Fast-WAM: Do World Action Models Need Test-time Future Imagination?¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Fast-WAM: Do World Action Models Need Test-time Future Imagination?
- 作者: Tianyuan Yuan, Zibin Dong, Yicheng Liu, Hang Zhao(IIIS, Tsinghua University & Galaxea AI)
- arXiv 编号: 2603.16666(2026-03 提交,NeurIPS 2025 模板,疑似为 NeurIPS 2026 或 preprint)
- 项目主页: https://yuantianyuan01.github.io/FastWAM/
- 关键词: World Action Model, video co-training, flow matching, Mixture-of-Transformer, action chunking, real-time inference, Wan2.2 backbone
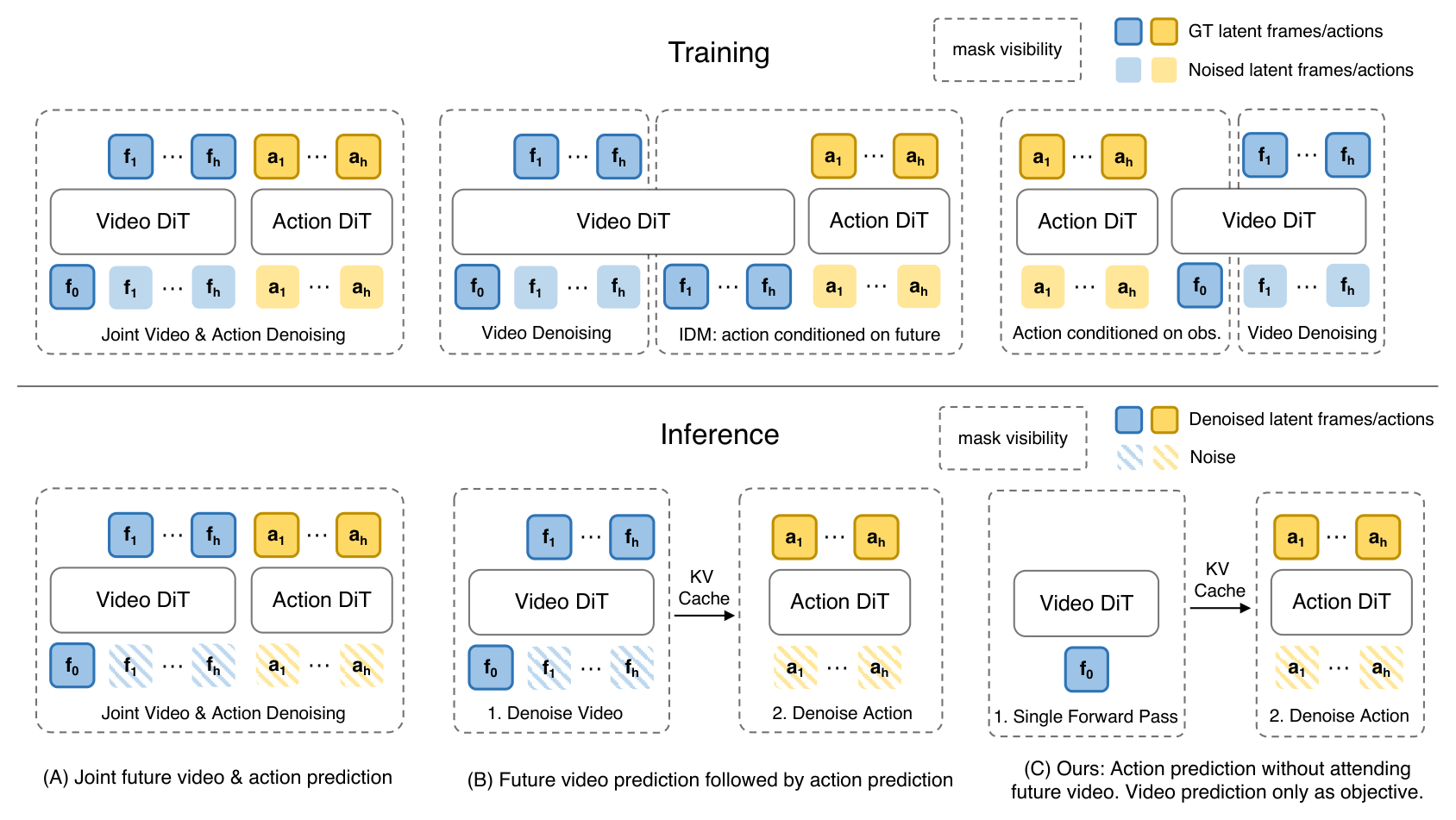 Figure 1:三种 WAM 范式 — (A) joint denoising 同时去噪视频与动作;(B) IDM 先生视频再喂给动作;(C) Fast-WAM 训练时保留视频 co-training,推理时只跑一次 forward、彻底跳过 future video denoising。
Figure 1:三种 WAM 范式 — (A) joint denoising 同时去噪视频与动作;(B) IDM 先生视频再喂给动作;(C) Fast-WAM 训练时保留视频 co-training,推理时只跑一次 forward、彻底跳过 future video denoising。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 embodied policy / World Action Model (WAM) 子领域。WAM 这个名字来自 ye2026worldactionmodelszeroshot,泛指那些"用 video prediction 当作辅助任务来学习 action policy"的一类模型,已经被 LingBot-VA、Motus、Vidar、Cosmos 等近期工作快速推进。论文问的是一个反直觉但很实际的问题:WAM 在 test-time 真的需要去把未来视频显式生成(denoise)出来吗?还是说它的好处其实只在训练阶段就拿到了?
2.2 Motivation¶
现在主流 WAM 走的都是 imagine-then-execute:先迭代 denoise 几十步把未来视频画出来,再 condition 在这堆 imagined frame 上预测动作。这个范式的两个直接代价是:
- 推理延迟极高 — Vidar/MimicVideo/LingBot-VA 这类方法每次 inference 要做完整的 video denoising,论文实测一个 IDM 变种要 810 ms 一次。机器人 closed-loop 控制对延迟极其敏感。
- 未被 disentangle 的两个因素 — WAM 的 gain 可能来自两个截然不同的来源:(i)训练时把 video prediction 当辅助损失,逼 backbone 学到 "physically meaningful" 的 latent;(ii)推理时显式生成 future,给 action head 真正的 foresight。过去工作把这两件事混在一起,从来没有 ablation 干净地告诉我们哪个才是关键。
论文要做的就是把这两件事拆开测一遍。如果 (i) 才是真正起作用的,那现行所有 imagine-then-execute pipeline 都是在"花高延迟买一个本来训练阶段就已经买到的东西"。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Joint denoising WAM | UWM (zhu2025), Motus (bi2025), ye2026 | 视频与动作 token 在同一去噪过程里耦合,每步推理都要碰未来视频;耦合的 gain 来源未被拆解 |
