FAST: Efficient Action Tokenization for Vision-Language-Action Models¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:FAST: Efficient Action Tokenization for Vision-Language-Action Models
- 作者 / 机构:Karl Pertsch*, Kyle Stachowicz*, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, Sergey Levine(Physical Intelligence / UC Berkeley / Stanford;* 为 core contributors)
- arXiv:2501.09747,提交于 2025-01
- 关键词:action tokenization、autoregressive VLA、DCT (discrete cosine transform)、BPE、action chunking、π₀、flow matching、高频灵巧操作 (dexterous manipulation)
- 核心缩写:
- FAST = Frequency-space Action Sequence Tokenization(DCT + BPE 的 action tokenizer)
- FAST+ = 在 1M 真实 action 序列上训练的 universal(通用、黑盒)tokenizer
- π₀-FAST = 把 FAST tokenization 接到 π₀ VLA 上、用 autoregressive 解码的 generalist policy
- π₀ = 同实验室的 state-of-the-art flow matching / diffusion VLA(对照基线)
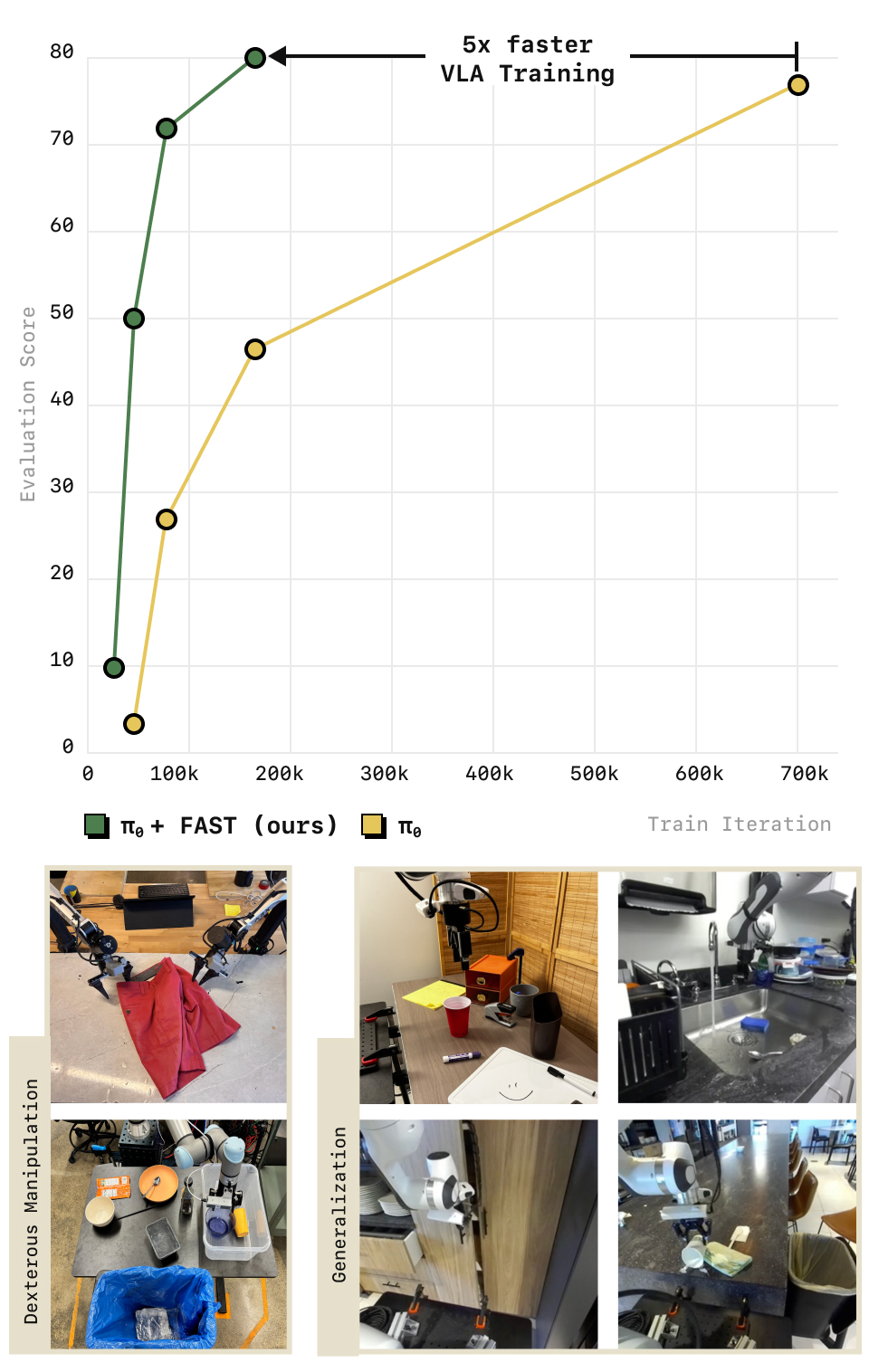 Figure 1(convergence_2):takeaway —— FAST 是一个基于时序压缩的 action tokenizer。用它训练的 autoregressive VLA(π₀-FAST)能解决复杂灵巧、长程操作任务并 zero-shot 泛化到新场景;在与 state-of-the-art diffusion π₀ 性能持平的同时,训练速度快约 5x(上方曲线)。
Figure 1(convergence_2):takeaway —— FAST 是一个基于时序压缩的 action tokenizer。用它训练的 autoregressive VLA(π₀-FAST)能解决复杂灵巧、长程操作任务并 zero-shot 泛化到新场景;在与 state-of-the-art diffusion π₀ 性能持平的同时,训练速度快约 5x(上方曲线)。
2. 文章介绍¶
2.1 解决的领域和问题 (autoregressive VLA action tokenization)¶
本文研究的是 autoregressive VLA(Transformer 自回归视觉-语言-动作模型)的 action tokenization 问题。VLA 把连续的机器人动作信号离散化成 token 序列,再用 next token prediction 训练。问题的核心是:怎样把一段连续 action chunk \(a_{1:H}\) 映射成离散 token 序列 \([T_1,\dots,T_n]\),使得自回归模型既能高效训练、又能高精度重建动作。
