π₀.₆ Model Card¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目:π₀.₆ Model Card
- 作者机构:Physical Intelligence(集体署名,无个人作者列表)
- 出处:Physical Intelligence 官网技术报告 / model card,2025-11-17 发布;PDF 链接
https://website.pi-asset.com/pi06star/PI06_model_card.pdf - 关键词:VLA、vision-language-action、π₀.₅ 演进、Gemma 3、Knowledge Insulation、flow matching、FAST tokens、metadata conditioning、out-of-the-box evaluation
- 一句话:π₀.₆ 是 Physical Intelligence 继 π₀ / π₀.₅ 之后的新一代 VLA 模型,沿用 π₀.₅ 的"高层子任务预测 + 低层动作生成"层级架构,但把 VLM backbone 升级到 Gemma 3 4B、引入可选 metadata conditioning 调控任务执行方式、并扩充训练数据,在无任务特定 fine-tune(out-of-the-box)的设置下相对 π₀.₅ 在静态、移动、泛化三大类任务上都取得了明显的成功率/吞吐量提升;它也是 RL 版本 π*₀.₆(arXiv 2511.14759, RECAP)的 base model。
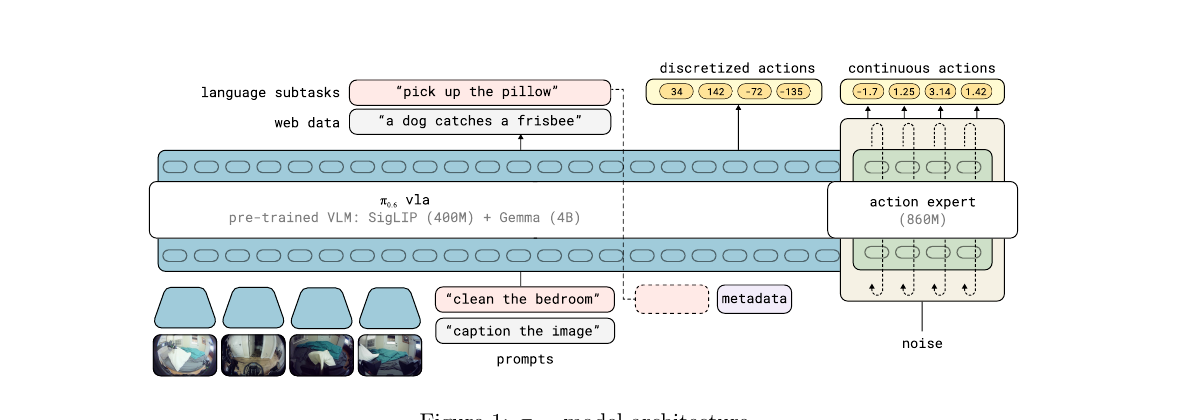 Figure 1:π₀.₆ 模型架构。VLA 主干由 SigLIP(400M)+ Gemma 3(4B)的预训练 VLM 与一个 860M 参数的 action expert 组成;输入包括最多 4 路 448×448 图像、本体感知 state、语言子任务、可选 metadata 与 web data 的 prompt;输出离散化的 FAST action tokens(走 VLM 主干)与连续动作(走 action expert,由 noise 经 flow matching 去噪得到)。
Figure 1:π₀.₆ 模型架构。VLA 主干由 SigLIP(400M)+ Gemma 3(4B)的预训练 VLM 与一个 860M 参数的 action expert 组成;输入包括最多 4 路 448×448 图像、本体感知 state、语言子任务、可选 metadata 与 web data 的 prompt;输出离散化的 FAST action tokens(走 VLM 主干)与连续动作(走 action expert,由 noise 经 flow matching 去噪得到)。
2. 文章介绍¶
2.1 解决的领域和问题¶
本文是一份 model card / 技术报告,定位是 PI 公司 VLA 谱系的版本说明:在 π₀ → π₀.₅ 已经把 VLA 推到能做"开放世界泛化"之后,π₀.₆ 想解决的核心问题是——如何在不针对每个目标任务做 task-specific post-training 的情况下,直接拿一个通用 VLA 部署就有可用性能。换言之,让"out-of-the-box"评测下的 success rate / throughput 跳一档,让"必须 fine-tune 才能动"的任务(如 laundry folding、box building)开箱可用。
2.2 Motivation¶
