GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning
- 作者: Shutong Ding, Ke Hu, Shan Zhong, Haoyang Luo, Weinan Zhang, Jingya Wang, Jun Wang, Ye Shi(ShanghaiTech / UESTC / SJTU / UCL)
- arXiv 编号: 2505.18763(submitted 2025-05,targeted at NeurIPS 2025)
- 项目主页: https://shanghai-guppy.github.io/genpoplusplus/
- 代码: https://github.com/wadx2019/genpo
- 关键词: on-policy RL, diffusion policy, flow matching, PPO, IsaacLab, exact diffusion inversion, EDICT, normalizing flow
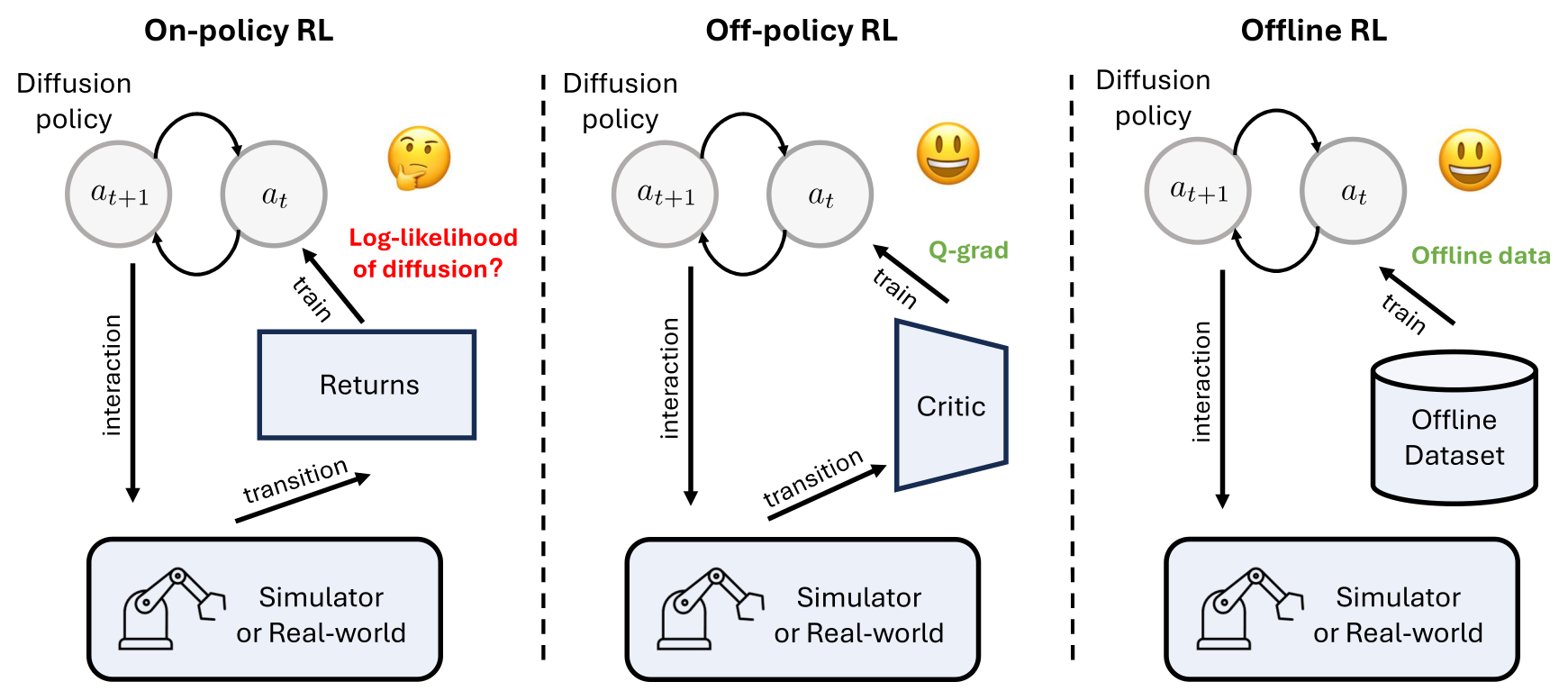 Figure 1:diffusion policy 的三种 RL 学习范式。off-policy(中)可用 Q 函数梯度回传更新;offline(右)用静态数据;on-policy(左)原本无法应用 — 因为 log-likelihood 不可解析得到。GenPO 要填的就是左侧这块空白。
Figure 1:diffusion policy 的三种 RL 学习范式。off-policy(中)可用 Q 函数梯度回传更新;offline(右)用静态数据;on-policy(左)原本无法应用 — 因为 log-likelihood 不可解析得到。GenPO 要填的就是左侧这块空白。
2. 文章介绍¶
2.1 解决的领域和问题¶
主线是 continuous-control RL 里的 policy parameterization 选择问题。传统 PPO 用 unimodal Gaussian 策略,表达力受限于单峰;扩散/flow policy 已被证明在 offline RL 和 off-policy RL 中能更好地拟合多模态最优动作分布,但没人把 diffusion policy 接进 on-policy PPO 框架。
而 on-policy 恰恰是当前 large-scale 并行 GPU 模拟器(IsaacGym, IsaacLab)的主流:成千上万个并行环境同步采样、同步更新,PPO 是 first-class citizen,off-policy 算法在巨大 replay buffer 的分布漂移下反而难以收敛。所以"扩散策略 + on-policy"的缺口直接堵住了 expressive policy 在主流机器人 sim2real pipeline 里的落地。
2.2 Motivation¶
核心矛盾:on-policy 的 surrogate objective 需要 explicit \(\log \pi_\theta(a|s)\)(用于 importance ratio、entropy bonus、KL 自适应),但 diffusion/flow policy 走的是迭代去噪 / ODE 积分,前向 (forward) 和反向 (reverse) 之间存在 Euler-Maruyama 离散化误差,导致 \(\log \pi\) 不可逆地求不出来。
