MEM: Multi-Scale Embodied Memory for Vision Language Action Models¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:MEM: Multi-Scale Embodied Memory for Vision Language Action Models
- 作者:Marcel Torne*, Karl Pertsch*, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z. Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, Karan Dhabalia, Michael Equi, Quan Vuong, Jost Tobias Springenberg, Sergey Levine, Chelsea Finn, Danny Driess — Physical Intelligence (主)、Stanford、UC Berkeley、MIT
- arXiv 编号:2603.03596(2026-03 提交;技术报告 + blog post 风格 IEEE 模板)
- 项目页:pi.website/research/memory
- 关键词:VLA、memory、video encoder、language memory、long-horizon manipulation、π₀.₆、in-context adaptation、space-time separable attention
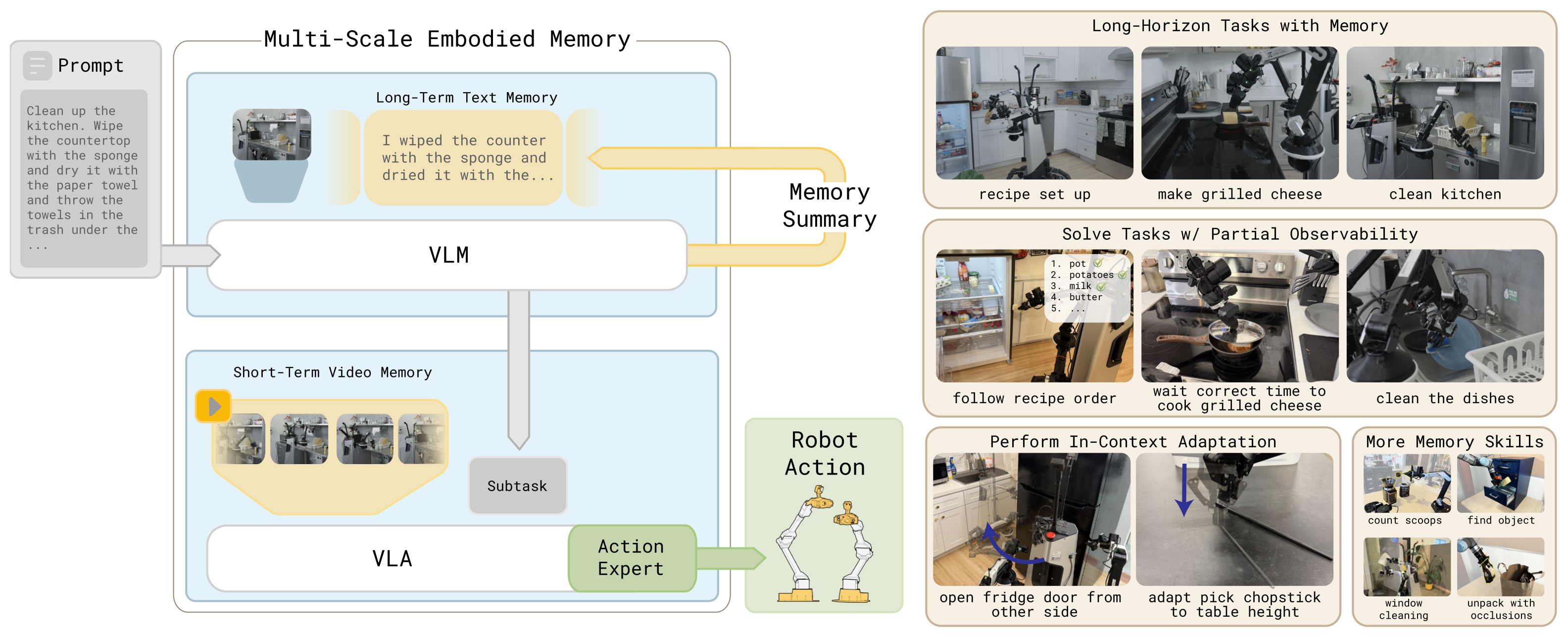 Figure 1:MEM 给 VLA 装上两个量级的记忆 —— video encoder 编码短时高保真观测(处理 occlusion、grasp 调整),language memory 用自然语言压缩长时语义事件(recipe 走到哪一步、抹布擦过哪些地方)。组合后政策能解决 ~15 分钟的厨房清洁、煎芝士三明治这类多阶段任务。
Figure 1:MEM 给 VLA 装上两个量级的记忆 —— video encoder 编码短时高保真观测(处理 occlusion、grasp 调整),language memory 用自然语言压缩长时语义事件(recipe 走到哪一步、抹布擦过哪些地方)。组合后政策能解决 ~15 分钟的厨房清洁、煎芝士三明治这类多阶段任务。
2. 文章介绍¶
2.1 解决的领域和问题¶
VLA(vision-language-action model)做 long-horizon manipulation 时绕不开 memory 问题:政策需要同时记住「短期:刚才那只手挡住的杯子在哪里、上一次抓滑掉了所以要调整 grasp height」,与「长期:菜谱已经做到哪一步、哪些柜门已经关过、桌子的哪一块已经擦过」。直接把整段历史观测塞进 transformer context 在 latency 和 GPU 内存上都不可行 —— 一个 15 分钟、4 路 camera、若干帧/秒的 task 直接爆炸。
业界目前的「memory VLA」要么只接受 short-horizon 几帧观测、要么用 proprioceptive history / 2D point traces / 单纯自然语言这类单模态压缩做 long-horizon,每种都有显著盲点。本文回答的问题是:有没有一个能同时跨「秒级 → 十几分钟」两个 scale 的 memory 架构,且在 real-time latency budget 内可部署?