- π₀.₅ 已经证明 VLA 能在新家、新物体上做开放世界任务,但在难任务上仍依赖任务特定 post-training——给一个新任务时必须先收集高质量精修数据再 fine-tune 才有非零成功率,这与"通用基础模型"的承诺相悖。
- 同时 Physical Intelligence 在做 π*₀.₆(RECAP)这条线,需要一个比 π₀.₅ 更强的、能承载"自主经验 + 人工纠正 + RL 改进"流水线的 base policy;π₀.₆ 就是这条 RL 改进流水线的起点。
- 作者押注两个改动方向:更强的 VLM backbone(Gemma 3 4B)+ 更丰富的训练数据 + metadata conditioning,希望把"必须 task-specific fine-tune"这一约束放松到"开箱即可"。
2.3 之前工作的问题¶
| 路线 | 代表 | 主要缺陷 |
|---|---|---|
| 通用 VLA 不带任务 fine-tune | π₀ / π₀.₅ | 在难任务(laundry folding、box building)out-of-the-box 成功率接近 0;速度也不够 |
| 任务特定 post-training | π₀.₅ + 任务高质量数据 | 每新增一个任务都要收一批精修示范并 fine-tune,运维成本高、扩展性差 |
| 切换更小/相近 VLM backbone | π₀.₅ 用的 PaliGemma 系 backbone | 容量、世界知识、多模态能力相对受限,开箱泛化打不开 |
| 不带 metadata conditioning 的纯语言 prompt | 历代 π₀.x | 任务执行细节(怎么折、放哪里、走多快)难以由 prompt 一句话精细约束 |
2.4 论文解决方案(一句话)¶
π₀.₆ = π₀.₅ 层级架构 + Gemma 3 4B 主干 + Knowledge Insulation 训练 + 可选 metadata conditioning prompt + 更丰富的跨形态/家庭/web 数据,从而在 out-of-the-box 设置下吊打 π₀.₅,且作为 π*₀.₆(RECAP RL)的 base model 给后续真实世界 RL 留出空间。
2.5 与前序工作的关系¶
- 直接演进自 π₀.₅:保留分层设计(high-level subtask prediction + low-level action generation)和大部分训练数据组成;
- 沿用 π₀ 的"flow matching + 离散 tokens 混合输出":动作既以连续 flow matching 生成,也以 FAST tokens 离散表征做监督;
- 训练方式遵循 Knowledge Insulation (KI):VLM 主干负责 FAST action tokens 与 web co-training 的 next-token 预测;action expert 负责连续动作;action expert 的梯度被 stop gradient 不反传回 VLM 主干,避免破坏 VLM 的语义表征;
- backbone 升级:从 π₀.₅ 的 PaliGemma 系换到 Gemma 3 4B(参考文献 6),多模态/语言能力增强;
- 作为 π*₀.₆ (RECAP, 2511.14759) 的 base:本 model card 里的 π₀.₆ 是 RL 训练的起点,RECAP 在此之上加 advantage conditioning + 真实世界 RL;
- 数据基础设施:跨形态(cross-embodiment)数据 + 家庭场景的 mobile / non-mobile 数据 + 高层子任务预测 + 多模态 web 数据(含 bounding box / keypoint 预测),整体延续 π₀.₅ 思路。
