Algorithm 1):
- 取相隔 \(n\) 帧的 \((o_t, o_{t+n})\),用 DINOv2 抽特征 \(e_t, e_{t+n}\)(跨数据集统一约 1 秒间隔)。
- 一组可学习 action query \(q_a \in \mathbb{R}^{N\times d}\) 与 \(e_t, e_{t+n}\)、T5 指令 embedding 沿序列维拼接,喂进带 causal temporal mask 的时空 Transformer encoder: $\(\tilde{a}^{L}_{t\to t+n} = \mathcal{I}_\theta(e_t, e_{t+n}, l, q_a)\)$
- VQ-VAE 量化到离散 codebook(vocab \(|C|{=}128\)):\(\hat{a}^{L}_{t\to t+n} = \mathcal{VQ}_\theta(\tilde{a}^{L}_{t\to t+n})\)。这一步既是离散化、又是 information bottleneck:阻止未来状态直接「泄漏」进 decoder,逼模型学有意义的 action 表征而非低级视觉捷径。
- 量化后的 latent action 经一个 Spatial-Transformer decoder 重建未来帧的 DINO 特征 \(\hat{e}_{t+n}\),目标是 MSE:\(\mathcal{L} = \mathcal{L}_{\text{pred}} + \mathcal{L}_{\text{VQ}}\)。
整套是完全无监督的——预训练时即使机器人数据带动作 / proprioception 也故意丢弃,只用帧 + 文本,从而能把 Ego4D 这类 action-free 人类视频纳进来。
3.4 Stage II:耦合微调¶
- 冻结 GFDM。理由:它已在覆盖下游域的大规模数据上预训练,再在小的下游 split 上微调反而会侵蚀 dynamics prior、损害泛化。冻结的 GFDM 当作稳定 backbone,提供时序一致的未来视频表征。
- 一个轻量 MLP 把 GFDM 的 future embedding 投到 GIDM 的输入流形,保证表征兼容。
- 同时用 VPP 的 video former 抽 GFDM 中间层特征;与 MLP 投影特征融合后,喂给 diffusion-based action adapter(DiT-B, 30M) 翻译成可执行指令。
- 微调阶段联合对齐三个目标:future prediction、action inversion、low-level control。
3.5 Implementation Details¶
| 项 | 值 |
|---|---|
| 硬件 | 8× NVIDIA H100 |
| GFDM 预训练 | 3 天 |
| GIDM 预训练 | 1.5 天 |
| CALVIN 微调 | 0.5 天;训练显存 64G,推理显存 7G |
| batch / lr / wd / opt | 32 / 1e-4 / 1e-2 / AdamW;预训练 20 epoch、微调 12 epoch |
| GFDM | SVD,256×256,预测 16 帧未来 |
| GIDM | Transformer,feature dim 768,16 层,VQ codebook 128 |
| Action adapter | DiT,feature dim 384,12 层,10 sampling steps,action dim 7 |
| 推理延迟(RTX 4090,5 次平均) | GFDM 86.1ms + GIDM 42.9ms + Adapter 24.3ms ≈ 153ms(约 6.5Hz) |
4. 结果对比¶
4.1 CALVIN ABC-D(训练 ABC,测试未见环境 D;Avg. Len = 连续完成 5 任务的平均长度)¶
| View | Method | 1 | 2 | 3 | 4 | 5 | Avg. Len ↑ |
|---|---|---|---|---|---|---|---|
| Third | SuSIE | 87.0 | 69.0 | 49.0 | 38.0 | 26.0 | 2.69 |
| Third | CLOVER | 96.0 | 83.5 | 70.8 | 57.5 | 45.4 | 3.53 |
| Third | UniVLA | 95.5 | 85.8 | 75.4 | 66.9 | 56.5 | 3.80 |
| Third | DeFI | 92.9 | 87.2 | 81.2 | 75.0 | 68.4 | 4.05 |
| Multi | GR-1 | 85.4 | 71.2 | 59.6 | 49.7 | 40.1 | 3.06 |
| Multi | OpenVLA | 91.3 | 77.8 | 62.0 | 52.1 | 43.5 | 3.27 |
