World Engine: 把"后训练时代"搬进自动驾驶¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: World Engine: Towards the Era of Post-Training for Autonomous Driving
- 作者: Tianyu Li, Li Chen, Caojun Wang, Haochen Liu, Kashyap Chitta, Zhenjie Yang, Yuhang Lu, Naisheng Ye, Yihang Qiu, Yufei Wang, Luoxi Zou, Jiaxin Peng, Jin Pan, Zhaoyu Su, Andrei Bursuc, Shengbo Eben Li, Andreas Geiger, Peng Su, Hongyang Li(HKU / 华为 / Archon Robotics / 上海创新研究院 / KE:SAI / NVIDIA Research / NTU / valeo.ai / 清华 / Tübingen)
- arXiv 编号: 2606.19836 (submitted 2026-06)
- 项目页 / 代码: opendrivelab.com/WorldEngine | GitHub: OpenDriveLab/WorldEngine
- 关键词: post-training, RL fine-tuning, long-tail, behaviour world model, 3D Gaussian Splatting, closed-loop simulation, end-to-end driving, nuPlan, Huawei ADS
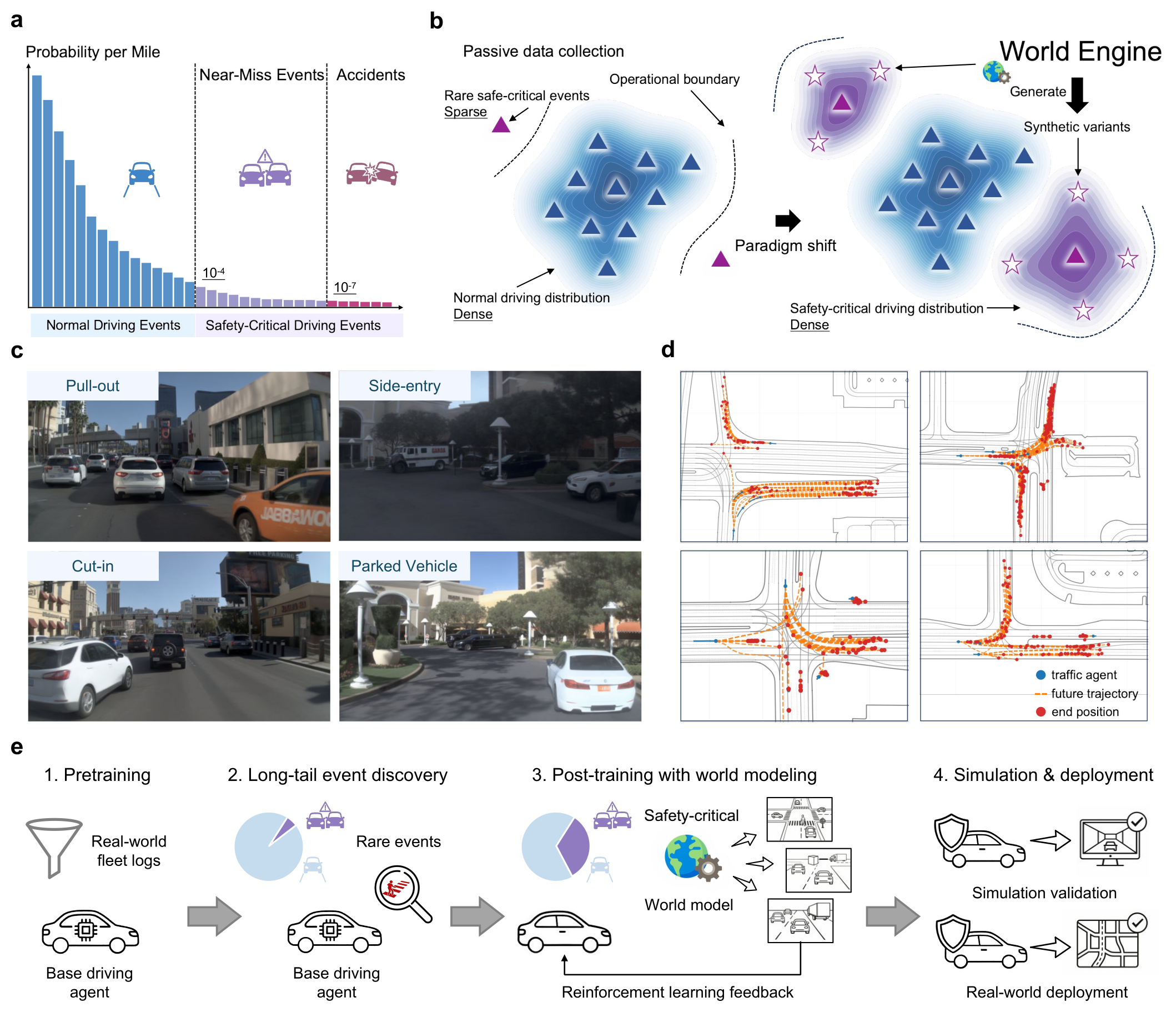 Figure 1:World Engine 的全景。a 长尾事件天然稀缺;b 从被动数据采集(密集在易例、稀疏在 safety-critical)转向"先发现失败、再合成变体、再 RL 后训"的主动后训范式;c 3DGS 渲染下同一场景的 photorealistic 变体;d 单条长尾 log 经 behaviour world model 扩展出的多条行为轨迹;e 四阶段闭环:预训练 → 长尾发现 → 世界建模 + RL 后训 → 闭环 / 实车验证。
Figure 1:World Engine 的全景。a 长尾事件天然稀缺;b 从被动数据采集(密集在易例、稀疏在 safety-critical)转向"先发现失败、再合成变体、再 RL 后训"的主动后训范式;c 3DGS 渲染下同一场景的 photorealistic 变体;d 单条长尾 log 经 behaviour world model 扩展出的多条行为轨迹;e 四阶段闭环:预训练 → 长尾发现 → 世界建模 + RL 后训 → 闭环 / 实车验证。
2. 文章介绍¶
2.1 解决的领域和问题¶
这是一篇 end-to-end autonomous driving + post-training 的工作,主题是"如何把已经预训练得很强的 E2E 驾驶策略,进一步在 safety-critical long-tail 上变得更安全"。
具体问题非常尖锐:现代 E2E 驾驶系统(UniAD/VAD/VADv2 系,以及华为 ADS 这类大规模产线)在常态场景上已经接近人类,但操作安全边界由 long-tail 决定——突如其来的行人横穿、激进的 cut-in、复杂的多 agent 博弈。这些事件在 fleet log 里统计上稀缺,而 fleet 没法以"出现事故"的方式去主动采集它们。结果是:最有价值的学习信号系统性缺席于自然数据。
2.2 Motivation¶
作者借用 LLM 的发展曲线作为类比:
- pre-training 时代:scaling law 给广义能力(语言流畅、常识、世界知识 ↔ 驾驶里 millions of km 的车队数据给常态驾驶能力);
- post-training 时代:在 narrow but consequential 的能力上(数学多步推理、code、obey instruction ↔ 驾驶里 safety-critical interactions)靠 prompt + RL + 合成数据补齐。
文中用 DeepSeek-R1、AlphaProof 作为 LLM 侧"用 synthesized reasoning 突破 pre-training 不足"的范例,论证 autonomous driving 已经到了同样的拐点:被动加量回报递减(scaling pre-training 在 rare cases 上饱和),下一阶段必须主动合成 + RL 后训。
更深一层 motivation:自动驾驶的不可逆性(错误 = 物理伤害)让 "fail fast in the real world" 这条 RL 的常规路径在物理世界走不通,必须把交互式探索移到 high-fidelity simulation 里。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 本文眼中的局限 |
|---|---|---|
| Scaling pre-training | nvidia2025e2escaling, waymo2025motionscaling | 在 common cases 上有 scaling law,rare cases 上饱和;扩 10× 才能换 World Engine 一次后训的收益 |
