LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs
- 作者: Jihwan Kim¹², Nikhil Parthasarathy¹, Danfeng Qin¹, Junhwa Hur¹, Deqing Sun¹, Bohyung Han¹², Ming-Hsuan Yang¹, Boqing Gong¹
- ¹ Google
- ² Seoul National University
- arXiv 编号: 2605.17260 (submitted 2026-05)
- 项目主页: jjihwan.github.io/projects/LiteFrame
- 关键词: Video LLM, efficient vision encoder, token compression, knowledge distillation, ViT, temporal convolution, long-form video understanding
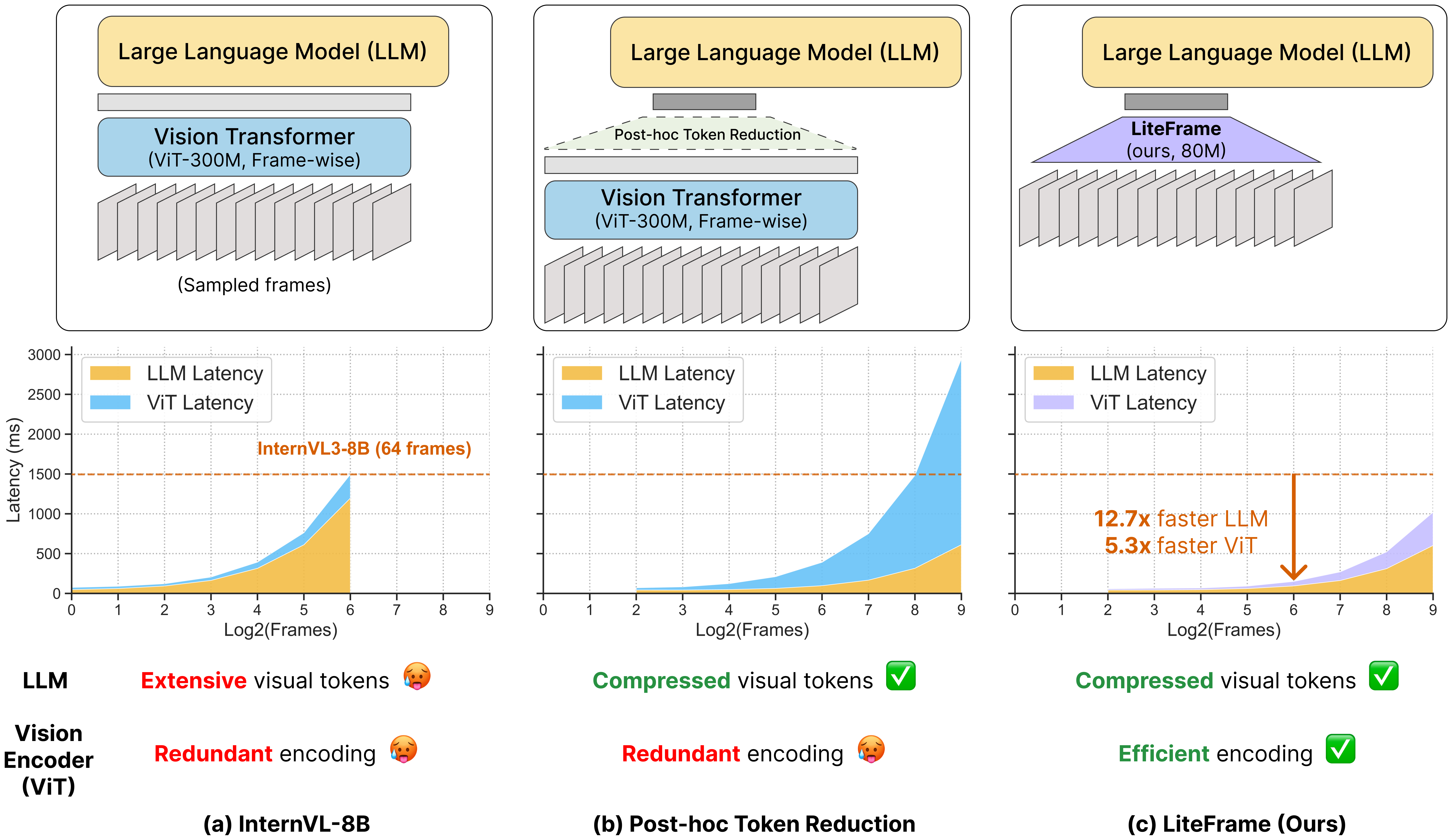 Figure 1:经典 Video LLM (a) 受 LLM 二次复杂度限制只能跑 ~64 帧;post-hoc token reduction (b) 缓解 LLM 但把瓶颈推给 ViT,帧数变多 latency 反而爆炸;LiteFrame (c) 把压缩"内化"进一个轻量 ViT,让 LLM 与 ViT 同时降负载——12.7× 更快的 LLM prefill、5.3× 更快的 ViT 编码(64 帧 vs InternVL3-8B)。
Figure 1:经典 Video LLM (a) 受 LLM 二次复杂度限制只能跑 ~64 帧;post-hoc token reduction (b) 缓解 LLM 但把瓶颈推给 ViT,帧数变多 latency 反而爆炸;LiteFrame (c) 把压缩"内化"进一个轻量 ViT,让 LLM 与 ViT 同时降负载——12.7× 更快的 LLM prefill、5.3× 更快的 ViT 编码(64 帧 vs InternVL3-8B)。
2. 文章介绍¶
2.1 解决的领域和问题¶
研究领域是Video LLM 长视频理解的效率瓶颈。当前以 InternVL3、Qwen-VL、LLaVA 为代表的多模态 LLM 由 "ViT 逐帧编码 → projector → LLM 推理" 三段式构成,每多一帧两端的开销都同步增长。社区主流的"extract-and-reduce"路线(ToMe、LLaVA-PruMerge、FastVID、PruneVid …)默认 LLM 二次复杂度是唯一瓶颈,因此保持 frozen 大 ViT、在 ViT 输出端做 post-hoc token reduction。
作者的核心观察:当 post-hoc 压缩比足够大(例如 16×)时,ViT 的逐帧成本反而变成新的瓶颈——因为 ViT 的延迟与帧数线性增长,而它的 per-frame 计算并没有减少。这道"压缩天花板"使得现有方法在长视频(hundreds-of-frames)场景下无法继续在 latency-accuracy 帕累托前沿前进。
2.2 Motivation¶
- 长视频准确率与帧数大致呈对数增长(Fig. frame_scaling)。InternVL3 在 64 帧后基本被 context length 卡死,无法继续 scale。
- 一旦用 WAP 把每帧 token 数从 256 降到 16(16×),帧数预算就可以放大到 512,准确率单调提升。
- 但 post-hoc 压缩只解放了 LLM 的 prefilling,ViT 还是按 256 tokens/frame 全量算——一旦 LLM 不再是瓶颈,ViT 的"地板成本"暴露出来。
- 那为什么不直接训一个内部就压缩 token 的轻量 ViT?这正是 LiteFrame 的切入点。
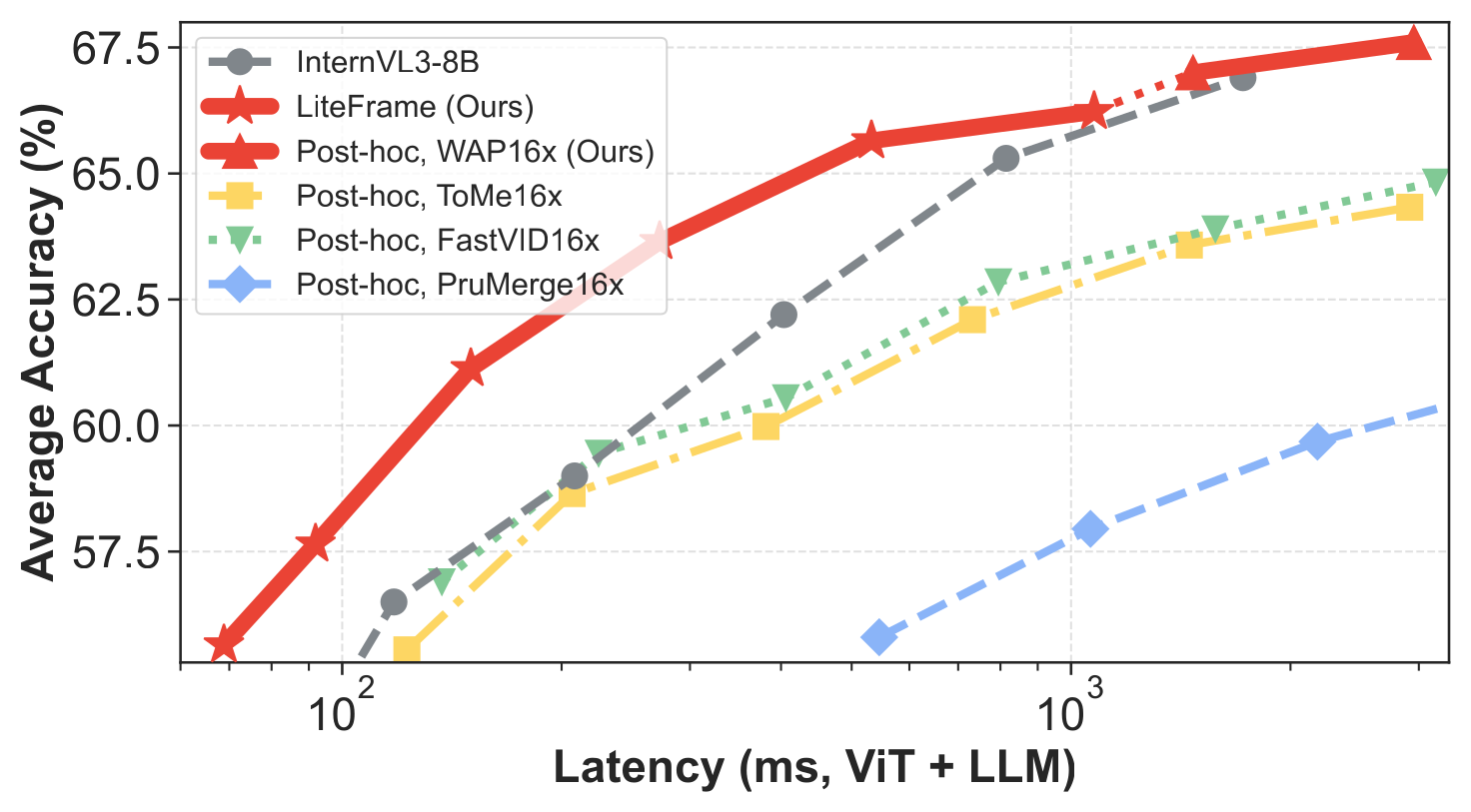 Figure 2:在 Video-MME(含/不含字幕)+ MLVU + LongVideoBench 的平均准确率 vs 端到端 latency(log 轴)。红星 LiteFrame 把帕累托前沿整体往左上推;红三角 WAP 表明即便不重新训练,把 InternVL3-8B 的 ViT 输出 post-hoc 做 WAP 也已经强过 ToMe / PruMerge / FastVID 等同行。