| Video-then-action (IDM) | Vidar (feng2025), LingBot-VA (lingbot-va2026), UniPi (du2023) | 必须完整 denoise 视频再喂给 action head,延迟最高(论文实测 810 ms);future video 质量直接影响下游 action |
| 标准 VLA | π₀ / π₀.₅, OpenVLA, GR00T, RDT | 训练阶段只看 static image-text 数据,未显式建模 physical dynamics → 数据效率低、对未见 embodiment 难泛化 |
| 绕开 test-time video 的尝试 | VPP (hu2024), UVA (li2025) | 同样 bypass 推理时视频解码,但没有显式做"video co-train vs. test-time imagination"的 controlled ablation;缺少回答 "为什么 work" |
2.4 论文解决方案(一句话)¶
训练阶段保留 video flow-matching 作为 co-training 辅助任务、推理阶段彻底丢掉 future video 分支 — 用一个 Mixture-of-Transformer(视频 DiT + 动作 DiT,shared attention)实现两套行为;并构造 Fast-WAM-Joint / Fast-WAM-IDM / no-video-co-train 三个变种作为 controlled comparison,证明 真正起作用的是训练时的视频目标,不是推理时的 future imagination。
2.5 与前序工作的关系¶
- Backbone: 直接复用 Wan2.2-5B 的 video DiT、T5 text encoder、video VAE — 这是和 LingBot-VA "from WAN2.2" 控制基线对齐的设计;
- MoT shared-attention 架构: 沿用 π₀ / OpenVLA 一脉的 dual-expert pattern,但把"语言专家"替换成"视频专家";
- Controlled variants: Fast-WAM-Joint 对应 UWM/Motus/ye2026 的范式,Fast-WAM-IDM 对应 Vidar/LingBot-VA/UniPi 的范式 — 这一节是论文 contribution 的核心,让 ablation 真正干净;
- 跟 VPP / UVA 的差异: VPP 也是用 video diffusion 的中间表征做策略,但走的是"freeze video model + 单独训 policy"路线;UVA 是 joint train 但 skip video decoding。Fast-WAM 在 framing 上更强调"两条 path 的 head-to-head controlled comparison",而不是再造一个绕开方法。
3. 方法介绍¶
3.1 形式化¶
记当前观察 \(o\)、语言指令 \(l\)、未来 \(H\) 步动作 chunk \(a_{1:H}\)。标准 visuomotor policy 直接建模 \(p(a_{1:H}\mid o,l)\)。Imagine-then-execute WAM 引入未来视觉变量 \(v_{1:T}\),做如下因式化:
实际实现要么 joint denoise、要么 video → action 两段式,外面通常再包一层 auto-regressive rollout(论文为对比简洁性把这层省掉了)。
Fast-WAM 反过来,直接 建模 \(p_\theta(a_{1:H}\mid o,l) = p_\theta(a_{1:H}\mid z(o,l))\),其中 \(z(o,l)\) 是 video DiT 单次前向得到的 latent — 不再 sample 或 denoise 任何 \(v_{1:T}\)。但训练时 video co-train 的损失仍然让 \(z\) 携带"未来运动结构"。这就是 disentangling 的核心:训练目标决定 representation 的结构,推理 path 决定 latency。
3.2 模型架构¶