| Multi | Vidman | 91.5 | 76.4 | 68.2 | 59.2 | 46.7 | 3.42 |
| Multi | π₀* | 93.8 | 85.0 | 76.7 | 68.1 | 59.9 | 3.84 |
| Multi | π₀.₅* | 94.8 | 87.4 | 78.2 | 71.7 | 64.3 | 3.97 |
| Multi | GR00T N1* | 94.2 | 86.1 | 79.6 | 73.9 | 66.8 | 4.01 |
| Multi | UP-VLA | 92.8 | 86.5 | 81.5 | 76.9 | 69.9 | 4.08 |
| Multi | Seer | 96.3 | 91.6 | 86.1 | 80.3 | 74.0 | 4.28 |
| Multi | VPP | 96.5 | 90.9 | 86.6 | 82.0 | 76.9 | 4.33 |
| Multi | DeFI | 97.9 | 94.2 | 90.7 | 87.0 | 81.2 | 4.51 |
*作者自行复现。注:DreamVLA(4.44)在源码里出现于注释行,但被排除出正式表(见 §5.2)。
数据效率(Figure 3):只用 10% 数据时,DeFI 相对 VPP 的 avg len 有 +18% 相对提升;只需约 60% 数据即可超过此前 SOTA(VPP 4.33 那条虚线)。
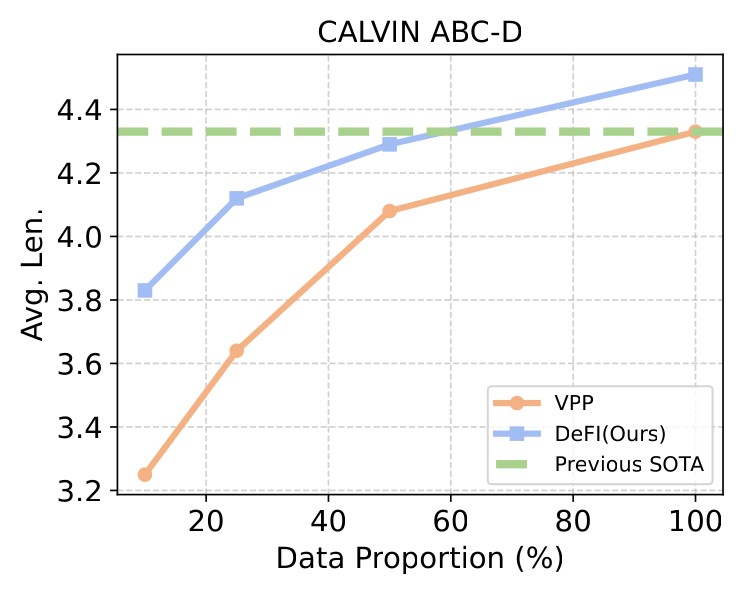 Figure 3:CALVIN ABC-D 上不同数据比例。DeFI 在 ~57–60% 数据处即越过 previous SOTA(绿虚线 = VPP 满数据 4.33),全程优于 VPP。
Figure 3:CALVIN ABC-D 上不同数据比例。DeFI 在 ~57–60% 数据处即越过 previous SOTA(绿虚线 = VPP 满数据 4.33),全程优于 VPP。
4.2 SimplerEnv-Fractal(Google Robot)¶
| Model | VM·Coke | VM·MoveNear | VM·Drawer | VM Avg | VA·Coke | VA·MoveNear | VA·Drawer | VA Avg |
|---|---|---|---|---|---|---|---|---|
| Octo-Base | 17.0 | 4.2 | 22.7 | 16.8 | 0.6 | 3.1 | 1.1 | 1.1 |
| TraceVLA | 28.0 | 53.7 | 57.0 | 42.0 | 60.0 | 56.4 | 31.0 | 45.0 |
| OpenVLA | 16.3 | 46.2 | 35.6 | 27.7 | 54.5 | 47.7 | 17.7 | 39.8 |
| DeFI | 54.2 | 60.7 | 38.6 | 51.2 | 53.9 | 58.2 | 24.0 | 45.4 |
(VM = Visual Matching,VA = Variant Aggregation。注意 DeFI 在 Drawer 子任务上反而落后 TraceVLA;且本表只保留了被 DeFI 超过的弱 baseline,见 §5.2。)
4.3 真机 Franka Panda(8 任务,1600 条 demo,每任务最多 20 次连续尝试)¶
| Method | Place | Open | Close | Cut | StackBowl | StackCube | StackBottle | Pour | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Diffusion Policy | 70 | 40 | 70 | 50 | 45 | 35 | 40 | 35 | 48.2 |
| Octo-Base | 55 | 35 | 60 | 20 | 30 | 25 | 30 | 20 | 34.4 |
| OpenVLA | 50 | 40 | 65 | 40 | 30 | 35 | 45 | 45 | 43.8 |
| DeFI | 90 | 75 | 100 | 80 | 80 | 70 | 80 | 75 | 81.3 |
4.4 关键消融(均为 CALVIN ABC-D multi-view,metric = Avg. Len)¶
解耦预训练的作用 & 人类视频的作用
| 配置 | Avg. Len | 配置 | Avg. Len | |
|---|---|---|---|---|
| GFDM w/o pretrain | 3.28 | All w/o human video | 3.92 | |
| GIDM w/o pretrain | 4.16 | GFDM w/o human video | 4.19 | |
| All w/ pretrain | 4.51 | GIDM w/o human video | 4.34 | |
| All w/ human video | 4.51 |