作者发现:现有 VLA(RT-2、OpenVLA 等)普遍采用的 per-dimension、per-timestep binning 方案,在高频 / 灵巧 (high-frequency, dexterous) 数据上表现很差,甚至完全无法学习。这直接限制了 autoregressive VLA 长期只能做低频、简单任务。
2.2 Motivation (为什么 naive binning 在高频/dexterous 数据上失败 —— token 相关性高,训练信号塌缩)¶
作者用一个 didactic 玩具实验(case_study,拟合一条三次样条插值曲线)说明问题:固定底层数据分布不变,只改变采样频率(25 → 800 步/序列)。结果是 naive binning 在低采样率下 MSE 很低,但随着采样率升高预测误差陡增,最终模型干脆直接 copy 第一个 action token。
原因在于 autoregressive 的学习目标本质:next token prediction 的学习信号正比于 \(T_i\) 在已知 \(T_{1:i-1}\) 下的边际信息量 (marginal information content)。对于平滑的高频信号,timestep 越短,相邻时刻动作变化越小 —— 相邻 token 高度相关,边际信息量趋近于零。此时只要"复制上一个 token"就能拿到很低的 next-token loss,模型被困在平凡的局部最优里,根本学不到任务结构。这就是训练信号塌缩 (signal collapse)。OpenVLA 在低频 BridgeV2 / RT-1 上能学好、却始终拟合不了高频 DROID,正是这一现象的真实例证。
2.3 之前工作的问题¶
| 方法类别 | 代表工作 | 做法 | 缺陷 |
|---|---|---|---|
| Per-dim per-timestep binning | RT-1, RT-2, RT-2-X, OpenVLA | 每个维度独立分 256 个 bin,逐时刻拼接 | 高频数据下相邻 token 高度相关、边际信息趋零,训练信号塌缩;token 数随频率/维度爆炸(50Hz 双臂 → 700 token/chunk),推理慢 |
| Semantic action 表示 | SayCan, PIVOT, ReKep, MOKA 等 | 用 language sub-task / keypoint 作为动作表示 | 依赖手工设计的 low-level controller,通用性受限 |
| Diffusion / flow policy(连续解码) | Diffusion Policy, π₀, TinyVLA, Crossformer | 用 regression head 或额外 diffusion / flow matching 权重解码连续动作 | 需要改动底层预训练 transformer、引入新权重(如 π₀ 的 300M action expert);与纯 next-token VLM 范式不一致 |
| Vector-quantized 表示 | BeT, MiniVLA, QueST | 训练 VQ-VAE / 类似编码器得到离散 codebook | 重建质量对超参/结构敏感、训练繁琐;低保真粗动作尚可,高频精细控制下失败 |