| 模块化栈 + 重新标注(data engine) | Tesla AI Day / Scale AI / 各家 data flywheel | 主要解决感知 coverage,多在 open-loop 设置下,不捕获 policy 行动的因果后果 |
| 神经渲染 / 闭环 simulator | UniSim, ReSim, MagicDrive, Bench2Drive | 多用于 verification / stress test,生成的 scenario 没和 policy 当前弱点耦合,behaviour generation 与 policy evolution 解耦 |
| 现有 post-training | RecogDrive, iPAD, DiffusionDrive v2, RawDrive, IRL-VLA, Think2Drive | 依赖 full-policy update、dense reward design、heavy online interaction,容易破坏预训练先验、过拟合特定 simulator |
| 手工设计的 corner case | CARLA scenario libraries, NCAP procedures | 物理可信但 distribution 由人工想象决定,覆盖不到"真实 log 里发生过但稀缺"的复杂交互模式 |
2.4 论文解决方案(一句话)¶
从真实 driving logs 出发,用 pre-trained agent 作探针找出失败前兆 → 用 3DGS 把每个失败场景重建成 photorealistic interactive scene → 用 diffusion-based behaviour world model 把 traffic 扩展成成百上千个 reactive counterfactual variants → 在这上面跑 behaviour-regularized RL post-training(KL 锚 + 真 log 混合)来"补 long-tail",全过程不触碰物理世界。
2.5 与前序工作的关系¶
- 基座 E2E 模型 直接继承 BEVFormer + UniAD 风格的栈:ResNet-50 + FPN → 6 层 BEVFormer encoder → planning decoder(VADv2 风格 vocabulary scoring)+ tracking / mapping decoder,58.3M 参数。换言之,paper 不在感知架构上 claim novelty,把它当 commodity backbone 用。
- 3DGS 重建:基于 kerbl20233dgs + MTGS(li2025mtgs),加 scene graph 分离静/动 + LiDAR 监督 + per-camera affine 颜色矫正 + flatten / OOB 正则。
- Behaviour world model:DiT 风格 diffusion,延续 Nexus / Omega 系(zhou2025nexus, li2025omega)的 vectorized scenario diffusion,但新增 decoupled triaxial noise masking(agent × time × denoising step 三轴独立 noise level)以同时具备 goal-following 和 reactivity(详见 §3.3)。
- RL post-training:标准 KL-regularized policy improvement(OFFLINE-flavored),关键是 experience mixture:\(p(\tau)=(1-\alpha)p_{\text{real}}+\alpha p_{\text{sim}}\)。
- 评测 metric:开环用 NAVSIM 的 PDMS;闭环用作者新引入的 PDMS*(用 human GT 替换 PDM-Closed 上界、并在反应式 traffic 下重打分)。
3. 方法介绍¶
整体是 4 阶段闭环(Fig. 1e):(1) pre-train + long-tail 发现,(2) Simulation Engine,(3) Behaviour World Model,(4) Reinforcement post-training。
3.1 形式化¶
驾驶任务建模为 POMDP \(\{\mathcal{O},\mathcal{S},\mathcal{A},r,\gamma\}\) over horizon \(T\):observation \(o\) = 多视图相机图像,state \(s\) = ego/agents/map 状态,action \(a\) = 驾驶动作(waypoints 或 acceleration+steering)。世界转移 \(\mathcal{T}_\theta(s_{t+1}|s_t,a_t)\) 由 behaviour world model 给出,渲染器 \(\mathcal{P}_\psi\) 把 state 映回 sensor 观测,\(\pi_\text{ref}\) 是预训练策略。优化目标:
experience 分布
real log + sim rollout 的混合既保留 common 分布、又密化 rare safety-critical 区域。KL 项是"防忘"锚,避免 RL 把预训练里学到的常态驾驶能力打掉。
3.2 Stage 1 — Long-tail Event Discovery(基座模型作探针)¶
不是手设 scenario,也不是从噪声里幻想,而是把预训练 agent 自己当 diagnostic probe:
- 用 imitation learning 在大规模 log 上 pre-train 一个 base E2E agent;
- 对每条 logged scenario,让 base agent 给出 planned trajectory;
- 在一个 轻量级 box+map 仿真器 里执行 non-reactive rollout(其他 traffic 按 log 回放,不反应);
- 凡是 ego 撞上 logged objects 或开出可行区的 scenario 就被标记为 safety-critical ——这等于"agent 当前能力边界"的明确画像。
两个好处作者明说:(a) 选出来的 scenes 全部 grounded in real sensor data 和 real traffic,物理合理性兜底;(b) 标记规则就是"base policy 失败的地方",直接对齐 post-training 收益最大的区域。
nuPlan 实验里:base 在 navtrain_50pct(51k 场景)pre-train 后,挖出 5,340 个 long-tail 场景;这 5,340 个再被 World Engine 扩展成 31,508 frames 作为 RL 的 sim experience。华为 ADS 上:从 80,000 小时数据里产 1.0M World Engine 合成 clip,再和 5.0M common clip 混合。
3.3 Stage 2 — Simulation Engine(3DGS 重建 + 可控渲染)¶
3.3.1 Scene representation¶
每个驾驶 clip 表示为 anisotropic 3D Gaussians \(\mathcal{G}=\{G_i\}_{i=1}^N\),\(G_i=\{\mathbf{x}_i,\mathbf{q}_i,\mathbf{s}_i,\alpha_i,\boldsymbol{\beta}_i\}\)(位置 / 四元数旋转 / 各向异性尺度 / 不透明度 / SH 颜色系数)。Scene graph 把静态背景 \(\mathcal{G}_\text{static}\) 和动态前景 \(\mathcal{G}_\text{dyn}\) 拆开——这是后续"挪车 / 删车 / 改轨"的关键:操作动态对象不破坏背景渲染质量。
3.3.2 重建 pipeline 细节¶
- Clip 抽取:以 key frame 为中心取 3 s 历史 + 8 s 未来,10 Hz;若 50 m 内开不完则延伸到 50 m 或 log 末尾。
- 冗余降采样:长时间低速 / 停车段去重;时空相邻 clip 合并联合重建。
- 图像 undistort:OpenCV optimal undistortion 保 FOV,渲染再 distort 回去对齐原始像素。
- Appearance modelling:两段式光度校准 —— LiDAR-guided exposure alignment(projected LiDAR 点颜色跨视一致)+ 每相机 affine(channel-wise scale + bias)联合优化。
- 几何监督:稀疏 LiDAR 深度走 inverse-depth loss \(\mathcal{L}_\text{depth}=|1/d_\text{pred}-1/d_\text{LiDAR}|\);patch-wise NCC 改善局部一致性;伪法线 + TV 正则;scale 退化用 flattening loss;transient 出界用 oob loss。
- 总 loss:\(\mathcal{L}=\lambda_r\mathcal{L}_1+(1-\lambda_r)\mathcal{L}_\text{SSIM}+\lambda_\text{depth}\mathcal{L}_\text{depth}+\lambda_\text{NCC}\mathcal{L}_\text{NCC}+\lambda_\text{normal}\mathcal{L}_\text{normal}+\lambda_\text{flatten}\mathcal{L}_\text{flatten}+\lambda_\text{oob}\mathcal{L}_\text{oob}\)。
3.3.3 Free-viewpoint 渲染 = 闭环必备¶
3DGS 的关键属性:一旦重建出来,任意 camera pose 都能实时渲。这是闭环 simulation 的硬要求——ego 走 novel trajectory、其他 agent 被 behaviour model 改轨之后,sensor 观测必须能跟得上。文中称 reconstruction 能扛 12,862 个 asset 全量重建(覆盖 navtrain split),用 PSNR / SSIM / depth \(\delta_1\) 报告稳定性。
3.4 Stage 3 — Behaviour World Model(diffusion-based reactive traffic)¶
3.4.1 表征¶
- Agent tensor \(\mathbf{x}\in\mathbb{R}^{A\times\mathcal{T}\times D}\):每个 agent 在每个时间步的 \([x,y,\sin\alpha,\cos\alpha,v_x,v_y,l,w]\);
- Map tensor \(\mathbf{c}\in\mathbb{R}^{L\times N\times D'}\):\(L\) lanes、每 lane \(N\) 点、\(D'\) 个属性(坐标 + 类型);
