ABC: Scalable Behavior Cloning with Open Data, Training, and Evaluation¶
论文阅读笔记 — 用于后续讨论的概览
注:本文不在 arXiv 上发布,仅有项目主页 PDF(https://abc.bot),因此本笔记基于 PDF 阅读,没有 LaTeX 源码可对照(公式/行号无法精确引用)。
1. 基础信息¶
- 题目: Scalable Behavior Cloning with Open Data, Training, and Evaluation
- 作者: Arthur Allshire, Himanshu Gaurav Singh, Ritvik Singh, Adam Rashid, Hongsuk Choi, David McAllister, Justin Yu, Yiyuan Chen, Huang Huang, Pieter Abbeel, Xi Chen, Rocky Duan, Phillip Isola, Jitendra Malik, Fred Shentu, Guanya Shi, Philipp Wu, Angjoo Kanazawa
- 单位: UC Berkeley, MIT, Amazon FAR, XDOF, Carnegie Mellon University(带 * 为 core contributor,工作在 Amazon FAR 实习期间完成)
- 公开方式: 无 arXiv 编号;项目主页 https://abc.bot,代码 https://github.com/amazon-far/abc,数据集 https://huggingface.co/datasets/XDOF/ABC-130k(2026 年)
- 关键词: behavior cloning, bimanual manipulation, open dataset, diffusion transformer (DiT), vision-language-action (VLA), sim-to-real, evaluation rubrics
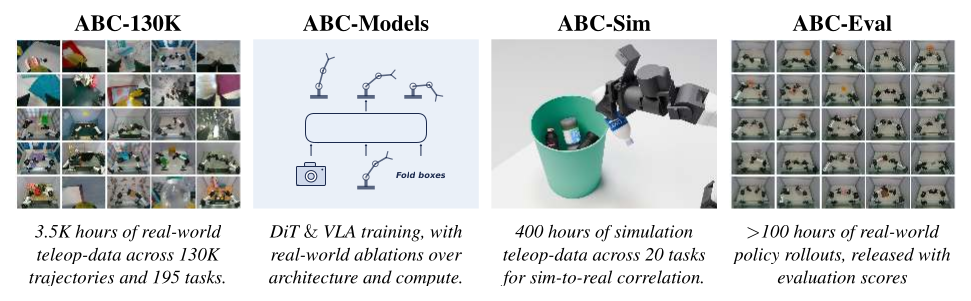 Figure 1(原文 Fig.2):ABC 是一个「数据 + 模型 + 仿真 + 评测」四件套的全栈开源项目 —— ABC-130K 提供 3.5K 小时真机遥操作数据,ABC-Models 给出 DiT/VLA 两类基线及架构-算力消融,ABC-Sim 提供与真机相关的仿真,ABC-Eval 提供 >100 小时真机评测 rollout + rubric。论文的卖点不是单一 SOTA,而是把整条 BC 研究链路全部开源。
Figure 1(原文 Fig.2):ABC 是一个「数据 + 模型 + 仿真 + 评测」四件套的全栈开源项目 —— ABC-130K 提供 3.5K 小时真机遥操作数据,ABC-Models 给出 DiT/VLA 两类基线及架构-算力消融,ABC-Sim 提供与真机相关的仿真,ABC-Eval 提供 >100 小时真机评测 rollout + rubric。论文的卖点不是单一 SOTA,而是把整条 BC 研究链路全部开源。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于机器人模仿学习 / behavior cloning (BC) 的大规模复现性问题。BC 的完整栈很「深」:要搭机器人硬件、采演示数据、设计能吃异构数据流的高效训练系统、找到收敛得动的训练配方,复杂任务还要 DAgger 迭代,最后还要做昂贵的真机评测才能验证设计决策。结果是 manipulation 前沿的进展非常「不透明」—— SOTA 系统大多在工业实验室的私有数据上开发,训练配方即便公开也很少给到能复现或定位「哪个设计真正驱动了性能」的细节。
2.2 Motivation¶
作者想把整条链路开源,让所有研究者站在同一起跑线上。具体瓶颈有三: 1. 现有开源数据规模/质量不够,或硬件太贵:DROID/BridgeData-V2 是单臂、以单步 pick-and-place 为主;Open X-Embodiment 质量参差、语言/动作空间噪声大;AgiBot-World 虽 3000h 双臂但机器人要 $30,000;最接近的 MolmoAct-2 在 YAM 平台也只有 750h。 2. 训练基础设施缺失:能在分布式下高效加载「几千小时编码视频」的 dataloader 很少有人开源。 3. 评测不可扩展:真机评测昂贵又费力,没有公开的 rubric + rollout 让大家对齐「成功」的定义。