Figure 2:在 Video-MME(含/不含字幕)+ MLVU + LongVideoBench 的平均准确率 vs 端到端 latency(log 轴)。红星 LiteFrame 把帕累托前沿整体往左上推;红三角 WAP 表明即便不重新训练,把 InternVL3-8B 的 ViT 输出 post-hoc 做 WAP 也已经强过 ToMe / PruMerge / FastVID 等同行。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Post-hoc token reduction (空间) | LLaVA-PruMerge, VisionZip, DyMU | 只压 LLM 端,每帧仍需走完整 ViT;attention/匹配打分破坏时空连续性 |
| Post-hoc token reduction (时空) | FastVID, DyCoke, PruneVid, HoliTom | 同样不省 ViT;time merge 也会破坏 spatial layout |
| Query-guided pruning | FastV, PyramidDrop, LongVU, TopV | 依赖 query–token attention,long-context 下 attention 信号本身就被稀释 |
| Edge-efficient ViT (image-centric) | MobileNet-v5, FastVLM (FastViTHD) | 只针对单图空间维度压缩,未利用帧间冗余 |
| Encoder-free video VLM | Video-Panda | 用时空 alignment block 取代 ViT,但 token 流仍然密集,瓶颈又回到 LLM |
| Pre-ViT 选择性输入 | AutoGaze (NVILA 系) | 在 ViT 前加 auxiliary 模块(VideoViT + 自回归 decoding),引入 3.0 秒级辅助开销 |
2.4 论文解决方案(一句话)¶
把"WAP 时空池化 + 轻量 ViT-Base + DW 1D 时序卷积"打包成 Compressed Token Distillation 的预测目标 + 学生架构,再用 LoRA-LMA 做语言对齐,让一个 87M 的视频编码器同时干掉 ViT 和 LLM 两端的 scaling 墙。
2.5 与前序工作的关系¶
- Teacher / baseline: InternViT-300M(InternVL3-8B 的视觉编码器,304M、24 层 ViT-Large)。直接复用其 LLM(InternLM-8B)做下游对齐。
- WAP 的来源: 受
wen2025token和liao2025vtcbench启发——他们已经发现 simple average pooling/downsampling 反而比复杂 ToMe / PruMerge 更稳。LiteFrame 在 average pooling 上加了 cls-token 注意力加权,演化成 WAP。 - DW temporal conv 的来源: 深度卷积本身不新(MobileNet 家族),文章把它移植到 ViT-Base,作为 spatial-attention 之间的 "时序交互层",并在 4/8 层后插入 strided DW conv 做时空 downsample。
- 同代竞品: 直接对标的是 AutoGaze (2026)——同样想同时解决 ViT 与 LLM 的瓶颈,但走的是 "ViT 之前先选 patch" 的路线,结果引入额外的 VideoViT + 自回归选择模块,反而比 baseline 还慢。
3. 方法介绍¶
3.1 形式化与整体训练框架¶
给定视频帧序列,teacher 编码器输出 \(T(x) = Z_T \in \mathbb{R}^{N \times D}\)(每帧 256 tokens × 1024 dim)。学生输出 \(S_\theta(x) = Z_S \in \mathbb{R}^{(N/r) \times D}\),目标压缩率 \(r = 16\)。
定义基于 WAP 的投影算子 \(\mathcal{P}(\cdot)\),则训练目标是
随后 LMA 阶段冻结大部分参数,用 LoRA 在 LLM 上做指令 / VQA 微调,保留 LLM 推理能力同时学一个新的对齐空间。
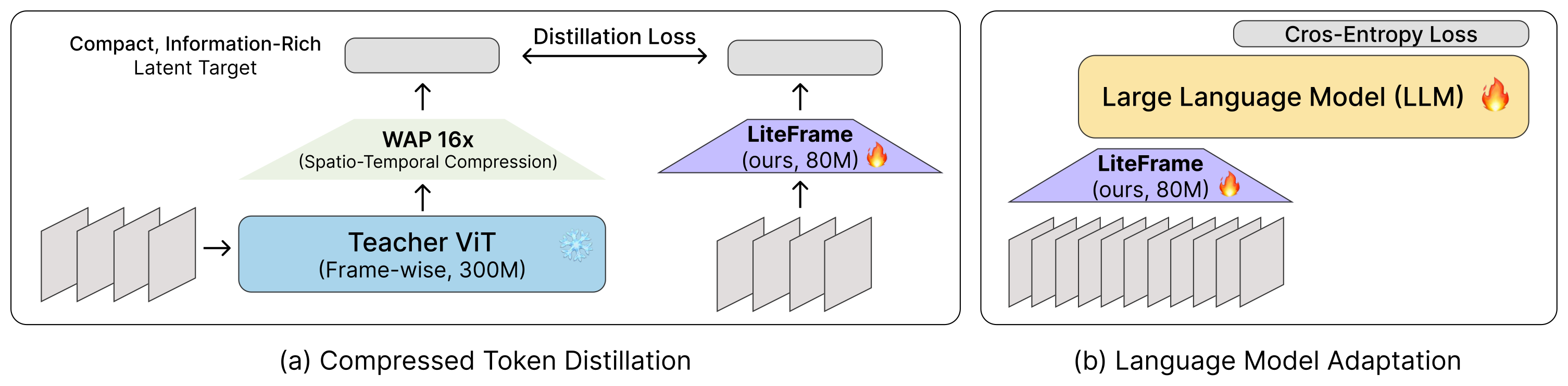 Figure 3:(a) CTD —— teacher 走 frozen 大 ViT 后用 WAP 压成 16×16 → 16×4×4 的紧致 latent,学生(87M ViT-Base + DW 时序卷积)直接拟合这个目标空间。(b) LMA —— 学生 + LoRA-LLM 用 (video, text) 监督端到端 fine-tune,把 latent 推到 LLM 真正能用的子流形上。
