π₀.₇: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:π₀.₇: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
- 作者机构:Physical Intelligence(团队作者,Bo Ai、Kevin Black、Danny Driess、Chelsea Finn、Karol Hausman、Sergey Levine、Karl Pertsch、Lucy Xiaoyang Shi 等)
- arXiv 编号 / 时间:2604.15483,2026-04
- 项目主页:https://pi.website/pi07
- 关键词:steerable generalist robot foundation model、VLA、flow matching、diverse prompt conditioning(subtask 指令 + subgoal images + episode metadata)、emergent capabilities(compositional / instruction / cross-embodiment / long-horizon generalization)、distillation(把 RL specialist 蒸馏进通用模型)、coaching(语言教学)、MEM history conditioning
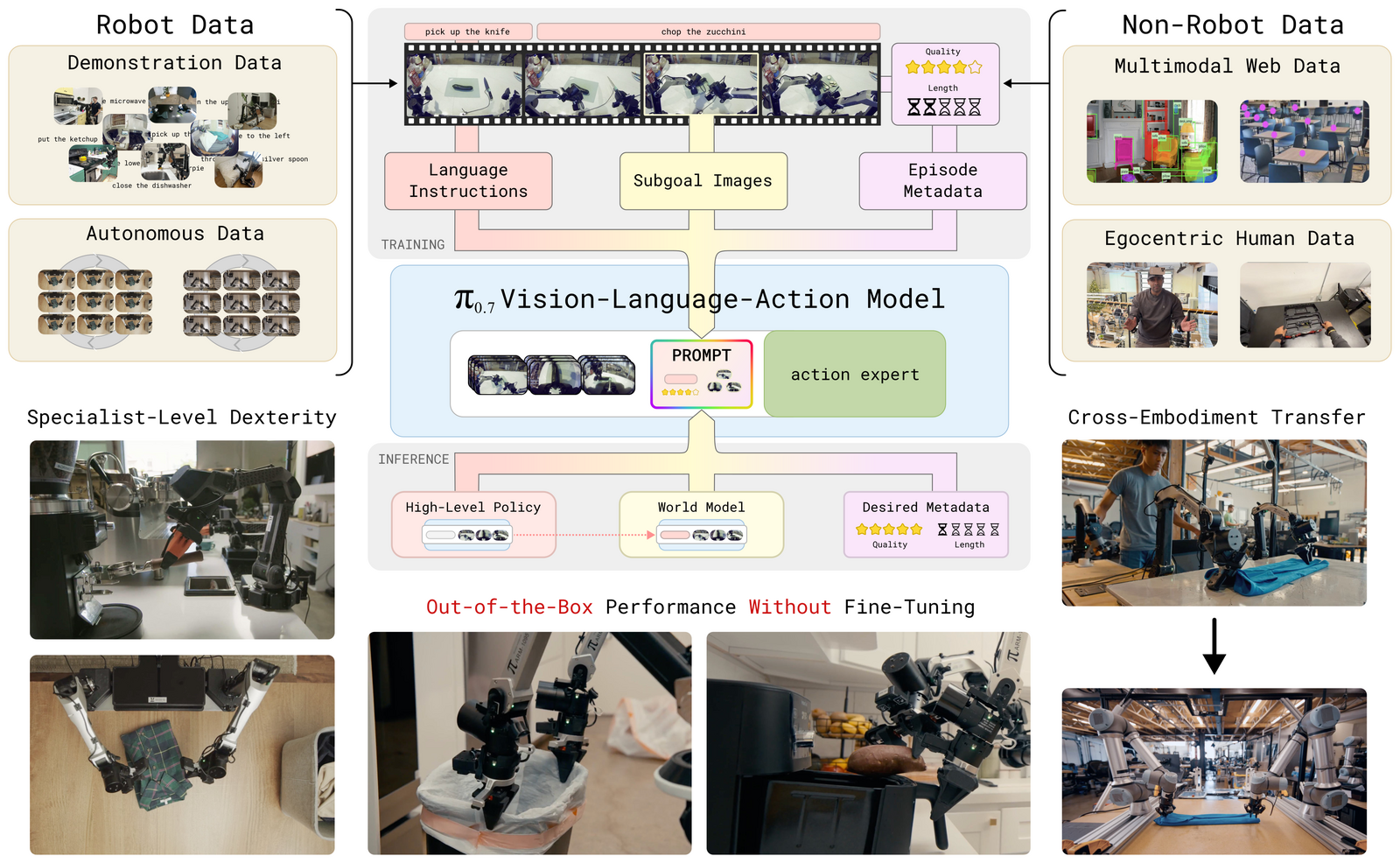 Figure 1:π₀.₇ 是一个可 steer 的通用机器人 foundation model,跨多任务、多环境、多机器人执行灵巧任务。核心 takeaway:训练时给每条数据加上丰富的多模态 prompt(不只是"做什么"的 task 描述,还包括详细 language、生成式 subgoal images、episode metadata),从而既能利用极其多样(含失败、自主、非机器人)的数据,又能在推理时把这些 skill 以新方式组合起来解决新任务。
Figure 1:π₀.₇ 是一个可 steer 的通用机器人 foundation model,跨多任务、多环境、多机器人执行灵巧任务。核心 takeaway:训练时给每条数据加上丰富的多模态 prompt(不只是"做什么"的 task 描述,还包括详细 language、生成式 subgoal images、episode metadata),从而既能利用极其多样(含失败、自主、非机器人)的数据,又能在推理时把这些 skill 以新方式组合起来解决新任务。
2. 文章介绍¶
2.1 解决的领域和问题 (steerable generalist robotic foundation model)¶
机器人 foundation model(VLA)近年在规模与能力上进步显著,但与 LLM 不同,它们的 compositional generalization 一直缺位:先前 VLA 不仅难以解决全新任务,甚至常常无法在不做 task-specific fine-tuning 的情况下流畅执行所有训练过的指令。本文要解决两个问题:
- 如何从大规模、异质、混质量的数据中学习(含 demonstration、失败/低质量数据、prior model 自主 rollout、egocentric 人类视频、web 多模态数据),而不被"平均不同模式"拖垮。
- 如何让一个单一通用模型在推理时被精确 steer——通过 prompt 指定"怎么做"(速度、质量、策略、视觉目标),从而 out-of-the-box 匹配为单任务专门 fine-tune(甚至 RL post-train)的 specialist。
2.2 Motivation (为什么需要 runtime steerability + 通用 foundation model 的 emergent 能力)¶
- 数据多样性 vs 朴素训练的矛盾:直接把高质量演示 + 失败 + 自主数据混在一起训练,模型会把不同模式 average 起来,产出次优行为。需要一种机制让模型"知道"每条数据的质量/策略,从而在推理时只被引导到高质量模式。
- 借鉴 prompt expansion:图像/视频生成领域用 prompt expansion 提升生成质量。机器人里仅靠"更详细的文字 caption"不够——决定成功与熟练度的细节往往很微妙(如整段 episode 的整体质量),或难以用语言表达(如一件叠得干净的 T 恤的具体外观)。因此除详细文字外,还要加 episode metadata 和 subgoal images。