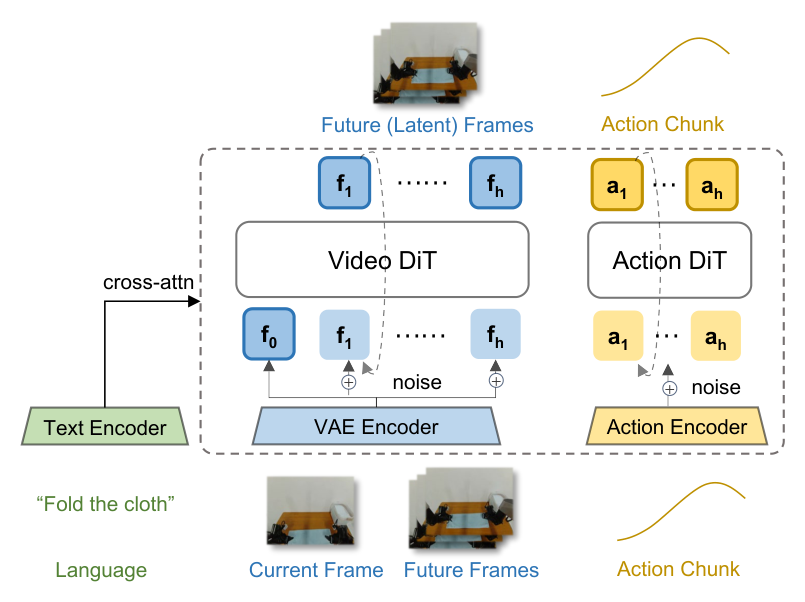 Figure 2:Fast-WAM 主架构。Video DiT 与 Action DiT 共享 attention,构成 MoT。三组 token —— 干净的 first-frame latent \(f_0\)、加噪的 future video latent \(f_{1:h}\)、加噪的 action \(a_{1:h}\) —— 都通过 cross-attention 接收 text encoder 的语言嵌入。VAE 与 text encoder 来自 Wan2.2-5B 的 pretrained 权重。
Figure 2:Fast-WAM 主架构。Video DiT 与 Action DiT 共享 attention,构成 MoT。三组 token —— 干净的 first-frame latent \(f_0\)、加噪的 future video latent \(f_{1:h}\)、加噪的 action \(a_{1:h}\) —— 都通过 cross-attention 接收 text encoder 的语言嵌入。VAE 与 text encoder 来自 Wan2.2-5B 的 pretrained 权重。
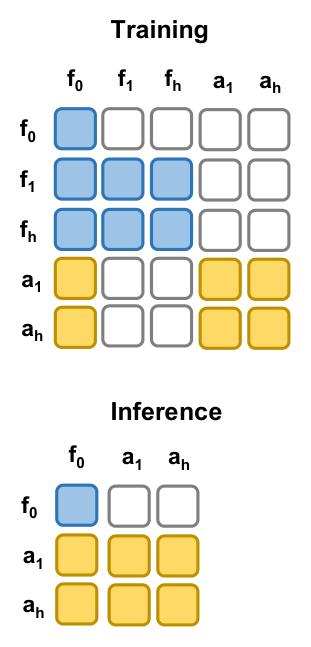 Figure 3:训练(左)/ 推理(右)attention mask。训练时 future video 与 action 都能看 \(f_0\),但 action 不能看 future video — 保证 video 仅作为训练目标存在,不在推理时给 action 提供 foresight;同时也保证 controlled ablation 干净。推理时整列 future video token 全部被 mask 掉。
Figure 3:训练(左)/ 推理(右)attention mask。训练时 future video 与 action 都能看 \(f_0\),但 action 不能看 future video — 保证 video 仅作为训练目标存在,不在推理时给 action 提供 foresight;同时也保证 controlled ablation 干净。推理时整列 future video token 全部被 mask 掉。
关键结构:
- Backbone: Wan2.2-5B 的 video DiT + T5 + video VAE 全部复用;
- Action expert: 与 video DiT 同样的层结构,但 hidden dim 从 video 分支降到 \(d_a = 1024\),结果为 ~1B 参数;total model 6B;
- Token 组:(1) clean first-frame latent —— 共享的 visual anchor,训练/推理都用;(2) noisy future video latent —— 只在训练时存在;(3) action token —— 由 action expert 处理;
- 多相机:直接在像素层把多视角拼成一张大图再过 VAE(朴素但实用);
- Token 流动规则(来自 structured mask):
- Future video 内部双向 attention,可以看 \(f_0\);
- Action token 内部双向 attention,可以看 \(f_0\);
- Action token 不能看 future video token — 这条最关键,否则 ablation 就不干净;
- \(f_0\) 不看任何其他 token(纯当 K/V source)。
3.3 训练目标 — Joint Flow Matching¶
对任意目标 \(y\)(动作或 future video latent),采样 \(\epsilon\sim\mathcal{N}(0,I)\)、\(t\in(0,1)\),构造插值样本 \(y_t=(1-t)y+t\epsilon\),模型预测 velocity field:
总目标 \(\mathcal{L} = \mathcal{L}_{\mathrm{act}} + \lambda \mathcal{L}_{\mathrm{vid}}\),其中 \(\mathcal{L}_{\mathrm{vid}}\) 在 latent space(VAE 输出)上做。Action horizon \(h=32\),video frame chunk 长度 9(时间上 \(4\times\) downsample)。
