μ₀ (mu-zero): A Scalable 3D Interaction-Trace World Model¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: μ₀: A Scalable 3D Interaction-Trace World Model
- 作者: Seungjae Lee*, Yoonkyo Jung*, Jusuk Lee, Jonghun Shin, Amir Hossein Shahidzadeh, Yao-Chih Lee, H. Jin Kim, Jia-Bin Huang†, Furong Huang† — University of Maryland College Park¹ + Seoul National University²(*共同一作,†共同通讯)
- arXiv 编号: 2606.13769 (submitted 2026-06)
- 项目页: https://mu0-wm.github.io/
- 关键词: world model, 3D interaction trace, B-spline, flow matching, cross-embodiment manipulation, action-free pretraining, VLM backbone
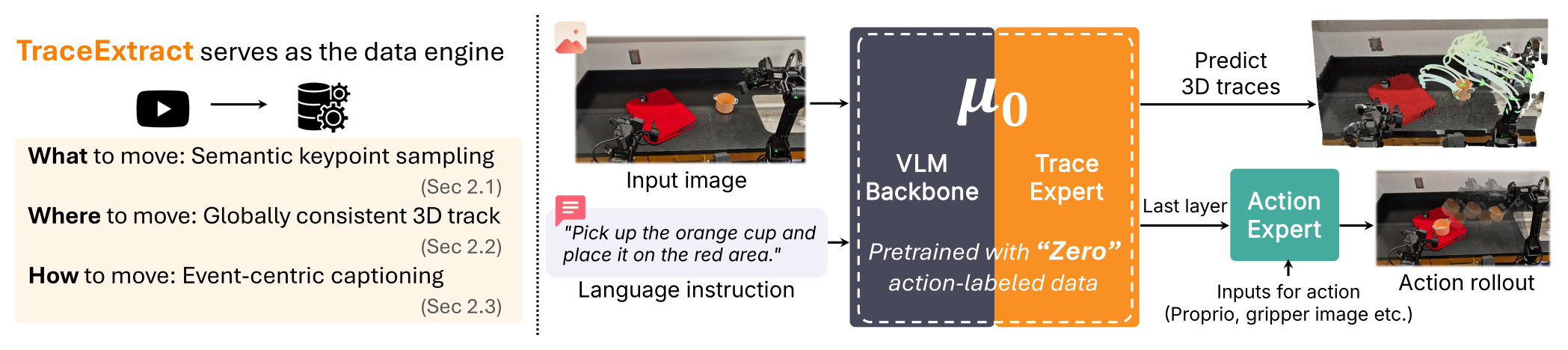 Figure 1:μ₀ 的核心范式 —— TraceExtract 数据引擎从异构视频里抽「3D 交互轨迹」监督(what/where/how to move 三问),预训练一个 VLM backbone + Trace Expert 的世界模型;它用「零」action label 预训练,冻结后接一个 Action Expert 就能产机器人动作。轨迹(trace)是介于「稠密像素」和「embodiment-specific 动作」之间的中间表示。
Figure 1:μ₀ 的核心范式 —— TraceExtract 数据引擎从异构视频里抽「3D 交互轨迹」监督(what/where/how to move 三问),预训练一个 VLM backbone + Trace Expert 的世界模型;它用「零」action label 预训练,冻结后接一个 Action Expert 就能产机器人动作。轨迹(trace)是介于「稠密像素」和「embodiment-specific 动作」之间的中间表示。
2. 文章介绍¶
2.1 解决的领域和问题¶
跨本体机器人操作(cross-embodiment manipulation)的可扩展预训练。机器人学习的根本矛盾:视频数据海量但没有动作标签,而 action-labeled 数据稀缺、昂贵、硬件绑定、本体之间不通用。World model 的思路是先从视频学动力学、再 ground 到具体机器人——但关键问题是:世界模型到底该预测什么?
