RLT (RL Token): Bootstrapping Online RL with Vision-Language-Action Models¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:RL Token: Bootstrapping Online RL with Vision-Language-Action Models
- 作者机构:Physical Intelligence(Charles Xu, Jost Tobias Springenberg, Michael Equi, Ali Amin, Adnan Esmail, Sergey Levine, Liyiming Ke)
- 出处:arXiv 2604.23073;项目页
https://pi.website/research/rlt - 关键词:VLA、online RL、actor-critic、TD3、readout token、reference action conditioning、sample efficiency、human-in-the-loop、π₀.₆、precision manipulation
- 一句话:在冻结的预训练 VLA(π₀.₆)顶上插入一个可学习的 encoder-decoder "RL token"(压缩 VLA 的内部表征),再用一个轻量的 actor-critic 在该 token + VLA 参考动作上做 chunk 级 off-policy RL,加上 BC 正则锚住 VLA 行为,从而在数分钟到几小时真机实践内显著提升螺丝拧入、扎带穿孔、网线/充电器插拔这类高精度任务的成功率与速度(关键阶段提速最高 3×,部分任务超过专家遥操作速度)。
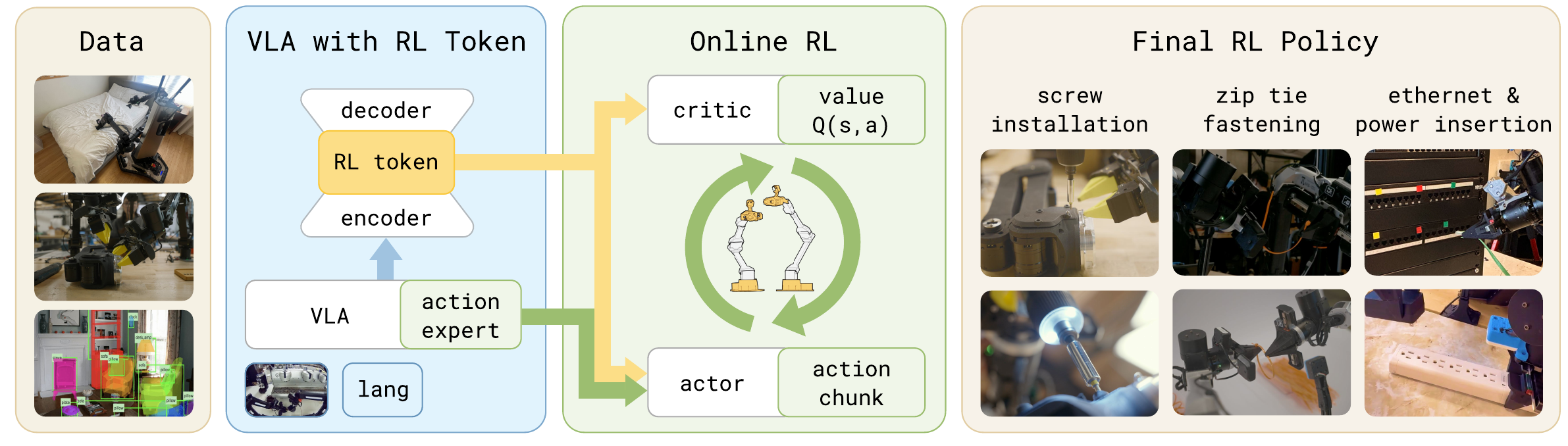 Figure 1(overview):方法总览。左:示范数据;中左:在冻结的 VLA 上加一个 encoder-decoder transformer,瓶颈位置的 token 即 "RL token";中右:用 RL token + 本体感知作为状态,actor 在 VLA 参考动作上做局部 refine,由 critic 提供 Q 值;右:在四个高精度真机任务(拧螺丝、扎带、网线、充电器)上得到的最终 RL 策略。
Figure 1(overview):方法总览。左:示范数据;中左:在冻结的 VLA 上加一个 encoder-decoder transformer,瓶颈位置的 token 即 "RL token";中右:用 RL token + 本体感知作为状态,actor 在 VLA 参考动作上做局部 refine,由 critic 提供 Q 值;右:在四个高精度真机任务(拧螺丝、扎带、网线、充电器)上得到的最终 RL 策略。
2. 文章介绍¶
2.1 解决的领域和问题¶
本文研究 如何在数小时真机数据预算内,用 online RL 把一个通用 VLA fine-tune 成精密任务(亚毫米对位、接触富集)上的可用策略,同时保留 VLA 大规模预训练带来的感知与行为先验。
核心痛点:通用 VLA(如 π₀.₆)虽能跨任务"开箱即用",但在精密、接触富集的"最后一毫米"环节经常掉链子——动作慢、要停顿重试、细小误差会级联失败。直接对几十亿参数的 VLA 做 online RL 在真机上代价过高、样本效率极差;而传统 real-world RL(SERL / HIL-SERL 那类)训练小网络虽快,却放弃了 VLA 的泛化能力与丰富表征。
2.2 Motivation¶
作者主张:"让 VLA 给小模型当感知 + 行为先验"。即不动 VLA 本身,而把 VLA 的内部表征压缩到一个 compact readout(RL token)上,再让一个几百万参数级别的 actor-critic 在它上面跑,并把 VLA 自身的动作分布作为 reference 提供给 actor 做"局部 refine"。这样: - critic 看到的状态低维 → 样本效率高; - actor 不用从零学习多模态动作分布,只需在 VLA 的好动作附近调整; - 整个系统计算开销小,能在真机几小时学习预算内完成。
2.3 之前工作的问题¶
| 路线 | 代表 | 主要缺陷 |
|---|---|---|