2.4 论文解决方案(一句话)¶
在 tokenization 前先对 action chunk 做"压缩"以降低相邻 token 相关性 —— 具体用 DCT 把动作转到频域、量化后再用 BPE 无损压缩 —— 从而让纯 next-token-prediction 的 autoregressive VLA 在高频灵巧任务上也能高效训练。
2.5 与前序工作的关系¶
- 相对 π₀ flow matching:FAST 与 π₀ 出自同一实验室、同期工作,构成 autoregressive (AR) vs flow matching 的直接对照。π₀ 用 flow matching / diffusion 连续解码动作;π₀-FAST 复用同一 PaliGemma-3B 骨干,但改成 FAST tokenization + autoregressive 解码。结论是二者性能可比,但 π₀-FAST 训练快约 5x。
- 借鉴语言/图像压缩:BPE 来自语言模型的 byte-pair encoding;DCT 来自 JPEG 等连续信号压缩。作者的洞见是"任何足够有效的压缩方法用在 action 目标上,都能改善 VLA 训练速度",DCT 只是其中简单高效的一个选择。
- FAST+ 通用 tokenizer:在 1M 跨本体 action 序列上训练,作为黑盒 tokenizer 开源(HuggingFace
AutoProcessor),免去为每个新数据集单独训练 BPE。
3. 方法介绍¶
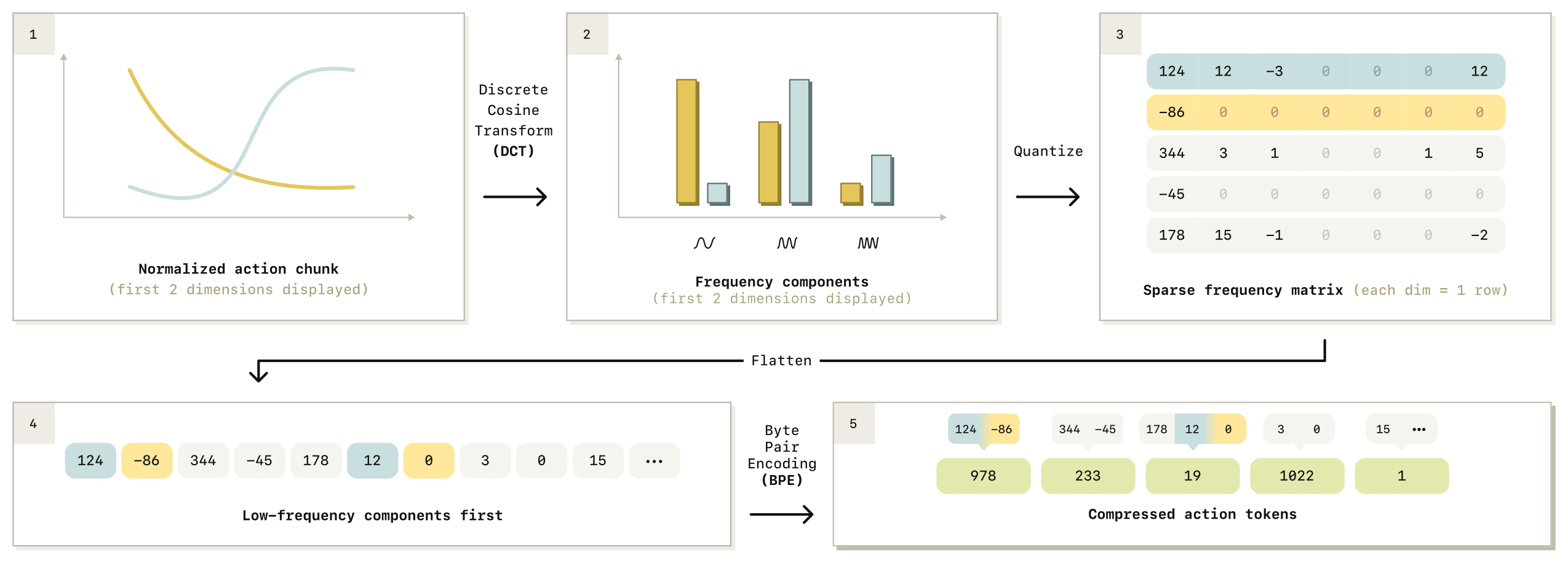 Figure 2(dct_method):FAST tokenization 流水线。归一化的 action chunk → DCT 转到频域 → 量化(scale-and-round)DCT 系数 → 按列优先 flatten 成整数序列 → BPE 压缩成最终 action token 序列。整条流水线均可逆,解码快速。
Figure 2(dct_method):FAST tokenization 流水线。归一化的 action chunk → DCT 转到频域 → 量化(scale-and-round)DCT 系数 → 按列优先 flatten 成整数序列 → BPE 压缩成最终 action token 序列。整条流水线均可逆,解码快速。
3.1 形式化 (action chunk → token 序列)¶
策略 \(\pi(a_{1:H}\mid o)\) 把观测 \(o\) 映射到一段未来动作 action chunk \(a_{1:H}\)(\(H\) 步、每步 \(|\mathcal{A}|\) 维)。Action tokenization 定义映射 $\(\mathcal{T}_a:\ a_{1:H}\ \rightarrow\ [T_1,\dots,T_n],\quad T\in|\mathcal{V}|\)$ 注意 token 数 \(n\) 不固定,就像同样长度的句子可以被切成不同数量的 text token。 - Binning 基线:每维独立离散成 \(N{=}256\) 个 bin,逐时刻拼接 → \([T_{1,1},\dots,T_{H,D}]\)。对高频数据轻易产生上百 token/chunk。
3.2 为什么 naive tokenization 失败 (信号分析)¶
