Spiced Self-Play:60 年合成驾驶 + 30 分钟人类数据 = 类人驾驶策略¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Human-like autonomy emerges from self-play and a pinch of human data
- 作者: Daphne Cornelisse\(^{1}\), Julian Hunt\(^{2}\), Zixu Zhang\(^{3}\), Waël Doulazmi\(^{4,5}\), Kevin Joseph\(^{2}\), Jaime Fernández Fisac\(^{3}\), Eugene Vinitsky\(^{1}\)
- \(^1\)NYU Tandon, \(^2\)NYU Courant, \(^3\)Princeton, \(^4\)Mines Paris CAOR, \(^5\)Valeo
- arXiv 编号: 2606.19370(2026-06 提交,目标 CoRL 2026)
- 关键词: self-play RL, KL regularization, behavior cloning anchor, autonomous driving, mixed-motive game, human compatibility, data scaling laws
- 项目主页: https://spiced-self-play.com/
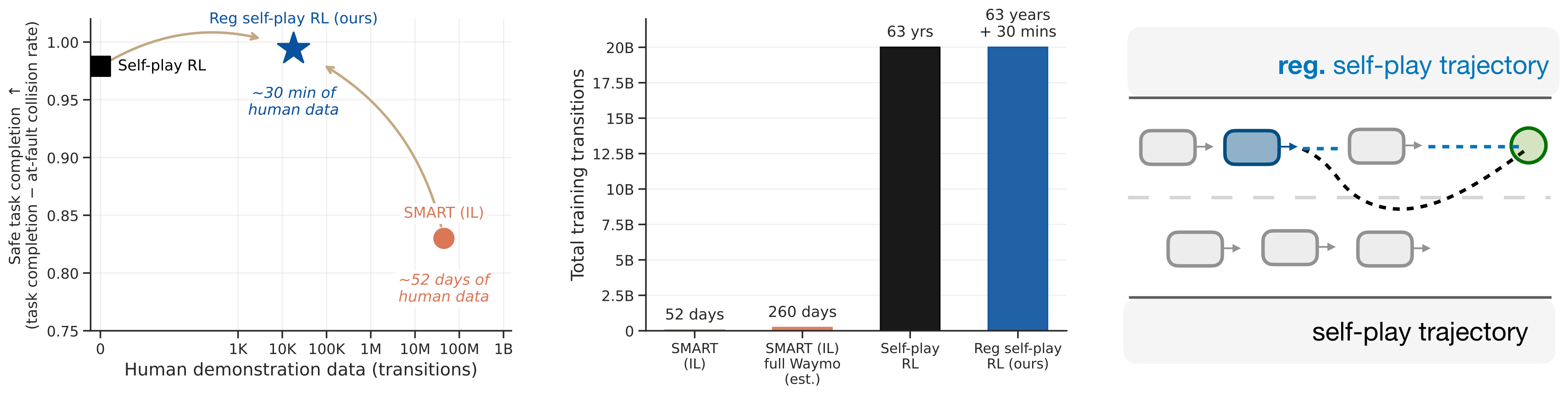 Figure 1:核心实验图。同样 20B self-play transitions(~63 年模拟驾驶),仅 30 分钟人类驾驶数据作为 BC anchor 的 KL 正则,就让 safe-task-completion(task complete − at-fault collision)从 unregularized self-play 的 0.979、SMART-tiny-CLSFT 的 0.830 拉到 0.994;SMART 训练用到 45M-225M 人类 transition(52 天-7 个月数据)。整训练流程 15 小时 / 单张消费级 GPU。
Figure 1:核心实验图。同样 20B self-play transitions(~63 年模拟驾驶),仅 30 分钟人类驾驶数据作为 BC anchor 的 KL 正则,就让 safe-task-completion(task complete − at-fault collision)从 unregularized self-play 的 0.979、SMART-tiny-CLSFT 的 0.830 拉到 0.994;SMART 训练用到 45M-225M 人类 transition(52 天-7 个月数据)。整训练流程 15 小时 / 单张消费级 GPU。
2. 文章介绍¶
2.1 解决的领域和问题¶
自动驾驶里 self-play RL 是新近兴起的"不靠人类数据,靠廉价 simulation 自己跟自己博弈"的路线(Gigaflow / GPUDrive / PufferDrive / SPACER 这条线)。它对策略产生自动进化课程,但有一个根本麻烦:驾驶不是 zero-sum 游戏,而是 mixed-motive coordination 任务。每个司机有自己的目的地,但要"遵守路面 conventions"和别人协调。Self-play 容易收敛到有效但"alien"的均衡——例如倒车、横向、走错车道也能"安全到达"。本文要解决的问题是:能否给 self-play 一个最便宜的"人类性 anchor",让它产出与人类司机兼容的策略?
