π*₀.₆ (RECAP): a VLA That Learns From Experience¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:π*₀.₆: a VLA That Learns From Experience
- 作者机构:Physical Intelligence(Kevin Black, Danny Driess, Chelsea Finn, Karol Hausman, Sergey Levine, Suraj Nair, Karl Pertsch, Jost Tobias Springenberg 等数十位作者,集体署名 Physical Intelligence)
- 出处:arXiv 2511.14759,提交于 2025-11;项目页
https://pi.website/blog/pistar06 - 关键词:VLA、reinforcement learning、advantage conditioning、flow matching、offline RL、human intervention/correction、value function、CFG
- 一句话:提出 RECAP(RL with Experience and Corrections via Advantage-conditioned Policies)这套通用 RL 配方,把 reward 反馈与人工干预贯穿到 VLA 训练全流程(从 pre-train 到部署后改进),训练出能"从真实经验中越练越好"的 π*₀.₆ 模型,在折叠衣物、组装纸箱、制作 espresso 等真实任务上把 throughput 翻倍、把失败率减半。
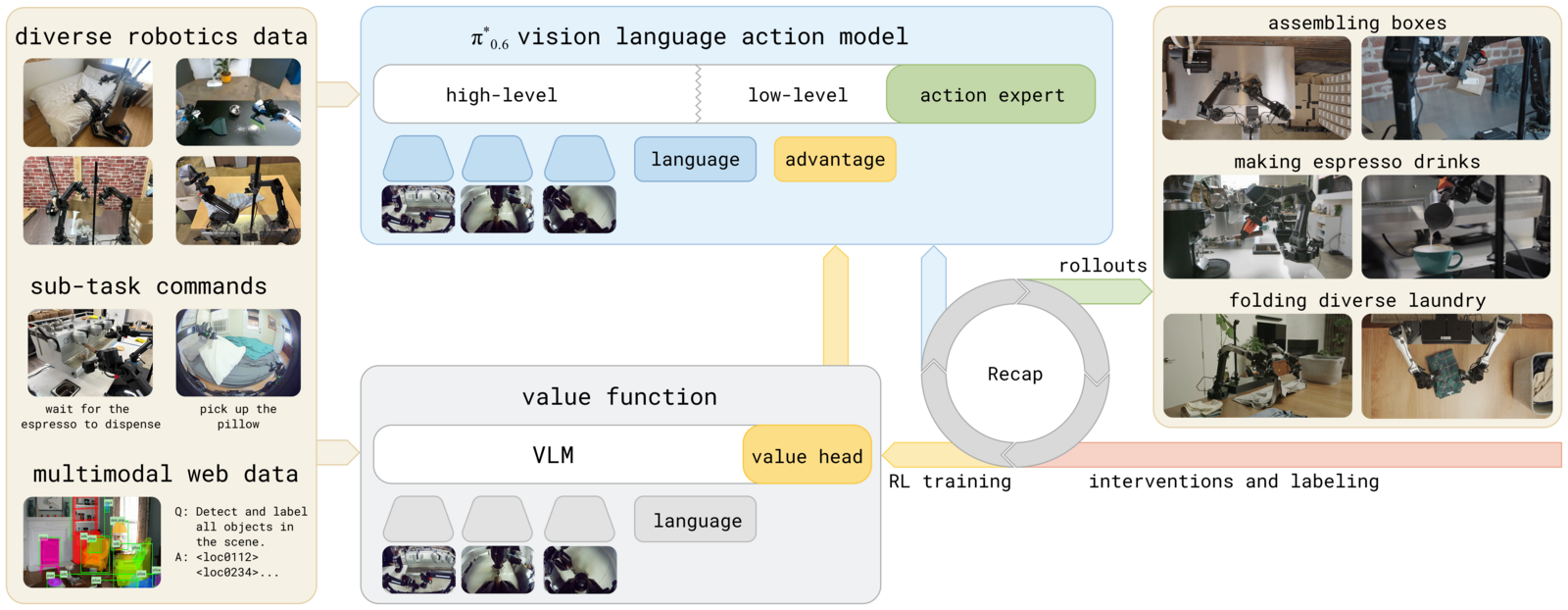 Figure 1:takeaway — RECAP 用 reward + 人工干预(intervention/correction)让 VLA 从真实经验中改进。流程为:带 advantage conditioning 的 pre-trained VLA → 部署收集 autonomous rollouts + online human corrections → 用这些 online 数据 fine-tune value function → 用更新后的 advantage 估计 fine-tune/condition 策略。
Figure 1:takeaway — RECAP 用 reward + 人工干预(intervention/correction)让 VLA 从真实经验中改进。流程为:带 advantage conditioning 的 pre-trained VLA → 部署收集 autonomous rollouts + online human corrections → 用这些 online 数据 fine-tune value function → 用更新后的 advantage 估计 fine-tune/condition 策略。
2. 文章介绍¶
2.1 解决的领域和问题¶
本文研究 VLA(vision-language-action)模型如何通过真实世界部署 + RL 持续改进,而不是只停留在 imitation learning(行为克隆,BC)的水平。
核心痛点:BC 训练的 VLA 在能力上"天花板就是示范数据"——示范者多快、多稳,策略最多也只能这么快、这么稳,并且会受到 compounding error(误差累积)的困扰。要达到真正可用的可靠性和速度(例如连续工作数小时、失败率个位数百分比),就需要让模型像人一样"练习":在部署中收集自己实际犯错的数据并加以纠正,超越人类遥操作的速度,并适应新的部署条件。RL 是这一目标的理论框架,但把它在大模型 + 真机 + 稀疏/含噪 reward 的环境里做得既通用又可扩展,一直很难。
2.2 Motivation¶
纯 BC 的 VLA 在部署时面对 distribution shift(自己造成的状态分布偏移)无法自我纠正:示范数据里没有"犯错后如何恢复"的样本,于是错误会滚雪球。同时,遥操作示范的速度和流畅度也限制了策略上限。作者主张:要达到与人相当的鲁棒性、速度与流畅度,必须从经验中学习——综合利用 demonstrations、autonomous rollouts(自主执行轨迹)和 expert interventions(专家在自主执行中进行的纠正),并用 reward 信号指导改进。
