LA-Pose: Latent Action Pretraining Meets Pose Estimation¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: LA-Pose: Latent Action Pretraining Meets Pose Estimation
- 作者: Zhengqing Wang¹²*, Saurabh Nair¹*, Prajwal Chidananda¹*, Pujith Kachana¹, Samuel Li¹, Matthew Brown¹, Yasutaka Furukawa¹² (*Equal contribution)
- ¹ Wayve ² Simon Fraser University
- arXiv 编号: 2604.27448 (submitted 2026-04,targeted venue: CVPR 2026)
- 项目页: la-pose.github.io
- 关键词: latent action, inverse dynamics, self-supervised pretraining, camera pose estimation, autonomous driving, Genie, feed-forward 3D
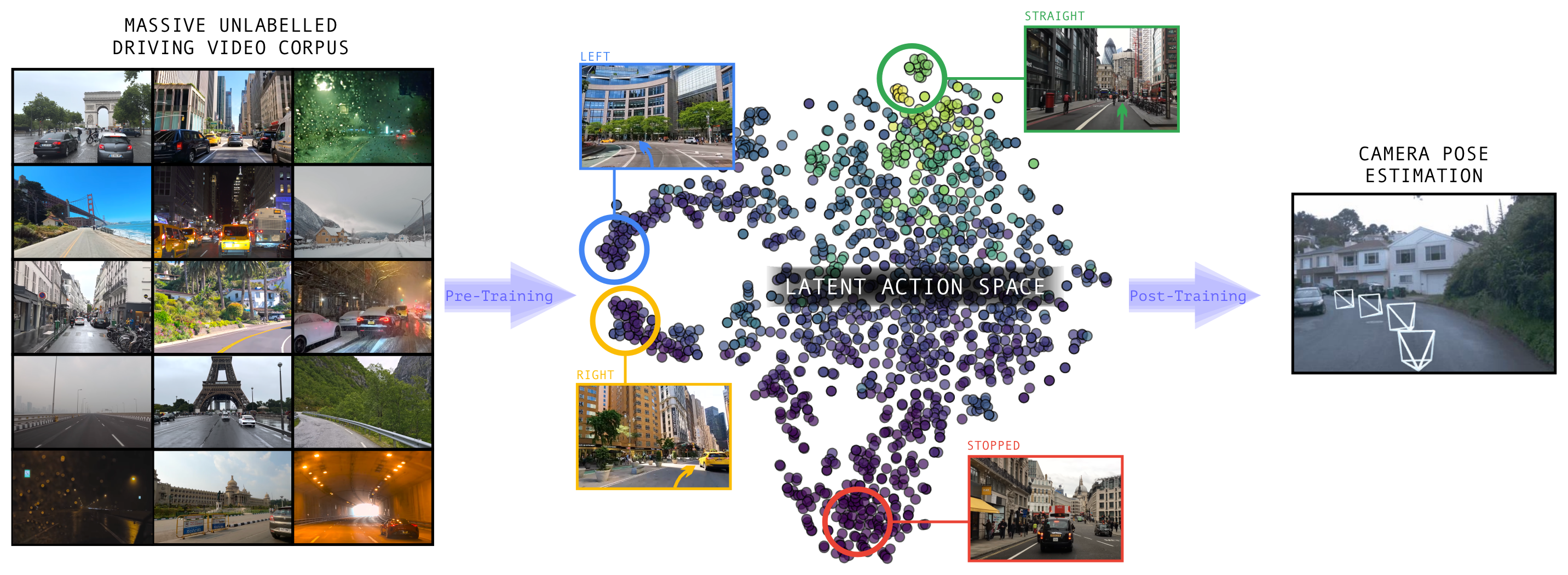 Figure 1:核心叙事——从海量无标注驾驶视频里用 inverse dynamics 学到的 latent action,在 T-SNE 空间天然聚成"左转/直行/右转/停车"的结构化簇(即 ego-motion 分布),再用极少量 3D 标注 post-train 出一个 feed-forward pose 估计头。latent action ≈ 压缩版的 pose。
Figure 1:核心叙事——从海量无标注驾驶视频里用 inverse dynamics 学到的 latent action,在 T-SNE 空间天然聚成"左转/直行/右转/停车"的结构化簇(即 ego-motion 分布),再用极少量 3D 标注 post-train 出一个 feed-forward pose 估计头。latent action ≈ 压缩版的 pose。
2. 文章介绍¶
2.1 解决的领域和问题¶
任务是自动驾驶场景下的相机位姿估计 (camera pose estimation)——给定一段单目前视视频,回归出帧间的相对位姿(旋转、平移)以及 metric scale。这是 self-driving、3D 重建、SLAM 的底层能力。
当前 SOTA 走的是 feed-forward 3D reconstruction 路线:DUSt3R / VGGT / Rig3R / MapAnything 等,一次前向直接预测 pointmap 或多帧位姿,精度高、推理快。但它们全部依赖昂贵的 3D 监督——来自 SfM、LiDAR 标定或仿真引擎的高质量标签。这些带标注的数据集规模有限(需要专门硬件 + 精细标定),相比互联网上海量的无标注驾驶视频是九牛一毛。监督数据成了瓶颈。
2.2 Motivation¶
其他 AI 领域(文本 GPT、图像 DINO、视频 V-JEPA)都靠 internet-scale 自监督预训练取得突破,唯独几何感知任务(如 pose estimation)几乎没人探索自监督预训练。而自动驾驶恰好是最适合搭这波车的领域:车队 + 行车记录仪积累了天量驾驶视频。