| 全量 RL fine-tune VLA | RECAP(π*₀.₆)/ DPPO / SimpleVLA-RL / GR-RL | 大模型在线更新太昂贵,需要数百到上千 episode;on-policy 的 PPO 类难扩到真机 sample-efficient regime |
| Real-world RL 小模型(不用 VLA) | HIL-SERL, SERL, RL¹⁰⁰ | 用 ResNet 编码器从零训,丢失 VLA 的 web-scale 先验和泛化;本文实验里 HIL-SERL 在 50 Hz、无 action-space bbox 的设置下根本学不出来 |
| Residual policy on frozen VLA(单步) | Policy Decorator, ConRFT, PLD | 单步动作 → 稀疏 reward 下信用分配 horizon 太长(一回合上千步),critic 梯度传不动;残差 scale 是手调超参,跨任务不鲁棒;PLD 在本文实验里只有 40% 成功率 |
| Latent-noise RL(在 diffusion noise 空间做 RL) | DSRL, GR-RL(部分) | 只能在 VLA 已有动作模式间"选择",无法发现 VLA 分布外的更快策略;本文实验里 DSRL 成功率与 RLT 相当,但速度提升远不如 RLT |
| DAgger 式纯监督介入 | HG-DAgger | 上限就是人类遥操作速度,无法发现"压一下抖一下"这种 emergent 的更快策略 |
2.4 论文解决方案(一句话)¶
冻结的 VLA + 可学的 encoder-decoder readout token(RL token) 作为状态 + chunk 级 off-policy actor-critic(TD3 风格) + reference action conditioning + BC L2 正则 + reference action dropout + 关键阶段聚焦 + 人工 intervention,把昂贵 VLA 当感知和动作先验,把廉价小网络放在外面学。
2.5 与前序工作的关系¶
- build on π₀.₆:直接用
pi06_model_card提到的 π₀.₆ 模型作为 frozen base,14-DoF、50 Hz、action chunk H=50。RLT 没有修改 π₀.₆ 主体,只是先在小量任务示范上做一次 SFT + RL token 训练。 - 与 RECAP(同组的 π*₀.₆)相对:RECAP 是全量 offline RL,用 advantage conditioning 训整个 VLA,靠成千上万 episode 在多任务上拿到 throughput 翻倍;RLT 反过来——冻结 VLA + 轻量 online RL,专攻"几小时之内精密任务变快变稳"。两者其实是 PI 内部的两条互补路线:RECAP 改 VLA 本身,RLT 在 VLA 外挂一个 RL "微调头"。
- 与 DSRL/GR-RL 关系:同样属于"冻结 VLA、外挂学习模块"路线。DSRL 在 diffusion noise 空间动手(不能跳出 VLA 模式),RLT 在 VLA 输出动作之外学一个完整 Gaussian 动作头,理论上能跳出 VLA 模式。
- 与 HIL-SERL 关系:继承了 HIL-SERL 的 human-in-the-loop(介入 + 二值 reward + 高 UTD)框架,但把 ResNet encoder 换成 RL token,把单步动作换成 action chunk。
- 理论底色:actor 的 BC 正则项 \(\beta\|\mathbf{a}-\tilde{\mathbf{a}}\|^2\) 与 KL-regularized RL(MPO, AWR, REPS)家族一脉相承。
3. 方法介绍¶
3.1 形式化与控制接口¶
设 MDP \((\mathcal{S},\mathcal{A},p,r,\gamma)\),稀疏二值 reward —— 一回合末尾人工标注成败:\(r_T=1\) 成功、\(r_T=0\) 失败。VLA \(\pi_{\text{vla}}\) 接受图像、语言指令 \(\ell\) 与本体感知 \(\mathbf{s}^p_t\),输出 H=50 步的 action chunk(1 s @ 50 Hz):
RL 策略与 critic 工作在长度 \(C<H\) 的子 chunk 上(论文用 \(C=10\),对应 0.2 s)以提升反应性。对应的 chunk 级 Q:
