OpenVLA-OFT: Fine-Tuning Vision-Language-Action Models — Optimizing Speed and Success¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
- 作者: Moo Jin Kim, Chelsea Finn, Percy Liang — Stanford University
- arXiv 编号: 2502.19645 (submitted 2025-02)
- 项目页: https://openvla-oft.github.io
- 关键词: VLA finetuning, parallel decoding, action chunking, L1 regression, FiLM, ALOHA bimanual, LIBERO
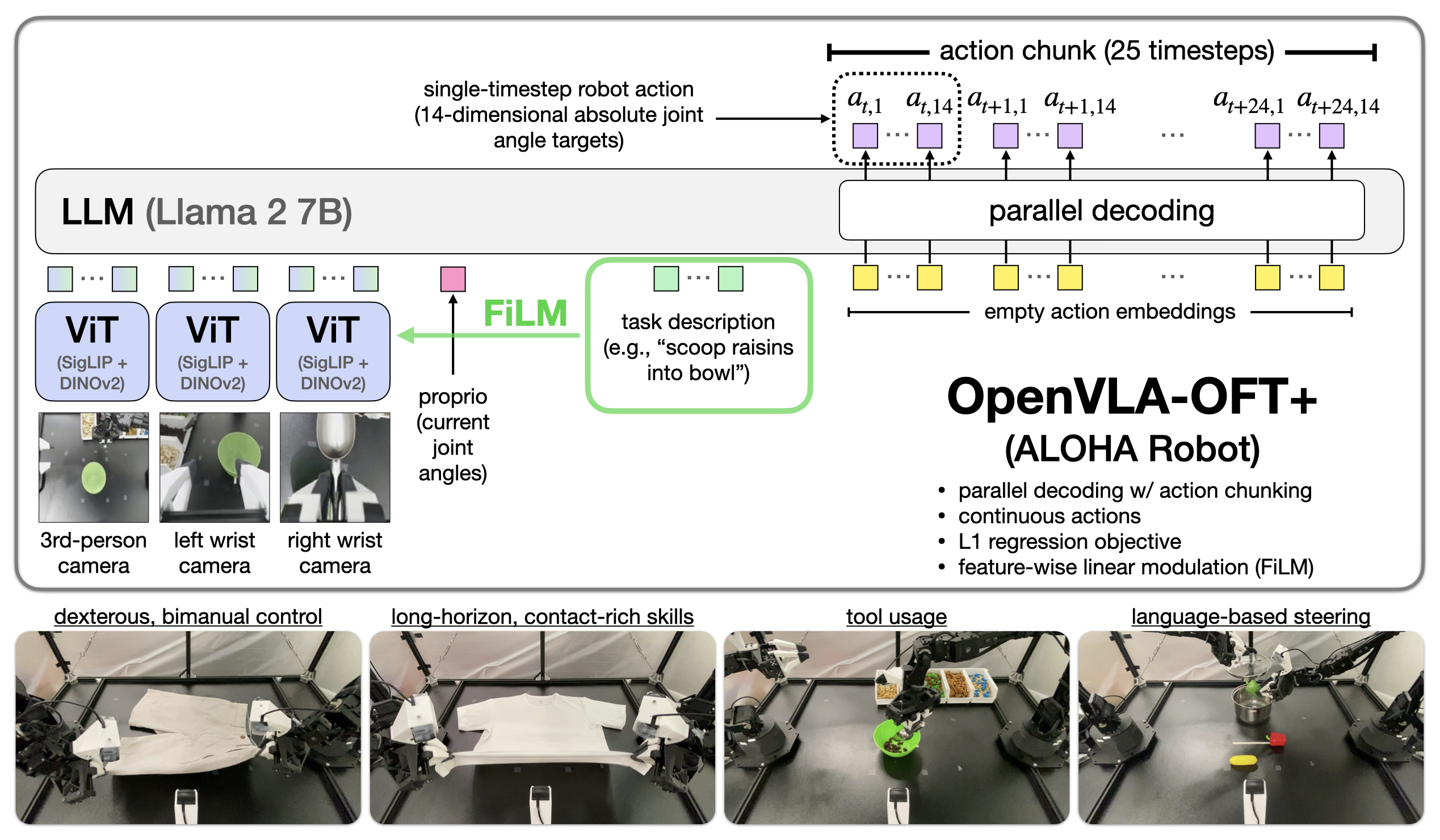 Figure 1:OpenVLA-OFT+ 用 OFT 配方(parallel decoding + action chunking + 连续动作 + L1 regression + FiLM)把单臂 7B OpenVLA 适配到双臂 ALOHA 上跑 25 Hz 高频控制——折衣物、长程灵巧任务、语言 grounding 全过关,且性能超过专门用 bimanual 数据预训练的 π₀ 和 RDT-1B。
Figure 1:OpenVLA-OFT+ 用 OFT 配方(parallel decoding + action chunking + 连续动作 + L1 regression + FiLM)把单臂 7B OpenVLA 适配到双臂 ALOHA 上跑 25 Hz 高频控制——折衣物、长程灵巧任务、语言 grounding 全过关,且性能超过专门用 bimanual 数据预训练的 π₀ 和 RDT-1B。
2. 文章介绍¶
2.1 解决的领域和问题¶
VLA 的 finetune 配方。OpenVLA / π₀ / RDT 这些大 VLA 在 OXE 之类的混合数据集上预训练之后,下游用户必须 finetune 到自己的机器人/任务上才能用。但 finetune 时到底该用什么 action decoding 方式、什么 action 表示、什么 loss——这个 design space 几乎没人系统对比过,大多数工作直接沿用 base model 的预训练配方(OpenVLA 用 discrete-token autoregressive、π₀ 用 flow matching),但这未必是 finetune 阶段最优。
OFT 想做的事:以 OpenVLA 为 base,系统对照 3 个轴——decoding strategy(autoregressive vs parallel)× action representation(discrete vs continuous)× learning objective(next-token vs L1 regression vs diffusion)——得到一个新的 finetune 配方,让 OpenVLA 不仅速度快 26×,性能也反超 π₀ 和 RDT-1B(用别人的 base model 跑别人擅长的任务)。
2.2 Motivation¶
OpenVLA 的根本短板:autoregressive 离散 token 生成太慢(3-5 Hz),没法上 25-50 Hz 的双臂高频控制;而且 chunk 一次 7K 个 token(K=action chunk size)的延迟在双臂上接近 1 秒,根本不能用。
之前的 fix(FAST 等更好的 tokenizer)能加速 2-13×,但 chunk 间延迟仍然 ~750ms,对 25Hz 双臂仍不够。
