Utonia: Toward One Encoder for All Point Clouds¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Utonia: Toward One Encoder for All Point Clouds
- 作者: Yujia Zhang¹, Xiaoyang Wu¹† (project lead), Yunhan Yang¹, Xianzhe Fan¹, Han Li³, Yuechen Zhang², Zehao Huang³, Naiyan Wang³, Hengshuang Zhao¹‡ (corresponding)。¹The University of Hong Kong,²The Chinese University of Hong Kong,³Xiaomi
- arXiv 编号: 2603.03283(2026-03 提交,LaTeX 用
icml2026preprint 模板,疑似投 ICML 2026) - 项目主页: https://pointcept.github.io/Utonia
- 关键词: point cloud SSL, cross-domain pretraining, PTv3, RoPE, perceptual granularity, modality dropout, teacher-student self-distillation
 Figure 1:同一个 Utonia encoder 在四类极端不同的点云(城市级遥感、室外稀疏 LiDAR、室内稠密重建、object CAD)上的 PCA 特征都保持结构化、语义连贯——这是全文要卖的"一个 encoder 通吃所有点云"的视觉证据。
Figure 1:同一个 Utonia encoder 在四类极端不同的点云(城市级遥感、室外稀疏 LiDAR、室内稠密重建、object CAD)上的 PCA 特征都保持结构化、语义连贯——这是全文要卖的"一个 encoder 通吃所有点云"的视觉证据。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 3D 点云的自监督表示学习(point cloud SSL)。图像 SSL 早就靠"把数据集混在一起训"实现了通用性,但点云没有:点云是稀疏、无结构的采样,其尺度、密度、采样模式、坐标约定、附加模态(color/normal)随传感器和预处理剧烈变化,导致极端的 domain shift。
后果是:点云 SSL 至今按 domain 割裂。前序 SOTA Sonata、Concerto 都是单 domain 内训练,跨 domain 迁移很差——即便所有点云本质上都是同一个 3D 物理世界的离散观测。本文要做的,是训练一个跨 domain 的 self-supervised PTv3 encoder,覆盖室内 RGB-D、室外 LiDAR、遥感、object CAD、以及从 RGB 视频 lift 出来的点云。
2.2 Motivation¶
核心 insight 来自一张图(Figure 2):人类感知有固定角分辨率,近处的小玩具车和远处的真车在视网膜上有相近的感知粒度,所以语义匹配应该在"某个规范粒度"上跨 domain 对齐。Utonia 的特征能把 object CAD 里的玩具车前部和室外 LiDAR 里真车的对应区域对上,而 Concerto 对不上。
作者的判断是:统一的两个前提都已经成熟——可扩展的 backbone(PTv3)+ 稳健的 SSL recipe(Sonata 处理 geometry shortcut、Concerto 加 cross-modal)。所以下一步该跳出 siloed pretraining,"是时候把碎片化的 3D 观测变成共享表示了"。