3.2 RL Token:从 VLA 表征中蒸出一个 readout¶
直接把 VLA 整层 token 序列喂给小 actor-critic 不现实——维度太高且 critic 学不动。RLT 用一个小型 encoder-decoder transformer 作为瓶颈把 VLA 的 final-layer token 序列 \(\mathbf{z}_{1:M}\) 压成一个向量 \(\mathbf{z}_{\text{rl}}\in\mathbb{R}^{2048}\)(架构图标的维度):
- 把一个可学习的
<rl>embedding \(\mathbf{e}_{\text{rl}}\) 拼到序列末尾,送进 encoder \(g_\phi\):
- decoder \(d_\phi\) + 线性投影 \(h_\phi\) 自回归重建被 stop-gradient 的 \(\bar{\mathbf{z}}_i\):
VLA 主体可选地与 \(\phi\) 联合做 SFT(系数 \(\alpha\)),训完之后两者都冻结,RL 阶段只更新外挂的 actor + critic。
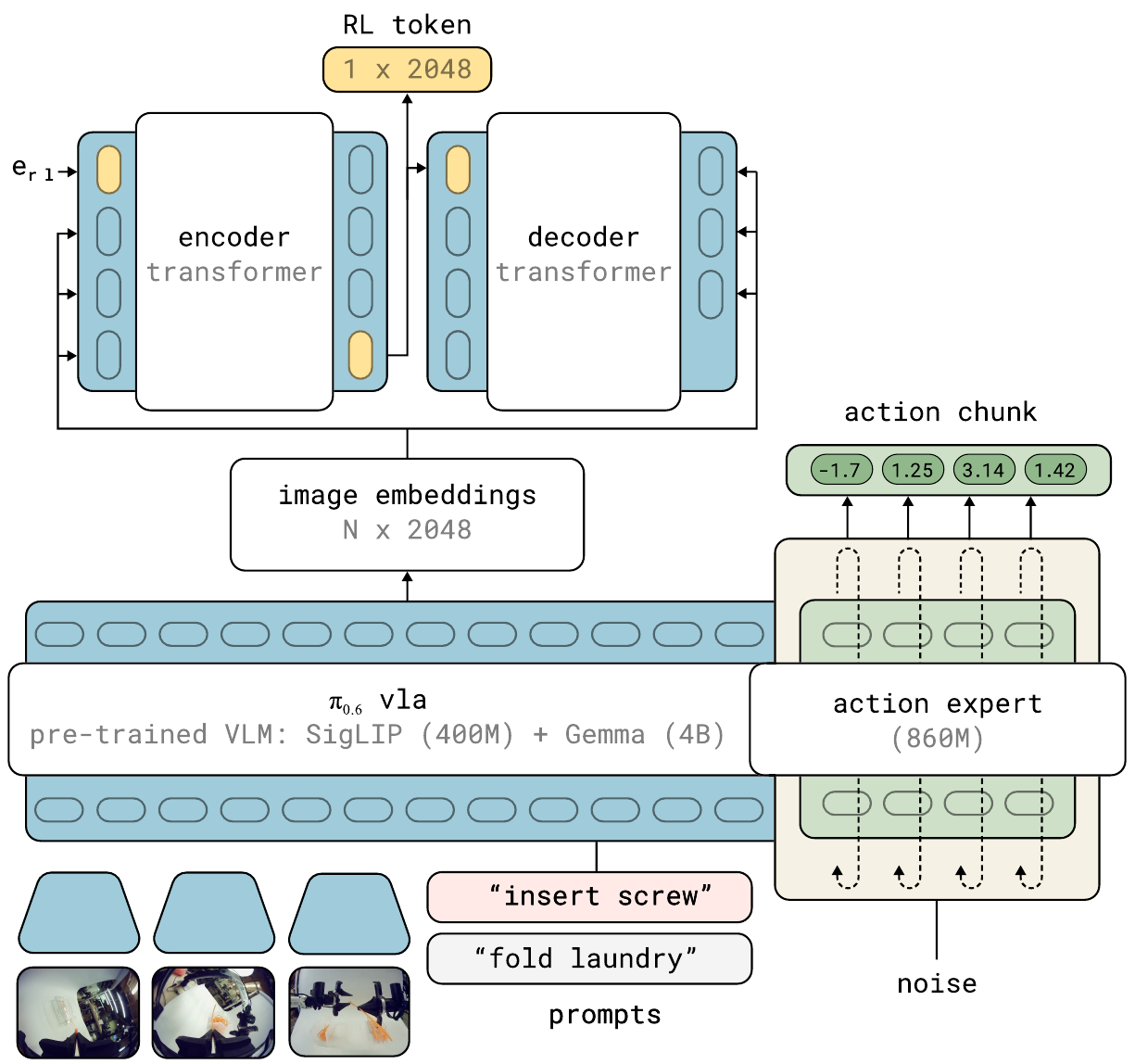 Figure 2(architecture):RL token 抽取细节。底部是 π₀.₆ —— 400M SigLIP + 4B Gemma 的 VLM backbone + 860M action expert。顶上新增的 encoder-decoder transformer 把 image embedding 压成 1×2048 的 RL token;RL 训练时只看这个 token + 本体感知。
Figure 2(architecture):RL token 抽取细节。底部是 π₀.₆ —— 400M SigLIP + 4B Gemma 的 VLM backbone + 860M action expert。顶上新增的 encoder-decoder transformer 把 image embedding 压成 1×2048 的 RL token;RL 训练时只看这个 token + 本体感知。
3.3 Online RL:chunked actor-critic + 参考动作 conditioning + BC 正则¶
Critic(TD3 风格 off-policy TD):输入 \(\mathbf{x}=(\mathbf{z}_{\text{rl}},\mathbf{s}^p)\) 与 chunk \(\mathbf{a}_{1:C}\),做 C-step return + target net bootstrap:
实操采用 二头 Q ensemble + min(clipped double Q)。
Actor:Gaussian 分布、固定小方差,关键在于条件输入里包含 VLA 的参考 chunk \(\tilde{\mathbf{a}}_{1:C}\sim\pi_{\text{vla}}\):
目标:最大化 Q 且惩罚动作偏离 VLA 参考的 L2:
Reference action dropout:训练时约 50% 概率把 \(\tilde{\mathbf{a}}\) 替成 0,强迫 actor 保留独立的动作生成通路;推理时总是把 \(\tilde{\mathbf{a}}\) 喂进去。这一条是防止 actor 偷懒直接抄 VLA 的关键工程 trick。
3.4 完整训练循环¶
参见 Algorithm 1(论文原文):
- 第一阶段(offline):在少量任务示范 \(\mathcal{D}\) 上联合训练 RL token 重建损失 \(\mathcal{L}_{\text{ro}}\)(可选叠加 VLA 的 SFT 损失 \(\alpha\mathcal{L}_{\text{vla}}\)),2000–10000 步。
- Warmup:用 \(\pi_{\text{vla}}\) rollout \(N_{\text{warm}}\) 步(约 5 分钟数据)填 replay buffer。
- Rollout(在线,每 C 步一次):
- VLA 出 \(\tilde{\mathbf{a}}_{1:C}\);
- 抽 RL token 形成 \(\mathbf{x}_t\);
