EgoExo-WM: Unlocking Exo Video for Ego World Models¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: EgoExo-WM: Unlocking Exo Video for Ego World Models
- 作者: Danny Tran, Roberto Martín-Martín†, Kristen Grauman† (UT Austin,†表示 equal advising)
- arXiv 编号: 2605.15477(2026-05 提交,目标会场 NeurIPS 2026 preprint track)
- 项目主页: https://vision.cs.utexas.edu/projects/EgoExo-WM/
- 关键词: egocentric world model, exocentric-to-egocentric, 3D human motion, SMPL action space, video diffusion, MPC planning, DINOv3 latent prediction
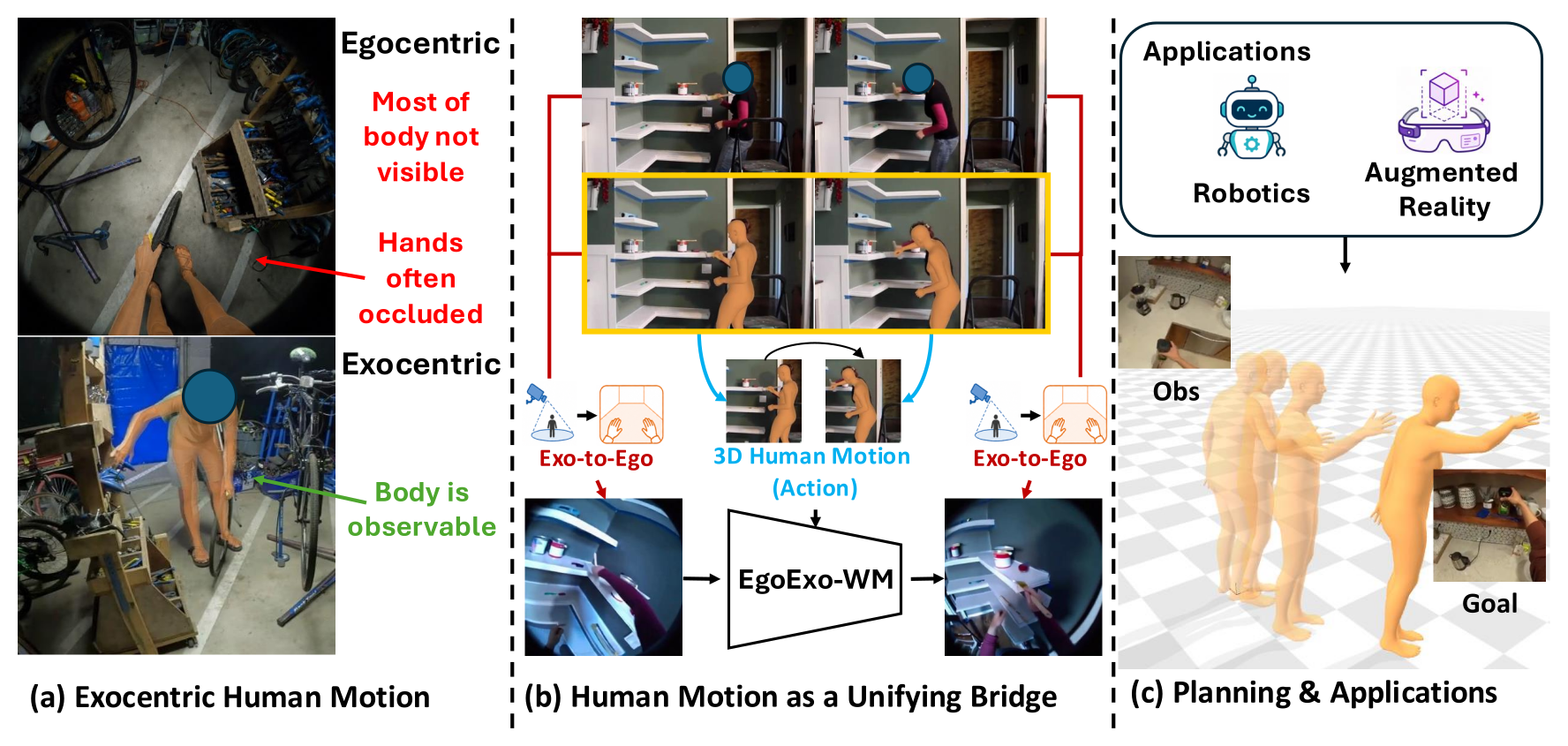 Figure 1:框架总览 — exo 视频(a)→ 经 3D human motion 桥接的 ego 视频(b)→ 用于规划(c)
Figure 1:框架总览 — exo 视频(a)→ 经 3D human motion 桥接的 ego 视频(b)→ 用于规划(c)
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 egocentric world model 子领域。具体问题是:第一人称视频的世界模型受限于 egocentric 训练数据稀缺,并且 ego 视角下身体(尤其手部)经常自遮挡,导致难以同时获得高质量观察与精确动作标注。论文要回答的是:如何把海量的 exocentric (第三人称) 视频转化为 egocentric 世界模型的训练资源?
