TerraTransfer: 学开车 vs 学看东西的解耦¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: TerraTransfer: Learning End-to-End Driving Policies Without Expert Demonstrations
- 作者: Zikang Xiong, Weixin Li, Zhouchonghao Wu, Akshay Rangesh, Saarth Bonde, Grantland Hall, Chen Tang, Yihan Hu, Wei Zhan — Applied Intuition / UCLA / UC Berkeley
- arXiv 编号: 2606.17386(2026-06 提交,目标 CoRL 2026)
- 关键词: end-to-end autonomous driving, self-play RL, vision-policy alignment, structural distillation, DINOv3, batch-relational low-rank loss, demonstration-free
- 项目主页: https://zikang-xiong-ai.github.io/terratransfer
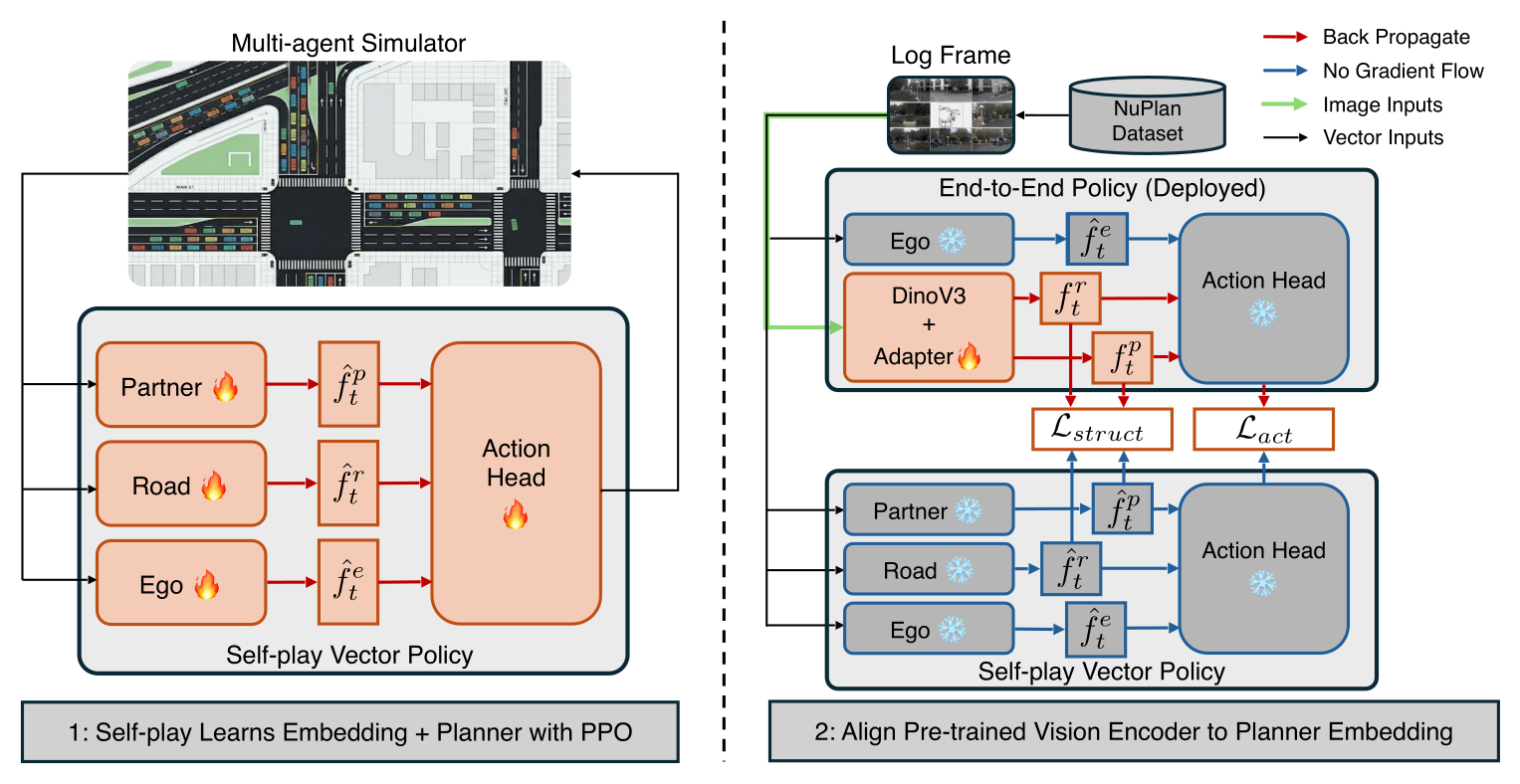 Figure 1:两阶段 pipeline。Phase 1(左)在 TerraZero vectorized sim 里用 PPO 训自我对弈 teacher,所有 agent 用同一参数;Phase 2(右)冻 teacher 的 ego-encoder + shared MLP + actor head,只换 road / partner 两个 set encoder 为 DINOv3 + 两个线性 adapter,靠 (image, scene-state) 配对帧 + action KL + 低秩结构 loss 蒸馏;自始至终不碰 logged 人类轨迹。
Figure 1:两阶段 pipeline。Phase 1(左)在 TerraZero vectorized sim 里用 PPO 训自我对弈 teacher,所有 agent 用同一参数;Phase 2(右)冻 teacher 的 ego-encoder + shared MLP + actor head,只换 road / partner 两个 set encoder 为 DINOv3 + 两个线性 adapter,靠 (image, scene-state) 配对帧 + action KL + 低秩结构 loss 蒸馏;自始至终不碰 logged 人类轨迹。
2. 文章介绍¶
2.1 解决的领域和问题¶
End-to-end autonomous driving 的训练 pipeline 长期被三股开销压着:(1) 百万小时多相机日志 + 3D label annotation——fleet 运营和标注几乎占总成本绝对大头;(2) 任何 fine-tuning 都得重新筹备 in-domain 高质量 rare-event 演示;(3) 闭环 image-RL 在 sensor renderer 里每步都得 photorealistic 渲染 + 大 vision backbone 推理,慢到难以扩量。
本文要解决的问题是:能否把"学开车"完全压到 vectorized self-play、把"学看东西"压到一次冻结的对齐过程,从而整条 pipeline 都不接触任何人类驾驶轨迹?
2.2 Motivation¶
观察一条经济学上的不对称:vectorized self-play 在多 agent sim 里能跑到 2M+ steps/s(论文给的 reference run 是 3M steps/s),整训练 ~96 小时 / 16×A100 跑出 2.4B 公里(≈1.5B miles)的合成驾驶;而 fleet log 一公里也得几十秒到几分钟的真实采集 + 几美元的人工标注。"获取 state-action 对"这件事在 vector-state 里是廉价的,对 image 来说极贵。
关键 framing:最优动作只取决于 scene state,而不取决于这状态是被哪种 modality 感知、也不取决于是不是人采过的。所以"学开车"(policy 从 state 到 action)可以完全在 vector sim 里训完,"学看东西"(image → 中间表征)只是一次性 modality bridging。后者所需的 paired (image, scene-state) 数据严格弱于 imitation 需要的 expert demonstrations——不需要好司机、不需要 rare event mining、不需要 trajectory label。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Image-based BC E2E | UniAD, VAD, LTF | 全程依赖 logged human driving;BC 的 covariate shift + bounded by expert quality |