作者的新角度:借鉴图像生成里的 EDICT(Exact Diffusion Inversion via Coupled Transformations),用一对耦合 noise vectors 交替更新构造真正可逆的去噪流程,从而能用 change-of-variables 公式精确算出 log-likelihood,把扩散策略带回到 PPO 一族的所有数学工具里(entropy 项、KL 自适应学习率、importance ratio clipping)。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 直接 policy gradient 套在 diffusion 黑盒上 | DACER, FlowPG, SAC-NF, TRPO-NF | 仍是 off-policy 框架;log-likelihood 用近似/启发式,无法保证在 on-policy 严格 importance sampling 下的无偏 |
| 用 Q 函数梯度/数值反推 diffusion 训练目标 | DIPO, QVPO, QSM, MaxEntDP | 不需要 log-likelihood,但只能用 Q 函数引导 — off-policy only;在 IsaacLab 这种巨量并行环境下 replay buffer 分布漂移使其难以收敛(论文表 1 中 DACER/QVPO 几乎学不出 Ant、Humanoid) |
| Diffusion 用于 offline / IL | Diffusion-QL, IDQL, FQL, Diffusion Policy, Decision Diffuser | 完全离线,无 online interaction;无法利用大规模并行模拟器 |
| 用 PG 微调离线预训练的 diffusion policy | DPPO | 是 fine-tune 而不是 from-scratch online RL,且依然需要绕过 likelihood 计算 |
2.4 论文解决方案(一句话)¶
用 EDICT 的耦合双噪声向量把 flow policy 的前向/反向过程构造成精确可逆映射,再把 MDP 重写到一个 doubled dummy action 空间里使可逆性成立,从而首次让 diffusion policy 拥有解析 log-likelihood,可以直接塞进 PPO 的 clipped surrogate、entropy bonus 和 KL 自适应学习率。
2.5 与前序工作的关系¶
- EDICT (Wallace et al., 2023):是方法上的直接来源 — image editing 里用耦合 noise 做精确逆扩散,本文把它从 inference-only 改造成"训练用 likelihood 估计"。关键差异:EDICT 用 \(x_0=y_0=\epsilon\)(同一个噪声);GenPO 独立采样两份噪声,才能套 change-of-variables 公式。
- Normalizing flow (Rezende & Mohamed, 2015):理论支撑 — 整个 log-density 计算依赖 Jacobian determinant 公式。
- PPO (Schulman et al., 2017):宿主框架,clipped surrogate / GAE / KL 自适应学习率原样照用。
- IsaacLab + RSL-RL:实验平台。GenPO 在 RSL-RL 里实现;baseline 在 SKRL 里实现。
3. 方法介绍¶
3.1 形式化¶
标准 MDP \((\mathcal{S}, \mathcal{A}, p, r, \rho_0, \gamma)\)。Policy 是一个 flow matching 策略:给定状态 \(s\),从 \(\mathcal{N}(0, I)\) 采初值,沿 learned vector field \(v_\theta(\cdot, t, s)\) 积分 \(T\) 步得到动作 \(a\)。问题:PPO 需要 \(\log \pi_\theta(a|s)\),但 Euler-Maruyama 离散化的前向/反向并不严格互逆 — 见 (eq:ddim) DDIM 的近似项。
3.2 EDICT-style 可逆耦合更新¶
引入两个状态变量 \((x_t, y_t)\),每个时间步交替更新:
Reverse(采样,\(t \to t+\Delta t\)): $$ \tilde{x}{t+\Delta t} = x_t + v\theta(y_t, t)\Delta t, \quad \tilde{y}{t+\Delta t} = y_t + v\theta(\tilde{x}{t+\Delta t}, t)\Delta t $$ $$ x} = p \tilde{x{t+\Delta t} + (1-p)\tilde{y}}, \quad y_{t+\Delta t} = p \tilde{y{t+\Delta t} + (1-p) x $$
Forward(反推 likelihood):先 unmixing 再倒推 vector field 即可逐步还原 \((x_0, y_0)\)。
这套耦合保证了每一步 Jacobian 都是闭式的、行列式可算(核心是因为更新 \(\tilde x\) 时只用了 \(y\),反过来只用 \(\tilde x\) — 是个 triangular 结构,类似 affine coupling layer)。
3.3 Doubled Dummy Action 空间¶
可逆耦合需要 \(x, y\) 两条 channel,但原 action 空间 \(\mathcal{A}\) 维度可能是奇数;作者直接把 MDP 改写到 \(\tilde{\mathcal{A}} = \mathcal{A} \times \mathcal{A}\) 上:
- 训练:策略输出 dummy action \(\tilde a = (x, y)\);
- 与环境交互时取 \(a = \frac{x+y}{2}\);
- 重参数后的 MDP 的最优解 \(\tilde a^\star\) 经平均映射回原 MDP 也是最优 — 显然成立。
新带来的问题:dummy action 空间是冗余的(\(\tilde a = (-1, 1)\) 和 \((-2, 2)\) 都对应 \(a=0\)),如不约束会导致无意义的探索,浪费样本。
解决:(1) 在 (eq:fpo_reverse) 的 mixing 步里用系数 \(p=0.9\) 让 \(x, y\) 互通信息保持靠近;(2) 加显式 compression loss \(\mathbb{E}[(x_1 - y_1)^2]\),让两个 channel 趋于一致。
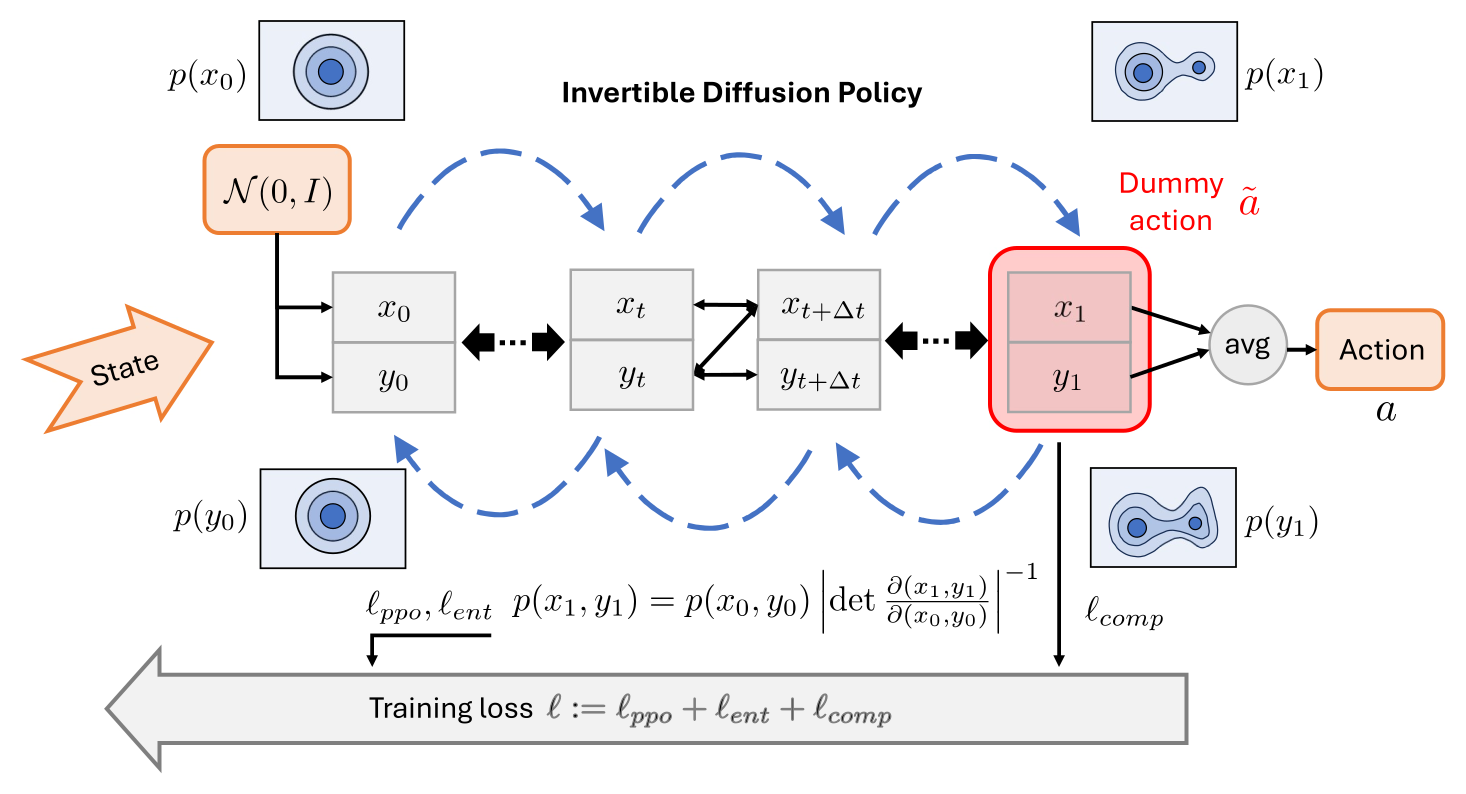 Figure 2:GenPO 的训练 (reverse) 和反推 likelihood (forward) 流程。每步 \(x\) 和 \(y\) 用对方在前一中间步的值更新,是 EDICT-style 双链耦合;mixing 步保证两链不偏离过远。这个图最该带走的一点是:可逆性来自"算 \(\tilde x\) 时不用 \(x\)、算 \(\tilde y\) 时不用 \(y\)"的 triangular Jacobian。
Figure 2:GenPO 的训练 (reverse) 和反推 likelihood (forward) 流程。每步 \(x\) 和 \(y\) 用对方在前一中间步的值更新,是 EDICT-style 双链耦合;mixing 步保证两链不偏离过远。这个图最该带走的一点是:可逆性来自"算 \(\tilde x\) 时不用 \(x\)、算 \(\tilde y\) 时不用 \(y\)"的 triangular Jacobian。
3.4 Likelihood / Entropy / KL 的解析估计¶
有了可逆性后,由 change-of-variables(Lemma 1): $$ \log \pi_\theta(\tilde a | s) = \log p_Z(\tilde a_0) - \sum_t \log \left|\det \frac{\partial \tilde a_{t+\Delta t}}{\partial \tilde a_t}\right| $$ 其中 \(\tilde a_0 \sim \mathcal{N}(0, I)\)。
