LeRobot: An Open-Source Library for End-to-End Robot Learning¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: LeRobot: An Open-Source Library for End-to-End Robot Learning
- 作者: Remi Cadene*, Simon Aliberts*, Francesco Capuano*† (University of Oxford), Michel Aractingi*, Adil Zouitine*, Pepijn Kooijmans*, Jade Choghari*, Martino Russi*, Caroline Pascal*, Steven Palma*, Mustafa Shukor*, Jess Moss*, Alexander Soare*, Dana Aubakirova*, Quentin Lhoest, Quentin Gallouédec, Thomas Wolf — Hugging Face(* = core team,† = work done while at Hugging Face)
- arXiv 编号: 2602.22818(submitted 2026-02,模板为 ICLR 2026 conference style)
- 关键词: open-source library, robot learning, middleware, LeRobotDataset, dataset streaming, asynchronous inference, imitation learning, VLA, low-cost robots
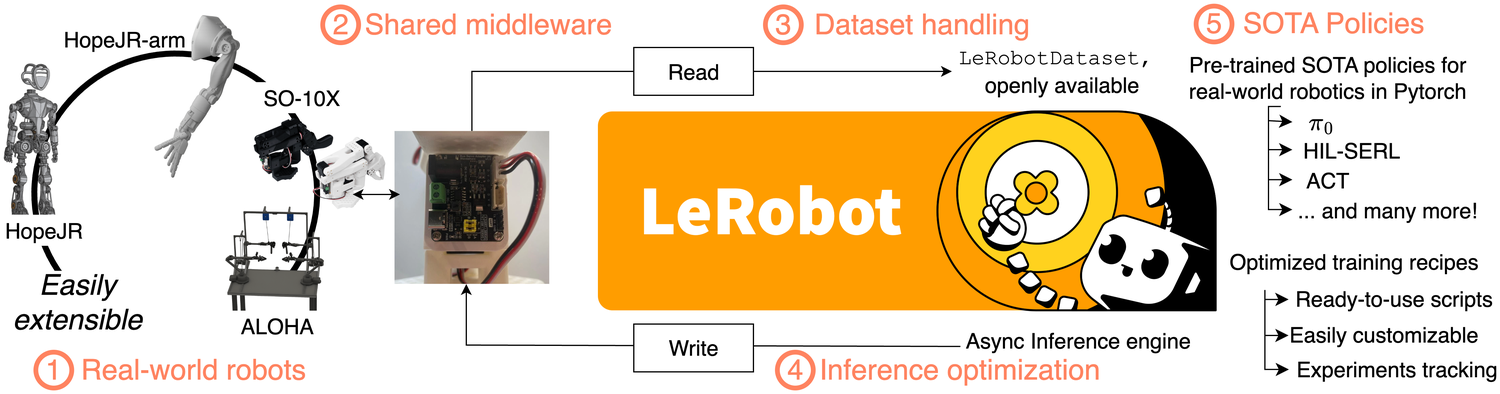 Figure 1:LeRobot 把机器人学习「整条栈」收进一个 PyTorch-native 库 —— ① 低成本真机(SO-10X / ALOHA / HopeJR)→ ② 共享 middleware(leader 读、follower 写)→ ③ LeRobotDataset 数据读写 → ④ 异步推理引擎 → ⑤ 预训练 SOTA policy(π₀ / HIL-SERL / ACT…)。这张图就是全文的「目录」,论文本身没有单一算法贡献,卖点是这五块的纵向打通。
Figure 1:LeRobot 把机器人学习「整条栈」收进一个 PyTorch-native 库 —— ① 低成本真机(SO-10X / ALOHA / HopeJR)→ ② 共享 middleware(leader 读、follower 写)→ ③ LeRobotDataset 数据读写 → ④ 异步推理引擎 → ⑤ 预训练 SOTA policy(π₀ / HIL-SERL / ACT…)。这张图就是全文的「目录」,论文本身没有单一算法贡献,卖点是这五块的纵向打通。
2. 文章介绍¶
2.1 解决的领域和问题¶
这是一篇 系统 / 软件库(infrastructure)论文,不是方法论文。领域是 robot learning(用 ML 的 implicit policy 取代经典机器人学的 explicit 建模 pipeline)。它要解决的不是某个学术问题,而是 生态碎片化 这个工程痛点:
- Middleware 碎片化:高层控制到低层电机的接口往往是「一机一套」,换机器人就要重写适配层。
- 数据格式碎片化:大规模数据集各用各的格式(TF Datasets、ROS bags、各家 JSON),无法把异构数据集拼成大 mixture。
- 训练框架碎片化:算法常以孤立组件存在,和栈的其余部分整合困难;实现上的小差异 + 硬件差异让结果难复现。
LeRobot 的主张是:用一个 vertically integrated(纵向打通)的开源库把 middleware → 数据 → 训练 → 推理 → 仿真评测全部串起来,把研究者从「系统集成」里解放出来。