(见 §2.2)自回归学习信号 \(\propto\) token 边际信息量;平滑高频信号下相邻 token 强相关 → 边际信息 \(\to 0\) → "copy 上一个 token"即可压低 loss → 收敛极慢、陷入差的局部最优。玩具实验证明这不是数据复杂度问题(分布不变),而纯粹是 tokenization 的问题:FAST 在所有采样率下都保持低 MSE。
3.3 FAST: DCT + 量化 + BPE 压缩 (具体步骤)¶
对应 Algorithm 1(FAST Tokenizer),超参只有两个:DCT 量化 scale \(\gamma\)、BPE 词表大小。 1. 归一化:对每个 action 维度,用训练集的 1st / 99th 分位数把数值映射到 \([-1,1]\)。用分位数而非 min/max 是为了对大规模机器人数据里偶发的离群动作鲁棒,也便于统一不同尺度的跨本体数据。 2. DCT:对每个 action 维度独立做 discrete cosine transform,把信号转到频域。低频系数刻画整体形状,高频系数刻画尖锐跳变。 3. 量化(压缩):\(\bar C^i_j = \mathrm{round}(\gamma\cdot C^i_j)\),scale-and-round 把不显著的系数压到 0。\(\gamma\) 越大越精确、压缩率越低;越小越有损、压缩率越高。量化后 DCT 系数矩阵通常稀疏,每维只剩少数显著系数。 4. Flatten:把 \(|A|\times H\) 的系数矩阵展平成一维整数向量。采用列优先 (column-first):先放各维度的低频分量,再放高频。这样自回归预测时先预测刻画整体形状的低频分量,rollout 更稳定(row-first 会先把单维全部频率排完,效果更差)。 5. BPE 压缩:在 flatten 后的整数序列上训练 byte-pair encoding tokenizer,无损地把大量重复的 0 系数"squash"掉、把高频共现的系数组合合并成新 token。选 BPE 是因为实现成熟、输出固定大小词表,可直接并入 VLM 现有词表(覆盖最少用的 token,沿用 RT-2 / OpenVLA 做法)。
整条流水线全部可逆 → 解码快。所有单数据集实验都用同一组超参:rounding scale = 10,BPE 词表 = 1024,作者强调两个超参都不敏感 —— 与需要逐数据集精调的 learned VQ 方法形成对比。
3.4 FAST+ 通用 tokenizer (训练于 1M 序列)¶
流水线里唯一 learned 的组件是 BPE 词表,每换一个数据集需重训(虽只需几分钟,仍有摩擦)。于是作者在一个大型跨本体数据集上训练 FAST+ 通用 tokenizer:约 1M 个 1 秒 action chunk,覆盖单臂、双臂、移动操作机器人,关节空间 / 末端执行器控制、多种控制频率(数据混合见附录)。训练后 FAST+ 可作为黑盒直接用于任意机器人的 1 秒 action chunk,三行代码即可调用:
from transformers import AutoProcessor
tokenizer = AutoProcessor.from_pretrained(
"physical-intelligence/fast", trust_remote_code=True)
tokens = tokenizer(action_chunk)
