Gigapixel:把 self-play 推进到 end-to-end 像素驾驶¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Scaling Self-Play for End-to-End Driving
- 作者: Luke Rowe\(^{1,2}\), Roger Girgis\(^{1,3,4}\), Rodrigue de Schaetzen\(^{1,2,4}\), Daphne Cornelisse\(^{5}\), Alaap Grandhi\(^{1,6}\), Felix Heide\(^{4,7}\), Eugene Vinitsky\(^{5}\), Christopher Pal\(^{1,2,3}\), Liam Paull\(^{1,2}\)
- \(^1\)Mila, \(^2\)Université de Montréal, \(^3\)Polytechnique Montréal, \(^4\)Torc Robotics, \(^5\)NYU Tandon, \(^6\)McMaster, \(^7\)Princeton
- arXiv 编号: 2606.19641(2026-06 提交,目标 CoRL 2026)
- 关键词: end-to-end autonomous driving, self-play, self-play DAgger, Gigapixel simulator, sim-to-real perception adaptation, closed-loop training, HUGSIM, NAVSIM-v2
- 项目主页: https://montrealrobotics.ca/gigapixel
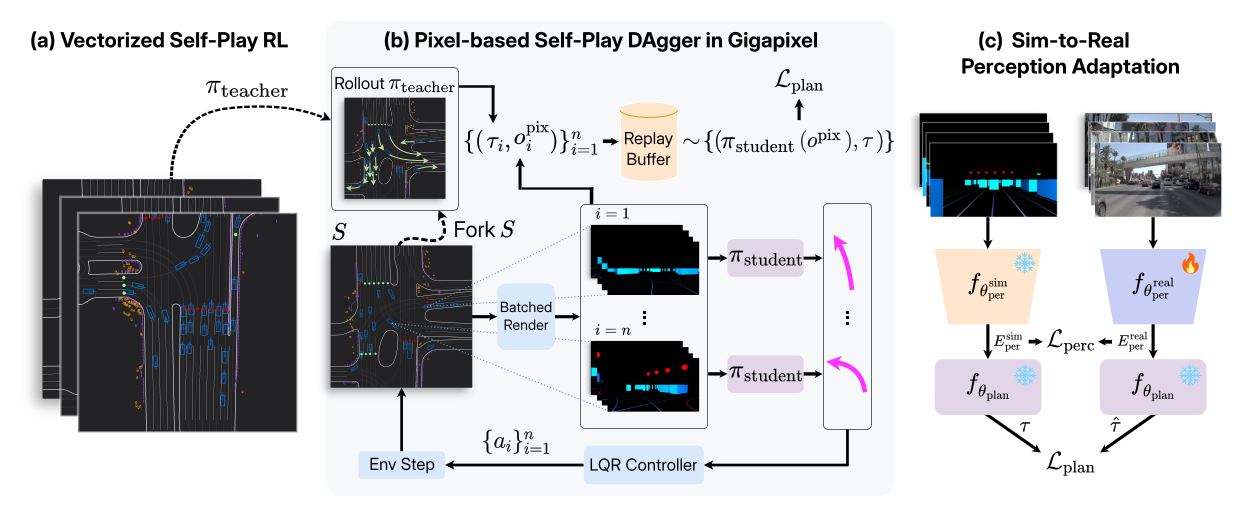 Figure 1:三段式 pipeline——(a) 在抽象 vectorized 模拟器里用 self-play RL 训一个特权 teacher;(b) 在 Gigapixel 透视渲染里,让 pixel-based student 自己控所有车,向并行 forked teacher rollout 的 4 秒轨迹蒸馏;(c) 仅用 NAVSIM 配对真实-合成观测微调 perception backbone,planning head 冻结。
Figure 1:三段式 pipeline——(a) 在抽象 vectorized 模拟器里用 self-play RL 训一个特权 teacher;(b) 在 Gigapixel 透视渲染里,让 pixel-based student 自己控所有车,向并行 forked teacher rollout 的 4 秒轨迹蒸馏;(c) 仅用 NAVSIM 配对真实-合成观测微调 perception backbone,planning head 冻结。
2. 文章介绍¶
2.1 解决的领域和问题¶
End-to-end autonomous driving(直接从相机像素输出轨迹/控制的单网络栈)目前几乎被 behavior cloning (BC) 人类驾驶 log 统治:UniAD / VAD / DiffusionDrive / Hydra / DrivoR 一脉。BC 的两个结构性缺陷在 closed-loop 上反复被打脸——(i) log 状态覆盖窄(compounding covariate shift),(ii) 训练时根本没有 "policy 自己行为引起的反馈",所以一旦走偏就回不来。本文的具体问题是:能否把 self-play 这条"靠廉价合成经验扩展"的范式从 vectorized BEV 抽象 simulator 推进到端到端像素 policy 上去?
