VideoWorld:从无标注视频中通过自回归生成学习知识¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: VideoWorld: Exploring Knowledge Learning from Unlabeled Videos
- 作者: Zhongwei Ren¹², Yunchao Wei¹†, Xun Guo², Yao Zhao¹, Bingyi Kang², Jiashi Feng², Xiaojie Jin²†‡(¹北京交通大学 / ²ByteDance Seed)
- arXiv 编号: 2501.09781(submitted 2025-01;CVPR 2025)
- 关键词: video generation, latent dynamics model, knowledge learning, Go-playing, robotic manipulation, autoregressive transformer, VQ-VAE, MAGVITv2, FSQ
- 项目页: https://maverickren.github.io/VideoWorld.github.io/
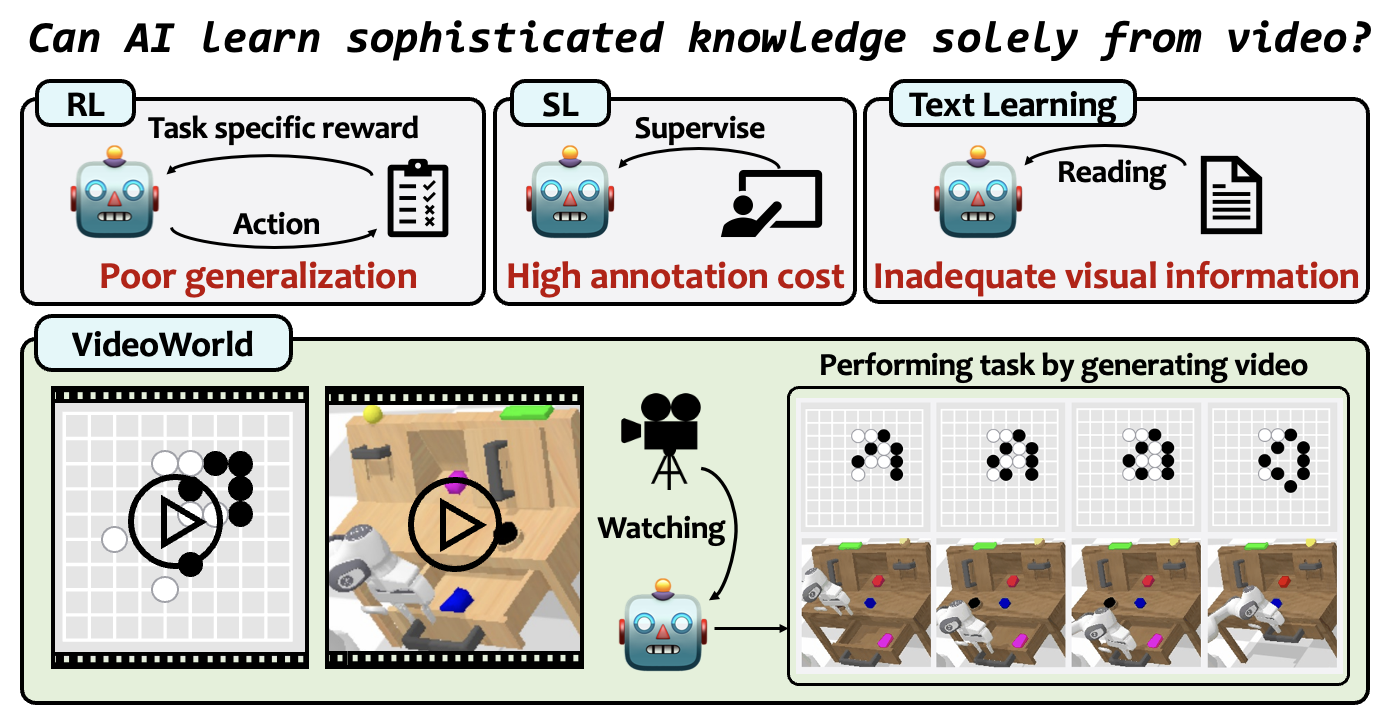 Figure 1:VideoWorld 试图把"读 token"换成"读 frame"。和 RL / SL / text-only LLM 相比,它声称的三大优势是统一的视觉表示(同一组接口跑围棋和机械臂)、无需手工标注、单帧承载的信息密度远大于文字描述。整张图基本是论文 elevator pitch。
Figure 1:VideoWorld 试图把"读 token"换成"读 frame"。和 RL / SL / text-only LLM 相比,它声称的三大优势是统一的视觉表示(同一组接口跑围棋和机械臂)、无需手工标注、单帧承载的信息密度远大于文字描述。整张图基本是论文 elevator pitch。
2. 文章介绍¶
2.1 解决的领域和问题¶
广义的"AI 怎样学习知识"。具体到本文是一个非常学院派的存在性问题:仅靠观看视频、不借助任何文本指令或动作标签,自回归视频生成模型能否学会规则、推理与规划? 实验场景两个:(a) 9×9 视频化围棋(Video-GoBench,自建),(b) 模拟机械臂操控(CALVIN + RLBench)。前者用于隔离"高层策略"——文本/动作 token 数极少时是否仍可观测到推理能力;后者用于检验是否能扩展到带有真实视觉噪声的连续控制。
2.2 Motivation¶
作者在 introduction 反复用同一个比喻:大猩猩通过看就能学会觅食和模仿成年个体,不需要语言。把这个 framing 翻译成 ML 术语就是:next-token prediction 已经在 LLM 上证明能消化结构化知识,那把"token = word"换成"token = video patch"是否仍然 work?文本里描述不出"折叠纸张时手指如何受力"这种身体常识,但视频里有。这条 motivation 直接决定了第二篇 VideoWorld 2 的存在——把这条路径推到真实世界视频。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 文本主导的 LLM/VLM | GPT, LLaMA, Gemini | 文本信息密度低,难以承载具身的物理 / 几何 / 动力学常识 |
| 语言指令驱动的视频策略 | UniPi (du2023unipi) | 仍依赖文本 instruction;任务局限于单步动作;不要求 reasoning / planning |