OFT 的洞察:不要修补 autoregressive,直接换成 parallel decoding。把因果 mask 改双向、把 7D 动作的输入位置全填空 embedding、一次 forward 出整个 action chunk。这条路的代价是失去 autoregressive 的「next-token 概率链」表达能力,但作者用实验证明在 finetune 场景下毫无性能损失,反而更好。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Autoregressive discrete VLA finetune | OpenVLA (LoRA / full FT) | 3-5 Hz 推理;双臂任务表现不可靠 |
| Better tokenizer | FAST、MiniVLA | 加速 2-13× 但 chunk 间仍 750ms 延迟 |
| Diffusion VLA | π₀、RDT-1B | 多步去噪,部署成本高;configure 复杂 |
| Diffusion Policy (scratch) | DP | 没用 VLM 先验,对多任务/语言 grounding 弱 |
2.4 论文解决方案(一句话)¶
把 OpenVLA 的 autoregressive 离散 token + next-token CE 配方换成 parallel decoding(双向 attention 一次出整个 chunk)+ continuous action(MLP head 直接出连续值)+ L1 regression loss(再可选叠 FiLM 加强语言 grounding),LIBERO 平均 76.5%→97.1%、推理速度 26× 提升、ALOHA 双臂上反超 π₀ 和 RDT-1B 最多 15 个点(绝对)。
2.5 与前序工作的关系¶
- Base model 是 OpenVLA(同一作者 Moo Jin Kim)——本质上是同一作者自我修订之前的设计。
- Parallel decoding 思路来自 NLP(BERT/BART 那类 non-autoregressive 生成),但 VLA 里第一个系统验证。
- Action chunking 从 ACT(Zhao et al. 2023)借;L1 regression 也是 ACT 的目标函数。
- Diffusion 对照 复刻 Diffusion Policy(Chi et al. 2023),50 步训练,inference 时 DDIM 可调步数。
- FiLM 用 Perez et al. 2018 的 feature-wise linear modulation,把语言 embedding 投成 (γ, β) 调制视觉特征。
- ALOHA 实验和 ACT 原 setup 一致(25Hz 控制频率从原 50Hz 降一半为了加速训练)。
3. 方法介绍¶
3.1 三个 design 维度的实验对照¶
 Figure 2:OFT 研究的两个核心维度。左:autoregressive(每 token 依赖前一个 token,causal mask,D 次串行 forward)vs parallel decoding(bidirectional attention,单 forward 出全部 action)。右:discrete action token(256-bin 离散 + softmax + next-token CE)vs continuous action(MLP head 直接出连续值 + L1 / diffusion loss)。原 OpenVLA 配方 = 左侧 + 右上。