- 用 valid mask \(\mathbf{m}\) 标 agent 出现/消失;输入前 z-score 归一化。
3.4.2 Decoupled triaxial noise modelling(核心新意)¶
传统 trajectory diffusion 是"全序列同步加噪声"——擅长 goal orientation(能 condition 在一个未来意图上),但不擅长 reactivity(不能边走边接 ego 的新动作)。Autoregressive next-token 反过来——reactive 但不会 follow 长 horizon 意图。
作者的做法:让每个 token 的 noise level 独立——\(\mathbf{k}=[k_{a,\tau}]\in(0,1]^{A\times\mathcal{T}}\),agent × time 两个轴都允许不同程度的"soft mask"。训练目标:
采样时:把"历史"和"goal"设低 noise(保留),把"中间未来"设高 noise(要去噪)——一次去噪同时拿到 goal-following 和帧级 reactivity。这等价于把 prefix decoding + goal conditioning 缝进 diffusion 训练目标里。
3.4.3 Classifier guidance 三件套(人类驾驶 prior)¶
去噪每一步用三个 rubric 当 sampling-time guidance,无需 retrain:
- Collision avoidance:bbox 相交时沿中心连线对推开,\(\mathbf{x}_\text{loc}\leftarrow\mathbf{x}_\text{loc}+\lambda_t\sum_{i\neq j}\mathbb{I}\{B(\mathbf{x}_i)\cap B(\mathbf{x}_j)\neq\varnothing\}\cdot\hat{\mathbf{d}}_{ij}\);
- Comfort:用二阶差分估纵/横加速度并平滑(adjacent points 平均),减抖;
- On-road:偏离最近 lane center \(>d_\text{th}\) 时往中心线拉。
3.4.4 Inference:Scenario Copy + Intent Attack¶
- Scenario Copy:在 10 m 内挑相关 agents,把它们 goal 在原 endpoint 附近做半径 1 m 圆内 uniform 扰动 \(G_\text{new}=G_\text{original}+\delta\),再 condition 生成完整 trajectory。保留交互模式,引入行为多样性。
- Intent Attack:在 ego 的 \(K=3\) 最近邻里随机选一个"adversary",把它的 goal 强制设到 ego goal 附近 (\(|\epsilon|\leq\Delta\), \(\Delta\sim 1\)–\(2\) m),强制制造 cut-in 类对抗。这是文中产 safety-critical variants 的主力机制。
- 后处理:LQR tracker 修动力学不合理 → 双检验(agent 初始无不可避碰撞 + drivable area 合法)→ 入库。
- 迭代:每个 seed scenario 跑到 \(N=10\) 验证通过 或 连续失败 \(F=30\) 次,dual termination。
并存的 backup 模式:log replay、IDM、learned BWM,可在一个 scenario 内混用(部分 agent 走 BWM、部分 replay)。
3.5 Stage 4 — Reinforcement Post-training¶
3.5.1 数据 sampler(hierarchical mixture + curriculum weighting)¶
source \(u\in\mathcal{U}\)(real fleet log、user data、disengagement 触发、offline mining、counterfactual rollout)× semantic category \(c\in\mathcal{C}\)(interaction、driving style、manoeuvre)按层级混合:
每条 trajectory 算 quality score 做 curriculum weighting \(w(\tau)=\text{clip}((q(\tau)-q_\text{min})/(q_\text{max}-q_\text{min}),w_\text{min},w_\text{max})\),限 rare-but-noisy 样本影响。
3.5.2 Verifiable reward modules¶
奖励拆成 乘法 gating(hard safety)× 加权和(soft preference):
| 类型 | 项 | 定义 / 权重 |
|---|---|---|
| Hard gate \(\mathcal{M}\) | No-at-fault collision \(r_\text{col}\) | 无 at-fault 撞=1.0;与静态对象单撞=0.5;与动态 agent 撞=0.0 |
| Hard gate \(\mathcal{M}\) | Drivable-area compliance \(r_\text{dac}\) | 全程在 lane / 路口 / 停车区内=1.0;否则=0.0 |
| Soft \(\mathcal{W}\) (\(\beta=5.0\)) | Ego progress \(r_\text{prog}\) | 沿 route centerline 距离 / PDM-Closed 给的安全上界,clip 到 [0,1] |