关键洞察:对车辆而言,motion 是 action 的直接结果。如果能学到一种"建模相邻帧之间转移"的 latent 表征,它必然内在地编码了 motion change——也就是 pose 的压缩表示。这正好是 Genie 风格 latent action 在做的事。所以与其用 latent action 去做世界模型的"动作条件"或机器人策略的"动作代理",不如直接把它 repurpose 成 pose 估计的输入特征。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 经典 SfM / VO | COLMAP | 推理慢、需迭代优化、对纹理稀疏/动态场景脆弱 |
| Feed-forward 3D 重建 | DUSt3R, VGGT, Rig3R, MapAnything | 精度强但完全绑死在带标注的 3D 数据分布上,继承其成本和偏置;VGGT 训练要 64×A100×9 天 |
| 通用自监督 (image/video) | DINO, Video-MAE, V-JEPA, Scaling 4D | 学的是语义/通用 4D 表征,没有专门针对 pose,下游 pose 精度未必最优 |
| 自监督 pose / NVS | Zhou'17, RayZer, SfM-free NVS | 多数不做大规模预训练,且偏重 photometric 重建(为 novel-view synthesis 设计),不是为精确 pose |
| Latent action (机器人/游戏) | Genie, LAPO, DynaMo, AdaWorld | latent action 被用作"动作条件"或"动作代理"用于生成/控制,没人把它当几何感知特征用 |
2.4 论文解决方案(一句话)¶
用 Genie 式 inverse-forward dynamics 在 1020 万条无标注驾驶视频上自监督学出 latent action,冻结 inverse dynamics 编码器,只用极少量 LiDAR 标定的 3D 标注 post-train 一个轻量 pose head,得到精度 SOTA、且标注量少几个数量级的 feed-forward 位姿估计器。
2.5 与前序工作的关系¶
- 直接建立在 Genie-1 (Bruce et al. 2024) 之上:沿用 inverse dynamics + forward dynamics 两个模块来学 latent action,但砍掉了 Genie 用于高质量视频生成的 video tokenizer 和额外的 forward dynamics 模块。
- 复用现成组件:冻结的 VQ-VAE codebook 作为 forward dynamics 的预测目标;ST-Transformer 架构源自 Genie。
- 与 LAPO/AdaWorld 等机器人 latent action 工作"自监督预训练 + 动作标签微调"的范式同构,但下游任务从"动作预测/控制"换成了"ego-motion / pose 估计"。
3. 方法介绍¶
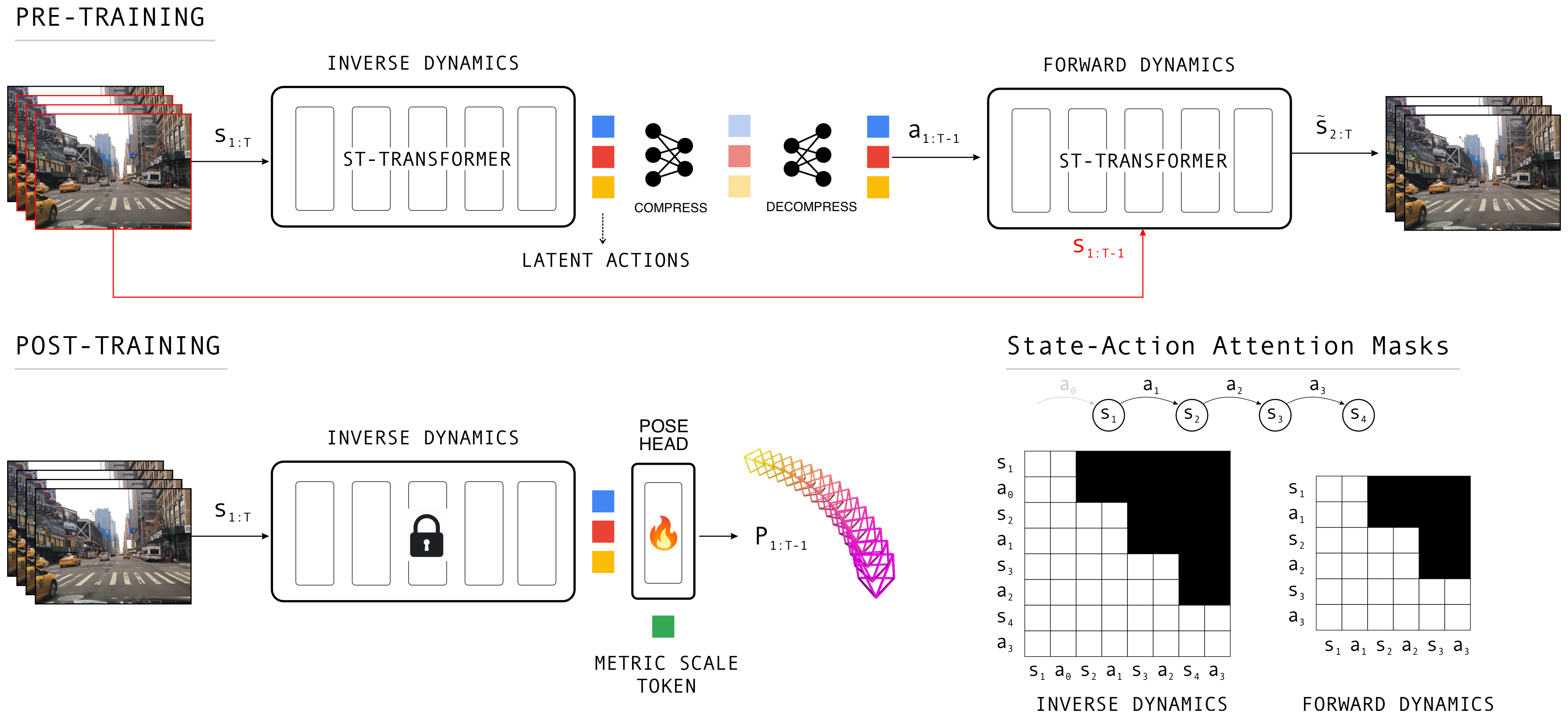 Figure 2:两阶段框架。上:PRE-TRAINING——inverse dynamics (ST-Transformer) 从相邻帧抽出 latent action
Figure 2:两阶段框架。上:PRE-TRAINING——inverse dynamics (ST-Transformer) 从相邻帧抽出 latent action a,经 compress→50 维瓶颈→decompress,喂给 forward dynamics 预测下一帧的 VQ-VAE code。下左:POST-TRAINING——冻结 inverse dynamics(锁图标),接一个带 metric scale token 的 pose head(火焰图标=可训练)输出位姿。右:state-action attention mask,latent action a_t 只能看到截至 t+1 的帧(causal)。