2.2 Motivation¶
核心叙事是 robotics 正在从 explicit models(解析刚体运动学、接触建模、规划——可解释但难 scale、undermodeling)转向 implicit models(端到端学到的 monolithic policy——随数据/算力增长而 scale)。这一转向之所以现在可行,靠三件事同时成熟:
- 廉价 teleoperation 硬件:SO-10X / ALOHA / GELLO 等低成本(甚至 3D 打印)遥操作臂,让去中心化的数据采集成为可能。
- 大规模开放数据集:Open-X、DROID 等集中式努力 + 海量社区去中心化采集。
- 可 scale 的学习方法:ACT(CVAE)、Diffusion Policy、π₀ / SmolVLA(flow matching) 这类生成式 BC,以及 HIL-SERL 这类真机 RL。
论文反复强调 accessibility(可及性)+ scalability(可扩展)+ openness(开放) 三个设计原则,本质是 Hugging Face 把「transformers 之于 NLP」的开源飞轮复制到机器人。
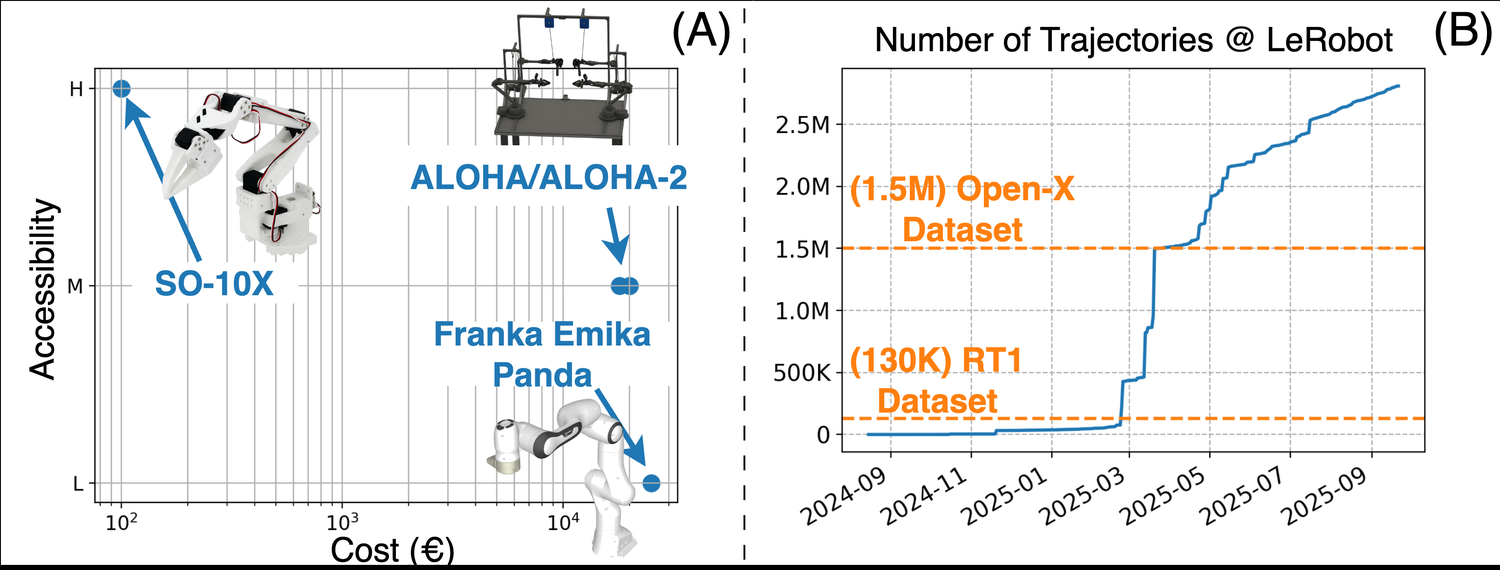 Figure 2:(A) accessibility-vs-cost 散点 —— SO-10X(≈€100 量级、高可及)在左上,Franka Emika Panda(≈€10⁴、低可及)在右下,ALOHA 居中偏贵。(B) LeRobot 上累计 trajectory 数随时间冲过 Open-X (1.5M) 与 RT1 (130K) 两条参考线,到 2025 年末约 2.7M。这张图是「democratization 真的发生了」的核心证据,但要注意纵轴是「LeRobotDataset 格式下的轨迹」,不等于「在 LeRobot 支持的机器人上新采的轨迹」(见 §5.2)。
Figure 2:(A) accessibility-vs-cost 散点 —— SO-10X(≈€100 量级、高可及)在左上,Franka Emika Panda(≈€10⁴、低可及)在右下,ALOHA 居中偏贵。(B) LeRobot 上累计 trajectory 数随时间冲过 Open-X (1.5M) 与 RT1 (130K) 两条参考线,到 2025 年末约 2.7M。这张图是「democratization 真的发生了」的核心证据,但要注意纵轴是「LeRobotDataset 格式下的轨迹」,不等于「在 LeRobot 支持的机器人上新采的轨迹」(见 §5.2)。
2.3 之前工作的问题¶
| 类别 | 代表 | 缺陷(LeRobot 的说法) |
|---|---|---|
| Middleware | ROS / 各家厂商 SDK | 抽象存在但实践中常「一机一套」,逼团队各写各的 bespoke 适配,重复造轮子 |
| 数据集格式 | TF Datasets / ROS bags / bespoke JSON | 缺统一的「modality-rich schema」,无法无缝聚合成大 mixture |
| 学习框架 | 各算法独立实现 | 实现细节差异 → 结果方差大(引 Henderson 2018 的 deep RL 复现性危机),叠加硬件差异更难复现 |
| 经典 robotics pipeline | perception→planning→control 模块化 | compounding errors、poor scalability、undermodeling,难适应非结构化环境 |
2.4 论文解决方案(一句话)¶
一个 PyTorch-native 的开源库,用 共享 middleware(多机器人统一接口)+ LeRobotDataset(可流式的统一多模态数据格式)+ 解耦的异步推理栈 + 一批可复用的 SOTA policy 实现,把机器人学习的整条栈纵向打通,并以低成本开放硬件压低入门门槛。
2.5 与前序工作的关系¶
