VibeThinker-3B: 在小模型里逼近可验证推理的前沿¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
- 作者: Sen Xu, Shixi Liu, Wei Wang, Jixin Min, Yingwei Dai, Zhibin Yin, Yirong Chen, Xin Zhou, Junlin Zhang(Sina Weibo Inc. 新浪微博)
- arXiv 编号: 2606.16140 (technical report, June 2026)
- 代码 / 权重: GitHub: WeiboAI/VibeThinker,HuggingFace: WeiboAI/VibeThinker-3B
- 关键词: small language model, verifiable reasoning, post-training, RLVR, MGPO, curriculum SFT, self-distillation, test-time scaling
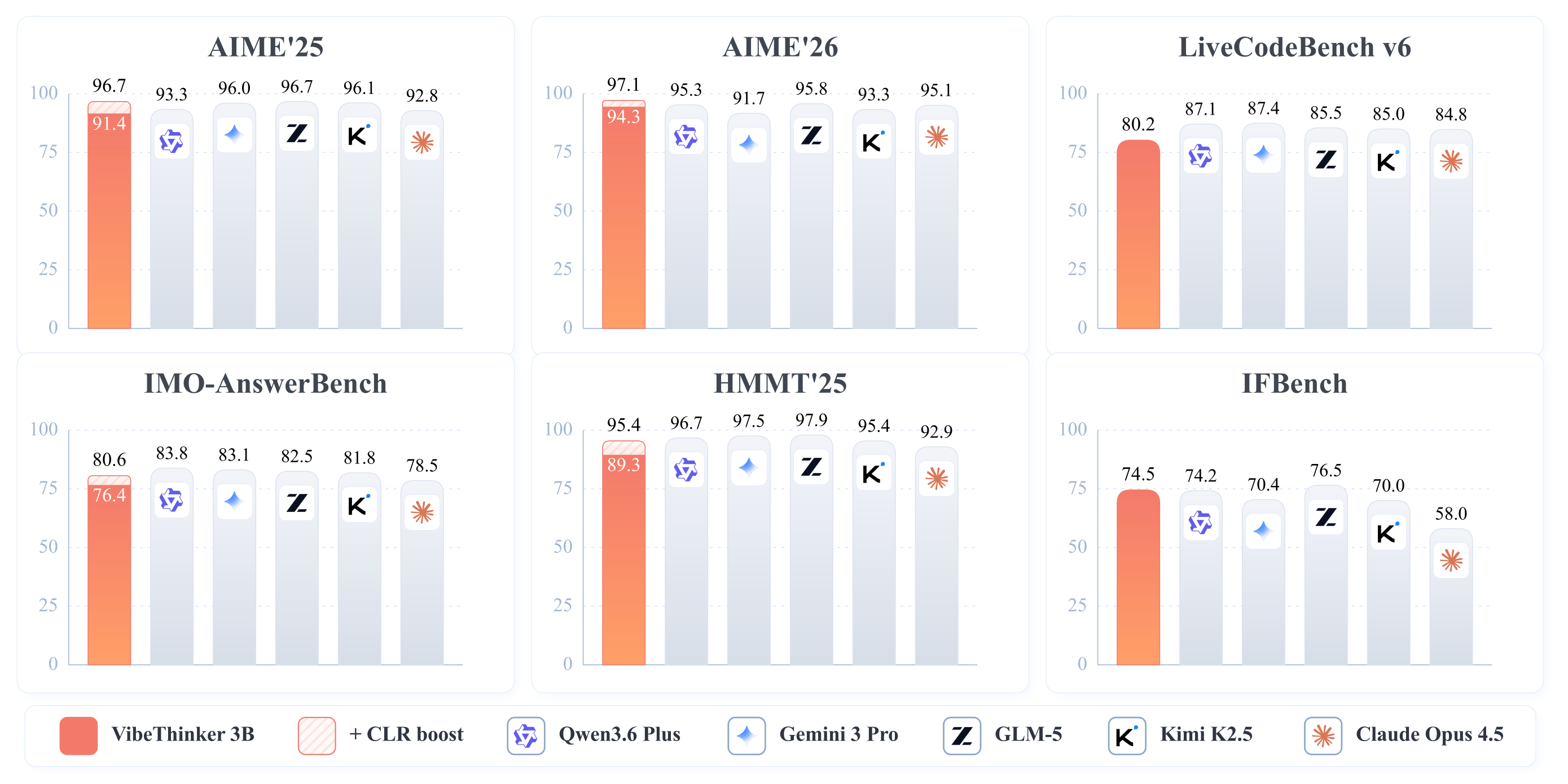 Figure 1:仅 3B 参数的 VibeThinker-3B 在 AIME/HMMT/BruMO/LiveCodeBench 等可验证推理基准上进入第一梯队;CLR 指 Claim-Level Reliability Assessment 这一 claim 级别的 test-time scaling 策略,能进一步把数学分数顶到接近满分。
Figure 1:仅 3B 参数的 VibeThinker-3B 在 AIME/HMMT/BruMO/LiveCodeBench 等可验证推理基准上进入第一梯队;CLR 指 Claim-Level Reliability Assessment 这一 claim 级别的 test-time scaling 策略,能进一步把数学分数顶到接近满分。
2. 文章介绍¶
2.1 解决的领域和问题¶
这是一篇典型的 post-training / RLVR(RL with verifiable rewards)技术报告,主题是"小语言模型(SLM,≤3B)在可验证推理任务上的能力上界到底有多高"。当前主流叙事是:复杂逻辑推理能力靠 scaling law 堆参数获得,前沿推理能力集中在几十亿到上万亿参数的大模型里,而 3B 级别的小模型被默认在困难数学推导和复杂编程上存在"先天瓶颈"。
本文要回答的具体问题是:严格 3B 的稠密模型,能不能在 verifiable reasoning(数学、代码)上达到和 DeepSeek V3.2、GLM-5、Gemini 3 Pro 这类旗舰模型相当的水平? 注意它刻意把范围限制在"可验证"任务上,不碰开放域知识问答(GPQA 这类反而是它的短板)。
2.2 Motivation¶
作者上一篇 VibeThinker-1.5B 证明了"小模型也能产出完整、连贯的推理链"——但那只是"feasibility(可行性)",1.5B 的能力上界还没被探明。本文把规模从 1.5B 提到 3B,问的是一个更尖锐的问题:进入第一梯队推理所需的参数门槛究竟在哪里?
更深一层的 motivation 是为一个假说提供经验证据——他们提出 Parametric Compression-Coverage Hypothesis(参数压缩-覆盖假说):