2.2 Motivation¶
直接的两条路线都有结构性硬伤: - 手工 reward engineering:Gigaflow 用 9 项 reward + 大量 domain randomization 才把 naturalistic driving 调出来,工作量爆炸且 brittle。 - Imitation learning (IL) 比如 SMART:直接拟合人类 log,得在 500k WOMD 场景上跑、配 closed-loop fine-tuning 才不崩;要靠 covariate shift 不出大问题就得大数据。
作者关键 framing:模拟环境步骤几乎免费(300k-20M SPS / 单 GPU),人类数据极贵——所以与其把人类数据当主要监督信号,不如把它当一个轻量级 anchor,把策略从 alien 均衡里拉回人类 convention 的盆地。这条直觉先前在 Diplomacy(KL-anchored search)和 driving 上零星试过(HR-PPO、SPACER),但"多少数据足够"从未被系统研究。本文回答这个问题。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Pure self-play RL | Gigaflow, GPUDrive base | 收敛到 alien 均衡;需要 9 项 reward + DR 调出 naturalistic 行为 |
| Pure IL(autoregressive) | SMART, MotionLM, Trajeglish | 需要海量人类数据;closed-loop covariate shift 严重 |
| Hybrid IL + RL | TrafficRLHF, CAT-K | 仍以人类数据为主,RL 只做轻微 closed-loop 修正 |
| KL-anchored self-play(小规模) | HR-PPO (Cornelisse 2024) | 2k SPS 的 Nocturne 限制了规模;140M 步 / 200 场景 / 5 天,无 data scaling 研究 |
| KL-anchored self-play(大规模) | SPACER (Chang 2025) | anchor = SMART (用全 Waymo 训),VRU 直接 log-replay 污染评测;规模只到 1B 步;没研究 data scaling |
2.4 论文解决方案(一句话)¶
用 sparse reward (+1 reach goal / −1 collision/offroad / 0 elsewhere) 的 PPO self-play,KL 正则到一个仅在 30 分钟到 3 小时 WOMD SDC 轨迹上训出的 BC anchor,跑 20B steps / 15h / 单张消费级 GPU,就拿到比"全 Waymo 数据的 SMART"低 2.5-11× 的 at-fault collision rate 与更类人的轨迹分布、更轻的碰撞 severity。
2.5 与前序工作的关系¶
- 直接前作:HR-PPO (Cornelisse 2024) 同作者,用 Nocturne (~2k SPS) 在 200 场景上试过同思路,被速度卡住;本文把 simulator 换成 PufferDrive 2.0 (~390k SPS on RTX 5090),experience 直接放大 ~3 个数量级。
- 同期对照:SPACER (Chang 2025) 也做 KL-regularized self-play,但 anchor 是全 Waymo 训的 SMART、VRU 在训练时被 log-replay 污染、规模只到 1B 步。本文显式去掉这些干扰:(1) anchor 在 nested data 子集上扫;(2) 训练时所有 agent 都由 policy 控制;(3) 扩到 20B 步。
