π₀.₅: a Vision-Language-Action Model with Open-World Generalization¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:π₀.₅: a Vision-Language-Action Model with Open-World Generalization
- 作者 / 机构:Physical Intelligence(Kevin Black, Danny Driess, Chelsea Finn, Sergey Levine, Karl Pertsch, Lucy Xiaoyang Shi 等,团队署名为整体)
- arXiv:2504.16054(2025-04),项目页 https://pi.website/blog/pi05
- 关键词:VLA、open-world generalization、mobile manipulation、co-training、flow matching、hierarchical / chain-of-thought inference、cross-embodiment、FAST tokenization
 Figure 1:核心 takeaway —— π₀.₅ 通过对异构数据源(其他机器人、high-level subtask prediction、verbal instructions、web data)做 co-training,使一台 mobile manipulator 能在完全没在训练里见过的真实家庭中清洁厨房和卧室,执行时长 10–15 分钟的多阶段复杂行为。
Figure 1:核心 takeaway —— π₀.₅ 通过对异构数据源(其他机器人、high-level subtask prediction、verbal instructions、web data)做 co-training,使一台 mobile manipulator 能在完全没在训练里见过的真实家庭中清洁厨房和卧室,执行时长 10–15 分钟的多阶段复杂行为。
2. 文章介绍¶
2.1 解决的领域和问题 (open-world generalization for mobile manipulation)¶
研究对象是 vision-language-action (VLA) 模型 在真实物理世界中的开放世界泛化(open-world generalization)。具体问题是:让一台移动操作机器人(mobile manipulator)在训练时从未见过的真实家庭里完成长程家务任务,例如清理厨房(把碗碟放进水槽、把物品收进抽屉、擦拭洒落、关上柜门)和整理卧室(捡起地上的衣物放进洗衣篮、铺床)。这些任务时长 2–5 分钟(单任务),完整房间清洁可达 10–15 分钟,远超以往 VLA 评测中典型的 <1 分钟短任务。
2.2 Motivation (lab demo → 真实新家庭的 generalization gap)¶
以往大多数 VLA 都在与训练数据高度相似的环境里评测,"in the wild" 的泛化程度仍是开放问题。作者类比人的学习方式:人解决新任务靠的不只是反复练习同一件事,还包括从他人言语、书本、以及其它任务中迁移而来的知识。因此假设:可泛化的机器人系统必须能从多种异构知识源迁移经验——有的来自目标平台的第一手经验,有的来自其它 embodiment / 环境 / 领域,有的甚至是完全不同的数据类型(verbal instructions、web 感知任务、high-level 语义命令)。