2.2 Motivation¶
Self-play(每个 agent 都被同一份 decentralized policy 控制)此前在 Gigaflow / PufferDrive / GPUDrive / Nocturne 上已被证明能产出鲁棒且自然的驾驶行为,但所有这些工作的 observation 都是 vectorized BEV——和真实部署需要的 raw sensor 输入完全脱节。另一方面,HUGSIM / DriveArena 这类 photorealistic sensor simulator 又慢得撑不起 self-play 所需的几十亿步经验。要把这两条线拼起来,需要:①一个 pixel-native 而又超高吞吐的 simulator;②一个能在大模型上跑通的 sample-efficient 训练范式(直接 pixel-space RL 太贵);③真实部署时的 sim-to-real 接口。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Pure BC E2E | UniAD, VAD, DrivoR, DiffusionDrive | 状态覆盖窄、compounding error、靠堆数据不解决根因 |
| Photorealistic Sim + RL | CARLA, HUGSIM, DriveArena | 渲染慢 1000-4000× 不足以撑 self-play 大规模训练 |
| Vectorized self-play | Gigaflow, PufferDrive, GPUDrive, Nocturne | BEV 输入与 pixel-based E2E policy 完全不兼容 |
| Single-agent DAgger | 老式 DAgger pipeline | 只有 ego 是 student,邻车 log-replay 行为缺多样性、不会产生交互场景的自演化 |
| Augmented BC (SimScale) | DrivoR + SimScale | 离线给 134k recovery 例子的"伪闭环",本质还是 open-loop 监督 |
| Simplified rasterizer | RAP | 思路类似但纯 CPU、无 batched ECS 渲染,比 Gigapixel 慢约 4000× |
2.4 论文解决方案(一句话)¶
用 Gigapixel(50k agent-SPS 的 GPU 批量透视渲染 simulator)+ self-play DAgger(让 pixel-based student 控所有车、特权 vectorized RL teacher 通过 forked 并行 rollout 提供 4-秒轨迹监督)+ lightweight perception adaptation(冻结 planning head、L2 配对 perceptual loss 仅微调 backbone),训出一套完全不用人类轨迹监督就能 SOTA HUGSIM 的 end-to-end driving policy。
2.5 与前序工作的关系¶
- 直接继承:Gigaflow(Cusumano-Towner et al. 2025)的 multi-objective + persona-conditioned 2.7M PPO teacher 配方;PufferDrive 抽象 simulator;Madrona ECS 批量渲染引擎(Shacklett 2023)。
- 复用:student 架构是 DrivoR(Kirby 2026),主干 DINOv2 + 64 trajectory proposals + 子 PDMS scoring,外加它的 regression-only 变体 DrivoR-Reg。
- 直接对比:DrivoR (BC)、DrivoR (w/ SimScale)、SimScale 本身、ZTRS、GuideFlow、UniAD / VAD / LTF。