| 基于状态序列的 SL | KataGo state-based AlphaZero 变体 | 状态序列虽紧凑、但失去局部 stone pattern 等视觉模式;不能跨任务统一 |
| 朴素 video-only AR | VQ-VAE + GPT (本文 baseline idx 5) | 每一步用上百到上千 token 编码冗余视觉细节,关键动作信息被稀释,学习效率远低于 state-based 同行 |
2.4 论文解决方案(一句话)¶
在 VQ-VAE + 自回归 Transformer 的基础上,额外训练一个 Latent Dynamics Model (LDM)——用 \(H\) 个 learnable query 把"当前帧到未来 \(H\) 帧之间的视觉变化"压成 \(H\) 个 FSQ 量化的 latent code,让 transformer 同时预测下一帧 VQ token 与这些 latent code,从而把"关键动作"从"无关像素细节"里分离出来。
2.5 与前序工作的关系¶
- 架构血统:VQ-VAE 端用自家训练的 MAGVITv2 + FSQ 量化器;序列建模端用 LLaMA 架构的 transformer(从头训)。
- 思想血统:把 next-frame prediction 当作 LLM 的视觉变体来训,借鉴 UniPi 的 "video as state space" 框架,但去掉文本条件、并提出 LDM 来缓解 video token 冗余问题——这是本文核心增量。
- 下游兼容:评估时仍需要小规模 action-labeled 数据训练一个独立的 Inverse Dynamics Model (IDM, MLP) 把生成的 frame + latent code 翻成 CALVIN/RLBench 的 7-DoF 控制信号。围棋则直接通过 frame diff 读出落子位置。
3. 方法介绍¶
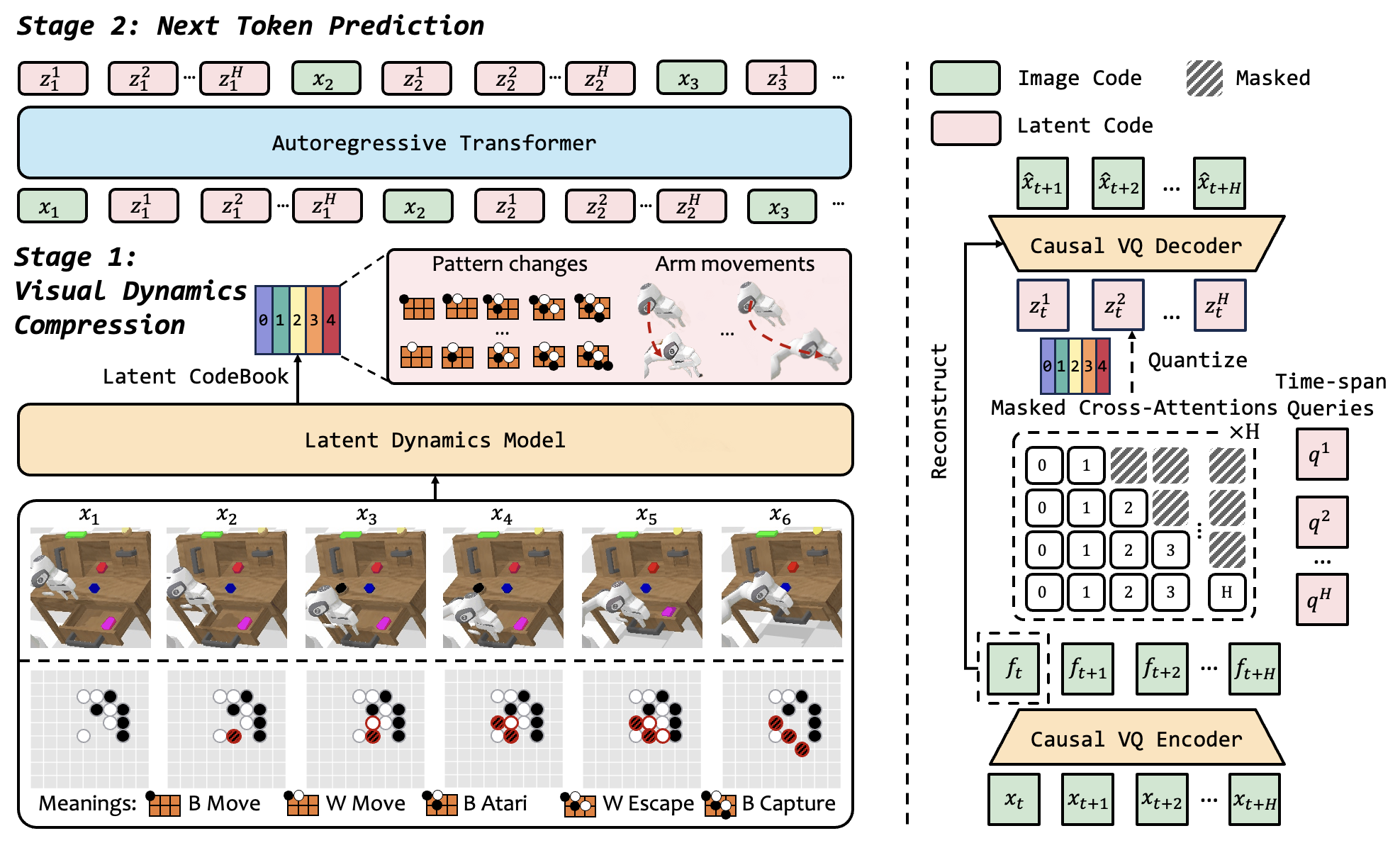 Figure 2:(左)整体架构 — 输入历史帧通过 VQ-VAE 编码成视觉 token,与 LDM 输出的 latent code 拼成同一序列让自回归 transformer 预测下一帧 token + 下一组 latent code。(右)LDM 内部 — causal encoder 出特征 \(f_{t:t+H}\),\(H\) 个 query embedding \(q^h\) 通过注意力捕获不同时间跨度的视觉变化、再 FSQ 量化得到 \(z^h_t\),最后 causal decoder 用 \(f_t\) 和 \({z^h_t}\) 重建未来 \(H\) 帧。
Figure 2:(左)整体架构 — 输入历史帧通过 VQ-VAE 编码成视觉 token,与 LDM 输出的 latent code 拼成同一序列让自回归 transformer 预测下一帧 token + 下一组 latent code。(右)LDM 内部 — causal encoder 出特征 \(f_{t:t+H}\),\(H\) 个 query embedding \(q^h\) 通过注意力捕获不同时间跨度的视觉变化、再 FSQ 量化得到 \(z^h_t\),最后 causal decoder 用 \(f_t\) 和 \({z^h_t}\) 重建未来 \(H\) 帧。
3.1 形式化¶
把每个任务视作元组 \(\mathcal{G}=\langle \mathcal{X},\mathcal{A},\rho\rangle\):\(\mathcal{X}\) 是观察空间(视频帧),\(\mathcal{A}\) 是动作空间,\(\rho\) 是视频生成器。目标是训练 \(\rho(x_{t+1}|x_{1:t})\) 拟合条件分布,配合 IDM \(\pi(\cdot|x_{1:t+1}):\mathcal{X}\rightarrow\mathcal{A}\) 把生成的视觉帧映射为可执行动作。