关键观察:直接用暴力扩规模采集移动操作数据来覆盖所有可能场景是不现实的(尤其是长程复杂任务)。但 VLA 的序列建模框架天然能把不同模态都映射到同一个 token 序列里,因而可以把机器人动作、语言、视觉任务统一 co-train。π₀.₅ 正是利用这一点来弥合 "实验室 demo → 真实新家庭" 的 generalization gap。
2.3 之前工作的问题¶
| 方向 / 代表工作 | 缺陷(相对本文目标) |
|---|---|
| π₀(前序 VLA,flow matching 动作专家) | 强但主要在贴近训练分布的环境评测;缺乏面向异构数据源的 co-training 配方与显式 high-level 推理 |
| 单 embodiment VLA(OpenVLA 等) | 局限于单一机器人 / 数据分布;长程、跨场景泛化弱 |
| 大规模跨机器人数据集(RT-X / Open X-Embodiment、DROID) | 主要让简单技能(抓取、开抽屉)泛化到新环境,任务通常 <1 分钟、成功率偏低,难扩展到清厨房这类长程任务 |
| 纯 imitation / 扩规模采集 | 靠暴力扩数据覆盖所有场景对长程复杂任务不可行 |
| 分层规划方法(SayCan、Hi Robot、用 LLM/VLM 做规划 + 独立低层策略) | 多采用两个独立模型(VLM 规划 + 另一个低层策略),高层不在机器人数据上训练,存在接口不匹配与语义-动作脱节 |
| RT-2 等 web 数据 co-training | 仅与 VLM 训练数据 co-train,改善物体/背景泛化,但未引入其它机器人、high-level 子任务、verbal instruction 等更广的机器人相关监督源 |
2.4 论文解决方案(一句话)¶
在 π₀ 基础上,提出一套异构 co-training 配方 + 统一分层架构:用一个模型同时学习"先输出 high-level 语义子任务文本、再输出 low-level 连续动作 chunk",通过对 MM/ME/CE/HL/WD/VI 六类数据的混合训练,让 mobile manipulator 在全新真实家庭中实现长程开放世界泛化。
2.5 与前序工作的关系 (直接 build on π₀)¶
- 直接构建于 π₀:复用其 flow matching 动作表示与 "action expert"(类 MoE 的专用权重)思想。架构维度与 π₀ 完全一致。
- VLM backbone 用 PaliGemma(2B),动作专家约 300M。
- 复用 FAST tokenizer(Pertsch et al. 2025):在预训练阶段用 FAST 离散 token 表示动作,训练更快、语言跟随更好。
- co-training 数据来源:MM(移动操作)、ME(多环境非移动机器人)、CE(实验室跨 embodiment,含开源 OXE)、HL(high-level 子任务标注)、WD(web 多模态:CapsFusion / COCO / Cambrian-7M / PixMo / VQAv2 + 物体定位)、VI(verbal instructions)。
- 与 SayCan / Hi Robot 等分层方法的区别:用同一个模型做高层与低层,更接近 chain-of-thought / test-time compute,而非两个独立模型。
