VideoWorld 2:用 VDM 做 appearance prior 让 latent dynamics 跨越真实世界¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: VideoWorld 2: Learning Transferable Knowledge from Real-world Videos
- 作者: Zhongwei Ren¹²*, Yunchao Wei², Xiao Yu², Guixun Luo², Yao Zhao², Bingyi Kang¹, Jiashi Feng¹, Xiaojie Jin¹*†(¹ByteDance Seed / ²北京交通大学)
- arXiv 编号: 2602.10102(submitted 2026-02)
- 关键词: video diffusion model, latent dynamics, appearance disentanglement, dLDM, autoregressive transformer, long-horizon manipulation, handicraft videos, Cosmos, ControlNet
- 项目页: https://maverickren.github.io/VideoWorld2.github.io/
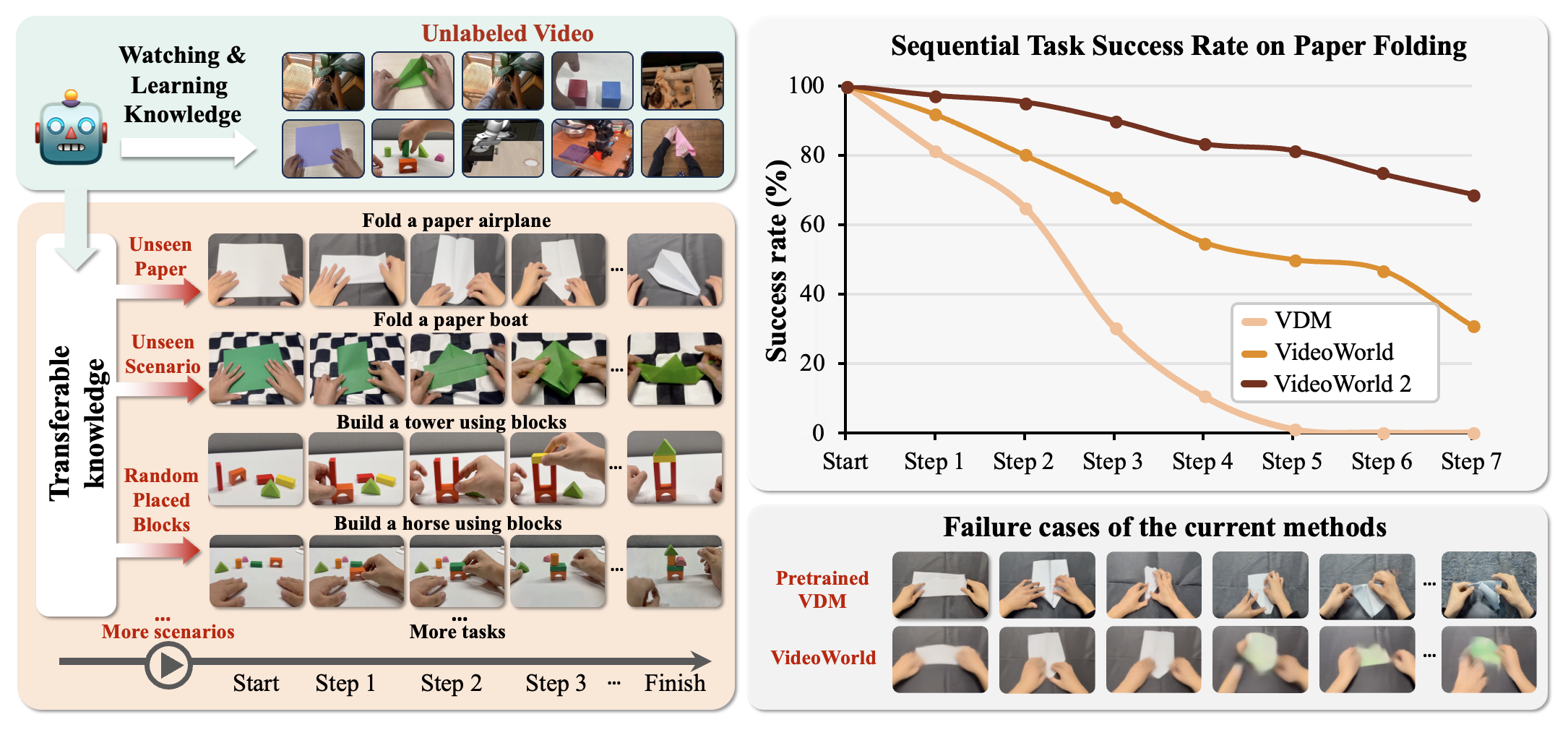 Figure 1:(左)VideoWorld 2 试图在真实世界视频上学习可迁移的具身知识。作者自建 Video-CraftBench 中"折纸 / 拼积木"长序任务做评估。(右)七步折纸任务的 step-wise 成功率:Wan2.2 14B 这种纯 VDM 视觉精美但策略学不到,VideoWorld 视觉退化、长 horizon 崩塌,VideoWorld 2 通过 appearance/dynamics 解耦在第 7 步仍保持 ~70% 成功率。
Figure 1:(左)VideoWorld 2 试图在真实世界视频上学习可迁移的具身知识。作者自建 Video-CraftBench 中"折纸 / 拼积木"长序任务做评估。(右)七步折纸任务的 step-wise 成功率:Wan2.2 14B 这种纯 VDM 视觉精美但策略学不到,VideoWorld 视觉退化、长 horizon 崩塌,VideoWorld 2 通过 appearance/dynamics 解耦在第 7 步仍保持 ~70% 成功率。
2. 文章介绍¶
2.1 解决的领域和问题¶
直接从无标注真实世界视频中学习可迁移的、长 horizon 的任务知识。具体到本文,"知识"被定义为完成任务所需的规则、推理与规划能力(沿用 VideoWorld 1 的术语)。两条评测路径:
- Video-CraftBench(自建):纸飞机 / 纸船折叠 + 三个搭积木任务,~7 小时 / ~9.5k clip 的第一人称教程视频。折纸 40-80 秒、积木 20-30 秒,比任何"娱乐向"视频生成或常规模仿学习长很多;测试集换桌面、纸纹、视角,专门考迁移。
- 机器人 manipulation:在 1.3M 规模的 Open-X 上预训练 latent code,再 fine-tune CALVIN,考 cross-embodiment / cross-environment 迁移。
2.2 Motivation¶
VideoWorld 1 在 9×9 围棋和 CALVIN 上证明 video-only AR 能学到 reasoning,但作者亲自 stress-test 后承认它在真实世界视频上根本不工作——纸飞机折到第 6 步就崩、新桌面下手部畸变、纸张变色。直接拿 SOTA 的 Wan2.2 14B / HunyuanVideo 13B / Cosmos AR 4B / Cosmos DiT 2B 来 fine-tune 视觉确实好看,但策略学不到——它们用上千 token 编码每一帧,关键动作信息被海量像素细节稀释。作者把症结归到一句话:appearance 和 dynamics 没有真正解耦——之前的 latent action / dynamics model 都用 VAE 风格 reconstruction,loss 会强迫 latent 编码 task-irrelevant 的纹理 / 光照 / 镜头抖动。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 纯 VDM fine-tune | Wan2.2, HunyuanVideo, Cosmos AR/DiT | 视觉质量很好,但 long-horizon step-wise 成功率第 4 步即崩到 ≤10.6%,第 5 步全为 0;语言指令也救不回来 |