2.2 Motivation¶
核心观察:不同时间尺度的 memory 需要不同的表示模态。
- 几秒内的 memory:需要稠密的视觉信息来 resolve self-occlusion、估计环境与机器人 dynamics、做 in-context 的策略调整(如换一种 grasp)。
- 几分钟到十几分钟的 memory:往往只需要少量 bits 的语义信息就够了("我已经把三个碗放进了右上柜子"),用语言做 lossy compression 极合适。
把这两种记忆正交分解到 video 与 language 两条路径上,长时记忆几乎不占 token budget、短时记忆又保留了像素级细节 —— 这是 MEM 的中心思路。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 无 memory VLA | π₀, π₀.₅, GR00T-N1, Gemini Robotics, OpenVLA | 无法处理 occlusion、不能跨 subtask 累积,长程任务必然失败 |
| Dense observation history | RT-2、Octo、Behavior Transformer 类 | latency 随 K 线性甚至超线性爆炸,>10 timestep 已超过 200 ms real-time 阈值 |
| Latent memory(attention pooling 等) | CronusVLA, MemoryVLA, SAM2Act | 只在 short-horizon memory tasks 验证,未触及十几分钟级别 |
| Proprio-only memory | TA 系列 | 只能记自身状态,环境状态("对象在哪个抽屉里")记不住 |
| 2D point-track / keyframe memory | TraceVLA, MEMER, BPP | 丢失 grasp 角度/高度等精细信息;keyframe 必须激进稀疏化 |
| Language-only memory | OneTwoVLA | 适合长时语义但短时 occlusion / dynamics 信息丢光 |
| Causal-confusion 缓解 | DiffusionCC, learning-from-corrections | 是辅助 loss,不是 memory 架构本身 |
2.4 论文解决方案(一句话)¶
MEM = 一个高效 video encoder(每 4 层 ViT 加 space-time separable 因果时序 attention、零新增参数、可由单帧 ViT 完美初始化)做秒级视觉记忆 + 一个 high-level policy 自己产出/更新自然语言记忆 \(m_t\) 做分钟级语义记忆,两者一起挂到 π₀.₆ VLA 上。
2.5 与前序工作的关系¶
- 直接前身:π₀.₆ VLA(Physical Intelligence,2025-11,5B 参数 = Gemma3-4B VLM + 860M flow-matching action expert + FAST discrete action tokens)。π₀.₆ 本身无 memory;MEM 给它加上 history encoder,得到内部记作 \(\pi_{0.6}^{\text{mem}}\) 的 VLA。