核心 angle 是:在一个便宜($8,000 级)的双臂 YAM 工作站上把数据规模推到最大,并把数据、训练、仿真、评测整条栈一起放出来。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 单臂开源数据 | DROID (350h)、BridgeData-V2 (~100h)、RH20T (110k traj) | 单臂、以 pick-and-place 为主,缺双臂灵巧/长程任务 |
| 大杂烩聚合 | Open X-Embodiment | 跨本体聚合但质量参差、动作空间/语言标注噪声大 |
| 昂贵双臂平台 | AgiBot-World (3000h, \(30k)、ALOHA 生态 (~\)20k) | 数据量可观但硬件昂贵,复现门槛高 |
| 同平台但规模小 | MolmoAct-2 BimanualYAM (720h, 28 tasks) | 和本文同 YAM 平台但任务/时长少一个量级 |
| 大规模 BC 配方 | GR00T-N1、π₀/π₀.₅、LBM、OpenVLA | 训练代码/细节大多闭源,连接器、batch size、conditioning 等设计的相对贡献无法独立评估 |
2.4 论文解决方案(一句话)¶
在便宜的双臂 YAM 平台上采集 3,553 小时、195 任务、134,806 episode 的开源遥操作数据(ABC-130K),配套开源 dataloader、DiT/VLA 两类基线及其架构-算力消融、与真机强相关的仿真栈(ABC-Sim)、以及 >100 小时带 rubric 的真机评测(ABC-Eval),把整条 behavior cloning 研究链路一次性放给社区。
2.5 与前序工作的关系¶
- 数据规模上对标 AgiBot-World(~3000h),但用的是便宜十倍的硬件;同平台对标 MolmoAct-2,但时长大一个量级。
- 模型直接复用现成组件做基线:ABC-DiT 用 DINOv3 ViT-B + DiT(受 LBM/π₀ 启发),ABC-VLA 用 Gemma 3(SigLIP + Gemma)4B VLM + 小 DiT action head。
- 训练配方借鉴了一批近期工作并直接做对照:FAST 动作 tokenizer、Knowledge-Insulation 风格的 cross-attention「绝缘」、Real-Time Chunking (RTC) 的 action prefix conditioning。
- 整体定位很像机器人版的「开源基础设施论文」(精神上接近 Octo / LeRobot),但更强调数据规模 + 评测可复现。
3. 方法介绍¶
3.0 公共设定¶
所有模型输入 3 张 224×224 图像(顶部 + 两个夹爪腕部相机)+ 14 维本体感受(proprioception)关节状态;非方形图用 letterbox padding。输出 30 步的绝对关节位置目标 chunk,state/action 都做 z-score 归一化。策略在真机以 30 Hz 异步执行,并用 action prefix(RTC) 防止模式切换、保证轨迹平滑。所有训练在 NVIDIA H200 上完成。§3 的对照模型先在一个内部 7,000 小时 corpus 上训练(数据集发布前用于开发),最终模型再在公开的 ABC-130K 上训练。
3.1 ABC-DiT(diffusion transformer 策略)¶
DiT action head 用 32 层、24 heads、hidden 1536、MLP ratio 4,比 DiT-XL 还大 —— 作者特意把 head 做大,确保「架构选择的差异不被网络容量瓶颈掩盖」。研究的核心是 DiT head 如何跟视觉编码器通信,对照三种变体:
- CLIP-AdaLN(受 LBM 启发的 baseline):每张图用 CLIP ViT-B 独立编码取 CLS token 拼成紧凑视觉表征,语言用 CLIP text encoder + MLP,和 proprio、diffusion timestep embedding 拼成单一 conditioning 向量,通过标准 adaLN 调制 DiT。问题:把每张图压成单个 token,会丢失对操作很重要的细粒度空间信息。
- CLIP-Cross-Attention:让 DiT 用一组 12 个 learned latent query 去 cross-attend 所有视觉 token(直接 attend 全部 token 太贵)。每个 self-attention 层后加一个 cross-attention 层,query 来自带噪 action token,KV 是 pooled 视觉 token。
