QGF: Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
- 作者:Zhiyuan Zhou¹、Andy Peng¹、Charles Xu¹、Qiyang Li¹、Tobias Springenberg²、Kevin Frans¹、Sergey Levine¹² — ¹UC Berkeley, ²Physical Intelligence
- arXiv 编号:2606.11087(2026-06 提交,preprint)
- 代码:
https://github.com/zhouzypaul/qgf - 关键词:offline RL、flow matching policy、test-time policy improvement、classifier guidance、critic gradient、action chunking、IQL、OGBench、best-of-N
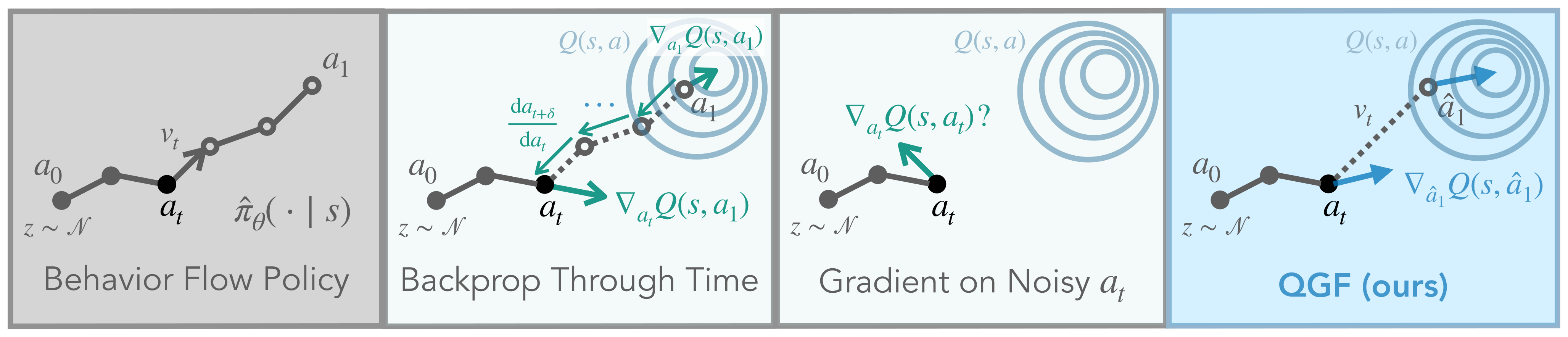 Figure 1:QGF 的核心一图——在 flow policy 的每个去噪步,先用一个大步 Euler 积分把噪声动作"投影"成近似干净动作 â₁,在 â₁ 上取 critic 梯度(绿色路径),既不在 critic 没见过的噪声动作上取梯度(QFQL 的问题),也不做穿越整条去噪链的 BPTT(贵且高方差)。
Figure 1:QGF 的核心一图——在 flow policy 的每个去噪步,先用一个大步 Euler 积分把噪声动作"投影"成近似干净动作 â₁,在 â₁ 上取 critic 梯度(绿色路径),既不在 critic 没见过的噪声动作上取梯度(QFQL 的问题),也不做穿越整条去噪链的 BPTT(贵且高方差)。
2. 文章介绍¶
2.1 解决的领域和问题¶
Offline RL 中的 policy extraction / policy improvement 问题,专门针对 flow matching / diffusion 这类表达力强的迭代去噪策略。这类策略在监督式 behavioral cloning (BC) 下训练稳定、scale 友好(已是 π 系/各家 VLA 的标准 action head),但要让它们超越数据集行为去最大化 reward,现有做法都要动训练过程:要么设计专门的 RL 训练目标(FQL 蒸馏、QAM adjoint matching、DAC/QSM score 匹配),要么对去噪链做 backpropagation through time(DQL 谱系),不稳定、难调、伤 scaling。
论文问的问题很直接:能不能完全不碰策略训练(保持纯 BC),把 reward 最大化全部推迟到推理时做?