LeRobot 不发明算法,而是 复用 / 集成 大量现成工作,本质是这些研究线的「公共部署层」:
- BC policy:ACT([Zhao 2023],CVAE)、Diffusion Policy([Chi 2024])、VQ-BET([Lee 2024])、π₀([Black 2024],flow matching)、SmolVLA([Shukor 2025],作者自家的小 VLA)。
- RL policy:HIL-SERL([Luo 2024],真机 human-in-the-loop RL)、TD-MPC([Hansen 2022])。
- 硬件:SO-10X([Knight, TheRobotStudio])、Koch-v1.1、ALOHA-2、HopeJR、LeKiwi、Stretch-3、Reachy-2。
- 底层 SDK:直接对接 FeeTech / Dynamixel 两家低成本舵机厂商。
- 数据/视频:torchcodec(on-the-fly 视频解码)、parquet、Hugging Face Hub 生态。
- 仿真评测:LIBERO([Liu 2023])、Meta-World([Yu 2020])。
- 异步推理:把 action chunking([Zhao 2023])+ Real-Time Chunking 式的「边执行边算下一块」做成通用 producer-consumer 抽象。
3. 方法介绍(其实是「五大 Feature」)¶
库的全部内容可归为五块。下面按论文 §3 的组织逐一拆。
3.1 Accessible Real-world Robots(统一 middleware)¶
支持的真机:SO-100 / SO-101(合称 SO-10X)(单臂 + 双臂)、Koch-v1.1、ALOHA-2、HopeJR(humanoid 臂+手)、Stretch-3 与 LeKiwi(移动操作)、Reachy-2(humanoid)。2025 年内从 3 套(Koch-v1.1、SO-100、ALOHA)扩到 8 套。
设计点:一套 shared middleware,能(1)从 leader 机器人读关节配置、写到 follower 上做遥操作,(2)直接用学到的 policy 控制 follower。中间层嵌进各机器人的高层抽象里,往下直接对接 FeeTech / Dynamixel SDK,强调 可扩展、可组合。
成本(开放 BOM,单位 €):
| Robot | 类型 | 成本(€) |
|---|---|---|
| SO-100/101 | Manipulator(双臂) | ~225(双臂 550) |
| Koch-v1.1 | Manipulator(双臂) | ~670(双臂 1346) |
| ALOHA | Bimanual Manipulator | ~21k |
| HopeJR-Arm | Humanoid 臂+手 | ~500 |
| LeKiwi | Mobile Manipulator | ~230 |
对照工业级闭源臂(Franka Emika Panda ≈ €10⁴ 量级),低端开放平台便宜 1–2 个数量级 —— 这就是「democratization」论点的硬件支点。
3.2 Datasets:LeRobotDataset + 流式¶
LeRobotDataset 是统一多模态 schema,目标是 self-contained:含高频 sensorimotor 读数、多路相机、teleop 状态信号,以及任务文本描述、embodiment 规格、FPS、传感器类型等 metadata(支持过滤 + 语言条件 policy)。
落地存储(见 Appendix):把数据切成 .parquet(表格型低频记录)+ .mp4(压缩视频)+ 轻量 metadata。
StreamingLeRobotDataset:为「百万 episode 级」数据集设计,frame 按需从远端取、而非整体预载。三个要点:
- 用
IterableDataset接口; - 集成
