LagerNVS: Latent Geometry for Fully Neural Real-time Novel View Synthesis¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: LagerNVS: Latent Geometry for Fully Neural Real-time Novel View Synthesis
- 作者: Stanislaw Szymanowicz¹², Minghao Chen¹², Jianyuan Wang¹², Christian Rupprecht¹, Andrea Vedaldi¹² (¹ Visual Geometry Group, University of Oxford;² Meta AI。S. Szymanowicz 与 M. Chen 工作期间为 Meta 实习生)
- arXiv 编号: 2603.20176 (submitted 2026-06;CVPR 2026,paperID 6806)
- 项目主页: szymanowiczs.github.io/lagernvs(含代码、模型、示例)
- 关键词: Novel View Synthesis, reconstruction-free / 隐式 3D, VGGT 特征复用, encoder-decoder transformer, 实时渲染, feed-forward, diffusion decoder
 Figure 1:LagerNVS 在不做任何显式 3D 重建的前提下,用一个「从 VGGT 初始化的 encoder + 轻量 decoder」直接渲染新视角;图中所有结果都是单张 H100 上 512×512、30 FPS+ 实时渲染出来的。
Figure 1:LagerNVS 在不做任何显式 3D 重建的前提下,用一个「从 VGGT 初始化的 encoder + 轻量 decoder」直接渲染新视角;图中所有结果都是单张 H100 上 512×512、30 FPS+ 实时渲染出来的。
2. 文章介绍¶
2.1 解决的领域和问题¶
任务是 Novel View Synthesis (NVS):给定一个场景的若干源视角图像,渲染出该场景在新相机位姿下的图像。主流路线分两类:
- 显式 3D 重建 + 渲染:先对场景拟合一个显式 3D 模型(NeRF / 3D Gaussians),再从目标视角渲染。质量好,但优化慢、在源视角少时容易过拟合。前馈版(pixelSplat / MVSplat / Splatter Image / AnySplat 等)用网络一次性预测 per-pixel Gaussians,快很多。
- reconstruction-free(隐式)NVS:彻底跳过 3D 重建,让网络直接输出新视角图像。代表是 SRT、LVSM、RayZer——把场景编码成一组潜在特征(latent light field),decoder 在目标相机条件下直接读出图像。
本文站在第二条路线(隐式、无显式 3D),核心论点是:「不做显式 3D 重建」并不等于「不需要 3D 先验」。
2.2 Motivation¶
LVSM 这类纯隐式方法把 3D 归纳偏置压到了最低——基本只剩「怎么编码相机参数(ray map)」。作者认为这是浪费:现在已经有 VGGT 这样用显式 3D 监督预训练出来的强重建骨干,它的中间特征天然「3D-aware」。能不能只借它的特征、不要它的显式 3D 输出,把这份 3D 先验注入一个纯神经的 NVS 网络?
一句话动机:用 3D 监督预训练出来的特征当 encoder,让隐式 NVS 既保留「无显式重建」的灵活性(处理反射、薄结构、遮挡补全),又拿到 3D 重建模型的几何先验和泛化能力。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 优化式显式重建 | NeRF, 3DGS | 每个场景都要优化,慢;源视角少时过拟合 |