- 选动作:human intervention 时执行 \(\mathbf{a}^{\text{human}}\);warmup 期执行 \(\tilde{\mathbf{a}}\);否则从 \(\pi_\theta(\cdot|\mathbf{x},\tilde{\mathbf{a}})\) 采。
- 介入时把 reference 字段也覆写为 \(\mathbf{a}^{\text{human}}\)(这样 actor 看到的"参考"在介入数据里就是专家动作,会被正则项拉过去)。
- 把 \(\langle\mathbf{x}_t,\mathbf{a}_{t:t+C-1},\tilde{\mathbf{a}},r_t,\mathbf{x}_{t+1}\rangle\) 存入 \(\mathcal{B}\)。
- Subsampling action chunks:每个观测都对应一个时间窗,stride=2 把 \(\langle\mathbf{x}_0,\mathbf{a}_{0:C}\rangle\)、\(\langle\mathbf{x}_2,\mathbf{a}_{2:C+2}\rangle\) ... 全部存入;一秒数据约产 25 个训练样本。
- Update(异步):UTD=5,每次 actor 更新对 2 次 critic 更新;rollout 与学习异步。
3.5 Targeted improvement of critical phases(关键阶段聚焦)¶
四个任务都是"先抓-移动-对位-插入/拧入"的长 horizon(30–120 s,1500–6000 步),但失败几乎都集中在最后的高精度阶段(5–20 s, 250–1000 步)。RLT 只在 critical phase 上 RL:
- 训练时人工决定从哪一步把控制权从 VLA 切换给 RL 策略(类似 HG-DAgger 的 handover);
- 收集与训练数据只覆盖 critical phase;
- 部署时可再额外让 VLA 学一个"何时 handover"的二值预测头,把人工介入作为标签,从而自动切换。
3.x Implementation Details¶
- Base VLA:π₀.₆ —— 400M SigLIP + 4B Gemma VLM backbone + 860M flow-matching action expert,14-DoF 双臂 50 Hz。
- RL token:encoder-decoder transformer,输出维度 2048。
- Actor / Critic:
- 三任务(zip tie, Ethernet, charger):2-layer MLP,hidden=256;
- 螺丝任务:3-layer MLP,hidden=512;
- Actor 头:Gaussian,固定小标准差,输出 \(C\times d = 10\times14 = 140\) 维 chunk;
- Critic:TD3 双 Q + target net,取 min。
- 超参:\(C=10\)、\(\gamma\) 折扣、UTD=5、critic:actor=2:1、reference dropout 50%、warmup ≈ 5 min、训练数据量约 15 min – 5 h(去掉 reset/overhead)、总 episode 数 400–1000。
- 输入:两路 wrist 相机 + 一路 base 相机经 VLA → RL token;本体感知额外加(screw 任务用 joint position;其它三个用 end-effector pose)。
- Reward:人工二值标签 +1 / 0,给在 critical 任务结束时。
- 数据组成:示范数据 1–10 h;warmup rollouts;online actor rollouts;human teleop interventions —— 全部进入同一 replay buffer。
- 训练流程:先 critical-phase 训练,再切到 full-task 微调(base VLA 跑非关键段,RL 接关键段)。
4. 结果对比¶
评测设置:4 个真机任务 × 两种 setting(critical-phase 控制评测 / full-task);每方法 50 episodes/任务;指标 = success rate 与 throughput(successes per 10 min)。
