Knowledge Insulation: Train Fast, Run Fast, Generalize Better¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better
- 作者机构:Physical Intelligence —— Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z. Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, Sergey Levine
- 出处:arXiv 2505.23705,NeurIPS 2025 preprint;项目页
https://pi.website/research/knowledge_insulation - 关键词:VLA、flow matching action expert、stop-gradient、knowledge insulation、FAST discrete actions、co-training、joint discrete + continuous prediction、PaliGemma、π₀
- 一句话:针对"在预训练 VLM backbone 上挂一个随机初始化的 flow-matching action expert 会破坏 VLM 知识、训练慢、语言遵循能力下降"的问题,本文提出 Knowledge Insulation (KI) —— 在 backbone 与 action expert 的 attention 路径上加 stop-gradient,同时让 backbone 继续用 FAST 离散动作 + 通用 VLM 数据做 next-token prediction,仅让 action expert 用 flow matching 学连续动作;既保住 VLM 预训练知识与语言遵循能力,又拿到快速推理的连续动作输出,并把训练速度提升约 7.5×。
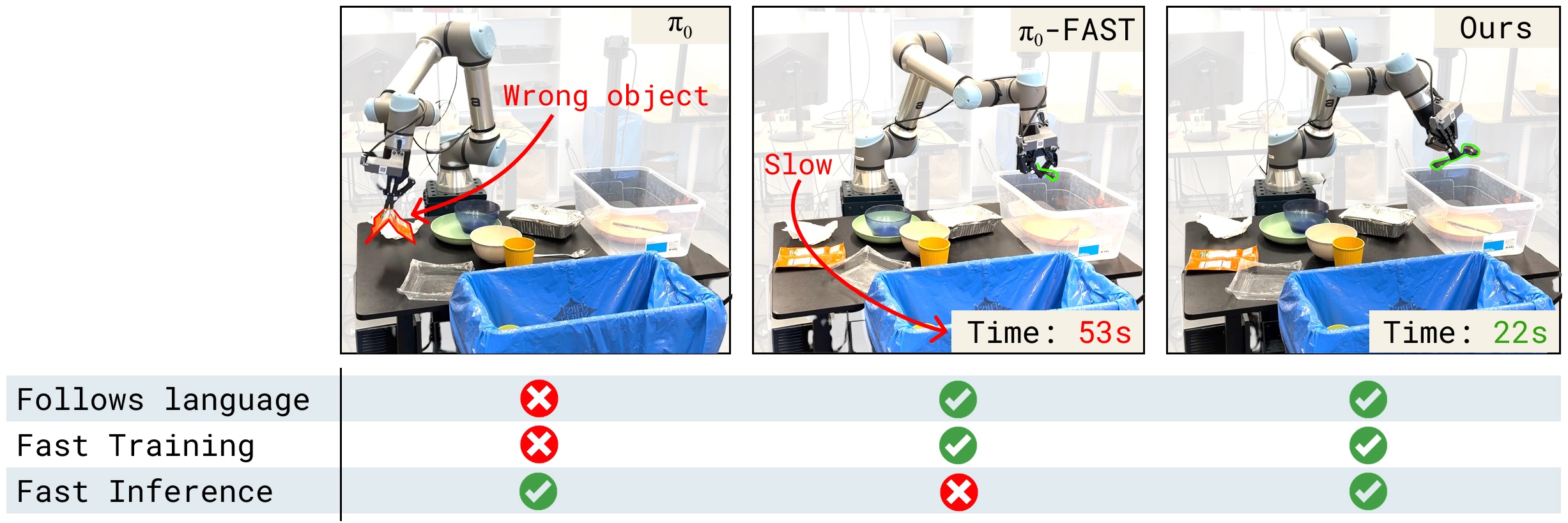 Figure 1:标准 VLA recipe 的问题。"把勺子放进垃圾桶" 指令下 π₀(左)抓错了对象(不遵循语言),π₀-FAST(中)能完成但推理慢(53s),KI(右)既遵循语言又快(22s)。
Figure 1:标准 VLA recipe 的问题。"把勺子放进垃圾桶" 指令下 π₀(左)抓错了对象(不遵循语言),π₀-FAST(中)能完成但推理慢(53s),KI(右)既遵循语言又快(22s)。
2. 文章介绍¶
2.1 解决的领域和问题¶
本文研究的领域是 VLA(vision-language-action)模型如何把 web-scale VLM 的语义/世界知识有效迁移到机器人控制,同时满足实时高频连续控制的工程约束。
核心问题:现代 VLA 为了拿到"连续动作 + 快推理",普遍在预训练 VLM 上加一个随机初始化的 action expert(diffusion 或 flow matching head),用 mean-squared 流场损失训练。这一做法会带来两个相互纠缠的副作用:
- VLM 预训练知识被破坏:随机初始化 expert 反传回 backbone 的梯度对预训练权重是噪声 → 语言遵循、OOD 泛化能力显著下降;
- 训练收敛慢:纯流场损失提供的信号弱,要花 7.5× 训练步数才能逼近 next-token prediction recipe 的性能。
作者要回答:能不能既保留 fast continuous control(action expert),又不损失 VLM 知识、又让训练快?