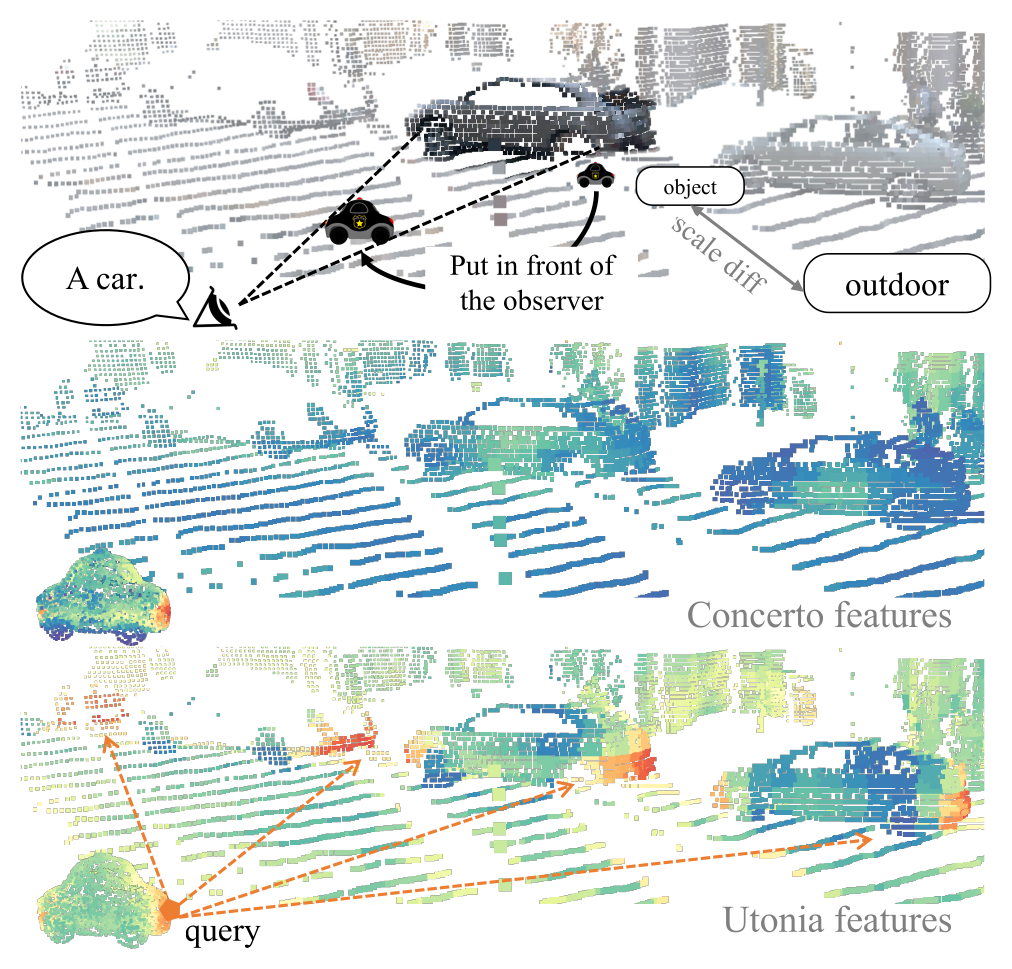 Figure 2:以 object CAD 玩具车的"车头"为 query,在室外 LiDAR 场景里按特征相似度检索——Utonia 能高亮真车对应区域,Concerto 失败。这张图是"固定角分辨率 → 规范粒度匹配"动机的直接支撑。
Figure 2:以 object CAD 玩具车的"车头"为 query,在室外 LiDAR 场景里按特征相似度检索——Utonia 能高亮真车对应区域,Concerto 失败。这张图是"固定角分辨率 → 规范粒度匹配"动机的直接支撑。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Object-level SSL | PointMAE, PointM2AE | 只做 object,不碰 scene;无 color/normal 处理 |
| Indoor scene SSL | MSC, PointContrast | 局限室内单 domain |
| Indoor+Outdoor SSL | Sonata | 室内/室外分开训两个模型;强依赖 color/normal,缺失时崩 |
| + 视频 lift 点云 | Concerto | 继承 Sonata recipe + cross-modal 预测,但仍单 domain;color 缺失时 mIoU 暴跌 |
| 显式"统一"尝试 | MoDE (zha2025), 占据体素切分 (zhang2022) | 靠复杂额外模块 / 只在有限 domain 组合上验证 |
一句话:点云 SSL 的割裂不是物理世界的结构决定的,而是工程设计选择造成的——简单混数据集并不能像图像那样自动涌现通用性。
2.4 论文解决方案(一句话)¶
不引入任何 domain-specific 模块,只用三个 domain-agnostic 的极简修复——Causal Modality Blinding(随机丢 color/normal)、Perceptual Granularity Rescale(把所有点云缩放到共享感知粒度)、RoPE on granularity-aligned coordinates(在对齐后的连续坐标上加旋转位置编码)——就能在 250k 跨 domain 点云 + 1M CAD 资产上稳定训出一个统一 encoder。
2.5 与前序工作的关系¶
这是 Pointcept 谱系的直接延续(Xiaoyang Wu、Hengshuang Zhao 即 Pointcept 团队,三作之一来自小米的 Zehao Huang / Naiyan Wang):
- Backbone 复用 PTv3(Wu et al. 2024),sparse conv + 序列化注意力。
- SSL recipe 沿用 Sonata + Concerto 的 teacher-student self-distillation,包括 Concerto 的 cross-modal joint prediction(有配对图像时用)。
- RoPE 来自 RoFormer(su2024),坐标增强抄 DINOv3(simeoni2025)的 anisotropic jitter + isotropic scale。
- 把 Sonata/Concerto 当成最直接的 baseline,并为公平起见替它们补训了原论文没报的 domain(Sonata 训 object;Concerto 训 outdoor 和 object)。
3. 方法介绍¶
整体 pipeline 见 Figure 3:跨 domain 数据 → RoPE-Enhanced PTv3(granularity-aligned 坐标 + domain-prior 擦除)→ 更广的评测(感知 + spatial reasoning + manipulation + open-world part seg)。底座是 Sonata/Concerto 式 teacher-student 自蒸馏,三个新设计分别对应 pilot study 找到的两大病根。