3. 方法介绍¶
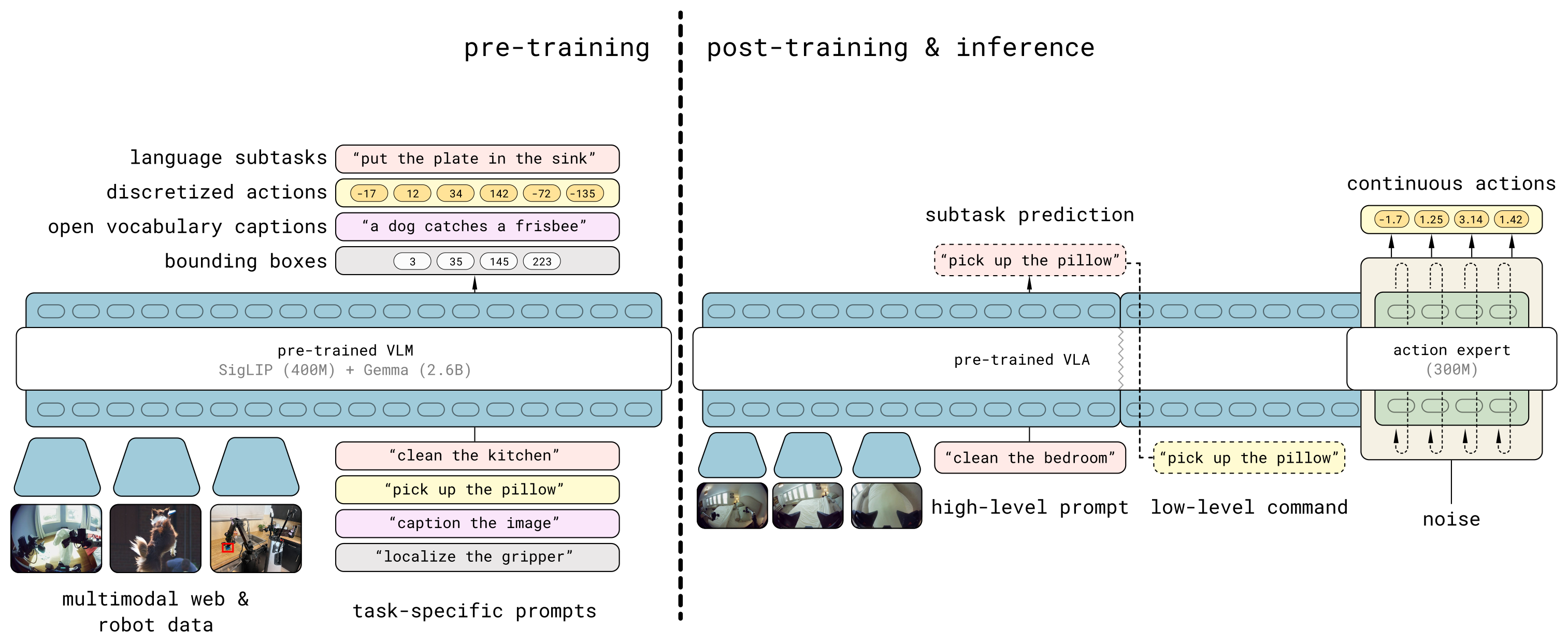 Figure 2:模型总览。两阶段训练 —— Pre-training 用离散 token(含 FAST 动作 token)融合所有数据源得到一个 VLA;Post-training 加入 flow matching action expert 专门化到 mobile manipulation。推理时先推 high-level subtask,再据此推 low-level actions。
Figure 2:模型总览。两阶段训练 —— Pre-training 用离散 token(含 FAST 动作 token)融合所有数据源得到一个 VLA;Post-training 加入 flow matching action expert 专门化到 mobile manipulation。推理时先推 high-level subtask,再据此推 low-level actions。
3.1 形式化 (hierarchical policy)¶
模型刻画联合分布并做分解:
其中: - \(\mathbf{o}_t = [\mathbf{I}^1_t, \dots, \mathbf{I}^n_t, \mathbf{q}_t]\) 为多相机图像 + 本体状态(关节角、夹爪位姿、躯干升降、底盘速度); - \(\ell\) 是高层总命令(如 "put away the dishes"); - \(\hat{\ell}\) 是模型输出的文本,可以是 high-level 子任务(如 "pick up the plate")或 web VLM 任务的答案; - \(\mathbf{a}_{t:t+H}\) 是动作 chunk(horizon=50,即 \(H=49\))。 - 关键点:动作分布只依赖子任务文本 \(\hat{\ell}\),不直接依赖原始命令 \(\ell\)。高层推理捕捉 \(\pi_\theta(\hat{\ell}\mid\mathbf{o}_t,\ell)\),低层推理捕捉 \(\pi_\theta(\mathbf{a}\mid\mathbf{o}_t,\hat{\ell})\),两者由同一个模型表示。
3.2 异构 co-training 数据配方 (MM / ME / CE / HL / WD / VI)¶
- MM(Mobile Manipulator):约 400 小时移动操作数据,覆盖约 100 个不同家庭环境,是与评测任务最直接相关的切片。
- ME(Multi-Environment 非移动机器人):固定在台面/平台上的单臂/双臂机器人,因更轻便易运输,可在更多样的家庭里采集;但 embodiment 与移动机器人不同。
- CE(Cross-Embodiment 实验室数据):实验室桌面环境的多种任务(收拾餐桌、叠衬衫等),含单/双臂、静态/移动底座,并纳入开源 OXE 数据集;是 π₀ 数据集的扩展版。
- HL(High-Level 子任务预测):把 "clean the bedroom" 这类高层命令拆成 "adjust the blanket"、"pick up pillow" 等短子任务,类似语言模型的 chain-of-thought。对 MM/ME/CE 中的多阶段任务人工标注子任务语义,让模型联合预测子任务文本与(基于该子任务的)动作。