- DINO-Cross-Attention:把 CLIP 换成 DINOv3 ViT-B —— image-text alignment 未必是最贴合低层动作的目标,DINOv3 的像素对齐表征能保留更精确的空间线索。
结论:从 adaLN 换成 pooled cross-attention 提升 task progress(保留 token 级视觉信息有用);CLIP 换 DINOv3 进一步提升。最终 ABC-DiT = DINOv3 + pooled cross-attention,3 张图共享 DINO 权重,总计 2B 参数(85.7M backbone + 1.93B action head)。
3.2 ABC-VLA(VLM 主干 + DiT action head)¶
基于 Gemma 3(4B VLM,SigLIP 视觉编码器 + Gemma 语言解码器),接一个小 DiT action head 生成 action chunk。作者发现冻结 VLM 效果很差,所以用动作预测目标端到端 finetune 整个 backbone。研究核心是 VLM↔action head 的 connector,固定其它变量只变 connector,对照三种:
- Cross Attention:DiT cross-attend VLM 最后一层 token 特征,diffusion 梯度通过 cross-attention 回流进 VLM(端到端 finetune)。
- Cross Attention + FAST:在 VLM token 序列里拼上 FAST-tokenized 的动作做 next-token CE co-training,同时 DiT cross-attend 并 detach VLM 最后一层特征以「绝缘」backbone(类 π₀.₅ 的 KV 复用)。
- Adaptive LayerNorm (AdaLN):把 VLM 最后一层 token 用 attention pooling(QK-Norm) 汇成 8 个 512 维 token,flatten + 投影成 adaLN 的 shift/scale/gate,DiT action token 不直接 attend VLM token。
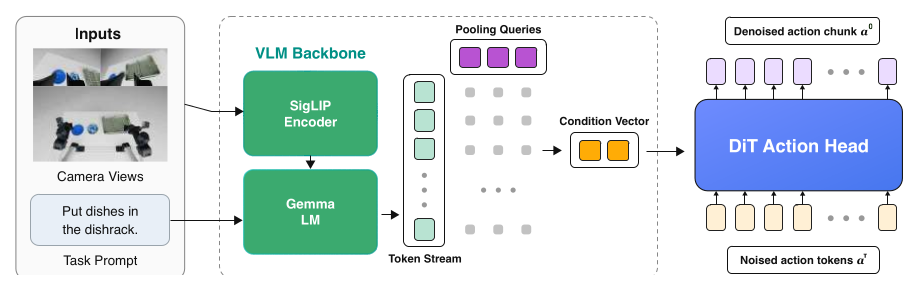 Figure 2(原文 Fig.20):最终选定的 ABC-VLA 走 pooled adaLN —— Gemma 3 VLM 把相机图 + 任务 prompt 编进 token stream,用 pooling queries attention-pool 成 8 个 token、再投成一个 condition vector,去 adaLN 调制一个轻量 DiT action head。注意 action head 只有 ~45M 参数,VLM 主干才是参数大头。
Figure 2(原文 Fig.20):最终选定的 ABC-VLA 走 pooled adaLN —— Gemma 3 VLM 把相机图 + 任务 prompt 编进 token stream,用 pooling queries attention-pool 成 8 个 token、再投成一个 condition vector,去 adaLN 调制一个轻量 DiT action head。注意 action head 只有 ~45M 参数,VLM 主干才是参数大头。
Variance Reduction(多 draw trick):AdaLN 和 Cross-Attention 的 diffusion loss 是对 (数据 \(x\)、噪声 \(\epsilon\)、timestep \(\tau\)) 三者的期望。由于 DiT head(42M)相对 VLM(4B)很小,可以摊销单次 VLM forward 跨多个 \((\epsilon,\tau)\) draw:forward 时把 VLM 特征和干净动作在 batch 内复制 \(k\) 份各配独立 \((\epsilon,\tau)\),backward 时梯度在 conditioning 接口处平均,于是 VLM 的反传成本与 \(k\) 无关。得到严格更低方差的梯度估计且开销可忽略:H200 上 \(k{=}1\) 时 1.346 s/step、\(k{=}8\) 时 1.366 s/step。