2.3 之前工作的问题¶
| 路线 | 代表 | 主要缺陷 |
|---|---|---|
| 纯 imitation VLA(BC) | π₀ / π₀.₅ / π₀.₆ | compounding error;上限就是示范数据;部署中无法自我纠正、无法超越人类速度 |
| 在线 RL on robots(PPO/REINFORCE 直接训 VLA) | InteractivePostTraining, VLA-RL, SimpleVLA-RL, VLAC, Self-Improving EFM | on-policy、需频繁真机采新数据,难以高效扩展;多用离散动作或简单高斯动作,难配 flow matching VLA;policy gradient 在大模型上不稳定 |
| DAgger 式人工纠正 | HG-DAgger, SHIV, DART, RaC | 理论上要求专家给出"最优"纠正,但真机里 intervention 是破坏性事件,质量不一致、无法改进速度等细节;本质是监督而非自主学习 |
| offline RL / RL fine-tune on top of VLA | residual policy, action-head fine-tune, DSRL(噪声空间), CO-RFT, GRAPE(DPO) | 多在预训练 VLA 之上加小模块,不是端到端训练整个 VLA;或仅离线无在线改进;或依赖偏好/Q-learning,任务窄(抓取、推物、移碗) |
| advantage/reward-conditioned policy | Decision Transformer, RvS, RCSL, CFGRL | 此前多在小模型/仿真验证,未扩展到大规模 generalist VLA,也未融合 demo+intervention+autonomous 多源数据 |
2.4 论文解决方案(一句话)¶
用 advantage conditioning(把策略条件在一个二值"优势改进指示符" \(I_t\) 上)替代不稳定的 policy gradient 做 policy extraction,从而能用一套简单可扩展的 iterated offline RL 配方,端到端训练 flow-matching VLA,并把 demonstration、autonomous rollout、human correction 三类异构数据统一纳入改进循环。
2.5 与前序工作的关系¶
- build on π₀.₆:π₀.₆ 是 π₀.₆ 为 RL 改造而来的版本;π₀.₆ 又是 π₀.₅(black2025pi05)的演进,换上更大的 Gemma 3 4B backbone、860M 的 action expert、更多机器人平台数据。π₀.₆ 在 π₀.₆ 基础上新增了对二值 advantage indicator 的条件能力。
- advantage conditioning 的理论根:来自 regularized RL 的一个不太常用的结论——若把策略写成 \(\hat{\pi}(a|o) \propto \pi_\text{ref}(a|o)\, p(I|A^{\pi_\text{ref}}(o,a))^\beta\),其中 \(p(I|A)\) 是"该动作相对 \(\pi_\text{ref}\) 改进"的概率,则 \(\hat\pi\) 保证不劣于 \(\pi_\text{ref}\)。
- 与 RL-as-conditioning / Decision Transformer:属于"把策略条件在 return/value/advantage 上"的家族(Upside-Down RL、RCSL、DT、RvS),但本文条件的是基于 value function 的 advantage 二值指示符,且扩展到 generalist VLA。
- 与 CFG 的关系:最接近 CFGRL(Frans 2025)。通过 Bayes 把改进概率重写为 \(\pi_\text{ref}(a|I,o)/\pi_\text{ref}(a|o)\),模型同时学习条件分布与无条件分布;推理时即可像 classifier-free guidance 一样用权重 \(\beta\) 在两者间外推(\(\beta>1\) 锐化)。