Figure 3:(a) CTD —— teacher 走 frozen 大 ViT 后用 WAP 压成 16×16 → 16×4×4 的紧致 latent,学生(87M ViT-Base + DW 时序卷积)直接拟合这个目标空间。(b) LMA —— 学生 + LoRA-LLM 用 (video, text) 监督端到端 fine-tune,把 latent 推到 LLM 真正能用的子流形上。
3.2 Weighted Average Pooling(WAP)—— 既是 baseline 也是 teacher target¶
把特征张量 \(\mathbf{X} \in \mathbb{R}^{T \times H \times W \times C}\) 按非重叠 spatio-temporal block \(\Omega_{u,v,s}\) 切分到目标分辨率 \((t,h,w)\)。每个 block 内的压缩 token 为
也就是用每帧的 cls token 作为 query,对 block 内 patch token 做注意力加权求和。文章主实验里用 \((t,h,w)=(4,2,2)\)(4× 时间 × 4× 空间 = 16× 总压缩)。
在 InternVL3-8B 上做 frozen 后处理,WAP 已经超过 Average / Max Pooling、Subsampling、ToMe、PruMerge、FastVID(Tab. wap_comparison:62.0 vs 60.0–61.2)。这也奠定了它作为蒸馏 target 的资格。
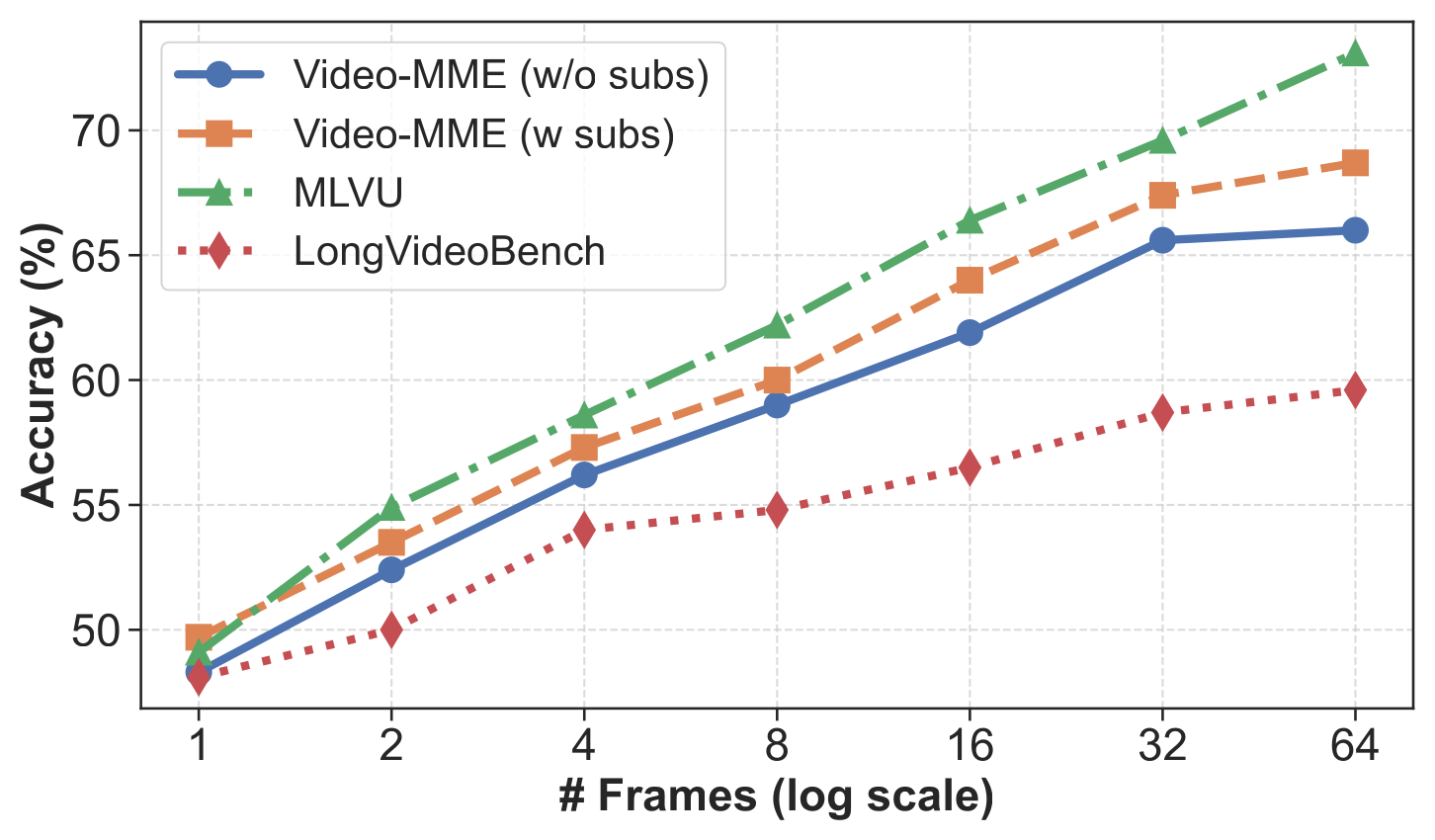
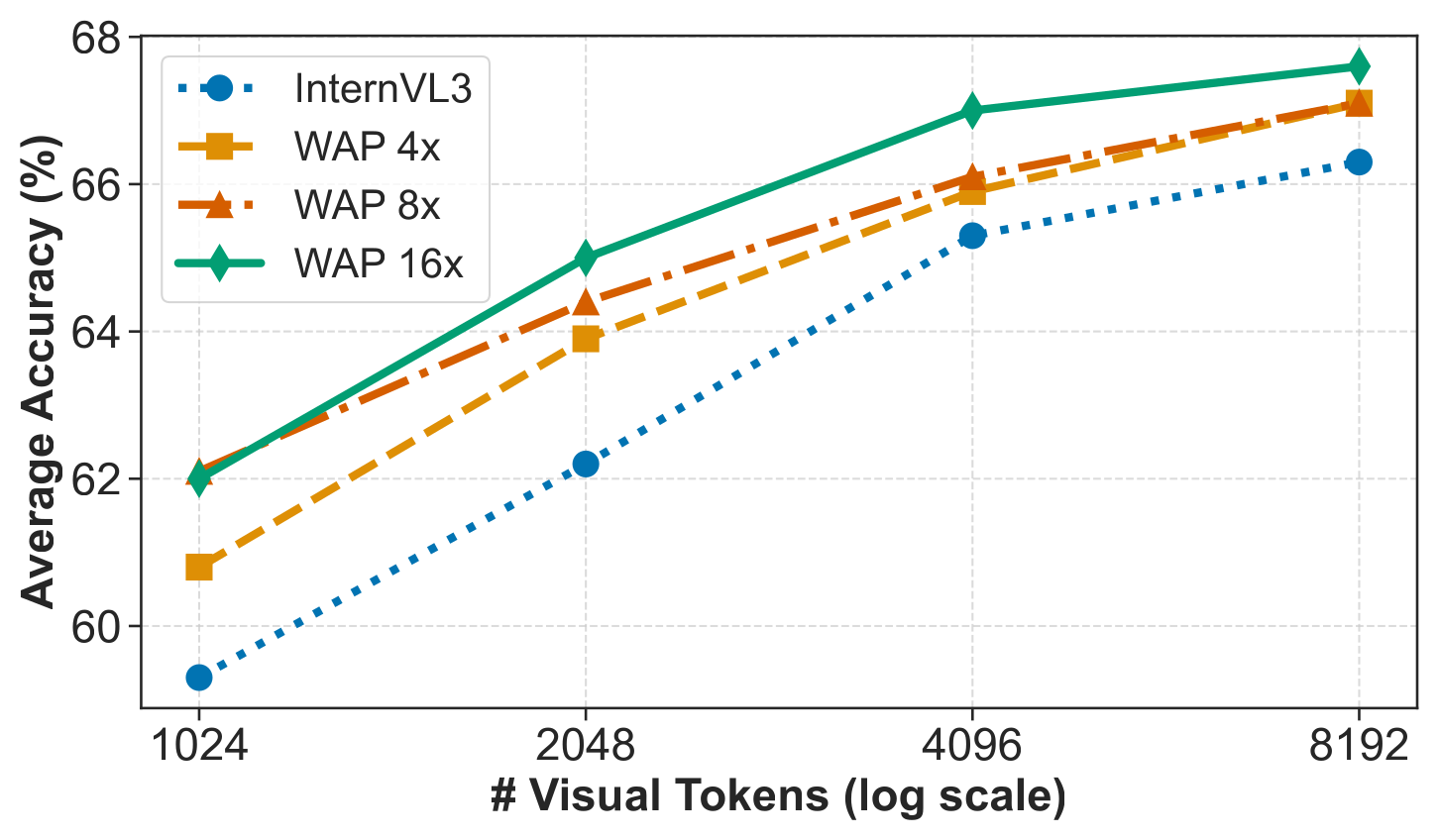 Figure 4:(左) Video LLM 在 Video-MME / MLVU / LongVideoBench 上的准确率与帧数成对数关系——帧数预算是关键瓶颈。(右) 固定 visual-token 总预算下,WAP 16× 让 InternVL3 多吃 16× 帧数,准确率随着帧数继续单调上升。这两张图给出"激进压缩 × 多帧"的设计正当性。
Figure 4:(左) Video LLM 在 Video-MME / MLVU / LongVideoBench 上的准确率与帧数成对数关系——帧数预算是关键瓶颈。(右) 固定 visual-token 总预算下,WAP 16× 让 InternVL3 多吃 16× 帧数,准确率随着帧数继续单调上升。这两张图给出"激进压缩 × 多帧"的设计正当性。
3.3 学生架构:内部时空 token 压缩 ViT¶
- Backbone: 12 层 768-dim ViT-Base,初始化用 teacher 权重剪到学生维度。
- 时序混合层: 每个 spatial-attention 层后接一个 depth-wise 1D temporal conv (仅在时间维 > 1 时有效)。
- 下采样: 第 4 层后插入 stride \([t,h,w]=[2,2,2]\) 的 DW strided conv;第 8 层后再插入 stride \([2,1,1]\)。整体把 16 帧 × 16 × 16 的 token grid 一步步压到 4 × 4 × 4 = 16 tokens / frame-clip。
- 为什么是 DWTempConv 而不是 temporal attention 或 full ST-attention:见 Tab. arch_latency(256 帧测)
| Arch | Latency (ms) | TFLOPs | Params |
|---|---|---|---|
| ViT-Large-24L (Teacher) | 1043.33 | 158.80 | 304.01M |
| ViT-Base-12L (No comp.) | 338.01 | 44.81 | 86.31M |
| TempAttn | 348.29 | 32.77 | 143.83M |
| SpatioTempAttn | 204.35 | 17.92 | 87.15M |
| TempConv | 202.08 | 22.44 | 109.54M |
| DWTempConv (Ours) | 174.84 | 17.92 | 87.15M |
DWTempConv 在同等参数/FLOPs 下 latency 最低,且 Tab. ablation_study 表明它在准确率上反而比 SpatioTempAttn 高 0.9pt(62.8 vs 61.9)。