- 像素空间视频生成(Cosmos 这类):可扩展,但把模型容量浪费在稠密外观和背景重建上,往往抓不住操作需要的 metric 几何、接触结构、遮挡关系。
- 直接预测动作(VLA):受限于动作标签的稀缺和本体特异性。
μ₀ 占据中间地带:预测「语义交互点」(物体部件、工具、手、接触区域)的 3D 轨迹(traces)——它紧凑地描述了「什么必须动」,且与用哪个机器人无关。
2.2 Motivation¶
motion-centric 的中间表示这几年已经有人在做(2D flow、3D flow、object trajectory),方向是对的。但现有系统有三个共性缺陷,正好对应 μ₀ 要补的三个轴:
- 欠采样 task-critical 的小区域:工具尖端、接触面这种「小但关键」的地方点太少(fixed-grid 是 area-biased 的,背景占满了 budget)。
- 物体运动和相机运动纠缠:在 local 或 2D image-space 坐标系下操作,分不开物体动还是相机动。
- 语言粒度太粗:长 demo 配 episode-level caption,缺少 event-level 的局部意图。
最接近的前作 TraceGen(同组上一篇)在三个轴上全都受限:fixed-grid trace、episode-level caption、inference 时还需要 depth 输入。μ₀ 是对 TraceGen 的全面升级。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 像素空间视频世界模型 | Cosmos, UniPi, Ctrl-World | 容量耗在稠密外观/背景上,抓不住 metric 几何与接触 |
| World-action 联合模型 | GigaWorld 等 | 同样浪费在像素生成,且仍需动作监督 |
| Latent feature 世界模型 | DINO-WM | 不可解释、不可控、难翻译成精确动作 |
| 2D track / optical flow | Any-point, Track2Act, ATM | 缺 metric depth,丢失 3D 接触和空间运动 |
| 3D flow(fixed grid) | 3DFlowAction, PointWorld | dense grid 浪费在静态背景;常需 action label 或 depth |
| 最接近:TraceGen | lee2026tracegen | fixed-grid、inference 需 depth、episode 级 caption、hand-designed trace replay,不是 reusable 的 query-conditioned 世界模型 |
2.4 论文解决方案(一句话)¶
用 TraceExtract 数据引擎把异构人/机器人视频自动转成「event-captioned 3D 交互轨迹」监督,训练一个 query-conditioned 的轨迹世界模型 μ₀(VLM backbone + permutation-equivariant Trace Expert + B-spline 目标 + semantic flow matching);预训练完全不用动作标签,冻结后接一个 Action Expert 消费它的 trace-denoising 特征,就能产出与 π₀/π₀.₅ 这类 action-supervised VLA 相当甚至更好的机器人策略。
2.5 与前序工作的关系¶
- 直接基于 TraceGen(同组前作)做全面改进:数据 pipeline(fixed-grid → 语义关键点 + 全局 3D 跟踪 + event caption + 运动过滤)、模型接口(query-conditioned B-spline flow matching)、动作消费方式(冻结特征 vs hand-designed replay)三处都重做。
- 复用大量 off-the-shelf 组件:backbone 是 SmolVLM2-2.2B(截断到前 20 层),Trace Expert 的 cross-attention 交错结构沿用 SmolVLA;数据 pipeline 里 DINOv2 抽特征聚类、VGGT 做全局-局部 3D 重建、TAPIP3D 做 3D 点跟踪、Depth Anything V2 估深度(仅给 TraceGen baseline)。
- Action Expert 直接借 π₀.₅ 的 self-attention 架构 + flow matching 产连续动作;B-spline trace 表示沿用 liu2025trace;DINO 特征注入借鉴 thakkar2026forecasting。