3.4 Controlled Variants(论文的核心 ablation 工具)¶
为了回答中心问题,论文用 同一套 backbone / tokenization / 训练 recipe 实现了四个变种:
| 变种 | 训练目标 | 推理 path | 对应 paradigm |
|---|---|---|---|
| Fast-WAM (main) | act + video co-train | 单次 forward,无 future video | "skip imagination" |
| Fast-WAM-Joint | act + video co-train | 视频与动作一起 denoise(10 步) | UWM/Motus/ye2026 |
| Fast-WAM-IDM | act + video co-train + noise aug (p=0.5) | 先 denoise video,再 condition action denoise | Vidar/LingBot-VA/UniPi |
| Fast-WAM w/o video co-train | act only | 单次 forward,无 future video | controlled baseline |
第四个变种是 最关键的对照 — 跟 main 完全同架构,只去掉 训练时的视频损失。如果 video co-train 才是 gain 来源,第四个变种应该塌掉;如果反过来,第四个变种应该和 main 接近、而 Joint/IDM 才显著更强。
3.5 Implementation Details¶
- Backbone: Wan2.2-5B video DiT,重用 pretrained 权重,不做 embodied pretraining;
- 总参数: 6B(5B video + 1B action expert);
- Action horizon: \(H=32\);video chunk: 9 帧(时序 4× downsample);
- Noise schedule: logit-normal over \(t\)(follow Wan2.2);
- 推理: 10 denoising steps,CFG = 1.0;
- 优化器: AdamW,lr \(1\times10^{-4}\),weight decay 0.01,cosine annealing,mixed precision,grad clip 1.0;
- 训练步数: LIBERO 20k steps;RoboTwin 30k steps;real-world towel folding 30k steps;
- Real-world 数据: 60 小时 Galaxea R1 Lite 远程操作 demonstration;
- 延迟测试硬件: 单卡 NVIDIA RTX 5090D V2 32GB;
- 关键延迟数字:Fast-WAM 190 ms / chunk,Fast-WAM-Joint 中间档,Fast-WAM-IDM 810 ms。
4. 结果对比¶
4.1 RoboTwin 2.0(bimanual,50+ 任务)¶
| Method | Embodied PT | Clean | Rand. | Average |
|---|---|---|---|---|
| π₀ | ✓ | 65.92 | 58.40 | 62.2 |
| π₀.₅ | ✓ | 82.74 | 76.76 | 79.8 |
| Motus | ✓ | 88.66 | 87.02 | 87.8 |
| Motus from WAN2.2 | ✗ | 77.56 | 77.00 | 77.3 |
| LingBot-VA | ✓ | 92.90 | 91.50 | 92.2 |
| LingBot-VA from WAN2.2 | ✗ | 80.60 | — | 80.6 |
| Fast-WAM (Ours) | ✗ | 91.88 | 91.78 | 91.8 |
要点:Fast-WAM 在不做 embodied pretraining 的条件下,把 LingBot-VA / Motus 在同样无 pretraining 下的"from WAN2.2"基线(77.3 / 80.6)甩开 10+ 个点,跟 LingBot-VA 带 pretraining 后的 SOTA 只差 0.4 点。