| Latent action / dynamics 模型 | LAPA, Moto, AdaWorld, iVideoGPT | 只建模 2-frame transition(LAPA / Moto 都是短 horizon)或用普通 VAE reconstruction → latent 仍裹挟 appearance 细节,跨环境立刻失效 |
| VideoWorld 1(自家上一代) | ren2025videoworld | 同样的 reconstruction objective 让 latent 编码不相关视觉变化,新场景下生成"手部畸变 / 桌面漂移 / 纸张错位",长序成功率第 7 步 0.0%(OpenX 预训练后也只到 31.9%) |
| 并行同期的 VDM-guided latent | CoLA (wang2025coevolvinglatentactionworld) | 也用 VDM 监督 latent,但限于 2-frame transition、忽略 coarse motion structure,长 horizon 仍仅 40.2% |
2.4 论文解决方案(一句话)¶
把 VideoWorld 1 的 LDM decoder 直接替换成预训练 VDM:VQ-VAE 编码器 + learnable queries 仍负责"把未来视觉变化压成 4 个 latent code",但视觉外观全部交给冻结/微调的 Cosmos DiT 2B 来负责——loss 不再要求 latent 重建像素,因此 latent 被迫专心编码"任务相关 dynamics";同时保留一个 gradient-stopped 的 ControlNet-like 旁路把 VQ-VAE 解码器产出的 low-fidelity 运动线索送进 VDM,稳定训练。
2.5 与前序工作的关系¶
- 直接续作:核心架构、问题 framing、IDM 接口都沿用 VideoWorld 1(同一作者团队,第一作者 Zhongwei Ren、Project Lead Xiaojie Jin 不变)。
- VDM 选用 Cosmos:Auto-regressive transformer 用 Cosmos AR 4B(next-token 改为预测 latent code),appearance VDM 用 Cosmos DiT 2B(93 帧 / 5 秒 / 480px / 16 fps)。这意味着论文的 base policy 已经是一个相当大的预训练模型,不像 VideoWorld 1 的"300M from scratch"。
- ControlNet 信号通路:借鉴 ControlNet (zhang2023control),把 low-fidelity decoder output 注入 VDM 但 stop gradient。
3. 方法介绍¶
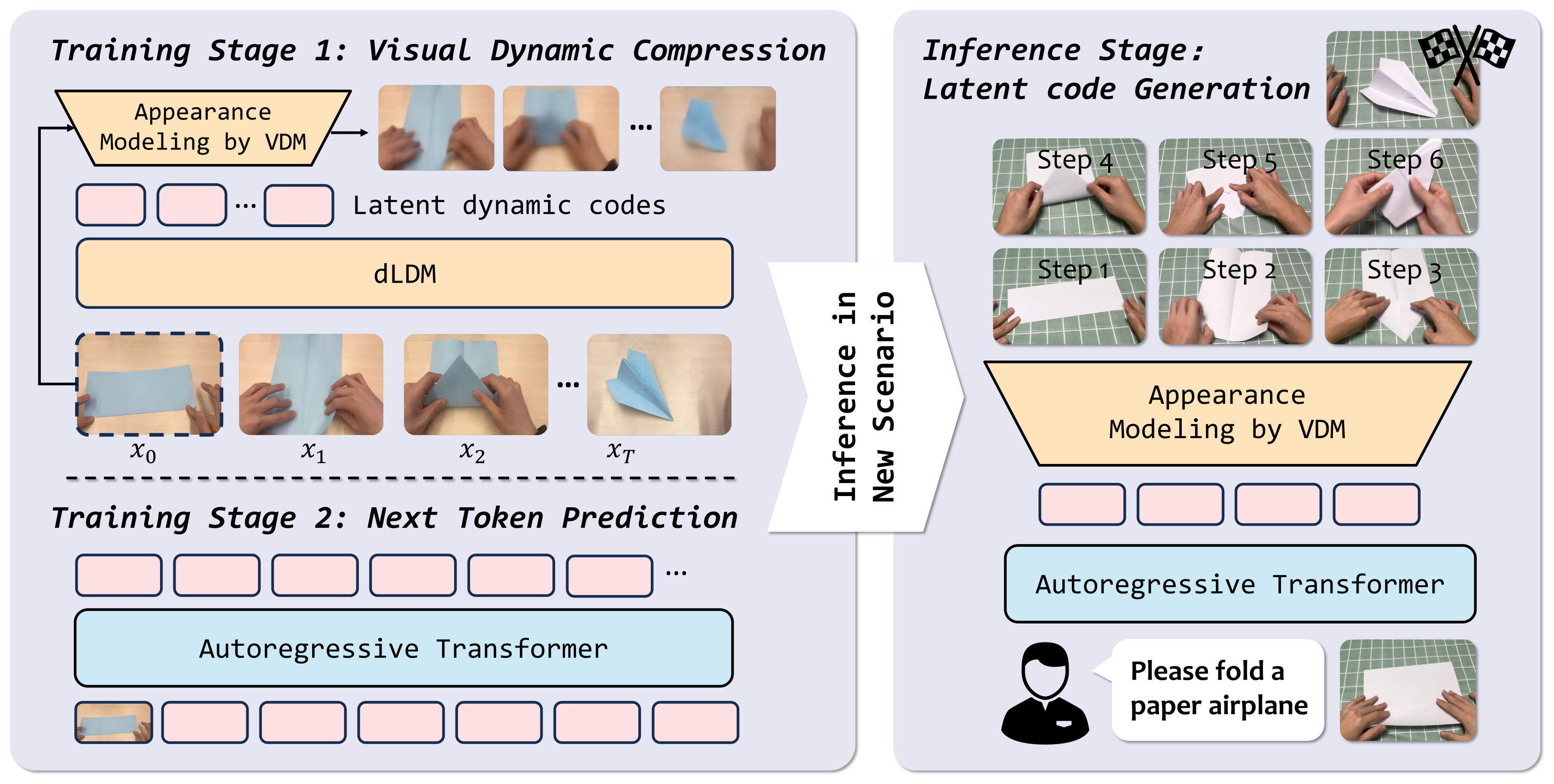 Figure 2:(左)训练 — dLDM 把 future 视觉变化压成 latent codes,自回归 transformer 学习其分布;(右)推理 — 单张新环境初始帧 + task instruction 输入 transformer,预测出 latent code 序列后由 dLDM 解码成执行视频。
Figure 2:(左)训练 — dLDM 把 future 视觉变化压成 latent codes,自回归 transformer 学习其分布;(右)推理 — 单张新环境初始帧 + task instruction 输入 transformer,预测出 latent code 序列后由 dLDM 解码成执行视频。
3.1 形式化¶
仍是 \(\mathcal{G}=\langle\mathcal{X},\mathcal{A},\rho\rangle\),但这一次完全没有 IDM:transformer 直接预测下一组 latent code、再由 dLDM(含 VDM)解码成视频片段,每段 93 帧(5 秒),auto-regressively 拼接到 minute-long 序列。机器人任务里下游再接一个 small action head(MLP + \(\ell_2\) loss)做 latent→action。
3.2 LDM 的痛点:appearance 与 dynamics 纠缠¶
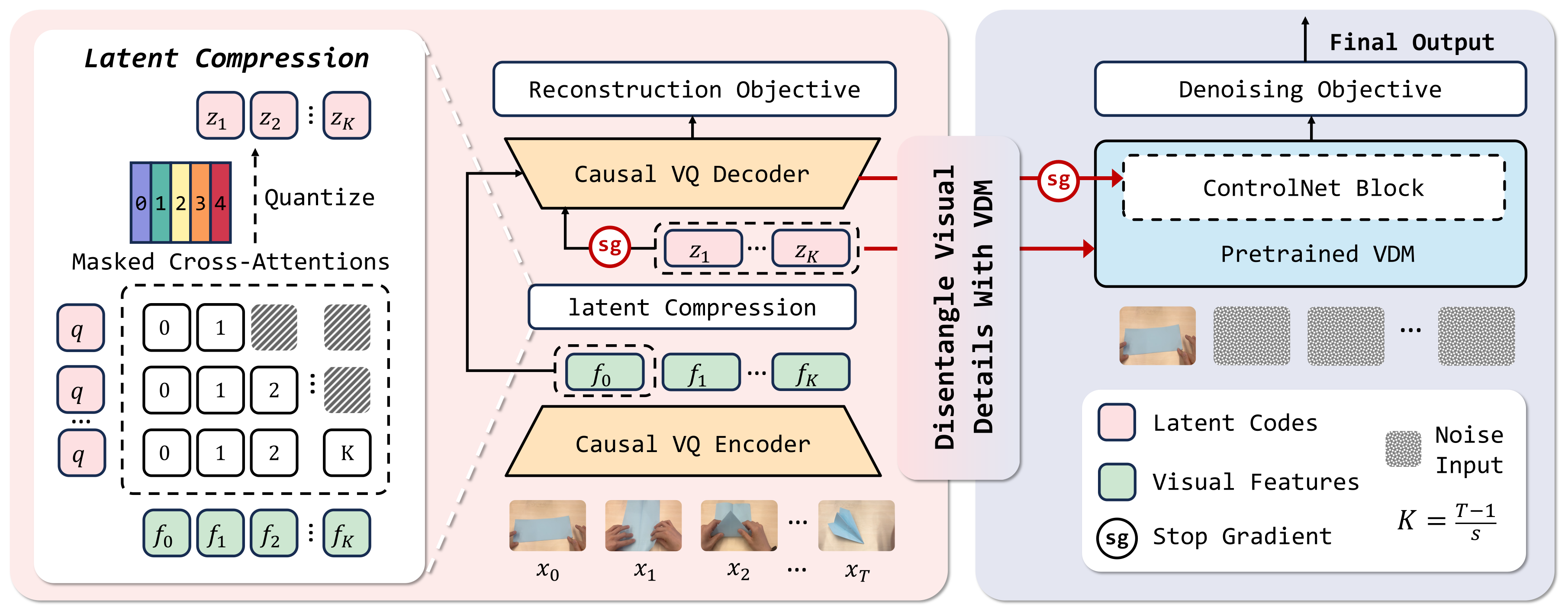 Figure 3:(左)VideoWorld 1 的 LDM —— 编码器/queries/解码器全是自己的 MAGVITv2 风格 codec,重建 loss 让 latent 既要扛 dynamics 又要扛 appearance;(右)VideoWorld 2 的 dLDM —— 解码器替换成 pretrained VDM,原 VQ-VAE 解码器降级为"低保真运动提示"通过 ControlNet-like 旁路注入 VDM。