- 直接后继:π₀.₇(2604.15483)直接 基于 π₀.₆-MEM 架构做 diverse context conditioning,把 MEM 的 history encoder 当成标配组件,并加入 subgoal images。可以说 MEM 是把 video history 引入 π 系列主线的关键一步。
- video encoder 取材:space-time separable attention 来自 ViViT / TimeSformer (Bertasius 2021, Arnab 2021) 的视频理解传统,但被剪裁到 robotics 的 latency 约束下。
- language memory 沿用 high-level / low-level policy 拆分这一惯例(π₀.₅ 早已采用),novelty 在于让 high-level policy 同时预测更新后的 memory string \(m_{t+1}\),相当于把"记忆维护"显式做成 action。
- 实时推理:依赖 π 系列自家的 RTC(Real-Time action Chunking,Black 2025 a/b)做异步执行。
3. 方法介绍¶
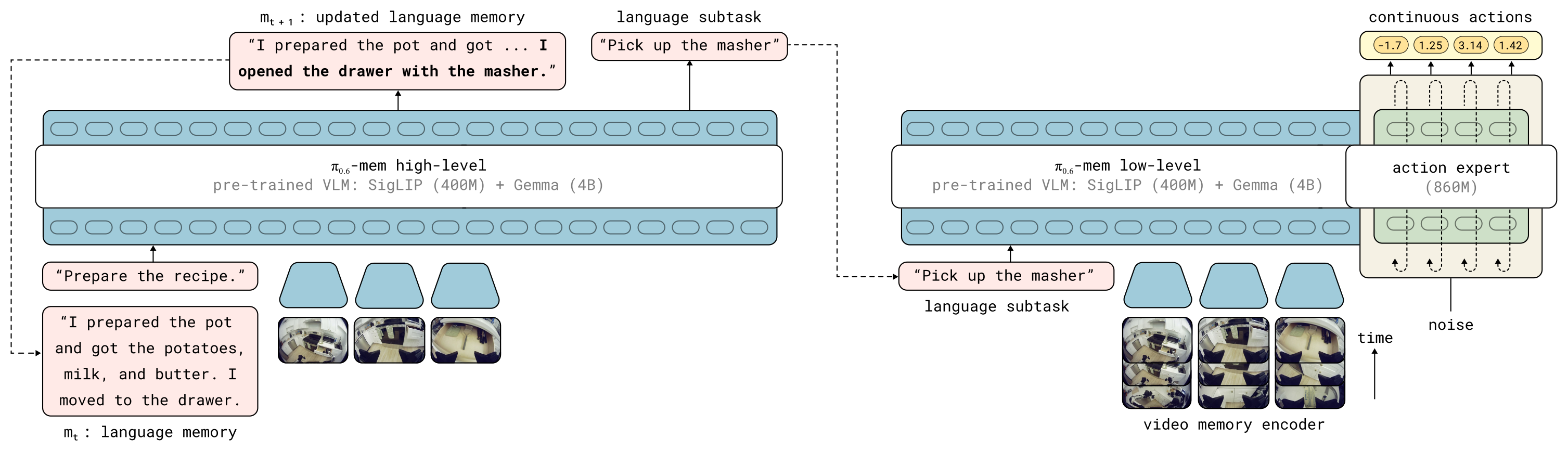 Figure 2:MEM 把策略分解成两条流:左侧 high-level policy 接收当前观测 \(o_t\)、上一段 language memory \(m_t\)、任务目标 \(g\),输出下一个 subtask 指令 \(l_{t+1}\) 与更新后的 language memory \(m_{t+1}\);右侧 low-level policy 接收稠密近期观测 \(o_{t-K:t}\)(经 video encoder 压缩)、subtask \(l_{t+1}\)、目标 \(g\),输出 action chunk \(a_{t:t+H}\)。
Figure 2:MEM 把策略分解成两条流:左侧 high-level policy 接收当前观测 \(o_t\)、上一段 language memory \(m_t\)、任务目标 \(g\),输出下一个 subtask 指令 \(l_{t+1}\) 与更新后的 language memory \(m_{t+1}\);右侧 low-level policy 接收稠密近期观测 \(o_{t-K:t}\)(经 video encoder 压缩)、subtask \(l_{t+1}\)、目标 \(g\),输出 action chunk \(a_{t:t+H}\)。
3.1 形式化¶
目标策略 \(\pi(a_{t:t+H} | o_{t-T:t}, g)\) 直接吃 \(T\) 帧观测在长程任务下不可行。论文做如下因子分解:
其中 \(K \ll T\)。关键 novelty:\(\pi_\text{HL}\) 同时预测 next subtask \(l_{t+1}\) 与 next language memory \(m_{t+1}\) —— 把 memory 维护本身做成 policy 的输出。
3.2 Language Memory(long-term)¶
\(m_t\) 是一段自然语言,由 LLM 训练数据 + high-level policy 在 inference 时自迭代产生。例:
\(m_t\):
I placed a plate in the cabinet and moved to the counter.⇩
\(m_{t+1}\):
I placed a plate in the cabinet, moved to the counter, and picked up a bowl.
