Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
- 作者: Qwen Team(核心贡献者 Qiuyue Wang*, Mingsheng Li*, Jian Guan*, …, Shuai Bai†, Jingren Zhou,*共同一作 †通讯)— Alibaba Qwen
- arXiv 编号: 2605.30280 (submitted 2026-05;模板为 COLM 2024)
- 关键词: vision-language-action, embodied foundation model, flow matching, DiT action expert, embodiment-aware prompting, multi-embodiment co-training, manipulation, vision-language navigation, RL post-training
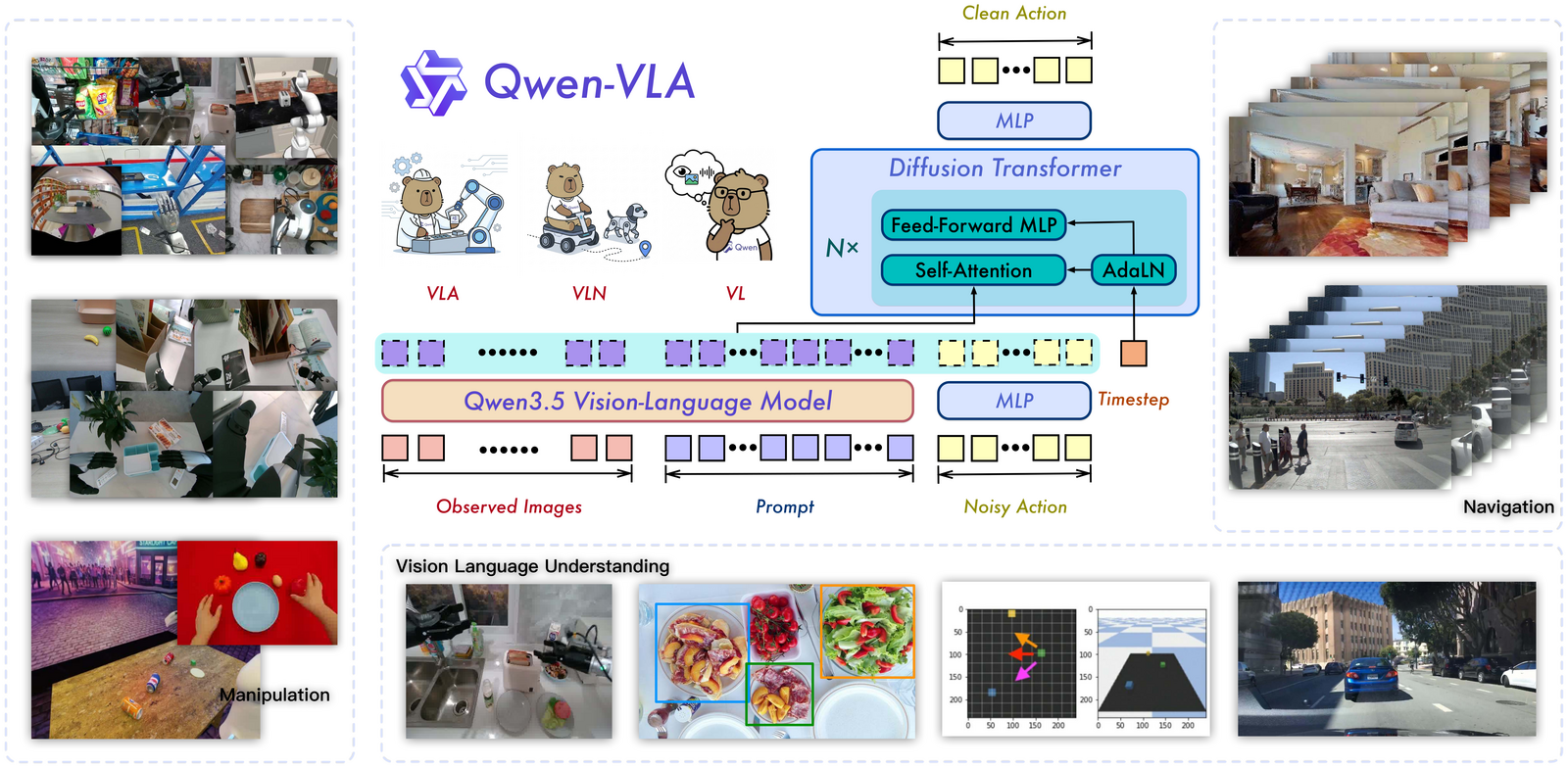 Figure 1:一个统一模型同时吞下 manipulation / navigation / VL 三类数据,左侧 Qwen3.5 VLM 做感知与理解,右侧 DiT flow-matching action expert 做连续动作生成,输出既可以是机器人动作也可以是文本回答。
Figure 1:一个统一模型同时吞下 manipulation / navigation / VL 三类数据,左侧 Qwen3.5 VLM 做感知与理解,右侧 DiT flow-matching action expert 做连续动作生成,输出既可以是机器人动作也可以是文本回答。
2. 文章介绍¶
2.1 解决的领域和问题¶
本文属于 embodied foundation model / VLA(Vision-Language-Action) 方向。当前具身智能的主流做法是为每个场景或任务单独训一个专用模型:manipulation 模型针对桌面或灵巧手控制,navigation 模型围绕室内 waypoint 预测,二者在观测格式、控制频率、预测 horizon、动作维度、评测协议上全都不同。这种碎片化使得能力无法在任务、环境、机器人本体之间迁移,也难以像通用 VLM 那样靠规模化预训练吃到红利。
论文要回答的核心问题是:这些表面异构的具身决策问题,能否被统一进单一 VLA 模型里联合训练?