- emergent 能力是通用性的基石:希望像 LLM 那样,通过 prompt/coaching 而非为每个新任务采集动作数据,就能让机器人执行新任务(instruction generalization、cross-embodiment、compositional、long-horizon)。
2.3 之前工作的问题¶
| 方法 / 路线 | 主要缺陷 |
|---|---|
| π₀ / π₀-FAST | 仅用短文字任务描述作为 context;最好性能仍需 task-specific fine-tune;语言跟随弱 |
| π₀.₅ | 引入了 high-level subtask 文字,但仍难处理开放词汇 / OOD 指令;跨较大 embodiment gap 退化明显(如 UR5e↔小型双臂) |
| π₀.₆ / π*₀.₆ (RL) | π₀.₆ 用 RL 把单个灵巧任务做到专家级,但是 per-task specialist*,不通用;通用 π₀.₆ 本身达不到 specialist 性能 |
| 其它 generalist VLA(RT-2、OpenVLA、Octo 等) | 语义泛化有(认新标签的物体),但执行新任务的 compositional generalization 基本缺位 |
| 固定/不可 steer 的策略 | 在有 dataset bias 的场景里会无视语言、盲目复制数据中的行为;无法被 runtime 引导到不同策略/质量 |
| 朴素混质量训练 | 把高低质量、不同策略数据 average,性能反而随数据量下降 |
2.4 论文解决方案(一句话)¶
在 π₀.₆-MEM 的 VLA 架构上,用 diverse context conditioning(detailed language + episode metadata + 生成式 subgoal images,且训练时各组件随机 dropout) 把大规模混质量/异质数据"消歧"成可控的训练信号,得到一个推理时可被 prompt/coaching 精确 steer、并涌现出 compositional / instruction / cross-embodiment / long-horizon 泛化能力的通用机器人 foundation model π₀.₇。
2.5 与前序工作的关系 (build on π 系列)¶
- Backbone:从 Gemma3 4B VLM(含 400M 视觉编码器)初始化。
- 架构基座:建立在 π₀.₆ 的 VLA 架构 + MEM 记忆系统之上(即 π₀.₆-MEM),扩展多模态 context conditioning。
- 训练配方:复用 Knowledge Insulation (KI)——VLM backbone 用 FAST 离散 token 做交叉熵监督,action expert 通过 flow matching 学连续动作,且 action expert 的梯度不回流到 backbone。
- subtask 文字:沿用 π₀.₅ 的 high-level/intermediate 语义子任务文字。
- subgoal image 生成:world model 沿 SuSIE 思路,从 BAGEL(14B mixture-of-transformers 图像生成/编辑模型)初始化。
- 数据来源之一:把 π₀.₆ 在 RL 训练中采集的自主数据作为额外样本,等价于把 RL specialist 的行为 distill* 进通用模型。
- 推理平滑:采用 real-time action chunking (RTC) 的训练时版本。
3. 方法介绍¶
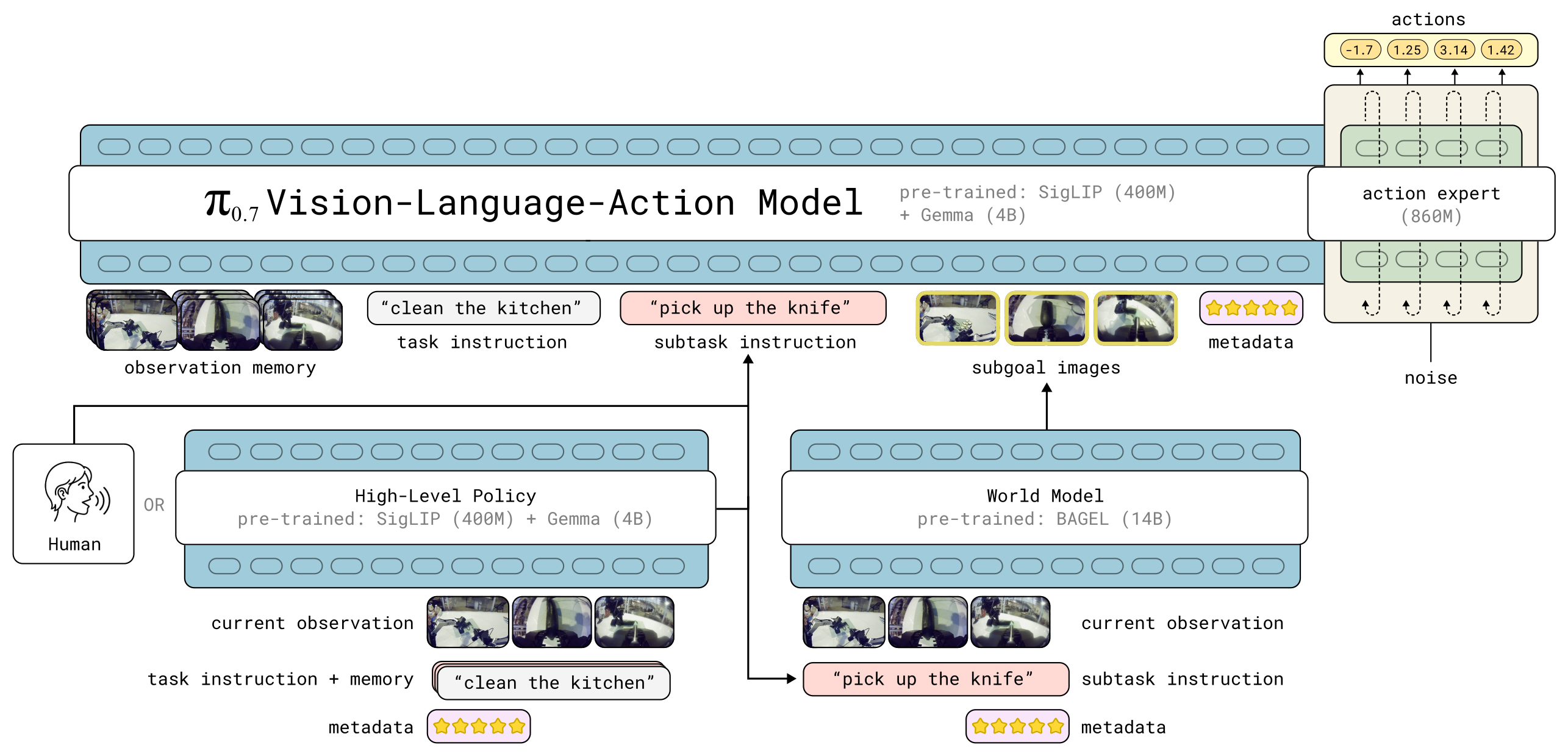 Figure 2:架构总览。π₀.₇ 是 5B 参数 VLA = 4B VLM backbone + MEM 风格视频 history 编码器 + 860M action expert。Context 含语言指令、episode metadata(数据质量/策略)、subgoal images 等多模态。运行时,语言指令由同架构的 high-level 语义策略产生,subgoal images 由基于 BAGEL 的轻量 world model 产生。