- 本质上是把「robot foundation model」拆成「可复用的运动先验世界模型 + 轻量本体特定 action head」,与本库的 TraceGen 系、ZPRL(小 latent steer 冻结大模型)、DeFI(forward/inverse 解耦预训练)共享「中间表示驱动跨本体迁移」的思路。
3. 方法介绍¶
μ₀ 分两大块:TraceExtract 数据引擎(§3.1,造监督)和 μ₀ 世界模型 + Action Expert(§3.2-3.5,学与用)。
3.1 TraceExtract:可扩展的跨本体数据引擎¶
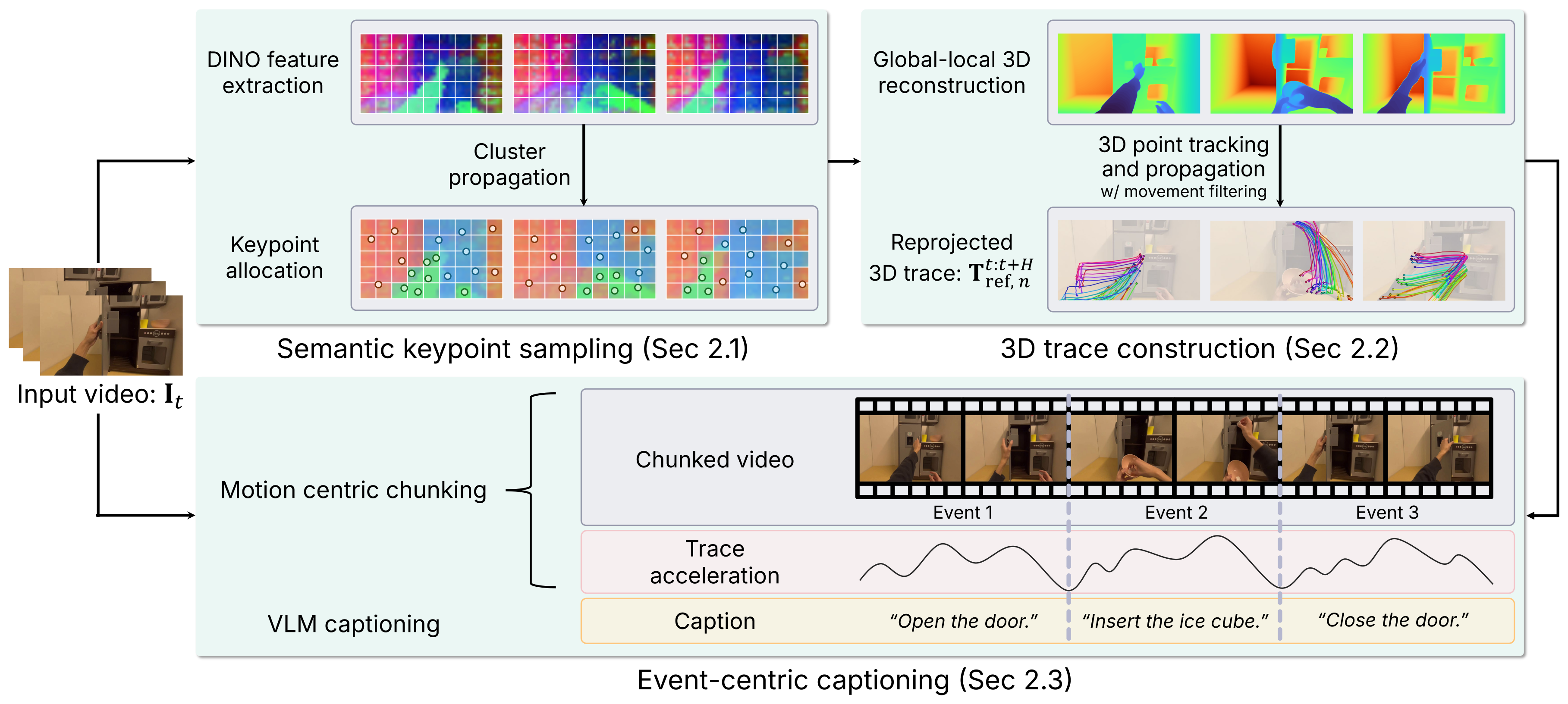 Figure 2:TraceExtract 三阶段。(1) 语义关键点采样:DINOv2 patch 特征聚成实体级 cluster、时序传播 identity、按可见 patch 覆盖分配关键点预算(小物体有最低配额),FPS 选空间多样的点 + 运动过滤剔背景;(2) 3D 轨迹构建:hybrid VGGT 全局稀疏 pass 定坐标系 + 局部 dense chunk 对齐 + TAPIP3D 渐进跟踪,reproject 回 per-chunk 参考相机得「去相机运动」的 screen-aligned 3D trace;(3) event-centric captioning:用 trace 加速度的 Savitzky-Golay 平滑找运动峰值,在低加速度谷点切 event 边界,VLM 对每段的首/中/尾帧产分层 caption。
Figure 2:TraceExtract 三阶段。(1) 语义关键点采样:DINOv2 patch 特征聚成实体级 cluster、时序传播 identity、按可见 patch 覆盖分配关键点预算(小物体有最低配额),FPS 选空间多样的点 + 运动过滤剔背景;(2) 3D 轨迹构建:hybrid VGGT 全局稀疏 pass 定坐标系 + 局部 dense chunk 对齐 + TAPIP3D 渐进跟踪,reproject 回 per-chunk 参考相机得「去相机运动」的 screen-aligned 3D trace;(3) event-centric captioning:用 trace 加速度的 Savitzky-Golay 平滑找运动峰值,在低加速度谷点切 event 边界,VLM 对每段的首/中/尾帧产分层 caption。
三个核心设计回应 2.3 的三个缺陷:
- 语义关键点采样(where to measure):不再 fixed-grid,而是 DINOv2 特征聚类成实体(物体/工具/手),按实体分配关键点预算,小物体保最低配额,FPS 保证空间多样性。运动过滤(trace diameter > 40 px 才算 moving)剔掉静态背景点,避免模型偏向「零运动」。
- 全局-局部 3D 重建(consistent 3D tracking):长视频塞不进显存且 egocentric 相机大幅运动。方案是一次全局稀疏 pass(均匀采 anchor 帧过 VGGT,定一个共享坐标系 + 单一全局内参 K,避免 chunk 边界 K 跳变)+ 多个 dense 局部 chunk,每个 chunk 直接对齐到全局 anchor(误差独立有界、不累积),TAPIP3D 用「上 chunk 最后已知 3D 世界位置」作 query 渐进跨 chunk 跟踪。最后 reproject 回 per-chunk 参考相机 → 去掉相机运动、保留图像对齐;arc-length 重参数化归一化轨迹速度,抹平人类 vs 机器人 demo 的时长差异。
- event-centric captioning(when/what intent):用 trace 加速度信号切 event(不是固定时长),VLM 对每段首/中/尾帧产结构化 caption(开始状态/交互/结束状态变化),再用纯文本 LLM 滑窗 merge 成粗粒度 task summary。
产出 tuple D = {(I_t, l_c, Q_t, T_ref^{t-h:t+H})}:观测图、event caption、query 关键点集、过去+未来 3D 轨迹。这样把 trace 数据规模扩到 TraceGen 的约 8×。
3.2 μ₀ 世界模型:query-conditioned 动力学¶
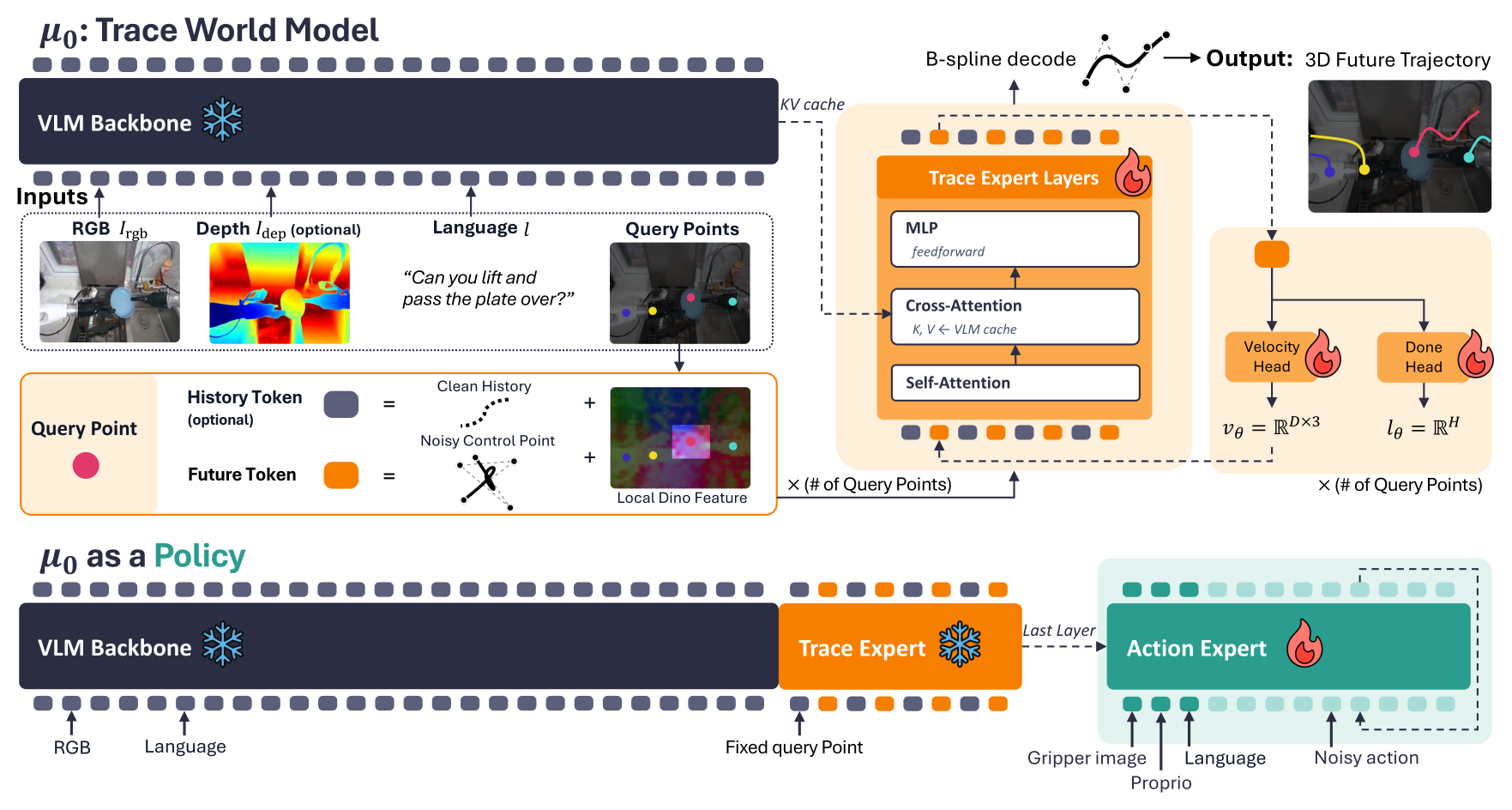 Figure 3:μ₀ 架构(上)与作为 policy 的接口(下)。VLM backbone 编码 RGB + 可选 depth + 语言;每个 query 关键点 = 一个可交换 token(B-spline query + 局部 DINO 特征 grounding);Trace Expert 用 flow matching 把噪声 control points 去噪成平滑 3D 未来轨迹,含 velocity head 和 done head。下方:冻结 μ₀,单步 partial-denoise 抽中间特征,gated cross-attention 注入 Action Expert 产动作。