| 前馈显式重建(pixel-aligned 3DGS) | pixelSplat, MVSplat, DepthSplat, AnySplat, Flare | 强制 Gaussian 沿射线对齐 → 任何视角都看不见的区域(遮挡)直接是空洞;反射 / 薄结构难以前馈预测准 |
| 纯隐式 · decoder-only | LVSM (decoder-only) | 整张网络对每个新视角都要重跑一遍 → 渲染慢,encoder/decoder 无法解耦 |
| 纯隐式 · bottleneck 编码 | LVSM (enc-dec, Bottleneck) | latent token 数被压到固定维度 → 信息瓶颈,质量明显低于 decoder-only(LVSM 自己也承认) |
| 纯隐式 · 弱 3D 先验 | SRT, RayZer | 几乎没有 3D 归纳偏置;RayZer 还要求有序图像集合 |
2.4 论文解决方案(一句话)¶
把一个用显式 3D 监督预训练的重建骨干(VGGT)当作 encoder、抽它倒数第二/第三层的 token 当「隐式 3D 特征」,配一个轻量 ViT-B decoder,用 photometric loss 端到端微调,得到一个无显式 3D、实时、可在有/无源相机位姿下工作、且能泛化到 in-the-wild 数据的 SoTA 前馈 NVS 模型。
2.5 与前序工作的关系¶
- 直接对标 LVSM:同样是 transformer-based 隐式 encoder-decoder,但本文 (1) 换了 encoder 的「信息流」结构(Highway 而非 Bottleneck),(2) 用 VGGT 预训练初始化 encoder。两点都带来显著提升。
- 复用 VGGT(Wang et al. 2025,一个前馈多视角重建网络):但只用它的特征,不用它的显式 3D 输出。AnySplat 也用 VGGT,但 AnySplat 把它接到 Gaussian splat renderer(显式路线),本文则保持纯隐式。
- vs RayZer:本文可处理无序图像集合(RayZer 不行)。
- 并发工作 SVSM(Kim et al. 2026):分析 encoder-decoder NVS transformer 的 scaling law,架构类似,但关注 compute 效率;本文关注 3D 预训练的作用和有/无相机的泛化。
3. 方法介绍¶
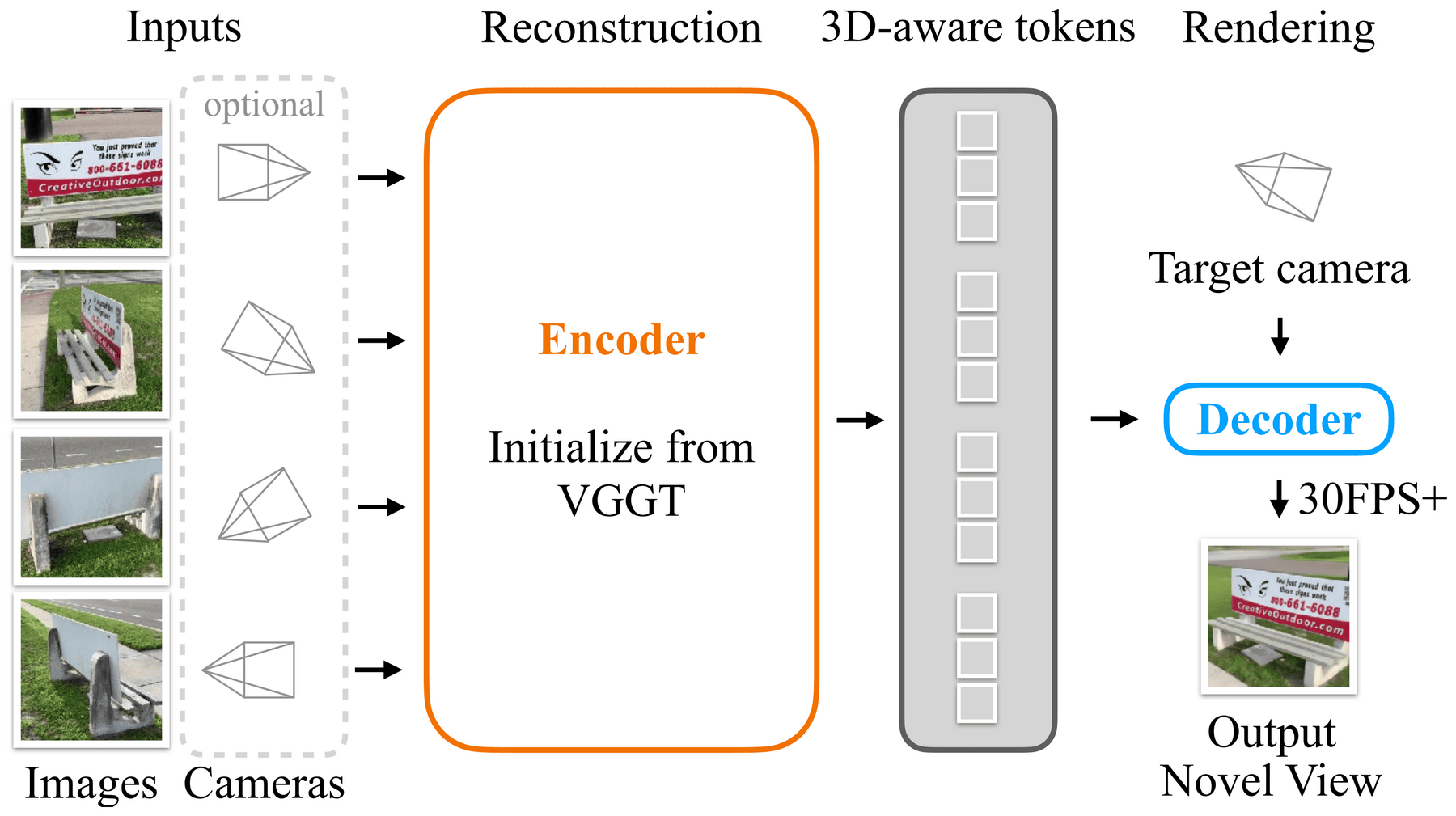 Figure 2:整体 pipeline。任意数量图像(可选附带相机参数)→ 一个从 VGGT 初始化的大 encoder 输出「带隐式 3D 信息」的特征 → 一个轻量 decoder 在目标相机位姿下查询、渲染出 512×512 图像(≤9 张输入时 30 FPS+)。
Figure 2:整体 pipeline。任意数量图像(可选附带相机参数)→ 一个从 VGGT 初始化的大 encoder 输出「带隐式 3D 信息」的特征 → 一个轻量 decoder 在目标相机位姿下查询、渲染出 512×512 图像(≤9 张输入时 30 FPS+)。
3.1 形式化¶
给定 \(V\) 张源图像 \(I_1,\dots,I_V\) 和目标相机 \(g\)(相对参考图 \(I_1\) 的视角表达),输出目标视角图像 \(I=f(g; I_1,\dots,I_V)\)。若源相机已知,则 \(f\) 额外接收 \(g_1,\dots,g_V\)。
相机沿用 VGGT 的 11 维参数化 \(g=(q,t,k,w)\):\(q\in\mathbb{S}^3\) 四元数旋转、\(t\in\mathbb{R}^3\) 平移、\(k\in\mathbb{R}^2_+\) 水平/垂直 FOV(光心假设在图像中心)、\(w\in\mathbb{R}^2_+\) 是辅助的「场景尺度」参数。所有 \(g_i\) 相对第一台相机。
