OASIS: Observation-Action Space Alignment via SE(3) Trajectory Prediction for Robotic Manipulation¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: OASIS: Observation-Action Space Alignment via SE(3) Trajectory Prediction for Robotic Manipulation
- 作者: Xinzhe Chen*, Sihua Ren*, Liqi Huang, Haowen Sun, Mingyang Li, Xingyu Chen, Zeyang Liu, Xuguang Lan† (西安交通大学,人机混合增强智能国家重点实验室;†通讯)
- arXiv 编号: 2605.25829 (submitted 2026-05, NeurIPS 2026 preprint format)
- 关键词: visuomotor policy, VLA, SE(3) trajectory prediction, aligned intermediate, metric depth, LIBERO, CALVIN
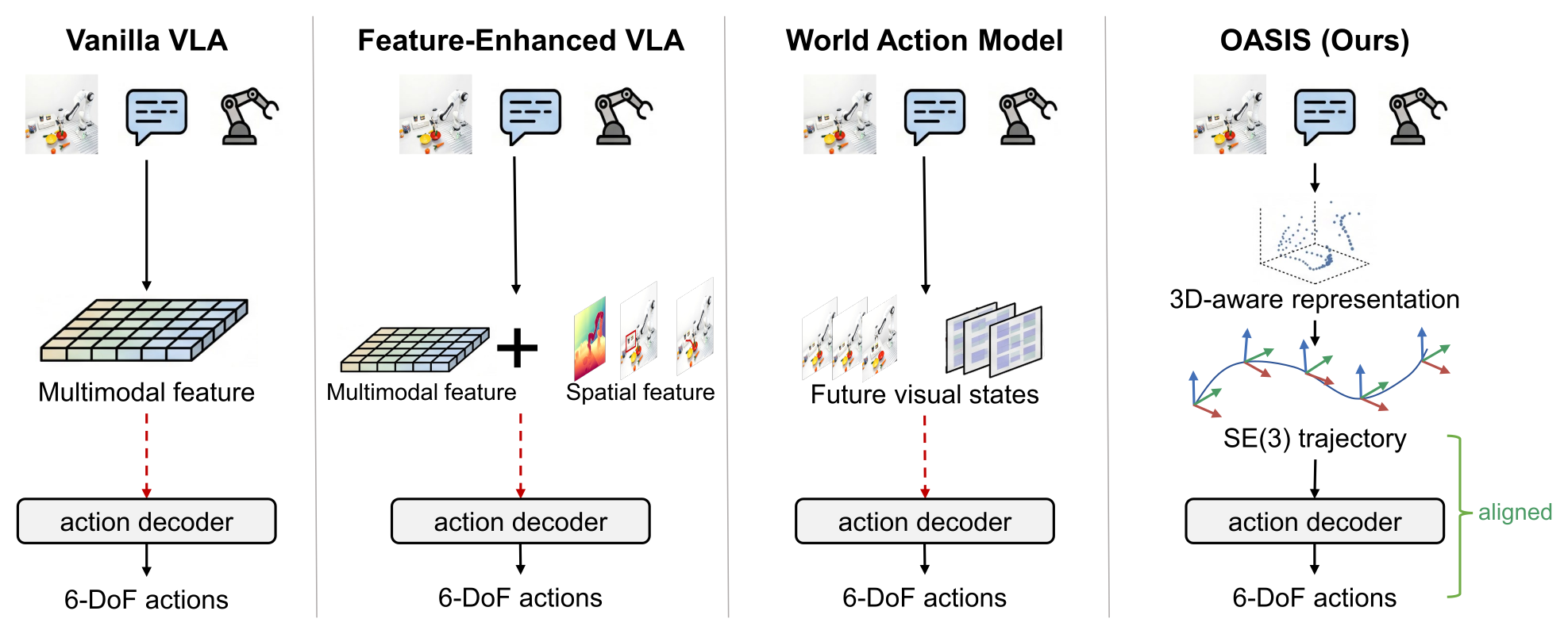 Figure 1:现有 VLA / WAM 的 intermediate representation 都停留在 observation space,几何信息要让 action decoder 自己 "implicit recover";OASIS 把 intermediate 直接搬到 action space ——预测 camera-frame 下的 SE(3) end-effector 轨迹,把刚体几何作为 inductive bias 喂进 decoder。
Figure 1:现有 VLA / WAM 的 intermediate representation 都停留在 observation space,几何信息要让 action decoder 自己 "implicit recover";OASIS 把 intermediate 直接搬到 action space ——预测 camera-frame 下的 SE(3) end-effector 轨迹,把刚体几何作为 inductive bias 喂进 decoder。
2. 文章介绍¶
2.1 解决的领域和问题¶
机器人桌面抓取/放置类 visuomotor policy。输入是 RGB 图像 + 语言指令 + 当前 end-effector 状态,输出是后续 H 步的 6-DoF 相对位姿动作 + gripper 命令。论文关心的核心问题是:policy 内部 intermediate representation 的几何结构与 action space 不匹配——即使是 VLA / WAM 这类强基线,decoder 也要在多模态特征或未来视觉预测里"挖出"刚体几何,再去解算相对动作。
2.2 Motivation¶
机器人末端的刚体运动天然活在 SE(3) 上,但单帧 RGB 在同一指令下可以对应许多种 6-DoF 动作(投影歧义 + 深度未知)。要消歧,intermediate 必须能"读出"目标 SE(3) 位姿。论文的核心 insight 一句话:
与其在 observation space 里堆加深度、ROI、2D 轨迹这种 auxiliary feature,不如直接预测 SE(3) 轨迹,把 intermediate 用 pose 监督,让它本身就和 action space 同构。
并把这个表述形式化为一个 design principle:intermediate \(\mathbf{m}_t\) 是 geometrically aligned 当且仅当存在一个固定的刚体变换 \(\mathbf{g}\in SE(3)\) 使得每一步都能写出 \(r(\mathbf{m}_{t+h})=\mathbf{g}\cdot\mathbf{T}_{t+h}\)(pose readout),剩余的非刚体残差(外参、接触动力学、gripper timing)交给学习型 decoder 吸收。
2.3 之前工作的问题¶
| 类别 | 代表工作 | intermediate 类型 | 缺陷 |
|---|---|---|---|
| Vanilla VLA | OpenVLA, \(\pi_0\), GR00T | multimodal latent \(\mathbf{z}_t\) | 既要 implicit 推目标位姿,又要解相对动作参数化 \(\rho\) ——两件事耦合在一个 decoder 里 |