训练数据制作:对每段带 subtask 标注 \(l_{0:T}\) 的机器人 episode,把所有 subtask + 是否成功标记输入一个 off-the-shelf LLM,让它写出"对未来执行还相关的"摘要 \(m_t\) —— 这就是 high-level policy 的 supervision。
核心 trick:明确教 LLM 做 compression。例如把 "I put a light green bowl, a dark blue bowl and a bright yellow bowl into the top right cabinet" 压成 "I placed three bowls in the top right cabinet"。理由: 1. 推理时 prompt 短 → latency 低。 2. 减小 train-inference distribution shift:训练数据多是 near-optimal 人类示范,每个 subtask 只说一次;inference 时政策可能反复失败、反复重发同一 subtask("pick up bowl → pick up bowl → pick up bowl"),naive 全量 concat 历史会让 high-level 看到训练时从没见过的"重复"模式 → 性能崩塌。MEM 的 memory 只在 subtask 成功完成后才 update,天然把失败重试抹掉。
3.3 Video Encoder(short-term)¶
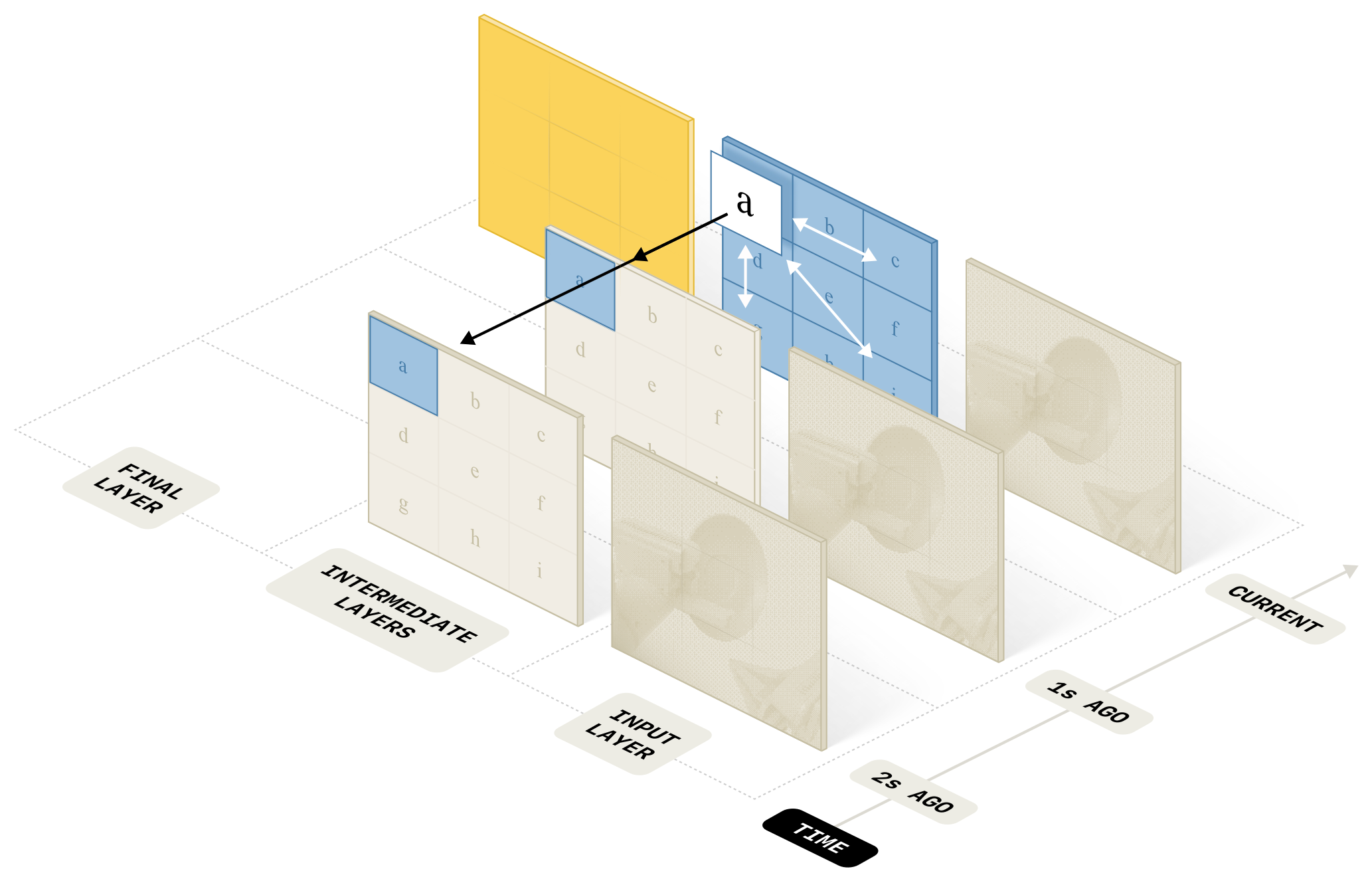 Figure 3:把标准 ViT 改造成视频编码器 —— 大多数层只在 image patch 之间做 bidirectional spatial attention(白箭头),每 4 层额外做一次 causal temporal attention(黑箭头,跨 timestep、同一 patch 位置)。Upper layers 把过去 timestep 的 token 全部丢掉,只让当前帧的 token 进 VLA backbone。
Figure 3:把标准 ViT 改造成视频编码器 —— 大多数层只在 image patch 之间做 bidirectional spatial attention(白箭头),每 4 层额外做一次 causal temporal attention(黑箭头,跨 timestep、同一 patch 位置)。Upper layers 把过去 timestep 的 token 全部丢掉,只让当前帧的 token 进 VLA backbone。
关键设计¶
- Factorized space-time attention:把朴素的"时空全连"注意力 \(\mathcal{O}(n^2 K^2)\) 拆成空间 + 时间两次单独的 attention,复杂度降到 \(\mathcal{O}(K n^2 + n K^2)\)(\(n\) = spatial patch 数, \(K\) = 历史帧数)。空间 attention 是 ViT 原有的双向;时间 attention 用 causal mask,只关注 same-patch 在过去 timestep 的表示。
- 每 4 层加一次时间 attention:取自 ViViT/TimeSformer 经验值,论文未做这个间隔的 ablation。
- 后段层丢掉过去 timestep 的 token:上层 ViT 中只保留当前帧 patch → 喂给 VLA backbone 的 token 数与单帧 ViT 完全相同。强制模型在前段层就把时序信息抽进当前帧 patch 表示。
- 零新增参数:复用原 ViT 的 \(W_Q, W_K, W_V\)、LN 等,额外只加 sinusoidal temporal position embedding \(e(t)\),且约束 \(e(0) = 0\) —— 这样 \(K=1\)(单帧输入)时 encoder 严格退化为原 VLM 的 ViT,可由 pre-trained 权重无损初始化。
- 数学定义(见附录 7.3):
attention 用 separable 串联:先时间(causal、跨 \(t\))后空间(双向、跨 \(p\))。
推理延迟(论文最关键的工程论证)¶
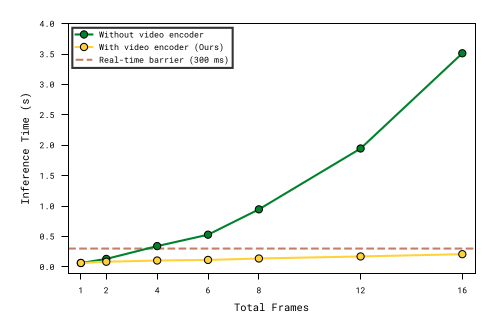 Figure 4:在单张 H100 + 4 路相机下,朴素地把多帧观测各自编码再拼进 VLA backbone(橙线),latency 随帧数近线性爆炸;MEM 的 video encoder(紫线)在 18 帧时仍保持 ≲100 ms,落在 RTC 的实时阈值内。
Figure 4:在单张 H100 + 4 路相机下,朴素地把多帧观测各自编码再拼进 VLA backbone(橙线),latency 随帧数近线性爆炸;MEM 的 video encoder(紫线)在 18 帧时仍保持 ≲100 ms,落在 RTC 的实时阈值内。
3.4 集成到 π₀.₆ — \(\pi_{0.6}^{\text{mem}}\)¶
- Backbone:Gemma3-4B VLM。
- Action expert:860M 参数 flow-matching expert,配合 FAST discrete action token 训练(Driess 2025 的双训练目标)。Action expert 的梯度不回流到 VLM backbone。