- WD(Web Data):图像描述(CapsFusion、COCO)、问答(Cambrian-7M、PixMo、VQAv2)、物体定位(并额外扩充室内场景/家居物体的 bounding box 标注)。
- VI(Verbal Instructions):仅在 post-training 引入。专家用户实时用语言"遥操作"机器人(让已训练的低层策略执行),逐步选择合适的子任务命令——本质是为高层策略提供"好的子任务输出"的示范。约占 high-level 移动操作样本的 11%。
值得强调:第一训练阶段中,97.6% 的训练样本并非来自移动操作机器人做家务,绝大多数来自其它机器人或 web 数据。
3.3 High-level 语义子任务预测 + bounding box (CoT 式)¶
高层推理接收高层命令("clean the bedroom"),输出下一步该做的子任务("pick up pillow"),再把该子任务作为低层动作推理的上下文,类似 chain-of-thought。HL 数据中模型还被训练先预测当前观测里相关物体的 bounding box,再预测子任务——把感知定位作为语义推理的中间步骤。高层推理用全部四个相机;低层推理用腕部相机与前向相机。高层以较低频率运行(低于低层动作推理频率)。
3.4 Low-level action 生成 (flow matching action expert) 与统一架构 / attention mask¶
- 离散 + 连续混合(hybrid):训练时同时用两种方式预测动作 —— (a) 用 FAST tokenizer 把动作离散化后自回归预测;(b) flow matching 迭代积分出连续动作场。损失为交叉熵(文本 + FAST 动作 token)加权重 \(\alpha\) 的 flow matching L2 项(见 Eq. 中 \(\|\omega - \mathbf{a} - f^a_\theta(\cdot)\|^2\))。
- 两阶段切换:pre-training 设 \(\alpha=0\)(纯当作离散 token 的 VLM,280k 步),post-training 设 \(\alpha=10.0\) 并加入随机初始化的 action expert(80k 步)。这样既享受离散 token 训练快、语言跟随好的优势,又能在推理时用 flow matching 做高效实时连续控制。
- 统一架构:transformer 输入多模态 token \(x_{1:N}\)(文本 token、图像 patch、flow matching 中的中间去噪动作值),不同 token 类型走不同 encoder / expert 权重。图像 patch、文本 prompt、连续动作 token 用双向注意力(不同于 LLM 的因果注意力)。
- attention mask 设计(关键,避免两种动作表示互相泄漏):images / prompt / 本体状态用 full prefix mask;FAST 动作 token 注意 prefix 并对先前动作 token 做自回归;action expert 的 embedding 注意 prefix 与彼此,但不注意 FAST 动作 token,以免两种动作表示之间信息泄漏。信息单向从 VLM 流向 action expert,没有任何 VLM embedding 注意 action expert。