2.2 Motivation¶
作者的核心 insight 是:尽管 manipulation、navigation、egocentric human motion、trajectory prediction 输出形式各异,它们共享同一个计算结构——给定视觉观测 + 语言指令 + 本体约束,预测一段在物理与语义上对齐的未来动作/轨迹。既然底层结构一致,就应该用一个统一的 conditional prediction 框架把它们全部纳入,让视觉 grounding、空间推理、连续动作生成的能力在不同本体之间互相迁移。再叠加 Qwen3.5 这种强多模态 backbone,就能把"通用 VLM 预训练"的范式复刻到具身领域。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Manipulation 专用策略 | π0 / π0.5 / GR00T N1.6 | 局限于桌面或灵巧操作,单 embodiment,跨任务/跨本体迁移差 |
| Navigation 专用模型 | NaViD / Uni-NaVid / NaVILA / StreamVLN | 围绕室内 waypoint/离散动作设计,与 manipulation 完全割裂 |
| 离散 token 化动作 | OpenVLA / π0-FAST | 自回归离散动作,难表达高频高维连续控制的多模态分布 |
| 多 embodiment 处理 | 各 specialist | 通常靠 per-embodiment 输出头/独立策略,无法共享单一接口 |
| 仅 imitation 训练 | 多数 VLA | 优化的是 demo likelihood,不是闭环 task success,分布漂移即失败 |
2.4 论文解决方案(一句话)¶
在 Qwen3.5-4B 多模态 backbone 上挂一个 1.15B 的 DiT flow-matching action expert,用 embodiment-aware 文本 prompt 作为唯一的本体接口,把 manipulation/navigation/egocentric/trajectory 全部统一进同一个 action-and-trajectory 预测空间,再用 T2A→CPT→SFT→RL 四阶段渐进训练,训出一个跨任务/跨环境/跨本体的通才策略 Qwen-VLA。
2.5 与前序工作的关系¶
- backbone 直接复用 Qwen3.5(原生多模态、early-fusion、hybrid attention:多数层 gated linear attention + 间隔的 grouped-query softmax attention)。
- action expert 沿用 π0 系列的 flow-matching policy 思路(Lipman 的 conditional flow matching),DiT 结构借鉴 SD3/Peebles 的 AdaLN-DiT。
- 数据上大量复用公开数据集:RoboSet / AgiBot World / DROID / BridgeData V2 / RH20T / RT-1 等真机数据,Ego4D / EPIC-KITCHENS(经 VITRA 处理)/ EgoDex / EgoVerse / Xperience 等 egocentric 数据,仿真用自研 RoboInF + IsaacLab + cuRobo。
- RL 用 RLinf 框架 + PPO/GAE。
3. 方法介绍¶
3.1 形式化¶
统一为 conditional prediction:在时刻 \(t\),模型接收视觉上下文 \(o_t\)(单帧/多帧/视频/历史窗口)、语言指令 \(x\)、本体描述 \(e\)、可选任务标识 \(z\),预测 horizon \(H\) 内的目标序列:
\(y\) 在不同任务下语义不同但落进统一的 action-and-trajectory 空间:manipulation 是未来末端位姿/关节,navigation 是 waypoint,trajectory-centric(自动驾驶/运动预测)是连续坐标轨迹,egocentric 是 MANO/骨骼 pose。作者强调该框架在输入轴(加 episodic memory)与输出轴(co-predict 未来视觉状态 → world model)上都可扩展。
3.2 模型架构¶
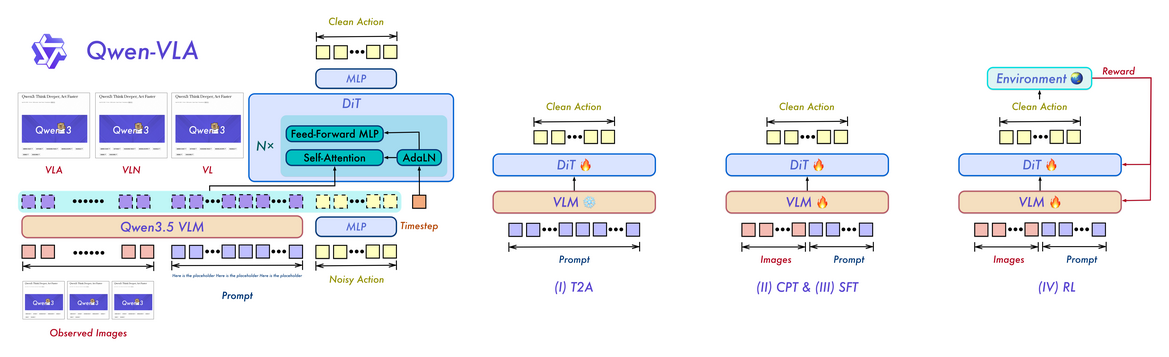 Figure 2:左为架构——VLM hidden states 与带噪 action chunk 拼成一条序列送进 DiT,DiT 每个 block 是 Self-Attention + Feed-Forward MLP + AdaLN(timestep 条件)。右为四阶段训练:(I) T2A 只训 DiT、冻 VLM、无图像;(II/III) CPT/SFT 全解冻引入图像;(IV) RL 接环境 reward。