LA-Pose 分两阶段:latent action pretraining 和 camera pose post-training。
3.1 形式化¶
输入是 \(T{=}16\) 帧序列 \((X_1, \dots, X_{T})\),训练分辨率 960×448。每帧 \(X_t\) tokenize 成 visual token 集合 \(s_t\),得到状态序列 \(\{s_1, \dots, s_T\}\)。目标是从中抽出 latent action \(\{\mathbf{a}_1, \dots, \mathbf{a}_{T-1}\}\)(\(\mathbf{a}_t\) 编码 \(t \to t{+}1\) 的转移),并最终从 latent action 回归出相对位姿。
3.2 Latent Action Pretraining¶
Image Tokenizer:标准 ViT,patch token + 可学习位置编码;时间维用 sinusoidal 频率 temporal embedding 经 MLP 投影——这种设计让模型天然支持可变帧率和时间间隔。12 层 transformer encoder,每帧输出 15×7×1536 的张量。
Inverse Dynamics Model:基于 Genie 的 ST-Transformer(causal temporal masking)。关键改动:引入一个 1536 维可学习 query token,在每帧重复,形成 \(\{\mathbf{q}_1, \dots, \mathbf{q}_{T-1}\}\),输出即 latent action \(\{\mathbf{a}_1, \dots, \mathbf{a}_{T-1}\}\)。每个 query token 聚合相邻两帧信息作为 latent action proxy;causal mask 让 \(a_t\) 能看到截至 \(t{+}1\) 的帧。张量维度 (16×15×7 + 15)×1536(+15 即 query token 数)。
瓶颈压缩:一对三层 MLP 把 latent action 从 1536 → 50 → 1536("compressed version")。这个瓶颈是后面消融的重点;但默认 pose 估计用的是 MLP 之前未压缩的 1536 维版本(注意这里正文有点拧巴,见 §5.2)。
Forward Dynamics Model:同样基于 Genie ST-Transformer 预测未来帧,两处改动:(1) 把最后的 MLP head 换成 4 个 transformer block(每个 4 层 self-attention + FFN);(2) 用冻结 VQ-VAE encoder 把 GT 未来帧编码成离散 code 作为预测目标,模型预测同一 codebook 上的 logits。
3.3 Camera Pose Post-training¶
丢弃 forward dynamics,给 inverse dynamics 接一个 relative pose head。Inverse dynamics 要么冻结要么微调(默认冻结)。只用少量高质量 GT 位姿样本训练。