数据集 \(D=\{x^n_{1:T_n}\}_{n=1}^N\) 完全无 action label —— action 标签只用于训练 IDM,且数据量被刻意压低(small amount of video action label data)。
3.2 Basic 框架:VQ-VAE + AR Transformer¶
- Tokenizer:MAGVITv2 风格 causal encoder-decoder,FSQ 量化器,levels=\([8,8,8,5,5,5]\) → 64,000 codebook。围棋/CALVIN 增加 downsampling 把每帧压到 4×4 grid。
- Sequence model:LLaMA 架构 transformer,输入是逐帧扁平化的 VQ token 串,next-token loss。
- 预训练观察一:纯视频 baseline (Tab. 1 idx 5) 围棋 legal rate 99.6% 已说明它能学会规则,但 Elo 1998 远低于状态序列同行 (idx 4) 的 2308,"会规则但不会下"。
- 预训练观察二:表征的紧凑度决定学习效率。围棋每一步真正信息量 = 1 个位置 token,但视频要花上百 token 编码同一变化。
3.3 Latent Dynamics Model(核心)¶
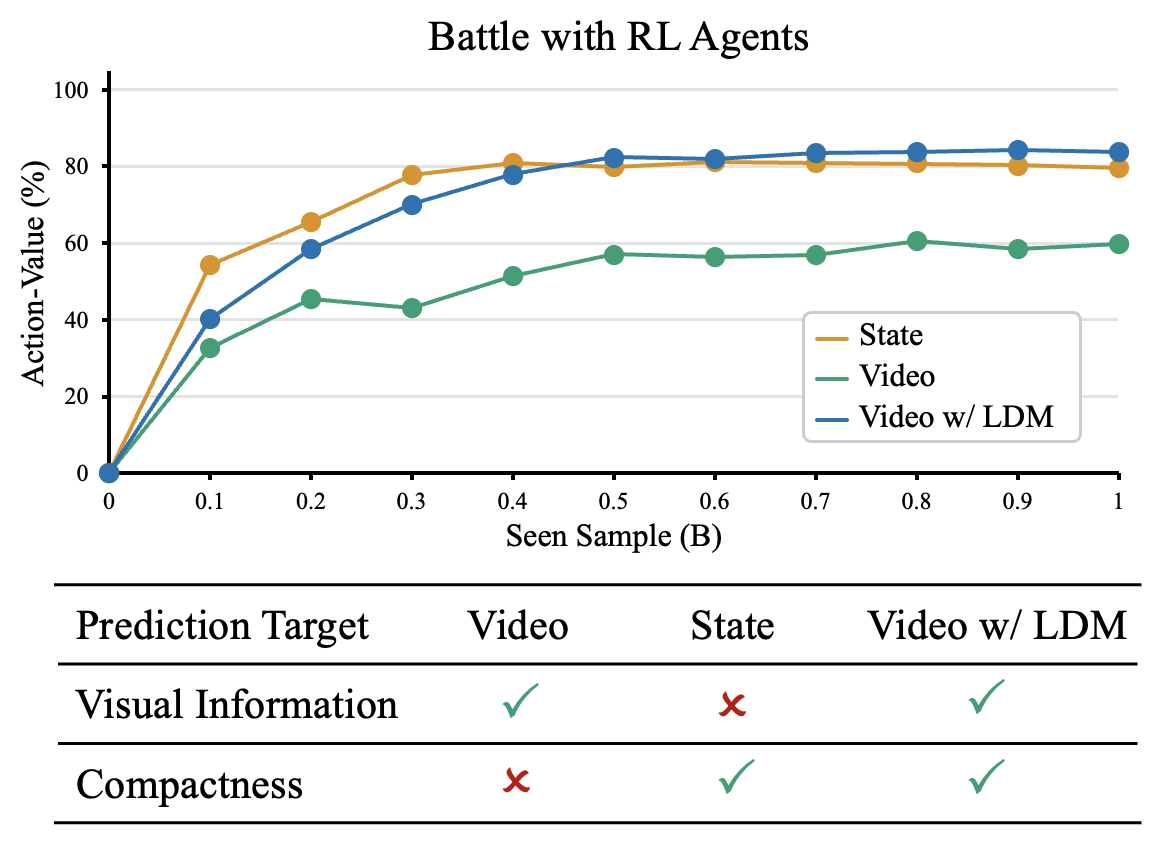 Figure 3:三种预测目标的对比图。State(状态序列)紧凑但失去 stone pattern;Video(裸视频)信息全但稀疏;Video + LDM 同时拥有视觉信息和紧凑的"变化"表示,作者的全部论证都围绕这张图展开。
Figure 3:三种预测目标的对比图。State(状态序列)紧凑但失去 stone pattern;Video(裸视频)信息全但稀疏;Video + LDM 同时拥有视觉信息和紧凑的"变化"表示,作者的全部论证都围绕这张图展开。
对一个长度为 \(T\) 的 clip \(x_{1:T}\),对每帧 \(x_t\) 取后续 \(H\) 帧 \(x_{t+1:t+H}\)(不足时 replication padding):
- Causal encoder:\(x_t,\ldots,x_{t+H}\to f_{t:t+H}\);故意不做时间下采样,保留每帧细节。
- Query bottleneck:\(H\) 个可学习 query \(\{q^h\}\),每个 \(q^h\) 通过 attention 从 \(f_{t:t+h}\) 抽取变化信息得到连续表征 \(\tilde z^h_t\)。
- FSQ 量化:\(\tilde z^h_t \to z^h_t\)。论文明确把这一步叫"information bottleneck,防止 LDM 把 \(f_{t+h}\) 直接 copy 到 \(z^h_t\) 作为捷径"。
- Causal decoder:用 \(f_t + \{z^h_t\}_{h=1}^H\) 还原未来 \(H\) 帧,loss 为 \(\ell_2\)。
关键设计:\(q^h\) 拿到的是 \(f_{t:t+h}\) 这个 逐渐扩张 的窗口而非固定 \(f_{t:t+H}\),因此 \(z^h_t\) 天然成 "逐步深入未来" 的因果序列,对应"先想下一步,再想再下一步"的规划直觉。
3.4 自回归 Transformer 的整合¶