IDM 架构 & 离散化策略 & 部分微调 & 去噪步数
| IDM 架构 | Len | 离散化 | Len | 微调范围 | Len | GFDM 设置 | Len |
|---|---|---|---|---|---|---|---|
| MLP | 3.42 | Gaussian Mixture | 4.12 | Adapter only | 4.33 | 5 steps | 4.45 |
| Transformer | 4.22 | Simple Binning | 3.98 | GFDM+Adapter | 4.35 | DINO-gen | 3.70 |
| GIDM (VQ-VAE) | 4.51 | Continuous Latent | 4.20 | GIDM+Adapter | 4.51 | Ours (1 step) | 4.51 |
| VQ-VAE (Ours) | 4.51 | All Train | 4.40 |
要点:① 预训练 GFDM 是最大单项贡献(3.28→4.51);② 人类视频带来 +0.59(按 scaling 表 3.92→4.51,且无饱和);③ IDM 架构很关键(MLP 3.42 → VQ-VAE 4.51);④ 全部微调(4.40)反而不如只微调 GIDM+Adapter(4.51),作者归因于联合优化导致 GFDM 输出漂移、IDM 输入分布不稳。
失败案例分析(CALVIN 200 例):forward-dynamics 失败占 62%(接触密集 / 杂乱场景下 FDM 产生 hallucination 或多视角不一致),inverse-dynamics 失败占 38%(即便预测准,IDM 仍可能抓取失败 / 放错 / 碰撞)。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
-
解耦让每个模块吃最合适的「数据 × 目标」组合:forward 用 video-generation 目标在人+机器人视频上学,inverse 用自监督 latent-action 目标在 action-free 视频上学。这正面绕开了 Seer 等耦合式方法「2D 预测 vs 3D 动作目标竞争 → 训练不稳」的老问题,立意干净。
-
把 inverse dynamics 提到一等公民,并给出可规模化的自监督 recipe(DINOv2 特征 + 时空 Transformer + VQ-VAE,吃 Ego4D)。这直接回应了它对 VPP(无 IDM)/ Vidar(IDM 弱)的批评,而且 IDM 架构消融(MLP 3.42 → Transformer 4.22 → VQ-VAE GIDM 4.51)确实把「IDM 设计很重要」这件事量化了出来——批评有据、解法对得上。
-
单步去噪 + 冻结 GFDM 是务实的工程权衡:用了 SVD 这种重视频生成器,却把推理压到 ~153ms(约 6.5Hz),让 video-as-policy 路线落地可行;且复用 VPP 的 video former 抽中间特征,省去重训。
-
VQ-VAE 同时当离散化器和 information bottleneck:论点是量化阻止 future-state 直接泄漏进 decoder,逼出有意义的 action 表征。离散化策略消融(GMM 4.12 / binning 3.98 / 连续 latent 4.20 / VQ-VAE 4.51)支持了这个选择。
-
数据效率亮眼:冻结 GFDM、只训轻量 GIDM+adapter,使得 10% 数据相对 VPP +18%、60% 数据即超 SOTA;partial-tuning 表里「Adapter only」已达 4.33,说明 GFDM 提供的 latent 空间确实强且表达力够。
-
失败归因诚实:62% / 38% 的 forward / inverse 失败拆解,反过来佐证了「inverse 和 forward 同等重要」的主张,比单纯报点更有说服力。
5.2 做得不够好 / 值得质疑的地方¶
-
SimplerEnv 表疑似 cherry-pick baseline。正式表只留了 Octo(16.8) / TraceVLA(42.0) / OpenVLA(27.7) 三个被 DeFI(51.2) 超过的弱对手。但源码注释里的早期草稿表包含 π₀(70.1)、RT-2-X(60.7)、RoboVLM(63.4)、SpatialVLA(73.8) ——这些在 Visual Matching 上都高于 DeFI 的 51.2。把更强的对手全删掉、只留打得过的,SimplerEnv 上「state-of-the-art」的说法站不住。
-
更严重:SimplerEnv 数字从草稿到终稿大幅跳水且方向相反。同一份注释草稿里 DeFI 自己是 75.1% VM / 70.7% VA,终稿变成 51.2% / 45.4%。一个方法在投稿过程中自报性能掉 24 个点,却没有任何说明,要么早期是 bug、要么终稿换了更严的协议——无论哪种,都说明这套 SimplerEnv 结果不稳、可信度存疑。