- 核心 baseline:SMART-tiny-CLSFT(在同 nested 数据子集上重训)+ SMART-tiny-CATK 全 Waymo checkpoint 作 IL 上界。
- 复用底座:PufferDrive 2.0、WOMD 数据集、PPO、WOSAC 评测、Waymo 安全报告的 \(\Delta v\) 碰撞 severity 度量。
3. 方法介绍¶
3.1 问题设定与评测三视角¶
 Figure 2:三种评测分别诊断不同失败模式。Self-play 测内部 convention 一致性;human-replay 用 log 中人类轨迹当对手,测策略是否吸收了人类 convention;IDM 用规则反应式对手测 closed-loop 鲁棒性。Human-replay 里很多碰撞是 replay 车从后撞过来的"不可避免事件",所以把 collision 和 at-fault collision 严格区分(沿 NAVSIM 习惯)。
Figure 2:三种评测分别诊断不同失败模式。Self-play 测内部 convention 一致性;human-replay 用 log 中人类轨迹当对手,测策略是否吸收了人类 convention;IDM 用规则反应式对手测 closed-loop 鲁棒性。Human-replay 里很多碰撞是 replay 车从后撞过来的"不可避免事件",所以把 collision 和 at-fault collision 严格区分(沿 NAVSIM 习惯)。
- Self-play:所有 agent 用同一份 decentralized policy。
- Human-replay:只有 SDC 是 policy,其他车走 log 轨迹(非反应式)。
- IDM:其他车走 Intelligent Driver Model 配 lane-center 路径(反应式但规则化)。
3.2 模拟环境¶
- PufferDrive 2.0,1 张 RTX 5090 上 390k SPS。
- 场景来自 WOMD,每段 9 秒 / 90 步,agent 上限 \(N=32\)(车 / 行人 / 骑行)。
- Decentralized observation:14 维 ego + 31 邻居 × 7 维 + 128 路段 × 7 维 = 1124 维。
3.3 Reward 设计:sparse to isolate the anchor's effect¶
刻意只保留 +1 / −1 / 0 sparse reward——任何"看起来像人"的部分完全归功于 BC anchor 的 KL 正则,杜绝"行为来自 reward shaping"的歧义。这是与 Gigaflow(9 项 reward)的核心方法论分歧。
3.4 Spiced Self-Play 两步训练¶
Step 1: 训 anchor。从 WOMD 抽 nested 子集 \(\mathcal{D}_n\)(10 min / 30 min / 3h / 30h 人类驾驶数据),仅用每个场景的 SDC 轨迹(自驾系统采集时往往质量最高),做 NLL BC:
训完冻结。
Step 2: 正则化 self-play。650k 参数 policy \(\pi_\theta\) 从零 PPO 训,损失:
KL 期望在 policy on-policy 状态分布上取,不是离线 \(\mathcal{D}_n\);这让 anchor 在 self-play 自然访问到的状态上才施加引力。\(\lambda = 0.075\) 在论文里是默认值(appendix 里能看到 sweep)。