Encoder-decoder 拆分(本文核心结构):
encoder \(e\) 每个场景只跑一次抽出 \(z\),decoder \(h\) 每个新视角才跑——从而把 encoding 的开销摊销到多个目标视角上。
3.2 三种架构:Decoder-only / Bottleneck / Highway¶
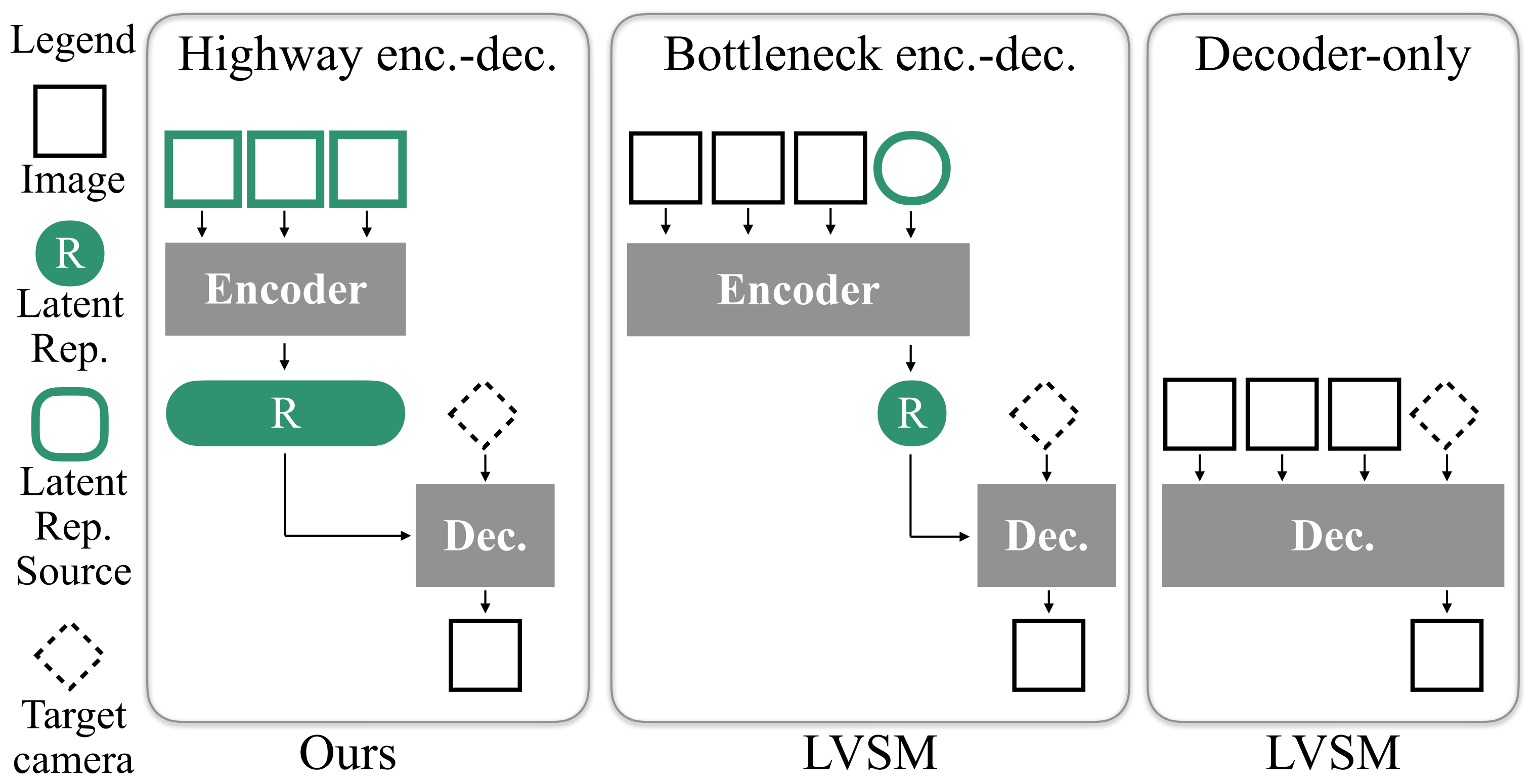 Figure 3:本文系统比较的三种前馈 NVS 架构。Highway(左,本文)让源图像信息无衰减地流入 latent R,比 Bottleneck(中)更有表达力;与 decoder-only(右)不同,它可以放大 encoder 而不拖慢 decoding。
Figure 3:本文系统比较的三种前馈 NVS 架构。Highway(左,本文)让源图像信息无衰减地流入 latent R,比 Bottleneck(中)更有表达力;与 decoder-only(右)不同,它可以放大 encoder 而不拖慢 decoding。
- Decoder-only:源图像 + 目标相机直接进网络出目标图像,无相机无关的中间表示 → 整张网络对每个视角都重跑(LVSM 的一个变体)。
- Bottleneck(
\indirect)encoder-decoder:latent \(z\) 的 token 数被约束到固定维度(与源视角数 \(V\) 无关) → 信息瓶颈。LVSM 的 enc-dec 变体走这条。 - Highway(
\direct)encoder-decoder(本文):\(z=(z_1,\dots,z_V)\) 为每张源图保留独立的特征向量,decoder 可直接访问所有图像特征,信息流不被衰减(命名借自 Highway Network)。
作者的关键洞察:LVSM 作者发现自己的 enc-dec 不如 decoder-only,归因于「enc-dec 架构本身」;但本文论证那是 Bottleneck 的锅,不是 enc-dec 结构的锅。Highway enc-dec 既保住「encode 一次、decode 多次」的摊销优势,又没有瓶颈,反而同时打败 decoder-only 和 Bottleneck。
3.3 Encoder:把隐式 3D bias 注入网络¶
在 VGGT 骨干上构建。VGGT 本是前馈 3D 重建网络(输出相机、depth map 等),但本文不用它的几何输出,而是:
- 对每张源图 \(I_i\),从 VGGT transformer backbone 的最后一层 local attention 和最后一层 global attention 抽 token(在 decoding head 之前),去掉 camera token;
- 把这两组 token 沿 channel 拼接 → 得到 \(z_i\in\mathbb{R}^{P\times C}\)(拼接后是 \(2\times1024\) 维);
- 过一个 linear 层投到 decoder 期望的维度 \(C\),再 LayerNorm 稳定训练。
给 encoder 加相机输入:VGGT 本身不吃相机。作者加一个 2 层 MLP 把 11 维相机参数投成 1024 维 token,加到 VGGT 默认的 camera token 初值上,再正常喂进 backbone。没有相机时把 \(g\) 置零向量(只保留尺度 \(w\))。于是同一个 encoder 既能用相机也能不用——靠训练时随机 dropout camera token 实现。
3.4 Decoder:高效轻量渲染器¶
目标相机编码:把目标相机 \(g\) 表示成稠密的 Plücker ray map(\(6\times H\times W\),每像素一条射线的方向 \(r_d\) 和 moment \(r_m\))。源相机内参未知时,用名义水平 FOV \(k_x=\pi/2\) 构造射线以防泄漏。再用 kernel=stride=8 的卷积抽出 \(HW/64\) 个 token,拼 4 个 register token,记作目标相机 token \(s\)。