torchcodec做 on-the-fly 视频解码; - metadata 因体量小被完整下载,高体量的视频/控制流全部按需取 → 内存占用与数据集大小无关。
附录给的 timing 显示:网络好的前提下,steady-state(初始化之后)流式与预载性能相当。
采用情况(截至 2025-09):16K+ 数据集、2.2K+ 贡献者;50%+ 的数据集采自 SO-10X。下表是按机器人统计的 top(注意「下载」与「数据集数」两个口径分歧很大):
| Robot | #Downloads | #Datasets | #Episodes |
|---|---|---|---|
| Panda | 1,878,395 | 588 | 926,776 |
| xArm | 1,107,329 | 74 | 450,329 |
| WidowX | 832,177 | 100 | 214,117 |
| KUKA | 662,550 | 3 | 419,784 |
| SO-101 | 319,586 | 3,965 | 58,299 |
| SO-100 | 278,697 | 5,161 | 78,510 |
| Koch-v1.1 | 43,561 | 849 | 20,959 |
读法:下载量 被 Panda/xArm/WidowX/KUKA 这些 学术集中式 数据集(Open-X、DROID 系)主导;而 数据集数量 被 SO-100/101 这些 社区去中心化 努力主导(SO-100 有 5,161 个数据集但只占少量下载)。两种生态在同一格式下共存,是论文想讲的「format 普适性」故事。
3.3 Models:可复用的 SOTA policy 实现¶
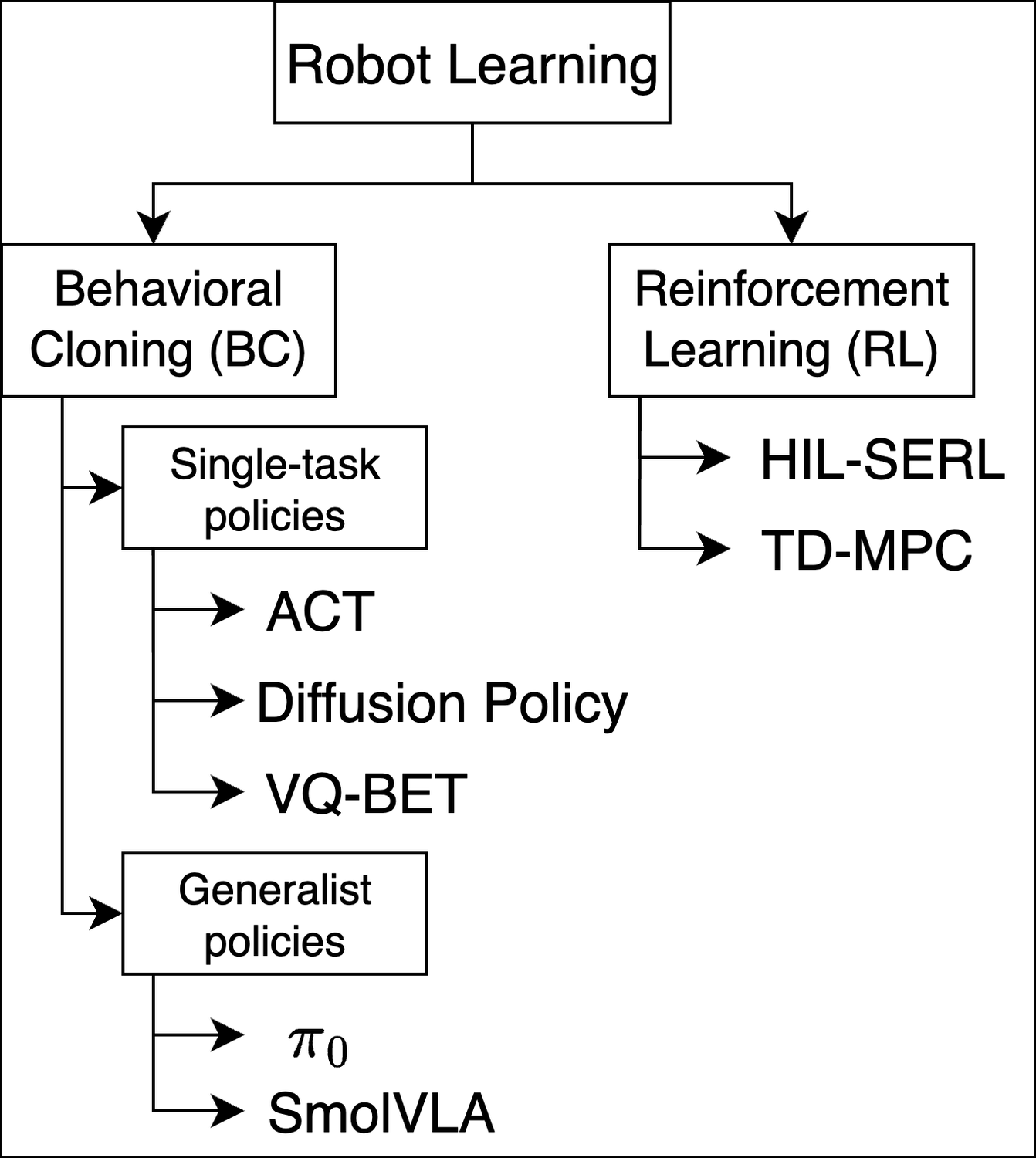 Figure 3:LeRobot 支持的算法 taxonomy —— BC 分单任务(ACT / Diffusion Policy / VQ-BET)与 generalist(π₀ / SmolVLA),RL 给 HIL-SERL / TD-MPC。全部纯 PyTorch 实现。
Figure 3:LeRobot 支持的算法 taxonomy —— BC 分单任务(ACT / Diffusion Policy / VQ-BET)与 generalist(π₀ / SmolVLA),RL 给 HIL-SERL / TD-MPC。全部纯 PyTorch 实现。
全部 policy 纯 PyTorch 写,既能(1)从真机数据 从零训练,也能(2)直接用开放预训练权重 推理。库吹的「易用性」:从零训一个模型 < 100 行代码、起一个 serving < 40 行代码。
ACT 是上传量最大的 policy(小、推理快、50 条真机轨迹就能训出可用 policy),但作为单任务模型,实验条件一变就得重训;SmolVLA 则是可语言条件的小 VLA,适用面更广。
Peak Memory(fp32,diffusion/flow 用 10 步去噪):
| Model | #Params | CPU | MPS | RTX 4090 | A100 |
|---|---|---|---|---|---|
| ACT | 52M | 817.4 MB | 462 MB | 211.24 MB | 211.24 MB |
| Diffusion Policy | 263M | 1.22 GB | 224 MB | 1.12 GB | 1.12 GB |
| π₀ | 3.5B | 4.13 GB | 97 MB | 13.32 GB | 13.32 GB |
| SmolVLA | 450M | 1.69 GB | 555 MB | 1.75 GB | 1.75 GB |
Avg Inference Latency(ms,100 次前向,5s 硬超时;(x%) 为超时比例):
| Model | #Params | CPU | MPS | RTX 4090 | A100 |
|---|---|---|---|---|---|