- Entropy loss:\(\mathcal{L}^{ENT} = \mathbb{E}_{\tilde a \sim \pi_\theta}[\log \pi_\theta(\tilde a | s)]\) — 直接蒙特卡洛估计,无需启发式。
- KL 自适应学习率:\(\widehat{\mathrm{KL}}(\pi_{\theta_{old}} \| \pi_\theta) = \mathbb{E}_{\tilde a \sim \pi_{\theta_{old}}}[\log \pi_{\theta_{old}}(\tilde a|s) - \log \pi_\theta(\tilde a|s)]\)。当 KL \(\geq \bar\epsilon\) 时学习率减半,KL \(\leq \underline\epsilon\) 时加倍 — 与 RSL-RL 标准 PPO 配置一致。
3.5 总 PPO 风格目标¶
其中 \(\mathcal{L}^{PPO}\) 是把 importance ratio \(\pi_\theta(\tilde a|s)/\pi_{\theta_{old}}(\tilde a|s)\) 放进 clipped surrogate(\(\epsilon=0.2\));GAE(\(\lambda=0.95\), \(\gamma=0.99\)) 估计 advantage。
3.6 Implementation Details¶
- Flow steps \(T = 5\)(diffusion 子时间步),积分 5 步推断动作。
- Mixing 系数 \(p = 0.9\),所有任务统一。
- Compression 系数 \(\nu = 0.01\),所有任务统一。
- Actor / critic:MLP
[400, 200, 100],Mish 激活。Actor 输入 =concat(state, action, sinusoidal_embedding(t)) → MLP。 - 时间嵌入:DDPM-style sinusoidal positional encoding,32 维(quadcopter 用 16 维),再过
[256, 256]MLP。 - 采样:\(x_0, y_0 \sim \mathcal{N}(0, I)\) 独立采样(与 EDICT 设 \(x_0 = y_0\) 不同)— 这是能套 change-of-variables 的必要条件。
- 并行环境:默认 4096 个并行环境;512 / 1024 / 2048 / 8192 都做了 scaling 实验,4096 是 sweet spot。
- 硬件:8× RTX 4090D(24 GB),8 卡上 PPO 几乎没加速,GenPO 反而能受益于多 GPU 并行(appendix Fig. 13)。
- 推断时延:Ant 任务上约 2.577 ms / call,比 QVPO/DACER 快得多,足够实时机器人控制频率。
- 任务套件:8 个 IsaacLab benchmark — Ant (60×8), Humanoid (87×21), Franka-Lift-Cube (36×8), Shadow-Hand-Repose (157×20), Anymal-D (48×12), Unitree-Go2 (235×12), Unitree-H1 (256×19), Quadcopter (12×4)。
- 种子:每个任务 5 个 seed。
4. 结果对比¶
4.1 IsaacLab 8 benchmark 主结果(平均 episode return ± std)¶