2.2 Motivation¶
VLA 的最大卖点本是 "从 web-scale VLM 继承语义",但实测中加了 action expert 之后这些好处大量流失——具体表现为: - π₀ 给定语言指令时常常"看图忽略文字",去抓最显眼的物体而非被命令的物体; - π₀ 训练慢得离谱(160K 步只到 0.3 task completion,而离散方案同步数到 0.9); - 把 backbone 冻住强行"保护知识"又彻底不能解任务,因为 PaliGemma 的预训练表征对机器人控制根本不够。
作者的直觉是:问题出在 随机初始化的 expert 反传脏梯度 —— 如果给 backbone 一路"干净"的训练信号(next-token prediction on FAST 动作 token + 通用 VLM 数据),同时把 action expert 当成"只接收 backbone 表征、不污染 backbone"的纯输出模块,就能既快、又稳、又保住知识。
2.3 之前工作的问题¶
| 路线 | 代表 | 主要缺陷 |
|---|---|---|
| 纯 autoregressive VLA(朴素离散化 → next-token) | RT-2、OpenVLA | 控制频率 <2 Hz,推理时序列解码慢;动作分辨率受 token 网格限制;难做高频 dexterous 任务 |
| FAST 离散 + AR(DCT + BPE 压缩 token) | π₀-FAST、MiniVLA | 训练快、保 VLM 知识好,但 1 秒 chunk 推理约 750 ms(RTX4090),实测速度仅 π₀ 一半,且离散精度限制 dexterous 任务 |
| 连续 flow / diffusion expert | π₀、AgiBot, GR00T | 推理快、连续精确,但随机初始化 expert 反传梯度污染 backbone → 语言遵循差、训练慢(7.5× 步数)、OOD 泛化差 |
| diffusion head(不分 expert) | RDT、DexVLA、HybridVLA | 同上;HybridVLA 还让 AR token 与 diffusion 输入互相 attend,本文显示这反而伤性能 |
| two-stage:先 FAST AR 训,再加 expert fine-tune | OpenVLA-OFT、π₀.₅ | 仍需两阶段管线;π₀.₅ 在 post-train 才挂 expert,本文把它形式化并改为单阶段联合训练 |
| Transfusion 风格(同一 backbone 兼做 diffusion) | Transfusion | 没有独立 expert 也能跑,但训练比本文慢、推理慢 |
| 冻结 backbone | — | VLM 预训练表征对机器人不够,实测真机任务 0% 成功 |
2.4 论文解决方案(一句话)¶
提出 Knowledge Insulation (KI) 训练 recipe:在单一 PaliGemma backbone + 300M flow-matching action expert 架构上,同时跑 (1) backbone 用 FAST 离散动作 token + 通用 VLM 数据做 next-token prediction,(2) action expert 用 flow matching 学连续动作,并在 attention 矩阵的 (action→backbone) K/V 路径插 stop-gradient,让随机初始化的 expert 不能把脏梯度传回预训练 backbone。
2.5 与前序工作的关系¶
- 直接继承 π₀ / π₀-FAST 架构:复用 PaliGemma 2B backbone + 300M action expert + FAST tokenizer;推理时仅用 expert 出 50 步 chunk。
- 形式化并扩展 π₀.₅:π₀.₅ 先 FAST AR 训 backbone,再 post-train 阶段加 expert(两阶段);本文把它改为单阶段同时训,更简洁、效果更好。
- 与 HybridVLA 对比:方法论最接近——也同时用离散 + 连续表征。区别在 (a) HybridVLA 让 AR token 与 diffusion 输入互相 attend,KI 用 attention mask 阻断;(b) HybridVLA 不做 stop-gradient。结果 HybridVLA 在 items-in-drawer 任务掉到 ~29%,KI 到 95%。
- 与 Transfusion 对比:Transfusion 共用 backbone 做 diffusion,无 expert;本文显示 KI 在语言遵循上更好,且推理更快。
- 与 mixture-of-experts 多模态架构:沿用 \citep{liang2024mixture} 风格的"按 token 类型分权重"思路,但创新点在 stop-gradient 而非 MoE 路由。
- 与 OpenVLA-OFT 对比:OFT 是 parallel decoding 离散方案,本文用它做 baseline,证明 KI 在性能上更强。
3. 方法介绍¶
3.1 标准 VLA 训练形式化¶