2.2 Motivation¶
人类的观察学习能力是核心 motivation:看别人揉面、画画、缝纫,就能在脑中预想自己第一人称下的同样动作。论文借此类比 — 互联网上的 exocentric 视频(HowTo100M、CrossTask、100 Days of Hands 等)规模远大于 egocentric 数据集(Ego4D、Nymeria 等),且 exo 视角能完整观察 body pose,恰好补足了 ego 视角下身体不可见、动作难标注的两个 bottleneck。如果能把 exo 转译成 "ego 观察 + 全身动作" 配对样本,就能解锁规模化训练。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Ego WM (pose-conditioned) | PEVA, EgoControl, PlayerOne | 完全依赖稀缺的 ego 数据 + motion capture pairing;评估仅在训练分布内进行 |
| Ego WM (no explicit action) | DreamDojo (latent action), UniSim (text-conditioned) | 动作表征不可解释或粒度太粗,无法支持精细 embodied control |
| Exo-to-ego 视角转换 | Exo2Ego (xu2025), 4Diff, EgoX | 主要做场景对齐,人体信息只依赖 ego 手部先验,缺少 full-body 运动学约束 → 会出现手左右互换、手部幻觉、动作不符等问题 |
| Pose-aware video gen 但不用于 WM | 各类 SMPL/MANO 引导生成方法 | 没有把 pose 作为统一接口同时用于「视角转换 + 世界模型动作空间」 |
2.4 论文解决方案(一句话)¶
以 3D human pose 作为统一接口,先用增强版 EgoX-Body 把 in-the-wild exo 视频"翻译"成 ego 视频 + 全身动作序列,再用这种合成数据连同真实 ego 数据一起训练一个 DINOv3-latent 空间内、SMPL 22-关节动作条件的 ego 世界模型,并以 MPC 风格做 goal-conditioned 规划。
2.5 与前序工作的关系¶
- EgoX (kang2025egox):本文的视角转换 backbone 即 EgoX。EgoX-Body 是它的增强版本 — 在 exo 端 overlay SMPL 骨架、在 ego 端 overlay 手部骨架,并去掉了 GGA 模块以提速。
- PEVA (bai2025whole):直接 SOTA baseline,pixel-space diffusion + Xsens 23 关节;EgoExo-WM 改为 DINOv3 latent + 22 关节 SMPL,并继承了 PEVA 的 Nymeria 预处理流程。
- EgoControl (pallotta2025egocontrol):另一个 SOTA baseline,作者自己重新实现因为代码未公开。
- UniEgoMotion (patel2025uniegomotion):既是 planning 的 baseline,也是 EgoExo-WM 在 MPC 阶段使用的 action proposal model(采样候选动作序列)。
- SAM-Body4D / ViPE / HaMeR:现成的人体 pose 估计与 4D 场景重建模块,直接复用。
- 数据:Nymeria (ego, ~200h) + HowTo100M / CrossTask / 100 Days of Hands (exo, 共 10h 子集) → 评估在 HOMAGE、LEMMA、Ego-Exo4D 三个 held-out 数据集。
3. 方法介绍¶
3.1 形式化¶
记 \(\mathbf{x}_t\) 为时刻 \(t\) 的 ego 观察,\(\mathbf{a}_t \in \mathbb{R}^{69}\) 为从 \(t\) 到 \(t+1\) 的 3D 人体动作。动作空间由两部分组成:
- root translation 的变化(3 维)
- 22 个 body joint 的相对旋转,用 Euler 角参数化(22 × 3 = 66 维)
视觉端用冻结的 DINOv3-L 把 \(\mathbf{x}_t\) 编码成 patch token 序列 \(\mathbf{z}_t = E(\mathbf{x}_t)\)(14×14 grid,1024-dim 每个 token)。
世界模型 \(f_\theta\) 接收 \(H=3\) 帧历史 latent + 下一时刻的动作,预测下一 latent:
3.2 World Model 训练目标¶
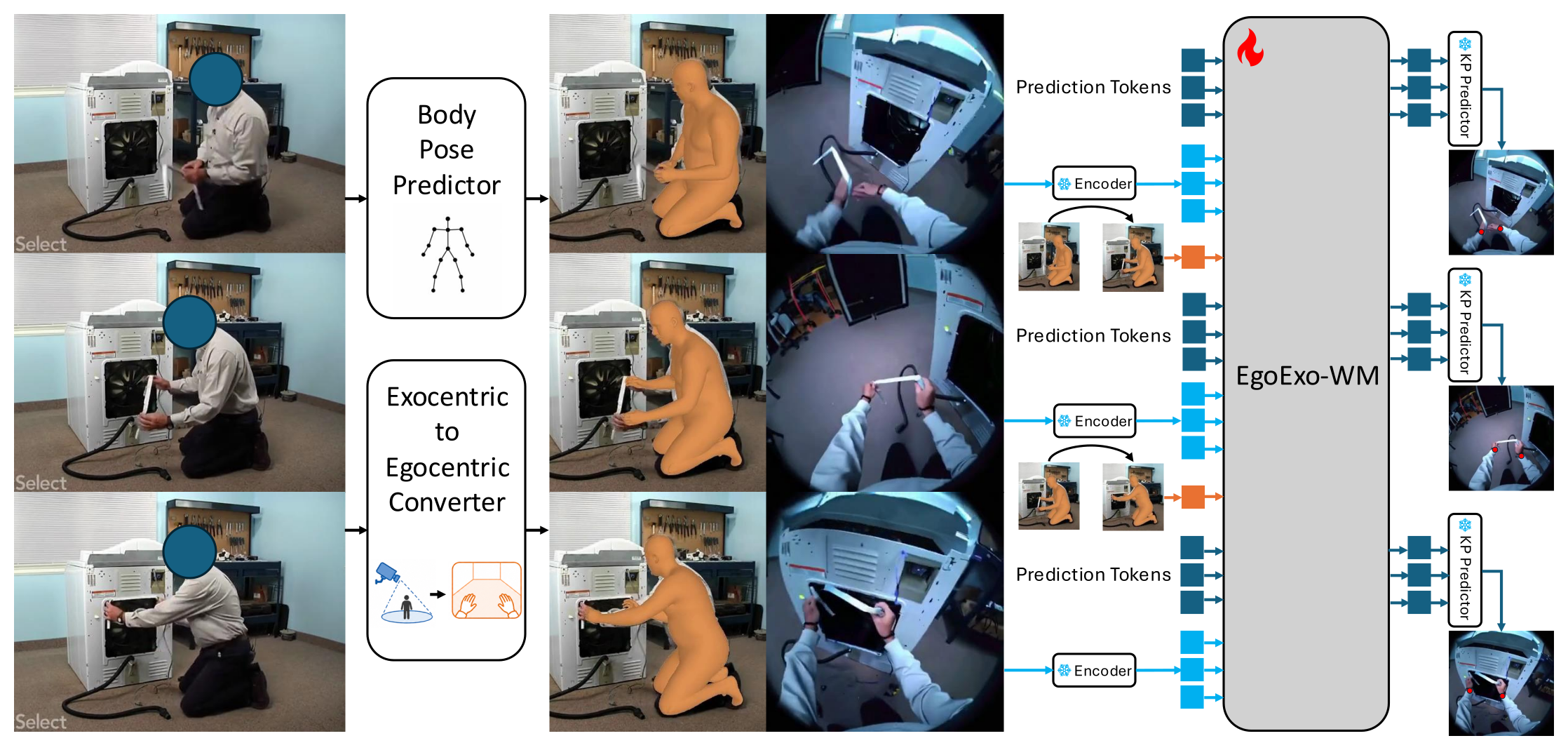 Figure 2:World Model 训练 — exo 视频抽取 3D human motion 作为动作,转换后的 ego 视频作为观察,autoregressive 训练带 teacher forcing;wrist keypoint predictor 给出辅助监督
Figure 2:World Model 训练 — exo 视频抽取 3D human motion 作为动作,转换后的 ego 视频作为观察,autoregressive 训练带 teacher forcing;wrist keypoint predictor 给出辅助监督
主 loss 是 latent 空间 L2: $\(\mathcal{L}_{\text{latent}} = \|\hat{\mathbf{z}}_{t+1} - \mathbf{z}_{t+1}\|_2^2\)$
辅助 loss 是 wrist position consistency:用一个冻结的 6-layer Transformer head(256-dim, 16 heads)从预测 latent 解码出一张 224×224 的手腕热力图,对比 ViTPose 提取的伪标签(双手 isotropic Gaussian, σ=3px,max-fuse): $\(\mathcal{L}_{\text{wrist}} = \|\hat{\mathbf{V}}_{t+1} - \mathbf{V}_{t+1}\|_2^2\)$
总 loss \(\mathcal{L} = \mathcal{L}_{\text{latent}} + \lambda \mathcal{L}_{\text{wrist}}\),\(\lambda = 1\)。
这套表示让真实 ego 数据(Nymeria,motion capture 提供动作)和转换后的 exo 数据(pose 估计提供动作)共享同一格式,可以混训。
3.3 EgoX-Body:Exo→Ego 视角转换¶
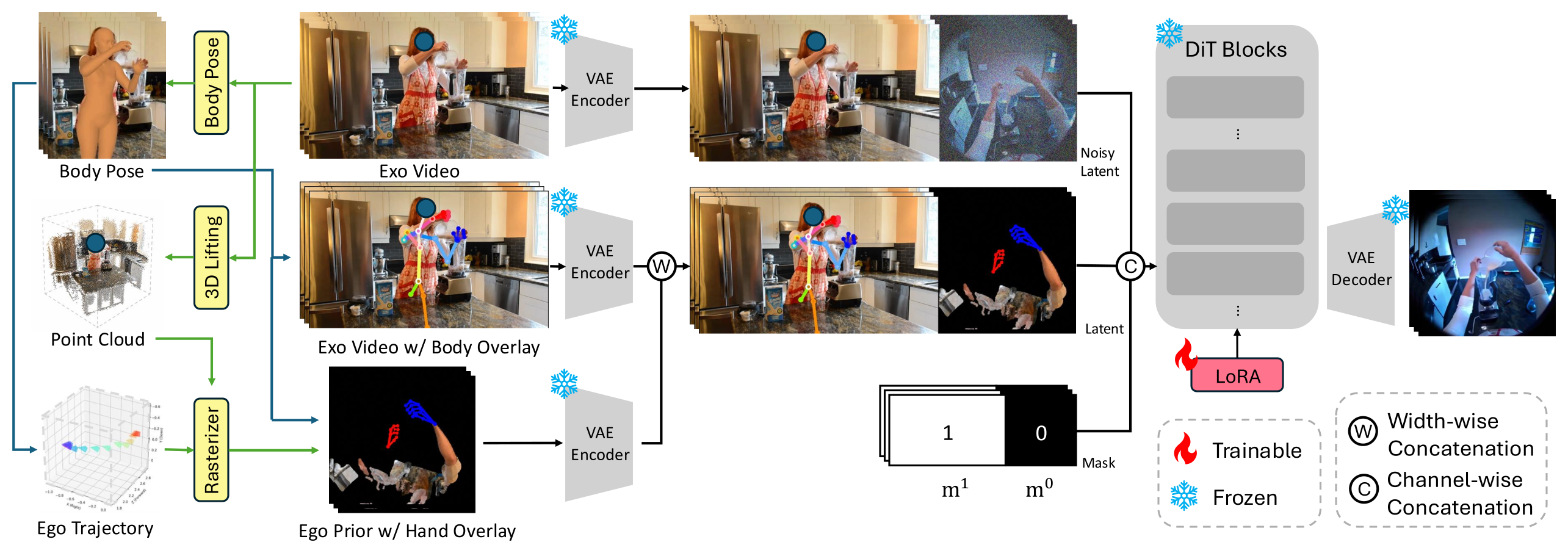 Figure 3:EgoX-Body 推理流程 — 从 exo 视频抽取 body pose + 3D scene 点云;同时构造两路 latent(干净 exo + noise / body-overlay exo + ego hand prior)送进 video diffusion 生成 ego 视频
Figure 3:EgoX-Body 推理流程 — 从 exo 视频抽取 body pose + 3D scene 点云;同时构造两路 latent(干净 exo + noise / body-overlay exo + ego hand prior)送进 video diffusion 生成 ego 视频
输入 in-the-wild exo 视频,输出对齐的 ego 视频 + 3D 人体动作序列。两个 kinematic prior 同时作用:
- Exo 端 body skeleton overlay:用 SAM-Body4D 估计全身 pose,把 SMPL-X 骨架画在 exo 条件帧上(提供 canonical 行为表示,与背景视角解耦)。
- Ego 端 hand kinematics overlay:把 3D 手位置投影到一个 head-anchored pinhole 虚拟相机视图上 — 相机中心是双眼关节中点向前推 0.1m,basis 由 eye-to-eye、center-to-NECK 方向构造。左手画红色,右手画蓝色,16 关节 + 15 骨连接。