3. 方法介绍¶
3.1 架构(保留 π₀.₅ 分层、升级 backbone 与 prompt)¶
π₀.₆ 仍是 flow matching + 离散 token 混合输出的 VLA:
- VLM 主干:从 Gemma 3 4B(参考文献 6)初始化,外加 SigLIP(400M)视觉 encoder(共同构成 pre-trained VLM)。
- Action expert:与 backbone 同层数、约 860M 参数,输出连续动作 chunk(flow matching 去噪)。
- 输入:
- 最多 4 路图像,448×448 分辨率(base camera、最多 2 路 wrist camera、mobile manipulator 上可选 1 路后向相机);
- tokenized language prompt;
- tokenized proprioceptive state;
- 可选 metadata prompt(详见 3.3);
- 可选高层 subtasks / web co-training prompts(如 "pick up the pillow"、"caption the image")。
- Attention 模式:图像 token 之间双向 attention(与 π₀.₅ 一致);text token 之间因果 attention;送入 action expert 的 action token 之间双向 attention。
- 输出:上层 VLM 主干同时输出 FAST action tokens(离散)和 web 数据 co-training 的 next-token;下层 action expert 输出连续动作。
- 推理速度:3 路相机 + 5 步 denoising,单张 H100 上 63ms / action chunk。
3.2 训练 — Knowledge Insulation (KI)¶
- VLM 主干承担 next-token prediction:FAST tokens、subtask 文本、多模态 web 数据。
- Action expert 承担连续动作的 flow matching。
- Action expert 的梯度 stop-gradient,不反传回 VLM 主干——保护 VLM 的语义/常识表示不被低层运动噪声冲垮。这一思路直接来自参考文献 3(Driess et al., Knowledge Insulating VLA)。
3.3 Metadata conditioning(本作的小新点)¶
除了语言 command("clean the bedroom"),π₀.₆ 可以在 prompt 里追加 conditioning metadata,进一步调控任务被如何执行——例如指定风格、约束、子目标顺序等(文中未给出穷举语义,但架构图 1 明确把 metadata 与 prompts 并列)。这一通道让作者无需新数据就能在推理时切换执行模式,是把"通用 VLA"变成"开箱即用"的关键 prompt 工程。
3.4 训练数据¶
π₀.₆ 大体继承 π₀.₅ 的数据组合:
- In-house cross-embodiment 数据:跨多种机器人形态采集;
- External data sources:外部公开/合作数据;
- 家庭场景:mobile + non-mobile 的真实家庭数据;
- High-level subtask prediction:高层任务规划样本;
- 多模态 web 数据:含 bounding box / keypoint prediction 任务。