4.2 LIBERO(4 个 suite × 10 任务,2000 trial 评估)¶
| Method | Embodied PT | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|---|
| OpenVLA | ✓ | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| π₀ | ✓ | 96.8 | 98.8 | 95.8 | 85.2 | 94.1 |
| π₀.₅ | ✓ | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| LingBot-VA | ✓ | 98.5 | 99.6 | 97.2 | 98.5 | 98.5 |
| Motus | ✓ | 96.8 | 99.8 | 96.6 | 97.6 | 97.7 |
| Fast-WAM (Ours) | ✗ | 98.2 | 100.0 | 97.0 | 95.2 | 97.6 |
Fast-WAM 没有 embodied pretraining 仍然超过 π₀.₅ (96.9) 与 OpenVLA (76.5),与最强 pretrained baseline 差 ~0.9 点。
4.3 Real-world Towel Folding(Galaxea R1 Lite,60h demos)¶
 Figure 4:真实世界毛巾折叠任务 — long-horizon、可形变物体、双臂协同。论文用 success rate 与 completion time 两个指标,因为完成时间能捕捉"反复 trial-and-error"这种隐性失败。
Figure 4:真实世界毛巾折叠任务 — long-horizon、可形变物体、双臂协同。论文用 success rate 与 completion time 两个指标,因为完成时间能捕捉"反复 trial-and-error"这种隐性失败。
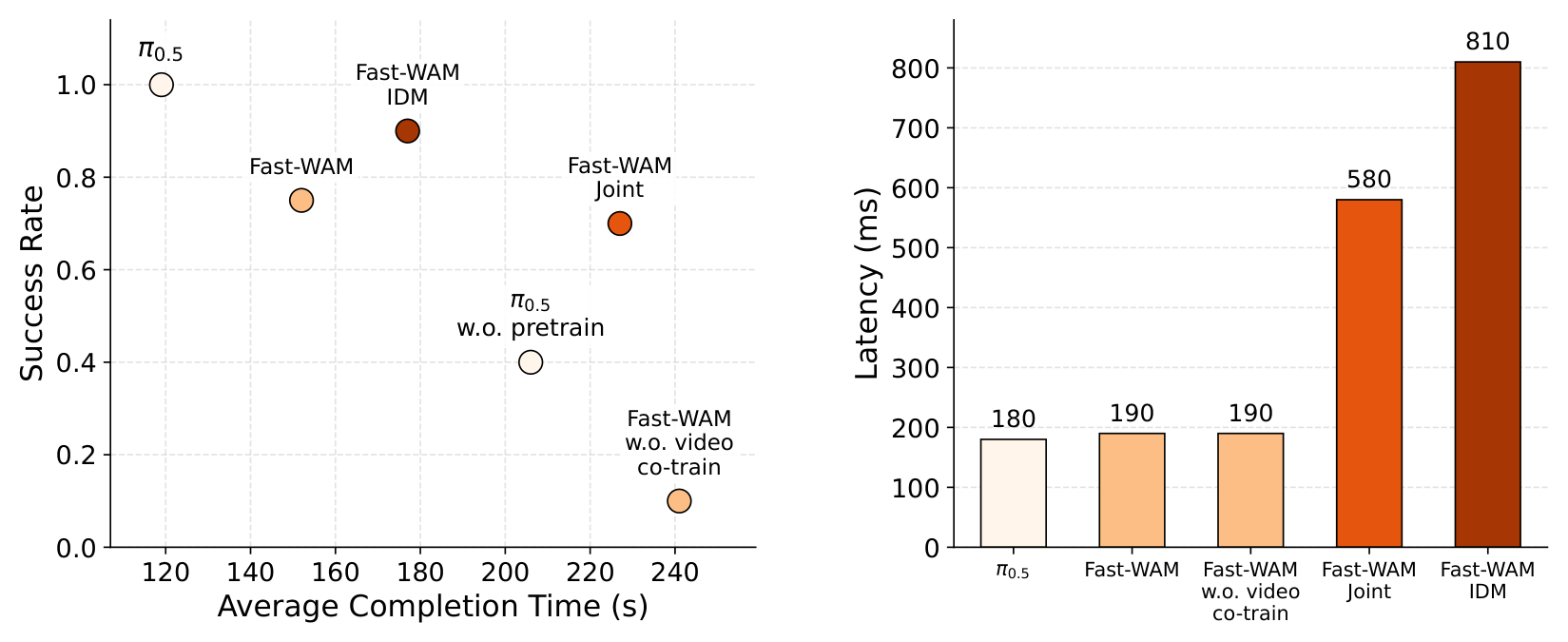 Figure 5:左图 success vs completion time(左上为佳),右图 inference latency 对比。Fast-WAM 在保持 strong success 的同时延迟最低 (190 ms),是 Fast-WAM-IDM (810 ms) 的 ~4× 加速。最右那个掉到 10% 的红点就是去掉 video co-train 之后的 ablation。
Figure 5:左图 success vs completion time(左上为佳),右图 inference latency 对比。Fast-WAM 在保持 strong success 的同时延迟最低 (190 ms),是 Fast-WAM-IDM (810 ms) 的 ~4× 加速。最右那个掉到 10% 的红点就是去掉 video co-train 之后的 ablation。
| Method | Latency | Real-world 任务结果(定性) |
|---|---|---|
| π₀.₅ (pretrained) | — | success rate 与 completion time 最佳(最强 baseline) |
| Fast-WAM | 190 ms | success rate 略低于 π₀.₅,但 completion time 是 Fast-WAM 家族最优 |
| Fast-WAM-Joint | 中间 | 表现相近 |
| Fast-WAM-IDM | 810 ms | success rate 在 Fast-WAM 家族里最高,但延迟最差 |
| π₀.₅ (no pretrain) | — | 显著低于 Fast-WAM 家族 → 说明 video co-train 提供了 data efficiency |
| Fast-WAM w/o video co-train | 190 ms | success rate 掉到 10%,completion time 最长(崩盘) |
4.4 关键 Controlled Ablation(论文最重要的表)¶
下面这个对比是整篇文章的论点支柱:
| Variant | LIBERO Avg | RoboTwin Avg | Real-world 趋势 | Latency |
|---|---|---|---|---|