- parameter-dense capabilities(参数稠密型能力):可验证推理属于此类。核心挑战是在结构化解空间里做 search、constraint satisfaction、error correction、multi-step composition,而不是记忆海量事实,因此可以被高度压缩进一个紧凑、可复用的 "reasoning core"。
- parameter-expansive capabilities(参数扩张型能力):开放域知识 / 通用能力属于此类。需要覆盖海量事实、概念、长尾场景,本质是一个 coverage 问题,必须靠大参数量。
由此引出 Reasoning-Knowledge Decoupling Paradigm:推理深度和知识广度只是部分耦合,小模型完全可以承载高密度推理引擎。这就解释了为什么 VibeThinker-3B 在数学/代码上能打旗舰,却在 GPQA-Diamond 这类知识密集型基准上仍有明显差距。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 本文眼中的局限 |
|---|---|---|
| 大模型 scaling 推理 | DeepSeek R1/V3.2, GLM-5, Kimi K2.5 | 前沿推理被默认要几百 B~1T 参数,部署成本高、学术不可及 |
| 小模型推理可行性 | VibeThinker-1.5B(自家前作) | 只证明"能推理",没探到能力上界;RL warm-up 用渐进 context 扩展 |
| 渐进 context 扩展 RL | DeepScaleR | 在更强的 3B 初始化下反而有害(见 §3) |
| 多阶段长度截断 RL | 通用 RLVR pipeline | 高截断早期阶段会破坏已有的长链推理行为,难以恢复 |
2.4 论文解决方案(一句话)¶
以 Qwen2.5-Coder-3B 为底座,沿用 Spectrum-to-Signal 范式,用「课程式两阶段 SFT(构建多样解空间)→ 多域 MGPO RL + Long2Short 效率优化 → 离线自蒸馏 → Instruct RL」的完整 post-training 流水线,把一个 3B 稠密模型推到可验证推理的第一梯队。
2.5 与前序工作的关系¶
直接续作 VibeThinker-1.5B,继承两大核心组件:
- Diversity-Exploring Distillation(SFT 阶段构建 "Spectrum",宽解空间)
- MGPO = MaxEnt-Guided Policy Optimization(RL 阶段放大 "Signal",高价值推理信号)
底座是 Qwen2.5-Coder-3B base(注意是 coder 版本作底,可能解释其编程强项)。3B 相比 1.5B 不只是参数翻倍,而是补齐了一整套 post-training 系统:能力构建、推理放大、效率优化、指令对齐。
3. 方法介绍¶
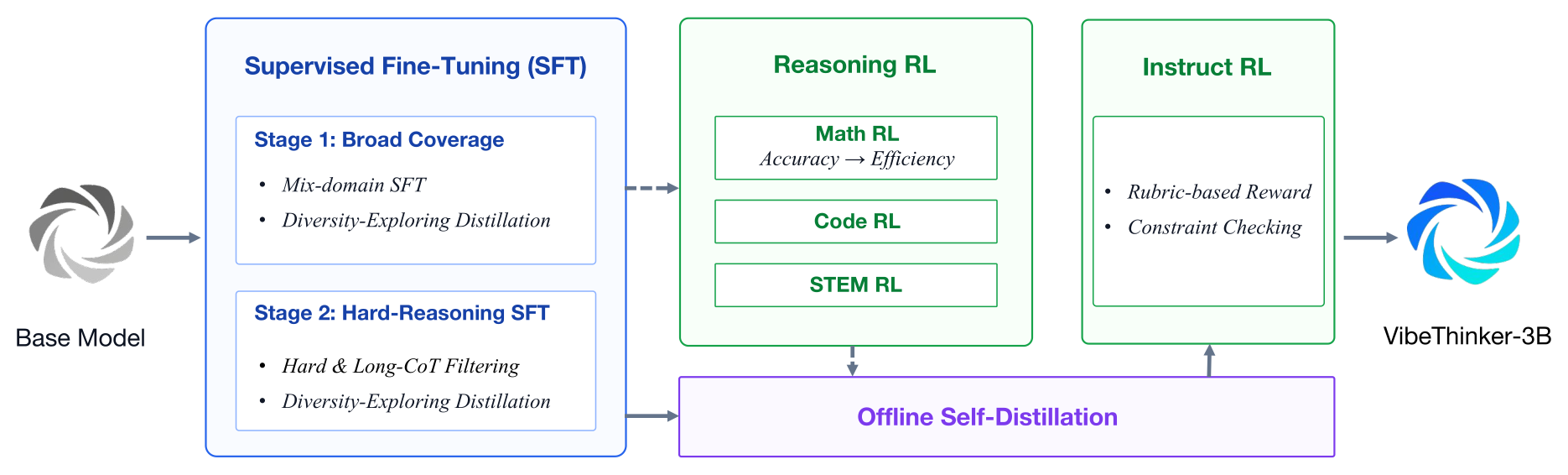 Figure 2:整体流水线。Base Model → 两阶段 SFT(广覆盖 + 难推理)→ 顺序多域 Reasoning RL(Math→Code→STEM,Math 内含 Accuracy→Efficiency 两段)→ 各阶段 checkpoint 喂给 Offline Self-Distillation → Instruct RL → VibeThinker-3B。