架构:一个 transformer,让 \(s\) 去 attend 编码后的源图特征 \(z_1,\dots,z_V\)。两种 attention 变体(速度/质量 trade-off):
- Full attention,\(\mathcal{O}(V^2)\):\(q=k=v=(s, z_1,\dots,z_V)\)。质量略高。
- Bidirectional cross-attention,\(\mathcal{O}(V)\)(主模型用这个):先在 \(s\) 内部做 full attention,再两层 cross-attention——
- 第 1 层 \(q_1=s,\ k_1=v_1=(z_1,\dots,z_V)\);
- 第 2 层 \(q_2=(z_1,\dots,z_V),\ k_2=v_2=s\)。
- 复杂度随源视角数线性增长 → 支持更多源图实时渲染。
输出时丢掉 register token,把目标相机 token 用 linear 投成 \(8\times8\) patch、reshape 回原图尺寸。
3.5 训练¶
- 损失:L2 (MSE) + perceptual(VGG/Johnson):\(\mathcal{L}=\lambda_2\mathcal{L}_2+\lambda_p\mathcal{L}_p\)。
- 必须端到端微调整个模型(含解冻 VGGT backbone)。原因:VGGT 只为重建几何而预训练,把颜色/反射/透明这些 NVS 关键的外观属性当噪声丢弃了;冻住就学不出反射和好纹理,也更难理解相机条件。
- 数据:13 个多视角数据集混合,规模/多样性约等于 VGGT 的训练数据——TartanAir、Eden、ARKit、BlendMVS、Hypersim、UCo3D、Taskonomy、RealEstate10k、StaticThings、NeSF、MVSSync、WildRGBD + 约 45k 互联网视频(用 SfM 标注相机后过滤)。
3.6 Implementation Details¶
- Encoder:预训练 VGGT(约 1.2B 参数量级的大骨干)。
- Decoder:ViT-B(\(C=768\),12 heads,12 blocks),用 FlashAttention。Full-attn decoder ≈ 85M 参数;主模型的 bidirectional cross-attn decoder ≈ 170M 参数(因为两个方向各一套 attention)。
- 优化:AdamW(\(\beta=(0.9,0.95)\),weight decay 0.05),cosine LR + warm restart + 3k 线性 warmup,QK-norm,grad clip(norm>5 跳过),gradient checkpointing。
- 主模型:512 分辨率(长边)、全数据、250k 迭代、batch size 512。各对比实验按 baseline 调整 batch/lr/iter。
- 增广:源视角数在 1–10 间随机、随机 dropout camera token、随机长宽比。
- 效率:encoding 数秒;decoding 30 FPS+,单张 H100、512×512、≤9 张源图实时。renderer 是标准神经网络——不用显式 3D 表示、不用自定义 CUDA kernel、不用 JIT。
4. 结果对比¶
4.1 对标 LVSM(RealEstate10k 2-view,256×256)¶
跟 LVSM 同一评测协议(pixelSplat 的源/目标视角,同分辨率、同 100k 步)。LVSM 作者给了 batch 64(模拟资源受限)和 batch 512 两档。
| Method | Batch | PSNR ↑ | SSIM ↑ | LPIPS ↓ | |