| Fast-WAM (main) | 97.6 | 91.8 | strong, fastest of family | 190 ms |
| Fast-WAM-Joint | 98.5 | 90.6 | comparable | mid |
| Fast-WAM-IDM | 98.0 | 91.3 | slightly higher success | 810 ms |
| Fast-WAM w/o video co-train | 93.5 | 83.8 | 10% success(崩) | 190 ms |
论文的核心结论:从带 video co-train 的三个变种之间(main vs Joint vs IDM)只差 ~1 个点,但砍掉 video co-train 让 RoboTwin 掉 8 点 / 真实世界掉到 10%。也就是说:"要不要在 test-time imagine future" 不重要,"训练时有没有这个目标"才重要 — 至少在当前 model scale / data scale 下。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- Disentangling 的实验设计干净。Joint / IDM / Skip / no-co-train 四个变种共享 backbone、tokenization、训练 recipe,只改两个 bit(训练时是否 video co-train × 推理时是否生成 video),这种 2×2 式的 ablation 在 WAM 文献里第一次被认真做。结论的可信度直接来源于这个设计。
- Action token 不能看 future video token 的 mask 设计。如果允许 action 看 future video,那 Fast-WAM-IDM 就变成"action 在 ground-truth 视频上 condition" → 训练/推理 mismatch;这条 mask 同时保证了三个变种的可比性,是教科书级别的 controlled experiment trick。
- 直接用 Wan2.2-5B 的 pretrained video DiT,并把 baseline 对齐到"from WAN2.2"列。这一对齐让 87% → 91.8% 的提升不能被简单归因为"更大的 backbone",因为 Motus from WAN2.2 / LingBot-VA from WAN2.2 用的是同一个起点。
- 结果反直觉但落地价值高。190 ms vs 810 ms 是机器人 closed-loop 控制能否真用的分水岭 — 折叠毛巾这种 long-horizon 任务要每 chunk 等近 1 秒,是非常糟糕的用户体验。论文用最少的 architectural change 拿到了 4× 加速。
- MoT shared-attention 重用了 Wan2.2 的 attention 结构,意味着不需要从头训 cross-modal attention pattern;这也是 6B 全模型只用 30k step 就 work 的工程基础。
- Real-world towel folding 同时报 success rate 与 completion time。后者捕捉的是"反复擦边补救"这种 closed-loop 失败模式,比单独看 success rate 诚实 — 实际上去掉 co-train 的版本两个指标都崩,进一步加强了结论。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 结论的 generality 受限于 scale。论文自己在 conclusion 里也提到了 future work 要研究 scaling,但目前的实验都在 Wan2.2-5B + 中小规模 demo 上。如果 backbone scale 起来到 30B+、或者 video co-train 用更大规模的 in-the-wild video 数据,是否结论仍然成立?Cosmos / Sora 那种 trillion-token 训练的世界模型可能反而能从 test-time imagination 中拿到更多 — 论文没有这方面证据。