| ACT | 52M | 182.3 ± 40.8 | 42.7 ± 10.1 | 5.01 ± 0.06 | 13.77 ± 0.45 |
| Diffusion Policy | 263M | (100%) | 3453.8 ± 39.3 | 369.8 ± 0.2 | 613.9 ± 10.2 |
| π₀ | 3.5B | (100%) | (100%) | 209.4 ± 2.8 | 569.0 ± 2.9 |
| SmolVLA | 450M | 2028.5 ± 302.6 (2%) | 721.8 ± 57.7 | 99.2 ± 1.2 | 278.8 ± 1.9 |
要点:小模型 ACT 在 4090 上 ~5 ms(≈100–200 Hz);大模型 π₀ 在 CPU/MPS 上 100% 超时,凸显「机器人 foundation model 真机部署」的现实困难。注意全部 fp32、零优化(论文 Conclusion 自承未做 quantization / graph compilation)—— 这点对怎么读这张表很关键(§5.2)。
3.4 Inference:物理 + 逻辑双解耦的异步栈¶
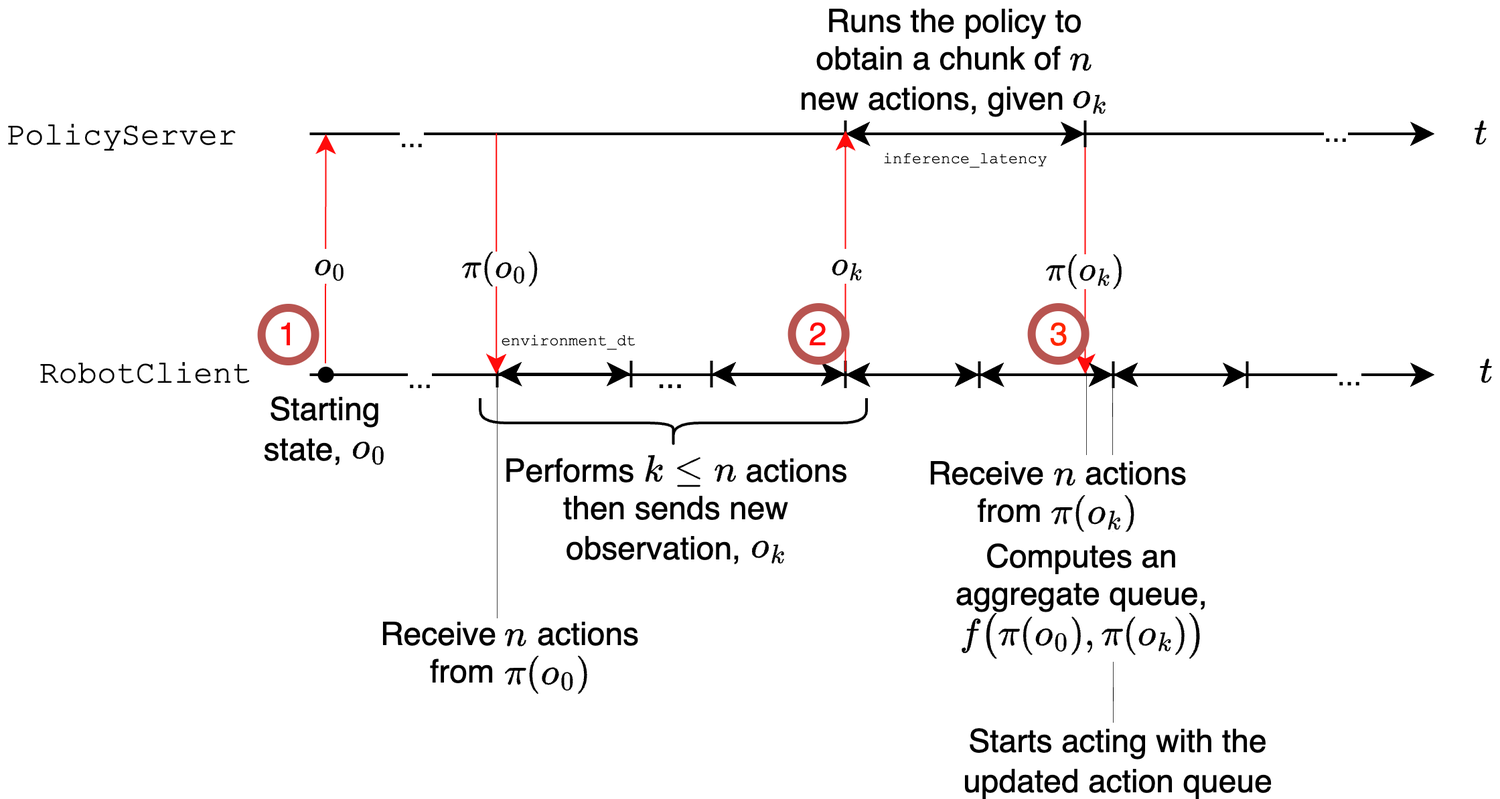 Figure 4:异步推理时间线。
Figure 4:异步推理时间线。PolicyServer 拿 o₀ 跑出 n 个 action 的 chunk 发给 RobotClient;client 执行其中 k≤n 个后把新观测 o_k 回传;server 在 client 还没把当前 chunk 执行完时就并行算下一块 π(o_k),两块重叠部分用聚合函数 f(π(o₀), π(o_k)) 合并,保证 action queue 永不空 → 机器人不 idle。本质是 action-chunking + Real-Time Chunking 的通用化部署抽象。
现代 BC policy 越来越多预测 action chunk \(a_{t:t+H-1}\) 而非单步控制。LeRobot 的推理栈把 动作预测(inference)与动作执行(control)解耦,分两层:
- Physical decoupling:inference 可跑在通过网络连到机器人低层控制器的 远端机器 上 → 用比机载算力更强的设备推理,同时 control 在本地按目标控制频率步进已收到的 action。
- Logical decoupling:inference 走 异步 producer-consumer:以 look-ahead horizon \(H\) 并行预测 action 序列,control 以固定频率消费;重叠的预测块用一个 用户可自定义的聚合函数 \(f\) 合并,保证队列非空。
接口上就是 PolicyServer(host policy)+ RobotClient(收 action 流执行),client 侧 policy_type / pretrained_name_or_path 一指就能换模型。
3.5 Simulation(评测用,非训练用)¶
LeRobot 的核心是真机,但也集成 LIBERO 与 Meta-World 两个仿真 benchmark —— 论文明确说仿真主要用于 系统化评测算法,不用于训练(因为目标的 contact-rich 复杂任务在仿真里很难还原),所以「尽量在真机数据上训」。注意:正文没有给任何 LeRobot policy 在 LIBERO/Meta-World 上的成功率数字,只是宣布「已 native 集成」。
3.x 复现 / 部署相关细节¶
- 代码量:train-from-scratch < 100 LOC,serve < 40 LOC(附录给了 train / inference / async server / async client 的完整示例脚本)。
- 延迟/内存测量:MacBook Pro M1(CPU)、同机 MPS、RTX 4090、A100 四平台;全 fp32;5 s 硬超时;latency 取非超时样本的均值±std。