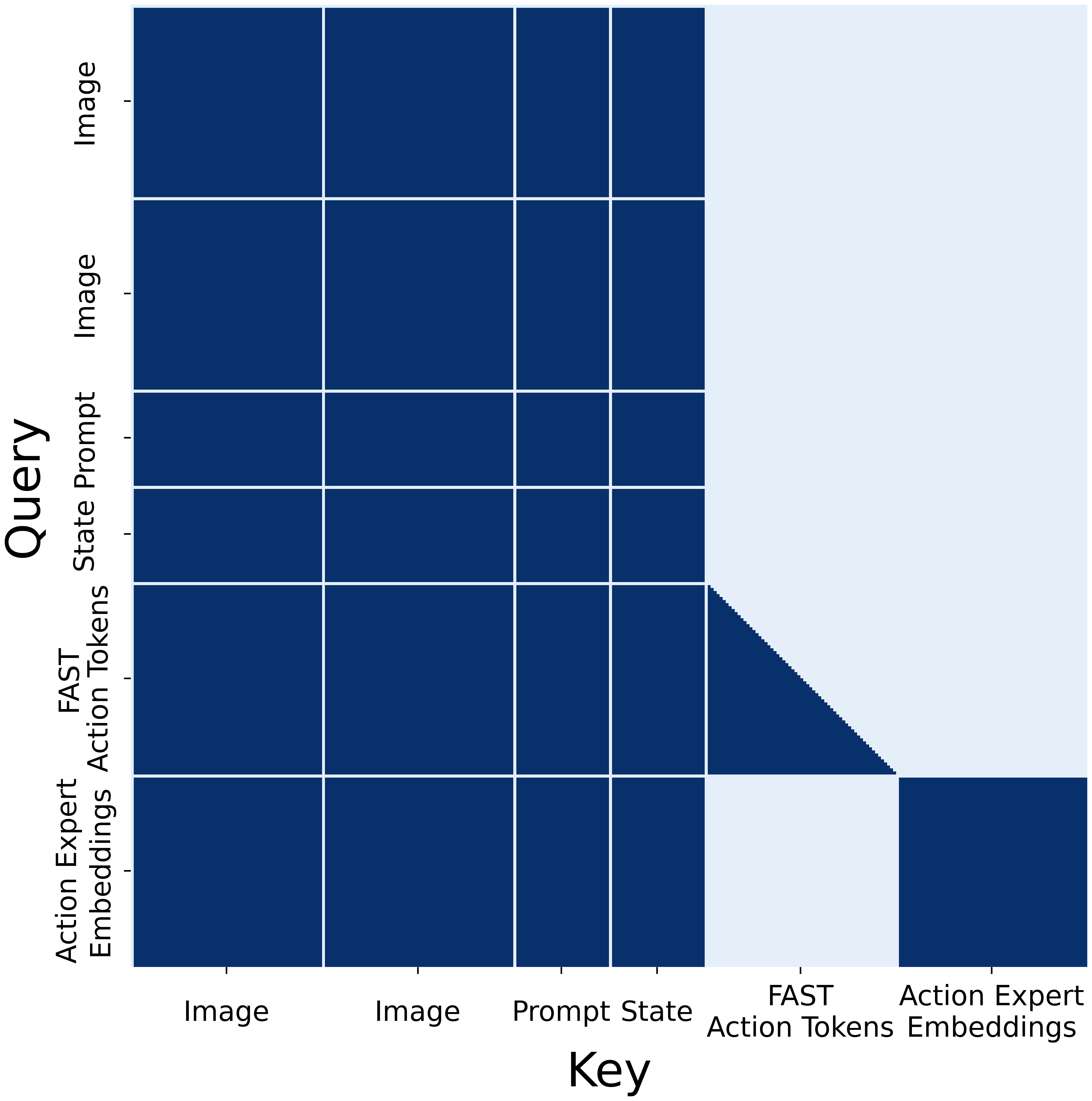 Figure 3:π₀.₅ 的 attention mask 模式示例 —— prefix(图像/文本/状态)双向;FAST 动作 token 自回归;action expert 看 prefix 但不看 FAST 动作 token,信息单向流动。
Figure 3:π₀.₅ 的 attention mask 模式示例 —— prefix(图像/文本/状态)双向;FAST 动作 token 自回归;action expert 看 prefix 但不看 FAST 动作 token,信息单向流动。
3.x Implementation Details¶
- 数据规模:~400h 移动操作数据(~100 个家庭)+ 大量 ME/CE/web 数据;pre-train 280k 步,post-train 80k 步。
- 机器人系统(Figure: robot system overview):两类 mobile manipulator,各 4 个相机(前、后、双腕),两条 6-DoF 机械臂 + 平行夹爪,全向轮式底盘,躯干升降机构。状态/动作空间共 18 或 19 维(含底盘 2D 线速度 + 1D 角速度、躯干升降 1D 或 2D)。
- 控制:模型直接以 50 Hz(带 action chunking)输出机械臂/夹爪/躯干目标位姿与底盘目标速度,由简单 PD 控制器跟踪,无额外轨迹规划或碰撞检测,导航与操作全端到端。
- 架构参数:backbone 用 PaliGemma 2B(width=2048, depth=18, mlp_dim=16384, heads=18, kv_heads=1, head_dim=256);action expert ~300M(width=1024, mlp_dim=4096,深度同前)。action horizon=50。
- flow matching 细节:动作专用 MLP 仅投影时间步 \(\tau\)(sinusoidal 编码 + swish),再用 adaptive RMSNorm 注入每层(与 π₀ 略有不同);时间步采样用偏向低时间步的 Beta 分布,阈值 \(s=0.999\)。
- 动作处理:预测关节与末端执行器目标位姿,用
<control_mode>标记区分;按各数据集 1%/99% 分位归一化到 \([-1,1]\),并 zero-pad 到统一最大动作维度。 - 推理流程:先标准自回归解码出文本 \(\hat{\ell}\)(子任务),再以其为条件做 10 步 flow matching 去噪生成动作 chunk。
- 图像增强:random crop(0.95) → resize → rotate(±5°) → color jitter。
4. 结果对比¶
评测全部在训练中未见过的环境进行:用 mock 厨房/卧室做可复现的受控对比,用 3 个真实家庭做最终现实评测。指标多为完成步骤百分比(rubric 打分,如把一半碗碟放进水槽 ≈ 50%),每策略每任务通常 10 次试验。
核心结论(粗体强调 π₀.₅ 的优势):
- 真实新家庭 eval(Figure: real home filmstrip / quantitative):π₀.₅ 在 3 个未见真实家庭里能稳定完成 'items in drawer' / 'dishes in sink' / 'laundry basket' 等任务,mock 环境表现可代表真实家庭表现。任务多为 2–5 分钟多阶段。