VLA 把 VLM 适配成 \(a \sim \pi(\cdot | I_{1:V}, q, \ell)\)(图像、proprio state、语言→动作)。模型按 token 类型 \(\rho(i)\in\{\text{image},\text{word},\text{action},\text{state},\ldots\}\) 分支:图像走 ViT,文本走 embedding,连续输入走 affine projection。Transformer 用 (width=2048, depth=18, mlp=16384, heads=18) 的 PaliGemma-2B 配置作为 backbone,action expert 用 width=1024, mlp=4096 的小版本(约 300M 参数)。
两种基础训练 loss:
- AR-VLA(离散动作 / 语言 next-token): $\(\mathcal{L}_\text{AR-VLA}(\theta) = \mathbb{E}_{(x,y)\sim\mathcal{D}}\Big[-\sum_{j=1}^{n-1} M_j \log p_\theta(y_{j+1}\mid x_{1:j})\Big].\)$
- FLOW-VLA(连续动作 flow matching):在 \(a^{\tau,\omega}_{1:H}=\tau a_{1:H} + (1-\tau)\omega\),\(\omega\sim\mathcal{N}(0,\mathbf{I})\) 上预测流场 \(\omega - a_{1:H}\): $\(\mathcal{L}_\text{FLOW-VLA}(\theta) = \mathbb{E}_{\mathcal{D},\tau,\omega}\Big[\big\|\omega - a_{1:H} - f^a(a^{\tau,\omega}_{1:H})\big\|^2\Big].\)$
π₀ 只用 FLOW-VLA 训整套模型;π₀-FAST 只用 AR-VLA + FAST 离散。两路都各有代价。
3.2 KI 总览¶
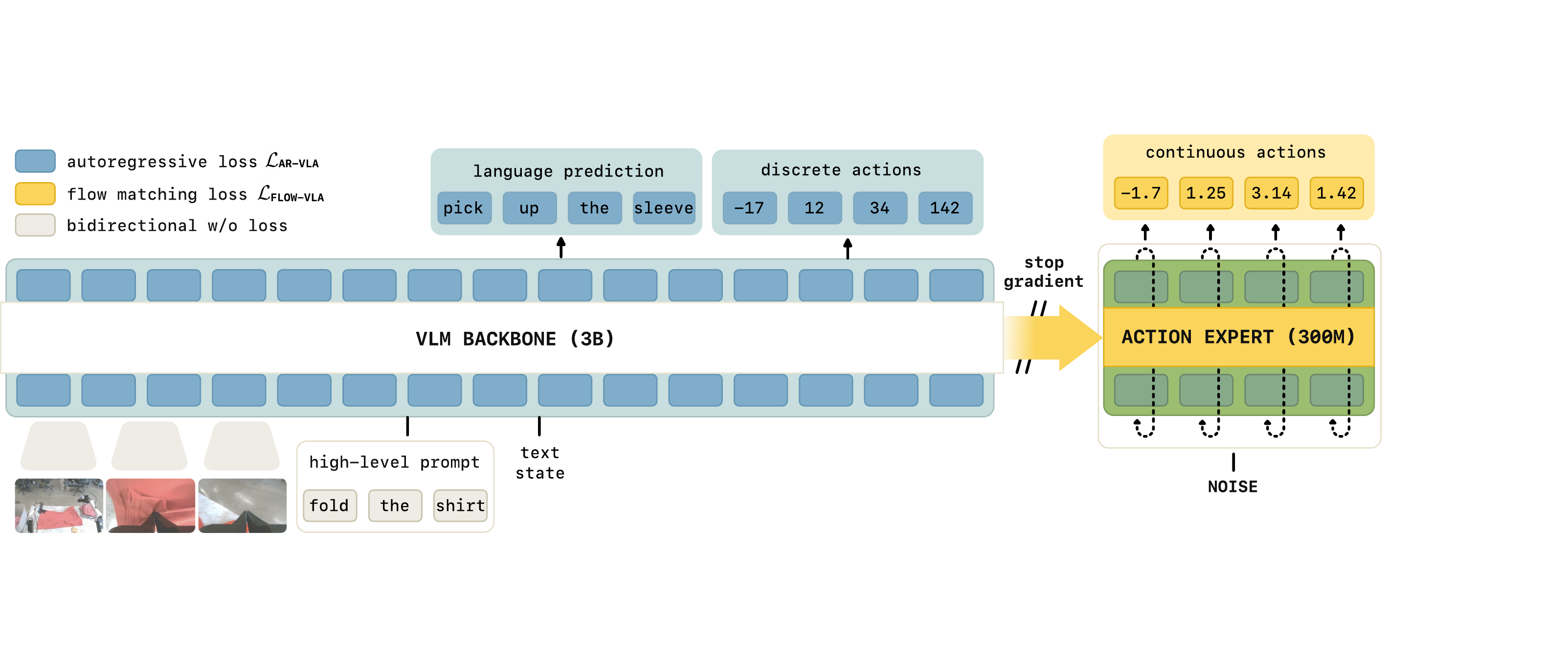 Figure 2:KI 架构。一个 3B PaliGemma backbone 接 300M action expert。Backbone 同时输出 (a) 语言 token(high-level prompt / 子任务文本)和 (b) FAST 离散动作 token;action expert 输出连续动作 chunk(flow matching)。Backbone 与 expert 仅通过 attention 交互,且 expert→backbone 的 K/V 路径插 stop-gradient(橙色"stop gradient"标注)。
Figure 2:KI 架构。一个 3B PaliGemma backbone 接 300M action expert。Backbone 同时输出 (a) 语言 token(high-level prompt / 子任务文本)和 (b) FAST 离散动作 token;action expert 输出连续动作 chunk(flow matching)。Backbone 与 expert 仅通过 attention 交互,且 expert→backbone 的 K/V 路径插 stop-gradient(橙色"stop gradient"标注)。
三个改进同步执行:
- Joint discrete + continuous action prediction:同一前向里 backbone 跑 FAST 离散动作 next-token loss,expert 跑 flow matching loss;
- VLM data co-training:训练 batch 里混入 image captioning / VQA / object localization 等纯 VLM 数据,保留 web-scale 表征;
- Stop-gradient knowledge insulation:随机初始化的 expert 不向 backbone 反传梯度。
3.3 Co-training loss¶
把两种损失写到一个目标里(式 4):
- \(\hat\ell\) 既包含语言 token 也包含 FAST 离散动作 token;\(M^\ell\) 是语言/离散动作 loss mask,\(M^\text{act}\) 指示该样本是否含连续动作。这一构造允许 batch 灵活混三类数据:纯 VLM 数据(只有图像 + 文本注释,\(M^\text{act}=0\))、纯动作数据(图像 + 语言条件 + 动作)、语言 + 动作联合(动作 chunk 上额外标注"机器人下一步该做什么"的子目标文本,ECoT 风格)。
- 关键约束:attention mask 设为 FAST 离散动作 token 不能 attend 连续动作 token,反之亦然。两路动作在表征上互不渗透,强迫 backbone 独立学好。
- 默认 \(\alpha=1\)(加 stop-gradient 后两 loss 分别作用于独立权重,无需精细加权)。