3.4 Compressed Token Distillation(CTD)¶
核心 trick:不让学生去拟合 teacher 的 dense 输出,而是拟合 teacher 经 WAP 后的紧致输出。直觉上:
- 学生本身就只能输出 \(N/r\) 个 token,强行拟合 \(N\) 个 dense token 会逼着它"学回它表达不了的细节"。
- WAP 已经把 cls-attention 的显著性挤压进 \(N/r\) 个 token,等于把 teacher 的注意力机制"静态化"地烧进学生权重。
训练用 AdamW + cosine + warmup,初始化裁剪自 teacher,1800 epochs / ~21 天 / 8× H100。损失上加 3σ outlier clipping 和 grad norm 1.0 防止爆炸。CTD 阶段不动 LLM,纯监督学生。
3.5 Language Model Adaptation(LMA)¶
CTD 之后 latent space 对 teacher 友好,但对 LLM 不一定。LMA 用 (video, text) 监督下游 cross-entropy,只用 LoRA(\(r=4, \alpha=8, \text{dropout}=0.05\))。文章特意指出更高 rank(8/16)反而更差。
- batch size 128 (gradient accumulation),lr 4e-5 cosine,25K steps,几小时跑完。
- frame budget 在 LMA 阶段从 \(\{128, 256, 512\}\) 均匀采样 + FPS \(\in [1,4]\),配合保留 LLM 推理能力的目的(context length adaptation)。
- 训练数据是 InternVL2.5 数据集的子集:ShareGPT4Video、LLaVA-Video-178K、FineVideo、CLEVRER、NTURGB+D(CTD 阶段);QA + caption(LMA 阶段)。
3.6 Implementation 关键数字¶
| 项 | 值 |
|---|---|
| Teacher | InternViT-300M, ViT-L/14, 304M, 1024d, 24 层 |
| Student | ViT-B/14 + DW temporal conv, 87M, 768d, 12 层 |
| 压缩比 | 16× (空间 4× × 时间 4×) |
| 训练 GPU | 8× H100 |
| CTD epochs | 1800(消融用 800) |
| CTD 总耗时 | ≈21 天 |
| LMA steps | 25K(几小时) |
| 推理 GPU(latency 测) | A100-80GB,中位 100 次 + 40 次 warmup |
| 输入分辨率 | 448px(短边) |
| Frame sampling | dense clip,4 帧/clip ≥1 FPS |
| 最大输入帧数 | 512(LMA 训练时已见过) |
4. 结果对比¶
4.1 主表:固定 latency 预算下的端到端 trade-off(Tab. main_results)¶
四个 benchmark 的平均准确率 vs ViT/LLM/总延迟,分三个等延迟组对比。LiteFrame 始终在同 budget 下吃 8× 帧数 + 更低总延迟 + 更高准确率。
| 等 latency 组 / 方法 | Frames | Tok./Frame | ViT Params | ViT (ms) | LLM (ms) | Total (ms) | Avg Acc (%) |
|---|---|---|---|---|---|---|---|
| InternVL3-8B (teacher) | 8 | 256 | 304M | 40.0 | 167.3 | 208.4 | 59.0 |
| + FastVID | 32 (4×) | 16 | 304M | 161.7 | 63.0 | 224.8 (+7.9%) | 59.5 (+0.5) |
| + LiteFrame | 64 (8×) | 16 | 87M | 54.8 | 94.9 | 150.1 (−28.0%) | 61.1 (+2.1) |
| InternVL3-8B | 16 | 256 | 304M | 74.0 | 329.3 | 403.6 | 62.2 |
| + FastVID | 64 (4×) | 16 | 304M | 310.6 | 95.4 | 406.2 (+0.6%) | 59.5 (−2.7) |