Figure 2:架构总览。π₀.₇ 是 5B 参数 VLA = 4B VLM backbone + MEM 风格视频 history 编码器 + 860M action expert。Context 含语言指令、episode metadata(数据质量/策略)、subgoal images 等多模态。运行时,语言指令由同架构的 high-level 语义策略产生,subgoal images 由基于 BAGEL 的轻量 world model 产生。
3.1 模型架构 (VLA + action expert, attention mask, history/memory conditioning)¶
- 总规模 ~5B:4B Gemma3 VLM backbone + 860M flow matching action expert。
- 输入:最多 4 路相机(前视、两个腕部、可选后视),每路最多 6 帧 history;最多 3 张 subgoal images(不含后视)。所有图像 resize 到 448×448。history 帧经 MEM 视频编码器做时间+空间压缩,压成与单帧相同的 token 数;subgoal images 走同一编码器。
- history / memory conditioning:history 帧按 1 秒 stride 采样,整段 history 以概率 0.3 整体 dropout;后视图以概率 0.3 dropout。本体状态 \(\bq_t\)(含历史状态)用线性投影嵌入 backbone(不再像 π₀.₆ 用离散文字 token),每个历史状态是一个 token,帧被丢则状态 token 也被 mask。
- attention mask(block-causal):observation token 与 subgoal image token 内部双向注意;goal-image token 可额外注意 observation;后续文字 token 用 causal 注意;训练期的 FAST token 与 flow action 互不注意。推理做 CFG 时把正/负样本打包进同一序列构成"attention tree"两个分支(互不注意)以高效推理。
- action expert:860M transformer,flow matching,用 adaptive RMSNorm 注入时间步。固定 50 个 action token = 50 步 action chunk,50 个 token 双向注意彼此并注意 backbone。
- RTC:训练时模拟 0–12 步延迟(50Hz 机器人上对应最高 240ms 推理延迟)以生成平滑轨迹。
3.2 Steerability 机制 (coaching / prompts / instruction following 在推理时如何起作用)¶
π₀.₇ 的"可 steer"来自训练时把 4 类 prompt 组件喂进 context \(\mathcal{C}_t\),并对每个组件随机 dropout,使推理时可任意取子集:
- Subtask 指令 \(\hat{\ell}_t\)(高层语义子任务,如"打开冰箱门"):可由学到的 high-level 策略给出,也可由人类实时给出 = verbal coaching。模型被训练成跟随多样语言指令,故能在全新任务上跟随人的现场分步指令。
- Subgoal images:用轻量 world model \(g_\psi\)(BAGEL 初始化)根据当前观测 + subtask 指令生成"近未来该长什么样"的多视角目标图,比纯语言更能消歧目标,提升语言跟随与泛化。生成式 subgoal 把 web-scale 语义/物理知识引入策略。
- Episode metadata:overall speed(按 500 步分箱的 episode 长度)、overall quality(1–5 分)、mistake(是否犯错的段标注)。运行时可指令模型"高速、最高质量、无错误"地执行。
- Control mode:文字标识
joint/ee,运行时按任务选关节空间或末端执行器控制(不做 dropout)。
完整 prompt 示例:
<Multi-view observation><Multi-view subgoals> Task: peel vegetables.
Subtask: pick up the peeler. Speed: 8000. Quality: 5. Mistake: false.