Figure 2:左为架构——VLM hidden states 与带噪 action chunk 拼成一条序列送进 DiT,DiT 每个 block 是 Self-Attention + Feed-Forward MLP + AdaLN(timestep 条件)。右为四阶段训练:(I) T2A 只训 DiT、冻 VLM、无图像;(II/III) CPT/SFT 全解冻引入图像;(IV) RL 接环境 reward。
- VLM backbone:Qwen3.5(natively multimodal,ViT + spatial merging,视觉 token 直接交织进文本流)。
- Action expert:single-stream DiT flow-matching policy。把 VLM hidden states 与 noisy action chunk 拼接成一条序列,经 joint self-attention + AdaLN timestep conditioning + 与 backbone 对齐的 multi-section RoPE。flow-matching 训练,推理时几步 Euler 积分出动作 → 低延迟实时控制。
- 参数量:action expert ≈ 1.15B:16 个 DiT block 是大头(每块 70.8M,共 1.13B),其余为 action projection MLP(4.9M)、VLM→DiT 维度线性层(3.9M)、timestep embedding(2.8M)、输出 AdaLN modulation(4.7M)。
3.3 Embodiment-aware Prompt Conditioning¶
唯一的本体接口是一段文本 prompt(不改任何架构),模板:
The robot is {robot_tag} with {single arm / dual arms}[, waist][, and mobile base]. The control frequency is {FPS} Hz. Please predict the next {chunk_size} control actions to execute the following task: {ori_instruction}.
FPS 与 chunk_size 取数据集原始控制频率与预测 horizon。部署到真机时只需把 prompt 换成物理平台的描述,backbone 和 DiT 完全不动 → 零样本跨本体。
3.4 Unified Action & Trajectory Representation¶
关键设计:统一 tensor 接口 + masking,但不强行把所有本体压进同一物理动作语义空间。每个样本贡献目标张量 \(\mathbf{Y}\in\mathbb{R}^{H\times K}\),\(H\) 固定 horizon,\(K\) 固定通道数(所有控制模式共享)。
- 通道布局:某控制模式用 \(c\le K\) 通道,放在 \(\mathbf{Y}\) 的前 \(c\) 维,其余 \(K-c\) 维零填充;二值 mask \(\mathbf{M}\in\{0,1\}^{H\times K}\) 记录哪些通道/时间步有效(\(M_{h,k}=1\) iff \(k<c\) 且 \(h<H_{\text{task}}\))。无需任何 per-embodiment 输出头。
- 控制信号:manipulation(Δ末端位置、Euler/四元数旋转、绝对关节、gripper、灵巧手关节)和 navigation(\((\Delta x,\Delta y,\Delta\theta)\) per waypoint)虽语义不同,但都被当作"区间内实值向量序列"统一处理。
- 归一化:每个数据集按 1%/99% 分位数做 per-dataset quantile normalization 到 \([-1,1]\),去掉尺度差异同时保留运动结构。各数据集保留原生动作格式,靠 prompt 告知控制约定。
- 多视角:用
<|tag_start|> <image> <|tag_end|>包裹每张图(tag 如 ego / cam_left_wrist),让 backbone 形成 view-aware 表示。
3.5 训练目标¶
两个 loss 加权和:
- Flow-matching action loss:clean target \(\mathbf{Y}_0\)、noise \(\mathbf{Y}_1\sim\mathcal{N}(0,I)\)、线性插值 \(\mathbf{Y}_\tau=(1-\tau)\mathbf{Y}_0+\tau\mathbf{Y}_1\),训 \(v_\theta\) 预测 conditional velocity field。用 per-channel, per-step 两级平均:先在每个有效通道内按 mask 求 MSE,再对 \(c\) 个有效通道均匀平均,保证每个控制维度等权贡献梯度、padding 完全排除。
- Vision-language loss:在辅助 VL 数据、fine-grained action caption、自动驾驶 VQA、通用 VL 语料上做 next-token prediction,防止 backbone 灾难性遗忘。