2.2 Motivation¶
- Actor-critic 的不稳定根源在"actor 追逐一个不断变化的 critic"这个耦合训练动态。如果 actor 只做监督学习、critic 只做 in-sample TD 学习(IQL),两者完全解耦,训练就回到了稳定可扩展的领域。
- 测试时已有 critic 在手,最朴素的用法是 best-of-N(采 N 个动作选 Q 最高的),但高维动作空间(action chunking 下 5 步 chunk)里 N 需要很大、FLOPs 数量级地贵。
- 用 critic 的梯度 \(\nabla_a Q(s,a)\) 来引导去噪过程(classifier guidance 的 RL 版)信息效率高得多——问题只在于:梯度该在哪个点取? 这是全文的核心技术问题。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Train-time:BPTT 穿越去噪链 | DQL、DiffCPS、EntDiff 等 | 反传穿越多步去噪,贵、不稳定(FQL 论文已指出)、梯度方差高 |
| Train-time:蒸馏一步策略 | FQL、OneStep | 额外蒸馏网络,有表达力损失;蒸馏-优化耦合 |
| Train-time:adjoint matching | QAM | 避开 BPTT 但训练时 critic-policy 仍耦合;本文实验显示模型变大性能不涨 |
| Train-time:噪声动作 score 匹配 | QSM、DAC | 用的就是"OOD 梯度"方向(在噪声动作上取 \(\nabla_{a_t}Q\)),critic 没在那里训练过 |
| Test-time:best-of-N | IDQL、BFN (Li et al.) | 高维 action chunk 下要 N 很大,FLOPs 比梯度法高几个数量级 |
| Test-time:只改最终动作 | PA-RL / GradStep | 去噪完成后再爬坡几步,不引导生成过程本身,提升有限 |
| Test-time:OOD 梯度引导 | QFQL | 在噪声动作 \(a_t\) 上直接取 \(\nabla_{a_t}Q(s,a_t)\)——critic 只在干净动作上训过,梯度有偏;1D 解析例子显示无论 guidance weight 多大都收敛到次优动作 |
| Test-time:optimality conditioning | CFGRL | 不用 critic 梯度,靠 advantage 条件 + CFG;实验中明显弱于 QGF |
2.4 论文解决方案(一句话)¶
在每个去噪步,用一个大步 Euler 积分 \(\hat a_1 = a_t + (1-t)\,v_\theta(s,a_t,t)\) 把噪声动作便宜地"投影"到近似干净动作,在 \(\hat a_1\) 上取 critic 梯度、把 Jacobian 直接替换成单位阵,将该梯度加权进 velocity 完成引导——critic 永远只在自己的训练分布(干净动作)附近被查询,整个 RL 发生在推理时。
2.5 与前序工作的关系¶
- 最近邻是 QFQL(Jang et al., 2025):同样是"BC flow + IQL critic + 测试时梯度引导",唯一区别是梯度取点(噪声动作 vs 一步近似干净动作)——所以这篇论文本质上是对 QFQL 的一个关键修正,主实验里 QFQL 是被反复吊打的对象。