 Figure 4:真实家庭 rollout 示例。从上到下:Home 1 把物品放进抽屉、Home 2 把碗碟放进水槽、Home 3 把衣物放进洗衣篮。每帧下方蓝字是 π₀.₅ 自主预测的 high-level subtask。
Figure 4:真实家庭 rollout 示例。从上到下:Home 1 把物品放进抽屉、Home 2 把碗碟放进水槽、Home 3 把衣物放进洗衣篮。每帧下方蓝字是 π₀.₅ 自主预测的 high-level subtask。
- 环境数量 scaling(Figure: env_scaling):用 3/12/22/53/82/104 个地点的数据后训练,任务表现随训练环境数单调上升。最终 104-location 模型逼近"把测试家庭直接放进训练集"的对照(绿色)——说明 co-training 配方有效弥合了泛化 gap。而不用完整 co-training 配方(只在测试家庭数据或仅 104-location 移动数据上直训)的两个 baseline(浅绿/浅黄)显著更差,证明其它数据源对泛化是必要的。
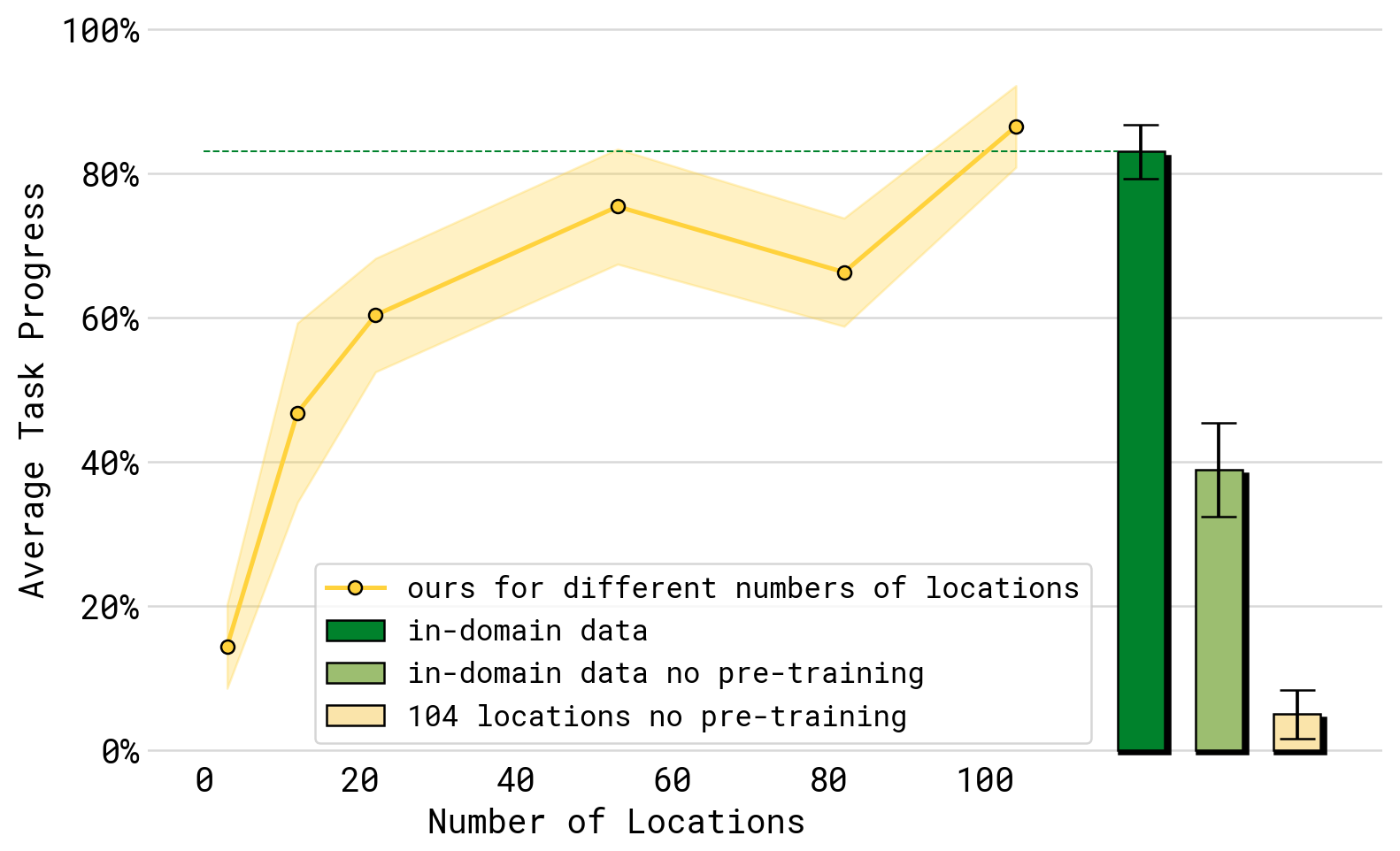 Figure 5:随训练地点数(3→104)增加,四个测试任务平均表现稳步提升。虚线绿条为"训练集含测试家庭"的对照,π₀.₅(未见过测试家庭)能逼近它;不含 co-training 的 baseline(浅黄)差距巨大。
Figure 5:随训练地点数(3→104)增加,四个测试任务平均表现稳步提升。虚线绿条为"训练集含测试家庭"的对照,π₀.₅(未见过测试家庭)能逼近它;不含 co-training 的 baseline(浅黄)差距巨大。
-
language following scaling(Figure: env_scaling_results0):随地点数增加,language following rate 与 success rate 都提升;in-distribution 物体提升快于 out-of-distribution(OOD)物体。
-
co-training 配方消融,mock homes(Figure: performance_vs_ll_data):去掉 ME 或 CE 任一跨 embodiment 数据源都显著掉点,两者都去掉更差。去掉 WD 在这组实验里不显著(但在 language following 与 high-level 上很重要)。
-
co-training 消融,language following(Figure: data_vs_generalization):去掉 WD 显著伤害 OOD 物体表现——web 的广博物体知识帮助理解/跟随涉及未见类别的语言命令;ME/CE 对 in-distribution 与 OOD 都影响大。
-
与其它 VLA 对比(Figure: performance_vs_ll_model):π₀.₅ 显著优于原始 π₀ 以及增强版 π₀-FAST+Flow(后者用了同样 hybrid 训练但只用动作数据、无 HL/WD,故不能做 high-level 推理)。即便把 π₀ 训到 300k 步结论依旧成立——印证 FAST token 训练比纯 diffusion 更省算力。language following 上 π₀.₅ 也略高于 π₀-FAST+Flow、远高于 π₀。
-