- 数据存储:parquet + mp4 + metadata;流式靠 IterableDataset + torchcodec。
- 舵机:FeeTech / Dynamixel 低层 SDK 直连。
4. 结果对比¶
这篇没有「我方法 vs baseline 的成功率擂台」。它的「结果」是三类:采用统计(§3.2 已给表)、延迟/内存基准(§3.3 已给表),和唯一一个 受控实验:同步 vs 异步推理。
4.1 唯一的受控实验:Sync vs Async 推理¶
设置:在 SO-100 上用 LeRobot 的 SmolVLA,跑三个真机方块任务(pick-and-place / stacking / sorting),每任务 10 episode、每 episode 60 s。重要 caveat(附录自承):server 与 client 跑在同一台机器上,所以这里测的是 逻辑 解耦的收益,不是 物理(跨机)解耦。
| 指标 | Pick-Place | Stacking | Sorting | Avg |
|---|---|---|---|---|
| Success Rate % — Sync | 75 | 90 | 70 | 78.3 |
| Success Rate % — Async | 80 | 90 | 50 | 73.3 |
| 指标 | Total | Avg | Std |
|---|---|---|---|
| 完成时间 (s) — Sync | 137.5 | 13.75 | 2.42 |
| 完成时间 (s) — Async | 97.0 | 9.70 | 2.95 |
| 指标(固定 60 s 内搬运方块数) | Total | Avg | Std |
|---|---|---|---|
| #Cubes — Sync | 9 | 1.8 | 0.45 |
| #Cubes — Async | 19 | 3.8 | 1.3 |
读法:异步把 周期时间压掉 ~30%(13.75→9.70 s)、固定时间内吞吐 ~2×(1.8→3.8 cubes),这是卖点。但要诚实看到:异步的平均成功率反而更低(78.3→73.3),Sorting 从 70 掉到 50 —— 论文标题只讲「similar success rate + 更高吞吐」,把成功率代价淡化了(§5.2)。
4.2 采用统计(adoption as "result")¶
- LeRobotDataset:16K+ 数据集、2.2K+ 贡献者(2025-09);累计 trajectory 冲过 Open-X(1.5M) / RT1(130K)。
- 最受下载的数据集多为社区把 Open-X / DROID 等 学术 benchmark 移植 进 LeRobotDataset 格式的版本(附录 Fig.)。
- 「Other」类别里
unknown(未记录机器人平台)的数据集数 2,370、下载 711K,是 Other 里最大的一块 —— 即大量数据并没填 schema 该有的 embodiment 字段。
4.3 关键消融¶
本文没有传统意义的「方法消融」。唯一近似消融的就是 §4.1 的 Sync/Async 对照,以及附录里 StreamingLeRobotDataset vs 预载 LeRobotDataset 的 timing 对照(结论:steady-state 相当)。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 真正的纵向整合,确实省 glue code。Intro 点出的痛点(middleware / 数据格式 / 训练框架三处碎片化)是真实存在的税,把 middleware→dataset→train→inference→sim 收进一个 PyTorch-native 库、且接口互通,对一线研究者是实打实的减负。这是「工程贡献」而非「科学贡献」,但价值不假。
- LeRobotDataset 的存储分层是对的。低频表格数据走 parquet、视频走 mp4、metadata 单独存,再用