- 联合:\(\mathcal{L}=\lambda_{\text{act}}\mathcal{L}_{\text{act}}+\lambda_{\text{vl}}\mathcal{L}_{\text{vl}}\),权重调到两者梯度量级平衡;每个 mini-batch 按固定比例混合所有任务族。
3.6 四阶段训练 Recipe¶
作者用 compression(压缩-解压)视角解释:语言指令 + embodiment prompt 是高度压缩的任务意图(几十个 token),动作轨迹是高维高频信号(数千关节值),二者间是结构化"解压"问题。冷启动时 backbone 已强预训练而 DiT 随机初始化,二者状态严重不对称,naive 联合训练既低效又不稳。
- Stage I — T2A (Text-to-Action DiT pretraining):冻 VLM、只训 DiT、故意不给图像,强迫 decoder 成为纯语言→动作解压器,在引入视觉前先建立结构化 action prior(语言选动作区域、prompt 指定平台运动参数化、flow-matching 管生成过程)。
- Stage II — CPT (Continued Pretraining):解冻两个模块,在异构混合数据(含仿真 + 真机)上把 action prior grounding 到视觉观测。产出 Qwen-VLA-Base。
- Stage III — SFT:从 CPT 分两条平行轨——多任务 SFT(VQA + spatial grounding + manipulation + navigation,embodiment/task 平衡采样);以及在 in-house 遥操作数据上为真机部署微调。
- Stage IV — RL:从多任务 SFT checkpoint 起,仅在 SimplerEnv 单一仿真环境用稀疏二值成功 reward 做 PPO,产出最终 Qwen-VLA-Instruct,刻意测试单环境 RL 的 task-success 增益能否迁移到 OOD 环境。
3.x Implementation Details¶
- 预训练数据混合(Table,按比例):Robot Manipulation Trajectories 74.2%、Navigation 7.5%、Egocentric Human 6.0%、Synthetic Simulation (ours) 3.7%、General VL 3.4%、Spatial Grounding (2D) 2.5%、Autonomous Driving VQA 2.4%、Fine-Grained Action Caption 0.2%。真机数据 >10,000 小时;in-house 真机 >1,000 小时(约占 20%);自研仿真 >8M 条轨迹。
- Egocentric 动作表示:每只手 SE(3) wrist 相对运动(6 维:平移 + axis-angle),手部 articulation 用 45 维 axis-angle 做 PCA 取前 10 主成分(eigengrasps),共 32 维/step(双手)。
- Language-action 仿真数据:6 个任务模板 × 6 个单臂机器人(Franka Panda / UR10e / UR5e / Kinova Gen3 / TM12 / xArm7),每对约 200k 条,共 ≈7.2M 条 / >14,000 小时,50Hz 记录关节位置/速度/末端位姿/gripper,无物理仿真无渲染(cuRobo 批量运动规划),专供 Stage I T2A。
- Vision-conditioned 仿真数据:RoboInF + IsaacLab,20 场景 × 10 初始配置 = 200 base scene,450 任务,每任务 300 条带 domain randomization(~3K 背景 + 1K 桌面纹理),共 359,848 条完整成功轨迹(含子任务段)。
- RL 细节:PPO(\(\epsilon=0.2\))+ GAE(\(\gamma=0.99,\lambda=0.95\)),value head 直接挂 backbone(stop-grad,LR \(10^{-4}\) ≈ actor LR \(5\times10^{-6}\) 的 20×)。flow-matching 下的 log-prob:把 probability-flow ODE 转成 SDE,每个 Euler 去噪步变成显式 Gaussian → 解析 log-prob;默认随机选单个去噪步估计,只需 1 次额外 DiT forward。log-prob 与 advantage 都在 action-chunk 级(\(H=16\),一个 chunk 一个 scalar reward/advantage)。128 并行 env,每 iteration 8 epochs × 128 steps → 8,192 transition chunks;rollout 温度 \(\tau=1.0\),评测 \(\tau=0.6\);client-server 解耦 rollout。