相对位姿表示(scale 解耦):借鉴 MoGe / MapAnything 的"scale-agnostic 表示 + 单独 metric scale"思路。把 GT metric 相对运动的平移 \(\{\mathbf{t}_1, \dots, \mathbf{t}_T\}\),先算平均平移幅度作为 metric scale \(s = \text{mean}_i(\|\mathbf{t}_i\|_2)\),再归一化得 scale-agnostic 平移 \(\tilde{\mathbf{t}}_i = \mathbf{t}_i / \max(s, \epsilon)\)(\(\epsilon{=}1.0\))。由于训练时帧率变化,该归一化按给定帧率分别做。
Pose Estimation Head:引入单个可学习 metric scale token(\(\mathbb{R}^{1536}\)),与 15 个 latent action token 一起,经一个非 causal self-attention transformer 处理,让 scale token 跨序列聚合信息。两个 MLP head:一个出 7D 相对位姿(3D 平移 + 4D 四元数旋转)+ 1D FoV;另一个出标量 metric scale(exp 激活保正且稳定训练)。
3.4 训练¶
损失:预训练用 logits 与 GT code index 的 cross-entropy。Post-training 用 L1 损失(归一化平移、四元数旋转、FoV、log-space metric scale)。
数据: - 预训练:内部 1020 万条无标注驾驶视频片段(在线 + 自有来源),涵盖多环境、车流密度、天气。 - Post-training:极小一撮高质量标注——Waymo (750 scenes, ~20s)、nuScenes (850, ~20s)、Argoverse (700, ~10s),均有 LiDAR 标定的 metric pose。每个训练样本 = 单前视相机的 16 连续帧,帧率在 1–4 fps 间随机抖动(鼓励学习长短时程 motion dynamics)。
训练细节: - 预训练:32×H100,global batch 64,160k steps,cosine LR(peak \(1{\times}10^{-4}\),end \(4.5{\times}10^{-5}\),warm-up 1.5k),约 4 天。 - Post-training:8×H100,batch 128,100k steps,cosine LR(peak \(1{\times}10^{-4}\) → 0,warm-up 4k),约 2 天。 - 对比:VGGT 要 64×A100×9 天,LA-Pose 计算成本显著更低。上述细节对应默认的冻结 backbone 配置。
4. 结果对比¶
评测在 Waymo Open(in-distribution,官方 train/val split)和 PandaSet(对所有方法都是 zero-shot)。评测时统一 2 fps 采样,16 帧 = 8 秒。三个指标:AUC@5(5° 误差阈下的累积误差曲线下面积,越高越好)、ATE-S(scale-invariant 对齐轨迹误差 RMSE)、ATE-M(metric-scale ATE,仅当 baseline 给 metric 预测时报)。
Baseline:Rig3R、VGGT、MapAnything——全部用了比 LA-Pose 更大量的 3D 监督。Rig3R 训练集严格更广(含 LA-Pose 全部数据 + PandaSet + KITTI 等,故 PandaSet 上排除 Rig3R)。