Figure 3:(左)VideoWorld 1 的 LDM —— 编码器/queries/解码器全是自己的 MAGVITv2 风格 codec,重建 loss 让 latent 既要扛 dynamics 又要扛 appearance;(右)VideoWorld 2 的 dLDM —— 解码器替换成 pretrained VDM,原 VQ-VAE 解码器降级为"低保真运动提示"通过 ControlNet-like 旁路注入 VDM。
作者的归因:训练 LDM 时,\(\ell_2\) pixel reconstruction loss 强迫 latent code 同时承担"动作变化"和"纹理 / 光照 / 镜头位移"。换新环境后,桌面颜色一变、光照一变,latent code 解码失败 → 长 horizon 漂移。
3.3 dLDM(Dynamics-enhanced Latent Dynamics Model)¶
四个组件:
- Causal VQ-VAE encoder:把 93 帧 clip 编码到 \(f_{0:K}\)。
- \(N=4\) 个 learnable query:通过 causal cross-attention 从 \(\{f_{0:k}\}\) 抽取变化信息,FSQ 量化得到 \(\{z^n_k\}\)。Vocabulary 仅 1000(FSQ [8,5,5,5]),比 VideoWorld 1 的 64k 小两个数量级——因为 appearance 不用 latent 来扛了。
- 原 VQ-VAE decoder(保留为 motion prior 通道):用 \(f_0 + z\) 重建出 low-fidelity 运动视频,通过 ControlNet-like 旁路注入 VDM,但梯度全部 stop(关键 ablation:不 stop 反而退化 ~20pp)。这一步称为"warm-up"训练策略,先用原 reconstruction loss 训出能产生"手 / 物体位移"的低保真视频,再切换到解耦方案。
- Pretrained VDM (Cosmos DiT 2B):吃 (initial frame, low-fidelity motion video, latent codes via causal cross-attention) → 输出高保真未来帧。Causal cross-attention 保证生成时刻 \(t\) 只能 attend 到 \(\leq t\) 的 latent,防止 future leakage。Full fine-tune VDM(freeze 与 LoRA 都明显差)。
3.4 Auto-regressive Transformer (Cosmos AR 4B)¶
输入 = task instruction (text) + initial frame + history latent codes;输出 = next \(\{z^n_k\}\)。训练 loss = next-token CE。推理时 latent code 序列被 dLDM 解码成 93 帧 clip,下一段用上一段的最后一帧续接 auto-regressively 直到全任务完成。
3.5 Implementation Details¶
| 项目 | 值 |
|---|---|
| dLDM clip 长度 \(T\) | 93 帧(~5s @ 16 fps) |
| Query 数 \(N\) | 4 |
| FSQ levels / Vocabulary | [8, 5, 5, 5] / 1000 |
| dLDM 优化器 | AdamW, lr=1e-4, wd=0.1, \((\beta_1,\beta_2)=(0.9,0.99)\) |
| AR Transformer 优化器 | AdamW, lr=3e-4, wd=0.05, \((\beta_1,\beta_2)=(0.9,0.98)\) |
| Batch size | 128 (dLDM) / 256 (AR) |
| Training iter | 1e5 (dLDM) / 5e4 (AR) |
| Trainable | AR transformer + dLDM (encoder/queries/decoder) + DiT (full FT) + projection layer |
| Cosmos AR | 4B |
| Cosmos DiT | 2B |
| 输出分辨率 | 480px |
| 训练数据 | Video-CraftBench (~7h / 9.5k clip) 单训 或 Video-CraftBench + Open-X (1.3M) 联训 |