视频 token 与 latent code 拼到 同一 vocabulary(两套 codebook 的并集),transformer 在统一 sequence 上做 next-token prediction。对一段 video \(x_{1:T}\),每个时间步既要预测下一帧的 VQ token,也要预测 \(\{z^h_t\}_{h=1}^H\)。联合预测 frame + code 比仅预测 code 更强(Tab. supp_onlylc:50M 模型上 Action-Value 73.0→73.9,Push 47.2→50.3),作者解释为 "frame 监督能让模型对环境理解更好,反过来提高 code 预测"。
3.5 推理:Frame → Action¶
每一步先让 transformer 自回归生成 \(\{\hat z^h_t\}_{h=1}^H\) 与 \(\hat x_{t+1}\);再用预训练的 IDM(小 MLP)把 \((x_t,\hat x_{t+1},\{\hat z^h_t\})\) 映射为动作。围棋里 action 就是落子位置(可直接读帧 diff),CALVIN/RLBench 里 action 是 7-DoF 末端 + gripper(小规模 action-labeled 数据训 IDM)。
3.6 Implementation Details¶
| 配置 | 围棋 | CALVIN | RLBench |
|---|---|---|---|
| Compression length \(H\) | 5 | 10 | 10 |
| Codebook size (LDM & VQ-VAE) | 64,000(FSQ [8,8,8,5,5,5]) | 同左 | 同左 |
| Per-frame token grid | 4×4 | 4×4 | 4×4 |
| Frame length per clip | 6 | 10 | 10 |
| Batch size | 256 | 32 | 32 |
| Optimizer | AdamW, lr=3e-4, no weight decay | 同左 | 同左 |
| Hardware | 8× A100 | 8× A100 | 同 CALVIN |
| Training time | ~4 days | ~2 days | 与 CALVIN 联训 |
| Model scales | 50M / 150M / 300M | 300M | 300M |
| Trajectory data | 10M 围棋记录(3.2M KataGo self-play + 7.8M OGS 人类比赛) | 标准 ABCD→D | 自建 20k traj |
4. 结果对比¶
4.1 Video-GoBench(围棋)¶
| Idx | Agent | Train | w/o Search | Input | Legal (%) | Action-Value (%) | Best Acc. (%) | Tournament Elo |
|---|---|---|---|---|---|---|---|---|
| 1 | KataGo-1d | RL | ✗ | State | 100 | 67.6 | 64.5 | 2019 |
| 2 | KataGo-5d | RL | ✗ | State | 100 | 83.5 | 83.7 | 2253 |
| 3 | KataGo-9d (Oracle) | RL | ✗ | State | 100 | 100 | 100 | 2700 |
| 4 | Transformer 300M | SL | ✓ | State | 99.8 | 79.7 | 87.2 | 2308 |
| 5 | Transformer 300M | SL | ✓ | Video | 99.6 | 59.7 | 58.9 | 1998 |
| 6 | VideoWorld 50M | SL | ✓ | Video | 99.5 | 73.9 | 80.9 | 2093 |