4.1 主结果(Waymo + PandaSet)¶
| Benchmark | Method | AUC@5 ↑ (%) | ATE-S ↓ (×10⁻²) | ATE-M ↓ (m) |
|---|---|---|---|---|
| Waymo | Rig3R | 77.9 | 3.17 | - |
| VGGT | 74.8 | 1.43 | - | |
| MapAnything | 65.0 | 3.00 | 4.74 | |
| LA-Pose | 91.4 | 1.20 | 0.88 | |
| PandaSet (unseen) | VGGT | 75.0 | 0.99 | - |
| MapAnything | 62.4 | 2.75 | 7.28 | |
| LA-Pose | 86.3 | 1.13 | 0.86 |
- Waymo 上 AUC@5 91.4%,比最好的 feed-forward baseline(Rig3R 77.9)高 13.5 个点。
- PandaSet(unseen)上 AUC@5 86.3%,超过所有 baseline;ATE-S 1.13 略逊 VGGT 的 0.99 但相当。
- ATE-M(metric scale)上对 MapAnything 是数量级碾压(0.88 vs 4.74;0.86 vs 7.28)。
- AUC 分布(Figure 3):LA-Pose 不仅均值高,方差也显著更小——大多数样本贴近满分,VGGT 则有长尾低分案例。说明稳定可靠而非只擅长简单序列。
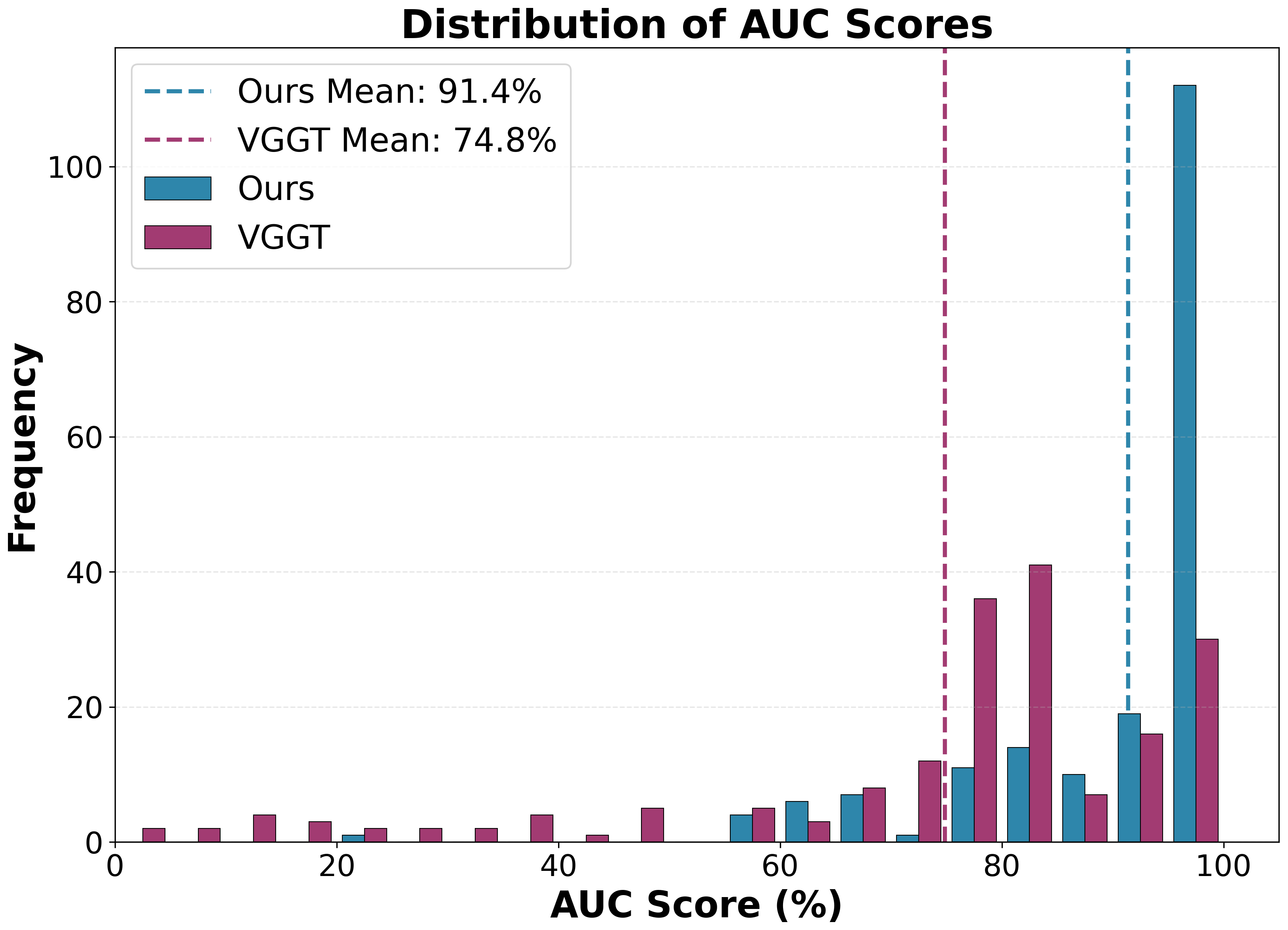 Figure 3:Waymo 上 AUC@5 的分布直方图。LA-Pose(相对 VGGT)质量集中在高分区、长尾少——这张图比表格里的均值更能说明"鲁棒一致"。
Figure 3:Waymo 上 AUC@5 的分布直方图。LA-Pose(相对 VGGT)质量集中在高分区、长尾少——这张图比表格里的均值更能说明"鲁棒一致"。
 Figure 4:定性轨迹对比(绿=Ours,品红=Rig3R,青=VGGT,红=GT,xz 平面投影)。作者刻意挑了低 AUC 的困难样本(雨/夜/雾/急转弯),LA-Pose 仍给出稳定、几何连贯的轨迹——尽管 post-training 数据以简单直行为主。
Figure 4:定性轨迹对比(绿=Ours,品红=Rig3R,青=VGGT,红=GT,xz 平面投影)。作者刻意挑了低 AUC 的困难样本(雨/夜/雾/急转弯),LA-Pose 仍给出稳定、几何连贯的轨迹——尽管 post-training 数据以简单直行为主。
4.2 消融:冻结 vs 微调 backbone¶
| 配置 | Waymo (in-domain) | PandaSet (zero-shot) |
|---|---|---|
| Fine-tune inverse dynamics | 相当 | 显著退化 |
| Freeze inverse dynamics(默认) | 相当 | 更优泛化 |
结论:两者在 in-domain Waymo 上差不多,但 zero-shot PandaSet 上微调版明显掉点——冻结 backbone 保住了预训练的 motion prior,泛化更好。这是默认选冻结的理由。
4.3 消融:latent action 维度¶
(为省算力用 8×H100, batch 16, 预训练 3.2M 样本, post-train 60k steps)
| Latent Dim. | Pre-train Loss @100k ↓ | @200k ↓ | AUC@5 ↑ | ATE-M ↓ |
