Roach: TerraTransfer / Gigapixel 的 2021 祖宗¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: End-to-End Urban Driving by Imitating a Reinforcement Learning Coach
- 作者: Zhejun Zhang\(^{1}\), Alexander Liniger\(^{1}\), Dengxin Dai\(^{1,2}\), Fisher Yu\(^{1}\), Luc Van Gool\(^{1,3}\) — \(^1\)ETH Zürich CVL, \(^2\)MPI for Informatics, \(^3\)KU Leuven PSI
- arXiv 编号: 2108.08265(2021-08 提交,ICCV 2021 camera-ready)
- 关键词: RL coach, BEV-based privileged expert, PPO with Beta distribution, action-distribution KL distillation, feature matching, value distillation, CILRS, DAGGER, NoCrash, CARLA LeaderBoard
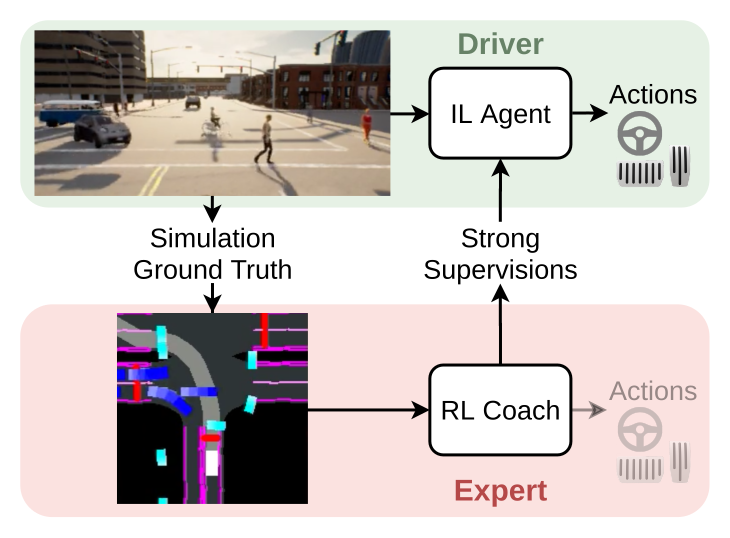 Figure 1:Roach = "RL Coach"。一个 RL 训出来的 privileged BEV-to-action 专家不仅在 CARLA 上设了新 SOTA,更重要的是——作为一个神经网络 coach,它能给 IL 学生提供 action 分布、value、latent feature 三种信息密度远高于"动作硬标签"的监督信号。这张图就是后来 2026 年 Gigapixel / TerraTransfer / Spiced / World Engine 全套"用 RL teacher 蒸馏 vision student"范式的最早原型。
Figure 1:Roach = "RL Coach"。一个 RL 训出来的 privileged BEV-to-action 专家不仅在 CARLA 上设了新 SOTA,更重要的是——作为一个神经网络 coach,它能给 IL 学生提供 action 分布、value、latent feature 三种信息密度远高于"动作硬标签"的监督信号。这张图就是后来 2026 年 Gigapixel / TerraTransfer / Spiced / World Engine 全套"用 RL teacher 蒸馏 vision student"范式的最早原型。
2. 文章介绍¶
2.1 解决的领域和问题¶
2021 年的 end-to-end urban driving 几乎完全靠 imitation learning from human demonstration(CILRS、LBC、SAM、DA-RB),核心痛点是 covariate shift——expert 数据稀少 + on-policy labeling 不可得 + 罕见事件(碰撞前兆、recovery)几乎不在 log 里。CARLA 上常用的"自动 expert"是 Autopilot(一个 hand-crafted 规则 planner),但它驾驶质量本身不达人类水准,连 expert demonstrations 的 upper bound 都不够。
具体问题:能否做出一个比 Autopilot 更强、且本身就是神经网络的"自动 expert",从而既提升 IL 的能力天花板,又能通过 soft target / latent feature 等"神经网络才有"的接口给 vision student 更密集的监督?