high-level inference 方法对比(Figure: performance_vs_hl_data):完整 π₀.₅(高层+低层)表现最佳,甚至超过 human HL "oracle" 基线。第二好的是 implicit HL(训练含 HL 数据但运行时不做显式高层推理)——说明很大一部分收益来自把子任务预测数据纳入训练混合。no HL(连训练都不含 HL)显著更差。仅占高层移动操作样本约 11% 的 VI 数据去掉后显著变弱;no WD 也显著更差(web 数据的收益很大在于改善高层策略);零样本 GPT-4 做高层最差,凸显用机器人数据适配 VLM 的重要性。
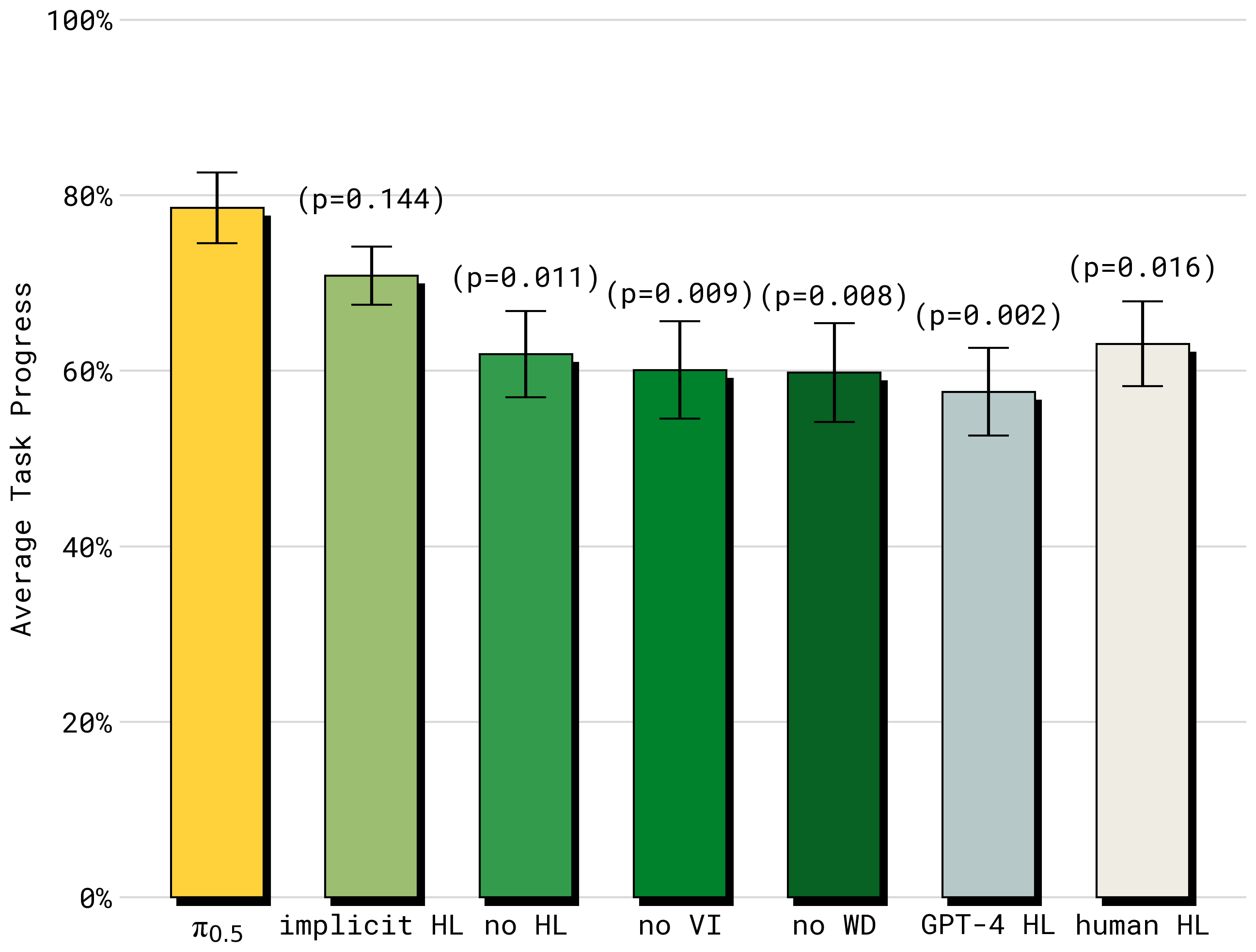 Figure 6:high-level 推理方法对比。完整 π₀.₅ 最佳并超过 human HL oracle;implicit HL 次之;去掉 VI / WD 显著下降;GPT-4 zero-shot 最差。
Figure 6:high-level 推理方法对比。完整 π₀.₅ 最佳并超过 human HL oracle;implicit HL 次之;去掉 VI / WD 显著下降;GPT-4 zero-shot 最差。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- co-training transfer 的有效性被清晰量化:97.6% 训练样本来自非目标任务的数据源,却能让仅 ~400h 移动数据的模型在全新真实家庭泛化;ME/CE 消融的大幅掉点提供了强有力的因果证据。
- 用 web data 注入语义/物体知识:WD 对 OOD 物体的 language following 与高层策略影响显著,说明把感知/语义任务 co-train 进 VLA 确实把"常识"带进了机器人控制。
- hierarchical 设计解决 long-horizon:同一个模型做高层子任务 + 低层动作(CoT 式),既能做长程多阶段规划,又让高/低两层各自从最合适的数据源受益;且全模型超过 human oracle 高层这一结果很有说服力。
- 离散 + 连续 hybrid 训练:pre-train 用 FAST 离散 token(快、语言好),post-train 用 flow matching(实时连续控制),attention mask 防止两表示泄漏,工程上优雅且经验上稳定。
- 极简控制栈:50 Hz + PD,无轨迹规划/碰撞检测,全端到端,却能完成 10–15 分钟的整房清洁。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "new homes" 是否真的是 unseen 分布? 训练已覆盖 ~100 个家庭,且 MM/ME 数据本身就是各种家庭厨房卧室;所谓"新家庭"在物体类别、布局风格、任务类型上可能与训练分布高度同质。真正的开放世界(如车库、办公室、非典型布局)并未测试,泛化主张的边界被乐观表述。
- 评测高度 in-house 且主观:rubric 打分("擦得很整齐 +1"、"毯子铺得很整齐 +1")由自家 operator 执行,存在主观性与潜在偏向;没有第三方或盲评。
- 数据闭源、不可复现:MM/ME/CE/VI 全部私有,模型权重与数据均不公开,外部无法复现核心 co-training 结论,社区只能 take it on faith。