训练时手部 kinematics 用 HaMeR 提取的 GT pose 来 instantiate;推理时直接从 exo body pose 投影获得(无需 ego ground truth)。
视频生成 backbone 是 video diffusion model(继承自 EgoX,含 ViPE 4D 重建 + Wan video prior + GPT-4o VLM 条件)。输入两路 latent,channel-wise concat + mask 后送入 diffusion: - 干净 exo latent + noise - body-overlay exo latent + ego hand prior latent
实用修改:去掉 EgoX 的 Geometry Guided Attention (GGA);分辨率 448→384;加 250 个 H2o 数据集样本(人正对镜头);NVIDIA GH200 上单条 49 帧推理 17.5 分钟 → 3.25 分钟。
3.4 MPC-style Planning¶
给定当前 ego 观察 + 视觉 goal 图像 \(z_g = E(\mathbf{x}_g)\):
- UniEgoMotion 采样 \(N=4\) 条候选动作序列 \(\{a^{(i)}_{t:t+H}\}\),horizon \(H=8\) 帧。
- 每条候选用 \(f_\theta\) autoregressive rollout 出 latent 轨迹。
- 用最终 latent 与目标 latent 的 L2 距离打分:\(\mathcal{C}^{(i)} = \|z^{(i)}_{t+H} - z_g\|_2^2\)。
- 选最小 cost 的候选作为执行动作。
3.5 Implementation Details¶
World Model 训练: - 架构:CDiT-L/2 (24 层,hidden 1024,16 head,MLP ratio 4) - 输入:DINOv3 ViT-L/16 patch tokens,14×14 grid (196 tokens) - 历史窗口:\(H=3\) 帧 - 优化器:AdamW,lr=8e-5,\(\beta=(0.9, 0.95)\),grad clip 10 - Batch:每卡 64 × 8 张 A40 GPU = global batch 512 - 训练 100K iterations,bfloat16 mixed precision,torch.compile
EgoX-Body 训练:4× GH200 × 20K iterations。单样本生成 49 帧 / 3.25 分钟。
数据: - Ego:Nymeria 200h(PEVA 预处理)→ 完整方法中只用 190h - Exo(共 ~10h,转换后):HowTo100M (5h, Food & Entertainment) + CrossTask (1h) + 100 Days of Hands (4h) - Exo 视频过滤:自动场景切分 + ViTPose 检测单人 + ORB 运动剔除大幅 camera motion + GPT-4o-mini VLM 二筛(overlay <20%,必须有 visible human action) - 生成视频后处理:384×384 → center-crop 85% → 224×224,16Hz → 下采到 8Hz,留 25 帧 - 生成质量过滤(保留约 80%):black_fraction < 0.30, white_fraction < 0.20, blur_median > 50, motion_median < 32.5
评估:2-second 开环 rollout,8 帧 @ 4Hz。所有 baseline 强制相同 200h 训练预算 + 224×224 分辨率。
4. 结果对比¶
4.1 Open-loop World Model 评估 — 4 个 held-out 数据集¶