tokenizer.fit(action_dataset) 在新数据集上重训一个 FAST tokenizer。
3.x Implementation Details (压缩率, 序列长度, 训练加速, 推理代价)¶
- VLA 骨干:主实验用 π₀(基于 PaliGemma-3B);ablation 用 OpenVLA(基于 Prismatic-7B)。训练时 tokenize 1 秒 action chunk,覆盖词表中最少用 token,不冻结权重做全量 fine-tune。
- 压缩率(comparable 重建精度下,Table 1):
| 数据集 | 动作维度 | 控制频率 | Naive token 数 | FAST token 数 | 压缩比 |
|---|---|---|---|---|---|
| BridgeV2 | 7 | 5 Hz | 35 | 20 | 1.75x |
| DROID | 7 | 15 Hz | 105 | 29 | 3.6x |
| Bussing | 7 | 20 Hz | 140 | 28 | 5.0x |
| Shirt Fold | 14 | 50 Hz | 700 | 53 | 13.2x |
有趣的是 FAST 每条 chunk 每条手臂约 30 token(双臂约 60),几乎与控制频率无关 —— 说明它逼近了动作信号的真实复杂度,而非时间长度。频率越高,相对 naive 的压缩收益越大。 - 训练加速:单数据集上,大数据集(Table Bussing)π₀-FAST 比 diffusion π₀ 少 3x 训练步达到高性能;generalist 训练上 π₀-FAST 比 π₀ 少约 5x GPU hours。 - 推理代价(关键 trade-off):autoregressive 解码需逐 token 串行预测 30–60 个 action token,并用完整 2B 语言骨干 → 单 chunk 约 750ms(NVIDIA 4090);而 diffusion π₀ 只需 10 步 diffusion、用 300M action expert → 约 100ms。即 π₀-FAST 推理慢约 7–8x。在静态任务上未观察到性能损失,但 eval 明显变慢。 - BPE 不可省:去掉 BPE 后策略性能下降(仍优于 naive),且因要自回归预测上百个含大量重复 0 的 token 导致推理大幅变慢。
4. 结果对比¶
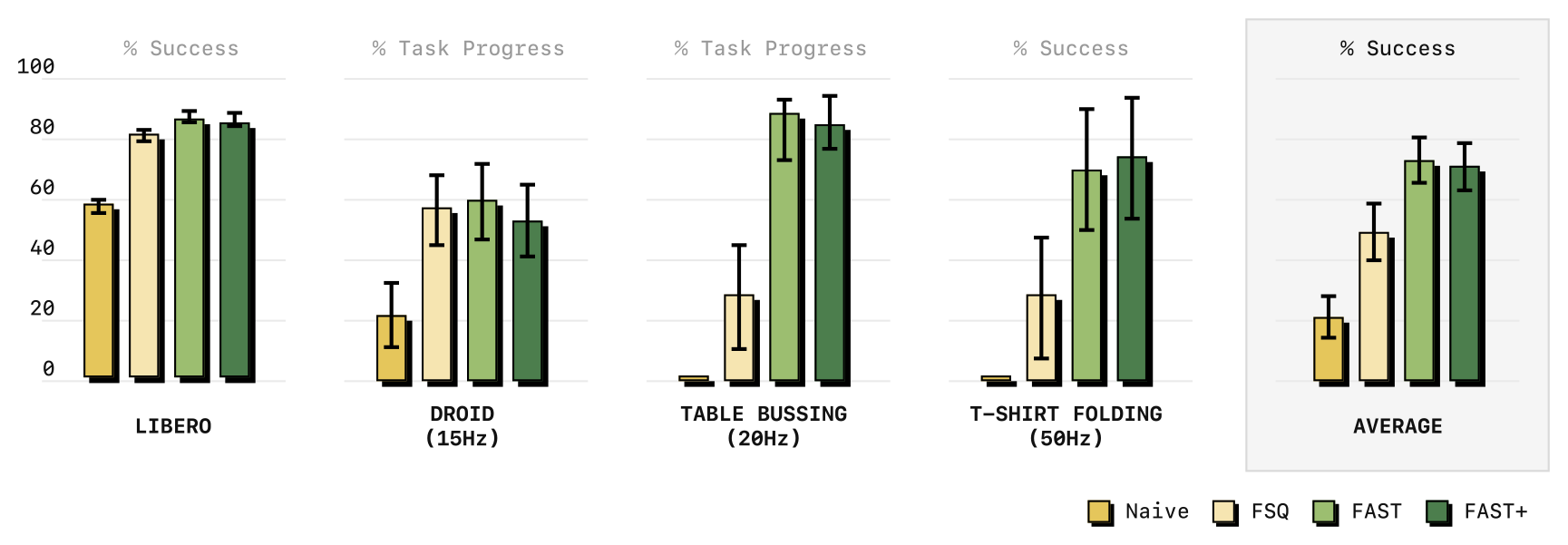 Figure 3(main_result):不同 tokenization 在策略性能上的对比。压缩类方法(FAST、FSQ)训练远比 naive binning 高效;FAST 总体优于 FSQ(尤其灵巧高频任务),且无需训练任何额外神经网络;FAST+ 通用 tokenizer 与逐数据集专用 tokenizer 性能持平。误差为 mean 与 95% CI。
Figure 3(main_result):不同 tokenization 在策略性能上的对比。压缩类方法(FAST、FSQ)训练远比 naive binning 高效;FAST 总体优于 FSQ(尤其灵巧高频任务),且无需训练任何额外神经网络;FAST+ 通用 tokenizer 与逐数据集专用 tokenizer 性能持平。误差为 mean 与 95% CI。