Control Mode: joint. <Proprioception>
Coaching → autonomous 闭环:人用语言一步步教模型完成全新长程任务后,把这些 coaching episode 拿来 fine-tune 一个 high-level 策略(输入观测 + 任务规格 + 历史 subtask,输出下一条 subtask 指令),即可让机器人 不采集任何新的低层/teleoperation 数据 就自主完成该任务。
3.3 训练配方与数据 (operator experience hours scaling, cross-embodiment)¶
- 数据构成:多机器人(静态/移动、单臂/双臂)多环境(实验室、类家庭、in-the-wild 真实家庭)demonstration;大量策略评测产生的自主数据;策略 rollout 中的人类干预;开源机器人数据集;egocentric 人类视频;web 非机器人多模态数据(物体定位/属性预测、VQA、纯文本);视频字幕任务。
- 重用 suboptimal 数据:显著区别于经典 VLA pipeline——大量使用低质量演示(失败或含大量错误的成功)和 prior model 评测时采的自主数据,包括 π₀.₆ 在 RL 训练中产生的数据 → 形成对 RL specialist 的"distillation"。注:明确排除*了任何 generalization 评测任务(含本文 §实验中的)中采的自主数据,避免泄漏。
- subgoal 训练采样:仅 25% 的 batch 样本加 subgoal images(加了后训练显著加速,因动作预测退化成"inverse dynamics"问题);加了 subgoal 的样本里 30% 概率再丢掉 subtask 文字;real subgoal 中 25% 取段末帧、75% 在未来 0–4 秒内均匀采;同时大量用 world model 生成的图替代真实未来帧以弥合 train-test 差异。
- metadata dropout:整体 15% 丢弃,三个分量各额外 5% 概率单独丢。
- cross-embodiment:训练数据跨多种臂;测试时把在小型静态双臂上采的灵巧任务(如叠衣)零样本迁移到形态/重量差异巨大的 UR5e 双臂平台(UR5e 20Hz,其余 50Hz)。
3.4 Distillation 加速推理(及 distillation 的两种含义)¶
注意本文"distillation"有两层含义,需区分:
- 能力蒸馏(主线,distillation_results / distillation_ablations 图):通过把 RL/SFT specialist 的评测自主数据 + episode metadata 一起喂入,通用 π₀.₇ 继承(distill)这些 specialist 的行为,从而 out-of-the-box 匹配甚至超过为单任务专门 post-train 的策略。这不是模型压缩,而是"行为蒸馏到一个通用策略"。
- 推理速度优化(见 Implementation Details):通过 RTC 训练时版本、注意力/量化优化把延迟压到可部署水平。
消融(distillation_ablations,见 §4):去掉 metadata(no metadata)或去掉评测自主数据(no eval data)都会全面变差,尤以 throughput 差距最大——说明"用 metadata 消歧的混质量评测数据"是匹配 specialist 的关键。
3.x Implementation Details (参数量, 控制频率, 推理延迟)¶
- 参数量:总 ~5B = 4B VLM backbone(含 400M 视觉编码器)+ 860M action expert;world model 基于 BAGEL 14B(7B LLM backbone + 7B 生成 backbone)。
- 控制频率:UR5e 20Hz,其余机器人 50Hz;动作经简单 PD 控制器执行,末端执行器命令用数值 IK 转关节目标。
- denoising / 执行:5 步 denoising 生成 50 步 action chunk,每次执行 \(\hat H \in \{15,25\}\) 步。