|---|---|---|---|---|
| 50 | 1.87 | 1.67 | 85.4 | 1.62 |
| 1536 | 1.35 | 1.15 | 86.5 | 1.94 |
核心权衡:大 latent(1536)预训练重建 loss 更低(直接编码稠密 motion flow + 外观),但会 information leakage、对 ego-motion 抽象更弱;小 latent(50)预训练 loss 更高,却得到紧凑、motion-centric 的表征,下游 ATE-M 明显更好(1.62 vs 1.94),AUC 几乎持平。即"压得更狠 → metric-scale 一致性更强"。
注意这里和 §3.2 的"默认用未压缩 1536 维"叙述存在张力,见 §5.2。
4.4 消融:帧率鲁棒性¶
| FPS | Method | AUC@5 ↑ (%) | ATE-S ↓ (×10⁻²) |
|---|---|---|---|
| 4.0 | VGGT | 74.1 | 1.03 |
| LA-Pose | 93.4 | 0.87 | |
| 1.3 | VGGT | 75.0 | 1.21 |
| LA-Pose | 88.6 | 1.20 | |
| 1.0 | VGGT | 74.6 | 1.43 |
| LA-Pose | 85.7 | 1.16 |
各帧率下 LA-Pose 全面优于 VGGT;低 fps(稀疏观测)下两者都略降,但 LA-Pose 更稳——得益于训练时的帧率抖动。
4.5 失败模式分析(附录)¶
按曲率/加速度分箱(Waymo val,AUC@5%):
| Small | Medium | Large | |
|---|---|---|---|
| Curvature | 94.50 | 78.32 | 91.22 |
| Acceleration | 92.81 | 90.96 | 88.25 |
最差的是中等曲率(缓慢转向)——帧间几何变化太微弱,future-frame prediction 学到的表征区分度不足;直行(稳定 ego-motion)和急转(强几何变化)反而更好。另外倒车 (reverse motion) 也会退化(post-training 数据里罕见)。
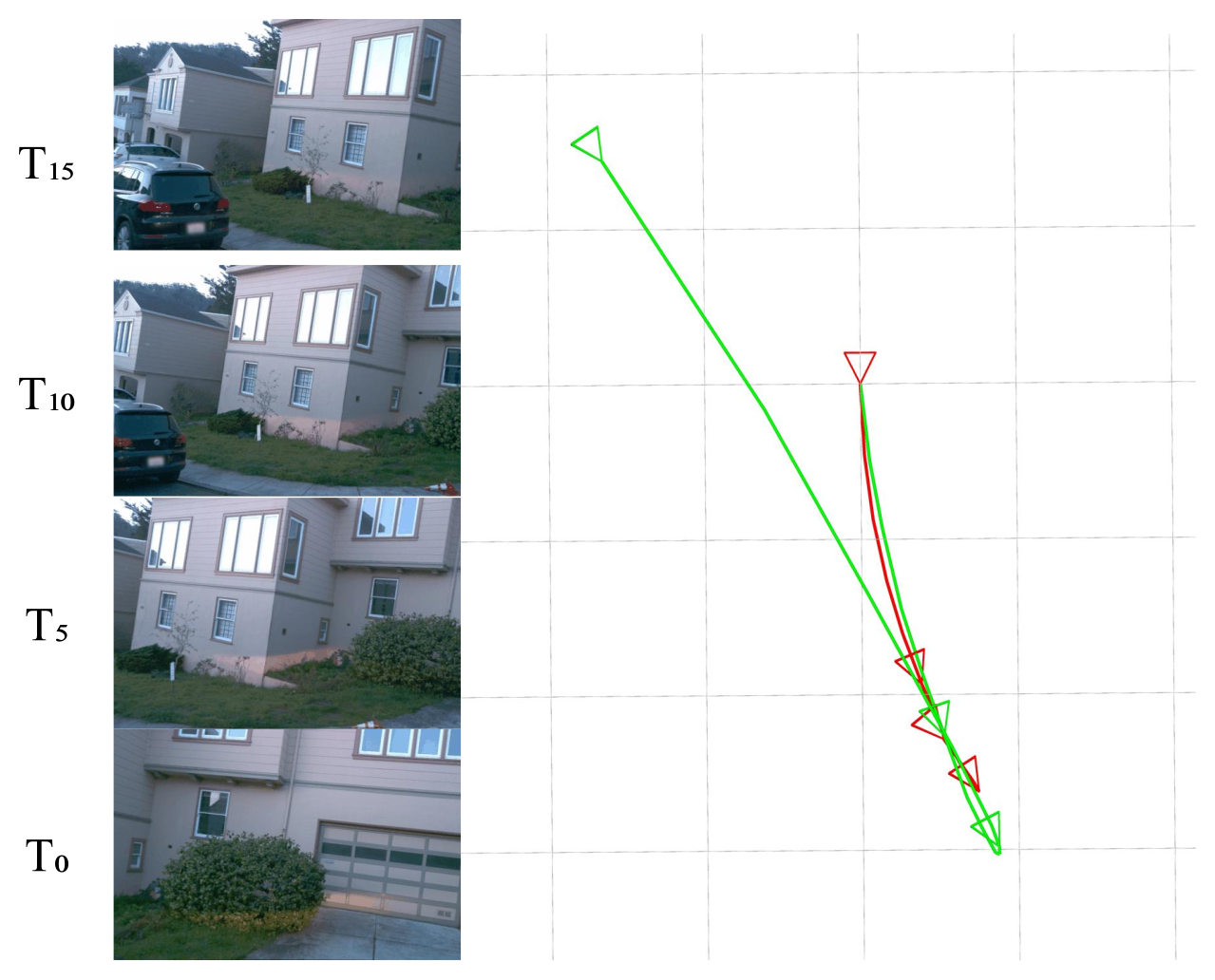 Figure 5:倒车失败案例。后退是监督集中的稀有条件,pose 估计变得不稳;但预训练 backbone 仍给出部分连贯的轨迹,说明问题主要在 post-training 数据覆盖而非表征本身。
Figure 5:倒车失败案例。后退是监督集中的稀有条件,pose 估计变得不稳;但预训练 backbone 仍给出部分连贯的轨迹,说明问题主要在 post-training 数据覆盖而非表征本身。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
-
概念上的"重新定位 (repurposing)"很巧:latent action 一直被当成生成/控制的"动作"条件,本文一句话点破——对车辆来说 motion 就是 action,所以 inverse dynamics 学到的 latent action 本质就是压缩版 pose,直接拿来当 pose 估计输入。这是个低成本但视角新颖的 reframing,Figure 1 的 T-SNE 簇(左转/直行/停车)是强有力的"表征已经懂 ego-motion"的证据。
-