| Soft \(\mathcal{W}\) (\(\beta=5.0\)) | Time-to-collision \(r_\text{ttc}\) | 二值:常速外推下最小 TTC > 1.0 s = 1.0;否则 0.0 |
| Soft \(\mathcal{W}\) (\(\beta=2.0\)) | Comfort \(r_\text{comf}\) | 二值:加速度 / 横向加速度 / steer rate 全在人类舒适阈内 = 1.0;否则 0.0 |
设计要点:乘法 gating 保证安全违规直接清零总分,与 soft objectives 解耦;progress 和 TTC 等权防止 agent 走向"原地不动"或"硬冲过去"两个退化解。
3.5.3 Hard experience mining¶
不是把 rollout 里所有 frame 平等地塞进 update,而是只挑当前 policy 表现 failure / near-failure 的 frame:imminent collision、off-road departure、large deviation from human driving。监督被集中在"改进最有杠杆"的瞬间。
3.6 Base E2E driving model(用什么策略被 post-train)¶
academic 实验:surround-view 8 摄像头 × 4 时间帧 → ResNet-50 + FPN → 6 层 BEVFormer encoder → 6 层 planning decoder(VADv2 vocabulary scoring)+ 并行 tracking / mapping decoders;58.3M 参数。Pre-train 在 8× H100 上分两阶段:感知 40 epoch / 164 h → planning 8 epoch / 15 h。Post-train 11 h / 8 epoch。
production 实验(华为 ADS):10 摄像头 + 融合 LiDAR + radar + GPS + IMU,80,000 小时驾驶数据、>10M 段 25 s clip,Ascend 910B NPU 上预训 40,000 NPU-h、后训 15,000 NPU-h,部署到 AITO M9 实车做 200 km 实路。
3.7 闭环 simulation 平台细节¶
- 状态:privileged \(s_t\) 含 ego + traffic + 路网 + 信号灯;渲染表征预部署预缓存;
- 控制器:planner 出 waypoint → LQR 追踪 → 自行车模型 \(x_{t+1}=x_t+v_t\cos\psi\Delta t\) 等;
- traffic mode:log replay / IDM / BWM 三选一或并存(闭环 default IDM);
- 终止:碰撞 / 偏离 / 规则违反 / 路线完成 / 时长上限;
- 分布式:simulation worker 推状态+渲染,inference worker 异步 batch policy;
- 吞吐:8× H200,11.59 scenarios / min,每个 scene 11 步(3 历史 + 8 planning);
- 每步成本拆解:state advance 6–9%、3DGS rendering ~15%、E2E model inference ~78%。瓶颈是 policy 推理,不是渲染。
4. 结果对比¶
4.1 nuPlan 安全关键闭环(核心实验,288 rare cases)¶
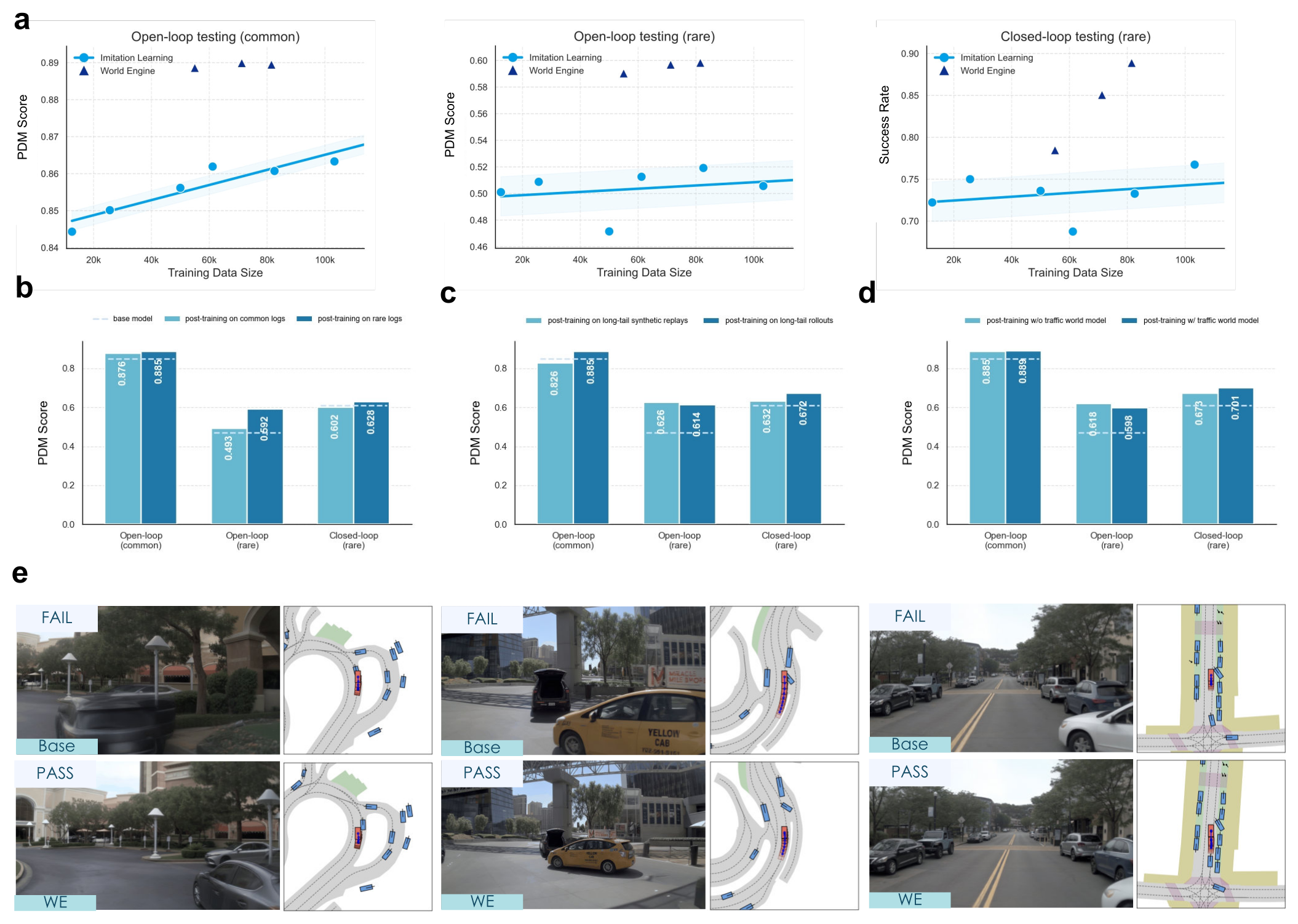 Figure 2:World Engine 在 nuPlan 安全关键基准上的核心结果。a Pre-training scaling:common cases 涨得稳,rare cases 在 ~50k 后饱和;50k 起跳的 World Engine 后训直接超过 100k 预训,按 trend 外推相当于 ~14× 更多预训数据;b rare-event log 后训 > common log 后训;c rare rollout > rare 合成 replay(封闭交互体验比静态回放更值);d 加 BWM 把 rare 闭环 PDMS 从 0.673 推到 0.701。*
Figure 2:World Engine 在 nuPlan 安全关键基准上的核心结果。a Pre-training scaling:common cases 涨得稳,rare cases 在 ~50k 后饱和;50k 起跳的 World Engine 后训直接超过 100k 预训,按 trend 外推相当于 ~14× 更多预训数据;b rare-event log 后训 > common log 后训;c rare rollout > rare 合成 replay(封闭交互体验比静态回放更值);d 加 BWM 把 rare 闭环 PDMS 从 0.673 推到 0.701。*
主表 Table 1(base = 50k 预训):
| Method | Open-loop PDMS (common) | Open-loop PDMS (rare) | SR (rare) | EP (rare) | PDMS* (rare) |
|---|---|---|---|---|---|
| base model | 85.64 | 47.14 | 73.66 | 46.71 | 60.98 |