|---|---|---|---|---|---|
| (a) | LVSM Enc-dec. Bottleneck | 64 | 28.32 | 0.888 | 0.117 |
| (b) | LVSM Decoder-only | 64 | 28.89 | 0.894 | 0.108 |
| (c) | Ours Highway — x-attn | 64 | 30.11 | 0.912 | 0.089 |
| (d) | Ours Highway — full | 64 | 30.48 | 0.918 | 0.086 |
| (e) | LVSM Enc-dec. Bottleneck | 512 | 28.58 | 0.893 | 0.114 |
| (f) | LVSM Decoder-only | 512 | 29.67 | 0.906 | 0.098 |
| (g) | Ours Highway — x-attn | 512 | 31.06 | 0.924 | 0.080 |
| (h) | Ours Highway — full | 512 | 31.39 | 0.928 | 0.078 |
→ 对最强的 LVSM(decoder-only, 512)也有 +1.7dB(31.39 vs 29.67);对 LVSM bottleneck 则 +2.8dB。两档训练规模下都赢。
4.2 对标前馈 3DGS(有/无相机)¶
| 设定 | Method | Test data | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|---|---|
| 有相机·单数据集 | DepthSplat | DL3DV 4-view | 22.30 | 0.765 | 0.189 |
| Ours | 27.56 | 0.869 | 0.095 | ||
| DepthSplat | DL3DV 6-view | 23.47 | 0.812 | 0.154 | |
| Ours | 29.45 | 0.904 | 0.068 | ||
| 无相机·泛化 | AnySplat | Re10k 2-view | 17.05 | 0.626 | 0.349 |
| Flare | 23.77 | 0.801 | 0.191 | ||
| NopoSplat (仅 Re10k 训练) | 24.06 | 0.820 | 0.178 | ||
| Ours (v2) | 25.54 | 0.828 | 0.158 | ||
| AnySplat | CO3D 9-view | 15.87 | 0.526 | 0.423 | |
| Ours (v2) | 22.05 | 0.689 | 0.365 |
→ 全面领先,CO3D 上对 AnySplat +6.2dB。注意:CO3D 9-view 即便 9 张图仍有大量遮挡,pixel-aligned Gaussian 方法(AnySplat/Flare)在没被任何源视角看到的区域直接留洞;本文隐式表示能「想象」简单区域(如地板)。
 Figure 4:vs 前馈 3DGS 的定性对比。本文(隐式)在反射面(镜子、桌面)、薄结构(金属杆、椅臂)、遮挡补全(地板)上明显更好;3DGS 强制 Gaussian-ray 对齐,看不见的地方就是空洞。
Figure 4:vs 前馈 3DGS 的定性对比。本文(隐式)在反射面(镜子、桌面)、薄结构(金属杆、椅臂)、遮挡补全(地板)上明显更好;3DGS 强制 Gaussian-ray 对齐,看不见的地方就是空洞。
4.3 关键消融(DL3DV 2-view,已知相机)¶
注:这张表的绝对 PSNR(~21)比 §4.1(~31)低,是因为评测 split / 数据更难,只用于横向比较各 ablation。
| Encoder | E2E | X-attn | Pre-Tr. | PSNR ↑ | SSIM ↑ | LPIPS ↓ | |
|---|---|---|---|---|---|---|---|