结论(Table 1):vanilla cross-attention 最差(aggregate progress 9.2%,和先前研究一致),FAST co-training 改善到 29.6%,AdaLN 反而最好(67.5%)——尽管它让 VLM 暴露在 denoising 梯度下。说明「diffusion 梯度并非天然与 VLM 特征不兼容,只要给对接口」。最终 ABC-VLA 用 8-draw 的 pooled AdaLN。
3.3 Scaling:batch size 与训练步数¶
batch size 业界没有共识(OpenVLA 2048、LBM 2560、GR00T-N1 16,384)。作者在 batch 1536 / 4608 / 9216 × {100K, 200K step} 下训 ABC-DiT 和 ABC-VLA:
- 更多步数 + 更大 batch 一致带来更好性能(Figure 3)。
- 小 batch 下 DiT > VLA,且 DiT 更 flop-efficient;但 batch 推到 9216 时 DiT 提升趋缓,VLA 跳升并反超 DiT。
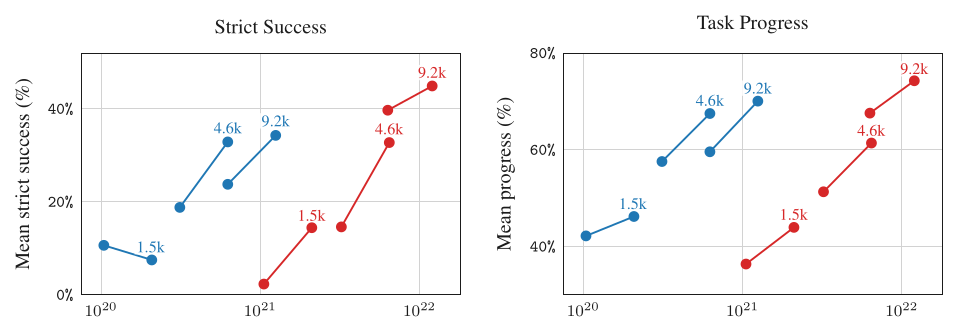 Figure 3(原文 Fig.5):横轴 training FLOPs、纵轴真机 strict success / progress,每条连线是同一 effective batch(≈1.5K/4.6K/9K)在不同 checkpoint。DiT(蓝)在相同算力下普遍更高(更 flop-efficient),但 VLA(红)在最大 batch 9.2K 时把 strict success 拉到 ~45%。
Figure 3(原文 Fig.5):横轴 training FLOPs、纵轴真机 strict success / progress,每条连线是同一 effective batch(≈1.5K/4.6K/9K)在不同 checkpoint。DiT(蓝)在相同算力下普遍更高(更 flop-efficient),但 VLA(红)在最大 batch 9.2K 时把 strict success 拉到 ~45%。
3.4 离线指标能不能预测真机表现¶
真机评测无法 scale 到每个小决策,所以作者想用离线指标筛掉大部分设计选择。对所有 checkpoint 比较真机 strict success / progress 与三种离线量的相关性:training loss、validation loss、validation action error(10 步 diffusion 解出的 action chunk 与 GT 的 L2 距离,无 action prefix)。
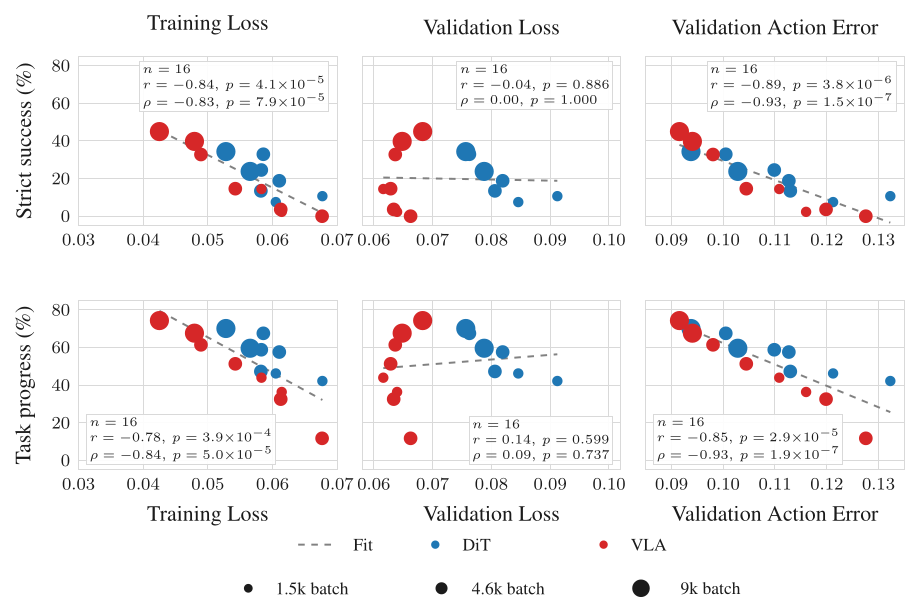 Figure 4(原文 Fig.8):n=16 个 checkpoint。training loss(左,r≈−0.84)和 validation action error(右,r≈−0.89/−0.93)都与真机表现强负相关、统计显著;而 validation loss(中)几乎不相关(strict success r=−0.04, p=0.886)。validation action error 相关性最强 —— 但前提是 diffusion 步数固定,否则降步数能 trivially 压低 error 却不提升真机表现。
Figure 4(原文 Fig.8):n=16 个 checkpoint。training loss(左,r≈−0.84)和 validation action error(右,r≈−0.89/−0.93)都与真机表现强负相关、统计显著;而 validation loss(中)几乎不相关(strict success r=−0.04, p=0.886)。validation action error 相关性最强 —— 但前提是 diffusion 步数固定,否则降步数能 trivially 压低 error 却不提升真机表现。
结论:training loss 和 validation action error 是便宜、可靠的代理,用来筛小设计决策;但它们不能预测绝对成功率、也不揭示失败模式。要更高保真度,就上仿真(§4)。
3.5 ABC-Sim(仿真栈)与 sim-to-real 相关性¶
在 MuJoCo 里重建真机 setup(图像在仿真内渲染,低保真),另提供 Blender path-tracing 重渲染管线生成高保真图像。释放 10 个任务的仿真环境(throwing bottles、turning mugs、loading dishrack、hanging mug、chess、spelling "abc"、markers in drawer、pouring beads、in-hand handover…),并配 400 小时 VR 遥操作仿真数据(GELLO leader arm 在 MuJoCo 内遥操,Meta Quest / Apple Vision Pro,240Hz 仿真、60Hz 给头显,开 pass-through 缓解晕动症)。