- EDP(Kang et al., 2023)是一步 Euler 近似的先行者,但 EDP 在训练时用它(对参数取梯度),QGF 在测试时用(对动作取梯度)。最好的 train-time baseline 恰好也是 EDP,侧面印证一步近似这个 trick 的有效性。
- Berkeley RAIL 工作群的延续:action chunking 设定与 100M 数据集来自 Li et al. 的 Q-chunking 谱系,goal-conditioned critic 用 DQC(Li et al.),QAM(Li et al., 2026)既是 baseline 又贡献了更强的 critic;CFGRL 是共同作者 Frans 的工作。Levine/Springenberg 的 Physical Intelligence 关联暗示这套东西的目标场景是 VLA 的 action expert——但论文本身没做 VLA 实验。
- 概念上是 classifier guidance(Dhariwal & Nichol)在 KL-regularized RL(closed form \(\pi\propto\hat\pi\cdot e^{Q/\beta}\))下的实例化。
3. 方法介绍¶
3.1 形式化¶
KL 正则化 RL 目标的闭式解:\(\pi(a|s)\propto\hat\pi(a|s)\exp(Q(s,a))^{1/\beta}\),对应 score 分解:
把它延拓到去噪中间步(参考 DAC),就得到"在 flow 的每步 velocity 上加一个 critic 梯度项"的引导式采样。问题归结为:\(\nabla_{a_t}Q\) 在噪声动作 \(a_t\) 上没有定义良好的含义——critic 只在干净动作上训练过。
三种候选梯度:
| 梯度 | 定义 | 问题 |
|---|---|---|
| OOD 梯度(QFQL) | \(\nabla_{a_t}Q(s,a_t)\) | critic 在噪声动作上 OOD,梯度有偏;\(a_t\) 甚至可能不是合法动作 |
| BPTT 梯度 | \(\nabla_{a_t}Q(s,\mathrm{ODE}(a_t))\) | 原则上正确(把噪声动作的 Q 定义为其去噪终点的 Q),但要穿越整条 ODE 反传:贵、对输入噪声极敏感(高方差)、高 guidance weight 下不稳定 |
| QGF 梯度 | \(\hat J^\top\nabla_{\hat a_1}Q(s,\hat a_1)\),其中 \(\hat a_1=a_t+(1-t)v_\theta(s,a_t,t)\),\(\hat J=I\) | 一次额外前向 + 一次 critic 反传;梯度始终在近似干净动作上取 |
3.2 QGF 推理算法¶
输入:状态 s,BC flow vθ,critic Q,guidance weight 1/β,步长 δ=1/T
a₀ ~ N(0, I)
for t = 0, δ, ..., 1-δ:
â₁ ← a_t + (1-t)·vθ(s, a_t, t) # 一步 Euler 投影到干净动作
g ← ∇_{â₁} Q(s, â₁) # 在 â₁ 上取 critic 梯度
a_{t+δ} ← a_t + δ·(vθ(s, a_t, t) + g/β) # 引导去噪
return a₁
两个看似"偷工减料"的选择,实验上都优于更"精确"的对应物:
- 丢掉 Jacobian(\(J=\partial\hat a_1/\partial a_t\approx I\)):完整链式法则要求对 \(v_\theta\) 求导,该 Jacobian 在早期去噪步(一步近似很粗时)病态、放大梯度方差。cosine 敏感性分析显示带 Jacobian 的估计器对输入扰动更敏感;性能上 QGF > QGF-Jacobian,难任务上差距更大。
- 一步近似而非完整 ODE(QGF vs QGF-chain):完整去噪链会把 \(\hat a_1\) 拉回数据集分布的全覆盖,反而限制了引导;一步近似"松绑"后允许 flow 偏向数据分布中的高价值 mode——作者称之为更好的 mode selection 能力。
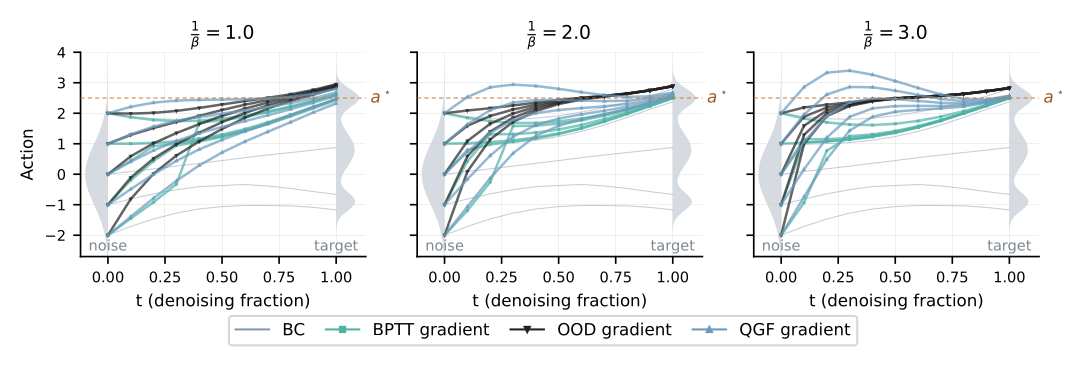 Figure 2:1D 解析例子(噪声 → 三峰分布,Q = 与最优动作 a* 的负距离)。OOD 梯度(QFQL 用的)无论 guidance weight 多大都把流引向错误的峰;BPTT 与 QGF 都能收敛到 a*,但附录显示 BPTT 在高 weight / 某些目标分布下剧烈不稳定。
Figure 2:1D 解析例子(噪声 → 三峰分布,Q = 与最优动作 a* 的负距离)。OOD 梯度(QFQL 用的)无论 guidance weight 多大都把流引向错误的峰;BPTT 与 QGF 都能收敛到 a*,但附录显示 BPTT 在高 weight / 某些目标分布下剧烈不稳定。
3.3 为什么 QGF 是更好的"Q 优化器"¶
把每种梯度估计器看作"以最大化最终动作 Q 值为目标的优化器",论文给出三条互相印证的证据链:
- 噪声敏感性:对 \(a_t\) 加微扰 ε,测 \(\cos(G(s,a_t),G(s,a_t+\epsilon))\)。QGF 的梯度方向最稳定(20 任务 × 4 seeds 平均),带 Jacobian / 走完整链 / BPTT 的都明显更敏感。
- 最终动作的 Q 值:QGF 是所有梯度法里把 Q 推得最高的,接近 best-of-N oracle。
- OOD 梯度的"作弊":OOD 梯度推出的 Q 值甚至比 BFN oracle 还高——但性能很差。附录分析显示其生成的动作到数据集动作的最近邻距离、到 BFN oracle 动作的距离都是所有方法里最大的:它在利用 critic 对 OOD 动作的过估计,不是真的找到了好动作。这是对 offline RL 里 "Q 值高 ≠ 性能好" 的一个干净演示。
3.4 Implementation Details¶
- 训练:actor = 纯 BC flow matching;critic = IQL(expectile τ=0.9,in-sample 学习,与 policy 完全解耦——特意选的,方便单变量比较)。两者都是 4 层 1024 MLP,lr 3e-4,batch 1024,γ=0.999,flow 10 步,500k steps(单任务)/ 1M steps(goal-conditioned)。critic ensemble=2 取 min(GC 的 puzzle 域取 mean)。
- Action chunking:chunk h=5,critic 条件在整个 chunk 上;goal-conditioned 实验用 DQC 双 critic(h_c=25 的长程 critic 蒸馏出 h_a=5 的短程 critic)。
- Guidance weight \(\tau_g=1/\beta\):每个 domain 在 {0.004,…,0.12} 共 9 个值里调(在该 domain 的 task 2、4 上调,然后 task 1–5 全部用 10 seeds 重跑);所有 baseline 同样按 domain 调各自超参。