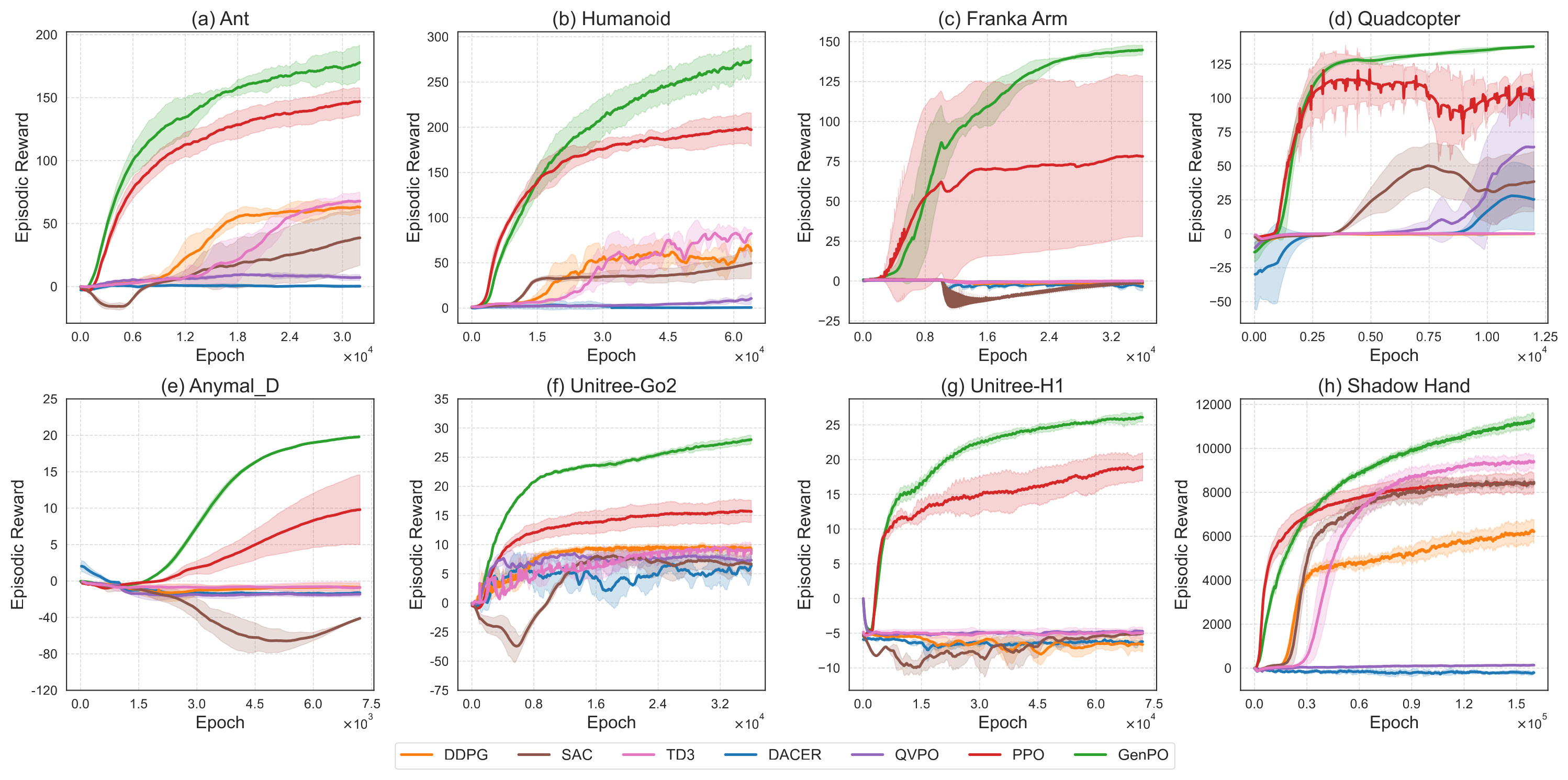 Figure 3:8 个 IsaacLab benchmark 上的训练曲线,5 seed 平均。GenPO(红)在 8/8 上都拿到最优;off-policy 方法(DDPG/TD3/SAC/DACER/QVPO)在大规模并行环境下普遍崩溃 — 这是论文最核心的"on-policy 才是 IsaacLab 该用的范式"的论据。
Figure 3:8 个 IsaacLab benchmark 上的训练曲线,5 seed 平均。GenPO(红)在 8/8 上都拿到最优;off-policy 方法(DDPG/TD3/SAC/DACER/QVPO)在大规模并行环境下普遍崩溃 — 这是论文最核心的"on-policy 才是 IsaacLab 该用的范式"的论据。
| 算法 | Ant | Humanoid | Franka-Arm | Quadcopter | Anymal-D | Unitree-Go2 | Unitree-H1 | Shadow-Hand |
|---|---|---|---|---|---|---|---|---|
| DDPG | 62.96 (5.18) | 63.34 (7.39) | -1.61 (0.76) | 0.03 (0.13) | -0.86 (0.55) | 9.09 (0.81) | -6.63 (1.04) | 6209.59 (559.44) |
| TD3 | 67.80 (7.05) | 82.36 (4.70) | 0.03 (0.12) | 0.17 (0.15) | -0.89 (0.77) | 8.44 (1.05) | -4.97 (0.87) | 9386.64 (314.37) |
| SAC | 38.68 (21.84) | 49.52 (16.89) | -1.10 (0.95) | 38.46 (22.20) | -5.12 (0.14) | 6.67 (2.02) | -5.05 (0.18) | 8459.74 (135.79) |
| DACER | 0.29 (0.98) | 0.58 (0.01) | -3.43 (2.82) | 25.39 (22.99) | -1.62 (0.09) | 6.37 (2.07) | -6.21 (0.17) | -207.43 (88.82) |
| QVPO | 7.19 (2.32) | 10.59 (6.30) | -0.12 (0.14) | 63.99 (45.42) | -1.81 (0.36) | 7.34 (0.62) | -4.72 (0.16) | 134.36 (39.05) |
| PPO | 146.94 (10.61) | 197.25 (18.26) | 78.14 (50.43) | 99.08 (13.49) | 9.80 (4.78) | 15.67 (1.92) | 18.97 (2.02) | 8402.21 (435.64) |
| GenPO | 177.90 (13.87) | 273.94 (16.96) | 144.78 (3.10) | 137.95 (0.84) | 19.80 (0.16) | 28.01 (0.76) | 26.09 (0.68) | 11282.35 (322.94) |
注意几个关键观察: - 相对 PPO 提升 21% (Ant) ~ 85% (Franka-Arm),在 Anymal-D / Unitree-Go2 上提升 ~ 2× — 这些任务里 PPO 早就饱和,GenPO 多模态探索拿到了显著新空间。 - DACER / QVPO 这两个 off-policy diffusion 在 IsaacLab 上几乎完全失败 — 这是支撑"on-policy diffusion 缺口必须填"叙事的关键证据。 - GenPO std 普遍比 PPO 更低(Anymal-D: 0.16 vs 4.78;Quadcopter: 0.84 vs 13.49)— 训练更稳定。