| Logged-traj open-loop RL | navhard-RL 类 | 仍以 logged trajectory 做 reward 信号;rare-event 覆盖不足 |
| Closed-loop image RL | CARLA-LBC, Roach, TCP, ECO | 每步 photorealistic 渲染 + 大 vision pass,吞吐被锁死 |
| Vector self-play | GigaFlow, SPACeR, GRBO, CorrectionPlanner | 训得很强但只能吃 vector state,没法直接部署到 image 输入的车上 |
| Privileged teacher-student (LTF, LBC, Roach) | CARLA + 脚本/特权 teacher | Teacher 仍是人类设计的脚本或 IL 拷贝;student 还是 BC/DAgger 对动作直接监督 |
| Cross-modal alignment (CLIP/ALIGN/BLIP-2) | 通用图文 | 不针对决策接口、不带 policy distribution 监督 |
2.4 论文解决方案(一句话)¶
Phase 1 在 TerraZero vector sim 里用 PPO 多 agent self-play 训完整 policy(ego + road + partner DeepSets encoder + shared MLP + actor),Phase 2 冻 ego-encoder / shared MLP / actor head,把 road / partner 两个 set encoder 替换成 DINOv3 + 两个 linear adapter,仅用 (image, scene-state) 配对帧 + action KL + batch-relational SVD low-rank 结构损失 把视觉 student 对齐到 teacher——全程零 logged trajectory。
2.5 与前序工作的关系¶
- 直接对标:GigaFlow (Cusumano-Towner 2025) 的 vector self-play 配方 + per-agent reward weight randomization 几乎照抄;但 GigaFlow 停在 vector state,本文把"下游 student 怎么吃像素"补齐。
- 直接挑战:LTF (Chitta 2022)、Roach、LBC、TCP 这套"privileged BC + DAgger 蒸馏"路线——本文换成 self-play teacher + 关系型结构 loss。
- 借用:DINOv3 (2025) 作为冻结视觉 backbone;HUGSIM (Zhou 2025) 作为闭环评测;nuPlan HD 地图作为 Phase 1 的 map geometry(但不用其轨迹/agent/goal);nuPlan 作为 Phase 2 的 paired-data 来源(51 小时 1.83M 帧)。
- 方法论亲缘:Similarity-Preserving Distillation (Tung 2019) 的关系型 distillation;Gavish-Donoho (2014) optimal low-rank denoising;Roy & Vetterli (2007) 的 effective rank。
- 姊妹论文:
- Gigapixel (Rowe 2606.19641) — 同样想把 self-play 推到 E2E,但他们造像素 simulator做 self-play DAgger;本文反着做:sim 始终留在 vector,只补对齐桥。
- Spiced Self-Play (Cornelisse 2606.19370) — 同 vector self-play 框架但需要 30 min 人类 anchor;本文连 anchor 都不要。
- World Engine (Li 2606.19836) — 后训范式 + 3DGS + BWM;本文走"前训-然后-对齐"。
3. 方法介绍¶
3.1 形式化¶
每个 agent 看三组观测:自身 ego state \(o^e_t\)(含 kinematics + per-episode reward-weight \(w^{(n)}\) + goal 信号 + 车体几何 + dynamics 系数)、变长 road element set \(\mathcal{O}^r_t\)、变长 partner set \(\mathcal{O}^p_t\)。三个 encoder 并行处理:
其中 \(E_r, E_p\) 是 DeepSets(\(\text{maxpool}_i\,\phi(o_i) + b\),learned bias \(b\) 处理空集),concat 后过 shared MLP + actor head 出离散 action 上的 softmax 分布(不是连续轨迹)。
奖励是 \(K\) 项加权和,weights \(w^{(n)}_k \sim \mathcal{U}(w^\min_k, w^\max_k)\) 每 agent 每 episode 独立采样并作为 ego 观测输入 policy——单个 \(\pi_\theta\) 因此同时学会"激进 / 谨慎 / 节能 / 守规"各种 driver persona。
PPO 训练目标:
3.2 Phase 1: Self-Play 在 TerraZero 里训 teacher¶
- TerraZero = Applied Intuition 自家 vectorized batched sim。3M steps/s on 16×A100。
- 地图:仅借 nuPlan HD map geometry——lane topology、lane boundary、drivable-area polygon。不用 logged trajectories / agent inits / goals / human actions / replay traffic。
- Spawn:从 lane centerline rejection sampling,保证初始不撞车不出路。Goals 也是 procedural——20-100 m 内沿 lane graph walk,到点重采样。
- 控制对象只有车(vehicle-only);行人和骑行只是 procedural 静态 / 障碍物,不被 policy 控制。
- 动力学:dt = 0.1 s,passenger-car 尺寸随机化(长 3.5-5.5 m / 宽 1.5-2.5 m),随每 agent 暴露给 policy。
- Reward 项:goal-reaching / collision / comfort / lane alignment / lane centering / velocity / traffic-rule compliance 等 \(K\) 项。
3.3 Phase 2: Vision Alignment(核心方法贡献)¶
为什么不级联 perception → policy?¶
直觉做法:训个 perception 模块把 image 还原成 teacher 需要的 bounding box / lane polyline / partner kinematics,再喂进冻结 teacher。作者明确反对——teacher 的 set encoder 是一个 lossy many-to-one map:很多不同的 detection set 会 pool 到同一个 fixed-dim feature,而只有这个 pooled feature 真正影响 policy。级联是解了一个更难的问题:还原 detection set 等于反演 pooling。直接预测 pooled feature 本身才是对齐目标。
Alignment 接口¶
冻结 teacher 的 \(E_\text{ego}\) / shared MLP / actor head。仅替换 \(E_r, E_p\) 为:单个共享 DINOv3 backbone + 两个 linear adapter → \(f^r_t, f^p_t\)。Student 和 teacher 各拿自己的 \((f^r, f^p)\) 喂同一个冻结 head,得到各自的 action 分布。
Loss 1: Action KL¶
policy-level 一致性。
Loss 2: 批内关系型低秩结构 loss(本文真正的创新点)¶
观察:在 1.83M 帧上看 teacher 的 \(D=64\) 维 partner feature 的 SVD 谱——前 13 维就吃掉 80% 能量;road feature 前 9 维吃 80%。
![]() Figure 2:Teacher 特征的奇异谱。partner \(f_p\) 和 map \(f_r\) 都明显低秩,作者将 \(k_p=13\)、\(k_r=9\) 作为 80% 累计能量阈值,直接当成"informative subspace"的尺寸来用,不再当成超参。
Figure 2:Teacher 特征的奇异谱。partner \(f_p\) 和 map \(f_r\) 都明显低秩,作者将 \(k_p=13\)、\(k_r=9\) 作为 80% 累计能量阈值,直接当成"informative subspace"的尺寸来用,不再当成超参。