| Feature-enhanced VLA | SpatialVLA, QDepth-VLA, ThinkAct, ReconVLA | 深度图 / ROI / 2D 图像平面轨迹 | 加强了空间理解但 intermediate 仍在 observation space;2D 轨迹缺刚体结构 |
| World Action Models | Seer, VPP, DreamVLA, Unified-VLA, WorldVLA | 未来 RGB / latent visual feature | horizon-indexed 但活在像素或视觉 latent space,decoder 还要再做一遍 image→SE(3) 推理 |
| Structured-pose policy | 3D Diffuser Actor, Act3D, RVT | 直接预测 SE(3) 作为最终动作 | 需要多视角 RGB-D 或额外 3D 传感器;不是从 RGB-only 的 VLA pipeline 出发 |
2.4 论文解决方案(一句话)¶
用一个 3D-aware encoder(VLM + frozen 度量深度 DA3METRIC-LARGE)拼出表征 → 一个轻量 transformer trajectory predictor 输出 8 步 camera-frame SE(3) end-effector 轨迹(axis-angle 参数化,\(\ell_1\) 监督) → 把 predictor 的 pose-supervised hidden states 直接 cross-attend 给 action decoder 产生 6-DoF 相对动作 chunk,端到端只用专家示教训练。
2.5 与前序工作的关系¶
- 沿用 Prismatic VLM 架构 (DINOv2 + SigLIP + Qwen2.5-0.5B):和 OpenVLA 同源,但 backbone 故意选小(0.5B),强调"不依赖 large-scale robotic pretraining"。
- 依赖 Depth Anything 3 (DA3METRIC-LARGE) 提供度量深度(不是相对深度,这点在消融里很关键)。
- action decoder 沿用 ACT-style query token + cross-attention 范式(参考 Zhao et al. 2023)。
- 与 ThinkAct 是最直接的对比对象:同样是"预测轨迹",但 ThinkAct 是 2D 图像平面轨迹,OASIS 是 camera-frame SE(3) 轨迹——主要 baseline 之一。
- 与 3D Diffuser Actor 在 CALVIN 表里同框;后者直接预测 SE(3) action 但要 RGB-D 多视角,OASIS 强调 RGB-only。
3. 方法介绍¶
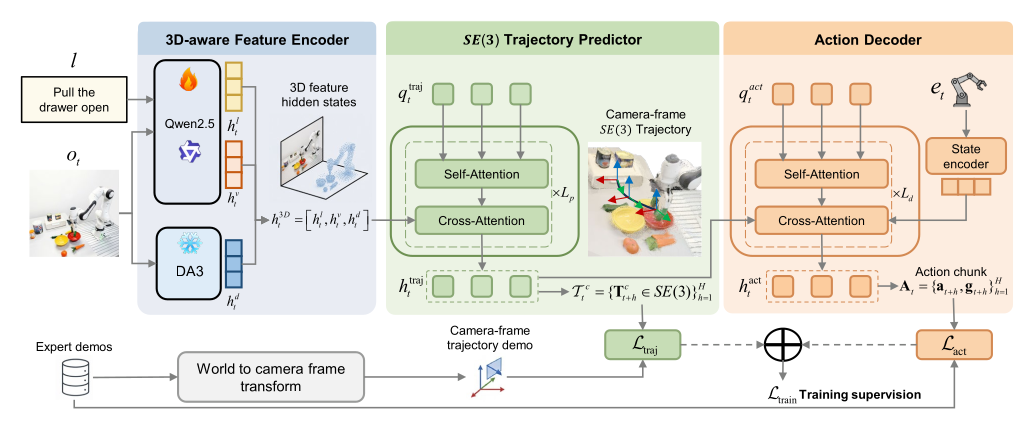 Figure 2:三阶段管线——(1) 3D-aware encoder 拼 [language, visual, depth] 三路 hidden states;(2) SE(3) predictor 用 8 个 learnable query 通过 self-attn (RoPE) + cross-attn(h³ᴰ) 得到 \(\mathbf{h}_\text{traj}\) 并线性投影成 8 步 SE(3) 轨迹;(3) decoder 仅 cross-attend \(\mathbf{h}_\text{traj}\) + state embedding 出 6-DoF + gripper chunk。注意 decoder 完全不直接看 visual / depth feature,只看 pose-supervised hidden。
Figure 2:三阶段管线——(1) 3D-aware encoder 拼 [language, visual, depth] 三路 hidden states;(2) SE(3) predictor 用 8 个 learnable query 通过 self-attn (RoPE) + cross-attn(h³ᴰ) 得到 \(\mathbf{h}_\text{traj}\) 并线性投影成 8 步 SE(3) 轨迹;(3) decoder 仅 cross-attend \(\mathbf{h}_\text{traj}\) + state embedding 出 6-DoF + gripper chunk。注意 decoder 完全不直接看 visual / depth feature,只看 pose-supervised hidden。
3.1 形式化¶