3.4 Knowledge insulation —— attention 矩阵里的 stop-gradient¶
Backbone 与 expert 仅通过 self-attention 交互。把单头 attention 的概率分块写成: $\(P = \mathrm{softmax}(QK^\top + A) = \begin{pmatrix} P_{bb} & 0 \\ P_{ab} & P_{aa} \end{pmatrix}\)$
其中 \(P_{bb}\) 是 backbone token attend backbone,\(P_{ab}\) 是 expert token attend backbone,\(P_{aa}\) 是 expert token 之间。把右下角的 logit 改成:
value 路径同步处理: $\(E = \begin{pmatrix} E_b \\ E_a \end{pmatrix} = \begin{pmatrix} P_{bb} V_b(X_b) \\ P_{ab}\,\mathrm{sg}\big(V_b(X_b)\big) + P_{aa} V_a(X_a) \end{pmatrix}.\)$
效果是:信息可以从 backbone 流入 expert,但 expert 的反传梯度不能流回 backbone(K/V 路径都被 sg)。 前提:backbone 必须有自己的训练信号,否则它根本不会更新 → 这就是为什么必须同时跑 FAST 离散动作 next-token loss。两者互为依赖:stop-grad 把 expert 隔离掉了 → backbone 缺信号 → 必须用 AR 离散动作和 VLM 数据补回来。
3.5 输入设计¶
- 图像:3 路(base + 双腕)ViT patch;
- 语言:high-level prompt + 子任务文本;
- state \(q\):作者比较 3 种表征——(a) text state(discretize → 数字文本),(b) special token state(每个 bin 一个特殊 token,\(s\) 个 token),(c) continuous state(affine projection)。结论是 text 和 continuous 都能 work,special token 反而最差。
- attention 结构:full prefix mask 作用于 image、language、text state;FAST 动作 token attend prefix + 自回归地 attend 历史 FAST 动作;action expert 的 50 步 noisy actions attend prefix + 互相 attend,但不attend FAST 动作 token。信息从 VLM 单向流向 expert,反向断开。
3.x Implementation Details¶
- 架构:PaliGemma 2B VLM backbone(width=2048, depth=18, mlp=16384, heads=18, num_kv_heads=1, head_dim=256) + 300M action expert(width=1024, mlp=4096,深度同 backbone)。注:论文摘要/介绍写 "3B",实际 backbone 是 PaliGemma 的 2B 版(数字与图 2 标注略有出入)。
- Action chunk:\(H=50\) 步,5 Hz / 50 Hz 不等(按 embodiment 决定);连续动作经单线性层投到 embedding,flow matching 时间步 \(\tau\) 用 sinusoidal embedding + MLP(
swish(W₂·swish(W₁·φ(τ))))再以 adaptive RMSNorm 注入到每层 expert。 - Flow matching timestep 采样:\(p(\tau)=\mathrm{Beta}\big(\tfrac{s-\tau}{s};\alpha=1.5,\beta=1\big),\ s=0.999\)(沿用 π₀,强调小 \(\tau\))。
- 离散动作表征:FAST tokenizer(DCT + 量化 + BPE);与"naive bin 离散化"的对照消融见 §4 ablation。
- VLM co-training 数据:CapsFusion + COCO(captioning)、Cambrian-7M + PixMo + VQAv2(VQA)、加自建室内场景 + 家居物体 bbox 数据(object localization)。
- 机器人数据(generalist):12 个 embodiment(单臂静态 ARX/UR5/Franka、双臂静态 ARX/AgileX/Trossen/UR5、双臂移动 Trossen/ARX slate/Galaxea G1/Hexmove H1/Fibocom),覆盖远多于评测的任务,并混入 OXE 公开数据集。
- Loss 权重:\(\alpha=1\)(stop-grad 后两 loss 作用于独立权重,不需要精细调);conditioning dropout / curriculum 等无需要。