| 7 | VideoWorld 150M | SL | ✓ | Video | 99.7 | 82.0 | 86.7 | 2218 |
| 8 | VideoWorld 300M | SL | ✓ | Video | 99.7 | 83.7 | 88.1 | 2317 |
亮点:300M video-only 模型 Elo 2317 vs KataGo-5d 2253,所谓"5-dan 专业水平"。和 idx 5(同样 300M 但没 LDM)相比 +319 Elo —— LDM 的增量非常诚实。
4.2 CALVIN(机械臂)¶
| Agent | Input/Output | Push | Open/Close | Turn on/off |
|---|---|---|---|---|
| MCIL | Video / Lab. Action | 33.0 | 38.7 | 41.2 |
| HULC | Video / Lab. Action | 65.8 | 80.9 | 85.3 |
| Transformer (Oracle) | Video / Lab. Action | 75.4 | 95.3 | 96.2 |
| Transformer (video-only baseline) | Video | 17.3 | 24.1 | 19.2 |
| VideoWorld | Video | 56.2 | 75.4 | 72.1 |
| VideoWorld + 10k extra | Video | 65.3 | 81.2 | 79.3 |
| VideoWorld + 30k extra | Video | 72.7 | 91.0 | 93.8 |
加入 30k 由 GR-1 自动生成的轨迹后,VideoWorld 几乎追平 oracle—— 这里 "oracle" 用的是真实 action 监督。
4.3 CALVIN + RLBench 联训(跨环境泛化)¶
| Agent | CALVIN Push | Open/Close | Turn on/off | RLBench Microwave | Fridge |
|---|---|---|---|---|---|
| Transformer (Oracle) | 61.3 | 79.5 | 78.0 | 72.1 | 69.0 |
| Transformer (video only) | 6.5 | 13.0 | 15.6 | 12.0 | 10.9 |
| VideoWorld | 56.0 | 74.8 | 74.5 | 67.1 | 62.5 |
作者主打的卖点:RL 方法很难跨环境共享(每个 env 的 state/action/reward 都不一样),但 VideoWorld 单 checkpoint 同时学会两个视觉迥异的环境。
4.4 关键消融(50M 模型上做的,需稍打折扣)¶
| 设置 | Go Act-Value | Go Act-Acc | CALVIN Push | Open/Close | Turn on/off |
|---|---|---|---|---|---|
| Baseline (no LDM) | 47.5 | 44.3 | 12.7 | 20.8 | 15.6 |
| \(H=1\) | 70.3 | 77.0 | 33.7 | 53.6 | 67.3 |
| \(H=5\)(围棋默认) | 73.9 | 80.9 | 46.8 | 66.1 | 69.6 |
| \(H=10\)(CALVIN 默认) | — | — | 50.3 | 71.1 | 69.7 |
| Codebook 729 | 65.5 | 71.1 | 12.9 | 20.0 | 16.0 |