时刻 \(t\),policy 收到 \(\mathbf{o}_t\)(图像)、\(l\)(语言)、\(\mathbf{e}_t=[\mathbf{p}_t,\boldsymbol{\theta}_t]^\top\)(末端位姿状态),等价于 world-frame 齐次变换 \(\mathbf{T}_t\in SE(3)\)。目标是输出长度 \(H\) 的 action chunk \(\mathbf{A}_t=\{(\mathbf{a}_{t+h-1},g_{t+h-1})\}_{h=1}^H\),其中刚体分量满足 $\(\mathbf{a}_{t+h-1} = \rho(\mathbf{T}_{t+h-1}^{-1}\mathbf{T}_{t+h})\)$ \(\rho:SE(3)\to\mathbb{R}^6\) 是平移+轴角参数化。Gripper 单独建模,因为开合不属于刚体运动。
Aligned intermediate 的定义:\(\mathbf{m}_t\) 几何对齐 ⟺ 存在固定 \(\mathbf{g}\in SE(3)\),每步都有 readout \(r(\mathbf{m}_{t+h})=\mathbf{g}\cdot\mathbf{T}_{t+h}\)。VLA 没有 horizon 索引、WAM 的 intermediate 在 \(\mathcal{P}^H\)(视觉空间)里,都不满足;OASIS 取 \(\mathbf{g}=\mathbf{T}_{c\to w}^{-1}\) 即 camera→world 外参的逆,则 \(\mathbf{T}^c_{t+h}=\mathbf{g}\cdot\mathbf{T}_{t+h}\) 天然成立。
3.2 3D-aware feature encoder¶
三路 token 拼接:
| 子模块 | 模型 | 输出 |
|---|---|---|
| Vision-language | Prismatic VLM (DINOv2 + SigLIP + Qwen2.5-0.5B),LoRA 微调 | \(\mathbf{h}^v_t\in\mathbb{R}^{N_v\times D}\), \(\mathbf{h}^l_t\in\mathbb{R}^{N_l\times D}\) |
| Metric depth | DA3METRIC-LARGE (frozen) | \(\mathbf{h}^d_t\in\mathbb{R}^{N_d\times D}\) |
\(\mathbf{h}^{3D}_t = [\mathbf{h}^l_t, \mathbf{h}^v_t, \mathbf{h}^d_t]\) 直接 concat,喂给 trajectory predictor 做 cross-attention 的 K/V。
3.3 SE(3) trajectory predictor¶
- 架构:4 层 transformer block,hidden 896,8 head。\(H=8\) 个 learnable trajectory query。
- Self-attn 上加 RoPE → 时间一致性
- Cross-attn 的 K/V = \(\mathbf{h}^{3D}_t\)
- 输出:每个 query 经线性投影出 \([\mathbf{p}^c_{t+h}, \boldsymbol{\theta}^c_{t+h}]\in\mathbb{R}^6\),平移 + axis-angle。
- 关键设计 1:axis-angle 参数化。通过 Rodrigues 公式 \(\mathbf{R}=\exp([\boldsymbol{\theta}]_\times)\) "by construction" 落在 \(SO(3)\) 上,不需要 Gram-Schmidt 或事后正交化。桌面操作里 \(\|\boldsymbol{\theta}^c\|<\pi\),避开了奇点。
- 关键设计 2:camera frame 预测。直接预测 \(\mathbf{T}^c_{t+h}=\mathbf{T}_{c\to w}^{-1}\mathbf{T}_{t+h}\),省得让网络去学未知的 camera→world 外参。这点在消融里贡献了 +2.0 (Long) / +2.5 (Spatial) 点。
- Loss:chart-space \(\ell_1\), $\(\mathcal{L}_\text{traj}=\frac{1}{H}\sum_h\|\hat{\mathbf{e}}^c_{t+h}-\mathbf{e}^c_{t+h}\|_1\)$ GT 来自把 world-frame 示教用外参投到 camera frame。选 \(\ell_1\) 是为了抗 teleoperation 噪声 + 高精度(沿用 ACT 经验)。
3.4 Action decoder¶
- 2 层 transformer block,hidden 896,\(H=8\) action query。