- 推理开销:每个去噪步 = 1 次 velocity 前向 + 1 次 critic 前向反传,10 步 flow 下约为纯 BC 推理的 2–3×;比 BFN 低几个数量级 FLOPs。
4. 结果对比¶
本文结果全部以 bar chart 呈现(无数字表),以下为图中可读出的结论性排序。
4.1 单任务 offline RL(OGBench,20 任务 × 10 seeds,500k steps)¶
环境:scene、puzzle-4x4、cube-triple、cube-quadruple(各 5 任务),100M transitions 数据集,chunk h=5,所有方法共享同一 IQL critic。
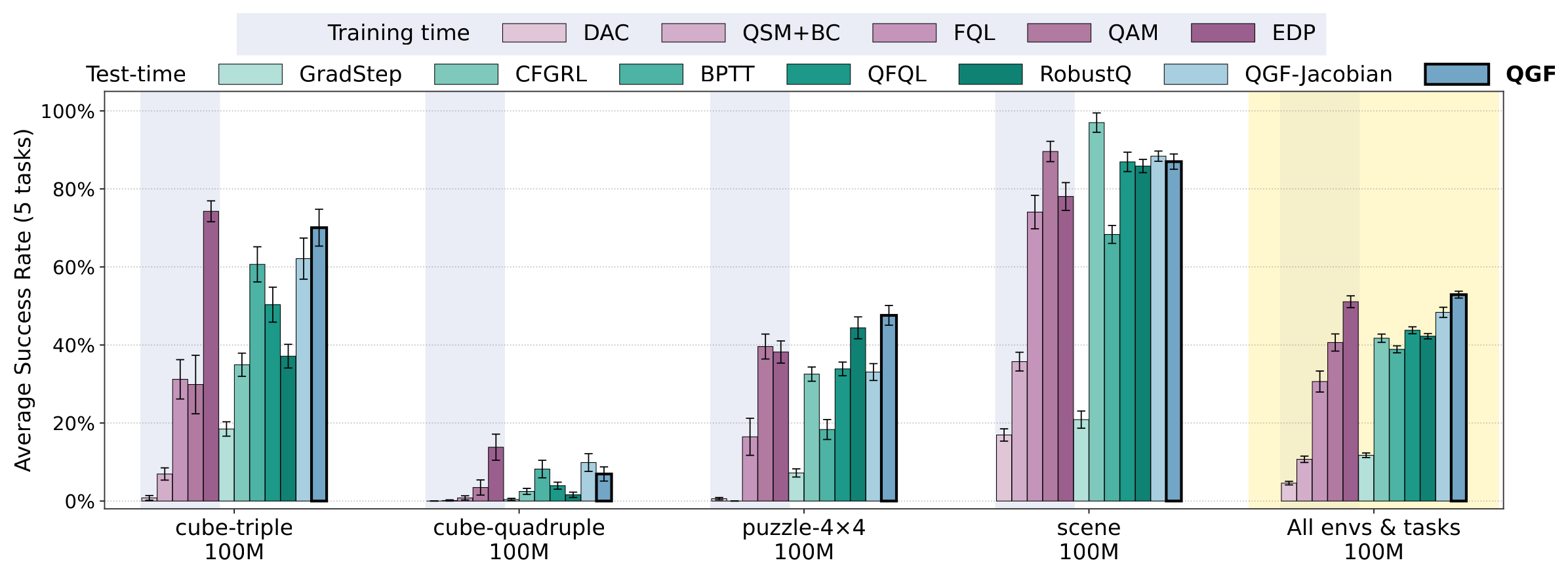 Figure 3:QGF 大幅超过所有 test-time 方法(QFQL、BPTT、RobustQ、GradStep、CFGRL),也超过多数 train-time 方法(FQL、QAM、DAC、QSM+BC),与最强的 EDP 相当且略好。QGF > QGF-Jacobian 确认丢 Jacobian 的选择。
Figure 3:QGF 大幅超过所有 test-time 方法(QFQL、BPTT、RobustQ、GradStep、CFGRL),也超过多数 train-time 方法(FQL、QAM、DAC、QSM+BC),与最强的 EDP 相当且略好。QGF > QGF-Jacobian 确认丢 Jacobian 的选择。
| 比较 | 结论 |
|---|---|
| vs test-time 梯度法(QFQL/BPTT/RobustQ) | 显著领先——梯度取点是决定性因素 |
| vs GradStep / CFGRL | 显著领先——引导每个去噪步 > 只改最终动作 / 无梯度 CFG |
| vs train-time 最强(EDP) | 相当且略好;注意 EDP 也用一步 Euler 近似 |
| QGF vs QGF-Jacobian | QGF 更好,难任务差距更大 |
4.2 测试时计算扩展(best-of-N 组合)¶
| 配置 | 相对 FLOPs | 性能 |
|---|---|---|
| BFN (N=4) | ≫ QGF(数量级) | 不如 QGF |
| BFN (N=16) | 更高 | 略好于 QGF |
| QGF+BFN (N=4) | ≈ BFN(N=4) | 匹配 BFN(N=16) |
梯度引导让每个样本的质量更高,从而用 1/4 的采样预算追平纯采样的上限。
4.3 Goal-conditioned RL(5 个最难环境,25 任务 × 10 seeds,1M steps,DQC critic)¶
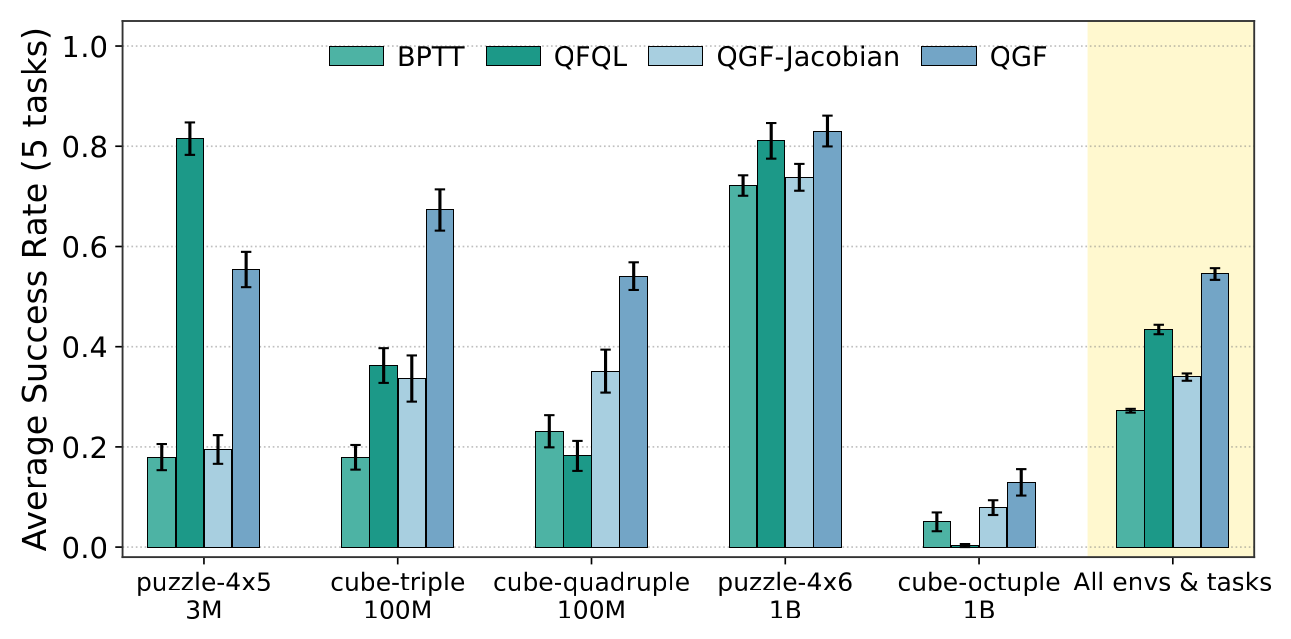 Figure 4:p45 这个最简单环境上 QGF 反而输给 QFQL;但 cube-triple/quadruple、p46-1B、cube-octuple-1B 这些更难、更长 horizon 的任务上 QGF 一致最优,且 QGF > QGF-Jacobian 的差距随难度放大。
Figure 4:p45 这个最简单环境上 QGF 反而输给 QFQL;但 cube-triple/quadruple、p46-1B、cube-octuple-1B 这些更难、更长 horizon 的任务上 QGF 一致最优,且 QGF > QGF-Jacobian 的差距随难度放大。