DINOv3-L latent L2 距离(越低越好)+ Wrist PCK@20(越高越好)。
| Model | HOMAGE L2(2s) | HOMAGE PCK(2s) | LEMMA L2(2s) | LEMMA PCK(2s) | Bike L2(2s) | Bike PCK(2s) | Cooking L2(2s) | Cooking PCK(2s) |
|---|---|---|---|---|---|---|---|---|
| PEVA-L | 0.115 | 0.326 | 0.115 | 0.439 | 0.108 | 0.340 | 0.105 | 0.210 |
| PEVA-XL | 0.112 | 0.308 | 0.110 | 0.324 | 0.106 | 0.319 | 0.105 | 0.210 |
| PEVA-XXL | 0.109 | 0.321 | 0.109 | 0.363 | 0.103 | 0.255 | 0.102 | 0.197 |
| EgoControl* | 0.099 | 0.352 | 0.091 | 0.343 | 0.085 | 0.414 | 0.090 | 0.223 |
| Ego-WM (own, ego only) | 0.069 | 0.313 | 0.068 | 0.433 | 0.050 | 0.468 | 0.063 | 0.460 |
| Naive EgoExo-WM (raw exo) | 0.065 | 0.347 | 0.064 | 0.439 | 0.048 | 0.382 | 0.062 | 0.368 |
| EgoExo-WM (full) | 0.057 | 0.404 | 0.058 | 0.515 | 0.049 | 0.489 | 0.062 | 0.460 |
观察: - 相对 PEVA 的提升幅度巨大,HOMAGE/LEMMA 上 L2 几乎减半 — 但很大一部分来自 CDiT 架构 + DINOv3 latent 表征 本身(看 Ego-WM 已经远超 PEVA)。 - 真正的 exo 贡献只在 Ego-WM → EgoExo-WM 这一行才看得清楚:HOMAGE/LEMMA 上 L2 下降 ~15%,PCK 显著上升;Bike/Cooking 上 L2 几乎打平,仅 PCK 提升。 - Naive EgoExo-WM(直接用 raw exo 视频,不转换)在 Bike/Cooking 上的 L2 和完整方法持平甚至更低 — 说明在这两个领域 exo-to-ego 转换的额外价值并不明显。
4.2 MPC Planning 评估 — Whole-body / Wrist MPJPE¶
| Model | HOMAGE MPJPE | HOMAGE Wrist | LEMMA MPJPE | LEMMA Wrist | Bike MPJPE | Bike Wrist | Cooking MPJPE | Cooking Wrist |
|---|---|---|---|---|---|---|---|---|
| UniEgoMotion (no WM) | 0.404±0.035 | 0.471±0.038 | 0.444±0.016 | 0.493±0.016 | 0.292±0.044 | 0.367±0.039 | 0.533±0.011 | 0.580±0.011 |
| UniEgoMotion + Ego-WM | 0.383±0.010 | 0.447±0.014 | 0.414±0.012 | 0.455±0.010 | 0.267±0.007 | 0.341±0.005 | 0.519±0.015 | 0.568±0.023 |
| UniEgoMotion + EgoExo-WM | 0.362±0.012 | 0.421±0.012 | 0.396±0.008 | 0.438±0.006 | 0.245±0.016 | 0.320±0.013 | 0.498±0.018 | 0.549±0.016 |
完整方法在 4 个数据集上的 MPJPE 都最低。提升幅度相对适中:相对 Ego-WM 改善 4-8%。