| (a) | Highway | ✓ | ✓ | 3D | 21.02 | 0.652 | 0.257 |
| (b) | Highway | ✓ | ✗ (full) | 3D | 21.30 | 0.667 | 0.248 |
| (c) | Decoder only | ✓ | ✗ | — | 18.39 | 0.533 | 0.407 |
| (d) | Bottleneck | ✓ | ✗ | — | 17.53 | 0.480 | 0.461 |
| (e) | Highway | ✓ | ✓ | — (scratch) | 18.03 | 0.551 | 0.405 |
| (f) | Highway | ✓ | ✓ | 2D (DinoV2) | 18.17 | 0.515 | 0.388 |
| (g) | Highway | ✗ (frozen) | ✓ | 3D | 19.01 | 0.553 | 0.334 |
三条核心结论:
- 3D 预训练至关重要:(a) 21.02 vs (e) scratch 18.03 = +2.9dB;而 (f) 2D 预训练(DinoV2)只带来 +0.14dB——说明吃到的不是「随便什么强特征」,而是显式 3D 监督这件事本身。
- 必须端到端解冻 VGGT:(a) 21.02 vs (g) 冻结 19.01 = +2.0dB。冻结时缺反射、纹理差、也学不会理解源相机。
- Highway > Decoder-only > Bottleneck:(a/b) > (c) 18.39 > (d) 17.53。Highway 即便被「更快的 cross-attn」拖累 (a),仍胜过 decoder-only 和 bottleneck。
4.4 Decoder attention 变体(512 实时上限 vs 质量)¶
| Attention | 复杂度 | 实时@512 最大图数 | 2-view | 4-view | 6-view | Params |
|---|---|---|---|---|---|---|
| Full | \(\mathcal{O}(V^2)\) | 6 | 21.30 | 24.17 | 24.84 | 85M |
| Unidirectional x-attn (未采用) | \(\mathcal{O}(V)\) | 26 | 20.51 | 22.56 | 22.91 | 113M |
| Bidirectional x-attn(主模型) | \(\mathcal{O}(V)\) | 9 | 21.02 | 23.65 | 24.54 | 170M |
→ 主模型选 bidirectional cross-attn:相比 full attention 仅掉 ~0.3 PSNR,但实时源图上限从 6 张提到 9 张。Unidirectional 虽能到 26 张但质量掉太多(6-view 差到 -1.9)。
4.5 生成式 NVS(diffusion decoder)¶
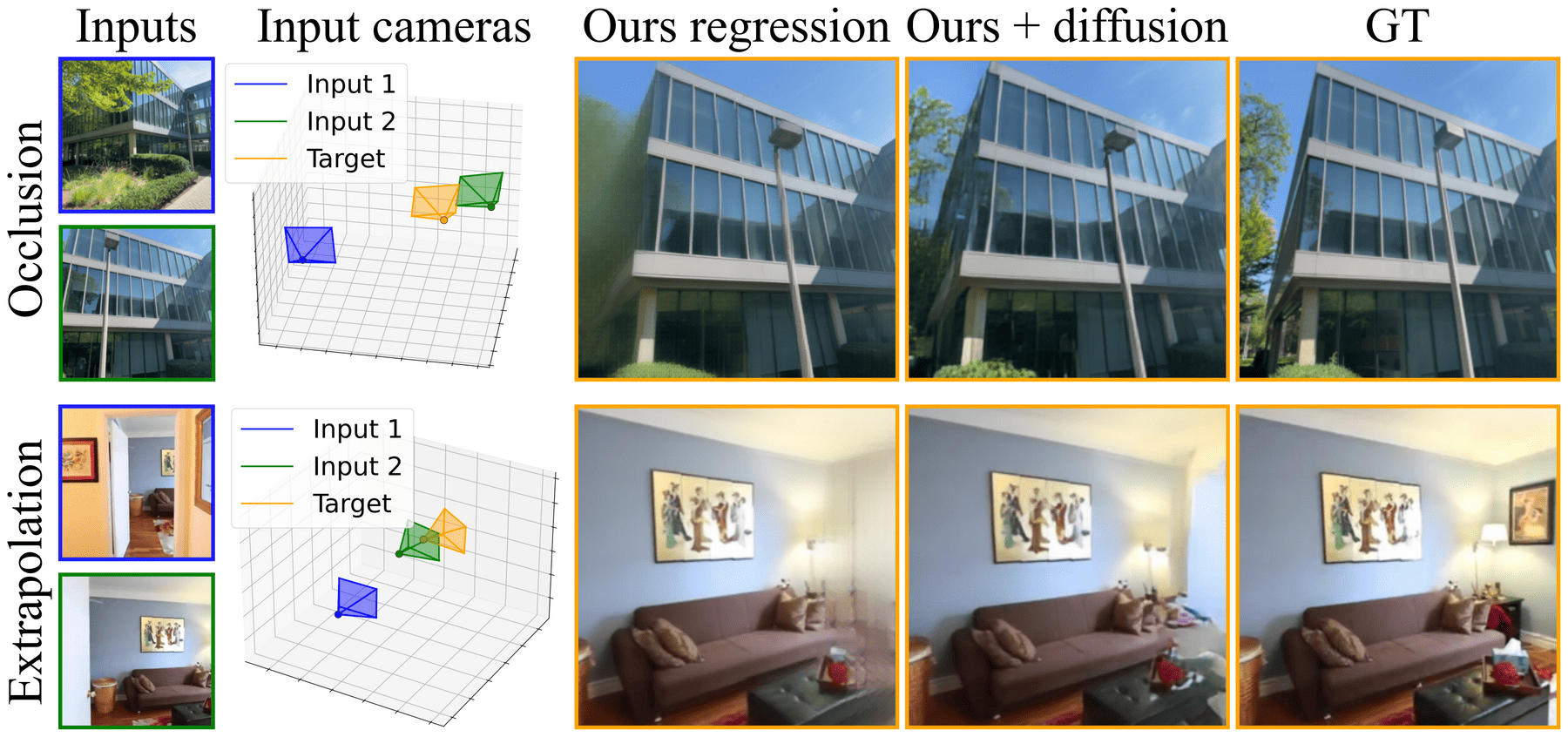 Figure 5:把 decoder 微调成 diffusion 后,在遮挡和外推两种「确定性模型会糊成均值」的场景下,能 hallucinate 出合理的补全。
Figure 5:把 decoder 微调成 diffusion 后,在遮挡和外推两种「确定性模型会糊成均值」的场景下,能 hallucinate 出合理的补全。