冻结 backbone 反而泛化更好,且有消融支撑:§4.2 显示微调在 zero-shot PandaSet 上掉点,冻结版保住 motion prior。这与"小数据微调容易过拟合到 in-domain 标注分布"的直觉一致,且让默认配置的计算成本也更低(pose head 很轻)。
-
标注效率的论证扎实:baseline(尤其 Rig3R)用的监督数据严格是 LA-Pose 的超集(还多了 PandaSet/KITTI),LA-Pose 仍在 AUC@5 上高 10+ 点。"少几个数量级标注 + 自监督预训练就能打赢"是这篇最硬的卖点,且 baseline 选得不偏袒自己。
-
scale 解耦设计合理:把 metric scale 拆成单独 token + exp 激活,scale-agnostic 平移单独归一化(且按帧率分别归一化),符合 MoGe/MapAnything 验证过的最佳实践,也解释了为何 ATE-M 对 MapAnything 是数量级优势。
-
帧率抖动训练 → 帧率鲁棒:1–4 fps 随机 stride 是个便宜但有效的增强,§4.4 显示低 fps 下相对 VGGT 优势更大,对真实部署(采样率不固定)有实际意义。
-
诚实的失败分析:附录主动剖析"中等曲率最差"并给出机理解释(缓慢转向帧间几何变化弱,future-frame prediction 信号不强),以及倒车失败,没有藏着掖着。
5.2 做得不够好的地方 / 值得质疑的地方¶
-
latent action 维度的叙述自相矛盾:§3.2 说"默认 pose 估计用 MLP 之前未压缩的 1536 维",但 §4.3 消融结论却是"50 维压缩版下游 ATE-M 明显更好(1.62 vs 1.94)"。如果压缩更好,为什么默认不用压缩版?正文没把"默认配置到底用哪个维度"讲清楚,这是核心设计点上的混乱,需要读源码/作者澄清。
-
预训练数据完全是内部私有的 1020 万片段,不可复现:整篇的核心卖点是"internet-scale 自监督预训练的威力",但预训练语料是 Wayve 私有,外部无法验证规模效应,也无法区分"是 latent action 范式好"还是"单纯 Wayve 数据多且干净"。附录虽展示 OpenDV-YouTube 泛化,但那是定性、无 GT。
-
没有 scaling curve:既然主张 internet-scale,却没给"预训练数据量 vs 下游精度"的曲线(§4.2 的 x 轴是 post-training 样本数,不是预训练规模)。"orders of magnitude less labeled data"成立,但"more pretraining data → better"这个 internet-scale 论点本身没有实证。
-
baseline 全是通用多域 3D 重建模型,不是驾驶专用 pose 方法:VGGT/MapAnything/Rig3R 训练分布大量非驾驶场景,在纯驾驶前视 benchmark 上本就吃亏。LA-Pose 整个 pipeline(预训练+微调)全在驾驶域,"赢"有一部分来自域特化而非范式优越。缺一个"同样只在驾驶数据上训练的 supervised feed-forward"对照组。
-
评测仅单前视相机、仅 2 fps / 8 秒、仅两个 benchmark:Waymo 是 in-distribution(post-train 就用了 Waymo),真正 unseen 只有 PandaSet 一个。多相机、长序列、跨城市的系统评测缺失,泛化结论的支撑面偏窄。
-
forward dynamics 用冻结 VQ-VAE codebook 作目标,但 VQ-VAE 本身的训练/来源没交代:这是预训练信号的关键一环,code 质量直接影响 latent action 质量,却被一笔带过。