| SFT on rare logs | 87.50 | 52.55 | 74.51 | 47.59 | 61.87 |
| post-train on common logs | 87.69 | 49.36 | 69.63 | 51.02 | 60.21 |
| post-train on rare logs | 88.51 | 59.20 | 73.35 | 51.86 | 62.78 |
| post-train on rare synthetic replays | 82.61 | 62.69 | 87.20 | 32.49 | 63.22 |
| post-train on rare rollouts w/o BWM | 88.53 | 61.88 | 77.96 | 56.74 | 67.33 |
| post-train with World Engine (full) | 88.95 | 59.83 | 88.89 | 47.66 | 70.12 |
关键读数:
- 相对 base,full World Engine 把 rare SR +15.23 pp(73.66 → 88.89)、rare PDMS* +9.14(60.98 → 70.12);
- 相对"无 BWM 的 rare rollouts"再 +10.93 SR / +2.79 PDMS*——BWM 的 traffic 多样性确实买到了东西;
- 把 common logs 喂进去后训不仅没帮还伤了 rare 闭环(PDMS* 60.98 → 60.21)——再次说明长尾发现这一步非可有可无;
- "rare synthetic replays" SR 漂亮(87.20)但 EP 最低(32.49)—— agent 学会了用停下来换 SR,与 reactive rollout 的 56.74 形成鲜明对比,揭示"二值 SR 单独看会误导"。
4.2 Huawei ADS 产线级闭环模拟(10,000+ scenarios)¶
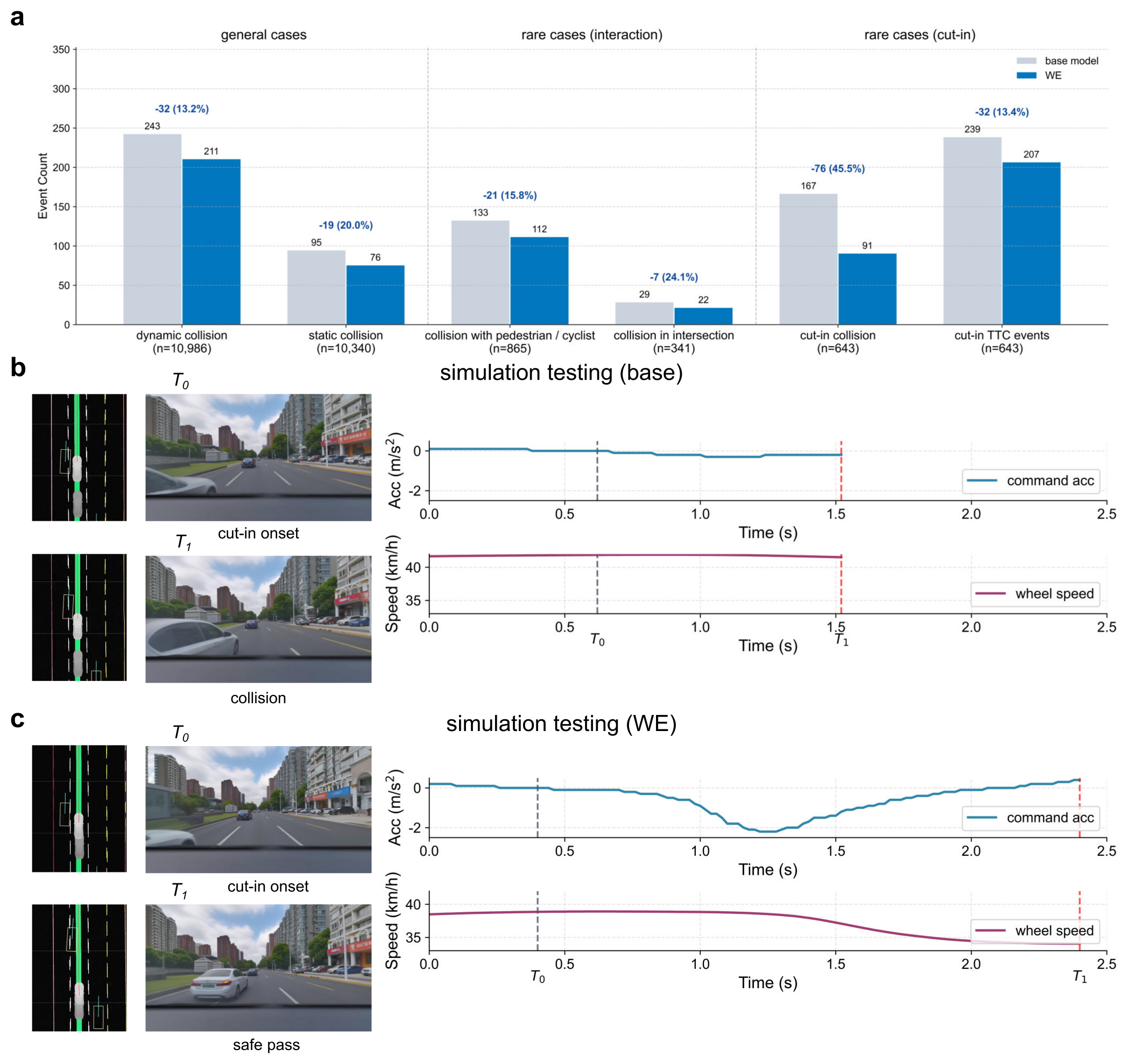 Figure 3:World Engine 在华为 ADS 产线 closed-loop simulation 上的六维安全指标。后训版相对 base 在 cut-in 撞车上降 45.5%,路口撞 24.1%,行人/骑行撞 15.8%。
Figure 3:World Engine 在华为 ADS 产线 closed-loop simulation 上的六维安全指标。后训版相对 base 在 cut-in 撞车上降 45.5%,路口撞 24.1%,行人/骑行撞 15.8%。
| Scenario 桶 | 指标 | 相对 base 变化 |
|---|---|---|
| Rare interaction (1,206 cases) | 撞行人/骑行 | -15.8% |
| Rare interaction (1,206 cases) | 路口撞车 | -24.1% |
| Rare cut-in (643 cases) | cut-in 撞车 | -45.5% |
| Rare cut-in (643 cases) | TTC 事件 | -13.4% |
| Common (10,986 cases) | 动态撞车 | -13.2% |
| Common (10,986 cases) | 静态撞车 | -20.0% |
每个 scene ~20 s、总仿真 60 h 相当于 ~3,000 km 全是交互密集场景(没拿 highway cruising 灌水),且 common 桶也跟着改善——说明 post-train 没把日常驾驶能力打掉。
4.3 200 km 实车(Shanghai,AITO M9)¶
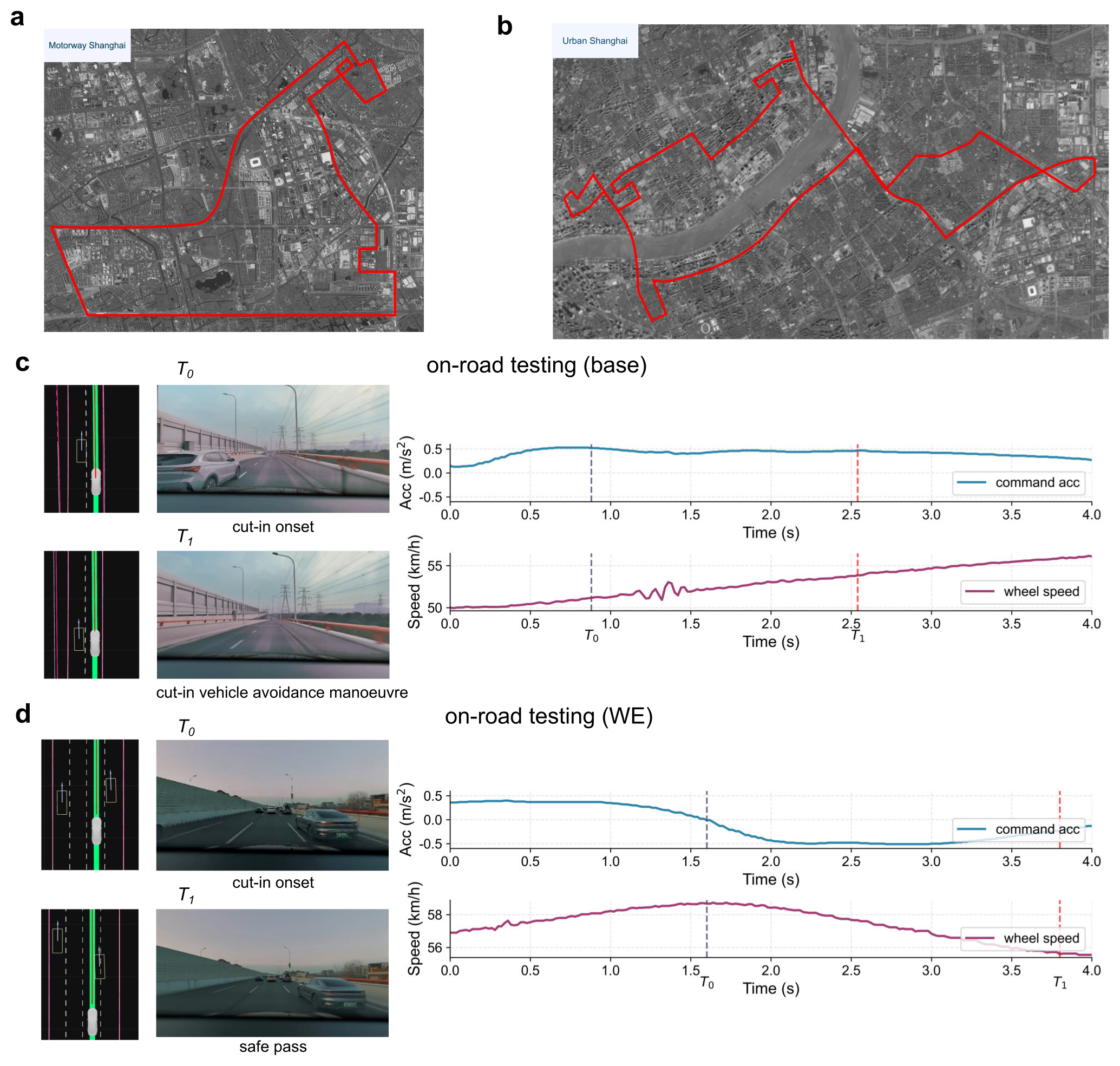 Figure 4:Shanghai 200 km 实路测试。a 65 km 城市快速/高架日间路线;b 70 km 城区夜间路线;c, d 同一类 cut-in 实况下,base 试图加速、被 cut-in 车被迫紧急回切;post-trained 早期识别并主动减速让行。这次 cut-in 是 真·非可复现 真实交互,预训语料里不可能见过。
Figure 4:Shanghai 200 km 实路测试。a 65 km 城市快速/高架日间路线;b 70 km 城区夜间路线;c, d 同一类 cut-in 实况下,base 试图加速、被 cut-in 车被迫紧急回切;post-trained 早期识别并主动减速让行。这次 cut-in 是 真·非可复现 真实交互,预训语料里不可能见过。
- 三次跑共 ~200 km,post-trained 模型 零接管 / 零 disengagement;base 触发一次 safety-critical 接管(c,d 的 cut-in);
- 作者明说:"就算 200 km 一次接管也是 production 严重失误"——因为它发生在 cut-in 这种 rare 但致命的桶里。
4.4 关键消融小结¶
- 数据来源:rare > common;rollout > replay;rare rollout + BWM > rare rollout w/o BWM(Fig. 2b–d)。
- 数据量 scaling:把 50k pre-train + World Engine 后训 vs. 把预训扩到 103k —— 前者 rare 闭环 SR 显著更高;外推预训 scaling curve,需要 ~10× 更多 real-world data 才能等价覆盖(论文文字给出 ~14× 数据点,~10× 数量级结论)。