- 训练 / 评测数据:nuPlan train split 抽 335k 个 20s 场景;HUGSIM (345 scenes from nuScenes/Waymo/PandaSet/KITTI 四难度等级) 与 NAVSIM-v2 navhard。
3. 方法介绍¶
3.1 形式化¶
学一个 end-to-end 策略 \(\pi(\tau | I, C)\),输出未来 \(H\) 步 ego-centric waypoint 序列 \(\tau = \{(x_t, y_t, \theta_t)\}_{t=1}^{H}\),由低层 LQR 控制器跟踪、receding-horizon 重规划。策略分解为 perception backbone \(f_{\theta_\text{per}}\) + planning head \(f_{\theta_\text{plan}}\),对 head 形式不加约束(scoring/diffusion/regression 均可)。
3.2 Gigapixel: 高吞吐透视渲染抽象 simulator¶
- State: \(S_t = (A_t, M, L_t)\) —— agent bbox、静态 map polyline、信号灯。
- Primitive 渲染:车辆 / 行人 / 骑行 / 静态障碍 = cuboid,lane polyline = 薄平面片,信号灯 = 小球。
- Engine:把 PufferDrive 抽象 sim 接上 Madrona rendering,提供 rasterization + ray tracing 两套渲染,全部 GPU 批量化。
- Throughput:1×A100L 上 ray-traced 50k agent-SPS;rasterizer 比 HUGSIM (3DGS) 快 ~1000×,比 RAP 快 ~4000×(同 512×512)。模型变重之后渲染基本不再是瓶颈。
- Action / Reward / 物理 / Camera Rig 在 Appendix;训练用前/前左/前右/后 4 路视角,分辨率 \(210\times126\) → 后期升到 \(434\times252\)。
3.3 Self-play DAgger(核心算法)¶
为什么不直接 pixel-space self-play RL?图 dagger_vs_rl 给了清晰答案——pixel CNN 直接 RL 跑到 60 分需要的步数是 DAgger 的 ~3000×。原因:(i) E2E policy forward/backward 比 vectorized teacher 贵得多;(ii) RL 输出是低层 control,与 E2E 需要的轨迹接口不一致。
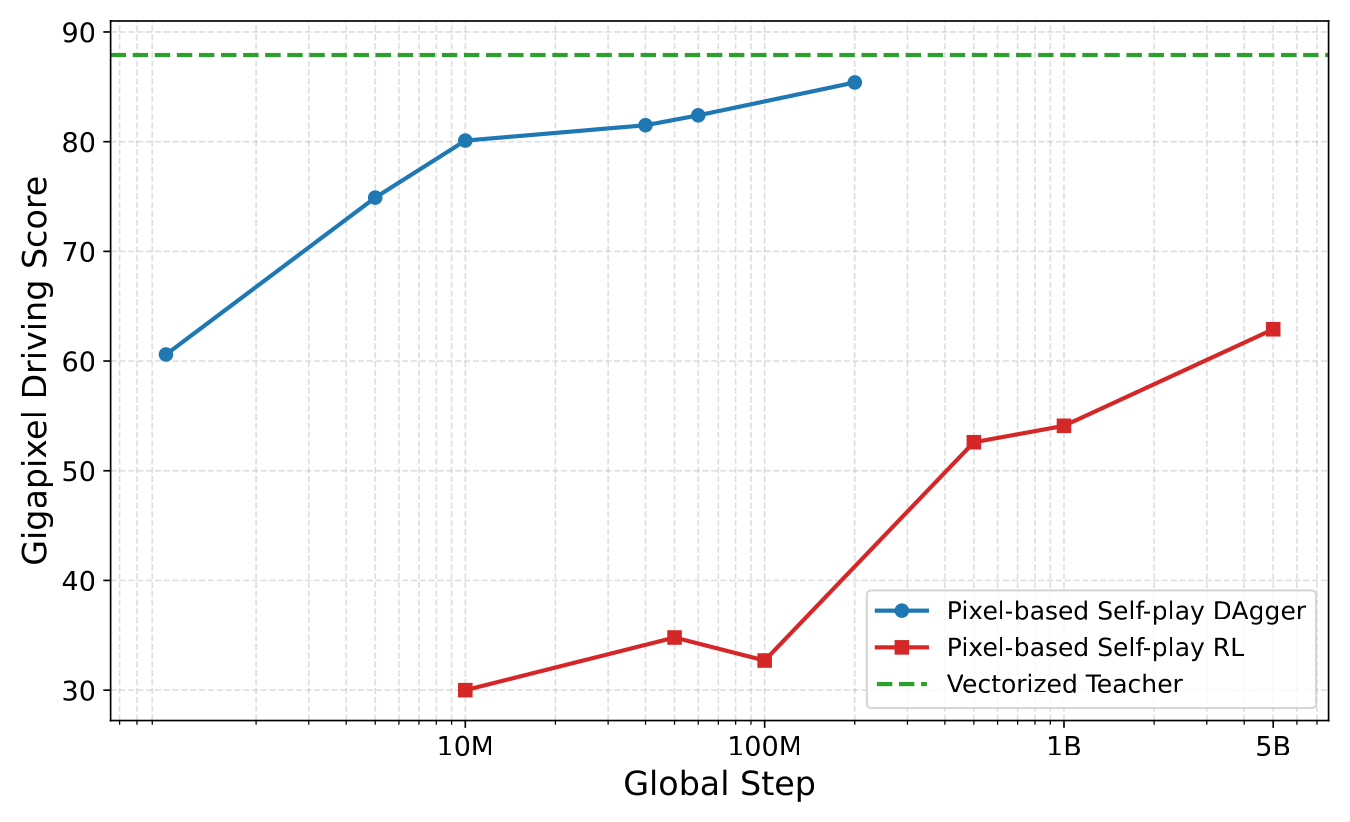 Figure 2:Self-play DAgger 用 3000× 更少 agent steps 达到 score 60,正是用 DAgger 蒸馏代替直接 pixel-RL 的核心理由。
Figure 2:Self-play DAgger 用 3000× 更少 agent steps 达到 score 60,正是用 DAgger 蒸馏代替直接 pixel-RL 的核心理由。
定义 self-play 诱导的状态分布 \(d^{\text{self-play}}_{\pi_\text{student}}\) —— 所有 agent 都被 student 控制时的边缘状态分布。目标:
关键区别于 vanilla single-agent DAgger 的两点: 1. 每个 agent \(i\) 都贡献监督样本——一个 sim step 出 N 条训练对,experience 直接 ×N。 2. 场景与 policy 协同演化——student 进步 → 多 agent 交互更刁钻 → 自动产出 BC 数据里几乎不存在的近碰撞、recovery、谦让等 corner case。
Teacher: 特权 vectorized RL¶