4. 结果对比¶
4.1 Video-CraftBench(折纸 + 积木 + 视觉质量)¶
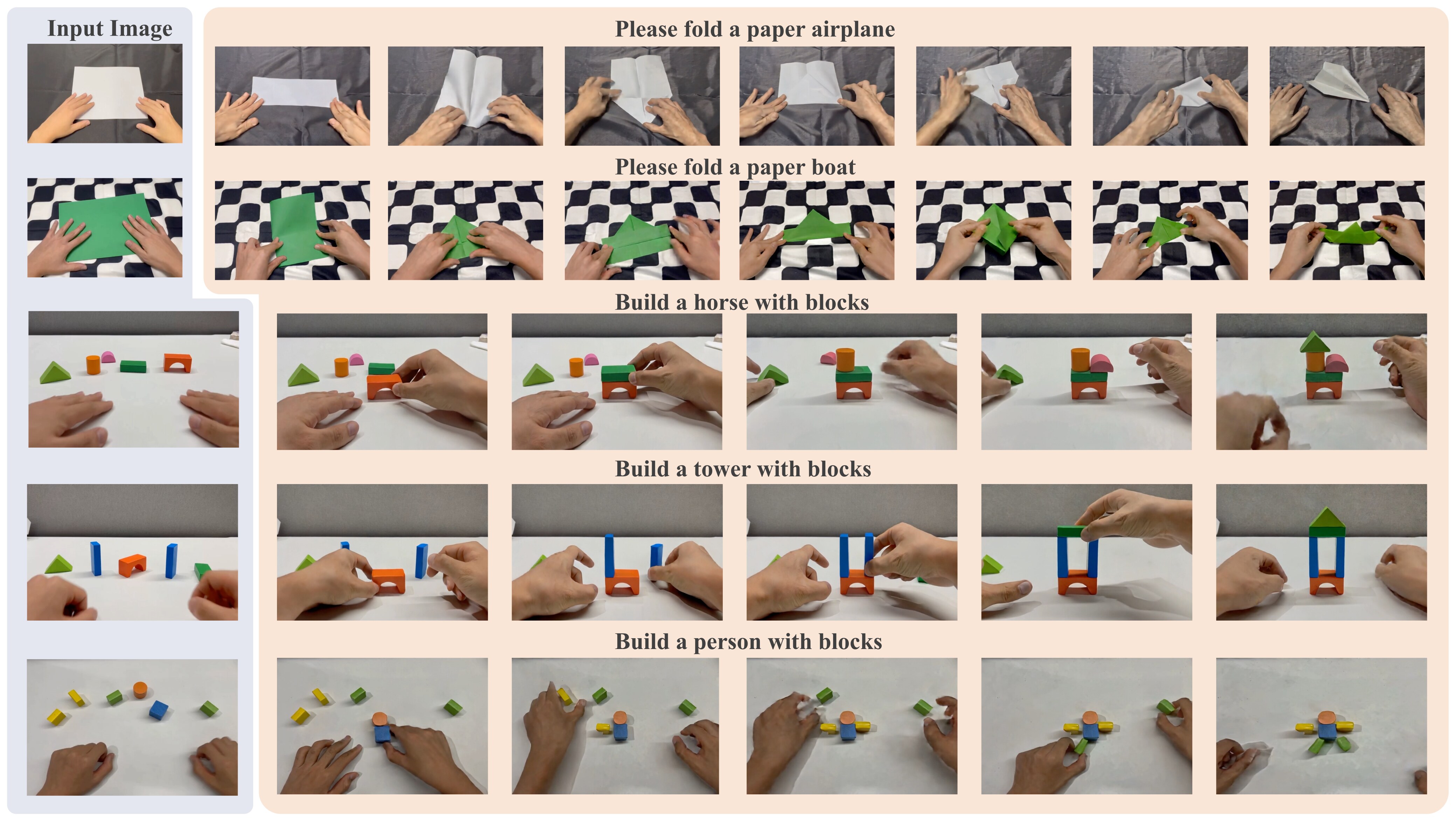 Figure 4:定性结果 —— VideoWorld 2 在 unseen 桌面 / 纸纹下能稳定走完 7 步折纸序列、最后产出可识别的纸飞机 / 纸船。这是 Wan2.2/HunyuanVideo 都做不到的。
Figure 4:定性结果 —— VideoWorld 2 在 unseen 桌面 / 纸纹下能稳定走完 7 步折纸序列、最后产出可识别的纸飞机 / 纸船。这是 Wan2.2/HunyuanVideo 都做不到的。
| Method | Fine-tuning | 折纸 step-1 | 2 | 3 | 4 | 5 | 6 | 7 | 积木 Human | Tower | Horse | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cosmos AR 4B | Craft-text | 68.4 | 56.7 | 11.5 | 3.3 | 0.0 | 0.0 | 0.0 | 10.1 | 18.0 | 12.0 | 0.643 | 0.312 |
| Cosmos DiT 2B | Craft-text | 73.4 | 63.3 | 20.0 | 6.7 | 0.0 | 0.0 | 0.0 | 24.2 | 21.3 | 19.7 | 0.680 | 0.264 |
| Hunyuan-13B | Craft-text | 76.9 | 68.1 | 27.5 | 5.8 | 0.0 | 0.0 | 0.0 | 30.9 | 38.4 | 31.5 | 0.703 | 0.255 |
| Wan 2.2 14B | Craft-text | 81.2 | 75.0 | 30.4 | 10.6 | 0.0 | 0.0 | 0.0 | 39.7 | 42.6 | 34.1 | 0.719 | 0.237 |
| LAPA | Craft | — | — | — | — | — | — | — | — | — | — | — | — |
| Moto | Craft | 19.1 | 11.7 | 3.3 | 0.0 | 0.0 | 0.0 | 0.0 | 11.5 | 10.1 | 9.8 | 0.585 | 0.394 |
| AdaWorld | Craft | 43.6 | 39.8 | 27.4 | 10.8 | 0.0 | 0.0 | 0.0 | 20.7 | 13.1 | 15.0 | 0.611 | 0.378 |
| VideoWorld | Craft | 70.3 | 66.7 | 42.5 | 21.3 | 6.7 | 0.0 | 0.0 | 23.8 | 33.9 | 27.8 | 0.680 | 0.351 |
| VideoWorld 2 | Craft | 97.2 | 95.3 | 90.0 | 83.3 | 81.4 | 74.6 | 68.8 | 70.0 | 81.5 | 80.9 | 0.770 | 0.205 |
| iVideoGPT | OpenX & Craft | 23.1 | 18.7 | 13.3 | 3.7 | 0.0 | 0.0 | 0.0 | 15.3 | 11.0 | 12.6 | 0.588 | 0.390 |
| Moto | OpenX & Craft | 43.1 | 35.3 | 30.7 | 25.5 | 18.3 | 9.7 | 0.0 | 17.4 | 15.3 | 16.0 | 0.596 | 0.387 |
| AdaWorld | OpenX & Craft | 49.5 | 41.6 | 34.8 | 30.7 | 22.3 | 19.8 | 13.0 | 37.4 | 29.8 | 29.1 | 0.624 | 0.365 |
| CoLA | OpenX & Craft | 83.5 | 74.4 | 69.1 | 64.8 | 52.3 | 49.8 | 40.2 | 54.1 | 52.4 | 49.9 | 0.668 | 0.289 |
| VideoWorld | OpenX & Craft | 91.7 | 75.0 | 68.2 | 63.1 | 51.7 | 48.2 | 31.9 | 47.3 | 52.7 | 49.8 | 0.601 | 0.389 |
| VideoWorld 2 | OpenX & Craft | 98.2 | 96.4 | 90.1 | 86.7 | 83.3 | 81.7 | 72.3 | 74.0 | 83.0 | 85.8 | 0.774 | 0.193 |
亮点:
- 不需要 OpenX 预训练 就能 step-7 达到 68.8%,已经把所有 baseline(含 SOTA VDM)甩开 30+ 个百分点。
- 加入 OpenX 后 step-7 进一步到 72.3% —— 增量虽不如别的 baseline 巨大(因为 baseline 起点本来就低),但 SSIM 0.770 → 0.774 / LPIPS 0.205 → 0.193 视觉质量稳步提升。
4.2 CALVIN(长序协议,5-task 链式)¶
| Idx | Method | Pretraining Type | Pretraining | Fine-tuning | 1 | 2 | 3 | 4 | 5 | Avg. Len. |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Transformer (Oracle) | — | — | ABCD→D | 80.9 | 55.6 | 44.5 | 31.3 | 24.6 | 2.36 |
| 2 | Transformer (Oracle) | — | — | 10% data | 50.5 | 35.4 | 20.1 | 5.2 | 0 | 1.11 |
| 3 | LAPA | Latent | ABCD→D | 10% data | 74.4 | 45.8 | 25.2 | 15.3 | 2.3 | 1.49 |
| 4 | VideoWorld 2 | Latent | ABCD→D | 10% data | 75.8 | 47.9 | 31.8 | 20.4 | 9.7 | 1.87 |
| 5 | Transformer (Oracle) | Video | OpenX | ABCD→D | 85.9 | 60.4 | 46.0 | 30.7 | 23.0 | 2.46 |
| 6 | LAPA | Latent | OpenX | ABCD→D | 84.0 | 58.8 | 46.2 | 35.4 | 27.0 | 2.51 |
| 7 | VideoWorld 2 | Latent | OpenX | ABCD→D | 88.5 | 64.6 | 55.8 | 47.5 | 30.9 | 2.88 |
关键观察:
- In-domain (10% data) 时,VideoWorld 2 latent pretraining 比 LAPA 同协议长 0.38 个 Avg.Len.,主要差距在 step-3 (31.8 vs 25.2) 和 step-4 (20.4 vs 15.3)。
- Cross-domain (OpenX → CALVIN) 时,VideoWorld 2 的 Avg.Len. 2.88 比 video-pretrained 同源 oracle (2.46) 还高 —— 说明 latent code 形态比 raw video token 更 transferable。
4.3 关键消融(Table tab:abla_arch + tab:abla_N + tab:abla_T + tab:abla_codebooksize + tab:abla_vdm)¶
(a) dLDM 架构 — 主消融
| Pretrained VDM | Decoder Stop-Grad | ControlNet 通路 | Paper | Block | LPIPS↓ |
|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | 0.0 | 28.5 | 0.312 |
| ✓ | ✗ | ✗ | 30.3 | 45.2 | 0.297 |
| ✓ | ✓ | ✗ | 47.3 | 54.7 | 0.275 |
| ✓ | ✗ | ✓ | 51.1 | 52.0 | 0.213 |
| ✓ | ✓ | ✓ | 68.8 | 77.5 | 0.205 |
把 VDM 加进来 → step-7 从 0% 到 30%;stop-grad → +17pp;ControlNet 通路再 +21pp。三件套缺一不可。
(b) Codebook size:8 → 50.4 (step-7) → 1000 → 68.8 (peak) → 4096 → 50.4 → 64k → 29.4。codebook 与 VideoWorld 1 不同(V1 用 64k 性能最佳),V2 因为不用承担 appearance 信息所以 1000 就够 —— codebook 越大反而越糟,作者归因为 "encoding extraneous noise 阻碍 dLDM 收敛"。
(c) Compression length \(T\):2 → 19.1 (step-7) → 9 → 55.4 → 49 → 65.3 → 93 → 68.8 → 177 → 69.0(饱和)。LAPA 类似的 2-frame 设置只到 19% step-7,再次说明短 horizon latent 撑不起 minute-long 任务。