| + LiteFrame | 128 (8×) | 16 | 87M | 105.3 | 166.6 | 272.6 (−32.5%) | 63.7 (+1.5) |
| InternVL3-8B | 32 | 256 | 304M | 144.5 | 669.8 | 814.5 | 65.3 |
| + FastVID | 128 (4×) | 16 | 304M | 625.8 | 168.9 | 794.9 (−2.4%) | 62.9 (−2.4) |
| + LiteFrame | 256 (8×) | 16 | 87M | 204.0 | 327.4 | 532.3 (−34.6%) | 65.7 (+0.4) |
要点: - 同 budget 下,每多 1× 帧数 LiteFrame 都仍然占优——这就是 §2 论证的"激进压缩 × 多帧"的实证。 - FastVID 在 32 帧组(最长视频组)首次跑赢 teacher 的延迟(-2.4%)但准确率 -2.4pt——典型的 post-hoc 方法困境。
4.2 与 efficient vision encoder 对比(Tab. sota_efficiency)¶
| 方法 | ViT Params | Tok./Frame | Frames | Total tokens | Vis. (ms) | LLM (ms) | Total (ms) | Avg Acc (%) |
|---|---|---|---|---|---|---|---|---|
| FastVLM | 125M | 49 | 32 | 1568 | 98.3 | 132.9 | 231.5 | 47.6 |
| VideoPanda | 45M | 272 | 32 | 8704 | 36.5 | 345.7 | 382.4 | 49.2 |
| LiteFrame | 87M | 16 | 32 | 512 | 30.1 | 61.5 | 91.9 | 58.0 |
LiteFrame 比 VideoPanda 快 1.2×,比 FastVLM 快 3.3×,且因为 token 极少,LLM 端 latency 也最低。
4.3 与 AutoGaze 对比(Fig. movinet_autogaze_combined)¶
| 方法 | Frames | AutoGaze (ms) | ViT (ms) | LLM (ms) | Total (ms) | Acc (%) |
|---|---|---|---|---|---|---|
| NVILA-8B-Video (ImageViT) | 32 | – | 451.0 | 329.9 | 780.8 | 63.1 |
| + AutoGaze (VideoViT) | 256 (8×) | 2961.4 | 2605.6 | 539.5 | 6106.5 (+682%) | 63.1 (0.00) |
| InternVL3-8B | 32 | – | 144.5 | 669.8 | 814.5 | 65.3 |
| + LiteFrame | 256 (8×) | – | 204.0 | 327.4 | 532.3 (−34.6%) | 65.7 (+0.4) |
AutoGaze 在 8× 帧数下 latency 飙升到 6.1 秒,其中近一半(3.0s)来自它自己的 pre-reduction 模块——结构性缺陷。
4.4 零样本空间分辨率扩展(HLVid)¶
LiteFrame 在 HLVid 上 zero-shot 拿到 54.1(2688px × 48 帧),超过 AutoGaze 的 52.6(需要 3584px × 1024 帧),且 LiteFrame 从未在高分辨率上训练过。这是 token-efficient encoder 的副产品:省下来的 token 预算可以换成空间分辨率。
4.5 关键消融(Tab. ablation_study & ablation_variants & ablation_strategies)¶
主消融(16/128 帧、403.6→87.4 ms):
| Ablation | TokComp | DWConv | WAP | LMA | Frames | Latency (ms) | Avg Acc (%) |
|---|---|---|---|---|---|---|---|
| InternVL3-8B (teacher) | – | – | – | – | 16 | 403.6 | 62.2 |