4.2 关键消融(Ant-v0)¶
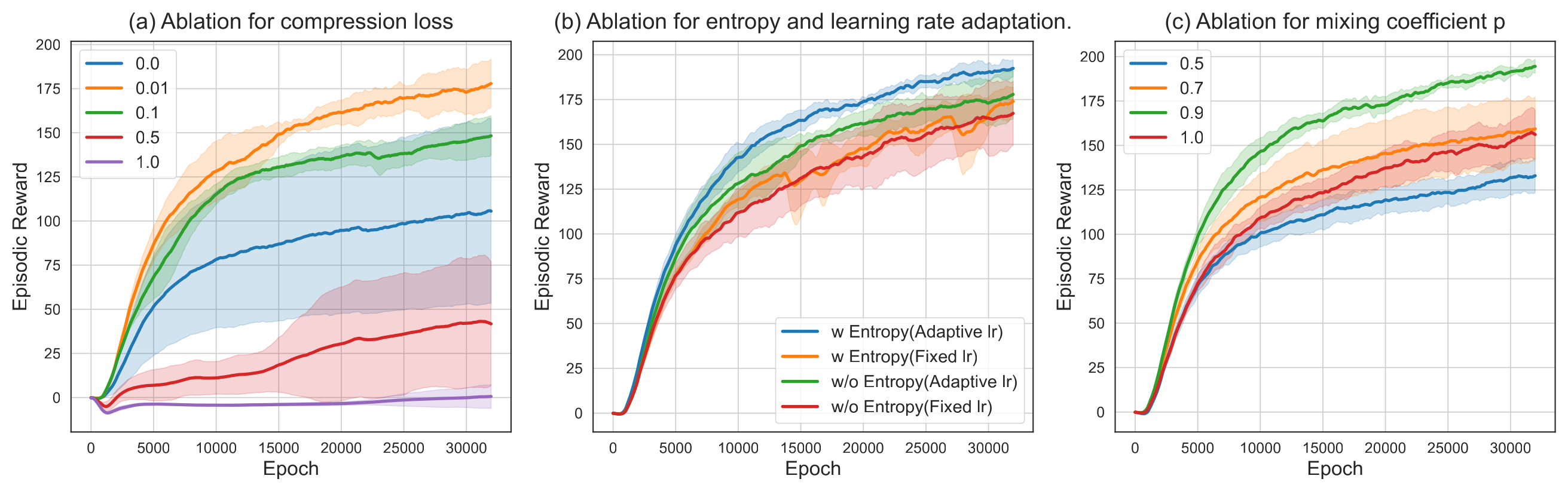 Figure 4:(a) 压缩损失系数 \(\nu\) 的影响;(b) entropy 和 KL 自适应学习率分别去掉的对比;(c) mixing 系数 \(p\) 的影响。最值得注意的是 (a) 的"过大反而崩"和 (c) 的"\(p\) 太小数值不稳定"。
Figure 4:(a) 压缩损失系数 \(\nu\) 的影响;(b) entropy 和 KL 自适应学习率分别去掉的对比;(c) mixing 系数 \(p\) 的影响。最值得注意的是 (a) 的"过大反而崩"和 (c) 的"\(p\) 太小数值不稳定"。
| Configuration | Ant return |
|---|---|
| \(\nu = 0.01\) (Full) | ~ 178 |
| \(\nu = 0\) (no compression) | 慢且抖 |
| \(\nu = 0.1\) | 受限 |
| \(\nu = 0.5\) | 显著下降 |
| \(\nu = 1.0\) | 几乎学不出 |
| Configuration | Ant return |
|---|---|
| Full | ~ 178 |
| 去掉 entropy bonus | 探索下降,return 收敛低 |
| 去掉 KL 自适应学习率 | 收敛慢且不稳 |
| 两者都去掉 | 性能显著退化 |
| Mixing \(p\) | Ant return |
|---|---|
| 0.5 / 0.7 | 数值不稳,foward 步爆掉 |
| 0.9 | 最优 |
| 1.0 (无 mixing) | dummy action 冗余探索,收敛慢 |
4.3 附加实验(appendix)¶
- Flow steps \(T \in \{1, 2, 5, 10, 20\}\):\(T=1\) 性能差,\(T \geq 2\) 都鲁棒;\(T=5\) 是 wall-clock vs return 的折中。
- Dummy action 重组系数 \(\alpha\):\(a = \alpha x + (1-\alpha) y\),\(\alpha=0.5\) 最优 — 两端 \(\alpha \in \{0, 1\}\) 都显著下降(验证了"两个 channel 都用"的设计)。
- Sinusoidal time embedding vs 直接 concat scalar \(t\):sinusoidal 显著好,验证了 DDPM-style 时间编码。
- 并行环境数:1024 / 2048 / 4096 单调上升,4096 → 8192 收益边际,作者选 4096。
- Wall-clock:单卡训练 GenPO 比 PPO 慢(约 2-3 倍),但8 卡并行时 GenPO 加速比远好于 PPO(PPO 单卡和多卡几乎一样),所以多 GPU 下 wall-clock 接近平手。推断时延 2.577 ms,远好于 QVPO/DACER 的几十毫秒。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
-
真把 likelihood 算出来了,而不是又一个估计。Change-of-variables 公式 + triangular Jacobian 让 \(\log \pi\) 是闭式的(采样路径上的逐步 log-det 之和),entropy 和 KL 也是无偏 Monte Carlo — 这一点直接区分于 DIME / DACER / QVPO 等"估计派",把 PPO 整套数学工具完整保下来。
-
EDICT → RL 的迁移角度新颖且精确。原始 EDICT 是 inference-time image editing trick,被搬到 RL 训练 loop 里仍要保证 forward / reverse 严格互逆 — 关键调整是 \((x_0, y_0)\) 独立采样而非耦合采样,这处变化才使 likelihood 公式可用。这是个 first-principle 推动的设计。