4.4 模型规模扩展(cube-triple,5 任务)¶
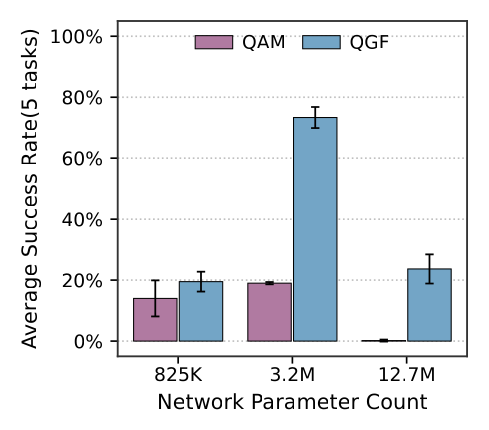 Figure 5:actor+critic 从 800k 扩到 3.2M 参数:QAM(train-time)不涨,QGF 提升近 4×;扩到 12.7M 后两者都过拟合,但 QGF 退化更少而 QAM 直接失效。论文把这归因于"BC 训练避开了 actor 追逐演化 critic 的不稳定"。
Figure 5:actor+critic 从 800k 扩到 3.2M 参数:QAM(train-time)不涨,QGF 提升近 4×;扩到 12.7M 后两者都过拟合,但 QGF 退化更少而 QAM 直接失效。论文把这归因于"BC 训练避开了 actor 追逐演化 critic 的不稳定"。
4.5 换 critic(QAM 训练的 bootstrapped critic,ensemble=10 取 mean)¶
QGF + QAM-critic > QGF + IQL-critic,也 > QAM 本身——QGF 是个与 critic 训练方式正交的 policy extraction 接口,critic 越好它越好。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 把"梯度在哪儿取"这个问题拆解得非常干净:OOD 梯度(有偏)、BPTT(无偏但贵且高方差)、QGF(便宜且低方差)三者用 1D 解析例子、噪声敏感性、Q-优化器视角三套互补证据定位,而不是只靠 benchmark 数字说话。Figure 2 的 1D 例子一眼就能看懂 QFQL 为什么错。
- 对自己的"crude approximation"诚实且追到底:J≈I 看起来像偷懒,作者补了 QGF-Jacobian Smooth / Regularized / Ortho 三个修复变体——发现 ortho(保方向去 scale)能恢复性能,从而把问题精确定位到 Jacobian 的奇异值缩放/方差,而非链式法则本身。这种"为什么近似反而更好"的归因工作比多数论文认真。
- 评测协议把 policy extraction 单变量隔离:所有方法共享同一个 IQL critic(in-sample、与 policy 解耦),10 seeds + 95% CI,按相同预算给每个方法调 domain 超参;还预答了"IQL critic 是否限制 train-time 方法"的质疑(4.5 节换 QAM critic)。
- OOD 梯度"作弊"的分析(附录 C)很有教学价值:Q 值最高 + 性能最差 + 离数据集最远的三角证据,是 offline RL 中 critic exploitation 的一个干净案例研究。
- 实验设定选得对论点有利但不算作弊:action chunking h=5 把动作空间抬到高维,正是 BFN 这类采样法最吃力、梯度法信息效率优势最大的 regime;100M/1B 大数据集保证 BC 上限离 RL 上限有可观 gap。
- 测试时计算的完整账本:FLOPs 对比 + QGF+BFN 组合实验,把"性能-计算"前沿画出来了,而不是只报性能。
5.2 做得不够好 / 值得质疑的地方¶