| Codebook 64,000 (默认) | 73.9 | 80.9 | 50.3 | 71.1 | 69.7 |
| Codebook 262,144 | 50.1 | 53.2 | 29.8 | 30.0 | 31.7 |
Intervene latent codes(intervention 实验):把第 1 个 latent code 替换成随机 token,Act-Value 从 73.9 暴跌到 46.2;替换第 3 个仅小幅下降到 72.1。证明 \(z^1_t\)(最近一步决策)是因果上游。
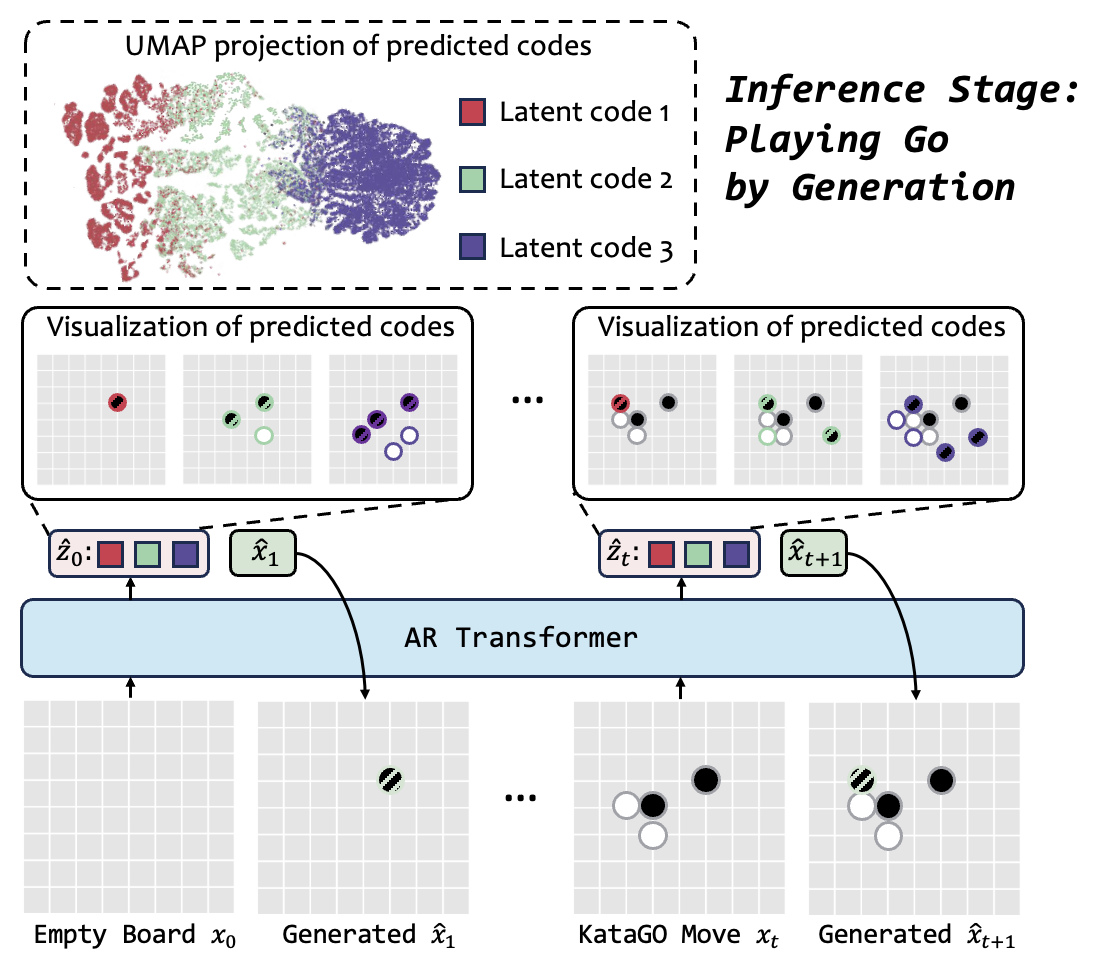 Figure 4:对局过程中预测的 latent code 在 UMAP 空间里按"未来落子位置"自动聚类,作者把这视为"模型有 forward planning"的可视化证据 —— 也是论文里最易引发讨论的一张图。
Figure 4:对局过程中预测的 latent code 在 UMAP 空间里按"未来落子位置"自动聚类,作者把这视为"模型有 forward planning"的可视化证据 —— 也是论文里最易引发讨论的一张图。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- Information bottleneck 用 FSQ + bounded \(H\) 量化器实现,避免 closed-form 形式难题。LDM 把变化压成 \(H\) 个 token 这个动作很关键 —— 既比直接预测 raw frame 紧凑、又比"只输 latent 不输 frame" 多了一个监督信号。本质上和 LAPA 的 latent action 一脉相承,但论文是较早把"latent code + frame token 同 vocabulary"做穿的一篇。
- 逐步因果的 query 设计 \(z^h_t\) 依赖 \(f_{t:t+h}\) 而非 \(f_{t:t+H}\):天然可以解释成"先想 next step、再想 next-next step"的规划序列。Intervention 实验把第 1 个 code 打乱影响最大,证据自洽。
- 联合预测 frame + code 比只预测 code 更强(supp_onlylc:50M 上 73.0→73.9)。这个微小但稳定的提升给"frame 监督仍有信号"提供了实证,否定了"既然 LDM 已经压完信息,frame 预测可丢弃"的怀疑。
- 任务选择很巧妙:围棋天然剥离低层视觉细节、把"高层规划"暴露成可量化的 Elo / Action-Value —— 这是 LLM 时代研究 reasoning 时罕见的 clean testbed。300M 单模型打到 KataGo-5d 的事实即便是抽水(详见 §5.2)也很有冲击力。
- CALVIN + RLBench 联训跨环境泛化(Tab. 4):在 video diffusion / WAM 这条线里,作者较早证明 "video-only AR + LDM" 这条更轻量的路线也能拿到跨环境单模型。
- 代码和数据集开源 + 10M 围棋 trajectory 真的有 benchmark 价值:Video-GoBench 作为"reasoning from video"的可控测试床,可以被未来工作复用,论文的开源承诺已落地。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "5-dan professional level" 这个 headline 非常会取标题。KataGo-5d 在公开排位里只是 5-dan 业余水准(围棋的 1d-9d 一套用于段位,9d 业余 ≠ 9d 职业),作者也在脚注承认这一点,但摘要/intro/会议宣传一律省略——这是论文最容易被业内挑刺的地方。