在 ABC-130K 上训 ABC-DiT/ABC-VLA 各取若干 checkpoint + 4 个 internal-7K + sim 混训的 DiT,共 12 个 checkpoint,在三任务上评测:sim 与真机的 Pearson 相关 strict success r=0.85(p=4.2e-4)、progress r=0.91(p=5.0e-5)。即仿真是真机表现的有意义预测器,可在昂贵真机评测前 debug 设计决策。
3.x Implementation Details(部署/复现关键)¶
- 硬件:双臂 I2RT YAM 6-DoF 低成本机械臂($8,000 级工作站),三面白墙围栏;3 个 Intel RealSense D405 相机 30Hz(1 第三人称 + 2 腕部);部分数据用 FlexPoint 夹爪。自研基于 ZMQ 的去中心化 PUB/SUB 机器人框架(类 ROS,节点用
time.sleep粗对齐 + 最后 300μs busy-spin 提精度)。 - 数据加载:自研
abcdl,MP4(拼接 3 路相机)+ binary(state/action)格式。关键 trick 是恒定 GOP=30 编码(每秒一个 keyframe、固定 ticks/frame)使帧索引可解析重建,把 torchcodec 默认「全文件扫描建索引」省掉 → 每次解码读取量降 ~70×(9.75MB → 0.14MB);+faststart移 moov、禁 B-frame、3 路相机叠进单个 MP4 减 3× 请求。支持本地或 S3/GCS 流式。 - ABC-DiT 训练:lr 1e-4(1000 步 warmup 后恒定),AdamW wd 0.01,视觉编码器 lr scale 0.1,grad clip 10,proprio dropout 0.1;12 H200 节点 × 96/GPU = global batch 9216;200K step。
- ABC-VLA 训练:bf16 混合精度;8 H200 节点 × 24/GPU × grad accum 6 = global batch 9216;同样的 lr/wd/dropout。
- 参数/算力(Table 2):ABC-DiT = 85.7M backbone + 1.93B action head(TFLOPs/sample 0.678);ABC-VLA = 4.3B backbone + 44.7M action head(TFLOPs/sample 7.020,因为 VLM 大)。ABC-VLA 用 8 个独立 draw,ABC-DiT 用单 draw(大 head 多 draw 太贵)。
- 推理优化(Appendix D,RTX 5090 实测,10 diffusion step):bf16 + 缓存视觉/VLM 特征 +
torch.compile(fullgraph=True)+ CUDA graph。 - ABC-DiT:63 ms → 36.3 ms(15.9 → 27.6 Hz)。
- ABC-VLA:47.8 ms → 17.5 ms(20.9 → 57.2 Hz)。
- 反直觉:ABC-VLA 比 ABC-DiT 更快,尽管参数多一倍多 —— 因为 VLM 只跑一次(缓存特征),重复部分只是 45M 的 diffusion head 跑 10 步;而 ABC-DiT 的 1.93B head 每个 diffusion step 都要全跑。
4. 结果对比¶
4.1 架构消融(Table 1,internal 7,000h corpus,200k step,3 任务各 50 trial)¶
Strict = 完成任务百分比;Progress = 平均任务进度。Latency = ms/chunk(10 diffusion step)。
| VLA: Pooled adaLN | VLA: FAST+X-Attn | VLA: X-Attn | DiT: DINOv3-xattn | DiT: CLIP-adaln | DiT: CLIP-xattn | ||
|---|---|---|---|---|---|---|---|
| Bottles | Strict | 67.3 | 8.0 | 0.0 | 73.5 | 11.8 | 38.9 |
| Progress | 83.0 | 44.0 | 5.2 | 93.1 | 53.6 | 74.1 | |