- Cross-attn 的 K/V = \([\mathbf{h}_\text{traj}, \mathbf{h}_\text{state}]\)(注意:只看 pose-supervised hidden + state embedding,不直接看视觉 / 深度 feature)。
- 输出 \((\mathbf{a}_{t+h-1}, g_{t+h-1})\)。
- 不替换成闭式 pipeline:作者专门做了 Appendix C.3 闭式 decoder 消融来佐证(详见 §4 和 §5)。
- Loss:\(\ell_1\) on \((\mathbf{a}, g)\)。
3.5 总目标¶
3.6 Implementation Details¶
| 项 | 值 |
|---|---|
| 总参数 / 可训练 | 1.73B / 0.18B |
| 各组件 | DA3METRIC-LARGE 0.35B (frozen) ; Qwen2.5-0.5B VLM 1.30B (LoRA 0.10B) ; predictor + decoder 0.07B ; linear/state 0.01B |
| 训练硬件 | 4× A800,global batch 64 (16/device) |
| 训练步数 | 50k / suite,3 seed 平均 |
| 优化器 / lr | AdamW,\(2\times10^{-4}\),cosine + 5k warmup |
| 推理硬件 | RTX 4090,4.5 GB GPU mem |
| 推理频率 | 单次 forward ≈ 50 ms → 一个 8 步 chunk 约 20 Hz |
| 输入图像 | third-person + wrist,224×224×3 |
| Robot state 维度 | 7 (pos + rot + gripper) |
| Chunk 长度 | \(H=8\) |
4. 结果对比¶
4.1 LIBERO(RGB-only,每 task 50 episode)¶
| Method | Intermediate | Pretrain | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|---|---|
| SpatialVLA | spatial features | ✓ | 88.2 | 89.9 | 78.6 | 55.5 | 78.1 |
| WorldVLA | future visual states | ✗ | 85.6 | 89.0 | 82.6 | 59.0 | 79.1 |
| ThinkAct | 2D-supervised features | ✓ | 88.3 | 91.4 | 87.1 | 70.9 | 84.4 |
| \(\pi_0\) | multimodal features | ✓ | 96.8 | 98.8 | 95.8 | 85.2 | 94.1 |
| QDepth-VLA | spatial features | ✓ | 97.6 | 96.6 | 95.2 | 90.0 | 94.9 |
| UniVLA | spatial features | ✓ | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| Unified-VLA | future visual states | ✓ | 95.4 | 98.8 | 93.6 | 94.0 | 95.5 |
| OASIS (Ours) | SE(3)-supervised | ✗ | 99.0 | 98.8 | 97.4 | 95.2 | 97.6 |
对最强 baseline (Unified-VLA) +2.1 avg;对同样 trajectory 路线的 ThinkAct(2D 轨迹)avg +13.2,Long +24.3。注意 OASIS 是唯一在 "Pretrain=✗" 列里达到 SOTA 的方法。
4.2 CALVIN ABC→D(1000 instruction chain,长 horizon 多任务)¶
| Method | Intermediate | Pretrain | 1 | 2 | 3 | 4 | 5 | Avg |
|---|---|---|---|---|---|---|---|---|
| SuSIE | future visual states | ✓ | 87.0 | 69.0 | 49.0 | 38.0 | 26.0 | 2.69 |
| 3D Diffuser Actor† | 3D feature | ✗ | 93.8 | 80.3 | 66.2 | 53.3 | 41.2 | 3.35 |
| ReconVLA | spatial features | ✓ | 95.6 | 87.6 | 76.9 | 69.3 | 64.1 | 3.95 |
| Seer-Large | future visual states | ✓ | 96.3 | 91.6 | 86.1 | 80.3 | 74.0 | 4.28 |