4.3 关键消融¶
最直接的消融是 Ego-WM vs Naive EgoExo-WM vs EgoExo-WM 三行: - Ego-WM vs Naive EgoExo-WM:单纯加 raw exo 数据本身就能改善 HOMAGE/LEMMA 的 L2(说明视觉多样性确实有价值),但牺牲了 Bike/Cooking 的 wrist PCK。 - Naive vs Full EgoExo-WM:转换步骤主要带来 PCK 的提升(HOMAGE 0.347→0.404, Bike 0.382→0.489, Cooking 0.368→0.460)— 这与论文设计相符:EgoX-Body 的 hand prior 直接对手部对齐有帮助,再加上 wrist consistency loss。
注:论文没有做 wrist consistency loss 单独的消融、\(H\) 上下文长度的消融、\(N\) candidate 数量的消融、\(\lambda\) 权重的消融。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
 Figure 4:EgoX vs EgoX-Body 定性对比 — 加了 body / hand kinematic prior 之后,左右手归属、手部姿态、与对象接触位置都明显更稳定
Figure 4:EgoX vs EgoX-Body 定性对比 — 加了 body / hand kinematic prior 之后,左右手归属、手部姿态、与对象接触位置都明显更稳定
- 3D human pose 作为统一接口:同一份 SMPL pose 同时承担「exo→ego 转换的条件」+「世界模型的动作输入」两个角色,省去了 latent action / IDM 的训练负担,也避开 text action 的语义模糊性。这是论文最巧妙的设计。
- EgoX-Body 中"双端 overlay"的对称设计:exo 端 body skeleton + ego 端 hand skeleton 分别针对各自视角的弱点(背景纠缠 / 手部遮挡),互不重复,且推理时手部 overlay 可由 body pose 直接投影获得,无 ego GT 依赖。
- DINOv3 latent space 训练:相比 PEVA 在 pixel 空间做 diffusion,latent 空间避免了 low-level appearance 主导损失,让 wrist PCK 这类 fine-grained 信号有机会被学到,也让训练成本可控(仅 8× A40)。
- Held-out 数据集评估:HOMAGE、LEMMA、Ego-Exo4D 全部不在训练集中,与 PEVA/EgoControl 「只在 Nymeria 上评估」相比是更诚实的设计。
- Wrist consistency loss 用冻结 head 解耦:先在 EgoExo4D + Nymeria 上预训一个 wrist heatmap decoder 然后冻结,避免与主 latent loss 相互干扰,是个干净的实现。
- 统一训练预算的 fairness 约束:所有 baseline + 自己的 variants 都用 200h 数据,避免"加更多数据所以更好"的混淆 — 这让 Ego-WM vs Naive EgoExo-WM vs EgoExo-WM 三行可比。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "Scalable"的口号 vs 实际只用 10 小时 exo 数据:abstract 与 intro 都用"unlock arbitrary in-the-wild videos"的语言,但实验只用 5+1+4=10h 转换数据。原因是 EgoX-Body 单条 49 帧推理 3.25 分钟(GH200),转换 10h(按 8Hz 计算 28.8 万帧,约 5,880 条 49 帧 clip)就需 ~320 GPU-hour — 在 GH200 上不算便宜。如果要真正 scale 到 HowTo100M 的全量,需要 ~3 个数量级的算力。这个 bottleneck 论文没有量化讨论。