- 与 AWR/policy gradient 的对比:AWR 等 weighted regression 会丢弃/大幅降权"坏"数据,相当于 filtered imitation;advantage conditioning 则用全部数据做监督学习,只是额外告诉模型这个动作好不好。
3. 方法介绍¶
3.1 形式化(advantage-conditioned policy)¶
标准 RL 设置:策略 \(\pi(a_t|o_t)\)、轨迹 \(\tau\)、reward \(r_t\)、return \(R(\tau)=\sum_t r_t\)(不使用 discount)。value function \(V^\pi(o_t)=\mathbb{E}[\sum_{t'\ge t} r_{t'}]\),advantage 用 n-step 估计: $\(A^\pi(o_t,a_t)=\mathbb{E}\big[\textstyle\sum_{t'=t}^{t+N-1} r_{t'} + V^\pi(o_{t+N})\big] - V^\pi(o_t).\)$
核心结论(regularized RL):定义改进概率 \(p(I|A^{\pi_\text{ref}})=g(A)/\int g(A')\,da'\)(\(g\) 单调递增),则 $\(\hat{\pi}(a|o)\propto \pi_\text{ref}(a|o)\,p(I|A^{\pi_\text{ref}}(o,a))^\beta\)$ 保证 \(\mathcal{J}(\hat\pi)\ge\mathcal{J}(\pi_\text{ref})\)。再经 Bayes 重写: $\(\hat{\pi}(a|o,\ell)\propto \pi_\text{ref}(a|o,\ell)\Big(\tfrac{\pi_\text{ref}(a|I,o,\ell)}{\pi_\text{ref}(a|o,\ell)}\Big)^\beta.\)$ 当 \(\beta=1\) 时直接退化为 \(\hat\pi=\pi_\text{ref}(a|I,o,\ell)\)——即只要训练一个能同时表示"有条件 \(I\)"和"无条件"的策略,就能拿到改进后的策略,无需显式建模 \(p(I|A)\)。这正是 CFG 的训练思路。
3.2 RECAP pipeline 总览¶
方法由三个子过程构成,可重复多轮(见 Algorithm 1):
- Data collection:在任务上跑 VLA,给每条 episode 打成败标签(决定 reward),可选地由专家在自主执行中提供 corrections。
- Value function training:用迄今所有数据训练一个大的 multi-task value function \(V^{\pi_\text{ref}}\)(检测失败、判断到成功还要多少步)。
- Advantage-conditioned policy training:用 value function 给每个动作算 advantage,转成二值指示符 \(I_t\) 放进 VLA 的 prefix,做监督式 policy extraction。
整体分两阶段: - Pre-training:在数万小时、多任务多机器人的示范数据上做 (2)+(3)。 - Post-training(学习经验):对每个目标任务,先用示范 SFT 得到 \(\pi^0_\ell\),再做 K 轮 (1)→(2)→(3)。注意:每一轮的 value function 和 policy 都从 pre-train checkpoint 重新 fine-tune(而非接上一轮),以避免多轮漂移。实践中常常一轮就有显著提升。
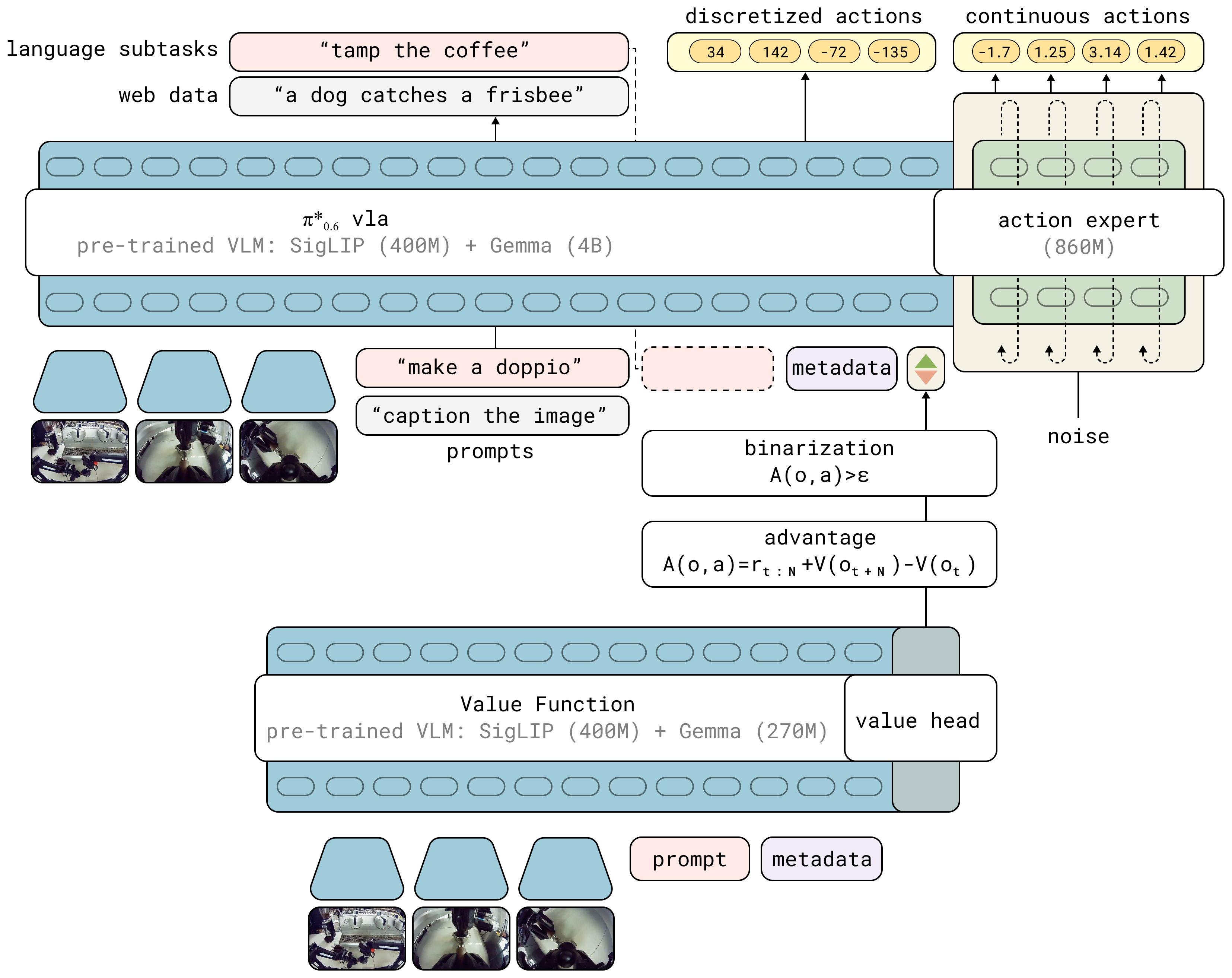 Figure 2:π₀.₆ VLA 与 value function 在 RECAP 训练中的交互。VLA 用预训练 VLM backbone,遵循 KI(Knowledge Insulation)recipe:pre-train 时对多源数据做 next-token prediction,flow-matching action expert 用 stop gradient 隔离。VLA 条件在二值 advantage indicator 上;该 indicator 由一个独立的、从更小 VLM 初始化的 value function 提供。*