冻住 encoder,只把 decoder 改成 denoising diffusion:输入层多接噪声图通道、加 adaLN-zero 的 timestep conditioning。仅微调 60k 步、像素空间(无 latent diffusion)、12 个 transformer block,就能在遮挡 / 外推场景生成合理补全(确定性模型在这些场景只会出模糊均值)。作者明确定位为 preliminary 实验。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 「3D-aware 特征」的归因做得干净。不是简单说「用了强 backbone 就好」,而是用 (e)(f)(a) 三行隔离出:scratch 18.03 → DinoV2(2D 预训练)18.17(几乎没动)→ VGGT(3D 预训练)21.02。2D 强特征几乎无效、3D 监督特征 +2.9dB——这把功劳精确地落在「显式 3D 监督」而非「特征强度」上,是这篇最有说服力的实验设计。
- 推翻了 LVSM「enc-dec 不如 decoder-only」的结论,并指出真正原因。LVSM 把锅甩给 enc-dec 架构,本文论证那是 Bottleneck 的信息瓶颈,换成 Highway(每张源图独立 token、信息无衰减)后 enc-dec 反超。这同时保住了「encode 一次、decode 多次」的摊销红利。
- bidirectional cross-attention 把渲染做到无 custom kernel 的实时。\(\mathcal{O}(V)\) 让 9 张源图也能 30 FPS+,相比 full attention 只掉 0.3 PSNR;而且整条 renderer 是标准神经网络,不依赖 3DGS 那种自定义光栅化 CUDA kernel,部署上是实打实的简化。
- 隐式表示对遮挡/反射/薄结构的天然优势被讲清楚了。pixel-aligned Gaussian 强制 Gaussian 沿射线对齐,看不见就是洞;本文全局 latent 表示让确定性模型也能「脑补」地板这类简单区域。CO3D 上 +6.2dB 主要来自这里,定性图(Fig 4)佐证扎实。
- diffusion 复用证明了特征是好底座。同一 decoder、冻结 encoder,60k 步、像素空间、12 block 就学会 diffusion——侧面说明 3D-aware 特征对生成式任务也是好的起点。
- 对自己 v1 的焦距泄漏诚实改正。第一版在「无源相机」设定下偷偷把源焦距泄漏给了模型;作者在脚注 + 附录里公开承认,v2 用名义 FOV \(k_0=53.13°=\arctan(0.5)\) 修复,并报告(略低但仍 SoTA 的)修正后数字。这种自曝其短在 NVS 论文里少见。
5.2 做得不够好 / 值得质疑的地方¶
- 「+5~6dB 碾压 3DGS」混入了训练数据的功劳,不是干净的架构对比。唯一控变量严格的是 §4.1 对 LVSM(同 Re10k、同 batch/步数),那里是 +1.7dB。而 vs DepthSplat(+5.3dB)、vs AnySplat(+6.2dB)里,本文用的是 13 数据集 ≈ VGGT 规模的大混合,DepthSplat 只训 DL3DV、AnySplat 训自己那套——架构 vs 数据的贡献无法分离。把「+6dB」当架构胜利来读会高估。
- 「实时」只指 decoder,encoder 是个 1.2B 的巨物。"encoding requires mere seconds" 把 encoder 体量轻描淡写过去了。对「静态场景 + 移动相机」这能摊销;但场景一变就要重跑整个 VGGT。real-time 是 decoder-only 的属性,不是 end-to-end 的。
- 「高效」的主模型 decoder 反而参数更多(170M vs full 的 85M)。bidirectional cross-attn 是 \(\mathcal{O}(V)\) 没错,但因为两个方向各一套 attention,参数翻倍。这里的「efficient」指高 \(V\) 时的 wall-clock FPS,不是参数效率——表里没解释为什么 O(V) 变体要 2× 参数,容易误读。
- 生成式部分是 teaser,不是结果。只有一张定性图(Fig 5),没有任何定量指标(FID / 感知分 / 多样性),没有和 CAT3D 等生成式 NVS 的对比。「我们也能做 diffusion」目前是宣称而非证据。