基准:base π₀.₆ SFT 策略 / HIL-SERL / PLD / DSRL / DAgger;以及 4 项消融 w/o RL token、w/o Chunk(\(C=1\))、w/o BC regularizer(\(\beta=0\))、w/o Pass-Through(actor 不看 \(\tilde{\mathbf{a}}\))。
主结果¶
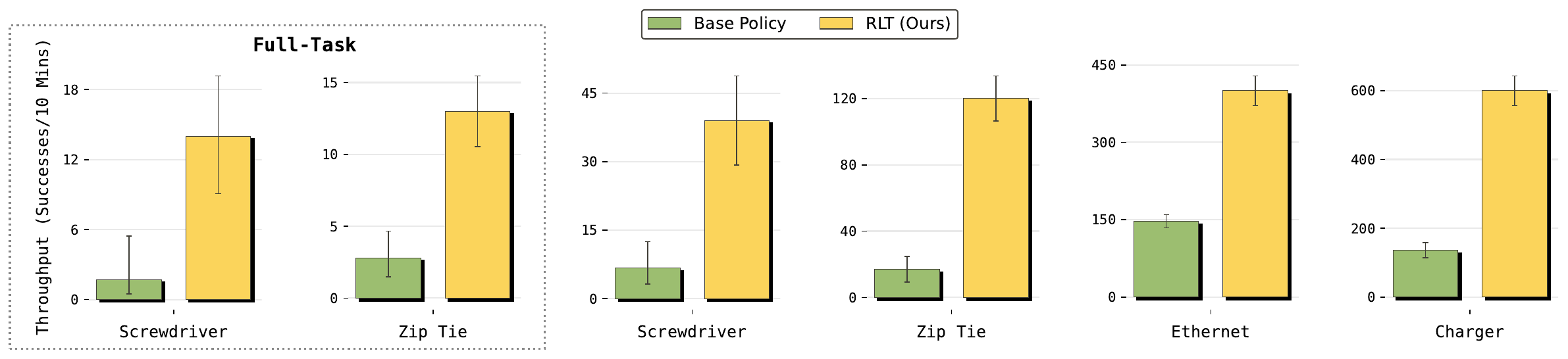 Figure 3(rlt_throughput_all):四任务 throughput 对比。左两个虚线框是 full-task 评测,右四个是 critical-phase 评测。RLT 在所有任务上 throughput 都比 base policy 高出数倍:Ethernet 从 ~150 → ~400+、Charger 从 ~120 → ~600、Zip Tie critical 从 ~15 → ~120、Screwdriver critical 从 ~6 → ~38。Full-task 上 Screwdriver 从 ~1 → ~14、Zip Tie 从 ~3 → ~13。
Figure 3(rlt_throughput_all):四任务 throughput 对比。左两个虚线框是 full-task 评测,右四个是 critical-phase 评测。RLT 在所有任务上 throughput 都比 base policy 高出数倍:Ethernet 从 ~150 → ~400+、Charger 从 ~120 → ~600、Zip Tie critical 从 ~15 → ~120、Screwdriver critical 从 ~6 → ~38。Full-task 上 Screwdriver 从 ~1 → ~14、Zip Tie 从 ~3 → ~13。
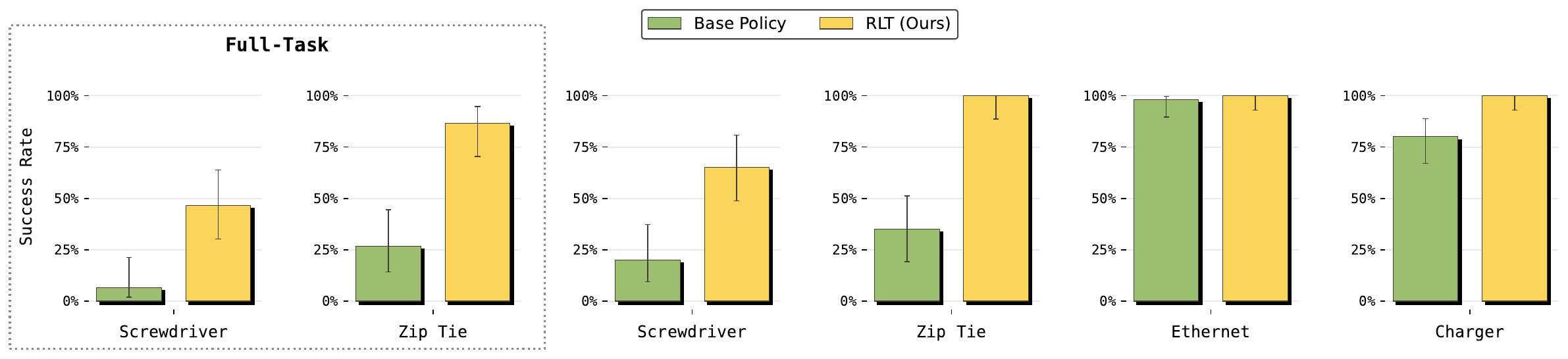 Figure 4(rlt_success_rate_all):对应的成功率。Ethernet/Charger 这种 base 已经接近上限(~80–98%)的任务 RLT 把 100% 拉满;Screwdriver/Zip Tie 这种 base 差的:critical Screwdriver 21%→65%、critical Zip Tie 35%→100%;full-task Screwdriver 6%→47%、Zip Tie 26%→86%。
Figure 4(rlt_success_rate_all):对应的成功率。Ethernet/Charger 这种 base 已经接近上限(~80–98%)的任务 RLT 把 100% 拉满;Screwdriver/Zip Tie 这种 base 差的:critical Screwdriver 21%→65%、critical Zip Tie 35%→100%;full-task Screwdriver 6%→47%、Zip Tie 26%→86%。
| 任务 | base SR → RLT SR | base throughput → RLT throughput |
|---|---|---|
| Screwdriver (critical) | ~21% → ~65% | ~6 → ~38(≈6×) |
| Screwdriver (full task) | ~6% → ~47% | ~1 → ~14(≈14×) |
| Zip Tie (critical) | ~35% → ~100% | ~15 → ~120(≈8×) |
| Zip Tie (full task) | ~26% → ~86% | ~3 → ~13(≈4×) |
| Ethernet (critical) | ~98% → ~100% | ~150 → ~400(≈2.7×) |
| Charger (critical) | ~80% → ~100% | ~120 → ~600(≈5×) |
注:数值是从 Figure 3/4 柱状图视觉读出,论文正文给的口径是 "Ethernet 的关键阶段提速 2×、screw 成功率 20%→65%、screwdriver/zip tie full-task 成功率 +40%/+60%"。
与其它 RL 方法对比¶