Figure 2:OFT 研究的两个核心维度。左:autoregressive(每 token 依赖前一个 token,causal mask,D 次串行 forward)vs parallel decoding(bidirectional attention,单 forward 出全部 action)。右:discrete action token(256-bin 离散 + softmax + next-token CE)vs continuous action(MLP head 直接出连续值 + L1 / diffusion loss)。原 OpenVLA 配方 = 左侧 + 右上。
三轴: 1. Action generation strategy:autoregressive vs parallel decoding; 2. Action representation:discrete (256 bins) vs continuous(连续值); 3. Learning objective:next-token CE / L1 regression / conditional diffusion。
3.2 Parallel decoding + action chunking¶
具体实现: - 输入:把 K 个时间步的「空 action embedding」插进 decoder 输入序列里; - mask:causal mask 改成 bidirectional(这些 empty embeddings 之间相互看,也看到 image + language); - 输出:一次 forward 出全部 KD 个 action 值(D=7 单臂或 14 双臂,K=8 LIBERO / 25 ALOHA)。
额外好处:parallel decoding 不只让 generation 加速 4×(不用 7 次 sequential pass),加上 chunking 后吞吐量 26×;且 chunking 本身已被证明(liu2024bidirectional, ross2011reduction)能捕捉时序依赖、减少 compounding error,所以速度和性能双赢。
3.3 连续动作头 + L1 regression¶
把 decoder 最后一层 hidden state 直接过一个 MLP action head 出 K×D 维连续动作,loss 是 L1:
L = mean |a_pred - a_gt|
(替代离散 256-bin + softmax + CE)
也对照了 conditional diffusion(DDPM 50 步训练 + DDIM 推理):性能持平 L1(LIBERO-Long 91.1% vs 90.7%),但 inference 慢非常多(50 步 DDIM latency 1.9 秒 / 1 步 0.07 秒但成功率掉到 0%)。
结论:在 7B OpenVLA 这种大主干上,L1 regression 就够,diffusion 的多模态表达能力收益边际。
3.4 额外输入处理¶
为了上 ALOHA(3 个相机、14D 关节状态),加了: - 腕部相机 + 顶部相机 + 左 wrist:每个走 OpenVLA 原 DINOv2+SigLIP,patch embedding 共享 projector(256 patch × 3 view = 768 patch token); - Proprioception:14D 关节角过单独 MLP 投到 1 个 embedding; - 所有 token 按序列拼接送入 Llama 2。
3.5 FiLM 加强语言 grounding(OFT+)¶