- CFG:因各组件训练时 dropout,可对 metadata 做 classifier-free guidance(\(\beta \in \{1.3,1.7,2.2\}\))以激发灵巧任务的强性能。
- 推理延迟:最小变体在单卡 H100 上 3 路相机 + 5 步 denoising + 训练时 RTC 仅 38ms;开启 MEM 视觉编码器 + subgoal images 后最坏 127ms。
- world model 延迟:14B、序列近 10000 token,用 4×H100 4-way 张量并行 + 8-bit 量化 + 改版 SageAttention,25 步 denoising(含 text+image CFG)约 1.25s,运行时异步(VLA 不等 world model)。
- subgoal 刷新:语义意图变化(新 \(\hat\ell_t\))或距上次 \(\Delta=4\) 秒,取先发生者;subgoal 与 subtask 生成在独立线程,VLA 始终用最新可用结果(异步推理)。
4. 结果对比¶
4.1 Out-of-the-box 灵巧性 / distillation(vs RL & SFT specialist)¶
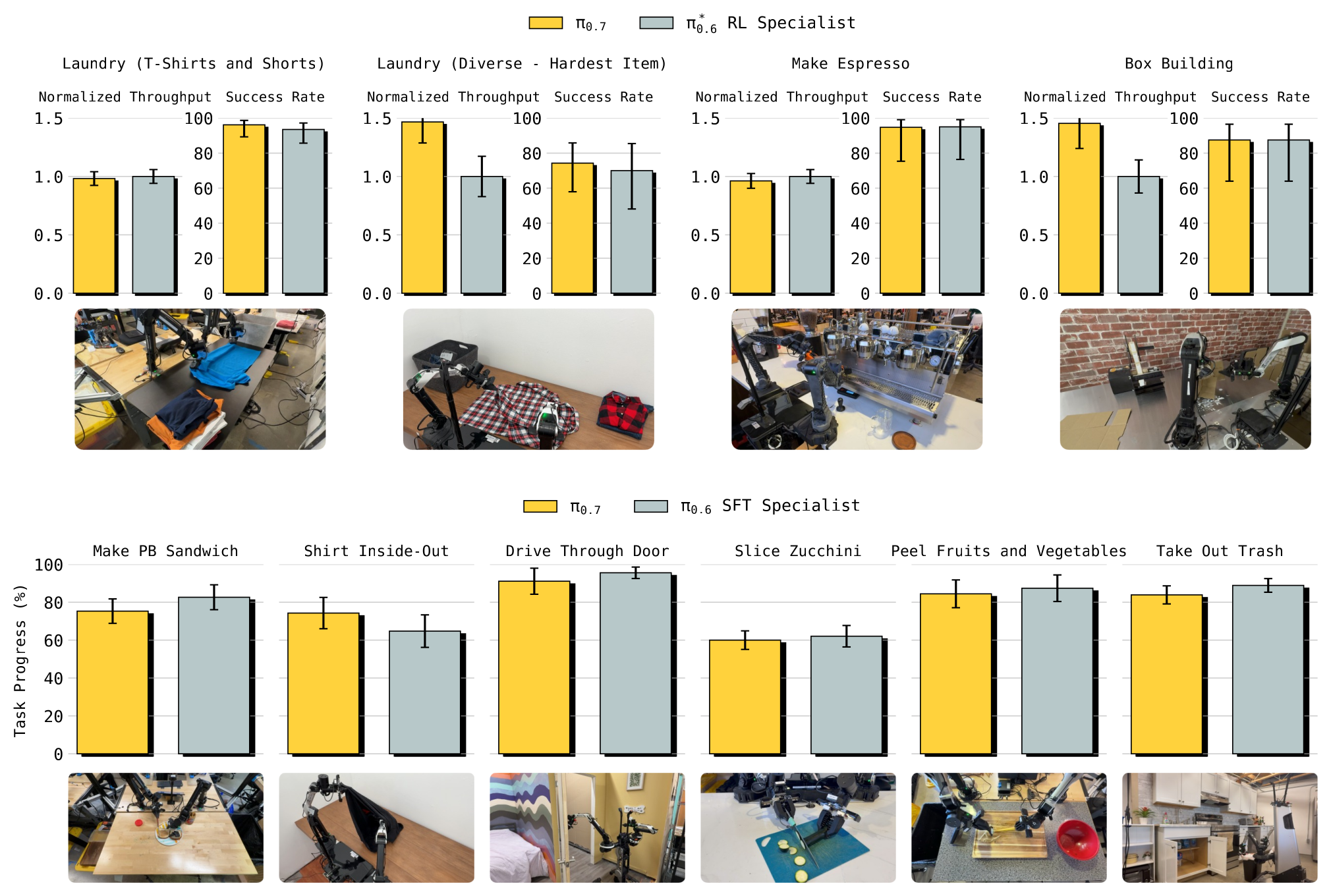 Figure 3:out-of-the-box 灵巧性。上排为 π₀.₆ 的任务(espresso、box building、laundry folding),报 success rate 与归一化 throughput(相对 specialist,原始单位 successes/hour);下排为其它灵巧任务报 task progress。同一个 π₀.₇ 模型直接 out-of-the-box 匹配 π₀.₆ / π₀.₅ 的 task-specific specialist,并在多样叠衣和 box building 上 throughput 超过 RL specialist。
Figure 3:out-of-the-box 灵巧性。上排为 π₀.₆ 的任务(espresso、box building、laundry folding),报 success rate 与归一化 throughput(相对 specialist,原始单位 successes/hour);下排为其它灵巧任务报 task progress。同一个 π₀.₇ 模型直接 out-of-the-box 匹配 π₀.₆ / π₀.₅ 的 task-specific specialist,并在多样叠衣和 box building 上 throughput 超过 RL specialist。
- 关键结论:单一通用 π₀.₇ ≈ 各任务的 RL/SFT specialist,部分任务(laundry、box building)throughput 反超。
4.2 Distillation ablation¶
- π₀.₇ > π₀.₇ (no metadata) 且 > π₀.₇ (no eval data),全任务领先,throughput 差距最大。佐证:评测自主数据 + metadata 消歧是必要条件。
4.3 Memory 任务¶
- 单个 out-of-the-box π₀.₇ 在需要记忆的任务上 相当或优于 MEM 论文里为各任务 fine-tune 的 π₀.₆+memory specialist。
4.4 Instruction following(vs π₀.₅ / π₀.₆)¶
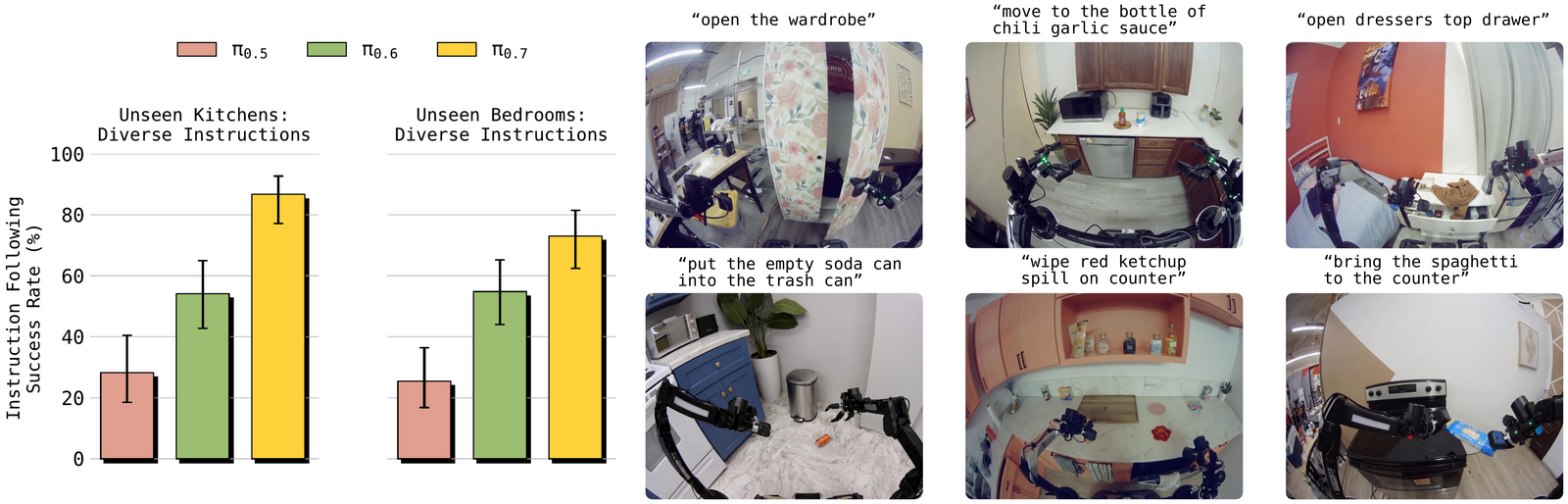 Figure 4:在 14 个 instruction following 场景(每个含 3–6 条开放式指令)、跨 4 个未见厨房 + 2 个未见卧室上评测,报正确跟随指令的百分比。π₀.₇ 全面、显著优于 π₀.₅ 和 π₀.₆,绝对成功率高。
Figure 4:在 14 个 instruction following 场景(每个含 3–6 条开放式指令)、跨 4 个未见厨房 + 2 个未见卧室上评测,报正确跟随指令的百分比。π₀.₇ 全面、显著优于 π₀.₅ 和 π₀.₆,绝对成功率高。