- "不用调参"的卖点与实际操作矛盾:guidance weight 是在评测环境本身(每个 domain 的 task 2、4)上从 9 个候选里调出来的,且附录敏感性分析显示性能对它非常敏感(过大直接把动作推出数据支撑)。比起 train-time 方法"调一次参重训一次"确实便宜,但"test-time 可调"在真实部署里没有 oracle evaluator 可用——这个卖点的实际含金量要打折。
- 实验世界与动机叙事之间有数量级鸿沟:intro 的故事是"diffusion/flow policy 是 scaling 真机 imitation learning 的 backbone",但全部实验是 OGBench 仿真、state-based 输入、4×1024 MLP,最大 12.7M 参数、无图像、无真机。所谓 favorable scaling 是 800k→3.2M 的 4×——对 VLA 尺度(GB 级 critic、视觉输入)的外推完全是展望。Physical Intelligence 挂名更让人期待一个 π₀.₅ 级实验,没有。
- J≈I 之后理论故事断裂:score 分解推导支撑的是完整链式梯度;换成单位阵后,所加的方向不再是任何明确定义目标的梯度。论文用 random feedback alignment 文献兜底 + 经验验证,但"principled derivation"与最终算法之间有一段未弥合的 gap——1D 例子里 QGF 收敛到 a* 是观察不是定理。
- 早期去噪步的一步近似系统性偏差未检验:t≈0 时 \(\hat a_1\) 基本是"噪声 + 数据分布均值方向",critic 梯度此时指向的可能是均值附近的高 Q mode。"mode selection" 假说(QGF-chain 受制于全分布覆盖、QGF 能选 mode)只有间接证据,没有直接可视化或对 multimodality 的控制实验。
- 离线、静态 critic 是隐含前提:整个方法依赖一个固定的、in-sample 训练的 critic。online RL 下 critic 随 policy 演化时,guidance 推 policy 出 critic 训练分布 → critic 又被新数据更新 → 引导方向漂移,这个反馈环的稳定性完全没碰。而"test-time RL"真正诱人的场景(部署中持续改进)恰恰是 online 的。
- BFN(N=16) 仍然略胜 QGF 单独使用:纯性能上限的王座还在 best-of-N 手里,QGF 的胜利是 compute-efficiency 的胜利;论文标题级的"competitive with the best train-time baseline"也意味着没有真正越过 EDP。把 QGF 描述成"better"还是"cheaper-at-same-quality",措辞上论文偏向前者,数据更支持后者。
- 基准覆盖窄:7 个环境全部是 OGBench manipulation(scene/puzzle/cube 三族),没有 locomotion、AntMaze、D4RL 经典套件,也没有任何视觉输入任务。"manipulation 数据 coverage 低所以更难"的理由成立,但也意味着结论的外推范围未知;而且在最简单的 p45 上 QGF 输给 QFQL,论文只一句带过,没有分析何时 OOD 梯度反而够用(这本可以是个有信息量的边界条件)。
- 新造 baseline 的强度存疑:BPTT 和 RobustQ 是作者自构的 baseline,QFQL/CFGRL 等也由作者复现/适配;超参 sweep 范围统一是公平的,但"被修正的方法"由"提出修正的人"调参,天然有 garden-of-forking-paths 风险。QFQL 原文如果有不同的 critic 训练配方,这里统一成 IQL 后是否还原了其最佳状态,无从知晓。