- 基座规模:在 80k h 训出的产线 base 上,long-tail 占比比学术 base 上显著更小,但后训仍然有改进——说明 base 越强、World Engine 瞄准越窄,但 still pays off。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 用 base policy 自己当 long-tail probe,比硬挖 rare metric 更精准对齐"该练什么"。被标为 long-tail 的 5,340 个 scene 不是行业先验,而是 policy 当前能力边界的画像;这条 closed-loop 反馈即"discover where I fail"——和 Tesla 的"shadow mode + disengagement triage"一脉相承,但更便宜。
- 3DGS scene graph 把静/动分开重建,是后续可控 rendering 的 enabler。背景固定 Gaussians + 动态对象独立 Gaussians + per-frame pose calibration,让"挪车 / 删车 / 改轨"在不退化背景渲染的前提下可行;MTGS 风格的多 traversal + LiDAR 深度监督进一步给 novel pose 提供几何先验。
- Decoupled triaxial noise diffusion 同时拿到 goal orientation + reactivity。每个 (agent, time, denoising step) 一个独立 noise level,把"prefix 低噪保留 + 中段高噪去噪"统一成 single training objective;这是相对 Nexus/Omega 一类全序列同步去噪显式可控性的关键升级,对"我要 cut-in 但要响应 ego"的需求贴得很紧。
- Reward 用 hard gate × soft weighted average。乘法 gating 让 safety 违反直接清零,soft 权重在合规集合里调偏好。比"加一项 collision penalty 调权重"更稳定,也避免 reward hacking 跨向 EP / TTC 之间的退化解(progress = TTC 等权这一点作者经验性证明很关键)。
- 数据混合 + KL 锚双重正则:\(\alpha\) 控 real/sim 比例(policy-level 之外的 data-level regularization),\(\lambda\) 控 KL 离 \(\pi_\text{ref}\) 的距离。两层防忘机制让 common case PDMS 没掉(甚至从 85.64 涨到 88.95),消除"RL 后训会破坏 IL 先验"的常见担忧。
- 评测 metric 自己也升级:PDMS* 用 human GT 替代 PDM-Closed 上界、并切换到 reactive traffic,让 closed-loop 下"打分"不再被 PDM-Closed 的能力天花板绑架——这是被很多 RL 评估忽略的细节。
- Production 端把 sim 收益对齐到实车。10,000+ scene 产线闭环 + 200 km 实路三跑零接管 + base 仍触发的 cut-in 实例,三个证据链拼起来形成 "sim → industrial closed-loop → on-road" 的迁移闭环,比纯 nuPlan 上 SOTA 更可信。
5.2 做得不够好的地方 / 值得质疑的地方¶
- long-tail 发现完全依赖"已采集 log 里发生过"。如果某类危险根本没出现在 fleet log 里(极端天气、罕见路型、新车型行为),World Engine 没法发现也没法合成。作者自己在 limitations 里承认这点,但没提"补"的方案;procedural / adversarial 在 latent space 里搜似乎是必走方向,但本文未实现。
- 3DGS 偏离原 trajectory 时质量下降。作者承认:ego 显著偏离 logged path 时 novel view 会有伪影。这意味着 RL exploration 一旦走远,渲染本身就开始失真,可能给出错误梯度——文中没量化这一失真半径,也没说 reward 是否对渲染质量做了门控。
- 闭环单步 ~78% 时间在 E2E policy 推理。这不是 World Engine 的问题,但意味着真正的 RL scaling 瓶颈不在世界模型而在 policy;而论文宣传的 RL 后训只跑了 8 epoch / 11 h,到底是 base 已经足够强、还是 sample efficiency 撞墙了,文中没区分。
- 同一 5,340 scene 被扩成 31,508 frame 拿来后训——sim experience 才 ~6× 增量。所谓"接近 10× 数据"的对比,post-training 端的 token / step 总量并不大,scaling 曲线右端的"等价 ~10× 预训"是个外推论断,不是观测。
- PDMS* 是作者自己引入的 metric。虽然动机合理(reactive traffic + GT 上界),但目前没有第三方使用,和外部 nuPlan baseline 的 SOTA 不可直接对比。SR 88.89% 也是 World Engine 自己 simulator 里的 SR——换 simulator 是否还是这么高,目前未知。