4.1 vs naive binning(Figure 3):在最高频任务上(Table Bussing 20Hz、T-Shirt Folding 50Hz),naive tokenization 训练的策略完全无法取得进展;FAST / FSQ 等压缩类方法能正常训练。FAST 与 FSQ 相当或更优,但简单得多、无需单独训网络。
4.2 vs learned VQ(FSQ):FAST ≥ FSQ,尤其在灵巧高频任务上更好;且 FAST 超参不敏感、无训练摩擦。
4.3 FAST+ 通用 tokenizer(bench_test_compression)
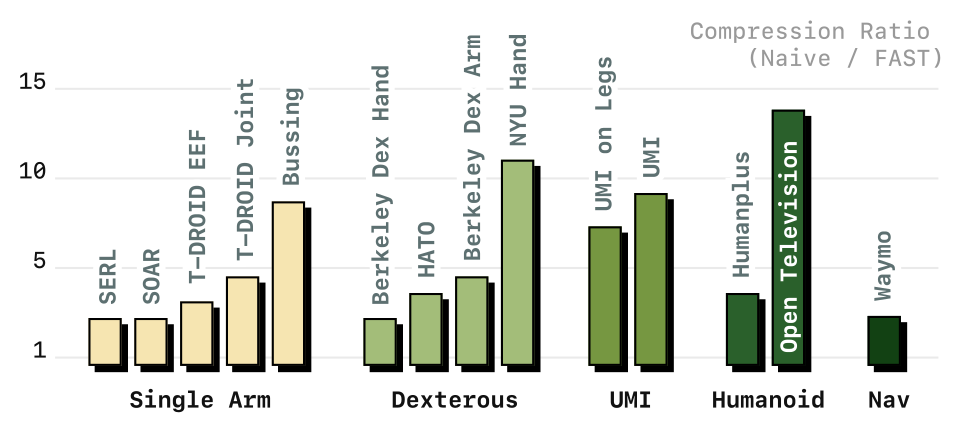 Figure 4(bench_test_compression):FAST+ 在训练时未见过的多样机器人数据集上的压缩率 vs naive。FAST+ 在不同形态、动作空间、控制频率上都有效,所有数据集 token 数至少减半(≥2x),部分远高于此。
Figure 4(bench_test_compression):FAST+ 在训练时未见过的多样机器人数据集上的压缩率 vs naive。FAST+ 在不同形态、动作空间、控制频率上都有效,所有数据集 token 数至少减半(≥2x),部分远高于此。
策略训练上,FAST+ 与逐数据集 FAST tokenizer 性能基本持平 —— 可作为机器人 action tokenization 的强默认项。
4.4 DROID generalist(zero-shot 泛化):FAST 首次实现了在 DROID 数据集上成功训练的强 generalist policy,可在完全未见的环境中 zero-shot(不 co-train、不 fine-tune,仅用自然语言 prompt)执行抓取放置、开关抽屉、开水龙头等桌面操作,跨三所大学校园验证。这是首个 DROID 策略的 zero-shot 评测;此前 DROID 原论文与 OpenVLA 都只做 co-train / fine-tune。
4.5 vs diffusion π₀(single-task,pi0_single_task):小数据集(Libero、T-Shirt Folding,<50h)两者相当;大数据集(Table Bussing)π₀-FAST 少 3x 步收敛;DROID 上 π₀-FAST 更好地遵循语言指令(diffusion π₀ 常忽略 language instruction)。
4.6 Generalist multi-task(pi0_multi_task):在 π₀ 的 10k 小时跨本体数据混合(903M 自有 timestep + 9.1% BridgeV2/DROID/OXE)上训练,π₀-FAST 匹配 diffusion π₀ 的性能(含最难的 laundry folding),同时训练所需 GPU hours 少约 5x。
4.7 训练收敛速度(convergence_2 / pi0_compute_matched)
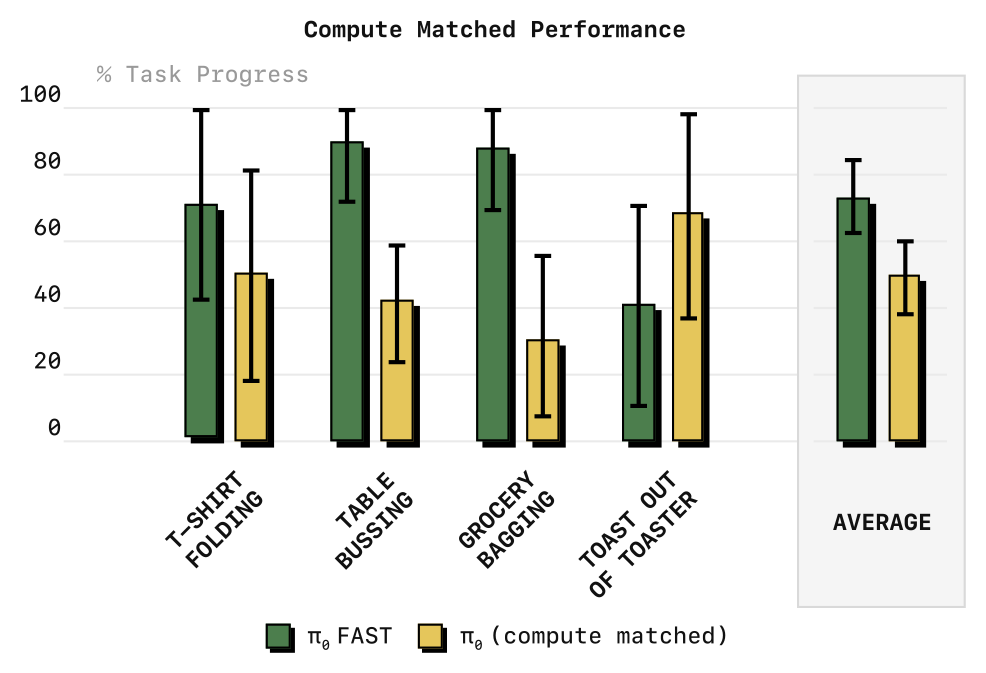 Figure 5(pi0_compute_matched,附录):compute-matched 对照 —— 在相同训练算力下,π₀-FAST 因收敛更快而明显优于 diffusion π₀。误差为 mean 与 95% CI。