ALOHA 上 OpenVLA-OFT 单独跑发现语言 grounding 失效——"scoop raisins" vs "scoop almonds" 在视觉相似时会忽略语言指令。原因是多视角输入下视觉 token 数量爆炸(768 个 patch),语言 token 被淹没。
FiLM 修复:
- 把语言 token 平均成 mean embedding x;
- 投影成 (γ, β);
- 在每个 ViT block 的 self-attention 之后、FFN 之前,对 patch embedding 做 F̂ = (1+γ) ⊙ F + β。
关键细节:γ, β 是 D_ViT 维(hidden-dim 级别)而非 token-level——每个 hidden unit 一个 scale/shift,跨所有 patch 共享(类似 CNN 里 FiLM 跨空间共享 channel-wise 参数)。这一选择实证比 token-level FiLM 强很多。
OFT + FiLM = OFT+。
3.x Implementation Details¶
| 项目 | LIBERO | ALOHA |
|---|---|---|
| Action chunk K | 8 | 25 |
| Action dim D | 7(单臂) | 14(双臂) |
| 输入相机 | 1 第三视角(+ optional wrist) | 1 顶部 + 2 腕部 |
| Proprio | optional | 14D 关节 |
| Finetune | LoRA | LoRA |
| 训练步 | 50-150K(L1)/ 100-250K(diffusion) | 50-150K |
| Batch | 64-128 (8 A100/H100) | 32 (8 A100/H100-80GB) |
| 推理 throughput | 109.7 Hz (LIBERO L1) / 71.4 Hz (LIBERO+wrist) | 77.9 Hz |
| 推理 latency | 0.073s | 0.321s(3 相机更长) |
| 控制频率 | — | 25 Hz |
4. 结果对比¶
4.1 LIBERO 主表(96.1%-97.1% SOTA)¶
| 输入 / 设定 | 方法 | Spatial | Object | Goal | Long | 平均 |
|---|---|---|---|---|---|---|
| 第三视角 + 语言 | Diffusion Policy (scratch) | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Octo (FT) | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 | |
| OpenVLA (FT) | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 | |
| OpenVLA + PD+AC | 91.3 | 92.7 | 90.5 | 86.5 | 90.2 (+13.7) | |
| OpenVLA + PD+AC + Cont-Diffusion | 96.9 | 98.1 | 95.5 | 91.1 | 95.4 | |
| OpenVLA-OFT (PD+AC+Cont-L1) | 96.2 | 98.3 | 96.2 | 90.7 | 95.3 | |
| 3-view + wrist + proprio | π₀ + FAST (FT) | 96.4 | 96.8 | 88.6 | 60.2 | 85.5 |
| π₀ (FT) | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 | |