Figure 2:整体流水线。Base Model → 两阶段 SFT(广覆盖 + 难推理)→ 顺序多域 Reasoning RL(Math→Code→STEM,Math 内含 Accuracy→Efficiency 两段)→ 各阶段 checkpoint 喂给 Offline Self-Distillation → Instruct RL → VibeThinker-3B。
3.1 整体范式:Spectrum-to-Signal Principle (SSP)¶
核心思想分工明确:SFT 负责构建尽可能宽的解空间(Spectrum),RL 负责在其中放大正确的推理信号(Signal)。所以 SFT 阶段刻意不追求单条最优解的拟合,而是保留多样性,为 RL 的 on-policy exploration 留足探索基础。
3.2 Supervised Fine-tuning¶
数据构建:
- Data Synthesis & Query Expansion:只从有可靠监督信号的数据里选 seed query(数学要有可信最终答案,编程要有可执行测试),再沿 concept composition / problem skeleton / constraints / evaluation objective 多维度改写扩展;合成 query 用强 teacher 多次采样 + majority voting 生成伪标签。
- Multi-path Reasoning Distillation:每个 query 用 teacher 采多条 reasoning trace,保留完整中间步骤而非只留单一标准解,让模型学到多种分解 / 推导 / 验证策略。
- Multi-level Quality Control:(1) N-gram 过滤(去重复退化 + 去测试集污染);(2) LLM 评 query 质量;(3) Trace correctness 过滤(答案校验 + 代码沙箱执行 + LLM majority voting)。
训练过程 — Curriculum 两阶段 SFT:
- Stage 1(广覆盖冷启动):全量质控数据,最大化任务类型和推理模式多样性。用 sequence packing 提效。global batch 128,lr 5e-5 → cosine 退火到 8e-8,5 epochs,5% warmup。
- Stage 2(难推理):从 Stage 1 末 checkpoint 续训,数据偏向高难度长链。过滤规则:丢弃 reasoning trace < 5K tokens 的样本;用 VibeThinker-1.5B 作 reference,每题 8 次 rollout,错误率 < 0.75 的"太简单"题被丢掉。同超参再训 2 epochs。
Diversity-Exploring Distillation:周期保存中间 checkpoint,在各域 probing set 上按 Pass@K 选 specialist(而非按 val loss 或 Pass@1),再做参数级 model merging 合成统一 SFT 模型,兼顾各域能力与输出多样性。
3.3 Reinforcement Learning — MGPO 算法骨架¶
每个 prompt \(q\) 采 \(G\) 条 response,计算 group accuracy:
MGPO 的核心是按"离最大熵点 0.5 的距离"给 prompt 加权——太难(p≈0)信号稀疏、太易(p≈1)已饱和,都降权;只重点学边界附近样本:
该权重乘进 GRPO 式 clipped objective 的 group-relative advantage 上。直觉:把更新集中到不确定性充分的 prompt,产生更稳健健康的梯度,并抑制对高概率 token 的过优化。
稳定性调整:3B 保持 MGPO 公式不变,但发现随着 rollout 引擎为吞吐做优化,training-inference 概率失配(mismatch)被放大、可能让 RL 崩溃。解法是采用 mismatch 稳定化策略,所有 RL 阶段都跑严格 on-policy。
3.4 Multi-domain Reasoning RL¶
顺序 pipeline:Math RL → Code RL → STEM RL,共享 MGPO,但 reward 来源不同(数学=答案校验,代码=沙箱+测试,STEM=答案匹配+选项校验)。各域 checkpoint 都保存下来供后续自蒸馏。训练前先剔除起始 checkpoint 上 accuracy 恰为 0.0 或 1.0 的样本。
Single Long-context Learning(一个关键反直觉发现):DeepScaleR / 自家 1.5B 都靠"渐进扩 context window"省成本+提分,但在 3B 上这个结论翻转了。作者发现高截断早期阶段会削弱长思考能力、把策略偏向不完整 / 过短的推理轨迹,且后期扩窗也难恢复。猜测原因:3B 的 SFT 初始化更强、无效推理模式更少,所以高截断 warm-up 不再是"去噪",反而破坏已有的高质量长链推理。结论:直接用单一 64K 长 context 跑 RL,减少 rollout 截断。
Long2Short Math RL(accuracy → efficiency 两段):第一段标准 MGPO 拉准确率;第二段把目标扩展到 token 效率。做法是只在每个 prompt group 的正确轨迹之间按长度重分配 reward——给定二元正确性 \(r_i\in\{0,1\}\),对正确集 \(\mathcal{C}\) 定义 brevity score \(s_i=1/L_i\),做 centered 长度感知偏移:
\(\lambda=0.2\)。由于偏移在 \(\mathcal{C}\) 内 centered,\(\sum_{i\in\mathcal{C}}(r_i'-r_i)=0\),零和设计保证组级 reward baseline 不被系统性平移,只重塑正确轨迹间对"更短解"的偏好。
3.5 Offline Self-Distillation¶
用 Math/Code/STEM 三个 RL checkpoint 抽高质量轨迹,再 SFT 回一个统一 student,稳定融合多域能力。
Learning-potential Filtering:先用 domain verifier 做 rejection sampling 去错;再对每条验证过的 teacher trace 算 student 下的长度归一化负对数似然:
分数越高 = teacher 能做对但 student 还没学会 = 蒸馏价值越高。为避免被长度 / 异常 token 干扰,在 domain × length 分桶内排序,剔除极短 trace 和极高分 outlier,最终取中高分段的 trace 混合 Math/Code/STEM 构成自蒸馏集。
3.6 Instruct RL¶