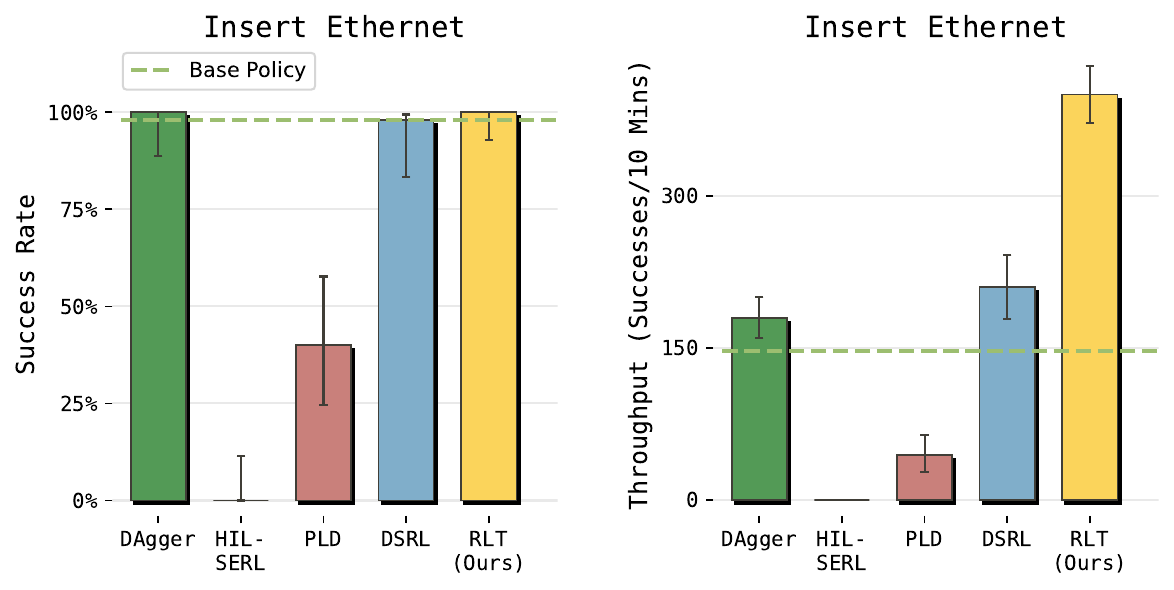 Figure 5(method_comparison):Ethernet 任务上 RLT vs. HIL-SERL / PLD / DSRL / DAgger / Base。结论:HIL-SERL 在 50 Hz 无 action-bbox 设置下根本学不出来(0% SR);PLD(单步残差)只 40% SR;DSRL、DAgger 与 RLT 在成功率上同档(接近 100%),但 throughput 远不及 RLT —— DAgger 受人类示范速度上限制,DSRL 受 VLA noise-space 内插性约束,只有 RLT 把速度做上去了。
Figure 5(method_comparison):Ethernet 任务上 RLT vs. HIL-SERL / PLD / DSRL / DAgger / Base。结论:HIL-SERL 在 50 Hz 无 action-bbox 设置下根本学不出来(0% SR);PLD(单步残差)只 40% SR;DSRL、DAgger 与 RLT 在成功率上同档(接近 100%),但 throughput 远不及 RLT —— DAgger 受人类示范速度上限制,DSRL 受 VLA noise-space 内插性约束,只有 RLT 把速度做上去了。
消融¶
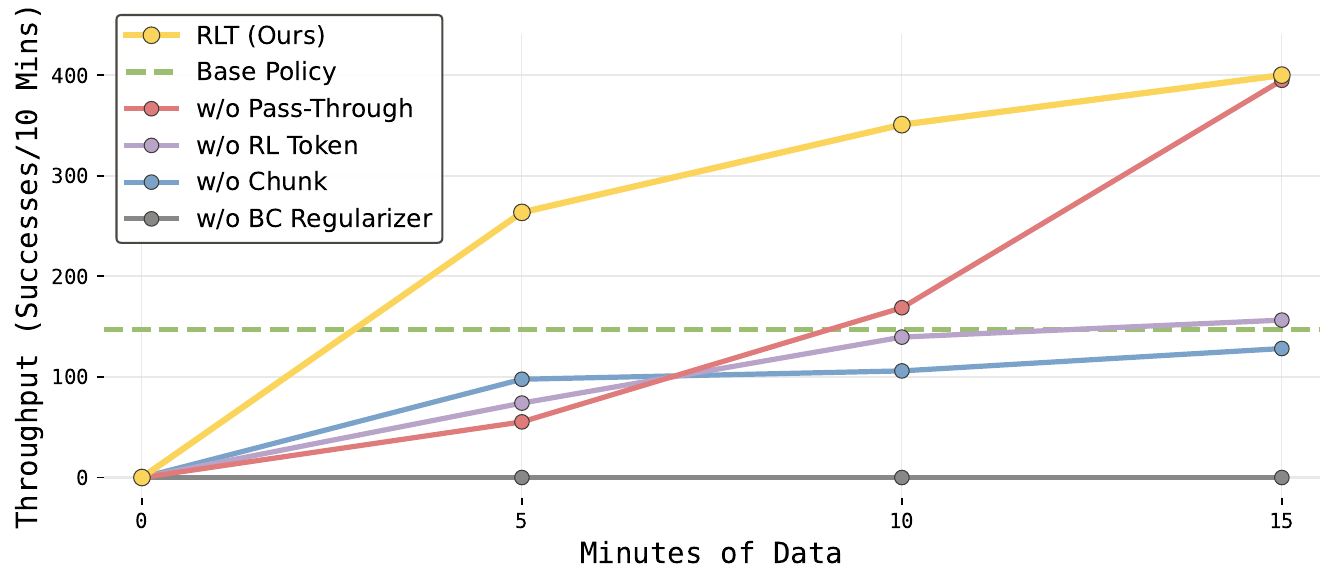 Figure 6(throughput_ablations):Ethernet 上 throughput 随训练时间曲线。结论:1) w/o BC regularizer 直接崩(\(\beta=0\) → 0% throughput)—— 单靠 Q 函数梯度在如此短的训练预算里探索整个 14×10 维 chunk 空间不现实;2) w/o RL token(换 ResNet-10)throughput 砍半;3) w/o Chunk(\(C=1\))由于 horizon 拉长 50× + 必须放弃 RL token,连 base 都比不上;4) w/o Pass-Through 最终能追上,但前期收敛慢、过程中失败显著更多。
Figure 6(throughput_ablations):Ethernet 上 throughput 随训练时间曲线。结论:1) w/o BC regularizer 直接崩(\(\beta=0\) → 0% throughput)—— 单靠 Q 函数梯度在如此短的训练预算里探索整个 14×10 维 chunk 空间不现实;2) w/o RL token(换 ResNet-10)throughput 砍半;3) w/o Chunk(\(C=1\))由于 horizon 拉长 50× + 必须放弃 RL token,连 base 都比不上;4) w/o Pass-Through 最终能追上,但前期收敛慢、过程中失败显著更多。
关键定性发现(Q4):RLT 学到的 Ethernet 插入动作比专家遥操作示范还快——base VLA 会"探测—回退—重试",RLT 学会一气呵成插入、首次失败时压一下抖一下利用接触柔顺性。这种行为不在示范里、是 online exploration 涌现的。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- clean 切分了"VLA 当感知 + 行为先验,小网络当 RL 学习者":架构上简单、计算上廉价,能在数小时真机预算内完成训练,几乎是当前 VLA + RL 路线里最务实的工程方案。
- RL token 这个 readout-bottleneck 设计:用 encoder-decoder 重建损失逼 token 留住 VLA 任务相关信息,效果上比直接挂 ResNet-10 编码器好出 50% throughput;同时维度 2048 足够小,适合下游小 critic 学习。
- chunk-level RL 解决稀疏 reward 长 horizon 信用分配:在 50 Hz 控制下把 horizon 缩 10×(C=10),让 critic 真的能学起来——消融里 \(C=1\) 几乎不能 work,这是 RLT 能在分钟级数据规模下收敛的直接原因。
- Reference action conditioning + BC 正则 + Reference dropout 三件套:actor 不从零学动作分布,只在 VLA 周围 refine;BC 正则提供训练早期的稳定信号;dropout 防止 actor 偷懒抄 VLA。三个组件互补,缺一不可(消融全证)。