Figure 3:μ₀ 架构(上)与作为 policy 的接口(下)。VLM backbone 编码 RGB + 可选 depth + 语言;每个 query 关键点 = 一个可交换 token(B-spline query + 局部 DINO 特征 grounding);Trace Expert 用 flow matching 把噪声 control points 去噪成平滑 3D 未来轨迹,含 velocity head 和 done head。下方:冻结 μ₀,单步 partial-denoise 抽中间特征,gated cross-attention 注入 Action Expert 产动作。
模型要解三个耦合挑战:semantic-metric fusion(保 VLM 先验 + 加 3D metric 推理)、query equivariance(处理变长无序的 query 集)、multi-modal dynamics(不把多解平均掉)。
多模态 conditioning backbone(§3.2):SmolVLM2-2.2B 前缀编码 RGB + 指令,Trace Expert 交错 cross-attend VLM 的 KV cache 同时保持独立 motion 流——分离「语义记忆」(VLM 保留)和「运动计算」(Trace Expert 学)。depth 是 VLM 原生输入空间之外的,所以走独立可训练 patch stem(从 RGB stem 克隆初始化),深层再和 RGB 共享 SigLIP 层,既利用几何线索又不破坏预训练 RGB 统计。
3.3 Permutation-Equivariant Trace Expert¶
- 可交换 query:每个关键点是一个独立 query,所有 query 共享同一处理栈,预测不依赖列出顺序(permutation-equivariant)。
- B-spline 目标:减去当前 3D anchor,把未来表示成 degree-3、D=10 个 control points 的 cubic B-spline(dataloader 里用 row-weighted ridge least squares 拟合,invalid 步权重置 0)。好处:紧凑(替代 dense waypoint)、平滑(抑制 tracker jitter)、易去噪(降输出维度)。decode 时一个矩阵乘
T̂ = B·P̂就还原。 - query tokenization:每个关键点的 history(h=8)和 noisy future controls 各 1 个 token,加 segment embedding(history vs future)、当前像素位置的 Fourier embedding、和双线性采样的局部 DINO 特征(注入 part-level 语义)。RoPE 位置全 pin 到 prefix 末尾,所有时空信息走 additive embedding,保持关键点轴可交换。
3.4 Semantic Flow Matching¶
未来运动有不确定性(多路径满足同指令、轨迹可能被遮挡截断),deterministic regressor 会把多解平均掉。所以 Trace Expert 用 conditional flow matching 在 control-point 空间去噪:
flow time 通过 adaLN-Zero 在每层注入(零初始化,初始即 identity)。三项损失:
- L_flow:masked MSE,只在 valid 关键点上算。
- L_done:validity head 预测每步是否有效(遮挡/track loss),inference 时给 stop index 冻结轨迹尾部。
- L_rig(semantic rigidity):同一 DINO cluster 内的关键点对,control point 间的两两距离应跨序列不变(鼓励保局部几何刚性)。关键点:TraceGen 那类刚性损失靠 ground-truth segmentation mask(只在仿真有),μ₀ 用 TraceExtract 的 DINO cluster identity 当 part label,真实视频里也能用。
inference 用 4-step Euler 在 τ∈[1,0] 积分。
3.5 Trace-Conditioned Action Expert¶
预训练完冻结整个 μ₀(VLM backbone + Trace Expert),只训一个 Action Expert:
- 不要完整 rollout:从纯噪声 control points 出发,只跑 4-step Euler 的单步(partial denoising),抽 Trace Expert 中间 hidden state 作 motion descriptor
z_trace。 - gated cross-attention 注入:
z_guided = z + σ(g)·CA(Q=LN(z), K=V=投影后的z_trace),gate g 零初始化 → 起步是弱运动注入、有益才增强,不破坏 VLM 表示。 - Action Expert 用 π₀.₅ 的 self-attention 架构 + flow matching 产连续动作 chunk,额外输入 gripper-camera 图(DINOv2 编码)、proprioception、语言。
3.x Implementation Details¶
| 项目 | 数值 |
|---|---|
| Backbone | SmolVLM2-2.2B,截断前 20 层文本 decoder(RGB 的 VLM + SigLIP tower 冻结) |
| Trace Expert | 20 层,hidden width 0.5× VLM,每 2 层交错 cross/self-attention |
| 主模型规模 | 2.59B(scaling 还测了 342M / 568M) |
| 输入分辨率 | RGB + depth 都 resize 512×512 |
| B-spline | degree-3,D=10 control points,history h=8,future H=32 |
| flow inference | 4-step Euler;Action Expert 只用单步 partial denoise |
| 训练 | AdamW lr=1e-4,VLM 参数组 0.1× 学习率;2×10⁵ 步,有效 batch 24(2 GPU × 6),grad ckpt |
| 每样本关键点数 N | 从 [1, 256] 均匀采样 |
| 训练 dropout | history 全丢 0.2 / 各自独立丢 0.3;depth 丢 0.7(强制能 fallback 到纯 RGB) |
| trace prediction 延迟 | 0.29s(A6000),比次快 2D baseline Track2Act 0.85s 快 2.9× |
| Action Expert 训练 | RoboCasa365 4×L40S,50k 步,batch 32;真机 UR3 6k-8k 步 |
4. 结果对比¶
4.1 2D / 3D 轨迹预测质量(核心 world-model 能力)¶
只在 moving points 上算 ADE / FDE / DTW,top-1 和 top-5(多采样)。
| 维度 | 方法 | top5-ADE (T=8/16/32) ↓ | top5-DTW (T=8/16/32) ↓ | 延迟 |
|---|---|---|---|---|
| 2D | Gemini-3.1-pro | 0.161 / 0.232 / 0.253 | 0.152 / 0.208 / 0.224 | 78s† |
| 2D | Hamster | 0.178 / 0.239 / 0.256 | 0.170 / 0.220 / 0.233 | 14.4s |
| 2D | Track2Act | 0.190 / 0.262 / 0.293 | 0.181 / 0.245 / 0.270 | 0.85s |
| 2D | μ₀ (Ours) | 0.124 / 0.188 / 0.227 | 0.114 / 0.171 / 0.211 | 0.29s |
| 3D | 3DFlowAction | 0.531 / 0.605 / 0.630 | 0.529 / 0.600 / 0.623 | 3.38s |
| 3D | Dream2Flow‡ | 0.201 / 0.286 / 0.336 | 0.198 / 0.281 / 0.329 | 106.8s |
| 3D | TraceGen‡ | 0.208 / 0.276 / 0.325 | 0.204 / 0.262 / 0.299 | 1.20s |
| 3D | μ₀ (Ours) | 0.132 / 0.199 / 0.239 | 0.127 / 0.187 / 0.223 | 0.29s |
†=API 延迟;‡=需 depth 输入。μ₀ 在 3D 所有指标全部最优,2D 的 top-5 全部最优(top-1 与强 VLM baseline 持平)——说明它的多采样轨迹里含更准的 goal-directed 未来。注意 baseline 里塞了 Gemini-3.1-pro / GPT-5.5 这类大 VLM,它们 top-1 偶尔略好但延迟是几十秒级。