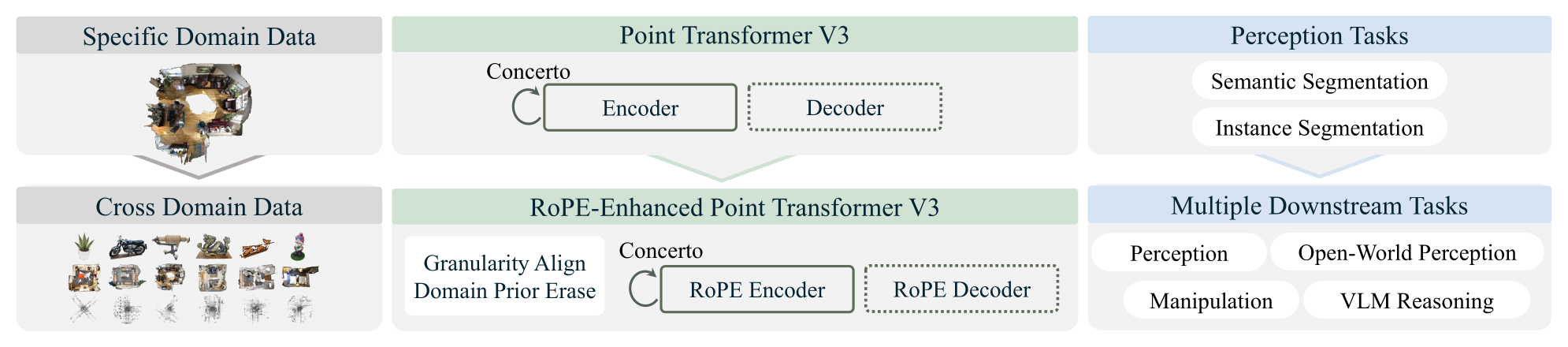 Figure 3:Utonia 在标准点云 SSL pipeline 上的三处改动——多 domain 联合训练、RoPE-增强的 PTv3(粒度对齐坐标 + 重力先验擦除)、以及超出标准感知的广义评测。
Figure 3:Utonia 在标准点云 SSL pipeline 上的三处改动——多 domain 联合训练、RoPE-增强的 PTv3(粒度对齐坐标 + 重力先验擦除)、以及超出标准感知的广义评测。
3.1 Pilot Study:什么阻碍了统一?¶
作者先做了一个诊断性实验,把"naive 混所有数据集联合训"为什么不稳,拆成三个 failure symptom:
- 对粒度(granularity)敏感。在 sparse 处理里 grid size 定义了 local neighborhood 的度量单位:同一个算子在一个 domain 覆盖厘米、在另一个覆盖米。直接合并 domain(用各自原始 grid 或 jitter grid)会大幅掉点(见下表)。
- 重力约定偏置(gravity bias)。很多 scene-level 点云是 gravity-aligned 的,height 成了物理参照,于是 scene 训练往往不敢做强 x/y 旋转(怕破坏 floor/ceiling 语义)。但 height 会变成 domain cue,伤害到 object-centric 的迁移。Sonata/Concerto 的特征有强 z-相关 pattern。
- 模态可用性不一致。color/normal 时有时无;naive 训练下 encoder 只要有就会去 exploit,于是缺失时表示和性能崩塌。
Table A(pilot:scale & grid size,linear probe mIoU)
| 设置 | ScanNet200 | Waymo | PartNetE |
|---|---|---|---|
| Separate domain(单 domain 上限,灰字参考) | 34.4 | 60.5 | 41.6 |
| Origin grid size(各自默认 grid 混训) | 29.1 | 43.9 | 39.5 |
| Jitter grid size | 29.6 | 42.6 | 38.7 |
| Fixed grid + rescale 到统一粒度 | 33.5 | 56.6 | 43.5 |
结论:多 domain 训练的两大病根是 (1) 空间坐标差异(粒度敏感 + 重力约定偏置)和 (2) 模态可用性不一致。
 Figure 4:Sonata/Concerto 特征带强烈的 z 轴(重力方向)相关 pattern;Utonia 通过把 rotation-invariant object + 强 SE(3) 增强引入预训练,把这种重力假设擦弱了。
Figure 4:Sonata/Concerto 特征带强烈的 z 轴(重力方向)相关 pattern;Utonia 通过把 rotation-invariant object + 强 SE(3) 增强引入预训练,把这种重力假设擦弱了。
3.2 Causal Modality Blinding¶
先定义统一模态接口:把 coord + color + normal 拼起来,缺的模态用全零填默认值。这让单 encoder 能吃所有 domain,但也带来 shortcut——encoder 会去依赖最丰富的可用通道,模态统计本身就成了 domain-identifying cue。