按 Gigaflow 改 PufferDrive。2.7M 参数 permutation-invariant decentralized policy,PPO,跑 25B agent steps(8×H200 / 24h)。多 reward 项 (collision / offroad / comfort / ...) 线性加权 + 系数 per-agent 随机化,相当于在 self-play 里隐式生成「冒进 / 稳健 / 谦让」等 persona 群体,student 在分布更宽的对手里被磨。
Student: pixel 蒸馏¶
- 在 \(S\) 处把 simulator fork 一份并行实例,rollout teacher \(H = 4\) 秒得到每个 agent 的目标轨迹 \(\tau_i\)。
- Student 输出 \(\hat\tau_i\),按 LQR 跟踪后续执行。
- DAgger 的 \(\beta\)(teacher 控制概率)从 1 线性退火到 0(前 125M 步),尾部 25M 步纯 student,避免初期 chaotic self-play 把训练带飞。
- Persona 向量 \(\mathbf{c}_i\) 同时输入 teacher(决定 \(\tau_i\) 风格)与 student(保持训练 / 行为一致),相当于把 conditional behavior 也一并蒸进 student。
- 训练用 FIFO replay buffer + filter 掉 teacher rollout 本身就撞车/出路的样本。
3.4 Sim-to-Real Perception Adaptation¶
把 sim-to-real 完全锁在 perception 而不让 planning head 动,是这篇结果能跑赢 BC 的关键工程选择。
- 配对集 \(\mathcal{D}_\text{paired} = \{(o^\text{real}, o^\text{pix})\}\):把 NAVSIM
navtrain每一帧的抽象状态重建出来,用 Gigapixel 渲染成 \(o^\text{pix}\),与原始 real frame 配对。 - 复制两份 student:frozen \(\pi^\text{sim}\)(吃 \(o^\text{pix}\),作 teacher);trainable \(\pi^\text{real}\)(吃 \(o^\text{real}\),只动 perception backbone);planning head 共享冻结。
- 损失 = self-play DAgger 时同款 planning loss + perceptual L2 对齐 $\(\mathcal{L}_\text{perc} = \|f_{\theta_\text{per}^\text{real}}(o^\text{real}) - f_{\theta_\text{per}^\text{sim}}(o^\text{pix})\|_2^2\)$
- \(\lambda = 1\),10 epoch,4×A100L / 12h,\(434\times252\)。
3.x Implementation Details¶
| 项 | 数值 |
|---|---|
| Teacher 参数 / 训练 | 2.7M / 25B steps / 8×H200 / 24h |
| Student 参数 / 训练 | DrivoR + DinoV2 / 150M self-play steps / 8×H200 / 36h |
| 渲染分辨率 | 前 125M 用 \(210\times126\);尾 25M 用 \(434\times252\) |
| Camera rig | 前 / 前左 / 前右 / 后 4 路 |
| Replay buffer | FIFO,filter teacher 自爆样本 |
| Sim2real | NAVSIM navtrain,10 epoch,4×A100L / 12h |