- 2 秒 horizon 太短:训练用 49 帧 @ 16Hz → 下采 25 帧 @ 8Hz;评估开环 rollout 仅 8 帧 @ 4Hz = 2s。对真正的 planning("load my laundry")远远不够,论文也明确把 long-horizon 列为 future work。但既然这是核心 motivation,2s 的结果就只能算 proof-of-concept。
- SMPL 22 关节 = 没有 articulated hands:planning 任务要"reach for a mug"、"pour cereal",但动作空间不建模手指。论文用一段文字(§4.2 末)辩护说"whole-body coordination still matters",但 dexterous manipulation 这条产品线被排除了。在 motivation 里讲 AR 教练教足球这种例子还行;要做 robot 实操就力不从心。
- Bike / Cooking 上 Naive ≈ Full 的暗示:见 §4.1 表 — 在 Ego-Exo4D 两个 split 上,Naive EgoExo-WM 的 L2 与 Full 持平甚至略低。这说明 exo-to-ego 转换的核心价值集中在 wrist alignment 与 in-home 任务上,对 outdoor/sport 收益小。论文把这归因于"biking not well represented in our converted data",但其实更像是 head-mounted camera 的运动模糊与剧烈视角变化使得 ego prediction 本来就难,pose 信息边际效用低。
- 评估指标都是"代理":World model 用 DINOv3 latent L2,planning 用 MPJPE。但论文真正的 selling point 是「视觉目标驱动 → 选出能达成目标的 motion」— 应该看 达成 goal 时的视觉 L2 / SSIM,而不只是动作 trajectory 的 MPJPE。当前的 MPJPE 指标只能说明"挑出的动作更接近 GT 动作",对 visual goal 完成度没有直接证据。
- N=4 候选太少:MPC 中只采样 4 条 candidate 然后选最优。这对体现"WM as evaluator"的能力非常受限 — 把 candidate 提升到 32/64/128 才是 MPC 的常态做法,结果可能完全不同。论文没解释为什么是 4。
- PEVA / EgoControl 的对照可能不公:(a) PEVA 用 7/15/15 帧 context,本方法用 3 帧;(b) PEVA 在 pixel space,本方法用 DINOv3 latent 作为评估空间 — PEVA 的输出需要再 encode 到 DINOv3 才能比;(c) EgoControl 是作者自己重实现的。L2(pixel-space encoded by DINOv3) vs L2(latent-space prediction directly) 的几何上就是有差异的,前者多一层 encode 误差。所以 PEVA L2≈0.11 vs Ego-WM L2≈0.07 这种 ~40% 的提升里,多少来自 latent space、多少来自架构、多少来自数据,没法拆开。
- Wrist consistency loss 没单独消融:论文反复强调它的作用,但没有"Full method w/o wrist loss"的实验。在 wrist PCK 这个指标上的提升究竟来自 loss 还是来自 EgoX-Body 的 hand overlay 不清楚。
- Synthetic data quality 的 distribution shift 风险:训练用 10h 合成 ego(含 EgoX-Body 的伪影),在真 ego 数据上评估。合成片段有"black/white degenerate frames"问题(已被 filter 80% 保留),但保留下的 20% 是否仍把 video diffusion 的特定偏差注入 WM?没有诊断实验。