| OpenVLA-OFT (Cont-L1 + wrist+proprio) | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
核心读法: - 单独加 PD+AC 就把 OpenVLA 从 76.5% 拉到 90.2%(+13.7pp)——chunking 是大头; - 连续动作(L1 或 diffusion)再加 5pp; - L1 vs Diffusion 几乎打平(95.3 vs 95.4); - 加 wrist 相机 + proprio 再 +2pp; - 97.1% 完全反超 π₀ 的 94.2%——而 π₀ 是更新更大 base 模型 + flow matching 训练。
4.2 LIBERO 推理效率¶
| 方法 | Throughput (Hz) | Latency (s) | LIBERO-Long SR |
|---|---|---|---|
| OpenVLA (原) | 4.2 | 0.240 | 53.7 |
| + PD only | 15.9 | 0.063 | — |
| + PD+AC | 108.8 | 0.074 | 86.5 |
| + PD+AC, Cont-L1 | 109.7 | 0.073 | 90.7 |
| + PD+AC, Diffusion (T=50) | 4.2 | 1.907 | 91.1 |
| + PD+AC, Diffusion (T=10) | 19.3 | 0.415 | 91.0 |
| + PD+AC, Diffusion (T=5) | 35.1 | 0.228 | 90.0 |
| + PD+AC, Diffusion (T=1) | 109.4 | 0.073 | 0.0 ❌ |
Diffusion T=10 时仍能保住 91%,但 latency 是 L1 的 5.7×。L1 在 7B 主干上是 Pareto 最优——速度匹敌 + 性能持平。Diffusion T=1 直接崩到 0,说明它的多步去噪是真必要不能省。
4.3 ALOHA 双臂¶
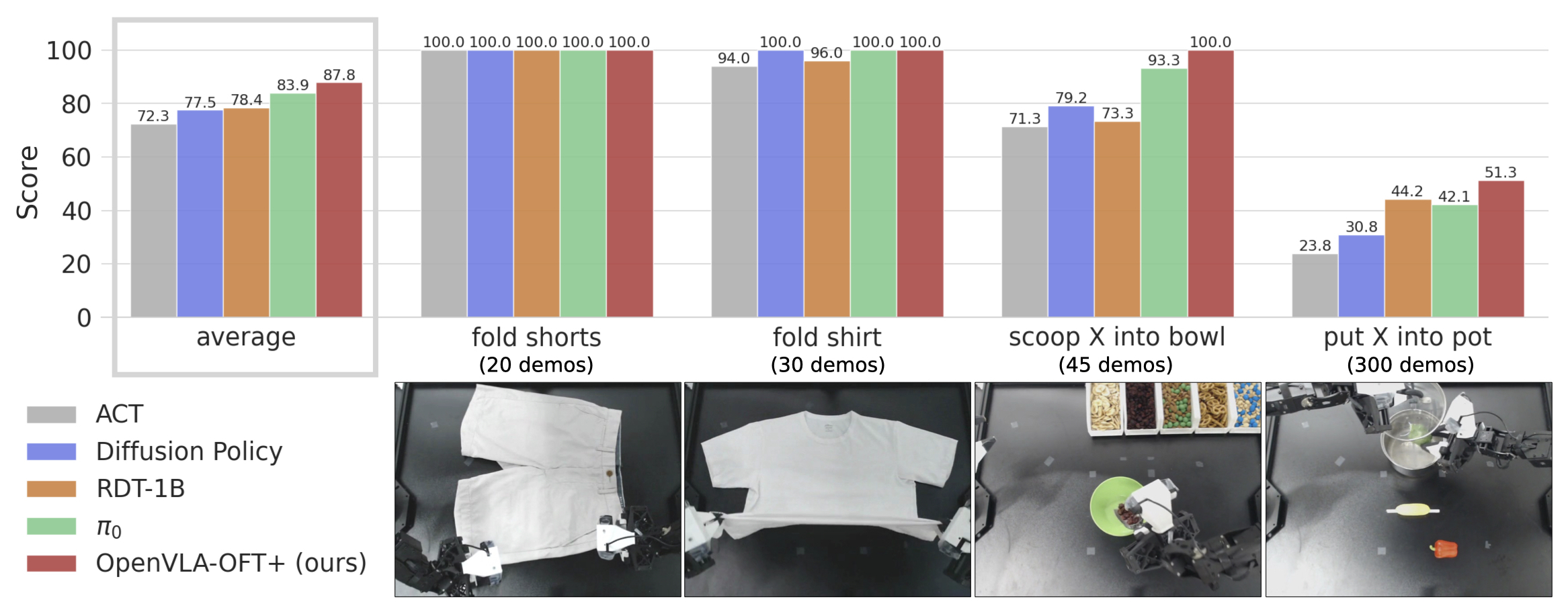 Figure 3:ALOHA 上四个任务(fold shorts、fold shirt、scoop X into bowl、put X into pot)。OpenVLA-OFT+(最右橙色)最高,超过专门双臂预训过的 RDT-1B 和 π₀。fold shirt 这个长程接触丰富任务上优势最明显。
Figure 3:ALOHA 上四个任务(fold shorts、fold shirt、scoop X into bowl、put X into pot)。OpenVLA-OFT+(最右橙色)最高,超过专门双臂预训过的 RDT-1B 和 π₀。fold shirt 这个长程接触丰富任务上优势最明显。
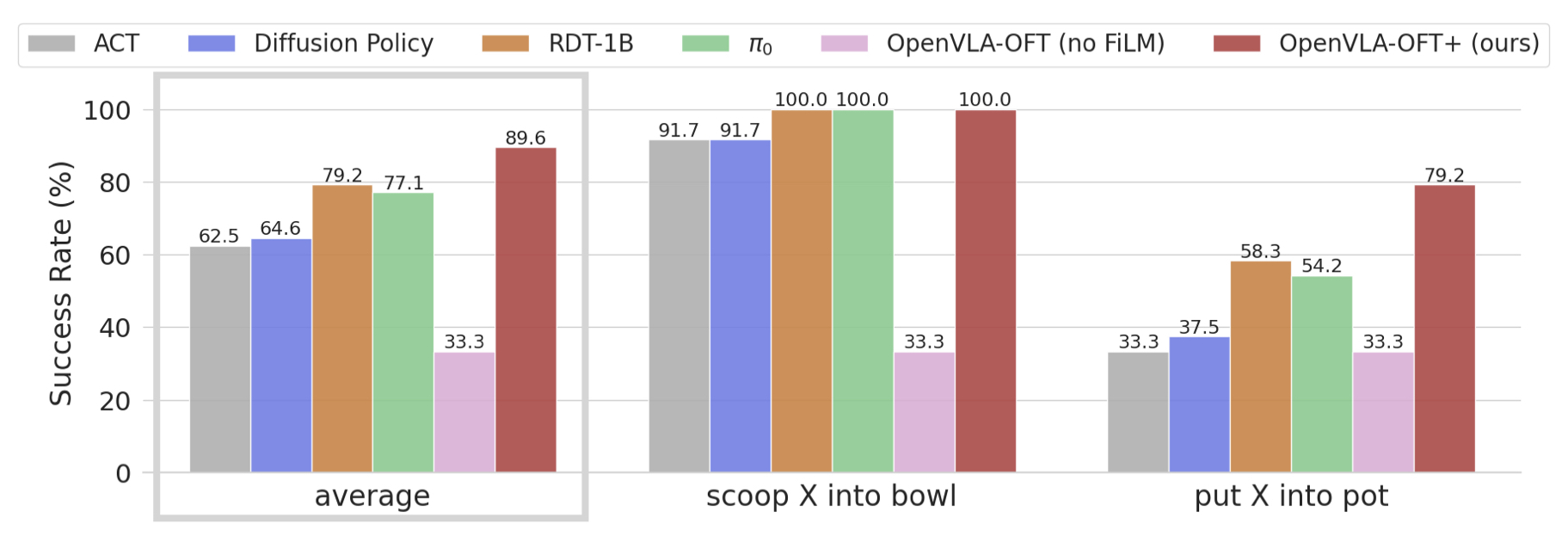 Figure 4:语言 grounding(接近正确目标物体的成功率)。ACT/DP 接近随机猜(~33%),RDT/π₀ 中等,OpenVLA-OFT+ 最强。但去掉 FiLM 后 OFT 也掉到 33% — FiLM 是必须的。
Figure 4:语言 grounding(接近正确目标物体的成功率)。ACT/DP 接近随机猜(~33%),RDT/π₀ 中等,OpenVLA-OFT+ 最强。但去掉 FiLM 后 OFT 也掉到 33% — FiLM 是必须的。
| 方法 | 平均聚合分数 | 备注 |
|---|---|---|
| ACT (scratch) | 最低 | 动作不精细 |