Figure 5(pi0_compute_matched,附录):compute-matched 对照 —— 在相同训练算力下,π₀-FAST 因收敛更快而明显优于 diffusion π₀。误差为 mean 与 95% CI。
收敛曲线(Figure 1)与 compute-matched 对照都表明 π₀-FAST 收敛显著更快;对动辄上千 GPU hours 的 VLA 训练,5x 算力节省意义重大。
4.8 骨干无关性(OpenVLA ablation):把 FAST+ 接到 OpenVLA 上训练高频 T-shirt folding,相比 OpenVLA 原生 naive tokenization 性能大幅提升 —— 说明 FAST 与底层模型骨干无关,可应用于任意预训练 autoregressive transformer。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 诊断清晰:从 next-token 学习目标的边际信息量出发,把"高频数据训不动"精准归因为 token 相关性导致的信号塌缩,并用可控玩具实验隔离验证(数据分布不变、只改频率)。
- 方法极简:DCT + round + BPE,纯解析、无需训练神经网络,全程可逆,仅两个不敏感超参(scale=10、词表=1024)。相比 VQ-VAE/FSQ 的调参痛点是实打实的工程优势。
- 强结果:让 autoregressive VLA 首次在 DROID 上训出可 zero-shot 泛化的 generalist;π₀-FAST 与 SOTA diffusion π₀ 性能持平且训练快 5x。
- 可复现/可用:FAST+ 黑盒 tokenizer 三行代码开源,降低社区采用门槛。
- 诚实的 trade-off 披露:明确给出推理慢 7–8x(750ms vs 100ms)的代价。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 推理速度是硬伤:autoregressive 逐 token 串行解码 + 完整 2B 骨干 → 750ms/chunk,比 diffusion 并行采样的 100ms 慢约 7–8x。文中坦承这让动态任务难以使用,所有评测都是静态操作,回避了高频闭环动态任务这一恰恰最需要高频控制的场景。声称的推理加速(speculative decoding、量化等)全部留作 future work,未给任何实验数据。
- "快 5x"是否 compute-fair 存疑:训练加速对比的是 GPU hours,但两个模型的有效解码器规模不同(AR 用 2B 全骨干 vs diffusion 用 300M action expert + 骨干)。收敛"步数/算力"的口径、batch、学习率是否对两边都最优,文中未充分交代;compute-matched 对照只在附录、且仍是同实验室自家两个模型互比。
- token 数随 chunk 长度/维度增长:虽然"每臂约 30 token、与频率近乎无关"很漂亮,但都是基于 1 秒 chunk。更长 horizon 或更高维(灵巧手、humanoid)下 token 数如何增长缺乏系统刻画,而 token 数直接决定 AR 推理延迟。
- BPE 引入数据集依赖:BPE 词表是唯一 learned 组件、需逐数据集重训;FAST+ 用通用词表缓解,但通用 vs 专用词表在策略性能上"基本持平"的结论仅在有限任务上验证,分布外本体上 BPE 合并规则是否仍最优未深究。