| VPP | future visual states | ✓ | 96.5 | 90.9 | 86.6 | 82.0 | 76.9 | 4.33 |
| Unified-VLA | future visual states | ✓ | 98.9 | 94.8 | 89.0 | 82.8 | 75.1 | 4.41 |
| DreamVLA | future visual states | ✓ | 98.2 | 94.6 | 89.5 | 83.4 | 78.1 | 4.44 |
| OASIS (Ours) | SE(3)-supervised | ✗ | 98.1 | 94.9 | 91.7 | 88.9 | 83.3 | 4.57 |
†多视角 RGB-D。OASIS 在 1-task 排第三、但越往长 horizon(task 5)领先越大(+5.2 over DreamVLA),作者用"per-step 误差累积更少"解释这一点。
4.3 Real-world(Franka FR3 + Kinova Gen3,每 task 60 trial = 3 run × 20)¶
| Method | Goal | Spatial | Long | Avg |
|---|---|---|---|---|
| ACT | 58.3 | 45.0 | 18.3 | 40.5 |
| Seer-Large | 73.3 | 55.2 | 46.7 | 58.4 |
| RDT | 81.7 | 66.7 | 60.0 | 69.5 |
| \(\pi_{0.5}\) | 95.0 | 78.3 | 71.6 | 81.6 |
| OASIS (Ours) | 98.6 | 85.8 | 83.3 | 89.2 |
对最强 baseline \(\pi_{0.5}\) avg +7.6。Wilson 95% CI 表明 Goal 和 Spatial 区间分离明显,Long 区间 [71.7, 90.7] vs [58.9, 81.6] 有重叠 — 作者诚实标注"numerical lead rather than statistically significant"。
OOD(仅 Goal task):
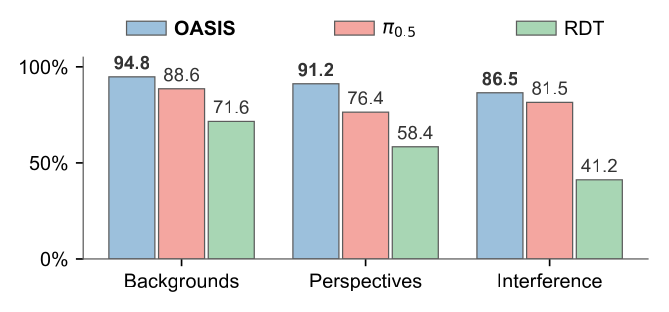 Figure 5:未见背景 / 第三视角偏移 ~15cm / 人手干扰下,OASIS 分别为 94.8 / 91.2 / 86.5,\(\pi_{0.5}\) 为 88.6 / 76.4 / 81.5。最大优势在视角偏移上 (+14.8),作者解释为 \(\mathbf{h}^{3D}_t\) 和 \(\mathcal{T}^c_t\) 都在 camera frame 里,整条链对相机位姿协变。
Figure 5:未见背景 / 第三视角偏移 ~15cm / 人手干扰下,OASIS 分别为 94.8 / 91.2 / 86.5,\(\pi_{0.5}\) 为 88.6 / 76.4 / 81.5。最大优势在视角偏移上 (+14.8),作者解释为 \(\mathbf{h}^{3D}_t\) 和 \(\mathcal{T}^c_t\) 都在 camera frame 里,整条链对相机位姿协变。
4.4 关键消融(LIBERO-Long / LIBERO-Spatial,所有变体共享 backbone + depth + 参数预算)¶
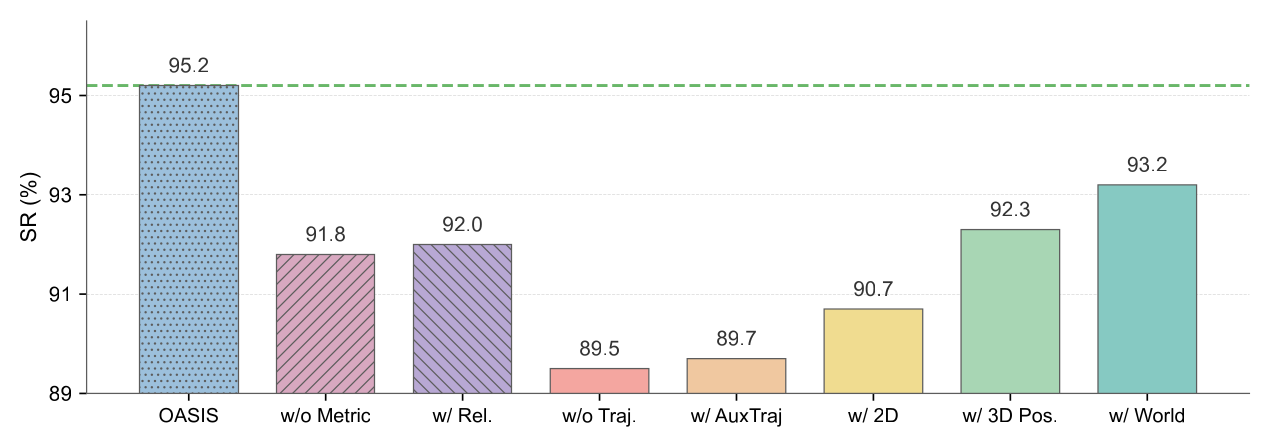 Figure 6:监督几何复杂度从无 → 2D → 3D position → world SE(3) → camera SE(3) 呈单调上升,对应 LIBERO-Long 89.5 → 90.7 → 92.3 → 93.2 → 95.2。最右两根 hatched bar 是深度消融。
Figure 6:监督几何复杂度从无 → 2D → 3D position → world SE(3) → camera SE(3) 呈单调上升,对应 LIBERO-Long 89.5 → 90.7 → 92.3 → 93.2 → 95.2。最右两根 hatched bar 是深度消融。
| Variant | LIBERO-Long | LIBERO-Spatial |
|---|---|---|
| w/o Traj.(去掉 predictor,单走 encoder+decoder) | 89.5 | 91.6 |
| w/ AuxTraj(traj loss 走旁路 branch,hidden 不送 decoder) | 89.7 | 91.9 |
| w/ 2D(ThinkAct 路线:图像平面 trajectory) | 90.7 | 93.3 |
| w/ 3D Pos.(只预测 3D 平移,不含旋转) | 92.3 | 95.4 |