| Diffusion Policy (scratch) | 中等 | put X into pot 上 scaling 差 |
| RDT-1B (FT) | 中等 | 语言好但 closed-loop 反馈差(不会修错) |
| π₀ (FT) | 较强 | 动作流畅、能 recover from grasp failure |
| OpenVLA-OFT+ | 最高 | + 15pp over best baseline |
ALOHA 推理:OFT+ 77.9 Hz、π₀ 291.6 Hz、ACT 432.8 Hz——OFT+ 比 ACT/DP/π₀ 慢但仍远超 25Hz 控制要求,所以这点速度差异不重要。
4.4 关键消融¶
| Configuration | LIBERO-Long | 备注 |
|---|---|---|
| Full OFT recipe | 94.5 | wrist+proprio version |
| - 去 OpenVLA pretrain(直接 FT Prismatic) | -5.2pp | base model 预训仍有用 |
| - 去 FiLM(ALOHA scoop/put 任务) | 语言 grounding 掉到 33% | FiLM 必需 |
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 三轴清晰的 ablation 设计(decoding × representation × objective)+ 逐步累积消融(PD+AC +13.7 → +Cont-L1 +5 → +inputs +2),让每个 design 选择的贡献定量可见。这种「先沿着主轴扫,再合成最优配方」的论文结构是 finetune 类研究的范式。
- Parallel decoding 是真本事:单独 PD(不加 chunking)就让 latency 从 240ms 降到 63ms(4×),且不掉点。这反驳了「autoregressive 表达能力更强所以应该串行」的直觉——在大模型 + 短序列 + finetune 场景下,bidirectional 一次出全部完全够用。
- L1 vs diffusion 在 7B 主干上几乎打平(95.3 vs 95.4)——挑战了 Octo / π₀ 的「VLA 必须用 diffusion」共识。原因是主干容量足够大时,简单 loss 就能模出多任务分布,diffusion 的多模态表达力收益边际。这是论文最重要的「common belief 被推翻」的实证发现。
- OpenVLA-OFT+ 反超 π₀ 和 RDT-1B——而后两者都用了 bimanual 预训数据,OpenVLA base 完全没见过双臂。这证明 「good finetune 配方 > 更大 / 更对齐的预训数据」,对工业部署是个重要信号(不一定要追最新最贵的 base model)。
- FiLM 的实现细节(hidden-dim level 而非 token-level)是一个真细节——naive 实现会失败。把这个细节写到方法里且实证消融了,比很多论文藏在 appendix 强。
- 诊断 RDT-1B 失败原因很犀利:rollout 显示 RDT 错过 bowl 后继续往空中倒——over-rely on proprio over visual。π₀ 反而能 recover from grasp failure。这种质性失败模式分析对理解 VLA 行为很有价值,超越了「平均成功率」一张数字图。