- 训练规模:图 6 给出 generalist 在 table bussing 上的训练曲线——KI 与 π₀-FAST 在 160K 步达 ~0.9,π₀ 同水平需 1.2M 步(约 7.5× 训练成本)。作者说 KI 因为多跑了离散 loss,每步比纯 π₀ 慢约 20%,但收敛快几倍,wall-clock 仍显著省。
- 推理:仅用 action expert 跑少步 flow integration 生成连续 chunk;FAST 离散 head 仅训练时用作表征学习辅助 loss。inference time vs π₀-FAST:表 bussing 任务时间 ~360s vs ~750s(图 5 右)。
- 评测协议:每个真机任务每个策略 10 episodes,按多分项打分;用两侧 t-test 报显著性。
4. 结果对比¶
指标:average task completion(多分项加权成功率)、language following rate(按指令到达正确对象的比例)、time to completion、训练步数 vs completion 曲线。
baselines(全部在作者自己的数据混合上重训):π₀、π₀-FAST、OpenVLA-OFT(去掉 FiLM,保留 text state)、Transfusion、HybridVLA(改加 expert)、joint-training(无 stop-grad)、joint-training w/o VLM data、naive tokenization(替换 FAST)。
4.1 Items-in-drawer(未见环境,单臂静态,专家模型)¶
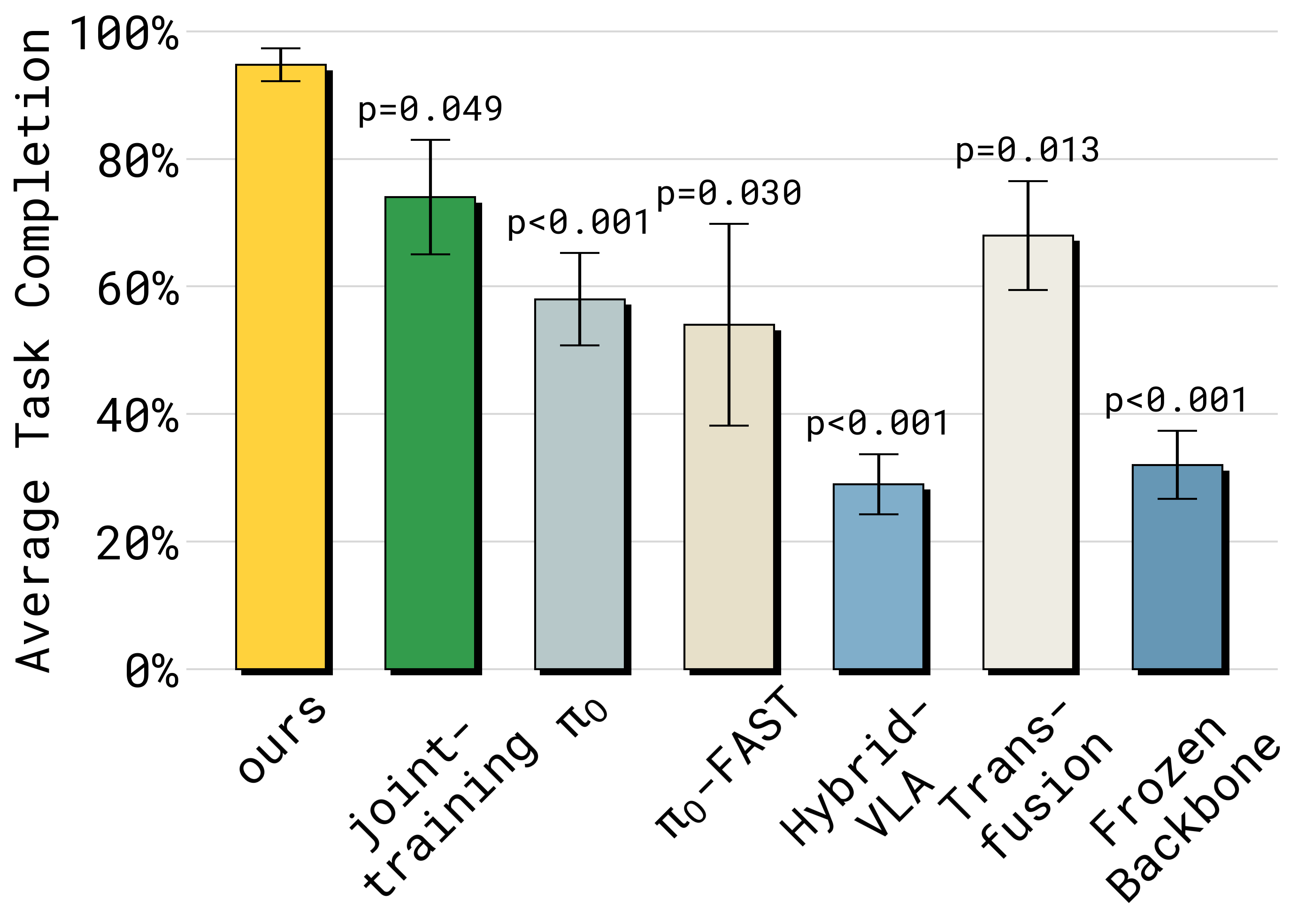 Figure 3:items-in-drawer 任务在 held-out 环境的 task completion。KI(ours,黄)~95%;joint-training(去 stop-grad)~74%(p=0.049);π₀ ~58%(p<0.001);π₀-FAST ~54%(p=0.030);HybridVLA ~29%(p<0.001);Transfusion ~68%(p=0.013);Frozen backbone ~32%(p<0.001)。
Figure 3:items-in-drawer 任务在 held-out 环境的 task completion。KI(ours,黄)~95%;joint-training(去 stop-grad)~74%(p=0.049);π₀ ~58%(p<0.001);π₀-FAST ~54%(p=0.030);HybridVLA ~29%(p<0.001);Transfusion ~68%(p=0.013);Frozen backbone ~32%(p<0.001)。
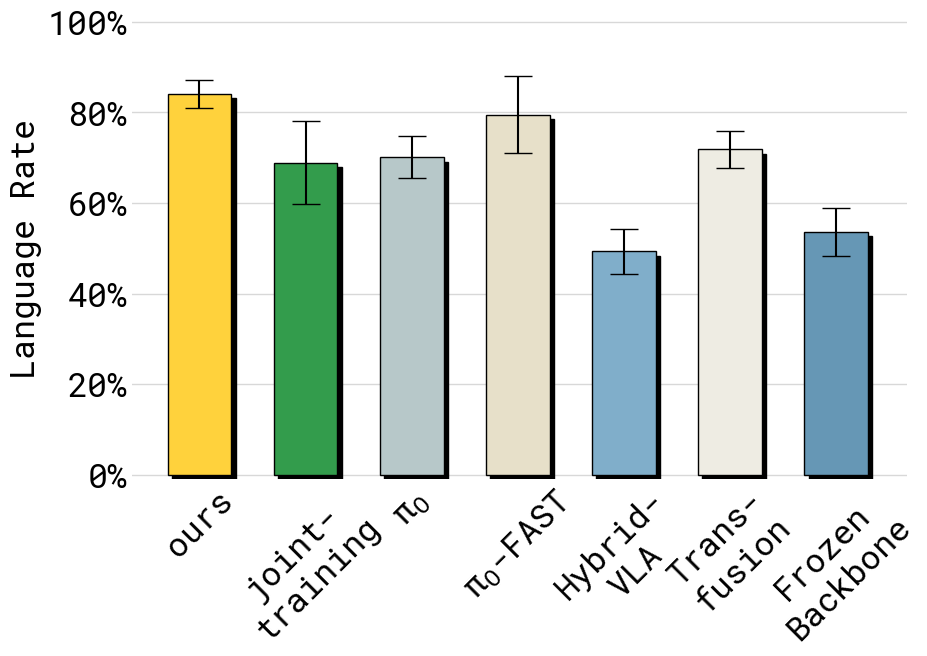 Figure 4:同任务的 language following rate。KI 与 π₀-FAST 在语言遵循上最好;π₀ 与 joint-training (w/o stop-grad) 显著较差,验证"action expert 的脏梯度伤 VLM 语言能力"的核心假设。
Figure 4:同任务的 language following rate。KI 与 π₀-FAST 在语言遵循上最好;π₀ 与 joint-training (w/o stop-grad) 显著较差,验证"action expert 的脏梯度伤 VLM 语言能力"的核心假设。
4.2 Table bussing(单臂静态,generalist & specialist)¶
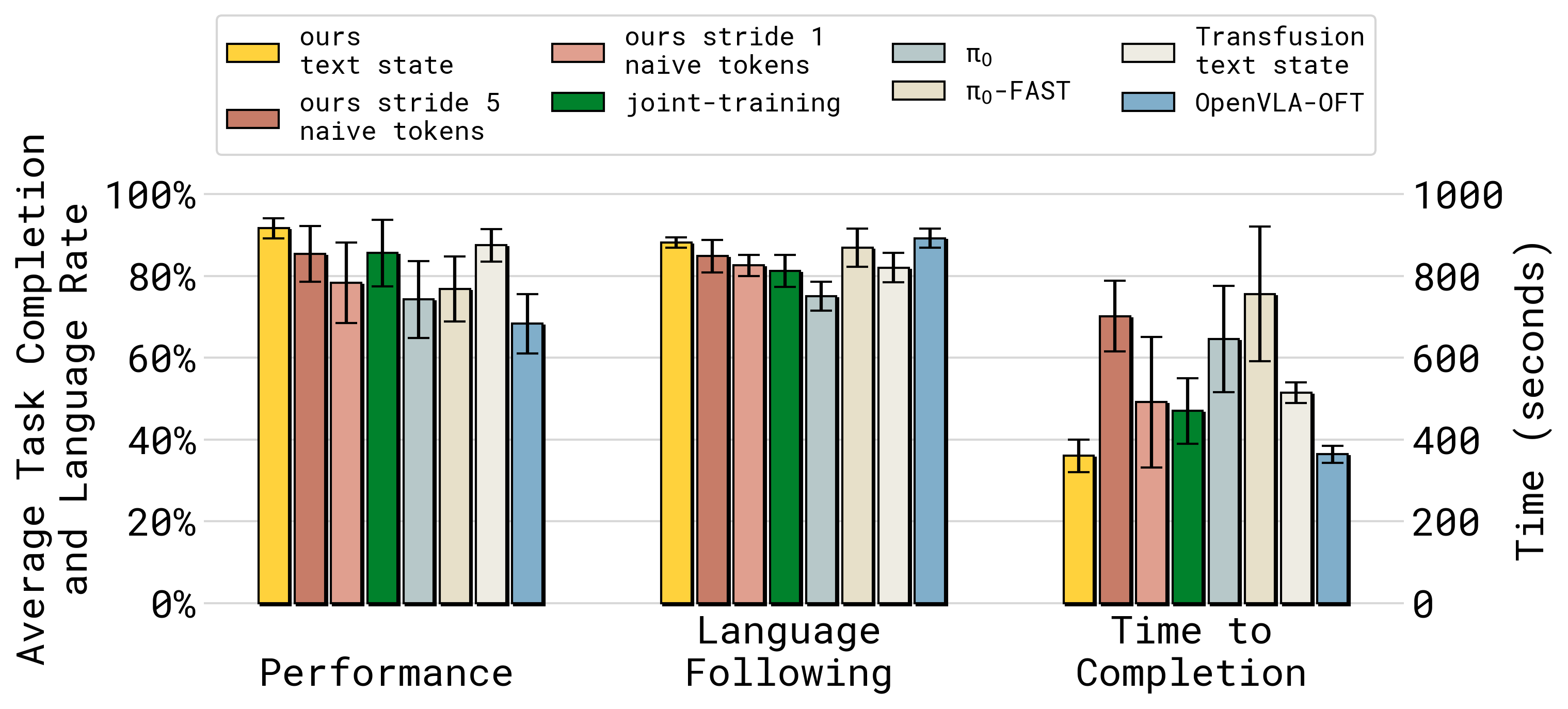 Figure 5:UR5 table bussing specialist 任务三联图。左:performance;中:language following;右:time-to-completion(秒)。KI 同时拿最高 performance、最高 language following 之一、最短 time(~360s),而 π₀-FAST 时间约 ~750s(2× wall clock)。naive tokens(stride 5 优于 stride 1,仍弱于 FAST),joint-training 性能不错但 language following 略差,OpenVLA-OFT 性能最低但推理快。
Figure 5:UR5 table bussing specialist 任务三联图。左:performance;中:language following;右:time-to-completion(秒)。KI 同时拿最高 performance、最高 language following 之一、最短 time(~360s),而 π₀-FAST 时间约 ~750s(2× wall clock)。naive tokens(stride 5 优于 stride 1,仍弱于 FAST),joint-training 性能不错但 language following 略差,OpenVLA-OFT 性能最低但推理快。