注意文中没有给出新增数据的具体小时数 / episode 数,只说"数据更多样、metadata 更丰富,于是不再需要任务特定 fine-tune"。
3.x Implementation Details¶
- VLM backbone:SigLIP 400M + Gemma 3 4B;
- Action expert:约 860M 参数,flow matching;
- 输入:≤4 路 448×448 图像 + 语言 + state + 可选 metadata;
- Attention:image bidirectional、text causal、action bidirectional;
- 训练 recipe:Knowledge Insulation(VLM next-token + action flow matching,action 梯度 stop-grad);
- 输出:FAST tokens(离散,VLM 端)+ continuous actions(flow matching,expert 端);
- 推理:5 denoising steps + 3 相机 → 63ms/chunk @ H100;
- 数据:cross-embodiment + 家庭 + 子任务 + 多模态 web(含 bbox / keypoint)。
4. 结果对比¶
4.1 评测设置¶
- 比较对象:π₀.₅(改进版,用 KI 训练,已在 openpi [4] 开源)vs π₀.₆。
- 关键设定:两个模型都不做 task-specific fine-tune("out-of-the-box"评测)。
- 指标:success rate / task progress 与 throughput(每小时成功数);误差棒为标准误。
4.2 静态任务(Figure 2)¶
任务:shirt folding(衣服平铺起折)、laundry folding(T-shirt/shorts 从篮子里折)、box assembly、table bussing。
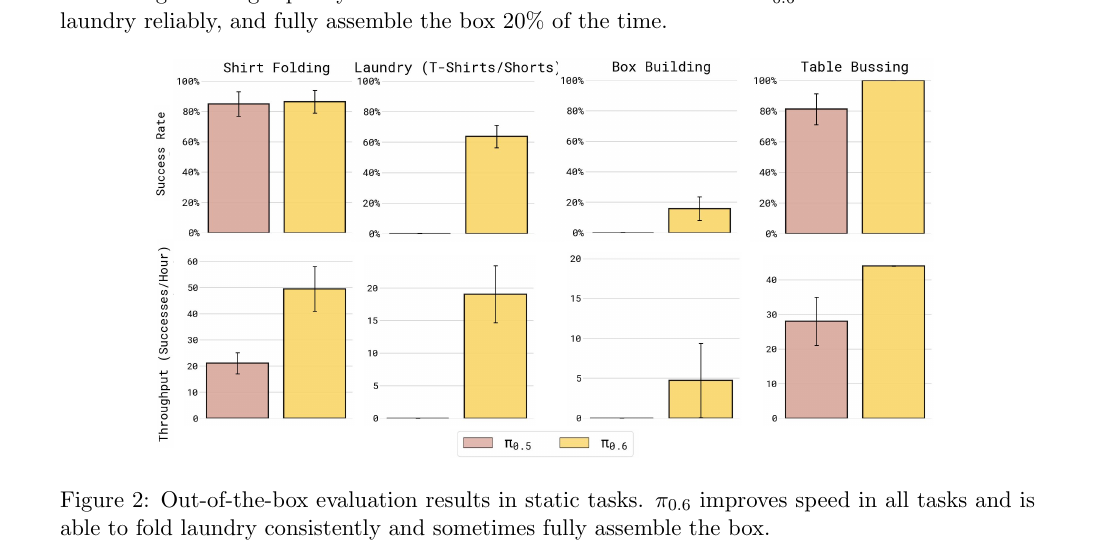 Figure 2:静态任务的 out-of-the-box 评测。π₀.₆ 在所有任务上提升了速度(throughput),成功率在 laundry 和 box building 上有质变。
Figure 2:静态任务的 out-of-the-box 评测。π₀.₆ 在所有任务上提升了速度(throughput),成功率在 laundry 和 box building 上有质变。
| 任务 | π₀.₅ | π₀.₆ | 备注 |
|---|---|---|---|
| Shirt Folding(平铺起折) | success ≈85%,throughput ≈20 /h | success ≈85%,throughput ≈50 /h | 2.5× throughput |
| Laundry (T-Shirts/Shorts,从篮子里) | success ≈0%(基本失败) | success ≈65%,throughput ≈18 /h | 从 0 → 可靠(之前必须 fine-tune 才有非零) |
| Box Building(组装纸箱) | success ≈0% | success ≈20%,throughput ≈5 /h | 从 0 → 20%(之前必须 fine-tune) |
| Table Bussing | success ≈80%,throughput ≈28 /h | success ≈100%,throughput ≈43 /h | success 上 ~+20pt,throughput ~+50% |