- 下游 manipulation chunk \(H=16\),navigation waypoint horizon 8。SFT loss 权重:VL next-token 0.1,manipulation/navigation action 各 1.0。
4. 结果对比¶
4.1 仿真 Manipulation(specialists vs 单一 generalist)¶
| Method | Type | LIBERO | RoboCasa-GR1 | Simpler-WidowX | RoboTwin-Easy | RoboTwin-Hard |
|---|---|---|---|---|---|---|
| π0 | Specialist | 94.4 | -- | -- | 65.9 | 58.4 |
| StarVLA-OFT | Specialist | 96.6 | 48.8 | 64.6 | 50.4 | -- |
| GR00T N1.6 | Specialist | 97.2 | 49.9 | 63.2 | 47.6 | -- |
| π0.5 | Specialist | 97.6 | 37.0 | 46.9 | 82.7 | 76.8 |
| ABot-M0 | Specialist | 98.6 | 58.3 | -- | 86.0 | 85.0 |
| Being-H0.5 | Specialist | 97.6 | 53.3 | -- | -- | -- |
| Qwen-VLA-Base | Generalist | 90.8 | 40.4 | 64.3 | 64.3 | 66.4 |
| Qwen-VLA-Instruct | Generalist | 97.9 | 56.7 | 73.7 | 86.1 | 87.2 |
注:specialist 是每个 benchmark 单独 fine-tune 的;Qwen-VLA 是一次性多本体联合训练、靠 prompt 切换部署到全部平台。Instruct 在 Simpler-WidowX / RoboTwin-Easy / Hard 上超过所有 specialist,LIBERO/RoboCasa 紧随最强 specialist。Base→Instruct 增益:LIBERO +7.1、RoboCasa +16.3、Simpler +9.4、RoboTwin-Easy +21.8、Hard +20.8。
4.2 真机 ALOHA(双臂,预训练的价值)¶
In-domain(成功率 %):
| Model | Pick&Place | Table Clean | Bowl Stack | Bowl P&P | Towel Fold | Fine-grained | Avg |
|---|---|---|---|---|---|---|---|
| GR00T N1.6 | 30.8 | 38.5 | 53.8 | 19.2 | 19.2 | 10.3 | 28.6 |
| π0.5 | 73.1 | 84.6 | 88.5 | 69.2 | 80.8 | 33.3 | 71.6 |
| Qwen-VLA-aloha (w/o pretrain) | 30.8 | 53.8 | 61.5 | 64.1 | 50.0 | 30.8 | 48.5 |
| Qwen-VLA-aloha (w/ pretrain) | 96.2 | 92.3 | 98.7 | 87.2 | 65.4 | 61.5 | 83.6 |
OOD(成功率 %):
| Model | Color | Instance | Position | Background | Instruction | Avg |
|---|---|---|---|---|---|---|
| GR00T N1.6 | 46.2 | 38.5 | 3.8 | 19.2 | 19.2 | 25.4 |
| π0.5 | 57.7 | 61.5 | 19.2 | 26.9 | 42.3 | 41.5 |
| Qwen-VLA-aloha (w/o pretrain) | 42.3 | 30.8 | 34.6 | 30.8 | 42.3 | 36.2 |
| Qwen-VLA-aloha (w/ pretrain) | 88.5 | 76.9 | 53.8 | 80.8 | 84.6 | 76.9 |
同架构下,预训练把 in-domain 48.5→83.6、OOD 36.2→76.9,OOD 上比 π0.5 高 35.4pp。说明增益来自 Qwen-VLA-Base 预训练而非架构本身。
 Figure 3:Qwen-VLA-Base 在 ALOHA 双臂上的零样本 OOD rollout——按颜色抓球(左上)、抓训练集外新物体并做组合式"清桌"(右上)、与完全未见物体交互(左下)、未见黄色背景下拔笔帽(右下)。这些行为主要靠混入的通用 VL 数据带来的物体词汇与背景多样性迁移而来。
Figure 3:Qwen-VLA-Base 在 ALOHA 双臂上的零样本 OOD rollout——按颜色抓球(左上)、抓训练集外新物体并做组合式"清桌"(右上)、与完全未见物体交互(左下)、未见黄色背景下拔笔帽(右下)。这些行为主要靠混入的通用 VL 数据带来的物体词汇与背景多样性迁移而来。