-
CALVIN 的「未见环境泛化」叙事被 GFDM 预训练数据污染。Appendix 称「除 SimplerEnv 外,下游环境(如 CALVIN)在预训练中均未见过」——但这只对 GIDM 成立。GFDM 的预训练 mixture 里 CALVIN-ABC 占了 30%(Table FFDM_data)。也就是说被冻结、当骨干的 forward model 早就大量见过 CALVIN-ABC(与微调同分布)。「冻结 GFDM 因为它已覆盖下游域」这个理由,在 CALVIN 上本质是「因为我们把它放进了预训练」,泛化叙事要打折。
-
人类视频消融表存在算术内部矛盾。CALVIN 的 Avg. Len 恒等于五个连续成功率之和 / 100。Table
ab_human_video的「All w/o h.v.」行 per-task 是 93.6/91.2/88.0/82.4/79.2,加起来 = 4.34,但该行 Len 却标 3.92;而同表「GIDM w/o h.v.」用了一模一样的 per-task 数字、Len 标 4.34。明显是 per-task 单元格 copy-paste 错了一行。这不仅是排版瑕疵——它正好落在支撑「human video 不可或缺」这一核心卖点的关键表上,让人怀疑该消融的制备严谨度。 -
「冻结 GFDM 永远更好」是被下游域偷偷决定的。作者自己在 §4.3 承认:SimplerEnv 上冻结的、在 Fractal 上训的 GFDM 只会预测真实图像,domain shift 传导到 IDM 产生错误动作。换句话说冻结策略在「域内」是优点、在「域外」是硬伤,论文却把它当普适原则来讲。
-
「All Train(4.40) < GIDM+Adapter(4.51)」反直觉且解释偏方便。更多可训练参数 + 联合训练却更差,归因于「表征不稳 / 梯度干扰」。这在调度得当时通常可缓解,结果更像是联合变体欠训或优化病态,而非「冻结必然更好」的证据。
-
information-bottleneck 的因果是断言而非测量。「VQ-VAE 阻止 future-state 泄漏」只有离散化策略的端到端对比,没有任何直接隔离「泄漏量」的实验(例如探测 decoder 能否从 latent 重建未来细节)。机制解释停在 narrative 层面。
-
强近邻 baseline DreamVLA 被移出正表。源码注释显示 DreamVLA = 4.44(task1/2 的 98.2/94.6 还高于 DeFI 的 97.9/94.2),是最接近的对手,却没出现在终表里,只在脚注式注释中。哪怕仍被 4.51 险胜,删掉它也削弱了比较的完整性。
-
真机 / 第三视角 CALVIN 的对照同样偏弱。真机只比 DP/Octo/OpenVLA,没有 π₀ / VPP 等近期 VLA;第三视角 CALVIN 只比 SuSIE/CLOVER/UniVLA(最高才 3.80)。大幅领先很大程度是对手太弱。
-
action 只条件于视觉 transition,无力学 / 接触建模。GIDM 从 \((o_t, o_{t+n})\) 视觉差推动作,没有 force/torque 通道;论文也承认 fine-grained、接触密集任务(62% 失败来自 FDM 在接触场景的 hallucination)仍是瓶颈。prediction-to-control 鸿沟被缩小但未真正闭合。
5.3 值得继续探讨的方向¶
- 修掉冻结 GFDM 的域外硬伤:对 forward model 做 LoRA / 轻量域适配,而不是非冻即全训的二选一;直接对应 SimplerEnv 的 domain-shift 失败。
- 换更强的 latent 预测器当 forward model:作者试过 DINO-gen(3.70,更差,因无法接入视频生成预训练知识),但点名 V-JEPA / V-JEPA2 / DINO-WM 类「latent embedding 预测」是探索上界的方向。
- 闭环 / replan 对付 62% 的 forward 失败:当前是开环跟踪 16 帧预测,接触密集场景一旦 hallucinate 就崩;引入短 horizon + 闭环重规划值得试。
- 加语言推理 / LLM grounding(作者自列 future work):当前框架不显式建模 language interaction,长 horizon 语义任务受限。
- 真正的跨 embodiment 泛化测试:现有评估的 embodiment 与预训练高度重叠;human video scaling 无饱和的结论,需要在「剔除域内泄漏」后重新核验。
- 量化 information bottleneck:设计能直接测「latent 是否泄漏未来细节」的探针实验,把机制从断言变成证据。
- 把 SimplerEnv 结果做扎实:在统一协议下补回 π₀ / RT-2-X / SpatialVLA 等强 baseline,澄清 75.1%→51.2% 的跳水原因。