最大亮点:laundry folding 与 box assembly 之前必须做任务特定 fine-tune 才能拿到非零成功率,现在 out-of-the-box 就能跑。
4.3 移动任务(Figure 3)¶
任务:laundry basket(拾衣放篮)、make bed(整理床铺)、dishes in sink(碗碟入水池)、items in drawer(物品放抽屉),由 mobile bimanual robot 完成(π₀.₅ 论文的主评测)。
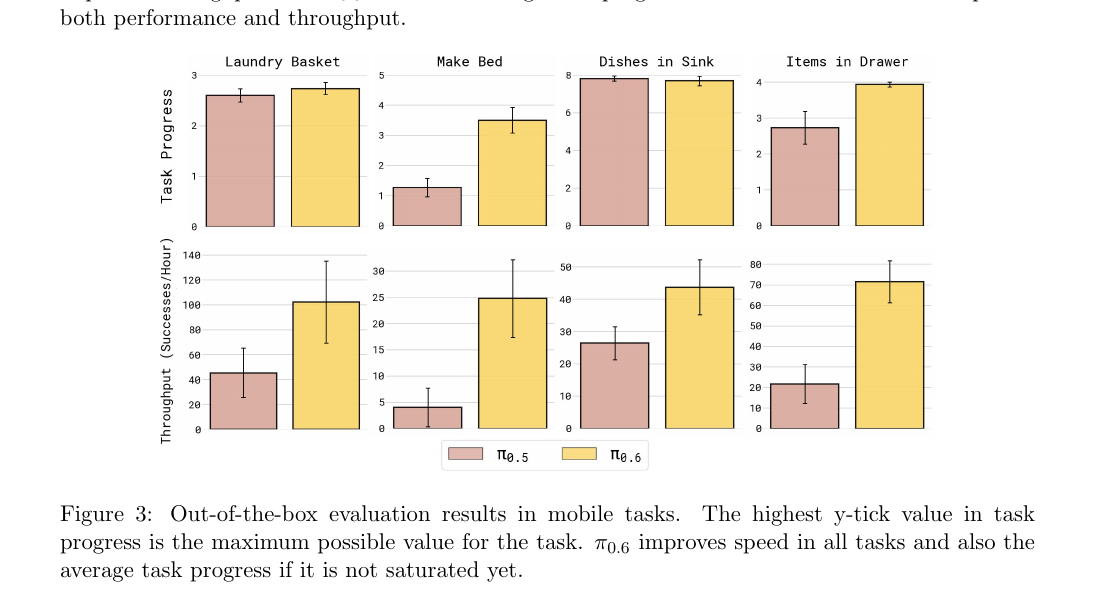 Figure 3:移动任务的 out-of-the-box 评测。task progress 已饱和的任务上 π₀.₆ 主要提升 throughput;未饱和的任务(make bed、items in drawer)上同时提升 progress 和 throughput。
Figure 3:移动任务的 out-of-the-box 评测。task progress 已饱和的任务上 π₀.₆ 主要提升 throughput;未饱和的任务(make bed、items in drawer)上同时提升 progress 和 throughput。
| 任务 | task progress | throughput |
|---|---|---|
| Laundry Basket | π₀.₅ ≈2.5 / π₀.₆ ≈2.7(满分 3,近饱和) | 40 /h → ≈105 /h(~2.5×) |
| Make Bed | π₀.₅ ≈1.2 / π₀.₆ ≈3.5(满分 5,~3×) | ≈4 /h → ≈25 /h(~6×) |
| Dishes in Sink | π₀.₅ ≈8 / π₀.₆ ≈8(满分 8,已饱和) | ≈25 /h → ≈45 /h(~+80%) |
| Items in Drawer | π₀.₅ ≈2.6 / π₀.₆ ≈4(满分 4,饱和到满分) | ≈22 /h → ≈72 /h(~3.3×) |
结论:progress 饱和则提速;未饱和则同时提 progress 与 throughput。
4.4 泛化任务(Figure 4)¶
四套泛化任务,每套 12–18 条指令,分三档难度,覆盖语言泛化(如"pick up the third fruit from the left"、"move to where the fresh milk is kept")和动作泛化(如"wipe the spill with the bread"、"hang the shorts into oven handle")。多数指令与物体未在训练中见过。
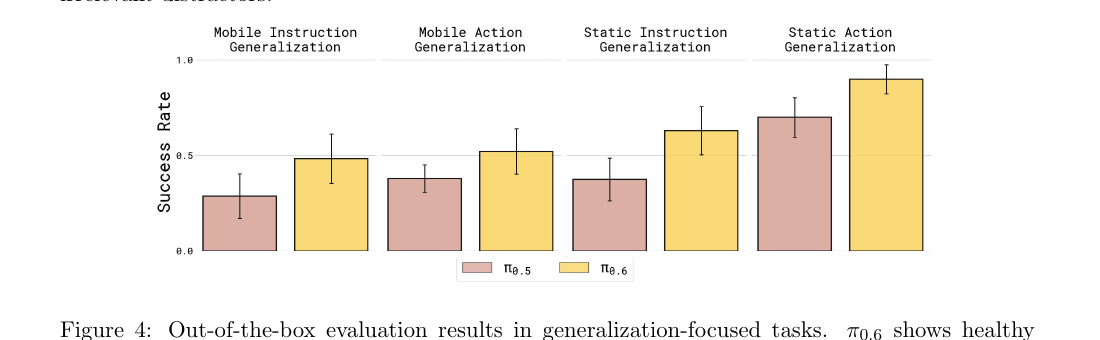 Figure 4:泛化任务的 out-of-the-box 评测。π₀.₆ 在 mobile/static × instruction/action 四种组合上都对 π₀.₅ 有"健康"的提升。
Figure 4:泛化任务的 out-of-the-box 评测。π₀.₆ 在 mobile/static × instruction/action 四种组合上都对 π₀.₅ 有"健康"的提升。
| 设定 | π₀.₅ success | π₀.₆ success |
|---|---|---|
| Mobile Instruction Generalization | ≈0.28 | ≈0.48 |
| Mobile Action Generalization | ≈0.37 | ≈0.52 |