- 诚实承认 limitation:discrete vs continuous 在大主干上的优势可能依赖容量,pretrain 阶段是否能换成 OFT 配方未验证,多模态 demo 数据下 L1 可能不如 diffusion。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "反超 π₀ 14.6%" 的 base model 比较不严格:π₀ 用 flow matching 训练、用更大更新的预训数据,OFT 用 OpenVLA(更老 base)+ 更优 finetune 配方。这两个变量纠缠——不能简单说"OFT 配方 > π₀ 配方",更准确的说法是"在 finetune 阶段 OFT 配方很强、能把弱 base 拉到反超强 base"。如果把 OFT 配方直接套到 π₀ 上呢?没做。
- LIBERO 是 simulation benchmark,且任务是分散单任务 finetune:每个 task suite 独立 finetune 50-150K 步,500 demo——这是 per-suite finetune 而非真 multi-task。π₀ / RDT 的多任务 generalist 优势在这种 setup 下被中和。LIBERO 96% 是真高但不是 generalist 上限。
- ALOHA 只 4 个任务,且评估用主观 rubric 部分完成度评分:fold shorts / shirt 这种长程任务靠 rubric scoring 而非二元 success。论文承认有这个细节但没贴 rubric 设计的 inter-rater agreement,分数差距 15pp 的统计显著性偏弱。
- FiLM 失效模式分析有限:去 FiLM → 33% 语言 grounding(=随机选)证明 FiLM 在 ALOHA 必须,但LIBERO 上不用 FiLM 也 95%+。这个差异作者只在 Limitation 部分承认「源头不明」——但其实是因为 LIBERO 单一第三视角 vs ALOHA 三视角导致 visual token 数量差异,patch token 增多导致语言信号被稀释。这是个值得做 dedicated ablation 的发现,但论文没深挖。
- L1 vs Diffusion 的「打平」结论可能跟训练步数有关:diffusion 训了 100-250K 步("converge slower"),L1 只训 50-150K。两者比较的 budget 不匹配——如果 diffusion 训更久会不会再涨?没确认。
- 没和 FAST/MiniVLA 同台比较 throughput:论文反复说"OpenVLA-OFT 26× faster than OpenVLA",但 FAST 自身也号称对 OpenVLA 加速 5×、且保持 token-level VLA 的能力。OFT 把 throughput 跟原版 OpenVLA 比是低 bar——和 FAST 同台对比的话差距会缩窄。
- ALOHA 训练量被夸大成「fine-tuning」:fold shirt 30 demos、put X into pot 300 demos——后者已经是中等规模数据集了。把这叫 finetune 有点宽泛,更像 small-scale supervised learning + good initialization。
- L1 regression 对多模态 demo 的 limitation 是真问题但被淡化:作者在 Limitations 提了一句,但所有实验都是 focused single-strategy demo(人为收集),所以这个 limitation 在 benchmark 上看不到。实际部署里 demo 来自不同标注员/不同策略时,L1 的 mean-collapse 可能成为瓶颈。
- 27 epoch 训练数 + 50-150K 步 finetune:放在一起,OFT 总训练量并不小。论文标榜的「simpler than diffusion」主要是算法 simpler,训练成本并没省。