2.2 Motivation¶
两层动机:
- Expert quality bottleneck:IL agent 的性能受 expert 性能 bound——Autopilot 自己 NoCrash-dense new-town 只有 ~28% SR,再 imitate 它再多次也突破不了。需要一个真·更强的 expert。
- Knowledge-transfer 视角:IL 的本质是 "knowledge transfer from teacher to student"。Hinton 那套 soft target / KD 早就证明神经网络 teacher 能给 hard label 之外的有用信号(action 分布的方差、value 估计、中间 representation)。但当时的驾驶 expert 全是 rule-based / scripted,给不出这些信号。一旦 expert 也是神经网络,整个 KD 工具箱就能用上。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Human IL | CILRS, DA-RB+, SAM | 受 covariate shift 困扰;人类无法做 on-policy labeling |
| 规则 expert + IL | LBC (使用 Autopilot 作 teacher), LSD | Autopilot 本身就是天花板,规则 driving 不够 nuanced |
| Pure RL camera | MaRLn, CIRL | 直接像素 RL 训练慢、不稳定,最终性能也只到 ~50% SR |
| Hand-crafted CARLA RL expert | Toromanoff CVPR'20 | 用 dense rewards + 大量 trick;本身 expert 性能受限 |
| Privileged teacher distillation | LBC (Chen 2020), Roach 类思路前身 | LBC 的 teacher 是 Autopilot 的镜像、本身没超过 Autopilot |
| 像素 + 模仿 + DAGGER | DA-RB+ | DAGGER 修 covariate shift 但 teacher 还是 Autopilot |
2.4 论文解决方案(一句话)¶
训一个纯 RL 的 BEV-to-action expert(Roach: 在 CARLA 上 6 GPU 跑 10M PPO 步,用 Beta 分布 + 自创 "exploration loss" 拿到 NoCrash 96% / new-town-new-weather SR),冻结后当神经网络 coach 用 action distribution KL + latent feature L2 + value MSE 三种 loss 蒸馏一个单相机 CILRS-架构的 IL 学生,让学生在 NoCrash-dense new-town-new-weather 拿到 78% SR——比之前所有方法翻倍。
2.5 与前序工作的关系(以及与 2026 后辈的关系)¶
- 直接前作:LBC (Chen 2020) "Learning by Cheating" 提出 privileged teacher → camera student 的范式,但 teacher 是 Autopilot 的镜像。Roach 把 teacher 升级成纯 RL 神经网络。
- 方法借用:PPO (Schulman 2017)、Beta 分布 (Chou 2017)、Hinton KD (2015)、CILRS (Codevilla 2019)、DA-RB+ (Prakash 2020)。
- 直接后辈(5 年后):
- TerraTransfer (2606.17386):思路几乎一比一复刻 Roach:vectorized self-play RL teacher → 冻结 → 用 action KL + latent feature 蒸馏 vision student。差异:teacher 升级到多 agent self-play(GigaFlow 风格)+ DINOv3 视觉 backbone + 把 feature L2 升级成 SVD low-rank 的 batch-relational 结构 loss。