4.2 RoboCasa365 仿真(8 任务,下游动作生成)¶
所有预训练方法都冻结 backbone、只 finetune action expert。
| Task | DiffusionPolicy (无预训练) | π₀ (action-labeled) | π₀.₅ (action-labeled) | TraceGen (video-only) | μ₀ (Ours, video-only) |
|---|---|---|---|---|---|
| CloseFridge | 34 | 44 | 34 | 38 | 54 |
| OpenFridge | 28 | 12 | 26 | 36 | 18 |
| CoffeeServeMug | 28 | 34 | 48 | 42 | 36 |
| PickPlaceFridgeShelfToDrawer | 28 | 30 | 66 | 30 | 40 |
| TurnOnMicrowave | 0 | 2 | 12 | 0 | 4 |
| SlideToasterOvenRack | 48 | 46 | 76 | 28 | 56 |
| PickPlaceCounterToCabinet | 6 | 18 | 54 | 0 | 12 |
| TurnOnToasterOven | 10 | 16 | 20 | 10 | 22 |
| 平均 | 22.75 | 25.25 | 42 | 23 | 30.25 |
μ₀ 平均 30.25%,超 π₀ 5 个点、超 TraceGen 7.25 点,但明显落后 π₀.₅(42%)。作者辩护:π₀.₅ 享受大规模 action-labeled 预训练,比较非 data-matched。
4.3 真机 UR3(3 任务,各 20 rollout)¶
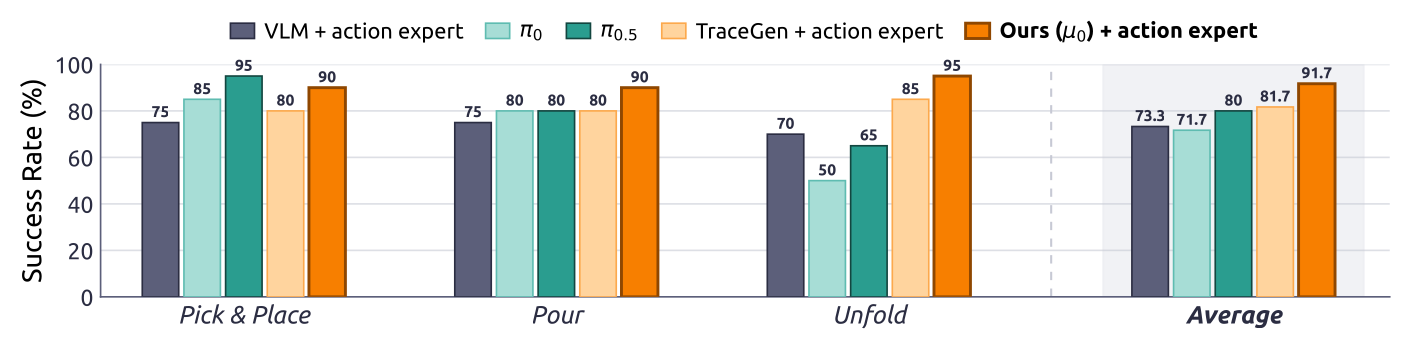 Figure 4:真机三任务成功率。μ₀ 平均 91.7% 最高,尤其 Unfold Towel(变形物,几何难)上 95% 大幅超 π₀(50%)/π₀.₅(65%)。「VLM + action expert」是去掉 trace expert 的同架构 ablation,落后 μ₀ 18.4 个点。
Figure 4:真机三任务成功率。μ₀ 平均 91.7% 最高,尤其 Unfold Towel(变形物,几何难)上 95% 大幅超 π₀(50%)/π₀.₅(65%)。「VLM + action expert」是去掉 trace expert 的同架构 ablation,落后 μ₀ 18.4 个点。
| 任务 | VLM+AE | π₀ | π₀.₅ | TraceGen | μ₀ (Ours) |
|---|---|---|---|---|---|
| Pick & Place into Sink | 75 | 85 | 95 | 80 | 90 |
| Pour Almonds | 75 | 80 | 80 | 80 | 90 |
| Unfold Towel | 70 | 50 | 65 | 85 | 95 |
| 平均 | 73.3 | 71.7 | 80 | 81.7 | 91.7 |
真机上反超 π₀ (+20)、π₀.₅ (+11.7)、TraceGen (+10)。注意这里仿真和真机的结论不一致(仿真 π₀.₅ 赢,真机 μ₀ 赢)。
4.4 Scaling 与关键消融¶
模型/数据 scaling(top5-DTW,越低越好):342M→568M→2.59B 单调变好(0.143/0.205/0.240 → 0.127/0.187/0.223);数据 5%→20%→100% 也单调变好。
Action-head scaling(最有信息量):
| Action head | w/o Trace | μ₀ + AE | gap |
|---|---|---|---|
| 200M | 10.675 | 25.625 | +14.95 |
| 400M | 28.25 | 30.25 | +2.0 |
→ action head 越小,trace 特征带来的增益越大:说明 trace 预训练提供了「有限策略容量无法自己恢复」的运动结构。