最后把推理增强后的 checkpoint 转成可靠的 user-facing 模型。混合数据含 format-sensitive prompt、长 context 指令、通用对齐样本。有显式约束的样本用 rule-based validator(查格式、顺序、条目数、关键词、任务完成);开放式 prompt 用 rubric-based reward model(helpfulness / coherence / 指令遵从 / 冗余)。在同一 on-policy RL 框架下强化可控性,同时保住前面阶段获得的推理能力。
3.x Implementation Details¶
- 底座: Qwen2.5-Coder-3B base(稠密 3B)
- SFT: batch 128, lr 5e-5→8e-8 cosine, Stage1 5 epochs + Stage2 2 epochs
- RL: 单一 64K context window,全程严格 on-policy;Long2Short \(\lambda=0.2\)
- 推理后端: vLLM;temperature 1.0, top-p 0.95, top-k −1,不额外限制输出长度
- 评测采样: 数学 Pass@1 over 64 次(IMO-AnswerBench 16 次),知识 16 次,代码 8 次
- CLR test-time scaling: 每题 \(K=32\) 候选轨迹,每条抽 \(M=5\) 个 decision-relevant claim;模型自验证给二元 verdict \(v_{k,m}\),非线性聚合 \(r_k=\left(\frac1M\sum_m v_{k,m}\right)^M\)(用 M 次幂重罚含错误中间逻辑的轨迹);按答案等价聚类、选 reliability 加权最大者;整个流程独立跑 8 次取平均
4. 结果对比¶
4.1 核心基准(vs 小 / 大推理模型,节选)¶
| Model | Params | AIME25 | AIME26 | HMMT25 | BruMO25 | IMO-Ans | LCBv6 | OJBench | GPQA-D | IFEval | IFBench |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 79.8 | 84.0 | 73.8 | 83.5 | 48.7 | 62.0 | 23.5 | 76.2 | 89.8 | 59.2 |
| Ministral-3-Reasoning | 14B | 82.9 | 85.0 | 67.1 | 86.7 | 63.4 | 66.0 | 15.1 | 71.2 | 73.9 | 32.3 |
| GPT-OSS-20B (high) | 20B | 91.7 | 90.2 | 76.7 | 86.7 | 61.9 | 61.0 | – | 71.5 | 92.8 | 65.0 |
| Qwen3-235B-A22B-Thinking | 235B | 92.3 | – | 83.9 | – | 70.5 | 74.1 | 32.5 | 81.1 | 87.8 | 51.2 |
| LongCat Flash | 560B | 90.6 | – | 83.7 | – | – | 79.4 | 40.7 | 81.5 | 86.9 | – |
| VibeThinker-3B | 3B | 91.4 | 94.3 | 89.3 | 93.8 | 76.4 | 80.2 | 38.6 | 70.2 | 93.4 | 74.5 |
要点:在 <14B 小模型里全面碾压;LCBv6 (80.2) 超过表里所有模型(含 235B/560B);但 GPQA-D 70.2 明显落后大模型——知识短板。