- Gigapixel (2606.19641):teacher 同样是 vectorized self-play,但用 self-play DAgger 在自家像素 simulator 内蒸馏,而非冻结 teacher 在 paired data 上对齐。
- Spiced Self-Play (2606.19370):teacher = self-play RL,把人类数据当 KL anchor 而非作目标——和 Roach 把 RL 当主体的精神一致。
- World Engine (2606.19836):teacher 是预训 E2E,World Engine 做后训长尾合成——是另一条范式,与 Roach 的"先 RL coach、后蒸馏"路线在哲学上有不同。
3. 方法介绍¶
3.1 Roach(RL coach)¶
策略网络 \(\pi_\theta(\mathbf{a}|\mathbf{i}_\text{RL}, \mathbf{m}_\text{RL})\) 与价值网络 \(V_\phi(\mathbf{i}_\text{RL}, \mathbf{m}_\text{RL})\) 都吃同一组输入:
- BEV semantic image \(\mathbf{i}_\text{RL} \in [0,1]^{W\times H\times C}\) —— 9 个灰度通道:drivable area、intended route、lane(实线白虚线灰)、车辆 K 帧时序 box、行人 K 帧时序 box、stop-line/stop-sign(红黄绿不同灰度区分信号灯状态)。ego 永远朝上、底部固定位置——把 ego 几何抽象掉,让网络专注交互。
- Measurement vector \(\mathbf{m}_\text{RL} \in \mathbb{R}^6\) —— steering、throttle、brake、gear、纵 & 横速度。
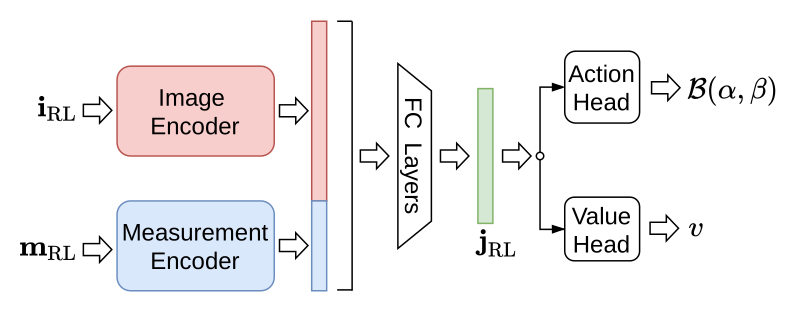 Figure 2:Roach 网络结构:6 层 CNN encode BEV + 2 层 FC encode measurement → concat → 2 FC → latent \(\mathbf{j}_\text{RL}\) → 分别接 value head 和 policy head(各 2 FC hidden)。Latent \(\mathbf{j}_\text{RL}\) 是后面蒸馏学生的关键接口。
Figure 2:Roach 网络结构:6 层 CNN encode BEV + 2 层 FC encode measurement → concat → 2 FC → latent \(\mathbf{j}_\text{RL}\) → 分别接 value head 和 policy head(各 2 FC hidden)。Latent \(\mathbf{j}_\text{RL}\) 是后面蒸馏学生的关键接口。
Output:直接预测 Beta 分布参数 \(\alpha, \beta > 0\)(steering 和 acceleration 两维)。比 Gaussian 优在 (a) bounded support,省 tanh squashing;(b) 熵和 KL 有解析式;(c) modality 适合"急刹/急转"这种 corner case 的双峰分布。
Training:6 张 GPU、6 个 CARLA server 同时跑 6 张 LeaderBoard 地图,10 FPS 采轨迹。损失:
第三项 \(\mathcal{L}_\text{exp}\)(Exploration Loss)是 Roach 的一个不显眼但关键的贡献:观察到 \(\mathcal{L}_\text{ent} = -\text{KL}(\pi_\theta \| \mathcal{U})\),即"max entropy"等价于"KL 拉向均匀先验"——那为什么不针对不同 episode 终止条件 \(z\) 用不同先验?