DROID open-source benchmark:KI 0.55 ± 0.09,π₀ 0.49 ± 0.09,π₀-FAST 0.45 ± 0.09。
4.3 LIBERO 仿真¶
| 方法 | Spatial | Object | Goal | 10 (Long) | 90 |
|---|---|---|---|---|---|
| Baku | — | — | — | 86.0 | 90.0 |
| MoDE | — | — | — | 94.0 | 95.0 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | — |
| π₀ | 96.8 | 98.8 | 95.8 | 85.2 | — |
| π₀-FAST | 96.4 | 96.8 | 88.6 | 60.2 | — |
| Ours (from scratch) | 96.6 | 97.2 | 94.6 | 84.8 | 92.7 |
| Ours (from generalist) | 98.0 | 97.8 | 95.6 | 85.8 | 96.0 |
Table 1:LIBERO success rates (%)。KI 在 Spatial 与 90 上拿到 SOTA;在 Long(10) 上不如 OpenVLA-OFT。
4.4 Mobile manipulator generalization(未见物体 OOD)¶
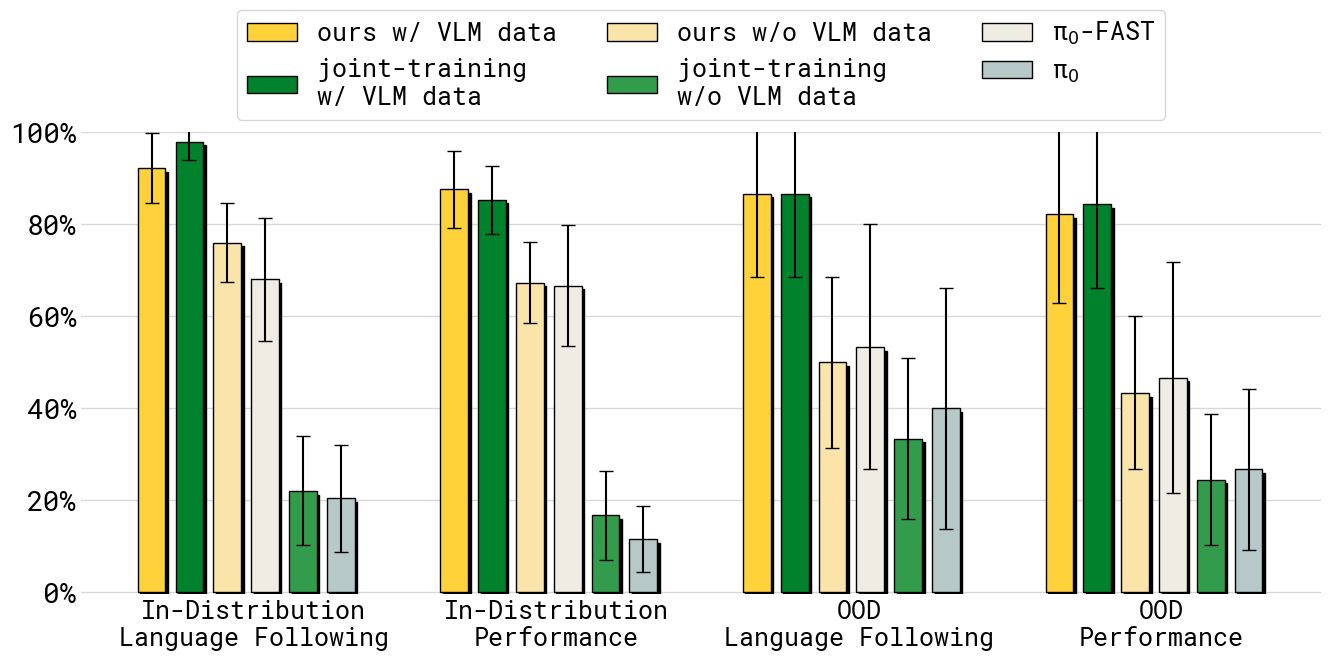 Figure 6:移动操作四子任务(make bed / dish in sink / mobile items in drawer / laundry in basket)平均,按 in-distribution / OOD × language following / performance 拆 4 列。结论:(1) 加 VLM 数据 co-training("w/ VLM data")对 OOD 语言遵循至关重要(KI w/ VLM data ~87% vs w/o ~50%);(2) joint-training (no stop-grad) 必须有 VLM 数据才能保住语言遵循,没有 VLM 数据时跌到 ~33%(红色证据:stop-grad 与 VLM co-training 是互补的两种"知识保护"机制);(3) π₀ / π₀-FAST 在 OOD 上几乎垮掉(~20-40%)。
Figure 6:移动操作四子任务(make bed / dish in sink / mobile items in drawer / laundry in basket)平均,按 in-distribution / OOD × language following / performance 拆 4 列。结论:(1) 加 VLM 数据 co-training("w/ VLM data")对 OOD 语言遵循至关重要(KI w/ VLM data ~87% vs w/o ~50%);(2) joint-training (no stop-grad) 必须有 VLM 数据才能保住语言遵循,没有 VLM 数据时跌到 ~33%(红色证据:stop-grad 与 VLM co-training 是互补的两种"知识保护"机制);(3) π₀ / π₀-FAST 在 OOD 上几乎垮掉(~20-40%)。
4.5 Shirt folding(双臂静态)¶
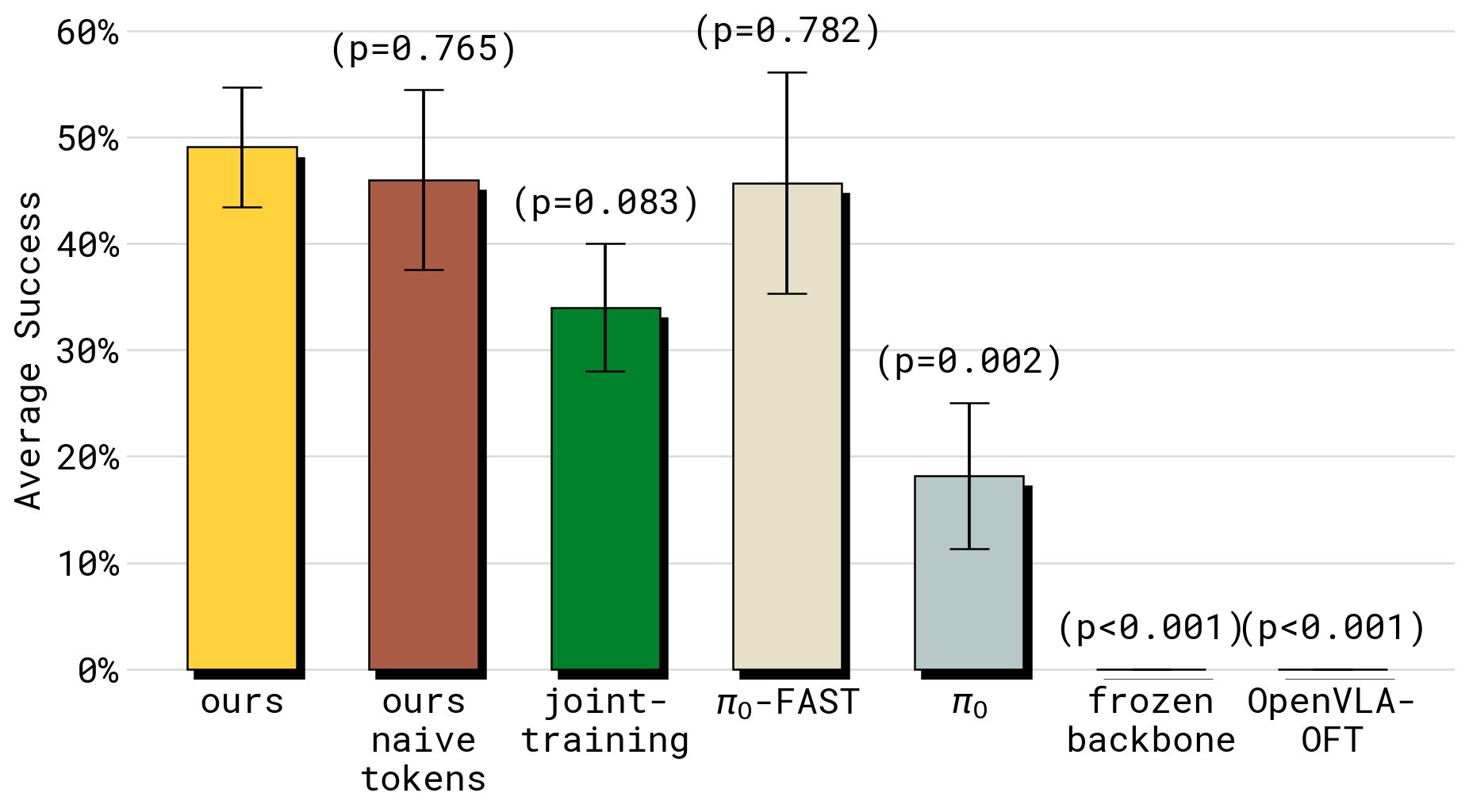 Figure 7:shirt folding 平均成功率。KI ~49%,naive tokens ~46%(与 ours 无显著差异 p=0.765),joint-training ~34%(p=0.083),π₀-FAST ~46%,π₀ ~18%(p=0.002),frozen backbone 与 OpenVLA-OFT 均近 0%(p<0.001)—— 说明这种 dexterous 高频任务里冻 backbone 和 parallel-decoding 完全不工作。
Figure 7:shirt folding 平均成功率。KI ~49%,naive tokens ~46%(与 ours 无显著差异 p=0.765),joint-training ~34%(p=0.083),π₀-FAST ~46%,π₀ ~18%(p=0.002),frozen backbone 与 OpenVLA-OFT 均近 0%(p<0.001)—— 说明这种 dexterous 高频任务里冻 backbone 和 parallel-decoding 完全不工作。
4.6 训练收敛速度¶
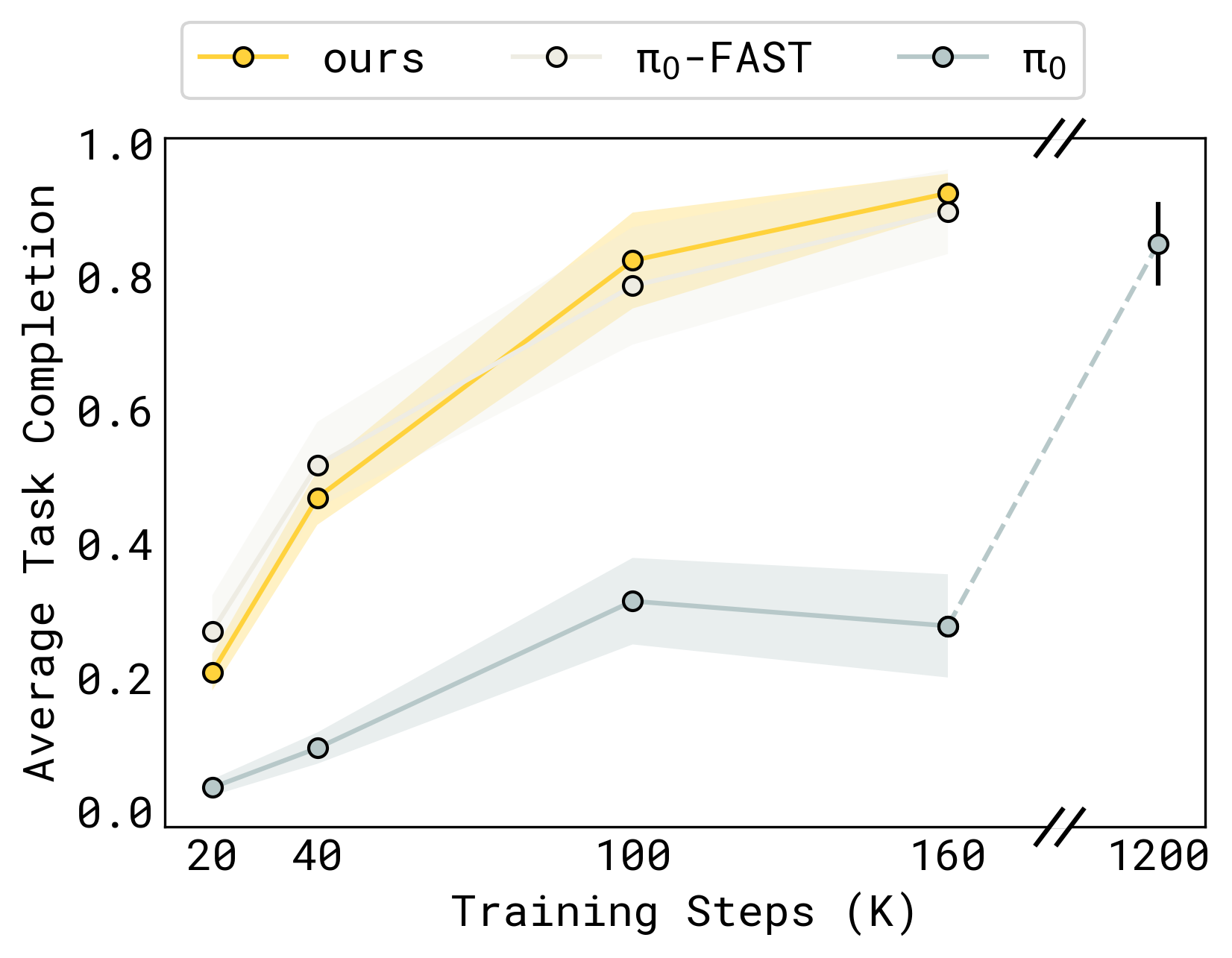 Figure 8:generalist table bussing 训练曲线(average task completion vs training steps,K 步)。KI(黄)与 π₀-FAST(米黄)在 160K 步双双 ~0.9;纯 π₀(蓝)160K 步仅 ~0.3,要到 1.2M 步才达到 0.85,约 7.5× 训练步数。