- co-training 各组件消融未必充分:消融多为"去掉某一类"的单因素,缺少 MM 数据量本身的 scaling、HL 标注质量/数量的敏感性、各数据源混合比例的系统扫描;WD 在不同实验里有时显著有时不显著,机制解释偏事后归因("我们推测")。
- 高层 VLM 错误传播:分层推理一旦高层子任务选错(论文也承认会反复开关抽屉、被干扰),低层只能忠实执行错误子任务;没有纠错/回退机制,缺乏对高层错误率的定量分析。
- 两段式推理延迟:每步先自回归解码文本子任务、再 10 步 flow matching 去噪,相比直接低层推理增加延迟;论文称高层以低频运行,但未给出实际控制循环时延/吞吐数字,实时性主张缺乏量化。
- 无公共 benchmark:全部自定义任务与环境,无法与其它 VLA 在统一标准上横向比较;与 π₀ / OpenVLA 等的对比都在自家 setup 内进行,外部可比性弱。
- 泛化主张的统计显著性:每策略每任务仅 ~10 次试验、连续多分钟任务方差大;虽声称用两侧 t 检验,但样本量小、报告以柱状图为主,部分"显著优于"的结论统计功效存疑(且承认有些 cancelled episode 被剔除,剔除规则可能引入偏差)。
- "超过 human HL oracle" 需谨慎解读:人类高层 oracle 的质量取决于该人对低层策略习性的了解程度;这更可能说明模型的高层与自身低层"自洽",而非真的超越人类规划能力。
- 本体/平台局限:只在两类自家移动平台上验证,18–19 维动作空间、平行夹爪;对灵巧手、不同形态机器人或更复杂操作的可迁移性未知。
5.3 值得继续探讨的方向¶
- 更丰富的上下文与记忆:当前 context 较短,难处理跨房间导航、记住物体存放位置等强 partial observability 场景;引入显式记忆/历史是自然延伸。
- 更复杂的 prompt 与偏好:目前只能处理较简单命令,可通过更丰富(人工或合成)标注支持细粒度偏好与多步指令。
- verbal instruction 作为新监督模态:VI 仅占 11% 却影响巨大,值得深挖人如何用语言为机器人注入上下文知识(在线纠正、交互式教学)。
- 更广的数据源探索:仿真、视频、人类示范等可进一步纳入 co-training。
- 高层错误的检测与自纠:引入不确定性估计、回退或与人类的 mixed-initiative 纠错闭环。
- 可复现的公共评测:建立标准化开放世界家务 benchmark,量化推理时延、统计显著性与跨平台泛化。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 关键 baseline / 相关论文:
- π₀(Black et al. 2024)—— 直接前序工作,flow matching action expert
- FAST(Pertsch et al. 2025)—— 动作离散 tokenization
- OpenVLA(Kim et al. 2024)—— 单 embodiment VLA
- RT-X / Open X-Embodiment、RT-2(Brohan et al. 2023)—— 跨机器人数据与 web co-training
- Mobile ALOHA / Bringing Robots Home —— 移动操作数据采集
- PaliGemma(Beyer et al. 2024)—— VLM backbone
- Hi Robot / SayCan —— 分层语言规划基线