Figure 2:π₀.₆ VLA 与 value function 在 RECAP 训练中的交互。VLA 用预训练 VLM backbone,遵循 KI(Knowledge Insulation)recipe:pre-train 时对多源数据做 next-token prediction,flow-matching action expert 用 stop gradient 隔离。VLA 条件在二值 advantage indicator 上;该 indicator 由一个独立的、从更小 VLM 初始化的 value function 提供。*
3.3 Advantage conditioning 与推理(β 参数、CFG-style steering)¶
- 训练目标(式 7):在数据 \(\mathcal{D}_{\pi_\text{ref}}\) 上最小化 $\(\mathbb{E}\big[-\log\pi_\theta(a_t|o_t,\ell)-\alpha\log\pi_\theta(a_t|I_t,o_t,\ell)\big],\quad I_t=\mathds{1}(A^{\pi_\text{ref}}(o_t,a_t,\ell)>\epsilon_\ell).\)$ \(I_t\) 以文本形式注入:"Advantage: positive" 或 "Advantage: negative",位置在子任务文本 \(\hat\ell\) 之后、动作之前,因此只影响动作的 log-likelihood。连续动作部分用 flow matching loss(作为 log-likelihood 的下界)替代精确似然,离散动作(FAST tokenizer)用交叉熵。
- 改进阈值 \(\epsilon_\ell\):每个任务设一个阈值。pre-train 时设为该任务 value 的 30% 分位(约 30% 数据为 positive);fine-tune 时一般设到约 40% rollout 为 positive;T-shirt/shorts 这种"示范已很可靠但慢"的任务则调高阈值,只让约 10% 数据为 positive。作者强调主要靠 \(\epsilon_\ell\)(训练时锐化)而非 \(\beta\) 来权衡 regularization 与 optimality。
- conditioning dropout:训练时 30% 概率丢掉 \(I_t\),使模型既能采条件分布也能采无条件分布(替代损失系数 \(\alpha\)),从而支持推理时 CFG。
- 推理 / β 参数:默认 \(\beta=1\),直接以 \(I_t=\text{True}\) 采样。\(\beta>1\) 时按 CFG 在条件/无条件梯度间外推: $\(\nabla_a\log\pi_\theta(a|o,\ell)+\beta\big(\nabla_a\log\pi_\theta(a|I,o,\ell)-\nabla_a\log\pi_\theta(a|o,\ell)\big),\)$ 进一步锐化策略,无需重新训练。但作者警告:\(\beta\) 过大会把动作分布推到支撑边界,导致动作过激;故实际只用适中的 \(\beta\in[1.5,2.5]\)。
3.4 价值函数 + 人工干预/corrections 的纳入¶
- value function 设计:multi-task distributional value function \(p_\phi(V|o_t,\ell)\in\Delta_B\),把经验 return 离散成 \(B=201\) 个 bin,用交叉熵做 Monte-Carlo 回归(即拟合行为策略 \(\pi_\text{ref}\) 的 value)。再按 \(V=\sum_b p_\phi(V=b)\,v(b)\) 取连续 value。这是 on-policy/Monte-Carlo 估计——作者承认不如经典 off-policy Q-function 最优,但简单且非常可靠,仍能显著超过 imitation。
- reward 定义:通用稀疏 reward——每条 episode 只有成败标签。\(r_t=0\) 若末步成功;\(r_t=-C_\text{fail}\) 若末步失败;其余步 \(-1\)。于是 value ≈ "到成功还差多少步"(成功的负步数),并按任务最大长度归一化到 \((-1,0)\)。
- 架构:value function 与 VLA 同构但用更小的 670M VLM backbone(也从 Gemma 3 初始化),训练时混入少量多模态 web 数据防过拟合;可在 VLA 训练时on-the-fly 推理算 advantage,开销很小。