修法:把除坐标外的每个模态组都当成 optional,两级随机致盲—— - per-data blinding:对一个样本随机丢掉整组模态; - per-point blinding:对单个点再 mask 模态。
类比:"蒙着眼训练的人,摘掉眼罩也能走"。消融发现在 data loading 阶段丢最强(让所有目标都在缺模态输入下被一致训练),在 masked view 上丢最差(masked view 本就信息有限,再丢会过度损坏)。
3.3 Perceptual Granularity Rescale¶
把坐标在做位置编码之前缩放到一个共享感知粒度,于是不同 extent 的输入被映射到可比的坐标空间。注意它不强制所有 domain 共享同一坐标约定:
- scene-scale(粗粒度)保留 upright 结构(重力对齐有用);
- object-scale(细粒度)鼓励 orientation invariance(任意朝向)。
即把 gravity 当成"依赖于目标粒度的 prior"。rescale factor 从一个范围里采样(暴露多种有效粒度),并通过 teacher/student 两个视图之间的非对称 scale / rotation / shift 来强制 cross-view 特征一致。推理时 rescale factor 可调以匹配目标粒度。
3.4 RoPE Bridges Granularity-Aligned Coordinates¶
rescale 对齐了基本空间单位,但没规定"相对几何如何调制 token 交互"。sparse conv 通过离散化编码位置,把交互耦合到离散化、邻域和密度不均上。作者发现:在 granularity-aligned 坐标上加 RoPE 恰好提供了统一的连续位置 hint——
- RoPE 是 parameter-free,直接旋转 attention 的 Q/K,天然支持不同密度的可扩展点集;
- 配合 rescale + 坐标扰动,让 attention 依赖局部几何而非记忆 domain-specific 坐标约定;
- 对密度不均特别有用(室外 LiDAR 近密远疏,单 scan 内就严重不均)。
3D RoPE 实现(separable,跨轴分离):把特征 \(\mathbf{u}\) 均分成三段 \([\mathbf{u}^x;\mathbf{u}^y;\mathbf{u}^z]\),各用对应坐标分量做 1D RoPE。坐标先按 DINOv3 方式做增强:
把 \(\hat{\mathbf p}^{rj}=r\,(\mathbf j\odot\hat{\mathbf p})\) 喂给每一层 attention 旋转 Q/K,避免模型把语义绑死到固定的单位约定或轴向尺度。约束:channel 数必须能被 6 整除(3 轴 × RoPE 成对)。RoPE base \(B{=}10\)。
3.5 Implementation Details¶
- 数据:250,434(197,868 train + val/test)跨 domain + 1M Cap3D object。Cap3D 太大,每 epoch 随机子采样 90k。室外无 color → 用标定把图像颜色投影到点,不可见点填黑;normal 用 Open3D 估计(朝向 LiDAR center)。视频数据用相机参数(GraspNet)或 feed-forward 重建(VGGT,RE10K)。
- 两阶段训练:Stage 1 在高质量子集(ScanNet + Structured3D + Waymo + PartNet,也是 ablation 设置)上拿稳定初始化;Stage 2 在全 mixture 上续训 100 epoch。
- 算力:batch size 256,64× NVIDIA H20。与 Concerto/Sonata 唯一区别:self-distillation 的 upcast level 设 0(更快,作者称大规模下对下游影响可忽略)。