(d) Query 数 \(N\):1 → 41.9 → 2 → 55.1 → 4 → 68.8 → 8 → 65.0。\(N=8\) 时 LPIPS 略降但 success 反退,"encoding noise"。
(e) VDM 训练策略:random init → 0.0;freeze → 31.7;LoRA → 50.9;full fine-tune → 68.8。预训练 prior 缺一不可,但还要全 fine-tune。
 Figure 5:baselines 在 Video-CraftBench 上的失败模式 —— Wan2.2 折出歪扭的纸张但步骤错乱、VideoWorld 1 在第 4-5 步开始出现"指头融化 / 桌面颜色漂移"、AdaWorld 频繁错位。这张图是 §5.2 critique 的直接 evidence。
Figure 5:baselines 在 Video-CraftBench 上的失败模式 —— Wan2.2 折出歪扭的纸张但步骤错乱、VideoWorld 1 在第 4-5 步开始出现"指头融化 / 桌面颜色漂移"、AdaWorld 频繁错位。这张图是 §5.2 critique 的直接 evidence。
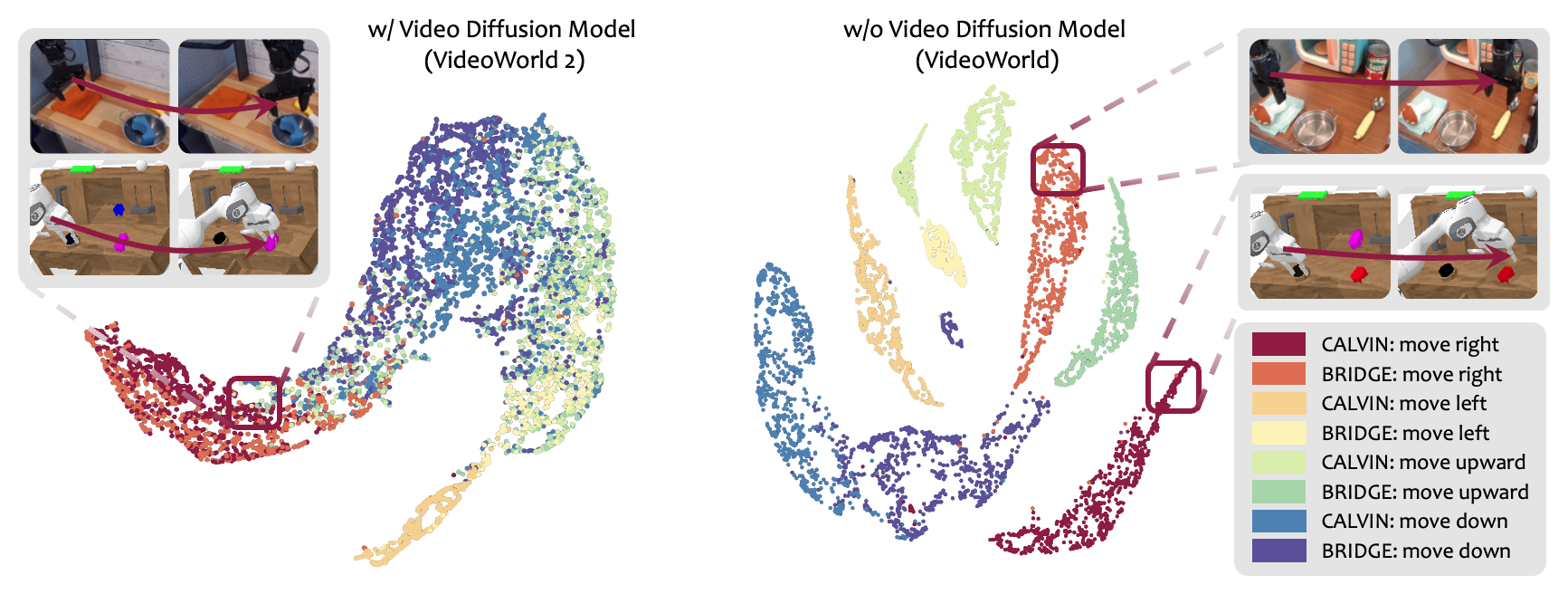 Figure 6:(左)有 VDM prior — 同一动作(向右移)在 CALVIN vs Bridge 两个环境的 latent code 在 UMAP 空间紧密聚类;(右)无 VDM — latent code 强烈按环境 cluster 而非动作。Visual 直观,但和 VideoWorld 1 的 UMAP 一样属于"软证据",详见 §5.2 critique 8。
Figure 6:(左)有 VDM prior — 同一动作(向右移)在 CALVIN vs Bridge 两个环境的 latent code 在 UMAP 空间紧密聚类;(右)无 VDM — latent code 强烈按环境 cluster 而非动作。Visual 直观,但和 VideoWorld 1 的 UMAP 一样属于"软证据",详见 §5.2 critique 8。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- "用预训练 VDM 承担 appearance 模型、迫使 latent code 专心 dynamics"是一个真正的架构级解耦。VideoWorld 1 的 LDM 用 reconstruction loss → latent 不得不编码外观;VideoWorld 2 把外观职责剥离给 VDM 后,latent vocabulary 从 64,000 缩到 1,000 都不掉点(甚至更好),这是直接证据,比单看 UMAP 可信得多。
- Stop-gradient 的 ControlNet 旁路:用 自己 VQ-VAE 解码器 的低保真输出作为 VDM 的 motion guidance,但梯度不回传到 latent —— 既给 VDM 一个稳定运动提示,又防止 reconstruction loss 反向污染 latent。Tab. abla_arch 的 row 3 vs 5 (+21pp) 单独验证了这个设计,非常工程化但有效。
- Warm-up + 切换训练 schedule:先让 dLDM decoder 单独训出"有运动但低保真"的 latent,再切到 disentangled 方案。如果直接 cold-start,作者明确说"slow and prone to incorrect motion"。这种"分阶段绕开局部解"的工程经验在论文里讲得很坦诚。
- Codebook 与 VideoWorld 1 反向调整:V1 上 codebook 越大越好(直到 262k 崩),V2 上 codebook 1000 即可、4k+ 即退化。这个反差自洽地支持了"V2 不再需要 latent 记忆外观"的论点,是一个 负面预测被验证 的例子。
- Long-horizon CALVIN 协议(5-task 链式 Avg.Len.)取代 V1 的独立 task 评估:作者主动选了对 latent 不利的协议(错一步全错)来评估自己 —— 一个研究者职业道德层面的小亮点。