| Dishrack | Strict | 30.0 | 2.8 | 0.0 | 23.2 | 28.6 | 34.7 |
| Progress | 75.7 | 47.2 | 25.0 | 74.1 | 72.3 | 81.3 | |
| Mugs | Strict | 1.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 |
| Progress | 25.5 | 6.5 | 5.0 | 35.3 | 15.9 | 21.0 | |
| Aggregate | Mean strict | 32.8 | 3.6 | 0.0 | 32.9 | 13.4 | 24.5 |
| Mean progress | 61.4 | 32.6 | 11.7 | 67.5 | 47.3 | 58.8 | |
| Latency (ms) | 17.24 | 19.24 | 19.24 | 37.4 | 27.5 | 37.5 |
要点:VLA 侧 pooled adaLN >> FAST+X-Attn >> 纯 X-Attn;DiT 侧 DINOv3-xattn 最高(mean progress 67.5)。Mugs(把杯子翻正)三方都很难,strict success 普遍 ≤2%。
4.2 真机最终能力(Figure 11,ABC-130K 训练)¶
ABC-DiT 与 ABC-VLA 在三任务上的真机 task progress(各 50 trial):Bottles ≈ 93% / 93%,Dishrack ≈ 80% / 70%,Mug flip ≈ 40% / 32%。两者整体接近,DiT 略高。论文同时展示策略能做长程灵巧任务:连插 6 个 AirPods、钥匙开 lockbox、折纸箱、装书包等。
4.3 Sim-to-real 相关性(Figure 9)¶
12 个 checkpoint,strict success r=0.85(p=4.2e-4),task progress r=0.91(p=5.0e-5)。
4.4 预训练对下游 finetune 的影响(Figure 13)¶
四个高精度灵巧任务(钱包取卡、LEGO 分拣、笔帽插入、拧瓶盖),同任务三种初始化对照:从头训 / 从 ABC-130K (3.5K h) 预训 finetune / 从 internal 7K h 预训 finetune。
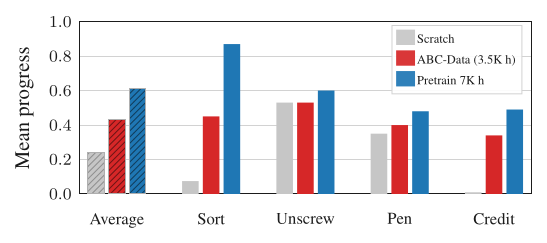 Figure 5(原文 Fig.13):平均 mean progress 大致 Scratch ≈0.25 < ABC-Data 3.5K ≈0.43 < Pretrain 7K ≈0.60。预训练数据越多越杂,单任务 finetune 越强 —— 而且 Sort LEGOs 这种需要强视觉表征的任务,7K 预训(≈0.87)远超从头训(≈0.06)。
Figure 5(原文 Fig.13):平均 mean progress 大致 Scratch ≈0.25 < ABC-Data 3.5K ≈0.43 < Pretrain 7K ≈0.60。预训练数据越多越杂,单任务 finetune 越强 —— 而且 Sort LEGOs 这种需要强视觉表征的任务,7K 预训(≈0.87)远超从头训(≈0.06)。
4.5 DAgger(box folding,Figure 14)¶
折纸箱是 pretrained ABC-DiT 零真机成功的难任务。先用额外 10h「collapsed data」(更严格 SOP 采集)finetune 仍只到 24%。再做 DAgger:rollout 时人介入遥操,记录整条 rollout,按 80:10:10(前一轮数据 : 本轮介入 : 本轮 episode 其余)混训 75k step。结论:finetune 24% → DAgger 后 ≈85%。作者强调只采「recovery / 中间修正」行为比为整条 rollout 采数据划算得多。
4.6 关键消融:policy conditioning(Appendix H,全部在 t-shirt folding 上)¶
| 机制 | 设置 | 关键数字 |
|---|---|---|
| Operator-ID | all-operator + op0 prompt | mean score 4.6,8/10 completion,237s(vs op-0 filtered 3.3、2/10;vs marginalize 4.4) |