-
Doubled action + averaging 的工程简洁性。比起重新设计可逆 NN 架构(normalizing flow 那种 coupling layer),这里只需要在 MDP 外层做 wrapper:策略输出 \((x, y)\)、与环境交互前取均值。完全不改 IsaacLab 接口,工程友好。
-
冗余探索的 mitigation 做得细致。Mixing 系数 \(p=0.9\)(信息互通保持 \(x, y\) 接近)+ compression loss \(\nu (x_1 - y_1)^2\)(显式拉近)双重约束,并且 ablation 系数选得很合理(\(p \to 0.5\) forward 数值不稳,\(\nu \to 1\) 完全限制策略表达力 — 都给出了直观解释)。
-
IsaacLab 大规模并行的"自然舞台"判断准确。论文反复强调 off-policy 在 4096+ 并行环境下 replay buffer 漂移导致 diffusion 跟不上,这个观察被 Table 1 的 DACER ≈ 0 / QVPO ≈ 7 等数字强有力地支持 — 不是为了证明"我比你强",而是确实点出了 paradigm 适配性问题。
-
解析 entropy 与 KL 自适应一起回归。这两个机制在 Gaussian PPO 里是默认配置,能让 diffusion policy 也享受,是显著的"以小博大"工程价值。
5.2 做得不够好的地方 / 值得质疑的地方¶
-
Compression loss 的 \(\nu = 0.01\) 暴露了核心 trick 的脆弱。Figure 4(a) 显示 \(\nu = 0.5\) 就崩了 — 这意味着 dummy action 空间扩张引入的冗余探索问题没有真正被解决,只是被超参强行压住。如果在更高维动作空间(比如 Shadow Hand 20 维 → dummy 40 维)冗余指数增长,\(\nu\) 是否需要任务相关调优?论文却把 \(\nu\) 在 8 个任务上全部固定 — 看起来太干净,可能是把没探好的 case 隐藏了。
-
Doubled action 是"用空间换可逆性",本质上是把 normalizing flow 的 coupling-layer 思路外置。但 RL 中真正需要的是动作空间维度的语义保留 — 把 20 维 Shadow Hand 写成 40 维 dummy,再让 mixing \(p\) 和 compression \(\nu\) 把它"压回去",这种 detour 在样本效率上几乎一定不如直接设计 invertible flow 架构(如 Real-NVP / Glow style 的 actor)。论文没和 normalizing-flow policy 做正面对比,回避了这个最自然的 baseline。
-
flow steps \(T = 5\) 的 Jacobian 都要存在反向图里 — 显存代价大。Conclusion 里作者自己承认了:每个采样步都要保留计算图算 log-det,PyTorch 下 VRAM 占用显著高于 Gaussian PPO。Ant (8 维 → dummy 16 维) 还撑得住,到 Shadow-Hand 20 维(dummy 40 维)× 5 步 × 4096 并行,这套 graph retention 的 GPU 内存 footprint 一定不小,但论文没给具体数字。
-
"GenPO 全胜"的 Table 1 隐藏了若干疑点。
- DACER 在 Ant / Humanoid 上 ≈ 0:这两个任务对其他 baseline 都拿到正 reward,DACER 几乎完全没学到 — 是否暗示 DACER 的实现 / 超参没有公平调优?