- 模型:Ablation 38M(channels 36/72/144/252/504,depths 2/2/2/6/2);Main 137M(54/108/216/432/576,depths 3/3/3/12/3)。带 task decoder 全参微调时整体 157.7M。
4. 结果对比¶
下表均以 mIoU/Acc 为指标,加粗 = Utonia。lin. = linear probing,dec. = decoder probing,f.t. = full fine-tune。
4.1 室内语义分割(mIoU)¶
| Method | ScanNet | ScanNet200 | ScanNet++ | S3DIS A5 |
|---|---|---|---|---|
| Concerto (lin.) | 77.3 | 37.4 | 45.6 | 73.5 |
| Utonia (lin.) | 77.7 | 36.4 | 44.7 | 74.7 |
| Concerto (dec.) | 79.5 | 37.8 | 48.3 | 75.5 |
| Utonia (dec.) | 80.3 | 38.0 | 48.5 | 76.2 |
| Concerto (f.t.) | 80.7 | 39.2 | 50.7 | 77.4 |
| Utonia (f.t.) | 81.1 | 39.6 | 49.0 | 78.1 |
室内 f.t. 多个 SOTA,但对 Concerto 的领先多在 0.4 量级;细粒度的 ScanNet200/++ 在 linear 下其实输给 Concerto,要靠非线性 decoder 才追平。
4.2 室外语义分割(mIoU)¶
| Method | NuScenes | Waymo | SemanticKITTI |
|---|---|---|---|
| Concerto (lin.) | 74.2 | 62.2 | 66.6 |
| Utonia (lin.) | 75.5 | 63.8 | 67.7 |
| Concerto (f.t.) | 82.0 | 69.2 | 71.2 |
| Utonia (f.t.) | 82.2 | 71.4 | 72.0 |
| Sonata (f.t., +PPT+额外数据,不可直接比) | 81.7 | 72.9 | 72.5 |
linear/decoder probing 下 Utonia 全面最优;但 full fine-tune 下,Utonia 在 Waymo/SemKITTI 反而不如单 domain 的 Sonata(71.4<72.9,72.0<72.5)——统一 encoder 在室外强微调时没有明确优势(Sonata 那行用了 PPT + 额外数据,作者也标注不可直接比)。
4.3 Object 分类 & part 分割¶
| Method | ModelNet40 (acc) | ScanObjectNN(H) mAcc | ShapeNetPart i.mIoU | PartNetE mIoU |
|---|---|---|---|---|
| Sonata (lin.) | 89.8 | 75.2 | 83.6 | 52.0 |
| Concerto (lin.) | 90.7 | 78.5 | 83.9 | 55.8 |
| Utonia (lin.) | 90.8 | 78.8 | 82.5 | 39.8 ⚠️ |
| Concerto (f.t.) | 94.1 | 86.7 | 86.1 | 60.8 |
| Utonia (f.t.) | 94.3 | 88.3 | 86.3 | 62.7 |