- 输入:448×448 px 每路,最多 4 路 camera。
- Proprioceptive state memory:π₀.₆ 原本把状态以文字 token 表示,但 sequence of states 会让 token 数线性增长。MEM 改用 linear projection 把每个 state 嵌入 backbone embedding space,每帧只占 1 个 token。
- 数据 mix(pre-training):teleop 演示 + policy rollouts + human corrections(同 π₀.₅/π₀.₆ 配方) + VL tasks + video-language tasks(video captioning 等,非机器人 video data)。
- 训练时观测窗口:6 帧(5 过去 + 当前),间隔 1 秒 = 5 秒短时记忆窗。
- Post-training expansion:训练时窗口可灵活扩展到 18 帧 / 54 秒(间隔 ~3 秒),类似 LLM 上下文窗口扩展(Chen 2023)。这一步是 MEM 能撑到「分钟级」短时记忆的关键 ——pre-train 5 s, post-train 54 s 视频 + language memory 串成更长时尺度。
- 实时推理:所有 on-robot 实验用 RTC(inference-time 或 training-time)做异步 action chunking。
3.5 Implementation Details¶
- 单 H100 GPU 上推理。
- 训练硬件、step 数、batch size、学习率 —— 论文未披露(典型 PI 技术报告做法,不公开 hyperparams)。
- Language memory 的 LLM 标注模型未具体说明哪个;只说"current generation LLMs are effective"。
- High-level policy 与 low-level policy 共享 backbone(两者都是 π₀.₆,high-level 输出 text,low-level 输出 action)。这一点论文里没明说但从 architecture overview + π₀.₅ 惯例可推。
4. 结果对比¶
所有评测都是 PI in-house,每个 task / recipe 10 rollouts,报告 mean ± SE。没有任何公共 benchmark 数字(LIBERO / CALVIN / SimplerEnv 全无)。
4.1 长程任务(15 分钟级)¶
任务:Recipe Setup(拿出 42 个 recipe 的全部食材+器具,eval 用未见 kitchen + 未见 object 上的 5 个 recipe,6-7 subtasks/recipe);Clean up Kitchen(擦台面、入冰箱、洗碗、收烘干架,约 8 subtasks/episode)。
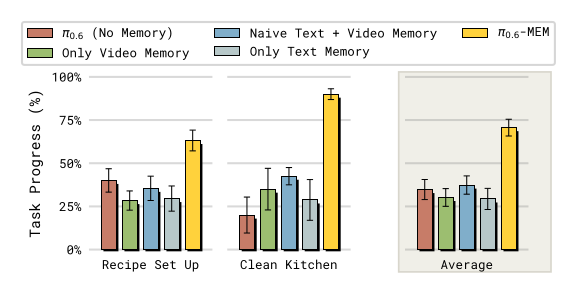 Figure 5:去掉 video memory 或去掉 language memory,长程任务成功率显著下降;"naive" language memory(直接拼接历史 subtask,不让模型 compress)反而比无 language memory 更差,因为 train-inference distribution shift。
Figure 5:去掉 video memory 或去掉 language memory,长程任务成功率显著下降;"naive" language memory(直接拼接历史 subtask,不让模型 compress)反而比无 language memory 更差,因为 train-inference distribution shift。
| 配置 | Recipe Setup | Clean Kitchen |
|---|---|---|
| π₀.₆-MEM (Ours) | 最高 (具体数值见图 5) | 最高 |
| − Video memory | 明显下降 | 明显下降(卡在某个 subtask 不前进) |
| − Language memory | 明显下降(无法跨 subtask 积累) | 明显下降 |
| − Compression (naive language) | 比无 language memory 还差 | 比无 language memory 还差 |
| π₀.₆(无 memory) | 严重失败 | 严重失败 |
(论文里数字以 bar chart 形式呈现,无 numeric table。下同。)
4.2 In-Context Adaptation¶
任务:Chopstick Pickup(OOD 桌面高度 → grasp 高度需要在线调整)与 Open Fridge(开门方向不确定,需要"上一次试错了换方向")。Training data 由"人工干预 + 修正示范"组成,故意把失败那一段保留在 short-horizon memory 里。
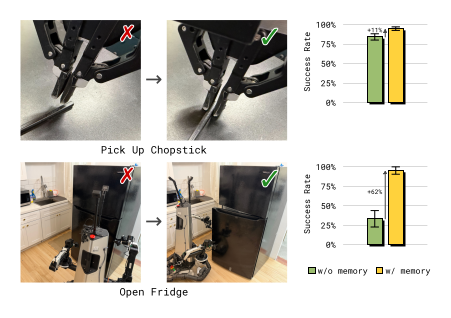 Figure 6:有 memory 的政策能"看到自己刚才失败了"并切换策略(grasp 高度、开门方向);无 memory 的政策反复重试同一种失败。
Figure 6:有 memory 的政策能"看到自己刚才失败了"并切换策略(grasp 高度、开门方向);无 memory 的政策反复重试同一种失败。