- Closed-loop / 真实部署完全没碰:所有 planning 都是 open-loop rollout + 离线 MPC + 与 GT 动作比 MPJPE。没有"WM 选了动作 → 真在场景中执行 → 看真实下一帧是否接近 goal"的循环测试。这种 evaluation gap 在 world model 论文里相当常见,但仍然是核心 limitation。
5.3 值得继续探讨的方向¶
- 替换 exo-to-ego 转换为 cross-view 条件直接学:能不能跳过 EgoX-Body 这一步(3.25 min/clip 太贵),让 WM 直接接收 (exo frame, ego pose) 作为条件 token?类比 cross-view co-training 的做法。
- 加入 articulated hand action 空间:SMPL → SMPL-X(已经在 EgoX-Body 里用了!)+ MANO 手指,但 WM 仍然只用 22 关节。把动作空间扩到 51 关节左右是否能提升 cooking、bike 上的 manipulation 精度?
- Long-horizon rollout 与 compounding error:8 步以上 rollout 时误差如何累积?是否需要类似 dreamer 的 hidden state recurrence、或在 latent 上加 stochastic regularization?
- 更大 N 的 candidate sampling:N=4 → 64/128,看 WM 作为 evaluator 的 scaling curve。
- Visual-goal-reaching 直接评估:用同一份 visual goal,让 WM 挑出动作并真实播放 → 与 goal 帧比较视觉相似度,建立 end-to-end 评估。
- 数据规模 ablation:固定 architecture,把 converted exo 从 0h → 10h → 50h → 200h,画 scaling curve。论文的 "scalable" 主张需要这个曲线来兑现。
- EgoX-Body 单独发布:作为一个独立的 exo→ego 转换工具,它有不错的应用价值(视频编辑、AR 体验创作)。论文已经在 supp 提到 release guidelines。
- 与 latent action models 的对比:DreamDojo 的 latent action 与本文 explicit SMPL action 各自的 strength — 是否可以混合:粗 navigation 用 SMPL,精细 manipulation 用 latent?
参考资源¶
- 论文 PDF:paper.pdf
- LaTeX 源码:GitHub: docs/2605.15477/source/
- 关键相关工作:
- PEVA (bai2025whole) — diffusion-based pixel ego WM baseline
- EgoControl (pallotta2025egocontrol) — diffusion ego WM baseline (作者重实现)
- EgoX (kang2025egox) — exo-to-ego conversion 的 base 框架
- UniEgoMotion (patel2025uniegomotion) — 既是 motion baseline 也是 action proposal
- DINOv3 (simeoni2025dinov3) — 视觉 encoder
- SAM-Body4D (gao2025sam, yang2026sam) — 3D body pose 估计
- Nymeria (ma2024nymeria) — 主训练数据
- HowTo100M / CrossTask / 100 Days of Hands — exo 数据来源
- DreamDojo (gao2026dreamdojo) — latent action ego WM 的另一条路线