- 没有任务/任务族粒度的 attribution。Per-task table 中,Open Microwave、Hanging Mug、Press Stapler、Move Stapler Pad 这些"难任务"上几种变种差距很大(Open Microwave 上 Joint 只有 3%!),但论文用 50 task 平均把这些信号 wash 掉了,没有讨论 imagine-then-execute 是不是在某些动力学复杂任务上才真的有用。
- Fast-WAM-IDM 在 real-world 任务上 success rate 反而最高。这点论文一句话带过("Fast-WAM-IDM 比 main 稍高"),但其实直接挑战了核心论点 — 当任务对未来 deformable 物体动力学要求很高(折叠毛巾),test-time imagination 似乎仍然有 marginal value。论文没有认真讨论这种 "low-data + 高动力学复杂度 → imagination 仍然帮忙" 的可能性。
- "video co-train 才是 gain 来源" 的因果解释不够深入。论文是用 ablation 证明 "去掉它会掉",但没有给出 "为什么它有用" 的 representation-level 证据。是 video objective 让 backbone 学到了 object permanence?motion smoothness?contact prediction?probe 实验、representation visualization、video reconstruction quality 与 success rate 的相关性 — 这些都没有。
- 训练-推理 mask 的不对称引入隐藏 distribution shift。训练时 video DiT 同时看 clean \(f_0\) 和 noisy \(f_{1:h}\),attention 分布是被 future 上下文塑造的;推理时整个 future 列被 mask 掉,attention 分布会变。论文没分析这是否导致 attention 退化、或某些 head 的功能在两个 mode 下不一致。
- CFG = 1.0 等价于没有 classifier-free guidance。Diffusion policy 文献里普遍用 CFG > 1(如 π₀ 用 1.5 - 3.0),论文用 1.0 实际是关闭了 guidance — 这可能是 video co-train backbone 已经足够稳定,但没有讨论为什么这里关闭了 CFG,是否对 Fast-WAM-IDM 这种依赖文本条件的变种不公平。
- 缺少 inference scaling 的对照。一种自然的怀疑是:"如果 imagine-then-execute 多花 5× compute,能换来 task 上的 gain 吗?" — 论文只比了 chain length 固定的版本。如果 Joint/IDM 给更多 denoising step、Fast-WAM 给更多 action denoising step,曲线是否会交叉?这是 test-time scaling 这种新潮研究里很关键的视角,论文没碰。
- Embodied pretraining 的对比是不对称的。Motus / LingBot-VA / π₀.₅ 都做了 embodied pretraining,"from WAN2.2" 的对照只是它们的"零 pretrain"版本;但 Fast-WAM 自己也"没 pretrain"。问题是:Fast-WAM 如果用同样规模的 embodied pretrain,是否还能保留这个 controlled comparison 结论?或者 pretraining 本身就足以替代 video co-train?论文回避了这个组合实验。
- MoT 架构选择没有 ablation。"Action expert 共享 video DiT 的 attention" 本身是一个 architecture 选择;如果改成完全独立的 action transformer(只读 video DiT 最后一层 latent),可能 video co-train 的 effect 会不同。论文把 architecture 当作 fixed,但 architecture 与 training-objective 是耦合的。
- 只有 6 页正文。NeurIPS 全文标准远不止 6 页 — 这个篇幅可能反映了 position-paper 性质(中心问题 + clean ablation),但工程细节(数据预处理、CFG scale 选择理由、多相机 stitching 的具体几何、训练时 video 长度对 GPU memory 的影响)大量被省。读者无法判断方法对 hyper-parameter 的鲁棒性。