- advantage 估计:post-train 用 N=50 步 lookahead 的 n-step advantage;pre-train 用 \(N=T\)(整条 episode,方差更大但一次推理即可)。
- corrections 的纳入:自主执行时专家可介入纠正。关键设计——对所有 human correction 动作强制 \(I_t=\text{True}\)(假设专家纠正总是好的);整条 episode(自主部分 + 纠正部分)都加入数据集。作者明确指出:corrections 本身不足以修好一切——介入是破坏性事件,质量不一致,也无法改进速度等细节;它主要用来修大错和帮助 exploration,并不提供 DAgger 理论意义上的最优监督,细节改进要靠自主数据 + RL。
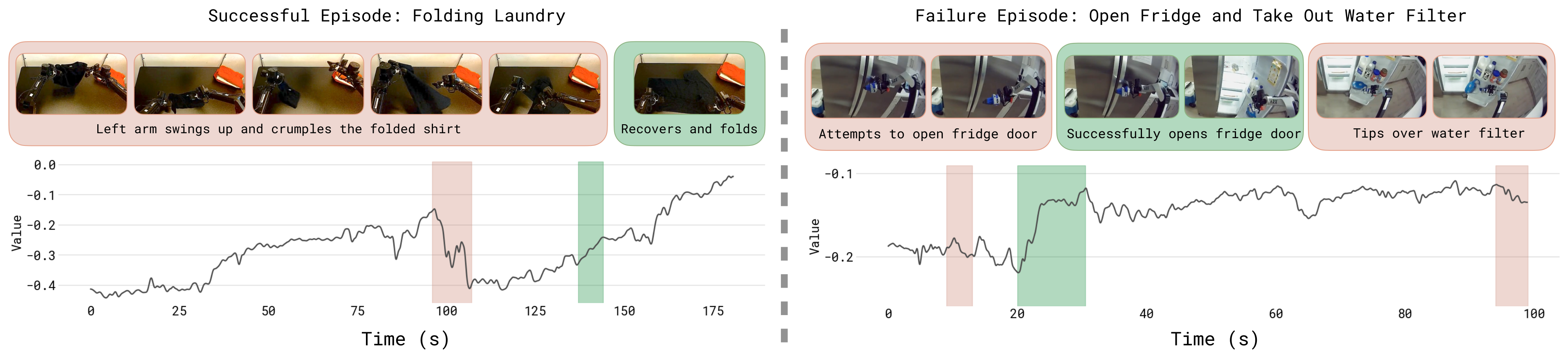 Figure 3:value function 可视化。VF 预测"到成功的剩余步数"(归一化到 (-1,0),0 为成功)。左:成功的折叠任务;右:pre-train 数据里一个失败的操作任务。红色=value 下降(识别出失误),绿色=value 上升(进展)。VF 能正确定位错误并反映进展速度。
Figure 3:value function 可视化。VF 预测"到成功的剩余步数"(归一化到 (-1,0),0 为成功)。左:成功的折叠任务;右:pre-train 数据里一个失败的操作任务。红色=value 下降(识别出失误),绿色=value 上升(进展)。VF 能正确定位错误并反映进展速度。
3.x Implementation Details¶
- base model:π₀.₆(π₀.₅ 的演进);VLM backbone = Gemma 3 4B;action expert = 860M 参数,flow matching 输出 50 Hz 关节角 + 夹爪指令;遵循 KI(Knowledge Insulation)训练,stop gradient 隔离 action expert;同时预测子任务文本 \(\hat\ell\)(高层决策,低频运行)和 FAST 离散动作 token。
- value function:670M VLM backbone(Gemma 3 初始化),201 个 value bin。
- 机器人平台:静态双臂系统,两条 6-DoF 臂 + 平行夹爪,50 Hz 关节位置控制;观测 = 关节/夹爪位置 + 3 路相机(base + 双腕)。pre-train 数据来自多种机器人。
- 任务:折叠衣物(T-shirts & shorts / diverse 11 类 / 严格失败移除)、做 espresso(双份浓缩,含磨豆、压粉、锁手柄、萃取、出杯)、组装纸箱(工厂真实部署,折箱、贴标、放入箱筐)。每个任务 5–15 分钟、多步、含可变形物 / 液体 / 受力操作。
- 数据量(每任务):
- T-shirt/shorts:仅自主数据无纠正,每轮 300 episodes × 4 robots,2 轮。
- diverse laundry:450 eval + 287 correction episodes。
- 失败移除:约 1000 自主 + (280+378) correction,3 robots,2 轮。
- box assembly:每轮 600 demo + 360 correction,3 robots。
- cafe:单轮,429 correction + 414 autonomous。
- 训练/部署流程:pre-train(VF→阈值→advantage→VLA)→ 目标任务 SFT(\(I_t\) 固定 True)得 \(\pi^0\) → 部署收数据 → fine-tune VF → 用更新 advantage fine-tune policy,可多轮。最终 generalist 从头训,specialist 从 pre-train checkpoint fine-tune。
- 推理设置:默认 \(\beta=1\);部分实验用 CFG(\(\beta\in[1.5,2.5]\))。
4. 结果对比¶
指标:throughput(每小时成功完成的任务数,同时反映成功率和速度)与 success rate(人工标注的成功比例)。