4.2 对比顶级旗舰 + CLR¶
| Model | Params | AIME25 | AIME26 | HMMT25 | BruMO25 | IMO-Ans | GPQA-D |
|---|---|---|---|---|---|---|---|
| DeepSeek V3.2 | 671B | 93.1 | 94.2 | 90.2 | 96.7 | 78.3 | 82.4 |
| Kimi K2.5 | 1T | 96.1 | 93.3 | 95.4 | 98.3 | 81.8 | 87.6 |
| GLM-5 | 744B | 96.7 | 95.8 | 97.9 | – | 82.5 | 86.0 |
| Gemini 3 Pro | N/A | 96.0 | 91.7 | 97.5 | 98.3 | 83.1 | 91.9 |
| Claude Opus 4.5 | N/A | 92.8 | 95.1 | 92.9 | – | 78.5 | 87.0 |
| VibeThinker-3B | 3B | 91.4 | 94.3 | 89.3 | 93.8 | 76.4 | 70.2 |
| ** + CLR** | 3B | 96.7 | 97.1 | 95.4 | 99.2 | 80.6 | 72.9 |
要点:不加 CLR 时 AIME26 (94.3) 已和 DeepSeek V3.2 / Kimi K2.5 同档;加 CLR 后数学基准基本顶进旗舰簇(AIME26 97.1、BruMO25 99.2)。但 GPQA-D 即使 +CLR 也只到 72.9,仍大幅落后——作者把这当作假说的佐证而非反例。
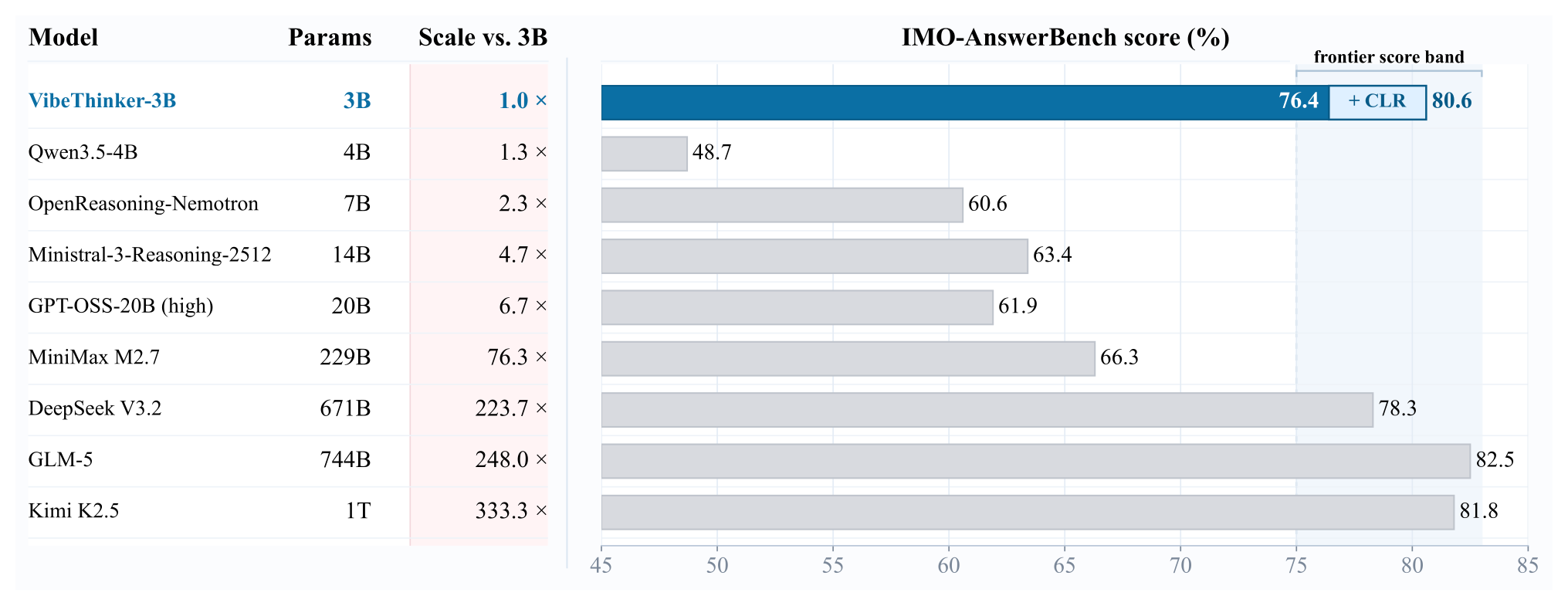 Figure 3:IMO-AnswerBench(400 道 IMO 级题)上的参数效率。VibeThinker-3B 仅 3B 拿到 76.4(+CLR 80.6),落在 DeepSeek V3.2 (78.3, 671B)、GLM-5 (82.5, 744B)、Kimi K2.5 (81.8, 1T) 这些大几百倍模型的区间内。
Figure 3:IMO-AnswerBench(400 道 IMO 级题)上的参数效率。VibeThinker-3B 仅 3B 拿到 76.4(+CLR 80.6),落在 DeepSeek V3.2 (78.3, 671B)、GLM-5 (82.5, 744B)、Kimi K2.5 (81.8, 1T) 这些大几百倍模型的区间内。
4.3 OOD 泛化:近期 LeetCode 竞赛(2026.04.25–05.31,Python 一次提交)¶
| Model | Overall (通过/总数) |
|---|---|
| GPT-5.3-Codex | 100.0% (128/128) |
| Gemini 3.1 Pro | 99.2% (127/128) |
| Gemini 3 Flash | 96.9% (124/128) |
| VibeThinker-3B | 96.1% (123/128) |
| GPT-5.2 | 95.3% (122/128) |
| Kimi K2.5 | 90.6% (116/128) |
| Claude Opus 4.6 | 86.7% (111/128) |
| GLM-5 | 76.6% (98/128) |