注意 PartNetE 的 linear probing:Utonia 39.8,比 Concerto 55.8 / Sonata 52.0 暴跌 ~16 点。这是全文最刺眼的回退(详见 §5.2)。f.t. 能拉到 62.7(最佳),但说明"part-level 语义在固定 linear readout 下变得不可线性解码"。
4.4 关键卖点:缺 color / normal 时的鲁棒性(mIoU)¶
| Method | ScanNet w/o color | NuScenes w/o color | NuScenes w/o normal |
|---|---|---|---|
| Concerto (lin.) | 36.8 | 42.7 | 43.6 |
| Utonia (lin.) | 77.0 | 74.5 | 75.7 |
| Concerto (f.t.) | 77.5 | 74.7 | 77.1 |
| Utonia (f.t.) | 78.5 | 81.1 | 82.1 |
这是 Causal Modality Blinding 最有说服力的证据:Concerto 一旦丢 color,linear probe 几乎崩盘(36.8/42.7),Utonia 几乎不掉。丢 normal 的损失普遍小于丢 color(normal 噪声大、可从局部几何粗略推断)。
4.5 下游应用¶
| 任务 | 指标 | Sonata | Concerto | Utonia |
|---|---|---|---|---|
| Manipulation(GraspVLA 仿真,3 次成功率) | SR | 74.7 | 80.0 | 82.1 |
| Spatial reasoning - ScanRefer | Acc@0.5 | 52.6 | 52.6 | 54.0 |
| Spatial reasoning - SQA3D | EM | 59.7 | 60.0 | 59.9 |
| Open-world part seg(PartObjaverse-Tiny,P³SAM) | avg mIoU | 55.57 | — | 57.95 |
4.6 关键消融¶
RoPE(linear mIoU,多 domain 设置)
| Benchmark | Single-Data | +RoPE | Multi-Data | +RoPE |
|---|---|---|---|---|
| ScanNet200 | 34.4 | 34.0 (−0.4) | 33.5 | 34.9 (+1.4) |
| Waymo | 60.5 | 62.1 (+1.6) | 56.6 | 59.2 (+2.6) |
| PartNetE | 44.1 | 42.4 (−1.7) | 43.5 | 44.6 (+1.1) |
RoPE 在单 domain 的室内/object 上反而掉点(−0.4 / −1.7),只在多 domain 才净正——它本质是 cross-domain 兼容性修复,不是普适更优的位置编码。室外 Waymo 即使单 domain 也涨(密度不均严重)。
Color Blinding 落点(linear mIoU)
| 策略 | ScanNet200 w/c. | ScanNet200 w/o c. | Waymo w/o c. |
|---|---|---|---|
| w/o drop | 34.7 | 9.3 | 54.5 |
| drop at loading | 34.9 | 31.7 | 58.1 |
| drop at masked views | 34.1 | 10.1 | 54.4 |
| drop at local views | 34.5 | 29.4 | 58.1 |
不丢时 w/o color 直接 9.3——崩了;loading 阶段丢恢复到 31.7。
Scale Up(lin. / ft.)