所以"逼 student 在 64 维上每个坐标都对齐 teacher"是错的——会让 student 浪费容量去拟合无结构的低能量长尾。改为只在 teacher 的低秩主子空间里、且只对齐 pairwise scene similarity:
- Batch \(B\) 帧,做 mean-center 得 \(\bar{F}_*, \bar{\hat{F}}_*\)(\(*\in\{r,p\}\));
- 对 teacher 矩阵跑 SVD,取 top-\(k_*\) 右奇异向量 \(V^{(k_*)}_*\);该 basis 每 batch 重算 + stop-gradient;
- 把 student / teacher 投影到该 subspace:\(Z_* = \bar{F}_* V^{(k_*)}_*\),\(\hat{Z}_* = \bar{\hat{F}}_* V^{(k_*)}_*\);
- 行归一后算 cosine similarity 矩阵 \(S_* = \tilde{Z}_* \tilde{Z}_*^\top \in \mathbb{R}^{B\times B}\)(teacher 同上得 \(\hat{S}_*\));
- 损失 = \(\frac{1}{B^2}\|S_* - \hat{S}_*\|_F^2\),对 \(r, p\) 各算一份相加。
这样 student 只用学"哪些场景之间像、相似度多高"这个关系几何,绝对坐标系和正交噪声补集随便它放——和 Similarity-Preserving Distillation 一脉相承,但用 SVD 给了它一个动态自适应的子空间。
总损失¶
3.x Implementation Details¶
| 项 | 数值 |
|---|---|
| Phase 1 sim | TerraZero (vectorized batched, in-house) |
| Phase 1 throughput | ~3M agent steps/s |
| Phase 1 训练 | 16×A100 / 96 h / 2.4B 公里模拟 |
| Phase 1 算法 | PPO,dt = 0.1 s |
| Map geometry | nuPlan HD map(不用 log / goal / agent) |
| Phase 2 backbone | DINOv3(frozen) |
| Phase 2 trainable | 仅 2 个 linear adapter(road + partner) |
| Phase 2 数据 | nuPlan 1.83M paired (image, scene-state) 帧 = 7129 shard × 256 帧 ≈ 51 h @ 10 Hz |
| Phase 2 训练 | 8×A100 / 10 h |
| \(\lambda\) (struct weight) | 0.5(不敏感) |
| \(k_p / k_r\) | 13 / 9(按 80% 累计能量阈值定,不是手调) |
| Action 空间 | 离散,softmax 分类 |
| 控制频率 | 10 Hz |
| 评测 | HUGSIM nuScenes 88 scenes × 4 难度等级(Easy/Medium/Hard/Extreme) |
4. 结果对比¶
4.1 HUGSIM 闭环 (主表,88 nuScenes 场景,closed-loop HD-Score)¶
| Method | Easy | Medium | Hard | Extreme | All |
|---|---|---|---|---|---|
| UniAD | 0.367 | 0.198 | 0.249 | 0.109 | 0.224 |
| VAD | 0.400 | 0.228 | 0.242 | 0.095 | 0.239 |
| LTF | 0.634 | 0.391 | 0.289 | 0.098 | 0.360 |
| ECO Smoothing-only | 0.764 | 0.416 | 0.405 | 0.255 | 0.452 |
| ECO Smoothing+Re-time | 0.720 | 0.388 | 0.342 | 0.236 | 0.415 |
| Self-play teacher (ref., vector state) | 0.780 | 0.497 | 0.639 | 0.185 | 0.520 |
| Ours (vision student) | 0.769 | 0.501 | 0.560 | 0.150 | 0.490 |
- All-set 0.490 比最强 IL baseline LTF 高 0.130,比 ECO 高 0.038;学生 0.490 与 teacher 0.520 仅差 0.03,证明对齐把大部分 teacher 能力迁移过来了。