4.3 Navigation(VLN-CE Val-Unseen)¶
| Method | R2R OS↑ | R2R SR↑ | R2R SPL↑ | RxR SR↑ | RxR SPL↑ |
|---|---|---|---|---|---|
| NaViD | 49.2 | 41.9 | 36.5 | 45.7 | 38.2 |
| Uni-NaVid | 53.3 | 47.0 | 42.7 | 48.7 | 40.9 |
| NaVILA | 62.5 | 54.0 | 49.0 | 49.3 | 44.0 |
| StreamVLN | 64.2 | 56.9 | 51.9 | 52.9 | 46.0 |
| Qwen-VLA-Base | 61.7 | 53.8 | 49.4 | 55.1 | 45.8 |
| Qwen-VLA-Instruct | 69.0 | 57.5 | 51.2 | 59.6 | 47.8 |
4.4 OOD 静态 manipulation(SimplerEnv-OOD,仅在 Bridge pick-and-place 上 fine-tune)¶
| Method | MoveAway | MoveRight | PlaceNear | PlaceRight | PutFront | StackYellow | Avg |
|---|---|---|---|---|---|---|---|
| π0.5 | 26.1 | 0.0 | 0.0 | 32.1 | 13.0 | 4.2 | 12.6 |
| Qwen-VLA-Base | 31.3 | 31.6 | 16.7 | 47.1 | 6.3 | 18.8 | 25.3 |
| Qwen-VLA-Instruct | 43.8 | 33.3 | 39.6 | 47.9 | 4.2 | 22.9 | 32.0 |
π0.5 在 MoveRight/PlaceNear 上完全失败(0%),Qwen-VLA 显著拉开位置泛化差距。
4.5 OOD 动态 manipulation(DOMINO,零样本)¶
Qwen-VLA-Instruct 取得最高 SR 26.6% / MS 39.5,零样本即超过专门 fine-tune 动态数据的 PUMA(17.2 / 35.0)9.4pp。仅用 current-frame 观测、无任何动态微调。
4.6 关键消融¶
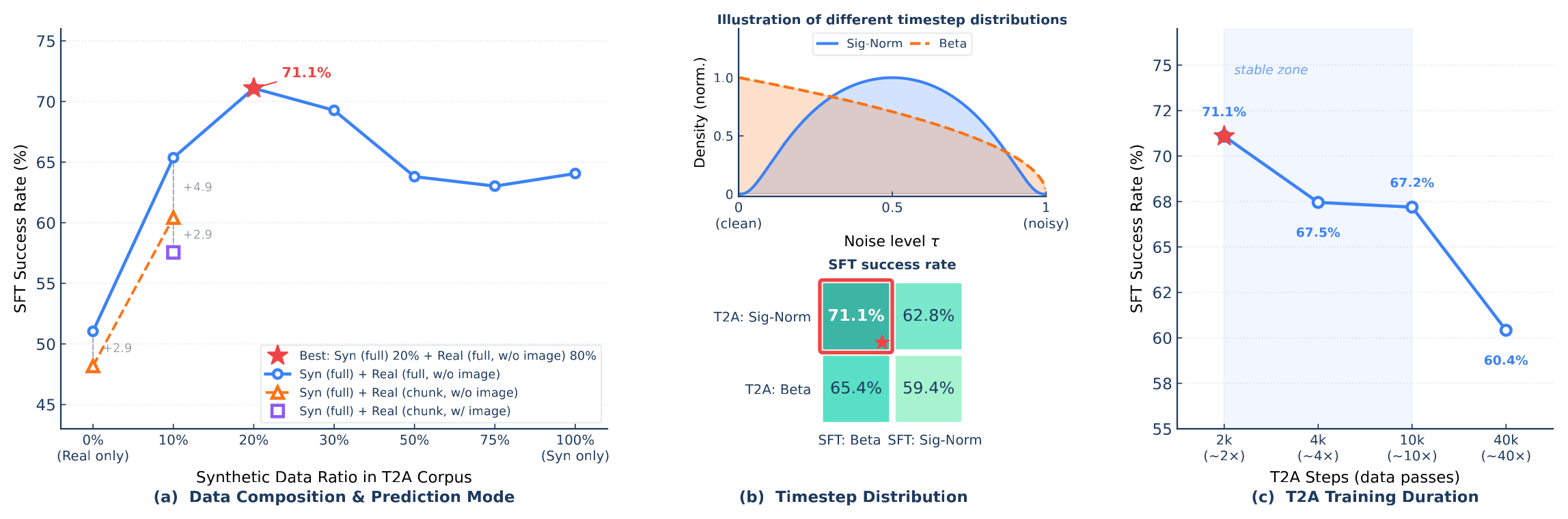 Figure 4:T2A 三组关键消融。(a) 数据配比 + 预测模式——20% syn + 80% real 的 full-sequence 预测峰值 71.1%,chunk 预测与含图像都明显更差;(b) timestep 分布——T2A 用 Sigmoid-Normal、SFT 用 Beta 组合最优,反着换都掉点;(c) T2A 步数——2000 步即达峰,40000 步因过拟合 T2A 语料反而下滑。
Figure 4:T2A 三组关键消融。(a) 数据配比 + 预测模式——20% syn + 80% real 的 full-sequence 预测峰值 71.1%,chunk 预测与含图像都明显更差;(b) timestep 分布——T2A 用 Sigmoid-Normal、SFT 用 Beta 组合最优,反着换都掉点;(c) T2A 步数——2000 步即达峰,40000 步因过拟合 T2A 语料反而下滑。
T2A 设计(SFT 后在 Simpler-WidowX 的成功率 %):
| 配置 | 成功率 |
|---|---|
| T2A 纯 real 数据 | 51.04 |
| T2A 纯 synthetic | 64.06 |
| T2A ~20% syn + 80% real,full-sequence | 71.09 |
| chunk 预测(10% syn) | 60.42(比 full-seq 低 4.94pp) |
| chunk + 含图像(10% syn) | 57.55(再 −2.87pp) |
| Beta@T2A(换掉 Sigmoid-Normal) | 65.36(−5.73) |
| Sigmoid-Normal@SFT | 62.76(−8.33) |
| Beta 两阶段都用 | 59.38 |
| T2A 步数 2k / 4k / 10k / 40k | 71.09 / 67.45 / 67.19 / 60.42(40k 过拟合) |
结论:T2A 用 full-sequence、20% syn+80% real、Sigmoid-Normal \(p(\tau)\)、2000 步最优;图像必须在 T2A 完全屏蔽。
Post-training 累积效应:
| Stage | Simpler | RoboCasa | RoboTwin-E | RoboTwin-H | LIBERO | SimplerOOD | DOMINO SR | DOMINO MS |