| 任务 | π₀.₆ (no mem) | π₀.₆-MEM |
|---|---|---|
| Chopstick Pickup | 低(反复在 OOD 桌高 mis-grasp) | 显著更高 |
| Open Fridge | 低(≤4 grasps 内开门成功率低) | 显著更高 |
4.3 Memory Capability Ablations(核心 baseline 对比)¶
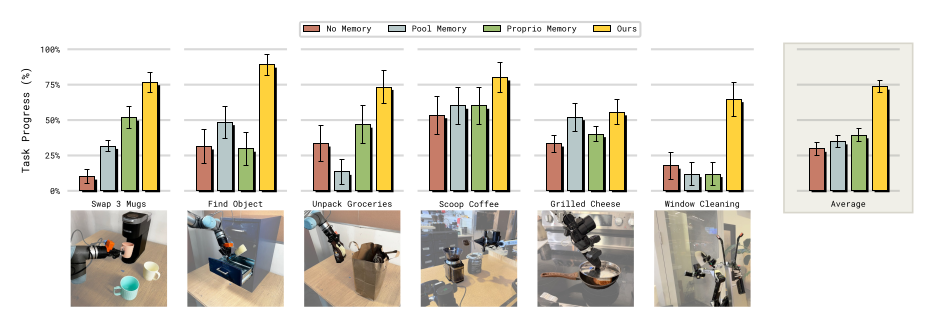 Figure 7:跨 partial observability / counting / spatial memory 三大类任务,MEM 是唯一在所有类别都强的方案。Pool-Memory 只在简单任务(少 bit)表现好、Proprio-Memory 只在记自身状态的任务表现好。
Figure 7:跨 partial observability / counting / spatial memory 三大类任务,MEM 是唯一在所有类别都强的方案。Pool-Memory 只在简单任务(少 bit)表现好、Proprio-Memory 只在记自身状态的任务表现好。
Baselines(都重实现在 π₀.₆ backbone 上,公平起见 MEM 这一栏关掉 language memory):
| Baseline | 思想 | 短板 |
|---|---|---|
| π₀.₆(no memory) | SOTA non-memory VLA | Find object 全靠瞎猜 (25%)、scoop 50% |
| Pool-Memory | 历史观测各自编码后 avg-pool 成 1 个 token (Jang 2025) | 信息压得太狠,长时观测必要的任务(mug 顺序、grocery 剩余)做不了 |
| Proprio-Memory | 只用本体状态历史 (Zhang 2025) | 环境状态记不住 |
| MEM (no language memory) | Video encoder,全程 pre-train | 唯一全类全强 |
| MEM-Posttrain-Only | Video encoder 只在 post-train 加(类似 CronusVLA) | 显著弱于全程 pre-train(见图 8) |
4.4 Pre-training 必要性¶
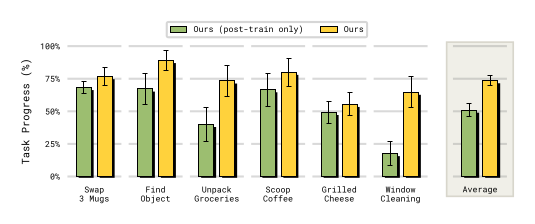 Figure 8:把 MEM 的 video encoder 只在 post-training 加(从 π₀.₆ checkpoint fine-tune)显著弱于全程 pre-train + post-train。即使 pre-train 用 5 s window、post-train 扩到 60 s,pre-train 的 memory exposure 不可替代。
Figure 8:把 MEM 的 video encoder 只在 post-training 加(从 π₀.₆ checkpoint fine-tune)显著弱于全程 pre-train + post-train。即使 pre-train 用 5 s window、post-train 扩到 60 s,pre-train 的 memory exposure 不可替代。
4.5 不需要 memory 的任务上不掉点¶
跨 box building、shirt folding、bed making、batch folding 等灵巧任务,π₀.₆-MEM ≈ π₀.₆。这点不平凡 —— 既有 memory VLA 文献多次报告加 memory 导致 causal confusion / performance degradation;MEM 作者归因于大规模多样化 pre-training data(含失败 episode、不同 control frequency、互联网 video)抑制了"复制上一步动作"这种 spurious 关联。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- Memory 模态正交分解 = 真正的 architectural insight。把"15 分钟里发生的事"完全用 token-cheap 的自然语言记,把"刚才几秒"用 pixel-rich 的 video 记,二者预算互不抢占;这是单模态 memory(无论是 image-only、proprio-only 还是 language-only)走不通的角落。
- Video encoder 的零新增参数 + \(K=1\) 完美回退。\(e(0)=0\) 的 sinusoidal temporal embedding 保证单帧输入下与 pre-trained ViT bit-equivalent,意味着可以直接复用任何标准 VLM 的 vision tower、无需 video pre-training,且对 single-frame 下游性能严格 invariant。这种"feature transfer 无损"工程性质极重要 —— pre-trained ViT 上的几十亿训练 step 不丢。
- Memory 维护被显式做成 high-level policy 的 action。让模型自己决定"什么时候 update memory、压成什么样",而不是用外部 LLM 在 inference 时插一脚。这避开了两段管线的 latency 累加,也让 train-inference distribution shift 在训练时就被处理。