设计消融(top5-DTW):去 B-spline(用 raw trace)退化最狠(0.127→0.156),去 DINO 特征、去 rigidity loss 各有退化。有趣的是 w/o Depth & Trace history(0.127/0.187/0.223)= Full μ₀,而加 depth+history 反而更好(0.107/0.160/0.203)——主表汇报的「Full μ₀」其实是没用 depth 和 history 的版本,靠 training dropout 让它能纯 RGB 跑。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 「3D trace 作中间表示」这个 altitude 选得准。像素世界模型烧容量在外观、VLA 受困于 action label——trace 恰好是「what must move」的紧凑 embodiment-agnostic 描述。而且它是显式可解释的(不像 DINO-WM 的 latent),又带 metric depth(不像 2D track),又稀疏 query(不像 fixed-grid 3D flow)。三个轴的取舍都站得住。
- 全局-局部 3D 重建的「直接对齐 anchor」是真 engineering insight。每个 chunk 直接对齐到同一组全局 anchor 而非对齐前一个 chunk → 误差独立有界、不累积。这是长视频 + egocentric 大相机运动下能做出全局一致 3D 轨迹的关键,比 sequential alignment 干净得多。
- rigidity loss 用 DINO cluster 替代 GT segmentation mask,把一个原本只在仿真可用的正则项搬到了真实视频。这是「让真实视频可监督」的实际贡献,不是花架子。
- B-spline 目标的消融最干净(去掉退化最大),且它同时解决紧凑性 + 平滑性 + 降维易去噪三件事,control points 还能一个矩阵乘解码。是个 well-motivated 的设计而非堆砌。
- Action-head scaling 表是全文最有说服力的证据:trace 特征的增益随策略容量减小而放大(200M head 上 +14.95),直接证明 trace 预训练注入了「容量受限策略学不出来」的运动结构,而不是「换个特征也差不多」。
- partial-denoising 单步抽特征:Action Expert 只跑 1 步 Euler 抽中间 hidden state,避免完整 rollout 的开销,又保留任务相关动力学。配 gated cross-attention(gate 零初始化)的渐进注入,工程上稳。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 预训练数据集从头到尾没被命名。全文只说「heterogeneous human and robot videos」「scaling 8× over TraceGen」,但具体用了哪些视频数据集(DROID? Ego4D? EPIC? Something-Something?)、多少小时、多少条轨迹、人/机器人比例——LaTeX 正文和 appendix 里全部缺失。这对一篇主打「scalable data engine」的论文是致命的可复现性黑洞。「8×」是相对量,绝对规模未知。
- 仿真和真机结论矛盾且都不强。仿真 μ₀(30.25%)被 π₀.₅(42%)甩开近 12 个点,作者用「non-data-matched」搪塞;真机却反超 π₀.₅ 11.7 点。两个结论打架,更可能是真机只有 3 个任务 × 20 rollout、且都是 in-distribution(无泛化测试),统计噪声大 + 任务选择有利。Unfold Towel 上 π₀ 只有 50% 很可疑——这更像 baseline 没调好而非 μ₀ 强。
- RoboCasa 单任务方差极大、平均掩盖了不稳定。μ₀ 在 OpenFridge 上 18 反而低于无预训练的 DiffusionPolicy(28)和 TraceGen(36),PickPlaceCounterToCabinet 上 12 也远低于 π₀.₅ 的 54。8 任务里 μ₀ 只在 2 个拿第一,「平均超 π₀」是被 CloseFridge/SlideToasterOvenRack 拉起来的,鲁棒性存疑。
- 「video-only / action-free」的旗号有水分。预训练确实没用 action label,但 TraceExtract 重度依赖一整条重型感知栈:DINOv2 + VGGT + TAPIP3D + 一个 VLM 做 caption + LLM 做 merge。这些模型本身都在大规模(含动作相关)数据上训过,监督信号是「蒸馏」出来的而非凭空。而且 limitation 自承「inherits errors from the perception stack」——trace 质量上限被这堆现成模型钳死。
- 主表的「Full μ₀」其实关掉了 depth 和 trace history。消融表显示 w/ Depth & Trace history 明显更好(0.107 vs 0.127),但主结果用的是 w/o 版本。虽然作者解释是为 inference 鲁棒性(depth 不一定有),但把更弱的配置标成「Full」、把更强的配置藏进 appendix 容易误导,且没说下游 action 实验到底用了哪个配置。