IterableDataset + torchcodec做 on-the-fly 解码 —— 这正是「内存与数据规模解耦」该有的架构,面向百万 episode 的设计方向正确,不是把 HDF5 一次性塞内存的老路。 - 异步推理抽象干净且正确。把 action chunking 的部署问题抽象成「producer-consumer + 用户可插拔聚合函数 \(f\) over 重叠 chunk」,并区分 physical(跨机)与 logical(重叠计算)两层解耦,是对 Real-Time Chunking 这条线的好工程化。把「大模型放远端、机器人端只收 action 流」做成一等公民,方向务实。
- 低成本开放硬件 + 去中心化数据,是最强的真实贡献。SO-10X ≈ €225、可 3D 打印,叠加 LeRobotDataset 格式,催出了 2.2K+ 贡献者、50%+ 数据集采自 SO-10X 的去中心化生态。不管统计口径有多少水分,这种「把机器人数据采集 democratize」的社区效应是别的库没做到的,也是 HF 的核心竞争力。
- Limitations 写得相对诚实。明说机器人覆盖不全、算法覆盖不全、且 完全没做低层推理优化(quantization / graph compilation)。第三点尤其重要——它等于提前承认了 §3.3 那张延迟表是「未优化下限」。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 这是软件发布,不是研究论文,却投了 ICLR。全文无新算法、无新科学结论、无可证伪的假设,「贡献」是集成本身。作为 tool paper 完全 OK,但放在 ICLR 语境下,novelty 的标准被隐性豁免了 —— 读的时候要把它当 技术报告 / 软件公告,而不是「学术发现」。17 位作者几乎全 HF、星号「core team」覆盖大半,也提示这是公司工程产出。
- 唯一的受控实验弱且部分自我拆台。Sync/Async 对照只用 1 个模型(SmolVLA)、1 种机器人(SO-100)、3 个玩具方块任务、每任务仅 10 episode;而且 异步平均成功率反而掉了(78.3→73.3),Sorting 直接 70→50。标题的「similar success + 2× throughput」把成功率代价藏起来了。更关键的是 附录承认 server/client 同机,所以连「物理解耦」(这库主打的跨机部署)都没真正测 —— network-distributed 的核心卖点是 零实验 支撑的。
- 延迟表是对「未优化基线」的稻草人。全 fp32、无 quantization / 无
torch.compile/ 无 TensorRT(Conclusion 自承)。于是「π₀ 在 CPU/MPS 上 100% 超时」讲的是「这库还没做工程优化」,而非「foundation model 本质上跑不动边缘」。换句话说这张表测的是 LeRobot 当前实现的状态,不是模型的真实部署下限,容易被误读成后者。 - 采用统计把「库」和「数据格式」混为一谈。头条数字(16K+ 数据集、冲过 Open-X)和「最受下载数据集」绝大多数 不是在 LeRobot 支持的机器人上新采的,而是社区把 Open-X / DROID / Panda / xArm 等 既有数据集移植 进 LeRobotDataset 格式。所以「LeRobot 的 adoption」很大程度是 re-hosting 现象,不等于这库真的生产了那么多新机器人数据。论文半承认了(Other 类下载占大头)却仍当成自己的胜利来叙述。