| w/ World(world-frame SE(3)) | 93.2 | 96.5 |
| OASIS (camera-frame SE(3)) | 95.2 | 99.0 |
| w/o Metric(去掉度量深度) | 91.8 | 93.4 |
| w/ Rel.(换成 Depth Anything 2 相对深度) | 92.0 | — |
两条关键消融观察:
- AuxTraj 已经带上了 trajectory predictor 的所有参数,但因为 hidden 没路由进 decoder,仅得 89.7 ≈ w/o Traj.(89.5)。这把"是否对齐"这件事和"是否多了参数"切开了——OASIS 在 LIBERO-Long 上比 AuxTraj 多 +5.5 是几何监督信号到达 decoder 的贡献,不是容量。
- w/o Metric vs w/ Rel.: 把度量深度换成相对深度只从 91.8 涨到 92.0;说明帮 OASIS 的不是"深度先验",而是"绝对尺度"。
\(SO(3)\) 参数化消融:axis-angle 95.2 > Euler 92.2 > quaternion 91.6,axis-angle 是覆盖桌面 orientation 范围的最小无约束 chart,无须 Gram-Schmidt。
闭式 decoder 消融(Appendix C.3,关键反驳实验):把学习型 decoder 换成"用已知外参 + 特权 simulator gripper 信号的硬编码 SE(3)→action 流水线",即使给出比 OASIS 强的特权信息,LIBERO-Spatial 从 99.0 → 12.4,Long 从 95.2 → 0.0。说明 predictor 出的几何是对的(机器人确实朝目标走),但残差(外参噪声、接触动力学、gripper timing)会复合到完全失败——learned decoder 不可替代。
SE(3) 轨迹可视化:
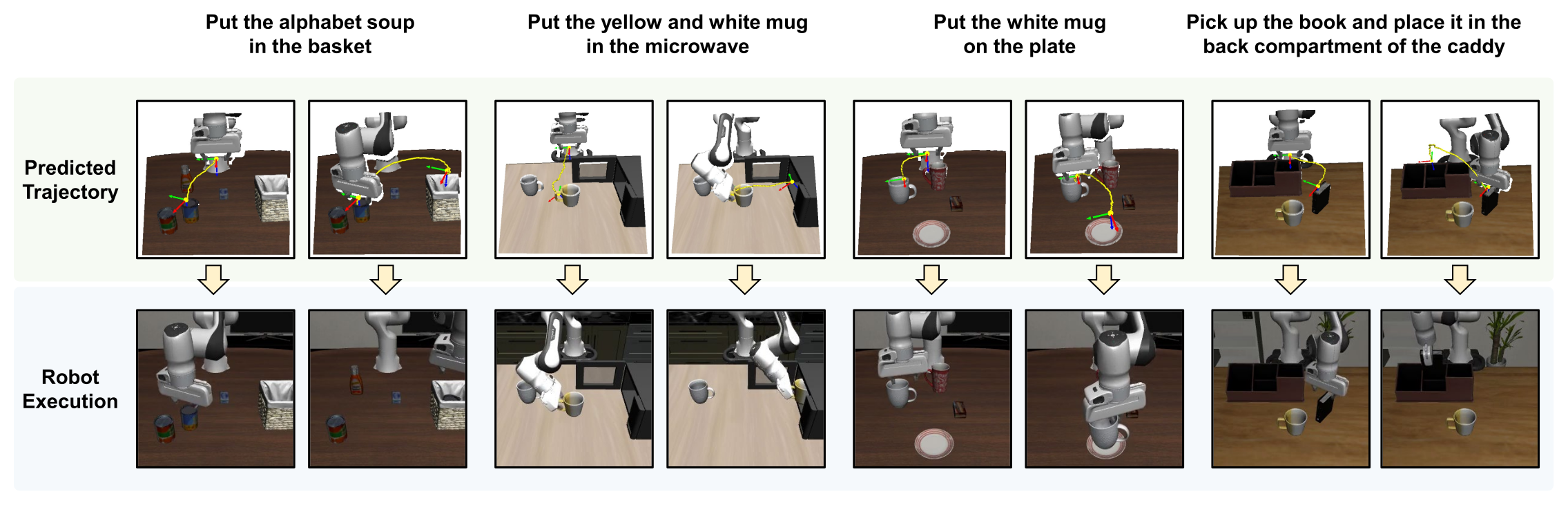 Figure 3:四个复杂 task 上把预测的位置 waypoint 和旋转轴叠到执行轨迹上,定性证明 predictor 出的是"可执行的刚体运动先验",不是空泛的 latent。
Figure 3:四个复杂 task 上把预测的位置 waypoint 和旋转轴叠到执行轨迹上,定性证明 predictor 出的是"可执行的刚体运动先验",不是空泛的 latent。
4.5 数据效率(real-world Long task,60 trial / config)¶
| Method | 10 demos | 25 demos | 50 demos |
|---|---|---|---|
| \(\pi_{0.5}\) | 15.0 | 35.0 | 71.6 |
| OASIS | 35.0 | 55.0 | 83.3 |
OASIS 用 10 个 demo 就追平了 \(\pi_{0.5}\) 用 25 个 demo 的成绩。但作者明确标注:这是 single-task 上的 low-data 优势,不是普适 scaling factor,且优势从 +20 (10 demos) 收窄到 +11.7 (50 demos)。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- "Aligned intermediate" 这条 design principle 很干净。论文把 VLA / WAM / Structured-pose policy 用一个统一的几何对齐定义切到位(§3.1-3.2),不止是 OASIS 这一个方法的故事——后人可以继续往这个 lens 里塞其他 alignment 形式(接触力、关节角等)。这一类"框架级 framing"通常比单点 SOTA 更耐用。
- AuxTraj 消融把"几何监督"和"信号路由"切开。这是全文最有说服力的对照:同样的预测分支,hidden 不进 decoder 立刻打回 baseline(89.5 → 89.7),进 decoder 一下 +5.5 (Long)。如果没有这条消融,整篇 paper 都可以被"trajectory loss 是个 effective auxiliary objective"消解。
- 闭式 decoder 反驳实验(Appendix C.3)做得很彻底。预测出 SE(3) 轨迹 + 已知外参 + 特权 gripper 信号 = 0% / 12.4%——这把"OASIS 是不是改了名的 inverse kinematics 流水线"的质疑提前解决,比同类 trajectory-prediction paper 更诚实。