- PD+AC 单独 +13.7pp 这个增益里 chunking 的贡献被低估:原 OpenVLA 没 chunking,加上 chunking 哪怕保留 autoregressive 也会大幅提升(因为减少 compounding error)。表里没有「autoregressive + chunking」这个中间格子来分离两个贡献。
5.3 值得继续探讨的方向¶
- 把 OFT 配方反过来用到 π₀ 上:当前 π₀ 用 flow matching 训整套——如果把 finetune 阶段换成 OFT 的 PD+AC+L1,是不是 π₀ 性能再涨?这是 OFT 论文回避了的最大问题。
- OFT 配方用于 pretraining:作者在 Limitations 承认这是未验证的。如果 pretrain 也用 L1 而非 flow matching/diffusion,能 scale 到 OXE 这种异构混合数据吗?我的直觉是不行(多模态需要 expressive head),但需要实证。
- FAST + OFT 是否互补:FAST tokenizer 是 token-level 的加速,OFT 是 decoding-level 的加速——两个方向正交,理论上可以叠加?
- L1 失效模式的实证:故意收集多模态 demo(同任务两种策略),看 L1 vs diffusion 的表现差距——这是论文该做但没做的硬实验。
- 大规模 multi-task generalist:当前 per-suite finetune,能否在 OXE 全集上重新 multi-task pretrain?需要重新 launch base run,工程量大。
- OFT 配方 + 双臂预训:OpenVLA-OFT+ 在 ALOHA 上反超 π₀ 是「弱 base + 强 finetune」赢「强 base + 弱 finetune」——如果把 OpenVLA base 也加上 bimanual 数据预训呢?大概率再加几个点。
- FiLM 跟 cross-attention / language-attention 的对比:FiLM 是 multiplicative gating 的 cheap 实现,但 cross-attention 才是 LLM 标准。后续工作(π₀.₆ 的 advantage conditioning 是某种 FiLM 类似物)值得对照。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页: openvla-oft.github.io
- 关键相关论文:
- OpenVLA (kim2024openvla) — base model,同作者前作;本库有 OpenVLA 笔记
- ACT (zhao2023learning) — action chunking + L1 regression 的源头;ALOHA setup 来源
- Diffusion Policy (chi2023diffusion) — 主要 baseline,连续动作 + diffusion 对照
- π₀ / π₀-FAST (black2024pi0 / pertsch2025fast) — 主要竞争者;本库有 π₀ 笔记、FAST 笔记
- RDT-1B (liu2024rdt) — ALOHA 上的 bimanual 预训 baseline
- FiLM (perez2018film) — 语言 grounding 模块
- Octo (team2024octo) — 早期 baseline;本库有 Octo 笔记
- MDT / Seer / DiT Policy — LIBERO 上的其他 SOTA