- 承认并利用任务的"critical phase"结构:明确只在关键阶段做 RL,把 VLA 留给容易段——避免了"全 horizon RL 但只有最后一步 reward 信号"的死局,是真机 RL 实务的好范式。
- emergent 比示范更快的策略:Figure 7(论文内 episode_length_histogram)显示一半 RL episode 比所有人工示范都快,且学到了"压一下抖一下利用柔顺性"这种示范里没有的行为——证明 RLT 确能跳出 VLA/示范的分布。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 任务集偏窄、几乎全是"插入/扎紧"类接触富集任务:四个任务在"高精度对位+插入"上结构相似,缺乏其它操作模式(如可形变物折叠、liquid pouring、长程序列任务)。论文主张"通用配方",但实际只在一个 task family 上验证,泛化性证据弱。
- HIL-SERL baseline 完全失败可能是 setup 不公平:论文承认 HIL-SERL 原本 10 Hz 且有 action bbox,本文 setup 是 50 Hz + 无 bbox 所以学不出来。把对比对手放在它的弱区里、然后宣称"我们更好",可信度打折扣;应该至少给一个 HIL-SERL 用其原本设置的对照点。
- "Sample-efficient"的口径要看 inference 开销:训练只需几小时数据,但每一步 inference 还是要跑完整 π₀.₆(4B+860M 参数)才拿得到 RL token 与 reference action。所谓"轻量"只是 RL 训练阶段的梯度便宜,部署时每个 50 Hz 决策都付 VLA 全量前向,对实际机器人端部署是非平凡负担——论文几乎不讨论这一点。
- critical phase 完全人工切分 + 人工标 reward + 人工介入:训练时人决定从哪一帧 handover、人决定按 +1 还是不按、人在出问题时介入。所谓"几小时真机训练"实际上是几小时专家在线时间,比 RECAP 还重——论文虽承认这是 limitation,但"sample-efficient"宣传中没有把这部分人力时间纳入。
- w/o RL token = ResNet-10,没有更强 baseline:消融里把 RL token 替成 ImageNet ResNet-10 当然差,但若换成 DINOv2、Theia、SigLIP 等更强的视觉编码器(可与 RL token 同等冻结)就不一定差这么多。当前对照不能完全证明"必须从 VLA 内部抽 token",可能只是"必须有个强视觉表征"。
- chunk 消融与 RL token 消融被混淆:作者明说 w/o Chunk 时因为不能 50 Hz 跑 VLA 所以同时换掉了 RL token——这意味着 Figure 6 中 w/o Chunk 的曲线把两个变量的影响合在一起了,无法清晰归因到 chunking 本身。
- BC 正则系数 \(\beta\) 和 dropout 比例对结果敏感但没扫描:\(\beta=0\) 直接崩,意味着 \(\beta\) 这个超参对结果至关重要;论文没给 \(\beta\) 的 sweep,也没给跨任务的 \(\beta\) 数值——稳定性可能依赖任务调参。
- 数据量统计不透明:正文说"15 min – 5 h actual robot data"、"400–1000 episodes",但具体哪个任务用多少 episode、多少 demo、多少 intervention 都没分项给。Figure 3/4 的对比基础(base 也用同样多 demo?)也不严格——base 已经是 SFT 在 1–10 h demo 上 fine-tuned,但 RLT 还在它上面又用了示范数据训 RL token——总数据使用对比对手未必对齐。
- 没有跨任务 RL token 复用实验:论文承认"RL token 是按任务示范单独训的,跨任务/跨本体迁移是 open question"。这削弱了"RL token 是 VLA 通用 readout"的叙事——目前它更像"任务专属 readout"。