也就是说仅对 episode 终止前 \(N_z = 100\) 步施加 task-aware 先验:撞车/闯红灯前的 100 步用 \(\mathcal{B}(1, 2.5)\)(鼓励减速);被堵住前的 100 步用 \(\mathcal{B}(2.5, 1)\)(鼓励加速);偏离路线前的 100 步对 steering 用均匀先验(鼓励多样转向)。这把 RL 的"failed episode 学到下次别再犯同样错"机制内化进 policy 而不是靠 dense reward shaping。
性能:10M 步内一周训完,LeaderBoard 6 张地图全部 SOTA,NoCrash-dense new-town-new-weather 96% SR——超过 Autopilot 自己。
3.2 IL Agents Supervised by Roach(核心 KD 部分)¶
学生架构 = CILRS(一个 ResNet-34 image encoder + measurement encoder → bottleneck \(\mathbf{j}_\text{IL} \in \mathbb{R}^{256}\) → 多 branch action head)。Roach 用 4 种 loss 监督它:
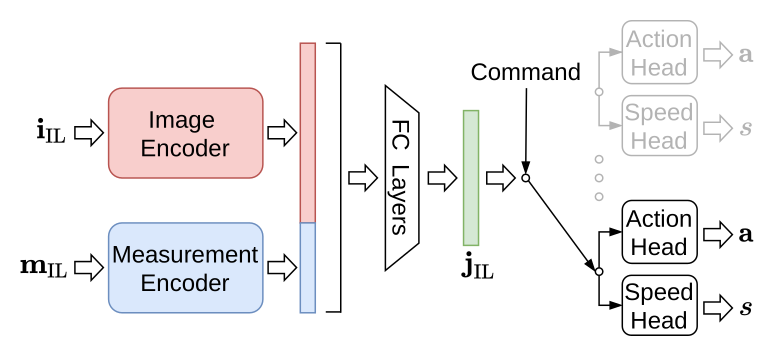 Figure 3:CILRS 学生网络结构。Bottleneck \(\mathbf{j}_\text{IL}\) 与 Roach 的 \(\mathbf{j}_\text{RL}\) 设计为同维(256),feature matching loss 直接 L2 对齐。这与 TerraTransfer 的 batch-relational SVD low-rank 结构 loss 是同一个思路的祖先版本。
Figure 3:CILRS 学生网络结构。Bottleneck \(\mathbf{j}_\text{IL}\) 与 Roach 的 \(\mathbf{j}_\text{RL}\) 设计为同维(256),feature matching loss 直接 L2 对齐。这与 TerraTransfer 的 batch-relational SVD low-rank 结构 loss 是同一个思路的祖先版本。
Loss 1: \(\mathcal{L}_\text{A}\) — 动作硬标签 L1(默认 baseline)¶
\(\hat{\mathbf{a}}\) 从 Beta 分布取 mode。Autopilot 这种 rule-based teacher 也只能给这个。
Loss 2: \(\mathcal{L}_\text{K}\) — Action Distribution KL(即 TerraTransfer 的 action loss)¶
教师和学生同时输出 Beta 分布,全分布对齐而非 mode。这与 TerraTransfer 的 \(\mathcal{L}_\text{act} = \text{KL}(\pi^T \| \pi^S)\) 是同一个 loss——只是教师输出从 Beta 改成 categorical softmax。
Loss 3: \(\mathcal{L}_\text{F}\) — Feature Matching L2(即 TerraTransfer 结构 loss 的祖先)¶
直接 L2 对齐 256 维 latent。论文的论据非常清晰: - \(\mathbf{j}_\text{RL}\) 只经过两层 FC 就能映出 expert action,所以它是 "包含驾驶必要信息的紧凑表征"。 - \(\mathbf{j}_\text{RL}\) 对 rendering / weather 不变,因为 Roach 用的是 abstract BEV,所以让 camera student 学进这个 latent 等价于"先把图像投影到 weather-agnostic 表征再决策"。
这正是 TerraTransfer 的 batch-relational SVD low-rank 结构 loss 的祖先——TerraTransfer 升级了两点: 1. 把"绝对坐标 L2"换成"批内 cosine similarity 矩阵的 Frobenius"(学相对关系而非绝对坐标) 2. SVD 截断到 80% 累计能量子空间(避开 teacher 特征的低秩噪声尾部)
Roach 的 \(\mathcal{L}_\text{F}\) 在 2021 年是用全 256 维做 full L2 的——经验上有效但理论上确实在拟合 teacher 表征的低能量尾部,TerraTransfer 5 年后用 SVD 给了它一个干净的理论封装。
Loss 4: \(\mathcal{L}_\text{V}\) — Value Regression(TerraTransfer 没保留 这条)¶
CILRS 加一个 value head 当 side task,学生学着估"这个 state 有多危险"——本质是 multi-task auxiliary supervision。文中说单独用 \(\mathcal{L}_\text{V}\) 效果不显著,但和 \(\mathcal{L}_\text{F}\) 一起用能加速 DAGGER 收敛("feature 编码了 value 所需信息,互相正则")。