| 训练场景 | nuPlan train 抽 335,245 段 20s |
| 评测场景 | Gigapixel held-out 1000 段;HUGSIM 345;NAVSIM-v2 navhard |
| Renderer | ray tracing(高画质) + rasterization(更快),均 Madrona ECS |
4. 结果对比¶
4.1 HUGSIM(闭环、Gaussian-splatting 重建 4 难度等级)¶
| Method | Human Traj? | RC Avg. | HD-Score Avg. |
|---|---|---|---|
| LTF | ✓ | 38.9 | 23.7 |
| VAD | ✓ | 31.4 | 13.4 |
| UniAD | ✓ | 45.9 | 32.7 |
| DrivoR-Reg (BC) | ✓ | 40.5 | 20.7 |
| Gigapixel-DrivoR-Reg (ours) | ✗ | 49.2 | 33.2 |
| DrivoR (BC) | ✓ | 49.8 | 35.7 |
| DrivoR (w/ SimScale) | ✓ | 46.4 | 38.1 |
| Gigapixel-DrivoR (ours) | ✗ | 50.1 | 38.5 |
- 不用任何人类轨迹监督就拿到 HD-Score / RC 双 SOTA。
- 反直觉细节:Extreme tier (X),BC 版 DrivoR 反而比 ours 高 11 分(32.5 vs 21.6)。作者剖析:BC 学了 high-velocity bias——开得快"碰巧"能甩开来撞自己的对抗 agent。证据是平均碰撞速度 DrivoR 5.27 m/s vs Gigapixel-DrivoR 1.95 m/s(2.7× 差距),即 BC 的 X 优势来自不安全而非更聪明。
4.2 NAVSIM-v2 navhard(伪闭环,Stage 2 是 perturbed 起姿的关键回归代理)¶
| Method | Human Traj? | SimScale? | Stage 2 Score | EPDMS |
|---|---|---|---|---|
| DrivoR-Reg | ✓ | ✗ | 38.4 | 25.5 |
| Gigapixel-DrivoR-Reg | ✗ | ✗ | 45.5 | 29.5 |
| DrivoR | ✓ | ✗ | 59.4 | 48.3 |
| DrivoR (w/ SimScale) | ✓ | ✓ | 64.6 | 54.7 |
| Gigapixel-DrivoR | ✗ | ✗ | 63.5 | 50.1 |
- 不用 human traj + 不用 SimScale 数据,Stage 2 接近 SimScale 顶配(63.5 vs 64.6)——而 Stage 2 恰是 perturbed 偏移姿态下的恢复能力测试,闭环鲁棒性的最直接代理。
- 总分输给 SimScale 4.6 分,作者诚实承认 SimScale 显式 mine 高 EPDMS 轨迹"对着 metric 训",而本工作的 Gigaflow teacher 没用任何 NAVSIM-v2-specific reward。
4.3 关键消融(HUGSIM Avg HD-Score)¶
| Gigapixel Training | Perceptual L2 | Frozen Plan Head? | Avg. HD |
|---|---|---|---|
| Self-play DAgger | ✗ | ✗ | 15.8 |
| Self-play DAgger | ✗ | ✓ | 18.5 |
| BC (\(\beta=1\) all the time) | ✓ | ✓ | 18.6 |
| DAgger (single-agent) | ✓ | ✓ | 30.1 |