3.x Implementation Details¶
| 项 | 数值 |
|---|---|
| Policy 参数 | 650k |
| 训练总步数 | 20B transitions(~63 年模拟) |
| 训练时间 | 15h / 单张消费级 GPU |
| Simulator | PufferDrive 2.0 @ 390k SPS (RTX 5090) |
| Anchor 数据规模 | 10 min / 30 min / 3h / 30h SDC trajectories |
| Anchor 网络 | BC,与 policy 同 obs 空间 |
| RL 算法 | PPO |
| KL 系数 \(\lambda\) | 0.075(默认;可调) |
| Reward | +1 goal / −1 collision/offroad / 0 否则 |
| 评测 | 10k held-out WOMD validation 场景 |
4. 结果对比¶
4.1 Human Data Scaling¶
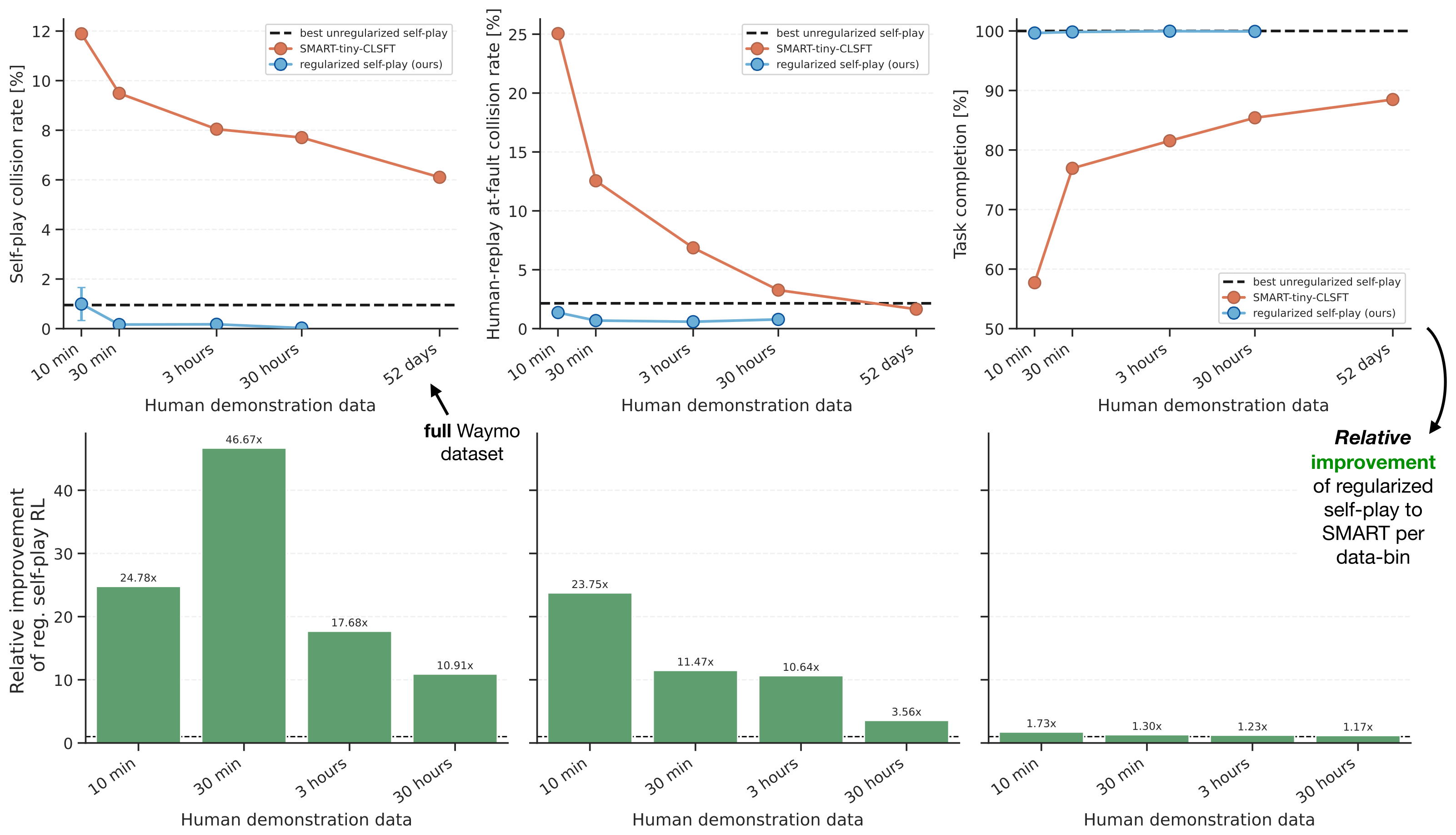 Figure 3:横轴是 BC anchor 训练用到的总人类驾驶时长(log 半轴),上图是绝对 score / collision rate / off-road,下图是相对 IL baseline 的 improvement。Spiced self-play 用 30 min 数据已超过 SMART 用 52 天数据;Spiced 30 hour ≈ 30 min(饱和)。
Figure 3:横轴是 BC anchor 训练用到的总人类驾驶时长(log 半轴),上图是绝对 score / collision rate / off-road,下图是相对 IL baseline 的 improvement。Spiced self-play 用 30 min 数据已超过 SMART 用 52 天数据;Spiced 30 hour ≈ 30 min(饱和)。
10k held-out scenario 上的关键数字(Table 1):
| Human demos | Method | Self-play Collision (%)↓ | Human-replay At-fault (%)↓ | Score↑ |
|---|---|---|---|---|
| 10 min | SMART | 11.9 | 25.0 | 0.246 |
| 30 min | SMART | 9.5 | 12.5 | 0.379 |
| 3 hours | SMART | 8.0 | 6.9 | 0.518 |
| 30 hours | SMART | 7.7 | 3.3 | 0.601 |
| 52 days (全 Waymo) | SMART-CATK | 6.1 | 1.6 | 0.654 |
| —— | unreg. self-play | 1.0 | 2.1 | 0.967 |
| 10 min | reg. self-play (ours) | 1.0 | 1.4 | 0.941 |
| 30 min | reg. self-play (ours) | 0.2 | 0.7 | 0.968 |
| 3 hours | reg. self-play (ours) | 0.2 | 0.6 | 0.973 |
| 30 hours | reg. self-play (ours) | 0.0 | 0.8 | 0.976 |
- 30 min 数据就把 unregularized 的 at-fault 从 2.1% 降到 0.7%(3× 改进);