3.3 训练框架:DAGGER + 4 种 loss 任选组合¶
实验里跑的组合: - \(\mathcal{L}_\text{A}(\text{AP})\) — baseline,Autopilot 当 teacher,L1 动作 - \(\mathcal{L}_\text{A}\) — Roach 当 teacher,仍 L1 动作(消融"换 teacher"的纯收益) - \(\mathcal{L}_\text{K}\) — Roach 当 teacher,换成 KL(消融 soft target) - \(\mathcal{L}_\text{K} + \mathcal{L}_\text{F}(c)\) — 最终最佳:KL + feature L2,用单 branch + command one-hot 架构
DAGGER 跑 5 轮。每轮收 student rollout,用 Roach 重新标注,加进训练池。
3.x Implementation Details¶
| 项 | 数值 |
|---|---|
| Roach 网络规模 | 6 conv + 2 FC encoder + 2 FC heads(不算大) |
| Roach 训练 | PPO-clip (stable-baselines3) / 10M 步 / 6 CARLA servers / ~1 周 |
| Roach Beta 分布 | 2D:(steering, acceleration) ∈ \([-1, 1]^2\) |
| Reward | Toromanoff CVPR'20 基础 + steering-change penalty + speed-proportional penalty |
| Exploration loss \(N_z\) | 100 步窗口(episode 末段) |
| CILRS encoder | ResNet-34 ImageNet 预训 + 3 FC → \(\mathbf{j}_\text{IL} \in \mathbb{R}^{256}\) |
| Camera 输入 | 单 wide-angle camera, \(900 \times 256 \times 3\), 100° HFOV |
| DAGGER iter | 5 轮 |
| Benchmark | NoCrash (NCd-tt/tn/nt/nn) + CARLA LeaderBoard (offline routes) |
| CARLA 版本 | 0.9.11 |
4. 结果对比¶
4.1 Expert 自身性能(NoCrash-dense, 一周训 = Roach SOTA)¶
Roach 在 NoCrash-busy new-town-new-weather 拿到 96% SR / 96% Driving Score,超过 Autopilot 的 91% / 79%。这就是新的 IL upper bound。
4.2 IL Agent 在 NoCrash-dense 上(success rate)¶
| Method | NCd-tt | NCd-tn | NCd-nt | NCd-nn |
|---|---|---|---|---|
| LBC (CARLA 0.9.6) | 71±5 | 63±3 | 51±3 | 39±6 |
| SAM | 54±3 | 47±5 | 29±3 | 29±2 |
| LSD | N/A | N/A | 30±4 | 32±3 |
| DA-RB+ (E) | 66±5 | 56±1 | 36±3 | 35±2 |
| DA-RB+ (0.8.4) | 62±1 | 60±1 | 34±2 | 25±1 |
| 本文 baseline \(\mathcal{L}_\text{A}(\text{AP})\) | 88±4 | 29±3 | 32±11 | 28±4 |
| 本文 best \(\mathcal{L}_\text{K} + \mathcal{L}_\text{F}(c)\) | 86±5 | 82±2 | 78±5 | 78±0 |
NoCrash 4 个 split(train-town/train-weather, train-town/new-weather, new-town/train-weather, new-town/new-weather)。最难的 NCd-nn(new-town + new-weather)从 baseline 28% 跳到 78%,几乎 3 倍。
4.3 Loss 消融(NoCrash-busy new-town-new-weather, DAGGER iter 5)¶
| Config | SR | Driving Score | Route Compl. | Infrac. Penalty |
|---|---|---|---|---|
| \(\mathcal{L}_\text{A}(\text{AP})\)(Autopilot teacher, L1) | 31±7 | 43±2 | 62±6 | 77±4 |
| \(\mathcal{L}_\text{A}\)(Roach teacher, L1) | 57±7 | 66±3 | 84±3 | 76±1 |
| \(\mathcal{L}_\text{K}\)(Roach teacher, KL) | 74±3 | 79±0 | 91±2 | 86±1 |