| Self-play DAgger | ✓ | ✓ | 33.2 |
- Perceptual L2 + frozen planning head 是 sim-to-real 阶段的双必选项:去掉 L2 → 33.2→18.5;再去 freeze → 18.5→15.8。
- Self-play DAgger 比 single-agent DAgger 多 3.1 分、比 BC 多 14.6 分;training-strategy ranking 完全延续到 sim-to-real 后的真实评测。
4.4 Scaling¶
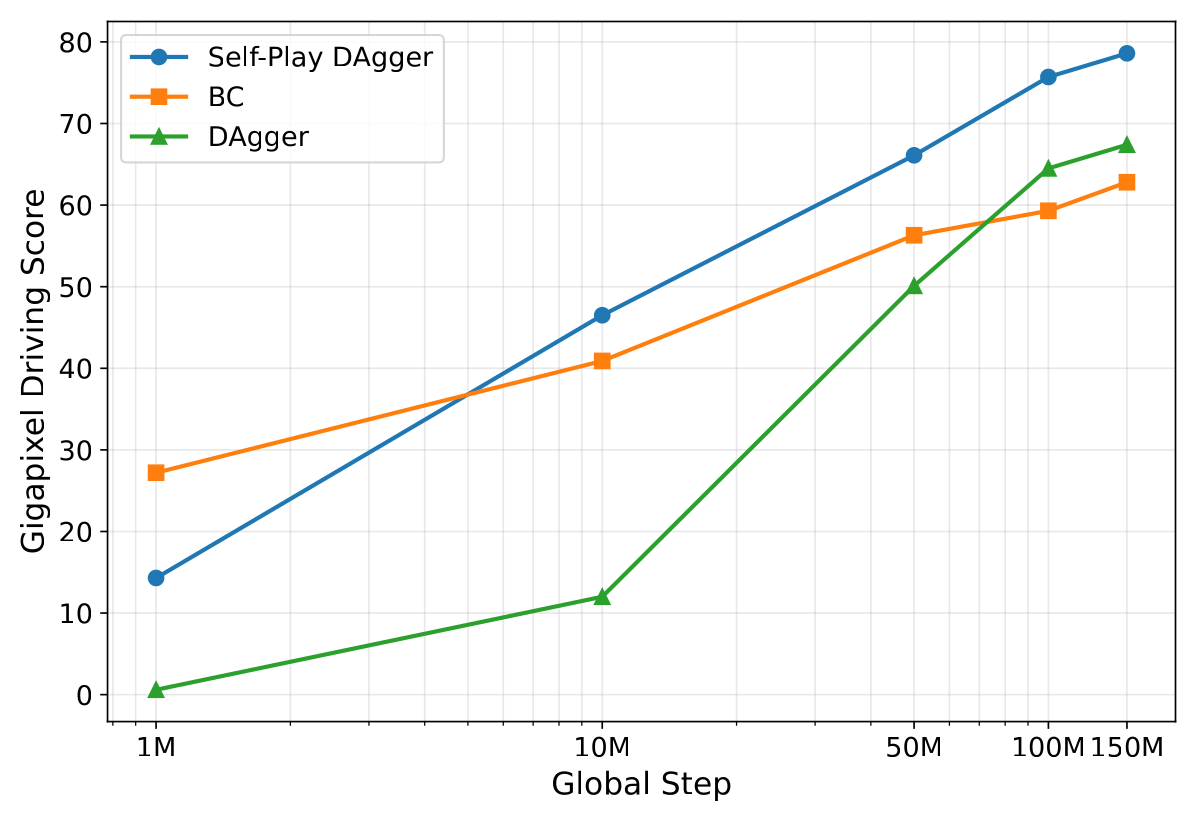 Figure 3:Gigapixel Driving Score vs 训练步数。Self-play DAgger 单调上升、不饱和;single-agent DAgger 全程在下面;BC 在 100M 步处 plateau——因为它永远碰不到 student 自己 rollout 出的状态。
Figure 3:Gigapixel Driving Score vs 训练步数。Self-play DAgger 单调上升、不饱和;single-agent DAgger 全程在下面;BC 在 100M 步处 plateau——因为它永远碰不到 student 自己 rollout 出的状态。
4.5 质性¶
 Figure 4:领头车逐渐停车的连续帧。绿(self-play)→ 提前减速并平滑绕开;红(BC)→ 维持直线高速 plan,最终追尾。Self-play 训练把"领头车减速 → 减速并绕开"这条 BC 数据里罕见的因果链显式暴露给 student。
Figure 4:领头车逐渐停车的连续帧。绿(self-play)→ 提前减速并平滑绕开;红(BC)→ 维持直线高速 plan,最终追尾。Self-play 训练把"领头车减速 → 减速并绕开"这条 BC 数据里罕见的因果链显式暴露给 student。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 把"为什么 pixel-RL 不行"用一张曲线钉死——3000× sample-efficiency gap 不是嘴上吹,是 dagger_vs_rl 图把 RL 与 DAgger 学习曲线画在同一坐标里直接 outscale 数量级。这个具体数字让"用 DAgger 蒸馏代替 RL"成为一条 hard motivation 而不是 vague justification。
- 每个 agent 都贡献训练样本 是 self-play DAgger 相对 single-agent 的真正杠杆——一帧 sim 出 N 条监督对,是 N× 的训练样本而不只是数据更难。这件事被 single-agent DAgger 比 self-play DAgger 差 3.1 HD 点的对照证实。
- Forked 并行 teacher rollout 提供轨迹监督——直接绕开"RL 学控制、E2E 要轨迹"这个 representation mismatch,思路干净到几乎像 trick。同时 4 秒 \(H\) 也对齐了下游 NAVSIM-v2 LQR 评测。
- Persona-conditioned teacher 同时被 student 复用——一份 vector \(\mathbf{c}_i\) 既是 reward weighting 又是 student 输入,把"训出多种驾驶风格 + 让 student 能 condition"压成同一件事,没有额外训练阶段。
- Sim-to-real 完全锁在 perception,planning head 冻结——把"closed-loop behavior 来自 sim 训练"这件事保护起来,最有信号的 ablation 就是这两个 design 各贡献十几个 HD-Score 点(33.2→18.5→15.8)。