unknown平台主导 Other 类,直接打脸「self-contained / standardized」卖点。Other 里unknown(没记录 robot 平台)有 2,370 个数据集、711K 下载,是最大一块。schema 本该强制的 embodiment 元数据,在真实社区数据里大面积缺失 —— 标准化更多是「格式上能跑」,而非「元数据真的齐全可用于 cross-embodiment 训练」。- 「reproducible SOTA implementations」只有口号、没有 parity 表。论文反复说自己的 ACT/DP/π₀/SmolVLA 实现「可复现 SOTA」,但 没有一张 LeRobot 实现 vs 原论文在 LIBERO/Meta-World/真机上的成功率对照。复现性是被 断言 的,不是被 展示 的 —— 而 Intro 自己刚引了 Henderson 2018「实现细节导致结果方差」。
- 仿真集成只宣布、未验证。LIBERO / Meta-World 写了快一页背景,却 没给任何 LeRobot policy 的 benchmark 数字。集成 = 公告,不 = 可用证据。
- 流式基准是低门槛达标。附录 timing 的前提是「good network connectivity」,且只展示 steady-state 与预载「相当」。没给冷启动延迟、真实带宽下吞吐、对训练 throughput(samples/sec、GPU 利用率)的影响。「稳态相当」是很低的 bar,真正的问题是大规模流式训练时 GPU 会不会被 IO 饿着。
- 成本对比是 apples-to-oranges。SO-100 €225 vs ALOHA €21k vs Franka,但便宜臂在精度 / 负载 / 重复性 / 寿命上差一大截。「accessibility」是真的,但 cost 轴掩盖了 capability gap —— €225 的臂做不了 Franka 能做的活。把「便宜」与「够用」划等号需要更克制。
- 聚合函数 \(f\) 留给用户「自己定义」= 把最难的问题外包了。异步部署里,重叠 chunk 怎么合并(soft/hard、RTC 式加权)直接决定动作连续性与成功率,本文给的是「可自定义」而非「我们找到了好的默认」。§4.1 异步掉成功率,很可能就和默认 \(f\) 不够好有关,但论文没做 \(f\) 的对照。
5.3 值得继续探讨的方向¶
- 补上低层优化再重测延迟表:quantization /
torch.compile/ TensorRT 上了之后,π₀「跑不动边缘」的故事大概率会变 —— 这恰恰是 Conclusion 自己点名的 future work,也是这库最该补的硬指标。 - 真正的物理解耦 async benchmark:跨机(WiFi/LAN)+ 注入网络 RTT,量化「成功率 vs 网络延迟」曲线。这是主打卖点,却 0 实验。
- 复现性 parity 表:LeRobot 的 ACT/DP/π₀/SmolVLA vs 原论文,在 LIBERO/Meta-World/真机上同台 —— 把「reproducible」从口号变证据。
- 聚合函数 \(f\) 的系统研究:soft vs hard merge、RTC-style 加权,给一个好的默认 \(f\),并解释 §4.1 异步为何掉成功率。
- schema 强制 + 富 embodiment 元数据:消灭
unknown标签,让标准化数据真能用于 cross-embodiment 混训(这才是「统一格式」的终极价值)。 - 流式训练的端到端吞吐:在百万 episode + 真实带宽下,给 samples/sec 与 GPU 利用率,证明流式不是「能跑」而是「能高效训」。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页 / 代码: Hugging Face
lerobot(github.com/huggingface/lerobot) - 关键 baseline / 相关论文:ACT(Zhao 2023)、Diffusion Policy(Chi 2024)、VQ-BET(Lee 2024)、π₀(Black 2024)、SmolVLA(Shukor 2025)、HIL-SERL(Luo 2024)、TD-MPC(Hansen 2022)、Open-X Embodiment(2025)、DROID(Khazatsky 2025)、LIBERO(Liu 2023)、Meta-World(Yu 2020)