- 共享/固定内参假设很强。假设所有源/目标相机焦距相同、像素正方、光心居中。in-the-wild 采集普遍违反这些。v1→v2 这段焦距风波本身就暴露了内参处理的脆弱。
- 纯隐式 = 拿不到任何下游几何。和 3DGS 方法不同,LagerNVS 导不出 mesh / 点云 / 可重光照资产,它只是个图像渲染器。需要几何的应用(仿真、编辑、relighting)用不了——「我们打败 3DGS」的叙事会掩盖这个本质取舍。
- 单视角 NVS 只在「小相机运动」下成立(Fig 6 caption 自己写的)。而单视角大基线恰恰是最需要先验、最能体现 3D-aware 价值的 regime,这里却退化。泛化卖点主要靠多视角撑着。
- CO3D 的 PSNR 优势被指标选择放大。作者自己注明 AnySplat/Flare 的 LPIPS 反而有竞争力——因为「锐利但错」在感知指标上不吃亏,而本文「模糊但合理」的补全恰好讨好 PSNR。所以 +6.2dB PSNR 高估了真实感知差距。
- 各表评测设定异构,难拼成单一故事。分辨率(256 vs 512)、源视角数(2/4/6/9)、split 都随 baseline 变。每张表都是为对齐某个特定 baseline 协议定制的,读者很难读出一条一致的强度曲线。
5.3 值得继续探讨的方向¶
- encoder 能瘦多少而不丢 3D-awareness:用 π³ / 更轻的 MVS 骨干替换 VGGT,或蒸馏一个小 encoder,能否保住大部分 +2.9dB?这直接决定 end-to-end 的实用性。
- 视频/移动相机下的 encoder 缓存与增量更新:相机在静态场景里移动时,能否增量更新 per-scene 编码而不是每次重算整个 VGGT?
- 在 VGGT 预训练里就加 rendering head:作者自己建议未来的 VGGT-like 应在预训练时加渲染损失以保住外观信息。若如此,是否就不必端到端解冻、encoder 可以冻住?
- 认真 scale diffusion decoder:上定量生成评测(FID / 感知)、latent diffusion、更多 block;3D-aware encoder 是否真给了 diffusion 一个相对 CAT3D 之流的起跑优势?
- latent + explicit 混合:能否从 latent 读出一个显式 3DGS 供需要几何的应用,同时保留 latent renderer 的质量?
- 内参泛化:处理变化/未知内参、非针孔相机、rolling shutter。
- 借并发 SVSM 的 scaling law:在本文设定下,compute-optimal 的 encoder/decoder 算力划分是多少?
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: szymanowiczs.github.io/lagernvs
- 关键 baseline / 相关论文:
- LVSM (Jin et al. 2025) — 直接对标的前 SoTA 隐式 NVS,本文的 decoder-only / Bottleneck 对照原型
- VGGT (Wang et al. 2025) — encoder 的预训练来源(3D 重建骨干)
- AnySplat (Jiang et al. 2025) — 同样基于 VGGT 但走显式 3DGS 路线的主要对照
- DepthSplat (Xu et al. 2025) / Flare (Zhang et al. 2025) — 前馈 3DGS baseline
- SRT (Sajjadi et al. 2022) / RayZer (Jiang et al. 2025) — 隐式 light-field NVS 前序
- SVSM (Kim et al. 2026) — 并发的 encoder-decoder NVS scaling law 工作