|---|---|---|---|---|---|---|---|---|
| CPT | 64.3 | 40.4 | 64.3 | 66.4 | 90.8 | 25.3 | 21.1 | 37.4 |
| +SFT | 70.8 | 56.0 | 86.3 | 87.1 | 97.8 | 31.6 | 25.7 | 39.1 |
| +RL | 73.7 | 56.7 | 86.1 | 87.2 | 97.9 | 32.0 | 26.6 | 39.5 |
RL 仅在 SimplerEnv 收集 rollout,最大增益在 SimplerEnv 本身(+2.9pp),其余 benchmark 保持或小幅正迁移,无灾难性遗忘。
其它消融:VL 数据 co-training 在难任务上 +4.9pp(RoboCasa)/ +4.6pp(RoboTwin);预训练 DiT 比 from-scratch 收敛更快峰值更高;投影头 Multi-MLP / Concat / Zero-Pad 差异 <1.2pp,选参数最省的 Zero-Padding;state conditioning(VLM prompt / DiT)最多只 +1.3pp,最终不用 state,只保留文本 prompt 作为唯一本体接口。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
-
统一 tensor 接口 + masking,而非统一物理语义空间。这是比"强行对齐所有本体动作"更聪明的折中:固定 \(K\) 通道 + 前 \(c\) 维有效 + per-channel mask,单套 DiT 参数吃下所有控制模式,padding 不污染梯度(两级平均保证每维等权)。配合 per-dataset quantile 归一化,既消除尺度差异又保留各源原生动作格式。
-
embodiment 用文本 prompt 编码 → 唯一接口。把"机器人是谁、几条臂、控制频率、horizon"全压进自然语言,使得跨本体不需要任何架构改动、部署到真机只换 prompt。这也是 RL 能零样本迁移到 OOD 环境的前提(prompt 不变 → 无分布漂移)。
-
compression 视角下的 T2A 阶段。把"语言→动作"看作结构化解压,先在无图像、无 backbone 干扰的条件下训出 language-indexed action prior,再把视觉 grounding 留给 CPT。这避开了冷启动时随机 DiT 梯度扰动预训练 backbone、且每步都白付图像编码成本的问题。消融充分(数据配比、full-seq vs chunk、有无图像、timestep 分布、步数)。
-
T2A 的 timestep 分布选择有物理直觉且被验证。无视觉条件时 backbone 给不了去噪引导,于是用 Sigmoid-Normal 把梯度推向中间噪声水平(信噪比最有信息);有了 backbone 条件后 CPT/SFT 换回 Beta。这个"阶段相关 \(p(\tau)\)"是有解释力的设计,且消融显示乱换会掉 5–8pp。
-
flow-matching 下的 PPO log-prob 估计。把 probability-flow ODE 转 SDE 让每个去噪步变成显式 Gaussian,从而能算解析 log-prob;默认只采单步、只多一次 DiT forward。这是把 diffusion/flow policy 接进 on-policy RL 的工程关键,且 chunk 级 reward/advantage 与 decoder 输出粒度天然对齐。
-
RL 单环境训、跨环境测的实验设计。刻意只在 SimplerEnv 收 rollout,然后看 RoboCasa/RoboTwin/LIBERO/DOMINO 是否保持——这是对"RL 是否引入过拟合/遗忘"的诚实检验,结论是温和正迁移。
5.2 做得不够好的地方 / 值得质疑的地方¶
-
"单一 generalist 超过 specialist"的口径需要谨慎。Table(§4.1)里 specialist 各自 per-benchmark fine-tune,而 Qwen-VLA-Instruct 是经过 SFT + RL(在 SimplerEnv 上专门优化) 的。Simpler-WidowX 的 73.7% 恰恰是 RL 直接优化的环境,拿它去和"未做 RL 的 specialist"比并不完全对等。真正的同台是 Qwen-VLA-Base(generalist 无 RL),而 Base 在多数 benchmark 明显落后 specialist(LIBERO 90.8 / RoboCasa 40.4)。
-
RL 的"跨环境迁移"被叙述放大了。Table(§4.6)里除 SimplerEnv 本身(+2.9pp)外,RoboCasa +0.7、RoboTwin-Hard +0.1、LIBERO +0.1、SimplerOOD +0.4,全部在噪声量级。把这说成"task-success optimization 带来正迁移"过强;更准确的结论是"RL 在训练环境涨、在其它环境基本不变(没退化)"。
-