- 相比 IL 上界 SMART (52 天 / 全 Waymo):spiced 30min 的 at-fault 是 SMART 52d 的 44%(0.7% vs 1.6%),self-play collision 低 46×(0.2% vs 6.1%);
- Anchor 数据从 30 min 加到 30 h,score 仅从 0.968 → 0.976,收益严重递减——anchor data 在这个区间不是瓶颈。
4.2 行为与安全分析¶
4.2.1 碰撞 severity(\(\Delta v\))¶
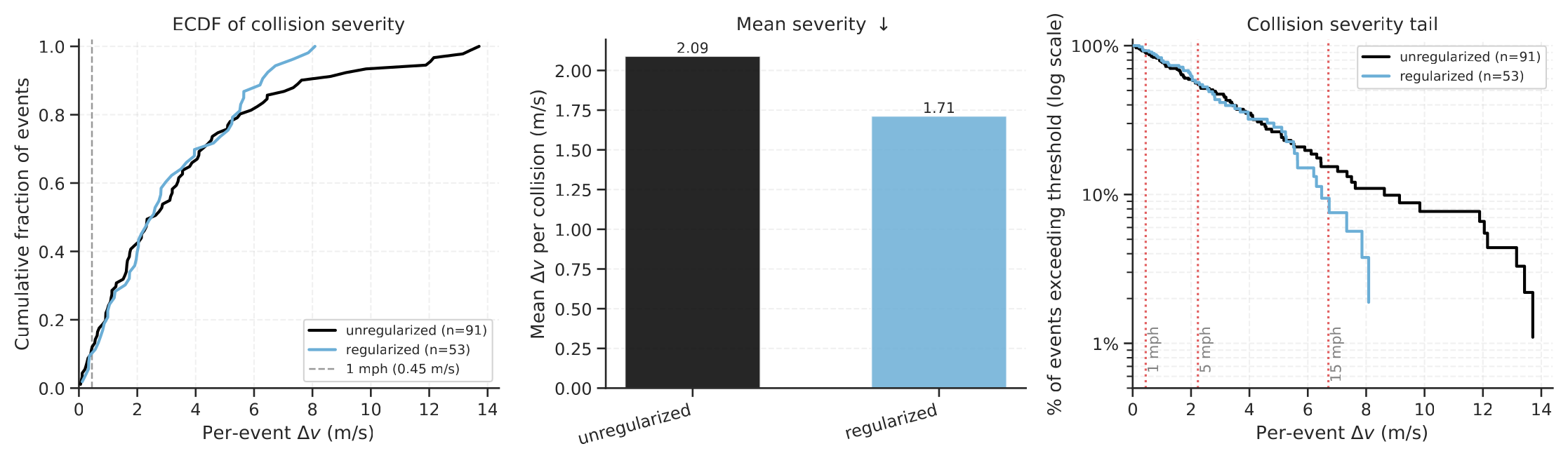 Figure 4:左 — 单次碰撞 \(\Delta v\) 的经验 CDF;中 — 条件 mean \(\Delta v\),regularized 比 unregularized 低 18%(1.71 vs 2.09 m/s);右 — 超过 \(\Delta v\) 阈值的碰撞分数 (log scale)。在 5 m/s 以上的"严重碰撞"区域两条曲线分叉显著拉开——正则化不仅碰得少,也撞得轻。
Figure 4:左 — 单次碰撞 \(\Delta v\) 的经验 CDF;中 — 条件 mean \(\Delta v\),regularized 比 unregularized 低 18%(1.71 vs 2.09 m/s);右 — 超过 \(\Delta v\) 阈值的碰撞分数 (log scale)。在 5 m/s 以上的"严重碰撞"区域两条曲线分叉显著拉开——正则化不仅碰得少,也撞得轻。
具体数字: - Mean \(\Delta v\):2.09 m/s → 1.71 m/s。 - Max \(\Delta v\):13.71 m/s → 8.09 m/s(−41%)。 - 超过 15 mph (= 6.7 m/s) 的严重碰撞占比:14.3% → 7.5%。
4.2.2 分布真实性(WOSAC meta-score)¶
- Unregularized self-play: 0.680
- Spiced (30 min anchor): 0.725
- SMART-tiny-CLSFT: 0.755(最高)
SMART 在 distributional realism 上仍是冠军,但在 collision rate / task completion 上全面输——证明"轨迹分布像人"不等于"行为安全有能力"。
4.2.3 longitudinal / lateral L2 拆解¶
| Method | At-fault (%) | Long. L2 (m) | Lat. L2 (m) | Time-aligned ADE (m) |
|---|---|---|---|---|
| Unregularized | 2.1 | 13.33 | 2.39 | 14.07 |
| Regularized (ours) | 0.7 | 5.56 | 1.27 | 5.93 |
- Unregularized 的 longitudinal L2 是 lateral 的 5.6×——说明它"走对路线但开太快";正则化同时改善路线(lateral ×0.5)与节奏(longitudinal ×0.4)。
- 平均 episode 长度 unregularized 38 步 vs regularized 64 步——RL 的"discounted return"鼓励最短路径,正则化把策略推向"satisficing"而非"optimizing",这与人的驾驶动机一致。
4.3 Scenario Metadata Scaling¶