| \(\mathcal{L}_\text{K} + \mathcal{L}_\text{F}(c)\)(KL + feature L2) | 87±5 | 88±3 | 96±0 | 91±3 |
| Roach (上限) | 95±2 | 96±3 | 100±0 | 96±3 |
| Autopilot | 91±1 | 79±2 | 98±1 | 80±2 |
逐步归因(DS = Driving Score): - 换 Autopilot → Roach 当 teacher(同 L1):+23 DS(这是单纯"更强 expert"的功劳) - L1 → KL(同 Roach teacher):+13 DS(soft target 的功劳) - KL → KL + feature L2:+9 DS(latent representation 对齐的功劳)
Camera-only student 最终 88 DS,距离 Roach 上限 96 DS 仅差 8 个点。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 2021 年就把 "neural-network RL coach + KD" 这件事完整钉死。论文反复强调一个 framing:"IL 的本质是 knowledge transfer;hard label 是 KD 工具箱里最弱的接口;要换上 soft target / latent feature / value"——这套话术 5 年后被 TerraTransfer 一字不差搬过来,loss 函数家族也几乎一比一对应。看 Roach 就等于看到 TerraTransfer 的"如果不上 self-play 多 agent 而留在单 agent CARLA"是什么样子。
- Exploration loss 是低调的好 idea。把 \(\mathcal{L}_\text{ent}\) 推广到 task-aware 终止条件先验,让 RL 在 episode 末 100 步针对失败原因"反向 backprop"——这在 reward engineering 之外补了一条更结构化的归纳通道,是真有方法学贡献的小创新。
- Beta 分布 + 自然的双峰 actions。CARLA 上"急刹 vs 稳速"、"急转 vs 直行"天然就有双峰分布;Beta 分布的 modality 比 Gaussian 适配得多,同时还省 squash 的近似。这是工程派 RL 论文里少见的"分布选择跟 task 物理性匹配"的案例。
- BEV 表征里 "stop sign 状态"用消失/出现编码替代 recurrent 网络——把 task-specific memory 灌进表征而非架构,省下 RNN 的训练麻烦。这种"用 representation 替代 architecture 复杂度"的工程思想在后辈论文里多次复现(GigaFlow 的 per-agent reward weight、TerraTransfer 的 per-agent persona 都是这条思路的延伸)。
- Latent dim 设计同维:\(\mathbf{j}_\text{RL}, \mathbf{j}_\text{IL}\) 都是 256 维——这件事看似工程细节,实际是 feature loss 能直接 L2 的前提。TerraTransfer 后来发现这种"全坐标对齐"其实在 fit teacher 表征的低能量尾部,于是用 SVD 子空间换掉——但 Roach 当年的选择对 CARLA 单 agent 场景刚好够用。
- 诚实的归因 ablation:换 teacher(+23 DS)、加 soft target(+13 DS)、加 feature loss(+9 DS)三段拆得清清楚楚,每个组件的边际贡献都是单变量对照。这种 ablation 设计在后续 BEV→camera distillation 类工作里被默认沿用。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 完全在 CARLA 0.9.11 里训和测——sim-to-sim transfer 而非 sim-to-real。"Roach 的 latent 对 weather/rendering 不变" 这个卖点的实证只在 CARLA 自己的 new-weather split 上验证,没真车 / 没跨 simulator 转移。这件事在 ICCV'21 时代是默认的,但后辈 (World Engine 200 km on-road, Gigapixel HUGSIM 3DGS) 之后看回去就显得弱了。
- Roach 的 BEV 里 route 是 rendered 进去的——意味着 ground-truth 导航信号被烤进了 expert 输入。Student 的 camera 没这个 channel,所以论文需要把 command one-hot 拼进 measurement vector 才能让 \(\mathcal{L}_\text{F}\) 有意义(否则 \(\mathbf{j}_\text{IL}\) 缺信息 mimic 不出 \(\mathbf{j}_\text{RL}\))。这一段在 §4.2 解释得有点拐弯,但真正暴露的是 Roach 自己的 BEV 信息泄露了导航——一个更干净的设计应该把 route 从 BEV 里抽出来同时给 teacher 和 student。