- Throughput 数字诚实:表里同时画了 "render-only" 与 "实际训练 SPS",并明说大模型下渲染不再是瓶颈,没有把 50k SPS 包装成全栈训练速度。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 抽象渲染先天有 representational ceiling。Gigapixel 只画 cuboid + lane strip + 信号灯小球,weather / debris / 临时路障 / 异物全部不可表达。作者把这件事完全甩给 sim-to-real perception adapter,但 adapter 也只是 L2 对齐到 sim 特征上——sim 里没有的语义类别在 real backbone 里学不出对应反应,这个问题在 Limitations 一带而过。
- Teacher / student 信息不对称是真威胁。Teacher 看全局 vectorized state(被 occluded 的车也看得见),student 看像素(看不见)。被遮挡车产生的 teacher 轨迹会去监督 student "做不到"的反应。作者自己承认这条,但全文没量化"无法从 pixel 推断的监督样本比例",也没做 occlusion-aware 过滤。
- Extreme tier 输给 BC 的"high-velocity bias"叙事可疑。平均碰撞速度 1.95 vs 5.27 这个比较是在总碰撞集合上取均值——但 Gigapixel 跑得慢同时也减少了"被追尾 / 主动避免碰撞"两类不同事件的统计构成,单一均值不足以下"BC 是不安全而非更聪明"的结论。需要按碰撞 cause(at-fault vs 被撞)拆开。
- NAVSIM-v2 总分输给 SimScale 4.6 点。作者强调 Stage 2 接近,但 SimScale 也就是 134k 离线 recovery 数据,从 ML 工程视角是远比 Gigapixel 训练栈轻的方案;要"卖" self-play 必须给出 SimScale 的 wall-clock / GPU-hour 对照,而文中没有。
- Sim2Real 配对数据来源限定在 NAVSIM。"用 NAVSIM 配对集学 perception adapter"暗含 NAVSIM 已经能从原始 log 重建出 BEV state——这件事在 raw 量产数据上几乎做不到。作者直接说"不 trivially extend to raw sensor logs",但同时还在用 NAVSIM 的 evaluator 给自己打 SOTA,这有点像在 benchmark 友好分布里测自己。
- Self-play 训出的"谦让 / 慢"风格在 Extreme tier 反而被对抗 agent 强行碰撞。这暴露 self-play teacher 训练时没有 adversary curriculum——所有 persona 都是合作-竞争混合的"普通驾驶员"。HUGSIM Extreme tier 才是显式做对抗,跨域评测的归因不能光归到 BC bias。
- 335k nuPlan scenarios 与 HUGSIM/NAVSIM 评测数据有底层场景重合嫌疑。三家测评数据都源自 nuScenes / Waymo / nuPlan,论文没正面讨论训练-评测的城市/路口可能存在结构性重合。
- DrivoR 是 baseline 又是 student 架构。同一家族里"Gigapixel-DrivoR 比 DrivoR (BC) 高 2.8 HD"的对照虽然控制了 architecture,但特权 teacher 自己额外吃了 25B 步 sim 经验——总 sim 经验量是 BC 那侧的天量倍数。"BC 数据更廉价"这个对照轴一直在文中被略过。
- Persona vector \(\mathbf{c}_i\) 没有 sim-to-real 评测时如何赋值。作者说推理时给 student 同样的 \(\mathbf{c}\),但 HUGSIM / NAVSIM-v2 评测时不会有 ground-truth persona,appendix 是否固定了一个保守 persona?若是,则 Extreme tier 表现差有可能是被 persona 选成"谨慎"型限速了。