Figure 8:generalist table bussing 训练曲线(average task completion vs training steps,K 步)。KI(黄)与 π₀-FAST(米黄)在 160K 步双双 ~0.9;纯 π₀(蓝)160K 步仅 ~0.3,要到 1.2M 步才达到 0.85,约 7.5× 训练步数。
4.7 State representation 与离散动作消融¶
- State(附录 figure):text state 与 continuous state 都能 work,special token state 反而最差(论文未给精确数字,仅给柱状图)。π₀ 在两种 state 下都比 KI 差,说明 KI 的提升不是因为换了 state 表征。
- 离散动作 tokenizer(图 5 中 naive stride 1 / stride 5):naive tokenization 比纯 flow 好(说明"离散 loss 提供监督信号"本身就有用),但仍弱于 FAST。stride-5 sub-sampling 又比 stride-1 dense naive 好——印证"FAST 的 DCT 时间压缩对表征学习的确有帮助"。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 诊断清晰、对症下药:作者干脆把"action expert 的脏梯度污染 backbone"这件事单独拎出来用 stop-gradient 解掉,机制上非常干净——一个 attention 矩阵的 sg 操作就能解释大量后续性能差异。
- 三机制互补:stop-grad、joint discrete+continuous loss、VLM data co-training 三件事单看每一件都有人做过,但放在一起后形成了"哪怕去掉 VLM 数据 / 哪怕不 stop-grad 也能 fallback 到次优"的鲁棒训练 recipe,工程价值大。
- 训练成本省 7.5×:在 generalist VLA 训练动辄百万步的语境下,把训练成本拉回 next-token prediction 同等档位(160K 步),同时保持连续动作推理速度 —— 这两件事兼得很罕见。
- OOD 语言遵循证据扎实:mobile manipulator 在未见物体上的对照特别有力:去掉 VLM data 后 joint-training 直接从 87% 跌到 33%,stop-grad 则把这一掉幅显著缩小 —— 直接证明 "保住 VLM 知识 → 保住语义泛化"。
- 诚实的负结果:作者明确报告 LIBERO-Long 上不如 OpenVLA-OFT(85.8 vs 94.5),并讨论 frozen backbone 完全不工作;HybridVLA 这个最像它的方法被它打到 ~29%,但作者也指出根本差异(attention mask + stop-grad)。
- 方法可移植:stop-grad on attention 是任何 dual-stream backbone-expert VLA 都可以无痛加的两行代码改动,可以预见会被其他 flow / diffusion VLA 工作直接吸收。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "stop-grad" vs "VLM co-training" 谁是真正起作用的?归因不彻底。 论文反复强调 stop-grad 是核心,但图 6 显示:joint-training (no stop-grad) 只要加上 VLM data co-training,OOD 语言遵循从 33% 飙到 86%,几乎追上 KI 的 87%。这说明两条防线高度可替代,stop-grad 单独的边际贡献其实没那么大;论文没有给"stop-grad on,VLM data off"vs"stop-grad off,VLM data on"的精细对比,归因含糊。
- 每任务 10 episodes 的样本量小,p 值要打折扣:items-in-drawer 的 KI vs joint-training 那个标志性"p=0.049"是踩着 0.05 边缘的;10 episodes × 多分项打分 + 两侧 t-test 在小样本上结果脆弱,多任务比较里没做多重检验校正。
- 打分维度不透明且主观:T-shirt folding 用 "squareness + wrinkles" 这种带主观判断的打分;items-in-drawer 把 "打开 + 放入 + 关闭" 复合成 5 分制。最终柱状图是这些分项之和的平均,掩盖了真正 hard 子步骤(如开抽屉精度)上各方法的差异,难以判断 KI 的提升来自哪个子步骤。
- 模型规模 / 数字含糊:论文摘要与图 2 标注 "VLM BACKBONE (3B)",但 §B 训练细节给的 PaliGemma 配置算下来是 2B 量级,action expert 又说 "约 300M 参数"——参数计数没明确给出,复现者得猜。
- VLM 数据混合配方未公开 ablation:CapsFusion、Cambrian-7M、PixMo、VQAv2、bbox 自建数据这几路的比例是多少?哪一路对 OOD 语言遵循贡献最大?论文整体把 "VLM data" 当一个开关 on/off 处理,未拆解。