- 统计显著性不充分:每任务每方法 50 episode、消融可能更少。Figure 3/4 的误差棒不小,Screwdriver critical 65% vs base 21% 看起来 wide,但 50 trial 的统计功效一般,少做多次 seed 重复——typical real-robot RL 缺陷。
- DSRL 在 Ethernet 上 success rate 与 RLT 持平:作者着重宣传"throughput 大幅领先",但若客户场景是"插得进就行",DSRL 已经够用且不需要 BC 正则、不需要参考动作 conditioning。"RLT 优势"的实际收益取决于场景是否对速度敏感。
5.3 值得继续探讨的方向¶
- RL token 的跨任务 / 跨本体迁移:能否一次性训一个通用 RL token(在多任务示范上),其它任务直接复用?这是把当前"按任务训 token"扩展到真正"通用 readout"的关键。
- 自动化 critical-phase handover 与 reward:作者已经提到可以训一个轻量 reward model 与 handover 预测头取代人工——把 RLT 推进到 fully autonomous RL pipeline。
- 把 RLT online 数据回流给 VLA:appendix 草稿留过 "Distilled VLA" 的影子(被注释掉),即把 RL 生成的高质量轨迹 SFT 回 VLA 形成 data flywheel;这是和 RECAP 路线汇合的关键一步。
- 更强的 visual encoder baseline:把消融里的 ResNet-10 换成 DINOv2 / SigLIP / Theia 等冻结编码器再比一遍,才能干净归因到"RL token 是 VLA 表征的有效压缩"。
- chunk length C 的自适应:当前 C=10 是固定,若不同任务/不同阶段用动态 C,可能进一步压低 critic 学习难度。
- 与 DSRL 的混合:DSRL 在 VLA noise 空间稳,RLT 跳得出去——把两者级联(先 DSRL warm start,再 RLT 跳出)可能兼得稳定性与上限。
- 真正多任务、长程任务:把 RLT 用到 cafe / box assembly 那种 RECAP 验证过的长程多步任务上,看看 chunk-RL + critical phase 的范式还能不能扩展。
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:source/
- 项目页:
https://pi.website/research/rlt - 关键 baseline / 相关论文:
- π₀.₆(pi06_model_card)、π₀(black2024pi_0)、π₀.₅(pi05)—— base VLA 谱系
- RECAP / π*₀.₆(pi06vla)—— PI 内部的"全量 offline RL 改 VLA"对比路线
- HIL-SERL(luo2024precise)、SERL(luo2024serl)、RL¹⁰⁰(rl100)—— real-world RL 小模型路线
- DSRL(Wagenmaker2025DSRL)、GR-RL(li2025grrl)—— latent noise RL 路线
- PLD(xiao2025selfimproving)、ConRFT(chen2025conrft)、Policy Decorator(pi_dec)—— 单步 residual policy 路线
- DPPO(Ren2025DPPO)、SimpleVLA-RL(Li2025SimpleVLA_RL)—— PPO 类 VLA fine-tune
- TD3(fujimoto2018td3)、SAC(haarnoja2018soft)、RLPD(ball2023efficient)—— off-policy actor-critic 基础
- HG-DAgger(kelly2019)、DAgger(rossdagger)—— human intervention 路线
- Cal-QL(nakamoto2023cal)—— PLD 的 critic 预训练算法
- action chunking(zhao2023learningfinegrainedbimanualmanipulation)、diffusion policy(chi2023diffusion)—— chunked action 与多模态动作分布