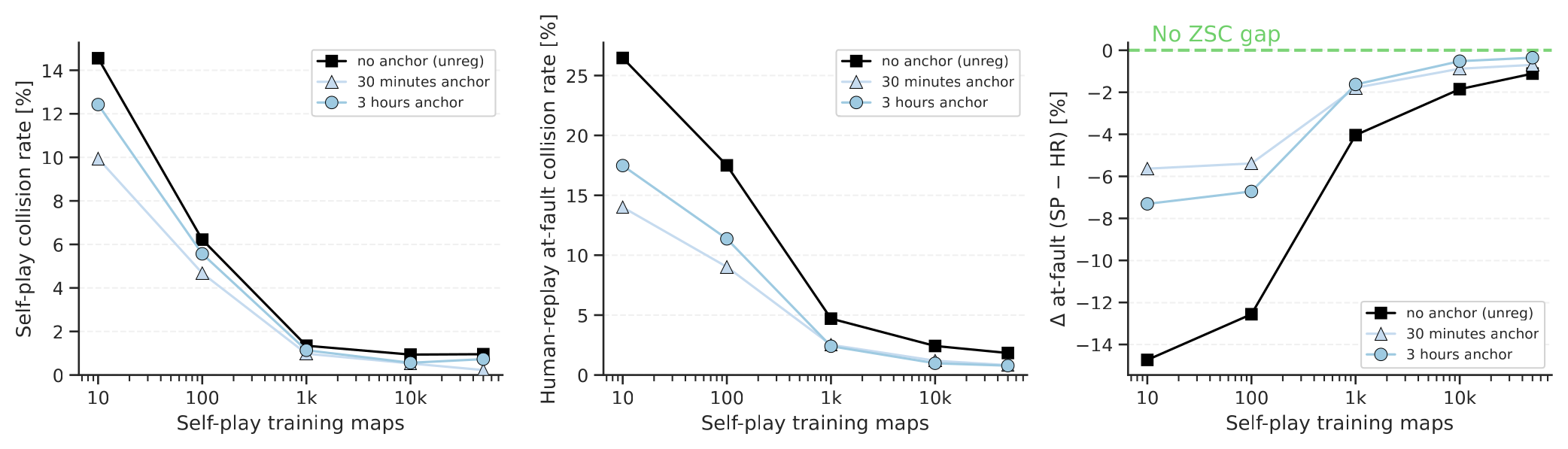 Figure 5:训练时用 \(|\mathcal{M}_k| \in \{10, 100, 1k, 10k, 50k\}\) 个场景做 sim init,anchor 与 reward 固定。从 10 到 50k 场景,unregularized 的 self-play collision 从 14% 掉到 0.5-1%,human-replay collision 从 25.2% 掉到 2%。正则化把绝对值再压低(30-min anchor 下 human-replay at-fault 14% → 0.7%)。场景 metadata 多样性比 anchor 数据更不可替代——50k 场景 + 30min anchor ≫ 10 场景 + 30h anchor。
Figure 5:训练时用 \(|\mathcal{M}_k| \in \{10, 100, 1k, 10k, 50k\}\) 个场景做 sim init,anchor 与 reward 固定。从 10 到 50k 场景,unregularized 的 self-play collision 从 14% 掉到 0.5-1%,human-replay collision 从 25.2% 掉到 2%。正则化把绝对值再压低(30-min anchor 下 human-replay at-fault 14% → 0.7%)。场景 metadata 多样性比 anchor 数据更不可替代——50k 场景 + 30min anchor ≫ 10 场景 + 30h anchor。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- Sparse reward + on-policy KL anchor 的"对照实验设计"很干净——刻意只给 +1/−1/0,所以任何"类人行为"都可归因到 KL 正则而不是 reward shaping。这跟 Gigaflow 9 项 reward 那套形成方法论上的强对比。
- 30 min / 3h / 30h nested 数据扫——把 "how much data is enough"这件事第一次量化,画出明显的饱和点 (~30 min)。这种 data-efficiency curve 在 self-play + IL hybrid 这条线上之前真没人系统做过。
- All-agent self-play(vs SPACER 的 VRU log-replay)——所有 agent 由 policy 控制,避免"训练时 mix-in 人类 log 轨迹"污染对照。这让"anchor 30 min 就够"的结论更可信,而不是数据偷偷流进来。
- Longitudinal / lateral L2 拆解 + episode 长度(64 vs 38 步)这条质性分析非常精彩——直接给出"unregularized RL 鼓励最短路径(satisficing vs optimizing)"的可解释根因,比单看 collision rate 更有信号。
- \(\Delta v\) severity 分析——把 Waymo 自家安全报告的 metric 搬过来,证明正则化不仅"碰得少"还"撞得轻"。Mean \(\Delta v\) 1.71 vs 2.09、严重碰撞占比 7.5% vs 14.3%,这种 ergonomic-safety 视角的指标在 IL/RL 论文里几乎没人列。
- Scenario metadata 与 anchor 数据被解耦扫——发现 metadata 多样性比 anchor 数据更不可替代,给后续工作(如 NoMAD 那种 metadata-grounded transfer)提供了直接结论。
- 15h / 单张消费 GPU——把"self-play 必须 fleet 级"的迷思打掉,复现门槛低。