- 基线 idx 5(300M Video transformer no-LDM, Elo 1998)有抽水嫌疑。同样 300M 没有 LDM 的 transformer 比 50M 带 LDM (Elo 2093) 还低 95 分。但 baseline 仍能保 99.6% legal rate,说明它学到了规则;那为什么 Elo 那么低?合理怀疑是 baseline 调得不够认真。如果对照组多花两周调,差距大概率不会这么夸张。
- VideoWorld 2 自承"VideoWorld 在真实视频上不工作":续作直接给出了 Video-CraftBench 上 VideoWorld 无法完成 paper folding 第 6 步以后的所有任务(Tab. 1 row 8, OpenX 预训练后 step-7 仅 31.9%),并归因为 "latent code 与 appearance 纠缠"。这条对 VideoWorld 的局限定性非常诚实,但反过来削弱了它在 motivation 里"general knowledge learner"的口号 —— 真实世界视频它没在工作。
- Codebook 大小、\(H\)、batch size 多个超参之间"恰好"对齐到 64,000 / [8,8,8,5,5,5]。Tab. ablation 显示 262,144 codebook 直接崩到 Act-Value 50.1(甚至低于 baseline)。也就是说 LDM 训练稳定性对 codebook 严重敏感,但论文没给"如何选 codebook"的可操作经验,更像 hyperparameter tuning 的运气。
- IDM 需要 action-labeled 数据:摘要里多次强调"video-only",但实际部署仍要小规模 action 标签训 IDM。这跟 LAPA 等 latent action 工作一样,只是把"label 量"压低、并没有真正做到 0-label。CALVIN +30k 数据那一行恰恰说明 IDM 的标签量是决定性变量。
- \(H=5\) 围棋外不收敛:"when we vary the compression length while keeping the codebook size constant... For Go, optimal performance is at 5 steps, but further increasing the length causes the LDM training to fail to converge."(§4.7)——LDM 的训练在 \(H\) 大、codebook 大时直接发散,但 paper 用"exponential growth"一句话糊过。对希望复现/扩展到长 horizon 任务的人是个深坑。
- CALVIN 评估接口对自家有利:CALVIN 任务划分为 "Push / Open-Close / Turn on-off" 三类,VideoWorld 报的是这三类独立 task success rate,而 CALVIN 协议常见的是 5 task 长序列评估(VideoWorld 2 自己改回了长序列协议)。当下数字看起来非常接近 oracle,但换成长序列协议数字会大幅降低。
- Forward planning 的"证据"几乎全是 UMAP 可视化。Fig. umap_test 显示 latent code 在空间上按落子位置聚类,作者把它解释为"规划",但 UMAP 是 t-SNE 同族的 降维可视化,强行从聚类得出"模型在做 planning"的结论是 over-interpretation 的常见姿势。Intervene 实验 (Tab. abla_intervene) 才是真正的因果证据,作者把可视化排在前面、把因果实验埋在后面,叙事偏好可见一斑。