| Static Instruction Generalization | ≈0.37 | ≈0.63 |
| Static Action Generalization | ≈0.70 | ≈0.90 |
作者评:mobile 设置普遍更难(任务更长 horizon、环境干扰多),但 π₀.₆ 在四种设置上都明显提升。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- "零 fine-tune"门槛跨过去了:laundry folding 与 box building 之前是"必须 task-specific post-training 才能动"的难任务,π₀.₆ 直接 out-of-the-box 出非零、甚至可用的成功率,这是产品化层面的实质进步——意味着新部署场景可以先丢预训练模型试,再决定是否需要精修。
- 吞吐量普遍翻倍:除了 success,throughput 全线提升 1.5–6×,对真机部署是直接收益(成本/小时下降)。
- 架构改动克制:保留 π₀.₅ 的分层 + flow matching + FAST tokens + KI 训练,主要靠 VLM backbone 升级 (Gemma 3 4B) + metadata prompt + 数据多样性,把工程改动收得很窄,便于对外宣称"同一套配方持续 scaling"。
- 63ms/chunk 推理速度:3 相机 + 5 denoising step 单卡 H100 63ms,对 50 Hz 关节控制完全够用,没有为了能力牺牲 latency。
- 铺垫 RL 改进:明确说明 π₀.₆ 是 π*₀.₆ (RECAP) 的 base,让"先做强 BC base,再做 RL 改进"的产品路线图清晰可循。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 报告内容极薄、缺消融:4 页 model card,没有任何消融实验——backbone 从 PaliGemma 换到 Gemma 3 4B 贡献多少?metadata conditioning 贡献多少?训练数据扩充贡献多少?读者完全无法分离这三大改动的贡献。
- 数据量与配比不透明:训练数据章节只写"largely inherits π₀.₅",没给具体新增多少小时、来自什么场景、metadata 来源是什么。"out-of-the-box 能力大涨"是否主要来自悄悄加进训练集的、跟评测任务很像的数据?无法判断。
- π₀.₅ baseline 的公平性:对比的 π₀.₅ 是"improved version trained with KI"(openpi 开源版)。但 π₀.₆ 看起来同样用了 KI、同样的训练数据基底——那么这个 π₀.₅ baseline 是否被故意"不灌新数据"以放大 gap?没有交叉 ablation 难以澄清。
- "out-of-the-box" 定义的范围:模型仍然是在跟评测任务高度相关的真机数据上预训练的;从用户视角,"开箱即用"通常指"完全没见过的任务"。这里更准确的说法是"没有针对单个 task 再 fine-tune",但 pre-train 时这个任务的相邻分布是覆盖过的。营销话术与技术含义之间的 gap 应该被读者注意到。
- Box Building 20% 远谈不上"可用":作者宣传"fully assemble the box 20% of the time",但 20% 成功率距生产可用还非常远;与 RECAP 把 box assembly 提到 2× throughput 的对比,反衬出纯 BC 上限就是这样,难任务仍需 RL——这其实是本 card 的隐性信息。