| 普通蒸馏 (ViT-B-12L) | ✗ | ✗ | ✗ | ✗ | 16 | 362.9 | 60.3 |
| CTD (SpatioTempAttn) | ✓ | ✗ | ✓ | ✗ | 128 | 102.2 | 61.9 |
| CTD (DWTempConv) | ✓ | ✓ | ✓ | ✗ | 128 | 87.4 | 62.8 |
| RTD | ✓ | ✓ | ✗ | ✗ | 128 | 87.4 | 43.8 |
| RTD + LMA | ✓ | ✓ | ✗ | ✓ | 128 | 87.4 | 61.5 |
| CTD + LMA (Ours) | ✓ | ✓ | ✓ | ✓ | 128 | 87.4 | 63.4 |
要点: - WAP 这个 supervision target 是关键:RTD(用自编码 reconstruct dense feature 的对照实验)裸跑只有 43.8%;加 LMA 才被救到 61.5%。CTD 不需要 LMA 就有 62.8%。 - DWTempConv 同 latency 下比 SpatioTempAttn 高 0.9pt:87.4 vs 102.2 ms,准确率 62.8 vs 61.9。 - 没有 token compression 的纯蒸馏(ViT-B-12L)即使省掉 40 ms 的 ViT 时间,仍因为 256 tokens/frame 撑爆了 LLM,绝对准确率 60.3 < teacher 62.2。 - CTD vs CTD+LMA:64 帧 60.0→61.0;128 帧 62.8→63.4;256 帧 64.1→65.3 —— LMA 平均带来 ~1pt 提升。
RTD(Reconstructive Token Distillation)的对照实验非常关键:用 auxiliary decoder 把学生的 compressed latent 还原成 teacher dense feature,理论上是"更自由的压缩流形",但 64/128/256 帧仅有 43.6/43.8/43.9,几乎是塌掉的。
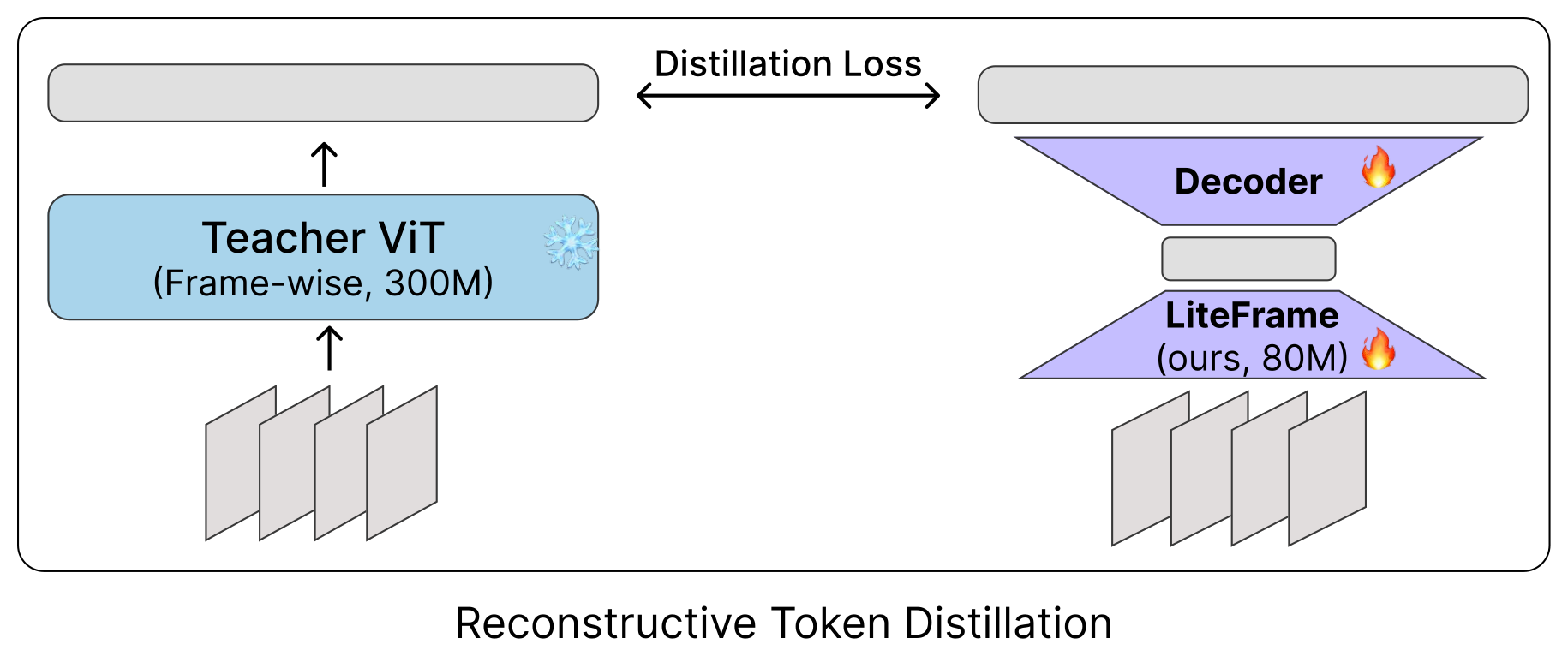 Figure 5:RTD —— 用 auxiliary decoder 让学生的 latent 还原 teacher 的 dense feature。这是为了证明 "学习一个 task-agnostic 的压缩流形" 不如 "直接对齐 WAP 这个有结构的 prior"。实证上 RTD 几乎学不出来。
Figure 5:RTD —— 用 auxiliary decoder 让学生的 latent 还原 teacher 的 dense feature。这是为了证明 "学习一个 task-agnostic 的压缩流形" 不如 "直接对齐 WAP 这个有结构的 prior"。实证上 RTD 几乎学不出来。
4.6 spatio-temporal vs spatial-only 压缩(Tab. ablation_strategies)¶
| 方法 | Frames | ViT (ms) | LLM (ms) | Total (ms) | Avg Acc (%) |
|---|---|---|---|---|---|
| InternVL3-8B (teacher, 32 帧) | 32 | 144.5 | 669.8 | 814.5 | 65.3 |
| Distill (No Comp., 32 帧) | 32 | 63.9 | 670.0 | 733.8 | 62.6 |
| Spatial 16× (256 帧) | 256 | 185.2 | 319.1 | 504.4 | 60.8 |
| Ours CTD (256 帧) | 256 | 204.0 | 327.4 | 532.3 | 64.1 |
128 帧组:Spatial 16× 60.5 vs CTD 62.8,Video-MME w/o subs 上差距更大(57.0 vs 61.9)。说明在固定 token 预算下,把压缩平摊到时间维比纯空间压缩更划算。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 问题切入找得很准:post-hoc reduction 圈子默认 LLM 是瓶颈,论文把"ViT 在大压缩比下成为新瓶颈"这件事用 Tab. main_results 的 ViT-latency 列子直接钉死。Fig. teaser 的 (b)→(c) 是一张说服力极强的图。