- 复杂指代指令(instruction_generalization):standard 指令各模型都行;complex 指令("拿我喝汤用的东西""拿最大盘子上的水果")π₀.₇ 明显更强,加 subgoal images(π₀.₇ (GC))再提升。
- 打破数据偏置(compositional_generalization):Reverse Bussing / Reverse Fridge-to-Microwave 这类与数据模式相反的指令,先前模型盲目复制偏置行为而失败,π₀.₇ 因语言跟随强能打破偏置;Reverse Fridge-to-Microwave 上 subgoal images 是成功的关键。
4.5 Cross-embodiment transfer¶
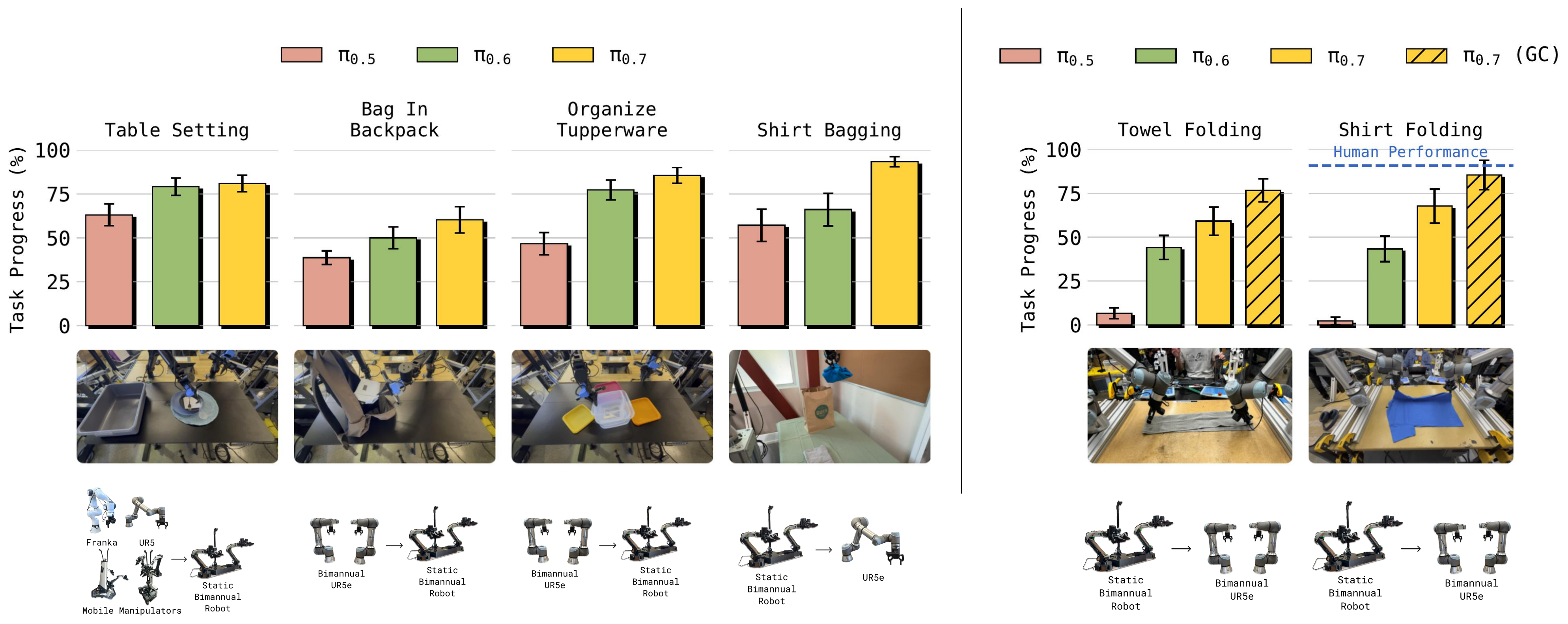 Figure 5:跨 embodiment 迁移。简单重排任务各模型都能零样本迁移;embodiment gap 增大时 π₀.₅ 退化、π₀.₆ 仍可,最大 gap(小型双臂→UR5e 的 Shirt Bagging、叠衣/叠毛巾)π₀.₇ 显著领先,加 world model subgoal(GC)进一步提升,task progress 匹配最有经验人类遥操作者首次尝试的"零样本"表现。
Figure 5:跨 embodiment 迁移。简单重排任务各模型都能零样本迁移;embodiment gap 增大时 π₀.₅ 退化、π₀.₆ 仍可,最大 gap(小型双臂→UR5e 的 Shirt Bagging、叠衣/叠毛巾)π₀.₇ 显著领先,加 world model subgoal(GC)进一步提升,task progress 匹配最有经验人类遥操作者首次尝试的"零样本"表现。
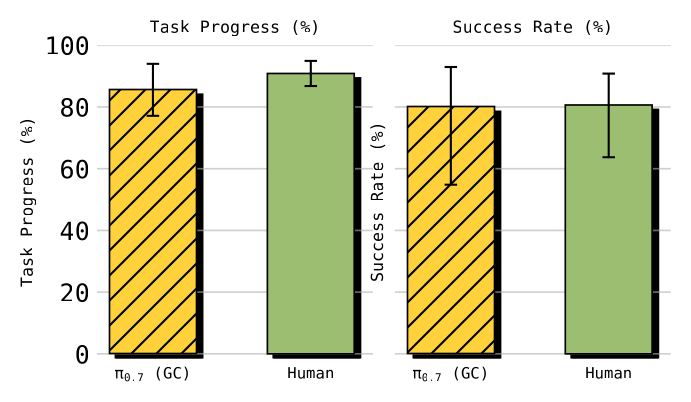 Figure 6:UR5e 叠衣任务上 π₀.₇ (GC) vs 人类操作者的定量对比,性能相当。
Figure 6:UR5e 叠衣任务上 π₀.₇ (GC) vs 人类操作者的定量对比,性能相当。
- 人类对照研究:10 名顶尖(全平台经验前 2%,平均 ~375 小时)操作者,均无 UR5e 叠衣经验(人和策略都"零样本")。
- 人类:task progress 90.9%,success rate 80.6%。
- π₀.₇:task progress 85.6%,success rate 80%。
- 结论:与专家操作者相当。实践意义——灵巧技能可从"易遥操作的低成本平台"迁移到"难采集数据的高负载工业臂"。
- 涌现策略(human_vs_policy):迁移不是简单复制源策略——源机器人用双臂撑袋/倾斜抓取,UR5e 上 π₀.₇ 自发改用单臂 pick-and-place / 垂直抓取,适配目标形态。
4.6 Compositional task generalization & coaching¶
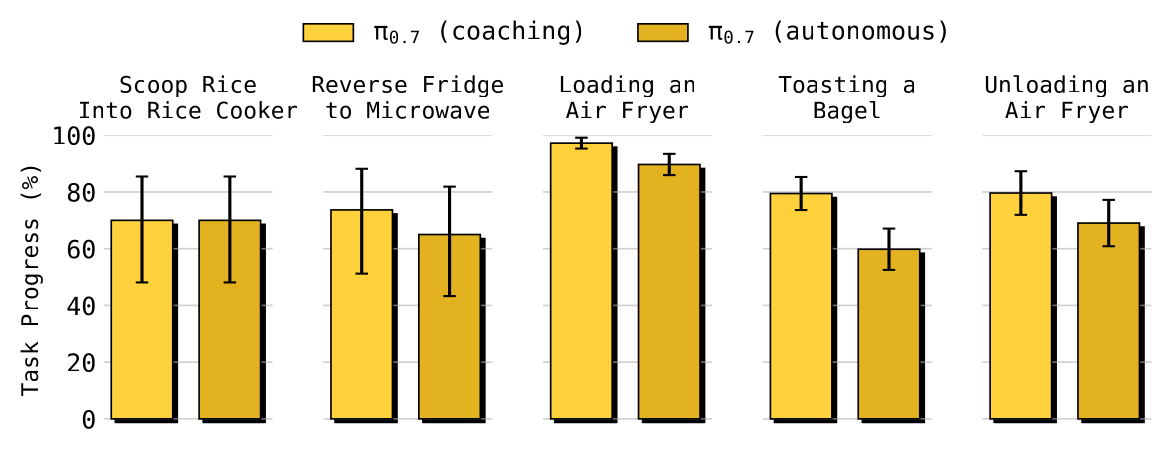 Figure 7:用 coaching 获得新的自主能力。把若干未见任务的 coaching episode 拿来训练 high-level 策略自动 prompt π₀.₇,得到的 π₀.₇ (autonomous) 在 5 个任务上接近 π₀.₇ (coaching) 的表现,全程不采集任何额外 teleoperation 或低层动作数据。
Figure 7:用 coaching 获得新的自主能力。把若干未见任务的 coaching episode 拿来训练 high-level 策略自动 prompt π₀.₇,得到的 π₀.₇ (autonomous) 在 5 个任务上接近 π₀.₇ (coaching) 的表现,全程不采集任何额外 teleoperation 或低层动作数据。
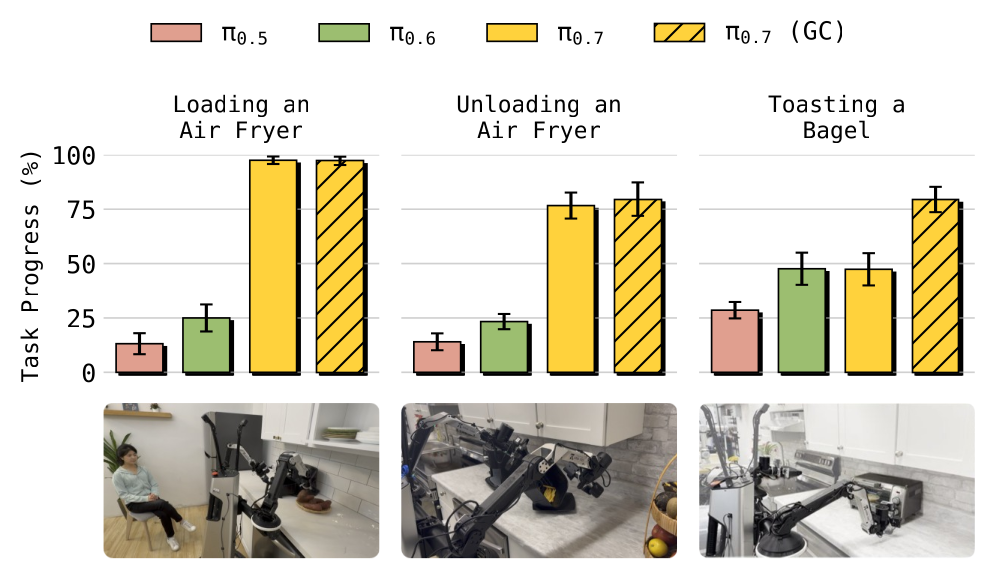 Figure 8:用语言 coaching 完成新长程任务(Loading/Unloading Air Fryer、Toasting a Bagel)。这些任务无任何 action-level 训练数据,π₀.₇ 被 coach 的效果远好于先前模型(后者语言跟随弱、几乎失败),加生成式 subgoal(GC)更佳。