baselines:pre-trained π₀.₅ / pre-trained π₀.₆(无 advantage indicator,纯 SFT)/ RL pre-trained π₀.₆ / π₀.₆ offline RL + SFT(在 RL pre-train 的 π*₀.₆ 上用示范 SFT,\(I_t\) 固定 True,是数据采集的起点)/ π₀.₆ (ours, 含自主 + 纠正);另比较两种替代 policy extraction:AWR 和 PPO*(DPPO/FPO + SPO 风格 trust region 的变体)。
主结果(Figures 4–5,定性数字来自正文):
| 对比 | 结论 |
|---|---|
| π*₀.₆ (ours) vs 各 baseline | 全部任务上显著优于 supervised π₀.₆、RL pre-trained π*₀.₆、offline RL + SFT |
| throughput(diverse laundry / espresso,从 offline RL+SFT → 最终模型) | throughput >2× 提升,失败率约降 2× |
| T-shirts & shorts(简单) | SFT 后 success 已接近上限,但 throughput 仍大幅提升 |
| 最终 success rate | 除 diverse laundry 外均达 90%+;可实用(office 做咖啡、工厂组装箱) |
| 长时连续运行 | espresso 连续 13 小时;新家折叠新衣物 2 小时+ 无中断;工厂真实纸箱组装 |
多轮迭代(Figures 6–7,experiment3,T-shirt 和 box assembly):
| 任务 | 迭代效果 |
|---|---|
| T-shirt/shorts(仅自主数据,无纠正,2 轮,每轮 300 traj) | success 第 1 轮即 >90%;throughput 整体 +50%——证明纯 RL(无 intervention)也能改进 |
| box assembly(自主 + 纠正,每轮 600 自主 + 360 纠正) | 长时任务需更多数据,先降后升,第 2 轮后 throughput 2×;折箱/贴标在 600 秒内 success ≈90% |
policy extraction 对比(Figure 8,experiment2,用与 ours 相同甚至更优的数据):
| 方法 | 结果 |
|---|---|
| RECAP(advantage conditioning) | throughput 最高,远超对手 |
| AWR | success 还行,但策略慢、throughput 低 |
| PPO(需极小 trust region η=0.01 才稳定) | 训练稳定但性能差,难超过 offline RL + SFT |
失败模式移除(Figure 9,experiment5):在 collar 必须朝上的严格 T-shirt 任务上,对抗性初始条件下用 RECAP 2 轮(每轮 600 traj,纯 RL 无 intervention 无额外示范)把成功率提到 97% 且速度快——说明 RECAP 能用较少数据精准移除特定失败模式。
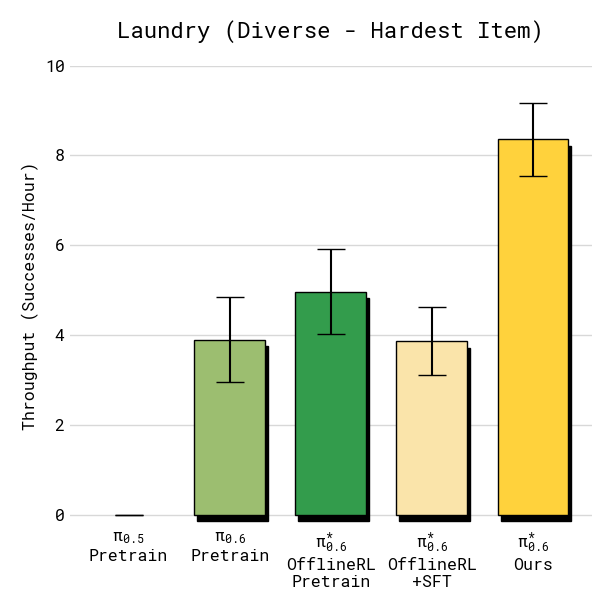 Figure 4:diverse laundry(最难单品 button-up shirt)的 throughput(每小时成功数)。π₀.₆ (Ours) 较各 baseline 显著提升,throughput 翻倍以上。*
Figure 4:diverse laundry(最难单品 button-up shirt)的 throughput(每小时成功数)。π₀.₆ (Ours) 较各 baseline 显著提升,throughput 翻倍以上。*
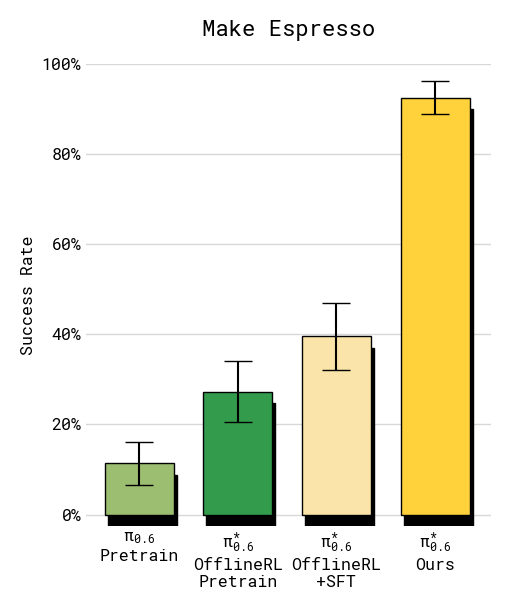 Figure 5:espresso 任务的 success rate。RECAP 各阶段逐步提升,最终模型达 90%+,失败率约降 2×。
Figure 5:espresso 任务的 success rate。RECAP 各阶段逐步提升,最终模型达 90%+,失败率约降 2×。
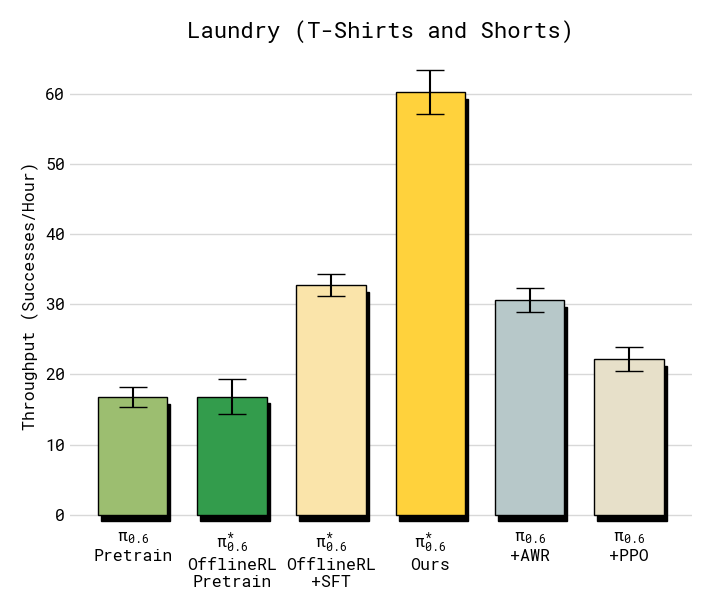 Figure 6:policy extraction 方法对比(T-shirts & shorts,throughput)。advantage conditioning(RECAP)远高于 AWR 与 PPO。