5.3 值得继续探讨的方向¶
- Scale 上限:把 backbone 换成 Wan2.2-30B 或 Cosmos,是否 imagine-then-execute 重新变得有价值?换言之,是不是 "test-time imagination 的价值随 model capability 单调上升"?
- 任务族级别 attribution:哪些任务(deformable / multi-step contact / 高物理复杂度)会让 IDM 仍然比 skip-imagination 显著更好?这指向一种"任务感知的 inference path"假设。
- Representation probing:在 video co-train vs no-co-train 两个 backbone 上做 reverse probing — 看哪些 physics-relevant property(object identity, contact, occlusion, motion smoothness)被显式学到。如果能识别出"video co-train 学到的是 X",就能往更便宜的 surrogate objective 上替代。
- 替代的辅助目标:能不能用 inverse dynamics、masked autoencoding、optical flow prediction 之类成本更低的辅助 loss 替代 full video diffusion loss?如果可以,那 video co-train 的 6B forward pass 都可以省掉。
- Closed-loop replanning + chunking:Action horizon 32 是相对长的 chunk,real-world 任务里 chunk 间的 replan latency 直接决定恢复能力。能否把 chunk 砍到 8 + 更频繁 replan,与 190 ms 单 forward 配合做 ~24 Hz 控制?
- Embodied pretraining × Fast-WAM 的组合:补一次"Wan2.2 + embodied pretrain + Fast-WAM 训练"的实验,看是否能逼近甚至超过 LingBot-VA (pretrained)。
- Inference-time scaling 曲线:固定模型,变 denoising step / chunk size,比较三个变种在 compute–performance 上的 Pareto frontier。这才是说服读者的最干净方式。
- 多模态扩展:把"video co-train"的概念推到 video+depth+force 同时 co-train,看 contact-rich 任务(开微波炉、按订书机)是否能解决论文中显示的弱项。
参考资源¶
- 后续讨论笔记: Fast-WAM_discussion.md — 从 "video DiT 单次前向是什么意思" 出发,推到 "video generation 作为 robot policy pretraining" 这条 thesis
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://yuantianyuan01.github.io/FastWAM/
- 关键 baseline / 相关论文:
- LingBot-VA (lingbot-va2026) — video-then-action paradigm,Fast-WAM-IDM 的原型
- Motus (bi2025motusunifiedlatentaction) — joint denoising 的代表
- ye2026worldactionmodelszeroshot — WAM 概念来源
- Vidar (feng2025) / UniPi (du2023) — IDM 范式更早期工作
- Wan2.2 (wan2025) — 论文的 backbone
- VPP (hu2024video) / UVA (li2025) — 同样绕开 test-time video synthesis 的相关尝试
- π₀ / π₀.₅ (black2024 / intelligence2025) — VLA baseline