- DCT 假设动作平滑:DCT 对平滑信号压缩好,但对真正高频、非平滑、含突变/接触事件的动作(如撞击、滑动、抓取瞬间)是否仍高效?量化 round 会丢掉高频系数,可能恰好抹掉关键的接触瞬态。文中未做频谱层面的失真分析。
- FAST+ 泛化边界未压测:FAST+ 在未见数据集上"≥2x 压缩"只验证了压缩率(offline),但策略性能在移动机器人、灵巧手、humanoid 上仅承认"未测真实 policy"。即压缩好 ≠ 学得好,二者之间的因果链没有在新本体上闭环验证。
- 有损压缩的精度上限:scale γ 控制 lossiness,作者选 γ=10 给出"comparable 重建精度",但没有量化"重建误差→任务成功率"的敏感度曲线;对需要亚毫米精度的任务,固定 γ 是否足够未知。
- 语言遵循优势归因模糊:π₀-FAST 在 DROID 上比 diffusion π₀ 更听 language instruction,作者自己也说"留待 future work"——这究竟是 AR 范式本身的优势,还是 diffusion π₀ 该任务上训练不充分,未做控制实验,结论站不住。
5.3 值得继续探讨的方向¶
- 加速 AR 推理:speculative decoding、量化、定制 kernel、并行解码,把 750ms 压到可做动态任务的水平 —— 这是该路线能否真正落地的关键。
- 压缩 + 非自回归解码结合:在 DCT/压缩表示之上接 diffusion / flow matching 解码,兼顾压缩带来的训练信号增强与并行采样的速度。
- 更广本体的真实 policy 验证:在移动操作、灵巧手、humanoid 上把"压缩好"推进到"策略强"。
- AR vs flow matching 的系统对照:在训练速度、语言 grounding、表达力三个维度做公平、控制变量的大规模对比,给出"何时用哪种解码"的明确指南。
- 替换压缩算法:Huffman / Lempel-Ziv (gzip) 或 learned 压缩与 DCT+BPE 的系统比较,验证"任何足够好的压缩都有效"这一核心假设的边界。
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:source/
- 项目主页:https://pi.website/research/fast
- 通用 tokenizer:HuggingFace
physical-intelligence/fast(FAST+,AutoProcessor) - 关键 baseline / 相关论文:
- π₀(Black et al., 2024)—— 同实验室 flow matching / diffusion VLA,主对照基线
- OpenVLA(Kim et al., 2024)—— per-dim binning autoregressive VLA,naive tokenization 代表
- RT-2 / RT-2-X(Brohan et al., 2023;Open X-Embodiment, 2023)—— binning tokenization 起源
- DROID(Khazatsky et al., 2024)—— 高频 in-the-wild 操作数据集,naive tokenization 失败的真实场景
- Diffusion Policy(Chi et al., 2023)、FSQ(learned VQ 对照)