- Single-agent 训练:CARLA Autopilot 还在控制其他车,Roach 只控 ego;这意味着对 partner 行为分布的覆盖完全靠 CARLA 内置 traffic 而非 self-play 演化。这条到了 Gigapixel / Spiced / TerraTransfer 才被升级成 multi-agent self-play——Roach 那时还没这一步。
- NoCrash benchmark 的天花板:作者自己说 "如果以 Autopilot 为 upper bound,我们的方法已经 saturate 了 NoCrash"——这其实是 NoCrash 本身评测过窄。也是为什么作者后段花精力跑 CARLA LeaderBoard 的原因。但读者要注意:78% NCd-nn SR 是"NoCrash 的尽头"而不是"自动驾驶的尽头"。
- Exploration loss 在 episode 末 100 步施加先验——这件事做了一个隐含假设:失败的归因主要在末 100 步。但有些 long-horizon 失败(错过路口要在 100 步前选择不同 trajectory)这个机制是漏掉的。论文没讨论这个 boundary case。
- Value loss \(\mathcal{L}_\text{V}\) 单独用没效果——论文承认了,但"feature 和 value 互相正则"的解释是事后合理化("intuitively..."),没有 controlled experiment 区分"协同 vs 单纯 multi-task regularization"。
- Roach teacher 网络很小(6 conv + 2 FC),10M PPO 步够;但 ImageNet ResNet-34 当 student backbone 又远比 teacher 大。学生 backbone 的容量是否过剩、是否能换更轻的 backbone 论文没探索(TerraTransfer 5 年后用冻结 DINOv3 + 2 个 linear adapter 就是回答这个问题)。
- DAGGER 5 轮的成本:每轮要重新跑 student rollout、Roach 重新标注、训学生——单卡训不动。"camera-based student" 看起来便宜,DAGGER 整流程的 wall clock 其实和 Roach 自己训 RL 是一个量级。这件事在 abstract 里被淡化了。
- NoCrash-dense new-town 4 个 IL agent baseline 数字几乎都来自论文复现而非原作者 leaderboard——CARLA 0.8.4 vs 0.9.6 vs 0.9.11 跨版本对比本身就有 rendering/物理差异,作者自己也提到 0.9.11 的"after-rain puddle reflection"渲染 bug 让 baseline 蒙难。LBC / DA-RB+ 的数字是不是被这个 bug 压低了?论文没拆。
- 代码和模型都不开源 Autopilot 改造细节——论文里"我们改进的 Autopilot 性能比原版高"是关键 baseline,但 Autopilot 的具体改动只在 supplement 略提,复现门槛高。
5.3 值得继续探讨的方向¶
- 接到 multi-agent self-play teacher:Roach 单 agent + CARLA 内置 traffic,换成 multi-agent PPO(GigaFlow / Spiced 路线)能否进一步推 NoCrash SR?这正是 TerraTransfer 在做的事。
- 把 \(\mathcal{L}_\text{F}\) 的全坐标 L2 换成 batch-relational + SVD low-rank:直接套 TerraTransfer 的损失到 Roach 这套 CARLA 0.9.11 setup 上,看 5 年理论封装能带来多少边际收益。
- 真车 / 跨 simulator transfer:Roach 的 weather-agnostic latent 在 nuScenes / Waymo 真实图像上是否仍 holds?这是论文当时没做的关键空白。
- 更细的 exploration prior:不同 episode-ending event 现在用 hand-coded Beta 先验;能不能学一个 conditional prior \(p_z(a|s)\)?这是 RLHF 风格的扩展。
- Mode-collapse risk in distillation:Beta 分布 KL 蒸馏能否捕捉到 teacher 的双峰行为?还是学生最后都收敛到 single mode?这点 ablation 缺失。
- End-to-end vision RL + Roach 当 critic:现在 student 是纯 IL,能不能让 student 也跑 RL,把 Roach 的 \(V_\phi\) 当 ground-truth value 监督 student value head?混合 IL + actor-critic 是 2021 后的发展方向。
- 跨任务(操作 / 双足):Roach 的"RL coach + neural KD"配方是否能推到机器人操作?需要怎样的 privileged state 表征?