要点:这是全新、未见过的题,execution-verified,比 LiveCodeBench/OJBench 更能说明非记忆泛化。3B 模型以 96.1% 超过 GPT-5.2、Kimi K2.5、Qwen3-Max、Claude 4.6 等,仅次于 GPT-5.3-Codex / Gemini 3.x。
4.4 关键设计的经验结论(散见正文,非独立消融表)¶
| 设计 | 结论 |
|---|---|
| 渐进 context 扩展 RL | 在 3B 上有害(与 1.5B 相反),改用单一 64K 长 context |
| Curriculum 两阶段 SFT | Stage2 丢弃 <5K token & 易题,迫使聚焦长链推理 |
| Long2Short | 零和 reward 重分配,降冗余 token 不掉准确率 |
| CLR test-time scaling | 数学基准普遍 +3~6 分,且比 trace 级自验证省 token |
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 反直觉的 single long-context 发现很有价值:直接挑战了 DeepScaleR / 自家 1.5B 的"渐进扩窗"经验,并给出了机制解释(更强 SFT 初始化下,高截断 warm-up 从"去噪"变成"破坏长链行为")。这种"在更强 baseline 上旧 trick 反转"的观察对社区很有参考意义。
- Long2Short 的零和 reward 设计干净:只在正确轨迹间 centered 重分配,数学上保证组级 baseline 不漂移(\(\sum(r_i'-r_i)=0\)),不污染 advantage 估计——比直接加长度惩罚项更稳。
- MGPO 的最大熵加权 + 严格 on-policy:把更新集中在能力边界(p≈0.5)的 prompt 上,配合 train-infer mismatch 稳定化,针对 RLVR 训练崩溃这个真实痛点。
- Diversity-Exploring Distillation 用 Pass@K 选 checkpoint + 参数级 merge:明确为后续 RL 保留解空间多样性,而不是 SFT 阶段就过早收敛到单一最优解,和 SSP 范式自洽。
- OOD LeetCode 竞赛评测有说服力:用训练数据日期之后(04.25–05.31)的全新竞赛题、execution-verified、一次提交,比静态 benchmark 更难反驳"只是拟合了 benchmark 分布"。
- 诚实标注短板:明确承认 GPQA-Diamond 落后,并把它整合进 Compression-Coverage 假说,而不是藏起来。
5.2 做得不够好 / 值得质疑的地方¶
- 没有真正的 ablation 表。全文的关键设计(curriculum SFT、Long2Short、self-distillation、Instruct RL、single long-context)几乎都只有"我们这样做了 + 散文式结论",没有 with/without 的对照实验。例如 Long2Short 到底省了多少 token、掉不掉分,文中无量化曲线。对一篇主打方法论的报告这是硬伤。
- 底座是 Qwen2.5-Coder-3B,这本身就是为代码强化过的模型。LiveCodeBench/LeetCode 的强表现有多少来自 post-training、多少来自底座先验,无法分离。缺少"同 pipeline 套在通用 3B 底座上"的对照。