Figure 8:用语言 coaching 完成新长程任务(Loading/Unloading Air Fryer、Toasting a Bagel)。这些任务无任何 action-level 训练数据,π₀.₇ 被 coach 的效果远好于先前模型(后者语言跟随弱、几乎失败),加生成式 subgoal(GC)更佳。
- 短程新任务 out-of-the-box:擦耳机、转风扇、按法压壶、舀米进电饭煲等无专门数据的任务可直接做,语言 vs 图像目标条件效果相当。
4.7 Scaling / mixed-quality 数据消融¶
- 混质量数据:把叠衣数据按质量+速度分 top30/50/80/100% 4 桶,训 with/without metadata 共 8 个模型。without metadata 随数据增多反而变差;with metadata 随数据增多持续提升(即便平均质量下降)。→ diverse prompting 让模型设计更 scalable。
- 任务多样性:去掉任务多样性最高的 20% 数据(w/o most diverse 20%)比去掉随机 20%(w/o random 20%)显著更差 → π₀.₇ 能把高任务多样性数据转化为 compositional 泛化性能。
- 总体泛化幅度:seen 任务成功率常 >90%;unseen 任务或 unseen 任务-机器人组合落在 60–80%。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 方法论而非新架构的贡献:作者明确说不主张新架构,而是"用多样 prompt 把异质/混质量数据变成可用训练信号"的方法论 + 大量实证,这一定位诚实且可迁移。
- 把失败/低质量/自主数据变废为宝:metadata 消歧 + 评测数据复用,既扩大数据又不伤性能,混质量 scaling 曲线(with vs without metadata 分叉)是很有说服力的证据。
- runtime steerability 的工程闭环:dropout 训练 → 任意子集 prompt → CFG → coaching → 用 coaching 数据训 high-level 策略自主化,形成"无需新动作数据即可教新任务"的完整链路。
- 跨 embodiment 的人类对照:把策略与顶尖操作者放在同一"零样本"口径比较,且公开了 protocol(无热身、相同初始构型/时限/评分),是机器人论文里少见的硬对照。
- 推理延迟数据透明:38ms / 127ms / world model 1.25s 等数字给得很具体,便于评估可部署性。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "emergent" 是否名副实? 作者自己在 Discussion 里承认:数据集太大太杂,"无法确定哪些任务真正 seen / unseen",模型可能只是把别处出现过的 skill"remix"。把这种 remix 直接等同于 compositional generalization、并冠以"emergent",更像是规模/数据多样性带来的连续效应,而非 LLM 意义上的相变式涌现。标题里的"Emergent Capabilities"有营销色彩。
- held-out 严谨性存疑:仅排除了"刻意为该任务采集"的数据,但相似 appliance/skill 在人类视频、外部数据、其它任务的副产物里可能大量存在。没有量化"测试指令/任务与训练分布的距离",零样本声明缺乏可证伪的界定。
- steerability 评测主观性:episode quality 是人工 1–5 主观打分、mistake 是"粗标",coaching 由人现场给指令——这些都引入人类先验与实验者自由度。coaching 成功多大程度归功于模型、多大程度归功于会"恰好分解任务"的人,难以分离。