- 限制章节的诚实程度高:明确写"replay agents 撞过来不算我们的失败"、anchor 的具体微观机制不清、external validity 没测真实路面——这种诚实有利于后续工作 attribute 改进点。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 跟 SMART 比的对照不完全公平。SMART-CLSFT 是 closed-loop fine-tune 版,但架构是 tokenized AR 大模型而 spiced 是 650k MLP——two papers 也只对 anchor data 量做对照,模型容量没控住。更干净的对照是"同样 650k policy + IL"。
- Sparse reward 表面看"无 reward engineering",但 anchor 本身就是设计选择。Anchor 是 SDC-only 轨迹("highest quality"),相当于隐式地把"人类 SDC 像怎么样"这个先验灌进 KL,与 Gigaflow 的 9 项手工 reward 只是显式 vs 隐式之分;论文没正面承认这件事。
- 30 min ≈ 30 h 的饱和现象有可能是 anchor 容量瓶颈而非"30 min 就够"。Anchor 是同一架构同一训练步数,3h / 30h 数据可能没拉满 anchor 容量。WOSAC meta-score 在 anchor 数据加倍时完全不动(0.725 → 0.725),作者也说"BC anchor quality is the limiting factor"——这说明所谓"30 min 就够"更可能是 anchor 形式被定死了。
- At-fault 判定基于 NAVSIM 的几何规则,不是真"驾驶员认为是谁的错"。Replay agent 从后撞 SDC 算被动碰撞,但如果 SDC 在前方突然刹停(合法但激进),按规则也算被撞——这种 edge case 在分数里全归到了被动。这一点在 limitations 里只提了一句。
- Hard set (top 200 interactive scenes) 上 at-fault 从 0.7% 涨到 2.1-2.8%(×3-4)。Limitations 自己承认了,但意味着在真实长尾里"30 min anchor"未必撑得住。这与 World Engine 等强调 long-tail 的工作有冲突,但本文没正面讨论。
- Single-agent RL(against fixed human replay)at-fault 是 0.2-0.3%,比 self-play 还低。作者用它论证"self-play 让对手分布更鲁棒",但反过来也意味着——如果只关心 "和人协调"评测,single-agent 反而最好。Self-play 的真正价值需要 ID 外(onboard 未来遇到的别的自动驾驶车 / 多 AV 群)才显现,而这条假设本文没测。
- SMART baseline 是另一个团队的工作(CAT-K)的 checkpoint 直接拿来用——没在文章实验里完整复现 SMART 的 ablation,相当于把 IL 那侧的能力上界外包。
- PufferDrive 2.0 simulator 也是同生态的工作。"15h on consumer GPU"的卖点高度依赖这套 simulator 选型;换 Gigapixel 或 SPACER 用的 simulator 时间倍数完全不同。
- Anchor distribution properties (entropy / mode coverage) 与最终 policy quality 的关系完全没拆。论文 limitations 自己承认这是 open question;既然"30 min 就够"成立,下一步当然是问"什么 30 min"——但全文没做 "anchor 选择" sweep。