- 公开和续作野心:自建 Video-CraftBench、配套训练 DINOv2 分类器评测 + 96.1% test accuracy + 25k 标注帧,作者明确表示要开源代码 / 数据 / 模型 —— 比"代码 coming soon"的 placeholder 类工作可信。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 真正的"无标注视频"声明被 Cosmos 4B + 2B 的预训练大模型偷渡了。论文反复强调"learn knowledge from unlabeled videos",但 AR 主干 Cosmos AR 4B 和外观 VDM Cosmos DiT 2B 都是已经在大规模 video-text pair 上预训过的模型。Cosmos 训练时显然包含 caption 监督。换句话说,本文的"无标注"只是 fine-tune 阶段无标注,预训练阶段的视觉先验是带语言监督的。和真正 from-scratch 的 VideoWorld 1 对比并不对等。
- VideoWorld 1 自家 baseline 在 Tab. 1 的表现存在 unfair 嫌疑。V1 (Tab. 1 row 8) step-7 = 0.0%,OpenX 预训后 31.9%。但 V1 原文 CALVIN 上能跑到 75% 单步 success,这里 30+ pp 的差距完全来自 "real-world handicraft vs synthetic" 域迁移失败。读者拿到这张表会以为 V1 "本来就崩",但实际 V1 的设计假设里从未 promised 真实世界泛化—— 这是 任务移到 V1 不擅长的领域 而非 V1 设计本身崩塌。需要更平衡的 framing。
- DINOv2 评估分类器的训练数据包含"所有 model 生成的 successful trajectory" 各 10k 帧。这意味着分类器在评估时见过 VideoWorld 2 风格的成功状态。即便论文声称"only judges shape geometry"且 disregards appearance,但 96.1% acc 是在包含 model-generated 数据的 25k 集上得到的,跨方法公平性需要更多评估(比如只用 ground-truth-only 训练的 classifier 复测一遍)。
- OpenX 预训练后差距没那么大了 — Tab. 1 第二组里 CoLA (40.2% step-7) 是 VideoWorld 2 (72.3%) 的 56%。两者都用 VDM 做 disentanglement,差异只在 multi-frame vs 2-frame transition、是否复用 VAE decoder coarse motion。但 CoLA 是 concurrent work,并未必经过同等工程投入。"VideoWorld 2 通过 multi-frame + ControlNet 把 CoLA 拉开 30pp" 这个增量更像 implementation 调优而非范式优势。
- VDM full fine-tune —— 一旦 freeze 或 LoRA 都明显差(68.8 vs 50.9 vs 31.7)。这暴露一个隐性结论:所谓的"VDM 提供 appearance prior"并不是真的拿来用,而是把 VDM 当成"可适应的高容量 image-to-video 模型 + 适当的 init"。一个 2B DiT 全 fine-tune 在 480px / 93 帧 / 16 fps 下的训练 / 推理成本远超 VideoWorld 1,但论文连 GPU 时数都没给。
- 缺乏 latency / 计算成本数字。整个论文一字未提:训练 / 推理 GPU·hours、单步 latent 解码延迟、生成一段 93 帧视频需要的扩散 step 数、long-horizon 推理累积时间。一条 minute-long 折纸任务靠 segment-by-segment auto-regressive 拼,每段 5 秒就要跑一次 2B DiT,实用性如何?读者无从判断。这一点对工程读者来说是最大的盲区,VideoWorld 1 至少给出了 8×A100 / 4 天的训练成本,V2 反而退步。
- 真实世界 ≠ 真实部署。"Real-world videos" 在论文里指 互联网上的人类教程视频,不是真机器人执行。CALVIN 仍是仿真。所谓 "transferable knowledge" 还没在真机器人上验证 —— motivation 里"小孩看视频学折纸"的类比并没有成立到"机器人看视频学折纸",模型生成的只是另一段视频,不是机器人动作。这是 V1→V2 共同的根本局限。
- UMAP 可视化继承自 V1 的方法学陋习。Fig. umap 看上去很说服人 —— "同动作跨环境聚类"。但 UMAP 的聚类强烈依赖参数(n_neighbors / min_dist)和数据子采样,作者随机选 4000 trajectory、按粗粒度 4 类(up/down/left/right)打标签。这个证据强度比 quantitative ablation (Tab. abla_arch row 2 vs 1: 30pp gain) 弱很多,但被放在叙事中心位置。