- Pre-train 与 post-train 的 window 解耦。Pre-train 5 s、post-train 54 s,比直接 pre-train 长窗口便宜得多,且实证显示性能不下降 —— 与 LLM context extension 的经验一致,把这个 trick 平移到 VLA 来。
- Compressed language memory 的 distribution-shift 论证既具体又有实验支撑。"naive concat" vs "LLM-compressed summary" 是一个干净的实验对照,且现象(重复 subtask → train 时没见过)与 mechanism(compression discards failed attempts)解释一致。
- Strong negative baseline trick:故意把失败示范放进 short-term memory 来训 in-context adaptation。这把"看到失败 → 换策略"显式当 supervised signal 训进去,而不是寄希望 emergent。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 没有任何公共 benchmark。没有 LIBERO、CALVIN、SimplerEnv 数字,所有 ablation 都是 in-house tasks + 10 rollouts/policy;relative claim 可信、但 absolute claim("SOTA across diverse manipulation")只能内部对照。
- 关键对照不完全公平。Pool-Memory 与 Proprio-Memory 被重实现在同 π₀.₆ backbone 上,但不清楚它们是否也用了同样的 pre-training 数据 mix。MEM 强调 pre-training 中含互联网 video 是关键,而 Pool-Memory 原文也用 video pre-train。如果对照 baseline 没获得同等 video pre-training,则"我们的 encoder 设计本质上更好"的论点被 pre-training mixture 污染。论文里只说"to ensure fair comparison, we re-implement..."—— 措辞模糊。
- "15 minutes of memory":标题/abstract 大字标榜 15 分钟,但论文里没有给出真正的 15-min 单 episode trace 或 success-vs-elapsed-time curve;最长任务(grilled cheese, clean kitchen)确实可以 take 长时间,但每段实际有效的 memory horizon 多深、有没有 forgetting,没量化。
- Language memory 的 LLM 选择被完全藏起来。Memory supervision 完全依赖 off-the-shelf LLM 写的"compressed summary",但是哪个 LLM、prompt 长什么样、不同 LLM 给的 summary 一致性如何 —— 全没说。Training data 实质上是被这个 anonymous LLM "蒸馏"过来的,鲁棒性未知。
- High-level policy 失败的传播。Hierarchical 分解的老问题:若 \(\pi_\text{HL}\) 输出错 subtask 或错误 update \(m_t\)(例如把一个失败错写成成功),低层政策无法纠正。论文里完全没分析 high-level 与 low-level 的失败模式拆解。
- "每 4 层加 temporal attention" 的间隔没 ablation。这是核心架构超参数;论文只说"inspired by space-time separable attention"。改成每 2 层、每 8 层、所有层效果如何,未知。
- Causal confusion 主张依赖间接证据。声称"无 causal confusion 因为 pre-train data 多样" —— 但论文没设计专门的 causal confusion 测试(如训练 demo 全 demonstrator 走右、test 时强制走左),只能从"在不需要 memory 的任务上不掉点"反推。这是必要条件不是充分条件。
- Proprio state memory 用 linear projection 替代文字 token —— 与 π₀.₆ 解耦不彻底。π₀.₆ 原本用 text token 表示状态以利于 VLM-native 训练;MEM 因 token 预算压力切回 continuous embedding。这破坏了"状态可被 language token interrogate"的统一接口,是为了 memory 妥协的代价,未讨论。
- In-context adaptation 数据收集流程偷渡了 oracle 信号。需要"人工干预 + 演示修正"才能训出 in-context adaptation;这意味着不是 emergent,而是 supervised on failure-then-recovery pairs。论文标题"in-context adaptation"措辞偏强。