- 缺与"先 FAST AR 训 backbone,再 freeze backbone 接 expert"的最直白对照:本文的核心 claim 是"单阶段联合 > 两阶段",但 baseline 表里只有 π₀.₅ 风格的"先 FAST 再 fine-tune"作为文字提及,未当 baseline 跑数字,使得"单阶段必要性"的证据弱。
- stop-grad 与"backbone 知道没 expert 反传"的矛盾:stop-grad 让 backbone 看不到 expert 的目标,等价于 backbone 不知道下游 expert 需要怎样的表征。论文用"FAST 离散动作也是动作"来回避——但 FAST DCT 压缩后的离散动作和连续 flow target 在 representation 需求上未必完全一致,这种 representation mismatch 在更复杂的 dexterous 任务上是否会暴露?文中无分析。
- 数据/模型完全闭源:π₀ 谱系 + Physical Intelligence 的多机器人 generalist 数据集均不公开,外部只能在 DROID/LIBERO 上做不可控的横向比较,且 LIBERO 上 KI 在 Long 任务输给 OpenVLA-OFT 近 9 个点,但作者轻描淡写带过。
- HybridVLA 的 "29%" 是否在原作配方下复现? 作者承认对 HybridVLA 做了 "slight modification" 来加 action expert,但没给原始 HybridVLA 的数字作为对照;29% 的低分有"为了讲清自己方法、把竞品改坏了"的潜在嫌疑。
- 训练成本 7.5× 的对照可能高估:π₀ 的 1.2M 步是单一 hparam 设定下的曲线,而 π₀ 原始论文中常用的优化器/lr 配置不一定与本文重训的设置一致;"7.5×" 这个数字可能放大了基线劣势。
5.3 值得继续探讨的方向¶
- stop-gradient 的层级与时机控制:能不能只在训练前期 stop-grad、后期解开,做退火式 knowledge insulation?也许能在不破坏知识的前提下让 expert 反过来微调 backbone。
- 把 stop-grad 推广到其他随机初始化模块:vision encoder 的新 adapter、状态投影、bounding-box head 等,所有"随机初始化 → 反传脏梯度"模块是否都该插 sg?通用 recipe 化。
- 把 KI 与 RL 结合:π*₀.₆ (RECAP) 已经在 π₀.₆ 上做 RL;如果 KI 是 π₀.₅/π₀.₆ 的训练前置,那么 RL 阶段应当沿用同样的 stop-grad 还是放开?语言遵循在 RL 中如何保住?
- 更小规模 VLA 上验证可迁移性:1B 以下的小 VLM(SmolVLM 等)上 stop-grad 是否依然有效?知识保护是否仍是瓶颈?
- dexterous + 高频任务的极限:作者已在 5 Hz 双臂任务上成功,但更高频(≥50Hz 力控)或含触觉模态时,离散 FAST 动作作为表征学习信号是否还够?
- 更严谨的归因实验:跑 "stop-grad on / off" × "VLM data on / off" × "FAST / naive / no discrete head" 的 2×2×3 完整网格,把三因素的边际效应分清楚。
- 公开复现:哪怕开源一个 LIBERO 上的 minimal reference 实现(stop-grad attention 改动只有几行),都会大大加速社区接受度。
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:source/
- 项目主页:https://pi.website/research/knowledge_insulation
- 关键 baseline / 相关论文:
- π₀(black2024pi_0)—— flow matching action expert 的原型
- π₀-FAST(pertsch2025fast)—— FAST tokenizer + AR VLA
- π₀.₅(pi2025pi05)—— 两阶段 FAST→expert post-train,本文形式化的对象
- PaliGemma(beyer2024paligemma)—— VLM backbone
- HybridVLA(liu2025hybridvla)—— 同时离散 + 连续动作的最近邻 baseline
- Transfusion(zhou2024transfusion)—— 共用 backbone 做 diffusion 的对照
- OpenVLA-OFT(kim2025fine)—— parallel decoding 离散 baseline
- FAST(pertsch2025fast)、flow matching(lipman2022flow / liu2022rectified)、ECoT(Zawalski24-ecot)—— VLA 训练组件
- DROID(khazatsky2024droid)、LIBERO(liu2024libero)—— 评测 benchmark