- WAP 一物两用:既当 post-hoc baseline(Tab. wap_comparison 已经赢过 ToMe / FastVID),又是 distillation 的 supervision target。让 ablation 链条特别干净——你想质疑 "学生 17M 参数能不能 carry",先看 WAP 把 teacher 输出 frozen 压完已经 62.0%,那学生只要逼近这个 latent 就行。
- DWTempConv vs SpatioTempAttn 是非平凡选择:在同 FLOPs / 同参数下 latency 还能再低 30 ms,多数论文不会去做这种 ops-level 的对比,但它正是 87.4 ms 这个 latency 的根。Tab. arch_latency 给得非常直白。
- RTD 这个对照实验:愿意付出 auxiliary decoder + 训练成本去构造一个"原则上更强的 baseline",实证 RTD 表现塌掉,让"WAP 这个 prior 不是工程选择而是结构性必要"的论证立住。
- HLVid 零样本空间扩展:48 帧 × 2688px 拿 54.1 超过 AutoGaze 1024 帧 × 3584px。这种"省下来的 token 预算可以换成空间分辨率"的副产品论证非常 clean,且只用 zero-shot 不再训练。
- AutoGaze 解剖:诚实地把 AutoGaze 的延迟分解成 AutoGaze (2961ms) / ViT (2606ms) / LLM (540ms),把 "auxiliary module 才是新瓶颈" 这件事讲清楚——比单纯说 "ours faster" 有说服力得多。
5.2 做得不够好的地方 / 值得质疑的地方¶
- CTD 训练成本极高:1800 epochs / 21 天 / 8×H100。考虑到学生本来就是为了"省",这种训练成本让方法的可复现门槛和小团队尝试的代价都不低。Appendix 也只在 ablation 时降到 800 epochs。
- Teacher-student 不同 family 的迁移没测:所有实验 teacher 都是 InternViT-300M、LLM 都是 InternLM-8B。LiteFrame 是不是 generalize 到 SigLIP / DINOv2 / Qwen-VL 这些 teacher、跨 LLM 还是个问号——而 InternViT 已知是相对老的 image encoder。
- WAP 的 cls-token weighting 隐含假设:WAP 用 \(\mathbf{x}_{\tau,\text{cls}}\) 当 attention query。对那些 cls-token 没有强语义聚合的 ViT(如某些 SigLIP 变体或 pure registers ViT)这个公式不一定能直接用——但论文没讨论 cls-token 缺失/弱化下的退化形式。
- 压缩率被钉死在 16×:所有正文实验都是 \((t,h,w)=(4,2,2)\)。Fig. extrapolation 表明 16× 比 4× / 8× 更优——但 32× / 64× 会发生什么、是不是有一个"信息密度 vs 帧数预算"的 sweet spot 都没有探索。Appendix limitations 也提到"训练更小学生时 loss 爆炸"——其实是说他们试过更激进但训不动。
- DWTempConv 的 receptive field 论证较弱:用 1D depth-wise conv 描述跨帧关系,长程时序依赖(如几秒之外的事件)只能靠 strided downsampling 的 stacking 累积。文章没给 receptive field 实测(比如对 LongVideoBench 中明显需要跨 2 分钟段的题做错误模式分析)。
- Latency 测得有点 cherry-pick:所有数据都在 A100-80GB 上跑、batch=1、median over 100,且预热 40 次。真实场景的 batch、KV cache、tensor parallel 都没碰;H100 / consumer GPU / edge 都没测。
- VideoPanda 对比的设置不一定公平:Tab. sota_efficiency 把 LiteFrame 跟 VideoPanda 都装到 InternVL3-8B 上 LoRA 微调,但 VideoPanda 原论文是 encoder-free 范式,强加 InternVL3 LLM 是不是发挥不出它最佳形态?Acc 58.0 vs 49.2 这个差距大到值得怀疑。
- HLVid 是 AutoGaze 自家 benchmark:作为零样本胜过 AutoGaze 的关键证据,HLVid 由 AutoGaze 团队发布,可能存在隐式的数据 / 设定偏向。论文没在第三方 spatial-heavy benchmark(如 V-STaR、DocVQA-video)上交叉验证。