- Long-horizon language memory 的长度不受控。Memory string 理论上可以越攒越长(LLM compress 不一定单调),论文没给出 inference 时 \(|m_t|\) 的分布。如果在长 episode 末段 memory 长度爆掉,high-level latency 会暴涨。
- Recipe Setup 的"未见 kitchen":评测在"unseen kitchens、unseen objects、seen recipes"。完全 unseen recipe 的泛化没测,所以"open-world"程度有限。
- 不可复现。Closed weights、closed data、closed-source(同 π 系列所有论文)。
- 作者贡献分布暗示这是 sprint 集成工作:贡献名单显示 video encoder 与 language memory 由不同小组分别设计(DD/HW/JTS vs KP),然后 MT/KP/HW/KV/SN/ME 做评测。架构层面"为什么这两件套刚好对得上而不重叠/不冲突"的设计 rationale 没深入讨论。
5.3 值得继续探讨的方向¶
- 跨 episode / 跨 deployment 的 memory:MEM 仍是 within-episode memory,结论里作者自己点了 weeks/months scale 的 continual memory。这需要把 language memory 持久化到外部 store + retrieval 机制。
- Memory 能否反向蒸馏到 low-level policy:让 low-level 也能直接读 language memory(而不是只通过 subtask interface),潜在收益是去掉 hierarchical bottleneck,但代价是 token 预算。
- Self-correcting language memory:当 high-level 写错了 memory,是否能让模型在下次看到环境反例时主动 retract?目前 memory 是 append-and-compress,不存在 "I was wrong about closing the cabinet" 这种修正。
- 每 4 层 temporal attention 这件事 vs Mamba / SSM-style 时序建模:在 robotics 这种实时高频场景下,linear-time temporal mixing 可能比 attention 更适合。MEM 的 factorization 是好起点但不是终点。
- Memory-aware data collection:现有 robot demo 大多是 near-optimal 单遍执行,对应 language memory 训练数据稀薄("做过就忘")。专门收"失败重试 + 长 horizon 决策"的演示能否进一步放大 MEM 的 gain?
- In-context strategy library:在 Chopstick / Fridge 这样的 in-context adaptation 上,能否把"曾经成功的策略"做成 retrieval-augmented memory(不是当前的 raw video frame 重播),从而让 in-context strategy 跨 episode 复用?
- Subgoal image memory(与 π₀.₇ 的衔接):π₀.₇ 在 MEM 之上加了 generated subgoal images 作为 context;这相当于 video memory 的"未来侧"。研究 video history + subgoal future 之间的对偶性可能有意思。
- language memory 的 latency budget 与 OOM:当 \(|m_t|\) 增长时 high-level 推理会变慢;与 video memory 的预算如何 trade off,缺乏公开数据。
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:source/
- 项目主页:pi.website/research/memory
- 关键 baseline / 相关论文:
- π₀.₆ 模型卡 — 本文 VLA backbone 的直接基座(无 arXiv,PI blog post)
- π₀.₇(2604.15483)— 基于 π₀.₆-MEM 架构的下一代,文献中已用 MEM 当 history encoder 标配组件
- π₀.₅(2504.16054)— 引入 high/low-level policy + co-training 的前作
- FAST(2501.09747)— discrete action tokenization
- RTC(Black 2025a/b)— real-time async chunking,让长 video encoder 在机器人上可部署
- ViViT (Arnab 2021) / TimeSformer (Bertasius 2021) — space-time separable attention 的源头
- CronusVLA, MemoryVLA, SAM2Act — short-horizon latent memory VLAs
- OneTwoVLA — 纯 language memory baseline
- TraceVLA — 2D point-track memory baseline