- 2D baseline 里塞大 VLM(Gemini/GPT)有凑数嫌疑。这些通用 VLM 做轨迹预测延迟几十秒、本来就不是为此设计,top-1 偶尔赢更像噪声。真正同类的 baseline(Track2Act/Hamster/TraceGen)才是公平对手,对它们 μ₀ 确实赢,但「outperform tokenized-VLM」的卖点是软的。
- rigidity loss、done head、DINO 特征的下游增益没拆开。消融只在 trace prediction(top5-DTW)上做,没有一个消融直接测这些组件对最终机器人成功率的影响。trace 指标好 ≠ 动作好,中间还隔着 Action Expert,因果链没闭合。
- 延迟比较只算 trace prediction(0.29s),但部署时还要叠 Action Expert 的 flow matching 采样、双相机编码等。端到端控制频率 / 真机实时性完全没报告,对一个要上真机的方法是关键缺失。
- 泛化(cross-embodiment 的核心卖点)几乎没真正测。标题和 abstract 反复强调「cross-embodiment」「embodiment-agnostic」,但实验是 RoboCasa 的 PandaOmron + 真机 UR3,都是单臂 tabletop。没有一个实验展示「同一个冻结 μ₀ 迁移到结构差异大的本体」(dexterous hand、mobile manipulator、不同自由度),limitation 也自承了这点。所谓 cross-embodiment 目前只是「trace 表示理论上 agnostic」,没被实证。
5.3 值得继续探讨的方向¶
- 公开数据规模与组成:这篇要想立住「scalable data engine」,必须补上数据集清单、规模曲线、人/机器人/不同来源的消融。否则 TraceExtract 的价值无法独立评估。
- 真正的跨本体迁移实验:冻结一个 μ₀,分别接 dexterous hand / 双臂 / mobile base 的 action expert,测同一运动先验能否迁移。这是检验核心主张的唯一硬证据。
- trace 质量 → 动作成功率的因果链:做一组「人为退化 trace 质量(加噪/降采样/去 rigidity)」→ 看下游成功率掉多少的实验,把 §5.2-7 的因果链补上。
- 力/触觉的缺失:limitation 自承 trace 只编码几何运动、不含 force/tactile/contact mode。对 contact-rich 精细操作(插拔、拧),能否在 trace 上叠一个接触/力的预测头?
- 端到端延迟优化:partial denoising 已经省了 trace 这边,但 Action Expert 的 flow sampling 步数、双 flow(trace flow + action flow)串联的总延迟值得做 control-frequency 报告 + 蒸馏。
- depth 的角色:消融显示 depth 明显有用但主模型为鲁棒性丢掉了。能否用一个学出来的 depth 置信度门控、而不是简单 0.7 dropout,让有 depth 时充分利用、没有时优雅退化?
- 与像素世界模型的互补:trace 抓「what moves」但丢了外观/语义场景变化。trace + 轻量像素/语义预测的混合世界模型(trace 主导运动、像素补全外观)可能两头通吃。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页: mu0-wm.github.io
- 关键 baseline / 相关论文:
- TraceGen (lee2026tracegen) — 同组最接近的前作,fixed-grid 3D trace + episode caption + inference 需 depth;μ₀ 全面升级版
- π₀ (black2025pi0) / π₀.₅ (intelligence2025pi_) — action-labeled VLA 主对照,本库有 π₀ / π₀.₅ 笔记
- SmolVLM2 / SmolVLA (shukor2025smolvla) — backbone 与 cross-attention 结构来源
- VGGT / TAPIP3D / DINOv2 — TraceExtract 感知栈
- RoboCasa365 (nasiriany2026robocasa365) — 仿真 benchmark
- Track2Act / Hamster / 3DFlowAction / Dream2Flow — trace 预测 baseline