- Metadata conditioning 没给一个例子:架构图里
metadata是一个独立 prompt,但正文没给任何示例(metadata 长什么样、字段有哪些、是否人工指定)。这导致最具新意的改动反而最模糊。 - 泛化指标只到 success rate:4 套泛化任务的对比只给 success,没给 throughput、没给失败模式分类,难以判断"泛化提升"是真理解还是更激进的尝试动作。
- 评测人工标注且任务有限:success label 仍为人工标注,且只覆盖少数任务族;与同期其他 VLA 论文一样存在主观性与覆盖窄的问题。
- 没有开源/复现:与 π₀.₅ 的 openpi 版本不同,π₀.₆ 本身没有开源承诺;外部研究者无法验证"开箱即用"的程度。这也意味着 π*₀.₆ (RECAP) 的可复现性同样受限。
- 63ms 数字的口径:宣称 5 denoising steps 下 63ms,但论文里 RECAP 用的 β-CFG steering 会改变推理代价;且没给 batch、precision 等具体设定,复现时数字可能差出一截。
5.3 值得继续探讨的方向¶
- 三大改动的拆解消融:发布一个"只换 backbone"、"只加 metadata"、"只扩数据"的三版控制实验,能极大澄清贡献来源。
- metadata conditioning 的语义白皮书:公开 metadata schema(字段、取值、采样方式),并对比"prompt 写 metadata vs. prompt 不写"的执行差异,让这个新通道真正可被外部用上。
- 泛化的失败模式分析:在 generalization 套件上做错误分类,看"out-of-distribution language"和"out-of-distribution skill"分别失败在哪——前者大概率是 VLM 主干升级(Gemma 3)的功劳,后者则关乎 action expert 与数据。
- 作为 RL base 的可改进余地:与 RECAP 论文交叉对比,分析"π₀.₅ 作 base + RECAP" vs "π₀.₆ 作 base + RECAP"的差距,验证升级 BC base 对 RL 上限的真实贡献。
- 公开一个 community-friendly checkpoint:哪怕是降配版,也能让外部把"out-of-the-box"这一主张接受为科学陈述而非营销陈述。
参考资源¶
- 论文 PDF:paper.pdf
- 原始链接:
https://website.pi-asset.com/pi06star/PI06_model_card.pdf - 关键参考与谱系:
- π₀(Black et al., RSS 2024)—— VLA 谱系起点
- π₀.₅(Black et al., CoRL 2025)—— 开放世界泛化、分层架构、π₀.₆ 的直接前身
- Knowledge Insulation(Driess et al., NeurIPS 2025)—— action expert 梯度隔离训练
- openpi(Physical Intelligence)—— π₀.₅ 的开源改进实现,本 card 的 baseline
- FAST(Pertsch et al., RSS 2025)—— 离散 action tokenization
- Gemma 3(Gemma Team, 2025)—— π₀.₆ 的 VLM backbone
- π*₀.₆ / RECAP(Physical Intelligence, 2025;arXiv 2511.14759)—— 以 π₀.₆ 为 base,叠加真实世界 RL 与 advantage conditioning 的后续工作