与今天 (2026-06) 四篇自动驾驶 self-play 论文的 lineage 对比¶
这是关键的"为什么再读这篇 2021 老论文"的回答:
| 设计选择 | Roach (ICCV 2021) | TerraTransfer (2606.17386) | Gigapixel (2606.19641) | Spiced (2606.19370) | World Engine (2606.19836) |
|---|---|---|---|---|---|
| RL teacher 训练域 | CARLA 单 agent | TerraZero 多 agent self-play | Gigapixel sim 多 agent self-play | PufferDrive 多 agent self-play | nuPlan 预训 + 3DGS 后训 |
| Teacher 输入 | BEV semantic image | DeepSets vector | DeepSets vector | DeepSets vector | 真实 sensor + 重建 |
| Teacher → Student 接口 | 冻 teacher,KD 蒸馏 | 冻 teacher,KD 蒸馏 | self-play DAgger (teacher 持续 rollout) | (无 student,policy 自己就吃 vector) | 直接对 policy 做 RL 后训 |
| Student 输入 | 单相机 image | 单相机 image (DINOv3) | 多相机 image (DrivoR) | (无 student) | 多相机 + 3DGS 渲染 |
| Action loss | \(\mathcal{L}_\text{K}\): KL(π_T | π_S) | \(\mathcal{L}_\text{act}\): KL(π_T | π_S) ✓ 同款 | trajectory L2 + scoring | (不蒸馏) | KL anchor + reward gating |
| Latent feature loss | \(\mathcal{L}_\text{F}\): L2 on full latent | \(\mathcal{L}_\text{struct}\): SVD low-rank batch-relational ✓ Roach 的升级版 | perceptual L2 between sim/real | (无) | (无) |
| Value loss | \(\mathcal{L}_\text{V}\): MSE on V | (丢弃) | (无) | (无) | reward shaping |
| 评测 | NoCrash + CARLA LeaderBoard | HUGSIM (closed-loop, 自定义 metric) | HUGSIM + NAVSIM-v2 | WOMD 10k val + WOSAC + Δv | nuPlan 288 rare + 华为 ADS 10k + 实车 200 km |
核心 takeaway:用户说"都是一样的思路"——精准。TerraTransfer 是 Roach 的多 agent self-play 升级版 + 把 feature L2 换成 SVD 低秩关系型损失的版本。两篇论文的 Phase 1 (RL teacher) → Phase 2 (image student via KD) 框架完全同构;2026 年的"新意"主要在: 1. RL teacher 从 single-agent CARLA 升级到 multi-agent self-play(GigaFlow 那一脉的功劳) 2. Vision backbone 从 ImageNet ResNet-34 升级到冻结 DINOv3 3. Feature loss 从全坐标 L2 升级到 SVD 子空间 cosine similarity 矩阵(Tung 2019 + Gavish-Donoho 2014 的理论封装) 4. 数据集从 CARLA 升级到 nuPlan + HUGSIM/nuScenes 跨数据集
但这三条升级是否质变?——是值得继续讨论的核心问题。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 关键 baseline / 相关论文:
- LBC (Chen 2020) — privileged teacher distillation 的 direct 前作
- CILRS (Codevilla 2019) — student 架构
- DA-RB+ (Prakash 2020) — DAGGER training pipeline
- SAM (Zhao 2020) — feature matching distillation 的前作
- Toromanoff CVPR'20 — RL reward 设计基础
- Hinton KD (2015) — soft target 思想源头
- 直接后辈:
- TerraTransfer (2606.17386) — Roach 的多 agent self-play + SVD 低秩升级版
- Gigapixel (2606.19641) — Roach 的"自家像素 simulator + self-play DAgger"变体
- Spiced Self-Play (2606.19370) — Roach 的"RL teacher + 人类 anchor"变体
- World Engine (2606.19836) — Roach 的"3DGS + BWM + RL 后训"远房表亲