- 唯一输的是 Extreme tier(0.150 vs ECO 0.255)。作者解释:Extreme 里 surrounding 会主动冲撞甚至 clip through 其他车,student 的保守反应保住了 safety 但牺牲了 route completion (RC)。
- 跨数据集泛化:Phase 2 训练帧来自 nuPlan,HUGSIM 用 nuScenes 场景——两个数据集相机 rig 和 location 都不同。这件事在 §4.2 被作为额外卖点强调。
4.2 数据效率¶
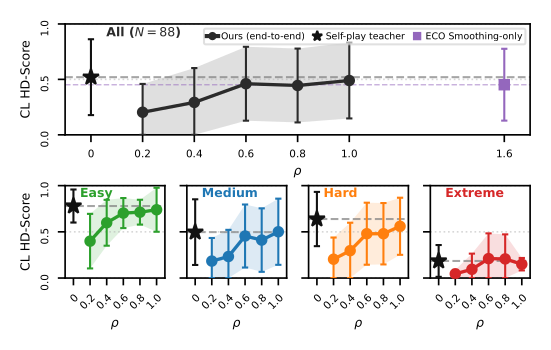 Figure 3:横轴 \(\rho\) = 用了多少 nuPlan 配对帧(\(\rho=1\) 即全部 1.83M)。\(\rho=0.6\)(约 1.1M 帧,是 ECO fine-tune 量 2.8M 的 40%)已经达到 0.461 超过 ECO 的 0.452;\(\rho=1.0\) 到 0.490。Teacher 在 \(\rho=0\) 处的水平线 (0.520) 是天花板。
Figure 3:横轴 \(\rho\) = 用了多少 nuPlan 配对帧(\(\rho=1\) 即全部 1.83M)。\(\rho=0.6\)(约 1.1M 帧,是 ECO fine-tune 量 2.8M 的 40%)已经达到 0.461 超过 ECO 的 0.452;\(\rho=1.0\) 到 0.490。Teacher 在 \(\rho=0\) 处的水平线 (0.520) 是天花板。
亮点:student 比 ECO 少用 60% 的 in-domain 数据 + 完全不用 trajectory label,依然超过它。
4.3 关键 ablation(HD-Score All-set,附录 D)¶
| 配置 | All HD-Score |
|---|---|
| Full: action KL + 低秩 struct (k=80% energy) | 0.490 |
| 去掉低秩 struct(仅 action KL) | 略掉(论文给在 Appendix D) |
| 全秩 struct(不截断) | 比 low-rank 差 |
| 不同 backbone(论文 Appendix E) | DINOv3 优于其他 |
(具体 Appendix D 数字本笔记没逐一抄;趋势是低秩 truncate 比 full-rank 好,DINOv3 比对比 backbone 强。)
4.4 Demo quality decoupling(Appendix F)¶
作者证明:在 HUGSIM 里用随机动作 collect 1.83M paired frame,对齐结果与正常 teacher 收的 paired data 几乎一致——因为对齐 target 永远是 teacher 在当前 state 上重新算的 action 分布,rollout policy 的好坏不影响对齐(只影响 state coverage)。这是 §2.2 那条 framing 的最干净的实验证据。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- "学开车 vs 学看东西"的解耦 framing 极清晰。Self-play teacher 训完一次 → 可以反复给 vision frontend / sensor rig / 区域适配做 alignment 监督。Phase 1 的 96 h 投入是 amortizable 的固定成本,Phase 2 才 10 h——这条 economics 比 GigaFlow + image-RL 那条全栈像素训练经济得多。
- 直接拒绝级联感知 → 决策的设计选择。作者点明 teacher 的 DeepSets pool 是 lossy many-to-one;student 学回 pooled feature 比反演 detection set 简单。这是非常少见的、对"perception-then-planning"做正面理论批判的论文。
- SVD 低秩 + 关系型 loss 是双重正则。一方面通过 80% energy cutoff 把 student 的注意力从无意义的尾部坐标里释放出来;另一方面 cosine similarity 矩阵让 student 不必匹配绝对坐标系——允许 vision 特征在自己的 basis 下重新表达。\(k_r = 9 / k_p = 13\) 不是手调,是数据自身给的——这件事让结果可信度高。
- "alignment target 是 teacher 在每个 state 上重算的 action 分布,不是 rollout 收集者的动作"——所以收 paired data 的 policy 可以是任何能产生合理 state 覆盖的东西,包括随机动作(Appendix F 实验证)。这条彻底打破"还得有好司机收数据"的假设。