- Behaviour world model 在行人 / 骑行 / 非结构化路用户上"fidelity 不足"(作者自承)。但 production 实验里 collision-with-pedestrian/cyclist 降 15.8% 的 figure 又来自这个模型生成的训练数据——存在 "用低保真模型练出高保真 metric 提升" 的逻辑张力,文中没拆开"哪部分收益来自 BWM 行人 vs. classifier guidance 把 rollout 拉离行人"。
- 多轮迭代 post-training 在 58.3M 模型上会不稳定(作者明言)。但论文同时把 World Engine 框架定义为"discover → augment → post-train"的闭环,一次性的 single-round post-training 严格说不是闭环;多轮稳定性留作 open question,意味着公开 setup 里它离 fleet-style 持续后训还有距离。
- on-road 200 km / 三次跑、N=1 接管对比。base 一次接管 vs. post-trained 零接管,统计意义脆弱;产线 sim 才是真正的强证据。论文有意把 on-road 写成"qualitative validation",但 abstract 仍然把它作为主卖点,叙事强度大于证据强度。
- 没有 latency / memory footprint 对比。post-trained 模型相比 base 在 H100 / Ascend 上的推理时间、显存、控制频率有没有变?文中没给。production 部署对这些非常敏感。
- Reward shaping 三件套是手工设的(NC / DAC / TTC / EP / Comfort)。作者承认这点。在产线规模下,一旦碰到"什么算合规"在不同城市 / 国家不一致(如让行规则、紧急车辆礼让),verifiable reward 这条路就开始捉襟见肘。
5.3 值得继续探讨的方向¶
- latent adversarial 在世界模型里搜 long-tail:把"发现"也变成可优化的(policy-aware adversary),而不是只依赖 base policy 已经失败的样本。
- video world model 取代 3DGS + BWM 解耦:作者结尾自己提到,Cosmos / sparse rendering 系视频世界模型已经接近 controllability + realism;如果一个端到端 video WM 能同时给 sensor 流和 reactive traffic,World Engine 的两段式架构有望被压成单段。
- 多轮 post-training 的稳定性:是不是要用 LoRA / adapter / 残差网络做"分层 post-training"避免破坏 main weights?iterative World Engine + EWMA-style policy averaging 值得一试。
- Reward learning:从 fleet disengagement / takeover 数据里学 reward(IRL / preference model)替代手工 NC+DAC+TTC,配合 verifiable gates 仍可保留 safety floor。
- 跨 simulator transfer:在 World Engine 训出来的策略放到 CARLA / Bench2Drive / Waymo Open Sim 上是否仍领先?这是当前 SR 数字之外更硬核的判别。
- Scaling law for post-training:把 World Engine 后训数据量 / KL 强度 / 真假 mix 比 \(\alpha\) 三个 knob 做完整 scaling 曲线,会得到比"等价 ~10× 预训"更有指导价值的实操指南。
- 从驾驶搬到操作 / 双足:作者在 Conclusion 里点了 "Towards general Physical AI"。同一 discover → world-model → post-train 范式在 robot manipulation / locomotion 上,需要怎样的 3D 重建替代品(NeRF? video WM?)和"自己当 probe"的失败模式定义?
- 后训 vs. 模型容量的权衡:58.3M 多轮不稳但有效;如果 base 是 1B / 10B 级 VLA 风格驾驶模型,World Engine 后训收益是否还成立、还是变成 marginal?这关系到自动驾驶要不要走 "VLA + 后训" 的整体路线。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页 & 代码: opendrivelab.com/WorldEngine | GitHub: OpenDriveLab/WorldEngine
- 关键 baseline / 相关工作:
- UniAD(hu2023uniad)/ VAD-v2(chen2024vadv2)/ BEVFormer(li2022bevformer)作为基座 E2E 栈
- 3DGS(kerbl20233dgs)/ MTGS(li2025mtgs)作为重建底座
- Nexus(zhou2025nexus)/ Omega(li2025omega)作为 behaviour world model 前作
- NAVSIM(dauner2024navsim)/ PDM-Closed(Dauner2023pdm)作为 metric / 上界
- DeepSeek-R1(guo2025deepseek)/ AlphaProof(hubert2025olympiad)作为 LLM 后训类比
- nuPlan(nuplan2024)数据集
- IDM(Treiber2000IDM)作为 fallback 交通模型