| Action prefix (RTC) | prefix=1 vs prefix=4 | prefix=1 更好(4.6, 8/10)vs prefix=4(3.9, 5/10);prefix 太长会压制视觉响应性 |
| Subtask conditioning | SARM 启发的 subtask 分类器 | 无 subtask prompt:10 次里 5 次「重折已折好的衣服」;有 subtask:0 次(但 1 次漏抓) |
三者共同主题:在推理时把策略的有效 conditioning 偏向「与当前决策最相关的信号」。其中 marginalized(训练时加 operator-ID、推理不指定)也优于无 conditioning baseline,说明训练时引入 operator 通道「严格有益」。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- DINOv3 + pooled cross-attention 的 DiT 设计有清晰的因果链:作者把 head 特意做大(比 DiT-XL 还大)来排除「容量瓶颈」这个混淆变量,再逐步换 conditioning(adaLN→cross-attn)和 encoder(CLIP→DINOv3),每一步的增益都能归到具体机制(保留 token 级空间信息 / 像素对齐表征)。这是难得干净的架构消融。
- VLA 的「多 draw 方差缩减」是一个真正利用了架构非对称性的 trick:VLM(4B) 大、DiT head(42M) 小,所以摊销一次 VLM forward 跨 8 个 \((\epsilon,\tau)\) draw,梯度方差降而成本几乎不变(1.346→1.366 s/step)。它直接解释了为什么 ABC-VLA 用 8-draw 而 ABC-DiT 只用单 draw —— 大 head 多 draw 太贵。
- 离线指标的诚实拆解很有价值:明确指出 validation loss 几乎不预测真机表现(r=−0.04),而 training loss / validation action error 才相关 —— 并附上「validation action error 只在 diffusion 步数固定时才有意义」这个易踩的坑。这种「哪些代理能用、边界在哪」的结论对社区比一个 SOTA 数字更有用。
- 数据加载的工程细节直接开源且可迁移:恒定 GOP=30 让帧索引可解析重建、把每次解码读取量降 ~70×(9.75MB→0.14MB),3 路相机叠进单 MP4。这是「几千小时视频能不能训得动」的真实瓶颈,很多论文回避了。
- sim-to-real 相关性给了可量化的代理(r=0.85/0.91),让没有真机的研究者也能 debug 设计决策 —— 配合 ABC-Sim 释放的 10 个任务,这是「降低评测门槛」的实质动作。
- 推理优化讲清了「VLA 比 DiT 还快」的反直觉:缓存 VLM 特征后,重复跑的只有 45M diffusion head,而 DiT 每个 denoising step 都要跑 1.93B head。这把「参数多 = 慢」的直觉精确证伪,对部署选型有直接指导。
5.2 做得不够好 / 值得质疑的地方¶
- 架构消融用的是 internal 7,000h corpus,不是公开的 ABC-130K:Table 1 / scaling / 离线相关性这些核心结论,全部在「发布前的内部数据」上得到,最终模型才换到 ABC-130K。开源论文的卖点是「站在同一起跑线」,但最关键的消融恰恰用了别人拿不到的数据 —— 社区无法独立复现这些 design 结论。
- 真机评测的任务面很窄:架构对照、scaling、离线相关性几乎全围绕 Bottles / Dishrack / Mugs 三个任务(每个 50 trial)。195 个任务的数据规模 vs 3 个任务的评测,结论的外推性有限,尤其 Mugs strict success 普遍 ≤2%,几乎是地板,难以区分方法优劣。
- 「DiT vs VLA 谁更好」其实没定论,被 batch size 搅在一起:小 batch DiT 赢、大 batch VLA 反超(§3.3),但论文没把「为什么 VLA 在 9.2K batch 跳升」讲透,也没给更大 batch 的外推。读者拿不到「该用哪个」的干净答案。
- Operator-ID / subtask conditioning 的样本量很小、评分主观:t-shirt folding 每条件 n=10、5 分 rubric、fold 质量靠 low/mid/high 人工判定(Table 4)。4.6 vs 3.8、8/10 vs 6/10 这种差异在 n=10 下统计意义薄弱,且没有多重比较校正。