- 跨数据集评测(nuPlan 训 alignment、nuScenes 测 HUGSIM)让 0.490 这个数字更有信号——不是 in-distribution replay。
- closed-loop HD-Score 自己重新定义了一版(Appendix B):原版 HUGSIM TTC 用 planned trajectory 测;本文用 realized rollout 重定义 TTC/COM/\(R_c\),NC/DAC 不变,aggregation 不变。对原版 metric 不适用单步 policy 的诚实承认 + 修复,做得很到位。
5.2 做得不够好的地方 / 值得质疑的地方¶
- closed-loop HD-Score 是作者自己改的 metric。原版 HUGSIM HD-Score 评估 planned trajectory;作者把 TTC / COM / \(R_c\) 都改成基于 realized rollout——理由合理但与原版 HUGSIM leaderboard 的数字不再可比。表 1 里 UniAD/VAD/LTF/ECO 的分数是作者用自己的 closed-loop 版本重新算的还是原 leaderboard 的?正文没明确,需要核 Appendix B 才能确认(暗示是作者自己重算的)。这把跨论文对比的可信度打了折扣。
- Action 空间是离散 softmax——而对比的 UniAD/VAD/LTF/ECO 都是连续 trajectory output。把"产 7-pose 轨迹"的方法和"产单步离散动作"的方法在同一张表里比 HD-Score,等于让两种范式在同一个 metric 下打架——而原 HUGSIM HD-Score 本就为前者设计;这才是作者必须重新定义 closed-loop 版本的根因。离散动作 + per-step replan + 重定义的 metric 这三件事捆在一起,构成了一种"重新定义评测以适配自家方法"的嫌疑。
- Phase 1 训练数据规模 (2.4B km) 几乎与 GigaFlow 同量级,但是 in-house TerraZero——既不开源 sim、也不开源 teacher checkpoint,复现门槛很高;尤其 GigaFlow 也不公开,这条线整体是"工业实验室级"研究而非可独立验证的科研。
- Extreme tier 的失利没有量化分析。作者只口头说"保守反应保 safety、牺牲 RC",但没给数据:Extreme 下 NC/DAC 比 ECO 高多少?RC 比 ECO 低多少?现在只能凭 0.150 vs 0.255 这一个数字猜,作为"safety trade-off"的论证不够。
- TerraZero 控制对象只有车,行人和骑行是 procedural 静态/障碍(论文 Limitations 自承)。这意味着 teacher 在 VRU 交互上根本没学过反应行为——但 HUGSIM nuScenes 场景里完全可能有这类对象,这是个潜在的 distribution gap,论文只在 limitation 一笔带过。
- signalized intersection 也没完整支持(Limitations 第三条)。两条加起来意味着 teacher 在城区驾驶里的覆盖面相当窄,HUGSIM 88 个 nuScenes 场景里有多少是纯 lane-following 高速路风格 vs. 真正的城区路口?作者没拆。
- vision backbone freezing:DINOv3 frozen + 两个 linear adapter 听上去经济,但linear adapter 跨 modality 容量极有限——这反过来可能解释了为什么 student 只到 0.490 而 teacher 0.520 还有 0.03 的差距。如果允许 partial fine-tune backbone 或者用 MLP 而非 linear adapter,差距可能再缩。论文 Appendix E 应该有 backbone ablation,但 trainable 模块设计的 ablation 没看到。
- paired data 来源是 nuPlan——而 nuPlan 同时也是 TerraZero 训练 map geometry 的来源(虽然作者明确只用 HD map 不用 trajectory,但 map 本身已经是 nuPlan 的 distribution)。所以 "alignment 跨数据集泛化"的说法严格说是"map distribution 一致 + sensor/region 不一致"——这一条作者没正面拆开。
- Phase 2 数据收 paired (image, scene-state) 时,"reconstructed scene state"是怎么得到的? 论文没正面说。如果是从 nuPlan log 的 3D label 重建出 teacher 需要的 set 表示,那"不用 expert demonstration"的卖点其实还是间接依赖 nuPlan 的人工 3D annotation——只是把"轨迹"和"标注"两个 expense 拆开了,annotation 没省。这件事是整个论文最关键的小字 caveat。