- human-vs-policy 比较口径偏向策略:人类操作者被要求"零样本、无热身、首次尝试 UR5e",这是人类的最不利设定(人稍加练习会大幅提升),而策略已在海量近似数据上训练过。"comparable to experts"在这种口径下证明力有限;且仅 30 trials(10 人 ×3),且只 1 个任务。
- 闭源、不可复现:模型、数据、operator hours、world model 均不公开,5B+14B 规模 + H100 集群 + 自有机器人车队,外部团队无法复现或独立验证任何数字。
- distillation 损失多少能力未量化:声称 out-of-the-box 匹配 RL specialist,但 distillation_results 多以"normalized throughput / task progress"呈现而非绝对 success;通用模型在每个单任务上相对 specialist 的真实损失、以及哪些任务匹配不上,缺乏全面披露。
- operator experience hours 不可获取且定义模糊:"top 2%""~375 小时"无外部基准,operator_experience_hours 图只是内部分布;这条"人类基线"本质上依赖私有劳动力,无法被第三方校准。
- 泛化成功率仍偏低:unseen 任务/组合只有 60–80%,对真实部署(尤其多阶段长程任务的逐阶段乘性失败)而言可靠性不足,论文对长程失败模式的分析较少。
- 大量结果以图(bar/曲线)而非数值表呈现:除人类研究外,正文几乎没有可逐项核对的数值表,难以精确比较 π₀.₅/π₀.₆/π₀.₇ 各任务差距。
- world model 依赖与失败耦合:多个关键结论(Reverse Fridge-to-Microwave、复杂指代、叠衣迁移)依赖 14B world model 生成 subgoal;其 1.25s 延迟 + 8-bit 量化下生成图质量/幻觉对策略的影响、以及 world model 失败时的退化行为未充分评估。
5.3 值得继续探讨的方向¶
- 利用 steerability 做在线适应:作者提出的方向——用更细 coaching 或自主 RL 在测试任务上高效学习,把 60–80% 的零样本成功率往上拉。
- 量化"novelty":发展可证伪的指标衡量测试任务相对训练分布的真实距离,为 compositional/emergent 声明提供严谨界定。
- 解耦 coaching 中的人类贡献:设计实验区分"模型可被任意分解指令引导"与"人恰好给了好分解"。
- subgoal world model 的轻量化:把 1.25s 的生成延迟压低、或蒸馏成更小模型,使 GC 模式可在更高频机器人上实时运行。
- 长程任务可靠性:研究多阶段任务的乘性失败与恢复机制(错误检测、回退、重规划)。
- end-effector vs joint 控制:附录显示先前模型上 EE 控制无明显增益,但在更大 embodiment gap 或 contact-rich 任务上是否值得重新评估。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 关键 baseline / 相关论文:
- π₀ (Black et al., 2024) — flow matching VLA 基础
- π₀.₅ (Black et al., 2025) — high-level subtask 文字、层次化
- π₀.₆ / π₀.₆-MEM — 本文 VLA 架构 + MEM 记忆系统的直接前身
- π*₀.₆ (RL post-trained specialist) — distillation 的能力来源与对照
- FAST (Pertsch et al., 2025) — backbone 的离散 action token 监督
- MEM (Torne et al., 2026) — history/记忆视觉编码器
- BAGEL (Deng et al., 2025) — world model(subgoal 生成)初始化
- SuSIE (Black et al., 2023) — subgoal image 条件思路
- RTC (Black et al., 2025) — real-time action chunking