- CALVIN cross-domain "OpenX 预训练" 与 "video 预训练 oracle" 的对比并不完全干净。Tab. 2 idx 5 是 video next-token 预训练 / idx 7 是 latent 预训练,两者都基于 OpenX 1.3M,但 idx 5 用 raw video tokens 训 transformer,idx 7 用 latent codes 训 transformer。latent 序列短得多,模型容量分配差异巨大,不能简单归因为"latent 更 transferable"。
- 没有讨论 latent code 的语义可解释性。V1 上作者尝试通过 LDM decoder 把 code 重渲染来 inspect "模型在想什么",V2 里这条 inspect path 被 VDM 吃掉了 —— latent code 解出来的全部交给 VDM 渲染外观,反而比 V1 更黑箱。Fig. dldm_vis("video clips with similar latent dynamic features")尝试做点定性补救,但很有限。
- CoLA 比较的引用:Tab. 1 把 CoLA 归类到 concurrent work,文中也明确强调"CoLA 也用 VDM 但限于 2-frame"。问题是 CoLA 的原始论文里并没有针对 long-horizon 任务 —— 作者把 CoLA 应用到自家 benchmark、得到 40.2% step-7,然后说"validates our design"。把别人的方法搬到自己 benchmark 上跑得不如自己,是论文学界很常见的 contestable framing。
5.3 值得继续探讨的方向¶
- 真机器人部署:把 dLDM 输出 + small action head 接到真机器人 manipulation 上(V1 都没做、V2 也回避)。本文的全部 motivation 都指向"从人类视频学折纸然后让机器人折",但 step 0 仍未完成。
- VDM 端的高效化:能否用蒸馏(如 Wan2.2 → 1B distilled)把 VDM 降到 0.5B 量级,同时维持 long-horizon 一致性?
- Latent code 的因果可解释:能否用 mechanistic interpretability 技术分析 4 个 query 各自承担什么 dynamic(V1 用 intervention 已开了头)?
- 多模态条件:VideoWorld 2 用 first frame + text 作为 transformer 条件,能否加入 force / tactile / audio?
- 长 horizon 一致性:作者承认 segment 拼接会逐渐 drift 颜色 / 光照(appendix),是否能引入 episode-level latent identity loss 强制长序一致?
- VDM 自蒸馏到 dLDM:既然 full FT VDM 就是关键,能否把 VDM 蒸馏到 dLDM 自身,去掉 Cosmos 依赖?
- 公平 baseline:把 V1 在 V2 的 dLDM 配置(保留 V1 的 LDM 但换 Cosmos AR 4B 主干)做一组消融,区分 "AR 主干升级" 与 "dLDM 解耦" 各自的贡献。
- CoLA 的限制是否真的来自 2-frame? 在 CoLA 配置上把 transition window 从 2 扩到 93,是否就能补齐与 V2 的 30pp gap?这才是真正干净的 disentanglement vs window-size ablation。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页:https://maverickren.github.io/VideoWorld2.github.io/
- 前作:VideoWorld (2501.09781)
- 关键 baseline / 相关论文:CoLA (wang2025coevolvinglatentactionworld), LAPA (lapa_ye2024latent), Moto (chen2025moto), AdaWorld (adaworld), iVideoGPT (wu2024ivideogpt), Cosmos (agarwal2025cosmos), Wan 2.2 (wan2025wan), HunyuanVideo (kong2024hunyuanvideo), ControlNet (zhang2023control), VideoWorld 1 (ren2025videoworld)