- DAgger 的 24%→85% 混入了多个变量:先用 10h「collapsed data」(更严格 SOP)finetune,再叠 DAgger 介入数据,80:10:10 混训。最终增益里有多少来自「更干净的 SOP 数据」、多少来自「recovery 行为」、多少来自「更多训练步」,没有拆开。
- sim-to-real 的 n=12 且任务仍是那三个:r=0.85/0.91 看着漂亮,但 12 个点、3 个任务,且其中 4 个 checkpoint 是「internal-7K + sim 混训」的 DiT —— 相关性可能部分来自共享的训练分布而非仿真本身的预测力。
- 「validation action error 相关性最强」有循环风险:它本质是「10 步 diffusion 解出的 action 与 GT 的 L2」,而真机也是 10 步 diffusion 部署。这个指标与真机用的是同一套推理配置,相关性强一部分可能是「测的是同一件事」,而非独立预测。
- 成本口径不完全透明:$8,000 工作站、3,553 小时数据 —— 但 195 任务、134,806 episode 的采集到底花了多少 operator-hours、多少人月,没有给。「便宜硬件」≠「便宜数据」,遥操作的人力成本才是大头。
- 缺力/触觉:30 步绝对关节位置 chunk + 视觉,没有力控/触觉通道。对拧瓶盖、插卡这类 contact-rich 任务,纯位置控制是隐含限制(Mug flip 仅 ~40%、单任务 finetune 也只到中等水平,可能与此有关)。
- 不在 arXiv、无公共 benchmark 数字:所有结果都是 in-house 任务 + 自定 rubric,没有 LIBERO / SimplerEnv / RoboTwin 这类公共对照,横向对比其他 VLA(π₀ / OpenVLA / GR00T)只能停留在定性。
5.3 值得继续探讨的方向¶
- History conditioning:论文自己在 §8「Requests for Research」列出 —— 当前策略只 condition 当前帧,长程任务(折箱/折衣)需要记忆。可对接 MEM 那种多尺度记忆,或 video encoder。
- BC 的 scaling law:有了 195 任务 / 3,553h 的数据,正好做「性能 vs 模型/数据规模」的系统曲线 —— 这是 BC 领域一直缺的,论文只给了 batch/step 的局部 scaling。
- RL finetune:用 ABC base model 做 RL(对接 RECAP / RLT / QGF 这类 test-time 或 offline RL),把 box folding 24%→85% 这种「DAgger 才能补」的 gap 用 RL 自动补上。
- 把架构消融在公开 ABC-130K 上重做:社区最该做的复现实验 —— 验证「DINOv3 + cross-attn」「pooled adaLN」「多 draw」这些结论在公开数据上是否成立。
- 更宽的真机评测套件:把评测从 3 个任务扩到覆盖 7 个 primitive category 的代表任务,让 DiT vs VLA、conditioning 等结论有外推性。
- action prefix 的系统刻画:RTC prefix 长度在「平滑 vs 视觉响应」间 trade-off(prefix=1 反而更好),论文留作 future work —— 值得做一条 prefix length × success 的曲线。
- 力/触觉融合:在 contact-rich 任务上引入力控通道(对接 FACTR 这类 force-aware 工作),看 Mug flip / 拧瓶盖能否突破中等成功率。
参考资源¶
- 论文 PDF: paper.pdf(项目主页 https://abc.bot 下载,本笔记基于 PDF;无 LaTeX 源码)
- 代码: https://github.com/amazon-far/abc
- 数据集: https://huggingface.co/datasets/XDOF/ABC-130k(ABC-130K,3,553h / 134,806 episodes / 195 tasks)
- 关键 baseline / 相关论文: DROID、BridgeData-V2、Open X-Embodiment、AgiBot-World、MolmoAct-2、GR00T-N1、π₀ / π₀.₅、LBM、OpenVLA、DINOv3、Gemma 3、FAST、RTC (Real-Time Chunking)、SARM