- 30k extra trajectory 数据从 GR-1 (一个用 ground-truth action 监督训的 SL agent) 蒸出来:意味着 VideoWorld + 30k 已经隐式接受了 SL 监督,"approaching oracle" 的对比因此并不干净 —— oracle 用 action label,VideoWorld + 30k 用了 GR-1 蒸出的 action label,差异只在标签 noise。
- 真实世界缺位。所有实验都在合成 / 仿真里跑。围棋当然是合成;CALVIN/RLBench 是仿真。"AI 像大猩猩学习"那个 motivation 站不到真实世界,论文里也只字未提 sim-to-real。VideoWorld 2 正是填这个洞。
5.3 值得继续探讨的方向¶
- LDM 与 LAPA / Genie 的真正差异是什么? 三者都用 VQ 把 inter-frame change 压成 latent action。LDM 强调多步(\(z^h_t\) 序列依赖于 \(f_{t:t+h}\))、LAPA/Genie 更接近 2-frame transition。可以做严格对照实验把这条线分清楚。
- codebook 调度:能否引入 progressive codebook(如 RQ-VAE 的 residual 量化、或可学习的码本扩张)避免 64k → 262k 崩溃?
- 长 horizon LDM 训练发散的原因:是 codebook collapse、还是 attention 在长 query 上的 gradient 信号衰减?做几条 ablation 应能区分。
- 把 LDM 视作 forward planning 的"显式 token",能否做 latent-level CoT? 比如让 transformer 在 reasoning 期间多采样几条 latent rollout 再 take expectation,类比文本 LLM 的 self-consistency。
- 去掉 IDM? 即把 action head 直接 join 到 transformer 的输出 vocabulary 上(像 OpenVLA / RT-2 那样把 action 也 tokenize),这样 video pretrain 与 action fine-tune 共享 backbone。
- 如何评估 latent code 是否真的"理解物理" vs 仅仅 memorize trajectory pattern。可以在 CALVIN 上做物理参数 perturbation(摩擦、质量),看 latent 是否仍稳健。
- VideoWorld 2 用 VDM 做 appearance prior 来 fix appearance entanglement —— 在 LDM 的 codebook + FSQ 设计内能否单独通过 architectural change 解决同样问题?
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页:https://maverickren.github.io/VideoWorld.github.io/
- 续作:VideoWorld 2 (2602.10102)
- 关键 baseline / 相关论文:UniPi (du2023unipi), MAGVITv2 (yu2024magvitv2), FSQ (mentzer2024fsq), LAPA (lapa_ye2024latent), Genie (bruce2024genie), KataGo (wu2019katago), CALVIN (mees2022calvin), GR-1 (wu2023gr1)