| 设置 | ScanNet200 | Waymo | PartNetE |
|---|---|---|---|
| 38M / 83k | 34.9 / 36.9 | 59.2 / 68.5 | 44.6 / 53.2 |
| 137M / 83k | 36.0 / 38.7 | 62.6 / 70.9 | 45.6 / 55.7 |
| 137M / all | 36.4 / 39.6 | 63.8 / 71.4 | 39.8 / 62.7 |
放大 backbone 一致涨(小模型是 capacity-limited);但继续放大数据会伤 PartNetE 的 linear(45.6→39.8),只在 ft 下涨——见 §5.2。
Object 增强:scene 只 jitter scale ±10%、x/y 旋转 ±π/64;object 用 ±50% scale + 全 SO(3) 旋转。减弱 object 旋转会让 ScanObjectNN(H) 从 66.9 掉到 63.0,但 PartNetE 反升到 47.5(因为 PartNetE 评测是 gravity-aligned,强 SO(3) 旋转反而伤它——作者承认 PartNetE 无法反映"重力擦除"的效果)。RoPE base 在 1~1000 间都稳,取 10。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- Pilot study 的诊断框架:把含糊的"domain shift"拆成三个可操作的轴(granularity / gravity / modality),每个都配了崩盘证据(Table A 的 34.4→29.1,缺 color 的 9.3)。这种"先解剖再开药"的写法比直接堆设计有说服力,也是全文最有复用价值的部分。
- Perceptual Granularity Rescale 抓住了根因:grid size = 度量单位这个观察是对的,"固定角分辨率观察者 → 缩放到共享粒度"的类比既直观又落地。pilot 表显示它能从 29.1 拉回 33.5,是三个设计里 ROI 最高的。
- Causal Modality Blinding 的效果是数量级的:Concerto 缺 color 时 linear 36.8、不丢 dropout 时 9.3,Utonia 77.0——这不是 marginal 提升而是"能用 vs 不能用"。而且"在 loading 丢最好、在 masked view 丢最差"的隔离实验干净,给出了为什么的机制解释(masked view 已信息有限,再丢会过度损坏)。
- 把 gravity 当成"粒度依赖的 prior"而非全局开关:scene 保 upright、object 上 SO(3),不强迫单一约定。更难得的是作者诚实地报告了 PartNetE(gravity-aligned 评测)其实更喜欢弱旋转,并指出该指标无法反映重力擦除——没有把不利消融藏起来。
- RoPE 与 rescale 的配对是对的:在对齐后的连续坐标上加 parameter-free 的相对几何 hint,对密度不均(室外 LiDAR 单 scan 近密远疏)增益最大(Waymo +2.6)。把"位置如何调制交互"和"基本单位对齐"分两步解决,逻辑清晰。
- 评测诚实度:主动替 baseline 补训它们原论文没报的 domain(Sonata→object,Concerto→outdoor/object),并明确标注 Sonata 室外那行用了 PPT + 额外数据"不可直接比"。
5.2 做得不够好 / 值得质疑的地方¶
- PartNetE linear probing 的回退是硬伤且解释不足:Utonia 39.8 vs Concerto 55.8 / Sonata 52.0,在唯一的细粒度 object part 基准上掉 16 点。作者用"不可线性解码、加 decoder/register 就好"带过,但"one encoder for all"恰恰最该在需要粒度统一的细粒度 object 任务上发光,结果这里最弱。SO(3) 旋转的解释只能覆盖一部分(PartNetE 评测 gravity-aligned)。
- 放大数据反而伤 object linear(45.6→39.8):这说明统一的 trade-off 不是免费的——更大更杂的 mixture 在 object linear-probe 这个度量上是净负的。论文把它框成"readout 问题"而非"表示问题",但 frozen-feature 下表示确实变差了,框架值得怀疑。
- "emergent behaviors" 的证据偏薄:abstract/intro 反复强调"只有联合训练才出现的有趣涌现行为",但落地证据主要是 (a) 模型够大时 object/indoor/outdoor 从竞争转为互利(Table scale-up),(b) 重力相关性减弱(定性 PCA 图)。没有任何定量的 emergence 指标;而且 38M 仍是竞争(capacity-limited),所以这更像"需要足够容量"而非真正的相变/涌现。