Figure 6:policy extraction 方法对比(T-shirts & shorts,throughput)。advantage conditioning(RECAP)远高于 AWR 与 PPO。
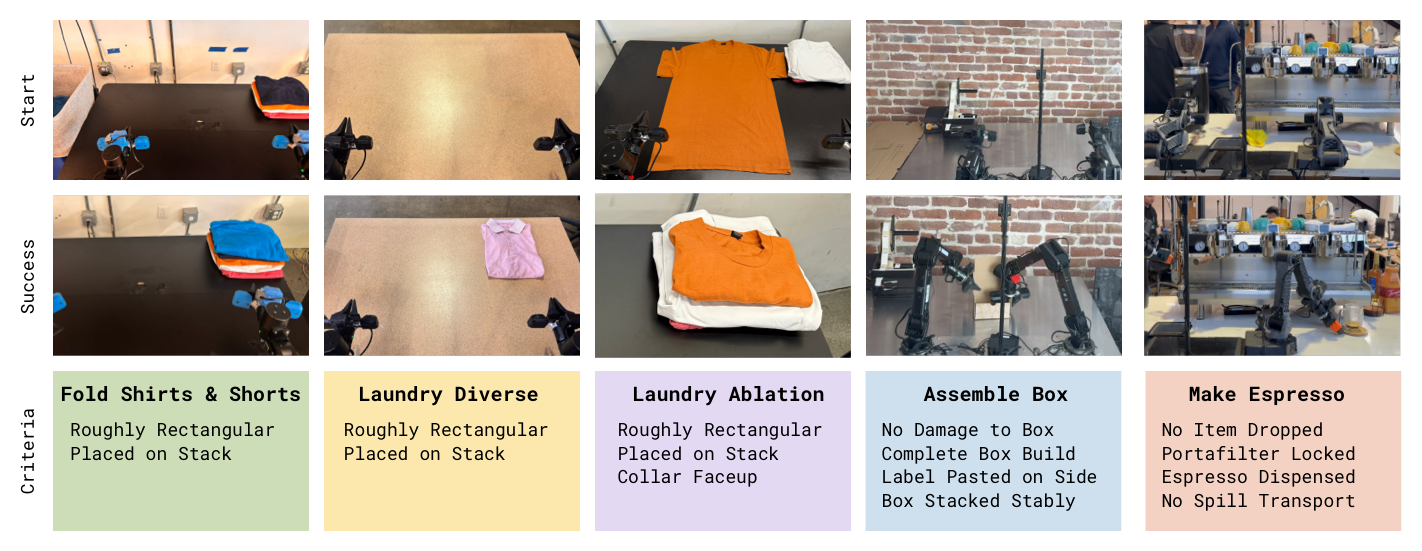 Figure 7:实验任务示意——三种 laundry 变体、纸箱组装、espresso machine 制作咖啡。
Figure 7:实验任务示意——三种 laundry 变体、纸箱组装、espresso machine 制作咖啡。
 Figure 8:RECAP 学到的部分任务连拍——做 espresso、组装纸箱、折叠多样化真实衣物,均含真实变异性(粘连弯曲的纸板、倒液体、各种衣物)。
Figure 8:RECAP 学到的部分任务连拍——做 espresso、组装纸箱、折叠多样化真实衣物,均含真实变异性(粘连弯曲的纸板、倒液体、各种衣物)。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- advantage conditioning 避开 policy gradient 的不稳定:把"改进策略"变成"在全部数据上做条件监督学习 + 一个二值指示符",天然兼容 flow matching/diffusion VLA(这些模型没有可解析的 log-likelihood,难做 PPO/SAC),且能用全部 off-policy/offline 数据。实验里直接吊打 AWR 和 PPO。
- 人工纠正补 reward 稀疏与 exploration:稀疏成败 reward 下纯自主探索很难触发罕见的正确行为;intervention 提供"如何从大错恢复"的稀有正样本,强制标 positive 注入策略,缓解 exploration 难题。
- β 提供 test-time steering:CFG 式的 \(\beta\) 让人能在不重训的情况下在推理时锐化策略,是个便宜的调节旋钮。
- 统一异构数据:demo + autonomous + correction 三类数据用同一目标函数纳入,工程上简洁、可迭代。
- distributional + MC value function 简单可靠:作者诚实地选了"次优但稳"的 on-policy MC 估计,避免了 off-policy Q-learning 在真机稀疏 reward 下常见的发散。
- 真实可用性强:13 小时连续做咖啡、工厂真实纸箱组装,是少见的真机长时验证。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "learns from experience" 在多大程度上是真 RL 改进 vs. human-correction 驱动的监督? 这是最该追问的点。box assembly、cafe、diverse laundry 都重度依赖 correction(cafe 甚至只有单轮、429 纠正 + 414 自主),而 correction 动作被强制标为 positive 并整段加入训练——这本质上非常接近 HG-DAgger 的监督式 fine-tune。论文把 throughput 翻倍主要归因于 RECAP,但很难从结果分离出"纠正带来的监督提升"与"自主 RL 改进"各占多少。
- 唯一干净的"纯 RL"证据偏窄:真正没有 intervention 的只有 T-shirt/shorts(+50% throughput)和失败移除(97%)。这两个都是相对短时、初始已可靠的任务;而最依赖 RL 价值的长时难任务(box、cafe)恰恰混入了大量纠正,因此"RL 能让难任务自主变好"的主张证据是最弱的。
- value function 在真机稀疏 reward 下的可靠性:value 来自 Monte-Carlo 拟合行为策略的 return,是 on-policy 估计,作者自己承认次优。早期迭代策略很差时,MC value 偏差大,advantage 阈值(30/40/10% 分位)也是手调的 heuristic——advantage 标签质量直接决定 \(I_t\),但论文没给 value function 准确率 / advantage 标签可靠性的定量评估。