- Tab. arch_latency 的对比设置缺细节:TempAttn 143.83M 参数 vs DWTempConv 87.15M——这意味着 TempAttn 的 baseline 把 ViT-B 加了很重的 temporal block。是不是把 temporal attention 用更轻的形式(如 axial 或 shifted-window)实现就能逼近?文章没提。
- CTD 用的训练数据本身已经"动态较强":LLaVA-Video-178K、ShareGPT4Video 等 VQA-heavy 数据集对 caption-grounded action 描述很重,对 dense narration / 长片段对话 / 多 turn 推理类任务的 token compression 是否仍合理,没测。Appendix 也承认"LMA 用的是 video-data subset,还没用 extreme long-form datasets"。
5.3 值得继续探讨的方向¶
- 更激进压缩率 + 更长上下文:32× 或 64× 总压缩 + 1K~2K 帧,配合 LLM 上的 long-context training,能否打通"小时级视频理解"?
- 跨 teacher family 的 CTD 迁移:在 SigLIP / DINOv3 / OpenCLIP 系作为 teacher 时,WAP 这个 cls-attention 投影还合不合适?要不要换成 "register token" 加权?
- 替换 WAP 的离线投影为 learnable projection 但显式 anchor 在 WAP 周围:RTD 完全 free-form 不行,CTD 完全 fixed 也丢自由度——在 fixed WAP 加上小幅 learnable residual 是不是 best of both?
- DWTempConv 与 Mamba / SSM 的对比:long-range temporal modeling 是 Mamba 家族擅长的,能否做一个 SSM-based temporal mixer 与 DWTempConv 比 throughput?
- 端到端推理优化:现在 ViT 与 LLM 还是串行调用。能不能让 ViT 输出 partial frame token 后就 streaming 喂给 LLM 做 prefill(pipeline parallel)?
- 小模型版的 CTD 稳定性:Appendix 提到尝试 < 87M 的学生 loss 爆炸。是否需要 progressive distillation(先蒸到 87M 再二次蒸馏)或者 EMA teacher?
- 与 token-budget aware decoding 联动:LiteFrame 让单 frame 只剩 16 tokens,LLM 的 prefill 极快,但 decode 阶段仍然是 dense KV——是不是要配上 video-aware sparse attention 或 cache compression?
- Action / 控制下游:本文都是 QA 类 benchmark。LiteFrame 能否作为 VLA / robot policy 的视频前端?token 数极少对实时控制(>20Hz)正合适。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: jjihwan.github.io/projects/LiteFrame
- 关键 baseline / 相关论文:
- InternVL3 (Zhu et al., 2025) —— teacher
- FastVID (Shen et al., 2025) —— post-hoc time-merge 主要对手
- AutoGaze (Shi et al., 2026) —— pre-ViT selection 主要对手
- FastVLM / FastViTHD (Vasu et al., 2025) —— efficient image-encoder 对手
- VideoPanda (Yi et al., 2025) —— encoder-free 对手
- ToMe (Bolya et al., 2023) —— 经典 token merging
- LLaVA-PruMerge (Shang et al., 2025) —— 空间 prune+merge
- LoRA (Hu et al., 2022) —— LMA 使用