- 方差→性能的因果链是相关性堆叠:噪声敏感性低 → Q-优化器好 → benchmark 好,每一环都是经验相关;缺一个控制实验(例如对 QGF 梯度人为注入可控噪声,看性能单调退化曲线)来钉死"方差是机制"这个解释。
5.3 值得继续探讨的方向¶
- 上 VLA 实测:把 QGF 接到 π₀.₅/π₀.₆ 级 flow action expert 上(critic 可来自 RECAP/RLT 式真机数据),QGF 作为"无需重训 policy 的部署期 policy improvement 接口"——这是这篇论文最自然的下一步,也是检验 2-3× 推理开销在 50Hz 控制下是否可行的关键。
- Online / iterated 设定:critic 周期性用 QGF-引导策略收集的数据更新,研究 guidance-critic 反馈环的稳定性;与 RECAP 的 advantage conditioning 正面对比(同为"不靠 policy gradient 的改进算子")。
- 自适应 guidance weight:按去噪时间 t 调度(早期小、后期大?),或用 critic ensemble disagreement 在 OOD 区域自动衰减 guidance——把"调参敏感"变成"自适应"。
- chunk 长度 scaling:h=5 → 25/50(VLA 常用),动作维度更高时 BFN 更糟、QGF 的相对优势理论上应扩大,值得画一条 h-scaling 曲线。
- 与蒸馏闭环:用 QGF 引导生成高质量数据 → distill 回 policy → 再引导,相当于把 test-time 改进摊销回权重(test-time→train-time 蒸馏,类似 LLM 里 best-of-N 蒸馏的做法)。
- 理论补洞:什么条件下(velocity field 的 Lipschitz/收缩性?)J≈I 引导保证收敛到 \(\pi\propto\hat\pi e^{Q/\beta}\) 的高密度区?1D 例子能否推广成证明?
- 视觉输入 + 大 critic 的推理优化:critic 梯度只需要对动作维度,视觉 encoder 可缓存——工程上 QGF 在视觉任务的真实开销可能远小于 2×,值得量化。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 关键相关论文:
- QFQL (Jang et al., 2025) — 被修正的最近邻:OOD 梯度引导
- EDP (Kang et al., 2023) — 一步 Euler 近似的 train-time 先行者,本文最强 train-time baseline
- FQL (Park et al., 2025)、QAM (Li et al., 2026)、DQC (Li et al., 2025) — Berkeley RAIL flow-policy offline RL 谱系
- IDQL / BFN (Hansen et al., 2023; Li et al., 2025) — best-of-N 路线
- CFGRL (Frans et al., 2025) — optimality conditioning + CFG 路线
- IQL (Kostrikov et al., 2021) — critic 训练
- OGBench (Park et al., 2024) — 评测基准