- Camera-frame 而非 world-frame 预测。表面上是工程细节,但消融里贡献 +2.0 / +2.5 点,且解释非常清晰:camera→world 外参是真实部署里最容易被 miscalibrate 的量,把它留给 decoder 当残差吸收,比让 predictor 显式学要稳。
- 训练成本和参数预算都"小"——0.18B trainable / 4 块 A800 / 50k 步,没有大规模 robotic pretraining,却能在 RGB-only setting 下打过 \(\pi_0\) / \(\pi_{0.5}\) / Unified-VLA 这种重训方法。这条对中小研究组很友好。
- 20 Hz 推理 + 4.5 GB 显存(RTX 4090),是个真能上桌面机器人的部署预算。同类 video-diffusion 类 WAM (VPP / DreamVLA / Unified-VLA) 推理都更重。
- 诚实的统计学交代:在 Long task 上 Wilson CI 重叠就明说"numerical lead, not statistically significant",data-scaling 那一节也强调"only on a single task"。这种克制在 robotics paper 里少见,加分。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 预测出的 SE(3) trajectory 的"质量"几乎只有定性证据。Figure 3 是定性 overlay 图,但没有给"预测 SE(3) 误差 vs 任务成功率"的 quantitative 曲线,也没有报告 ADE/FDE 这类轨迹评价指标。如果未来有人改进 predictor,他们没有直接的指标可以比,只有最终 success rate。
- Single-step (current frame) 输入下做 8-step 预测,本质假设"动作只依赖当前观测"。Eq.(3) 里 \(\mathbf{u}_t = F(\mathbf{o}_t, l, \mathbf{e}_t)\) 没有历史窗口,意味着任何需要 力觉 / contact-rich / 时间相关 的 task(插销、拧螺丝、推大重物)都不在它的能力范围内。论文 Limitations 只提"扩展到 mobile / dexterous",没提这一条更基础的局限。
- CALVIN 1-task 成绩 (98.1) 反而不是第一(Unified-VLA 98.9)。论文用"长 horizon 优势"圆过去,但 1→5 task 单调下降并非 OASIS 独有,DreamVLA / Unified-VLA 同样有这个 pattern——"compounding error 更小"这句要更严格证明,需要 per-step error rate 的对比,而非只比终值。
- Real-world baseline 选择有点偏向自己。\(\pi_{0.5}\) / RDT / Seer-Large / ACT 这套都是非"trajectory-prediction"路线;没有把 ThinkAct 或 3D Diffuser Actor 等"也预测某种轨迹/位姿"的方法放进 real-world 表。如果同样路线的方法没有进 real-world 对比,"alignment 是关键"这个论断在真机上就少了一个对照点。
- OOD 实验只有 Goal task,且 perturbation 都很温和。"unseen background" 是换桌布加 distractor、"altered camera" 是 ~15 cm 平移、"human interference" 是把碗搬走——都是单一维度小幅扰动。没有测光照、没有测物体材质 / 形变、没有测 robot platform 切换(虽然训练用了 FR3 + Kinova,但 OOD 只在一个上做)。"OOD generalization" 这种宣称语气有点超过实验体量。
- 度量深度模块的真实贡献被绑死在 DA3METRIC-LARGE 上。"w/o Metric" 91.8 vs "w/ Rel." 92.0,差距小但作者结论是"metric scale matters"——只换了一个模型(DA3 → DA2),变量包括"训练数据""分辨率""架构",把这个差异完全归到"度量 vs 相对"上有点冒。理想消融是给 DA2 加一个学习到的全局 scale 来匹配。
- Decoder 只看 \(\mathbf{h}_\text{traj}\) + state,丢掉了视觉细节。对插销 / hang cup 这类亚厘米 placement 任务(成功率最低,76.6%),残差控制最需要的就是局部视觉反馈。论文 §4 (failure analysis) 也把 hang cup 失败归到"残差旋转误差"——这本质上是 decoder 没办法用视觉伺服去修正。
- \(\lambda=0.1\) 没有消融。两条 loss 权重对最终 alignment 强度的影响应该是核心超参,没看到 sweep。