- 训练总成本(8×H200 × 60 小时 ≈ 480 H200-hours)+ teacher 25B 步,与 DrivoR BC 的 25 epoch 训练相比要贵很多——但被"不需要人类轨迹"这条卖点掩盖。完整 compute fairness 应该把"BC 同 GPU-hour 但更多 data"和"Gigapixel 同 GPU-hour 但更小 teacher"两端都列出来。
5.3 值得继续探讨的方向¶
- 把人类数据当 anchor 而不是 supervision —— 直接接姊妹论文 Spiced Self-Play(2606.19370)的 KL 正则范式,本文 Future Work 里也明确点了这条。
- Pixel-space RL 直接训 —— 现在 self-play DAgger 是绕过 RL 的工程妥协;如果 Gigapixel 后续把 throughput 再翻一档,能否让 pixel-RL 学会原生 trajectory output,干掉 teacher-student 信息不对称。
- Generative scenario init —— nuPlan log 限制了 self-play curriculum;用 Scenario Dreamer / SLEDGE 生成 rare / adversarial 初始构型可补充 Extreme tier 短板。
- Pose-conditional persona learning —— 让 student 在推理时根据当前路口语义自己选 persona,而不是固定 conservative 值。
- Sim-to-real perception adapter 形式 —— 当前 L2 对齐到 sim 特征是个紧约束;尝试 contrastive 或 distillation-free adapter(直接对齐 planning latent 而非 perception 中间特征)。
- 多 city / 多本体——目前 HUGSIM 与 NAVSIM 还都在普通城市道路。要主张"端到端 self-play 范式"还需要跨城市、不同摄像头 rig 的可迁移性。
- 与 World Engine (2606.19836) 的接口 —— 后者主张"3DGS reconstructed counterfactual + RL post-training",本工作的 Gigapixel teacher 完全可以作为它的 \(\pi_\text{ref}\);两条线合并是 plausible 的下一篇。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://montrealrobotics.ca/gigapixel
- 关键 baseline / 相关论文:
- DrivoR (Kirby 2026) —— student 架构与 BC baseline
- Gigaflow (Cusumano-Towner 2025) —— vectorized self-play teacher 配方
- PufferDrive (2025) —— 抽象 simulator 底座
- Madrona (Shacklett 2023) —— 批量 GPU 渲染引擎
- HUGSIM (Zhou 2025) / NAVSIM-v2 (Cao 2025) —— 评测 benchmark
- SimScale (Tian 2025) —— offline recovery augmentation 对照
- RAP (Feng 2025) —— 简化 box 渲染但 CPU-only 的同类方法
- Spiced Self-Play (Cornelisse 2606.19370) —— 姊妹论文,做"vectorized + 人类 anchor"那条线