-
"latent action = pose"的等价是近似的:latent action 编码的是帧间一切可预测的转移信息,不只 ego-motion——还混入了动态物体运动、光照/外观变化。中等曲率失败恰恰暴露:当 ego-motion 信号弱时,latent action 里的"非 pose"成分占主导。瓶颈压缩理论上能缓解,但又回到第 1 点的矛盾。
-
ATE-S 在 PandaSet 上其实输给 VGGT(1.13 vs 0.99),正文用"comparable"带过。AUC@5 大幅领先但 scale-invariant 轨迹误差落后,说明 LA-Pose 的优势更多在"整体方向/旋转精度",纯轨迹形状一致性未必更好。
-
没有推理延迟/吞吐的实测数字:宣称 feed-forward 高效,但没给 inference latency / FPS / 显存,对"下一代 self-driving 技术"的部署可行性论证不足。
-
post-training 数据"以直行为主、无针对性采样"被当成优点(robustness emerges)讲,但同时又是倒车/转弯失败的根因——这两个叙述其实是同一枚硬币的两面,作者偏向正面解读。
5.3 值得继续探讨的方向¶
- 用更结构化的 latent action 替换:能否借 LAPO/DynaMo 的离散 codebook 或 information-bottleneck(如 VIB)显式约束 latent action 只保留 ego-motion,剥离动态物体/外观,针对性解决中等曲率失败?
- 真正的 internet-scale 验证:在公开的 OpenDV-2K(1700 小时、40+ 国家)上预训练并给出 scaling curve,把"数据多带来的增益"和"范式增益"解耦。
- 跨域迁移到非驾驶 embodied 视频(论文 future work 也提到):把同一套 inverse dynamics 预训练用到 ego-centric 手持/无人机/机器人视频,看 latent action 作为通用几何先验是否成立。
- 多任务 head:latent action 既然编码稠密 motion,能否同时挂 depth / optical flow / scene flow head,做成一个统一的自监督几何感知 backbone?
- 闭环 / 长序列:当前 16 帧 8 秒固定窗口,能否做成滑窗 + 累积,处理分钟级长轨迹的漂移问题(VGGT 在低 fps 长序列已暴露 drift)。
- 倒车/罕见运动的针对性补救:是仅靠扩大预训练数据,还是需要在 post-training 做难例采样 / 合成倒车序列?论文把希望全压在"scale up 预训练"上,值得质疑。
- 瓶颈维度的系统 sweep:50 与 1536 之间(如 128/256/512)的完整曲线,以及"压缩版 vs 未压缩版作为 pose 输入"的彻底澄清。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页: la-pose.github.io
- 关键 baseline / 相关论文: Genie (Bruce et al. 2024, latent action 起源)、VGGT (Wang et al. 2025)、Rig3R (Li et al. 2025)、MapAnything (Keetha et al. 2025)、DUSt3R (Wang et al. 2024)、LAPO / AdaWorld / DynaMo (机器人 latent action)、MoGe (scale 解耦)