- advantage 标签来源的循环性:policy 条件在自己的 value function 推出的 \(I_t\) 上,而 value function 又拟合包含旧策略的混合行为;多轮里靠"每轮都从 pre-train checkpoint 重训"来防漂移——这暗示流程对漂移敏感,稳定性可能脆弱。
- 数据与模型闭源:π₀.₆/π*₀.₆、数万小时 pre-train 数据、value function 均不公开,外部无法复现或验证,"通用配方"的可迁移性只能信任作者。
- 评测任务窄且指标主观:success label 由人工标注、聚合多个质量指标得到,存在主观性;throughput 受"超时即失败"主导(作者称多数失败是 run out of time),可能放大了"速度"维度而非"能力"维度的提升。
- β>1 的副作用:作者自承 \(\beta\) 偏大会把动作推到支撑边界、产生过激动作,所以实际只敢用 1.5–2.5;CFG steering 的可用区间其实很窄,宣传意义大于实用空间。
- 与"更简单的 BC + 更多数据"的对照是否公平? RECAP 收的自主 + 纠正数据,若直接当作额外示范做 BC(尤其纠正本就是专家动作),能涨多少?论文比了 AWR/PPO,但没比"把同样这些数据全当 demo 做 SFT"这个最朴素的对照,难以排除"提升主要来自更多在线数据"而非 advantage conditioning 机制本身。
- 真实经验采样成本极高:每任务数百到上千条真机 episode、多机器人、人工 reset/标注/介入。"learns from experience" 在成本上离自动化很远——作者在 future work 里也承认系统不是 fully autonomous(依赖人工 reward、intervention、reset)。
- exploration 朴素:探索基本是 greedy,靠策略随机性 + 人工介入;对初始策略很差或需要全新行为的任务,本配方未必奏效。
5.3 值得继续探讨的方向¶
- 全自动化数据循环:用高层 VLA 策略自动 reset 场景、自动判定 reward,减少人工,向 fully autonomous RL 演进。
- 更聪明的 exploration:超越 greedy + intervention,引入有方向的探索机制处理真正需要新行为的任务。
- fully online / concurrent RL:当前是 iterated offline(收一批→重训→重复),把 policy 与 value function 改成实时在线更新可能更高效。
- off-policy value/Q estimator:用更优的 off-policy 估计替代 MC value,有望在更少数据下得到更准 advantage。
- 更严谨的消融:分离 correction 监督 vs. 自主 RL 的贡献;加入"同数据纯 SFT"对照;给出 value function / advantage 标签的定量可靠性评估。
- 可复现性:开放 benchmark 或部分组件,让社区验证"通用 RL 配方"的普适性。
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:source/
- 关键 baseline / 相关论文:
- π₀(black2024pi_0)、π₀.₅(black2025pi05)、π₀.₆(pi06model)——基础 VLA 谱系
- CFGRL(Frans 2025, Diffusion Guidance)——advantage conditioning 与 CFG 的直接来源
- Decision Transformer / RvS / RCSL / Upside-Down RL——reward/return-conditioned policy 家族
- AWR(peng2019advantage)、CRR、IQL——weighted regression policy extraction
- DAgger(ross2011dagger)、HG-DAgger(kelly2019)——human intervention/correction
- DPPO / FPO / SPO——diffusion policy 的 PPO 变体(本文 PPO baseline)
- KI / Knowledge Insulation(driess2025)、FAST(pertsch2025)、flow matching(lipman2022)——VLA 训练组件