- 没有真车 / 跨 simulator transfer 验证。比 World Engine 的 200 km on-road、华为 ADS 产线 10k 场景至少落地两个数量级。"learning to drive without demonstrations"的卖点需要真车上至少跑通才能完全成立。
5.3 值得继续探讨的方向¶
- 把 alignment 接口从 pooled feature 提升到中间 DeepSets 节点:teacher 的 set encoder 内部还有可解释结构,做 entity-level alignment 而非 set-pool alignment 是否能再榨 0.03?
- 替换 DINOv3 为更小的视觉 backbone + 让 backbone unfreeze:partial fine-tune backbone 是否能补齐 teacher / student 0.03 的差距?\(k_r=9, k_p=13\) 的瓶颈在 backbone 还是在 linear adapter?
- VRU + signalized intersection 补全:把行人 / 骑行也用同样 self-play 多 agent + reward 加权方式训进 teacher,看 Extreme tier 上能否反超 ECO。
- 跨域 alignment scaling law:固定 1.83M 帧但改 source(nuPlan / Waymo / nuScenes / DROID-like log),看跨域 alignment 是否需要更多 paired data 还是同 data quantity 更稳。
- 接 Gigapixel / World Engine 的桥:本文 Phase 1 teacher + Gigapixel renderer 做 closed-loop image-RL 是否能进一步把 HD-Score 推过 0.520 teacher 上限?反之,World Engine 的 long-tail discovery 能否用 TerraTransfer 的 alignment 做 sim-to-real perception 接口?
- alignment phase 的 metric 完全在 closed-loop HD-Score 上——能否给一个不依赖于自家重定义 metric 的 evaluation(比如直接在 NAVSIM-v2 navhard 上跑伪闭环)让对比变干净?
- 关系型 loss 推到 sequence / multi-step:现在是 single-frame batch;如果 batch 是 trajectory snippet,scene-similarity 是否能加 temporal axis?
- 多 simulator scene-state 表示标准化:TerraZero 的 DeepSets ⇄ 其他 sim 的 vector observation 是否能定义一个开放接口让 alignment 可以跨 teacher 复用?
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://zikang-xiong-ai.github.io/terratransfer
- 关键 baseline / 相关论文:
- GigaFlow (Cusumano-Towner 2025) — vector self-play teacher 配方原型
- SPACeR (Chang 2025) / GRBO (Seong 2025) / CorrectionPlanner (Guo 2026) — 同期 vector self-play 方案
- DINOv3 (Simeoni 2025) — 视觉 backbone
- HUGSIM (Zhou 2025) — 闭环评测基准
- LTF / ECO / UniAD / VAD — IL baseline
- Similarity-Preserving Distillation (Tung 2019) — 关系型 distillation 原型
- Gavish-Donoho (2014) — optimal low-rank denoising 理论
- Gigapixel (Rowe 2606.19641) — 同期"像素 self-play DAgger"对照
- Spiced Self-Play (Cornelisse 2606.19370) — 同期"vector self-play + 人类 anchor"对照
- World Engine (Li 2606.19836) — 同期"3DGS + BWM + RL post-training"对照