- 多数"SOTA"在噪声量级内:室内 f.t. 81.1 vs Concerto 80.7(0.4),很多领先 <1 点;同时 params 不完全可比(Utonia main 137M / ft 157.7M vs Concerto 137.4M,且混了 PPT-vs-direct)。"competitive"是更准确的描述。
- RoPE 在单 domain 室内/object 上掉点(−0.4 / −1.7),只在多 domain 净正。论文把 RoPE 当普适改进卖,但单 domain 数字说明它是 cross-domain 兼容性修复——叙事和证据有错位。
- granularity rescale 的关键超参没量化:方法正文全是定性的,"共享感知粒度"到底是多大的目标 grid size、各 domain 的 rescale factor 采样范围是什么,正文都没给(附录只给了 RoPE 的 jitter/scale 公式,没给 rescale range)。这对复现是硬缺口。
- cross-modal 预测被静默继承,成为混淆变量:Utonia 沿用了 Concerto 的 cross-modal joint prediction("有图像时用"),但消融只隔离了 RoPE/blinding/aug,没有隔离 cross-modal recipe 的贡献。Utonia 相对 Sonata 的部分增益可能来自 Concerto 的配方而非三个新设计。
- 下游增益小且可能挑选过:manipulation 仅 +2.1(单数字、3 次成功率、纯仿真);spatial reasoning 增益 <2 点,且 SQA3D 上 Concerto 反超(60.0>59.9)。VLA / reasoning 各只有一行结果,难支撑"也能助力 embodied/multimodal reasoning"的大标题。
- 室外 full fine-tune 不如单 domain Sonata(Waymo 71.4<72.9,SemKITTI 72.0<72.5)。统一 encoder 在最需要"通吃"价值的强微调室外场景反而落后,弱化了核心卖点。
- "+1M CAD assets" 的表述夸大:Cap3D 每 epoch 只子采样 90k,实际每轮 object 数据量适中。"250k + 1M"的 headline 让人以为 object 数据主导了每个 epoch,实情并非如此。
5.3 值得继续探讨的方向¶
- 修 linear-probe 与 ft 的鸿沟:作者自己提的 query-based decoder + global register /
[CLS]token——前者给 part seg 检索结构化信息,后者给 classification 干净的全局接口。这是最该先验证的。 - 量化"感知粒度":是否存在一个最优目标分辨率?能否在推理时按下游任务自适应 rescale(论文说 factor 可调,但没系统实验)。
- 隔离 cross-modal recipe 的贡献:做一个去掉 Concerto cross-modal prediction 的消融,才能说清三个新设计的真实增量。
- 为什么放大数据伤 object linear:是 domain interference 还是纯 readout?用 frozen-feature kNN(不带任何可学 head)测一下能区分。
- 4D / 时序预训练:现在只有 frame aggregation(pose-aligned 多帧给 teacher、单帧给 student),真正的 spatiotemporal 目标(cross-frame consistency、motion-aware)是自然延伸。
- 下一代 backbone:作者自己承认 sparse conv memory 重、部署有 kernel 依赖摩擦,限制 token budget / 分辨率 / 序列长度。换更 hardware-friendly 的几何 backbone 是 scaling 的瓶颈。
- 生成式 / latent-action 下游:目前下游全是判别式感知 + 轻量 fusion,把统一几何特征接到生成或策略学习里会更有意思。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://pointcept.github.io/Utonia
- 关键 baseline / 相关论文: PTv3(Wu et al. 2024,backbone)、Sonata(Wu et al. 2025,SSL recipe + geometry shortcut)、Concerto(Zhang et al. 2025,cross-modal SSL,最直接对手)、RoFormer/RoPE(Su et al. 2024)、DINOv3(Siméoni et al. 2025,坐标增强)、下游用到的 GraspVLA、P³SAM、Video-3D LLM