- 跨 city / 跨地理 generalization 未测——所有训练 + 评测都在 WOMD(北美城市)。这与 NoMAD 那条"metadata-grounded transfer"线还没接上。
5.3 值得继续探讨的方向¶
- 多 anchor / mixture-of-anchors:30 min 的"激进 / 谦让 / 老练"司机分别训 anchor,做 mixture KL 而非单 anchor;和 Gigapixel 的 persona-conditioned teacher 是同一方向不同切法。
- Anchor curriculum:先用大 anchor 数据搭框架,再退到小 anchor 做精细调;类似 schedule 在 RLHF 里有现成范式。
- \(\lambda\) 调度:现在 \(\lambda\) 固定 0.075;前期高 \(\lambda\)(强 anchor 拉到人类风格)→ 后期低 \(\lambda\)(让 RL 在人类盆地里做 fine-grained 优化)是直接可试的。
- 跨 dataset / 跨地理 anchor 移植:在 WOMD 训 anchor、在 nuPlan / Argoverse 上 self-play,能否撑住"30 min 就够"。
- 接 Gigapixel 的 pixel-based self-play DAgger:用 Spiced 的 anchor 替代 Gigaflow teacher 作为 vectorized teacher,给 pixel student 蒸馏。两条线天然互补。
- Anchor 的最小信息量度量:能否在采集前就估出"完成 task X 需要多少 min 人类驾驶数据"——论文末尾点了 epiplexity (Finzi 2026) 但承认不可计算。
- Hard scenario 上的 robustness:top 200 难场景上 at-fault 增 3×;可考虑 hard-example mining + KL 退火。
- Real-vehicle deployment:external validity 是 Limitations 里最弱的一环;论文里完全没有真车数据。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://spiced-self-play.com/
- 关键 baseline / 相关论文:
- HR-PPO (Cornelisse 2024) —— 同作者的"前作 v1",受限于 Nocturne 2k SPS
- SPACER (Chang 2025) —— 同期 KL-anchored self-play,anchor 是全 Waymo SMART
- SMART (Wu 2024) + CAT-K (Zhang 2025) —— IL 上界 baseline
- Gigaflow (Cusumano-Towner 2025) —— 反面:9 项 reward + DR 的 self-play 方案
- GIGAPIXEL (Rowe 2606.19641) —— 姊妹论文,把 self-play 扩到 pixel-based E2E(同样作者群体之一 Vinitsky)
- WOSAC (Montali 2023) —— 分布真实性评测
- Waymo Safety Impact Report 2025 —— \(\Delta v\) severity 度量来源
- PufferDrive 2.0 (2025) —— 仿真底座
- Hu et al. 2022, Bakhtin et al. 2022 —— Diplomacy 上的 KL-anchored self-play 先例