- QVPO 在 Quadcopter 上 63.99 (std 45.42):std 远大于 mean,说明部分 seed 学到了部分没学到 — 但被作为"GenPO 远超"的对照,不太严谨。
-
PPO baseline 用的 SKRL 实现,GenPO 用 RSL-RL 实现:作者承认了,但两套库的 PPO 实现并不完全等价(advantage normalization、minibatch shuffle、KL early-stop 等细节可能不同)。在 Anymal-D / Unitree-Go2 / Unitree-H1 上 PPO 表现明显低于社区已知 RSL-RL 的训练结果,这点未做 sanity check。
-
Mixing 系数 \(p = 0.9\) 在所有任务上统一 — 但 \(p\) 物理意义是"信息互通强度",跟动作维度强相关。Quadcopter 4 维 → dummy 8 维,跟 Shadow-Hand 20 维 → dummy 40 维所需的"信息整合带宽"差异巨大,统一 0.9 几乎肯定不是最优。这是后续工作必然要打开的口子。
-
EDICT-style 可逆其实是数学上严格、实际上数值脆弱。Figure 4(c) 已经显示 \(p \leq 0.7\) forward 反推就数值爆掉 — 因为 unmixing 步要除以 \(p\)。在 \(T=20\) 这种深步数下,5 个 task 都至少 \(T \geq 5\),单步浮点误差能否在 log-det 求和中保持稳定?没有给数值精度的分析。
-
真实机器人部署的缺席。摘要明明把"real-world robotic deployment"作为卖点,但全篇没有 sim2real 实验。8 个 task 全部停留在 IsaacLab — 这是 NeurIPS 2025 的合理 scope,但 "first method to unlock real-world deployment of diffusion policies" 的措辞和实验范围严重不符。
-
多模态探索这个理论优势没被实验验证。Diffusion policy 相对 Gaussian 的核心卖点是"多峰动作分布",但论文没设计"显式多最优解"的 task(如 multi-goal maze、双目标 dexterous)来证明 GenPO 真的能利用多模态 — 只是在常规 IsaacLab 上比 PPO 高一截。高出来的部分可能来自更复杂的 noise 网络(参数量)和更细的 mixing 调度,未必来自 multimodality 本身。
-
缺少与 DPPO 这个最接近的 baseline 对比。DPPO 也是把 PPO 套在 diffusion 上,虽然定位是 fine-tune offline-pretrained diffusion,但 PG 损失结构跟 GenPO 高度相似,作者只在 related work 一笔带过没做实验对比。
-
匿名链接
anonymous-project365.github.io在最终版(arXiv v2)还出现在 appendix,说明作者投稿和 arXiv 文本同步性较差 — 不影响科学性,但能感觉到论文成稿时间紧。
5.3 值得继续探讨的方向¶
- Doubled dummy 是必要的吗? 能否在 single-channel 上用 affine coupling layer 设计真正的 invertible policy 架构(如 Glow),跳过 \((x, y)\) → average 这一层 detour?
- EDICT 之外的 inversion:BELM、null-text inversion、DDIM-with-trajectory-storage 等更近期的精确扩散反演方法是否能用到 RL — 也许能减少 doubled action 维度爆炸的代价。
- 多模态探索的针对性实验:构造显式多 optima 的任务(双门走廊、双抓握姿势),看 GenPO 的策略在 KL 等约束下能否真的"分配概率质量到多个 mode"。
- 混合精度 / 显存优化:当前 forward / reverse 都要存计算图算 Jacobian,能否用 checkpointing 或者解析 Jacobian 公式(每步是 affine triangular,应该可写解析式)避免 autograd?
- Sim2real:把 GenPO 训出的 Unitree-Go2 / H1 policy 真在硬件上跑一遍 — 它的"多模态 → 鲁棒性"叙事需要硬件证据。
- 更大动作维度的极限:Shadow Hand 已经 20 维,更高维(如全身 humanoid 30+ 维 → dummy 60+)下,\(p\) / \(\nu\) 是否还稳?
- 与 normalizing flow policy 的正面对比:用 Real-NVP / Neural Spline Flow 作 actor 跑同样 8 个 task,验证"扩散表达力 > flow"在 on-policy RL 上是否真的成立。
- VLA / robot foundation model 中作为 head:扩散 head 已是 VLA 的标准件(pi0/RDT),但目前都是 BC + offline RL,把 GenPO 作为 on-policy fine-tune 的方法接进去,能否解决长程任务的 reward shaping 问题?
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:source/
- 项目主页:https://shanghai-guppy.github.io/genpoplusplus/
- 官方代码:https://github.com/wadx2019/genpo
- 关键 baseline / 相关论文:
- EDICT (Wallace et al., 2023) — 扩散精确反演原型
- DPPO (Ren et al., 2024) — diffusion + PPO 的离线微调对照
- QVPO (Ding et al., 2024) / DACER (Wang et al., 2024) — 表中 off-policy diffusion baseline
- Flow Matching (Liu et al., 2022 / Lipman et al., 2022) — base policy parameterization