- "camera frame 预测的优势"和"未知外参当残差"的论证略循环。CALVIN / LIBERO 里的相机外参其实在 simulator 里就是 known 的;w/ World 比 OASIS 差 2 点可以用"learning curse"解释也可以用其他因素,无法断定就是"外参未知"导致。真实机器人外参未知场景下的 world-frame vs camera-frame 直接对照才更有说服力。
- 作者把 OASIS 定位为 "no pretraining",但 VLM 内部的 Qwen2.5-0.5B + DINOv2 + SigLIP + LLaVA-instruct,和 frozen DA3METRIC-LARGE 都是 heavy 预训练过的。这条 "no pretraining" 的 framing 应该限定为"no large-scale robotic pretraining"——口径很容易被读者过度解读。
5.3 值得继续探讨的方向¶
- 接触阶段的 trajectory 怎么对齐?SE(3) 轨迹在自由空间里 expressive,但插销 / 螺纹这类需要 wrench/impedance 的接触阶段几乎一定要扩展到 contact-conditioned 或力觉条件。OASIS 在 Limitations 里点了这条,是个明显的下一步。
- Mobile manipulation 的 \(SE(2)\times SE(3)\) 耦合轨迹:base 在 SE(2)、arm 在 SE(3),alignment 形式应该是 cross-block diagonal。
- 多视角融合:现在 third-person + wrist 是 concat 视觉 token,但 trajectory 还只在 third-person camera frame 里——能不能用 wrist camera frame 多预测一条 SE(3) 轨迹做 multi-view consistency?
- Predictor → diffusion:现在 trajectory predictor 是确定性的;用 flow matching / diffusion 出多模态轨迹分布会怎样?多模态 demonstration(拿杯子可以左手也可以右手)现在直接平均损失。
- 大规模 robotic pretraining + alignment 同步加上去:作者强调 "no robotic pretraining" 是对自己 framing 干净,但和 pretraining 显然不互斥。Bridge / Open X-Embodiment 上预训一遍 trajectory predictor + LoRA fine-tune,可能能再爆一波数据效率。
- 数据效率优势可不可复现到 Spatial / 多任务?现在只在 real-world Long 一个 task 上做了,论文也强调了。一个 4×3 grid(task × demo count)会更强。
- Closed-form decoder 失败的更深分析:12.4% / 0.0% vs 99.0% / 95.2% 的 gap 大到令人意外。如果再把"特权 gripper 信号" + "learned residual delta"(小残差网络)加上去,gap 缩到多少?这个 ablation 会让 "learned decoder 必要性"的论断更精细。
- VLM 的角色到底有多重?整篇 paper 用了 Qwen2.5-0.5B,可不可以剥到更小的 BLIP-style 或纯 SigLIP+language encoder,看看 alignment 思路对 backbone 的依赖。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://npuhandsome.github.io/OASIS_web
- 主要 baselines / 相关论文:
- ThinkAct (2D 轨迹预测路线,§5.2 第 4 条对比)
- \(\pi_0\) / \(\pi_{0.5}\)(vanilla VLA 强 baseline)
- Unified-VLA / DreamVLA / Seer-Large / VPP(WAM 路线)
- 3D Diffuser Actor(structured-pose policy)
- QDepth-VLA / SpatialVLA(feature-enhanced VLA)
- ACT (Zhao et al. 2023,decoder 架构来源)
- Depth Anything 3 / DA3METRIC-LARGE(度量深度模块)
- Prismatic VLM / Qwen2.5-0.5B / DINOv2 / SigLIP(VLM 组件)