- CLR 把比较口径搞乱了。表 2 里 VibeThinker 用 +CLR(K=32 候选 + 自验证,等于 32+ 倍推理算力)去和旗舰模型的单次 Pass@1 比。这不是同等 test-time budget 的公平对比——旗舰模型若也做同等 test-time scaling,差距会重新拉开。"3B 媲美 1T"的标题党成分主要来自这里。
- 对手分数全是"采集来的"。§Eval 明确写 comparison 模型分数来自 released report / leaderboard / official record,采样设定、prompt、decontamination 标准未必一致。自己 64 次采样 Pass@1 平均 vs 别人报告的数字,可比性存疑。
- decontamination 仅靠 n-gram。AIME25/HMMT25 等是公开竞赛题,2606 这个时间点的模型在 04–05 月竞赛上的"OOD"成色,取决于训练数据截止与去污染的严格度,而 n-gram overlap 过滤对改写 / 同题异构很脆弱。
- Compression-Coverage Hypothesis 证据偏单薄。它本质是"数学/代码强、GPQA 弱"这一个观察的归纳,缺少更细粒度证据(如不同知识密度任务的连续 scaling 曲线)。作为"hypothesis"提出尚可,但正文措辞("elucidates why...")有点过度推断。
- AIME26/HMMT25 这种小样本(每年 ~30 题)基准的方差。即使 64 次采样平均,单题对错的权重仍很大;94.3 vs 94.2(DeepSeek V3.2)这种小数点级别的"匹配/超越"叙事意义有限。
- 缺推理成本数据。3B 模型的卖点是部署效率,但全文没给延迟、吞吐、单题平均 token 数(尤其 Long2Short 之后)、以及 CLR 的实际算力开销。"省 token"只有定性描述。
- Instruct RL 一笔带过。作为"不牺牲可控性"的关键论据(IFEval 93.4),它的数据规模、reward model 细节、是否回退推理能力都没展开。
- 未开源训练数据 / 合成 pipeline 细节。teacher 模型是谁、合成 query 占比多少、self-distillation 数据量级都未披露,复现门槛高。
5.3 值得继续探讨的方向¶
- 公平的 test-time scaling 对比:在相同 inference budget(如都给 K=32 + self-verify)下重测旗舰 vs VibeThinker,看"3B 媲美旗舰"还剩多少。
- 底座消融:把整套 pipeline 套到通用 3B(如 Qwen3-3B 非 coder)底座上,分离底座先验 vs post-training 的贡献。
- Compression-Coverage 的量化验证:设计一组知识密度连续变化的任务,画 3B/7B/14B... 的 scaling 曲线,看"推理 vs 知识"是否真的解耦。
- Single long-context 结论的边界:到底是"初始化更强"还是"3B 这个规模"导致渐进扩窗失效?在 7B/1.5B 上做交叉验证。
- Long2Short 的极限:能压到多短而不掉分?\(\lambda\) 敏感性如何?是否能和 CLR 联动(短轨迹 + claim 验证)。
- 知识短板的补救:能否用 RAG / 工具调用让 3B 在 GPQA 这类任务上补齐,从而验证"推理核心 + 外接知识"的解耦架构。