DOMINO 零样本 26.6% 超过 fine-tuned PUMA 的归因含糊。作者归功于"flow-matching 产生 coherent action chunk 减少 hesitation + 大规模预训练 prior",但这是定性叙事,没有针对性消融(比如换成离散 token decoder、或去掉预训练比较)。动态操作零样本胜过专门微调的方法,是个很强的 claim,证据链偏弱。
-
VL co-training 的代价被淡化。Limitations 里一句"action 训练会 modestly regress 部分纯 VL 和 navigation 评测",但正文没给 backbone 在标准 VL benchmark 上训练前后的对比数字。既然卖点之一是"保留 Qwen3.5 的感知推理能力",缺这组数据是明显空白。
-
proprietary 数据 + 自研仿真占比巨大但不可复现。in-house 真机 >1,000h(~20%)、自研 RoboInF 仿真 359,848 条 + language-action 7.2M 条,合计是预训练主力之一,但 RoboInF 细节"见 blog post",无法独立验证。74.2% manipulation 里多少来自不可获取的私有源没有拆清。
-
T2A 主要靠"零物理零渲染"的运动规划合成数据(7.2M 条纯运动学、cuRobo 规划、无接触动力学)。这种 kinematically idealised 轨迹建立的 action prior 是否会让模型对接触/力控任务有系统性偏差?消融里"纯 syn 64% vs 20%syn+80%real 71%"已暗示 real 数据在锚定物理动力学上不可或缺,但最终 prior 仍以合成为主体,风险未被讨论。
-
"current-frame only"是架构假设而非优势。模型基本基于单帧/当前观测预测动作 chunk(state-conditioning 消融也据此论证"相对位移预测不需要显式 state")。这等于假设动作只依赖当前帧——对需要历史、力觉、接触状态的任务(精细插拔、可变形物体、长程依赖)是硬限制。Towel Folding(真机 65.4 落后 π0.5 的 80.8)可能正是这个短板的体现。
-
egocentric 数据 6% 的实际贡献没有单独消融。论文花大篇幅讲 eigengrasps、MANO、四个 ego 数据集,但没有"去掉 ego 数据"的对照,无法判断这 6% 到底带来多少下游收益,还是主要为了叙事完整性。
-
navigation 联合训练实为轻微拖累。Limitations 自承 action 训练会 regress navigation;§4.3 里 Qwen-VLA-Instruct 虽在多数指标领先,但 nDTW(57.1)低于 NaVILA(58.8)和 StreamVLN(61.9),说明轨迹保真度上联合训练有代价。
-
评测仍以短程、benchmark 为主。作者自己在 Limitations 承认 long-horizon、failure-prone 的真实部署是 open challenge。当前所有数字都来自相对受控的 suite,"通才"在长时序鲁棒性上的真实水平未知。
5.3 值得继续探讨的方向¶
- co-prediction 未来视觉状态 → world model:作者在 §2.1 与 Conclusion 明确点到"output 轴上 co-predict future visual states 即可统一 action generation 与 world modeling"。这是把本文从"action 接口"推向"world model + action"的自然下一步(对照站内 Pelican-Unified 的联合 video+action DiT)。
- 用 latent-action IDM 替换/补充手工 action 表示:egocentric 现在靠 MANO + PCA eigengrasps 显式编码,能否像 LAPO/LA-Pose 那样用自监督 latent action 统一人/机器人动作空间,减少对显式 pose 标注的依赖?
- 接触/力觉信号注入:state-conditioning 消融结论是"视觉够用所以不要 state",但那是在 vision 可见末端的任务上得出的;引入 tactile/force/proprioception 对插拔、可变形物体是否能突破 current-frame 假设?
- RL 的环境多样性:当前 RL 只在 SimplerEnv,跨环境基本无增益。把 rollout 扩到多环境(RoboTwin/RoboCasa)后,task-success 优化能否带来真正的跨域提升而非仅训练环境内涨?
- VL 能力退化的定量刻画与缓解:给出 backbone 在标准 VL benchmark 上 co-training 前后曲线,并尝试更好的 objective balancing / 数据课程 / 模块化专门化。
- 长时序 + episodic memory:把 \(o_t\) 扩展为带历史/记忆的上下文,验证统一框架在真正长程任务上的失败恢复与重规划能力。