FASTer: 用神经动作 tokenizer 让自回归 VLA 又快又准¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: FASTer: Toward Efficient Autoregressive Vision Language Action Modeling via neural Action Tokenization
- 作者: Yicheng Liu, Shiduo Zhang, Zibin Dong, Baijun Ye, Tianyuan Yuan, … Jingjing Gong, Xipeng Qiu, Hang Zhao(清华、复旦、上海创智学院 Shanghai Innovation Institute、Galaxea AI、天津大学、港大、UCSD)
- arXiv 编号: 2512.04952(submitted 2025-12,投稿 ICLR 2026)
- 关键词: action tokenization, RVQ, autoregressive VLA, block-wise decoding, action expert, cross-embodiment, inference efficiency
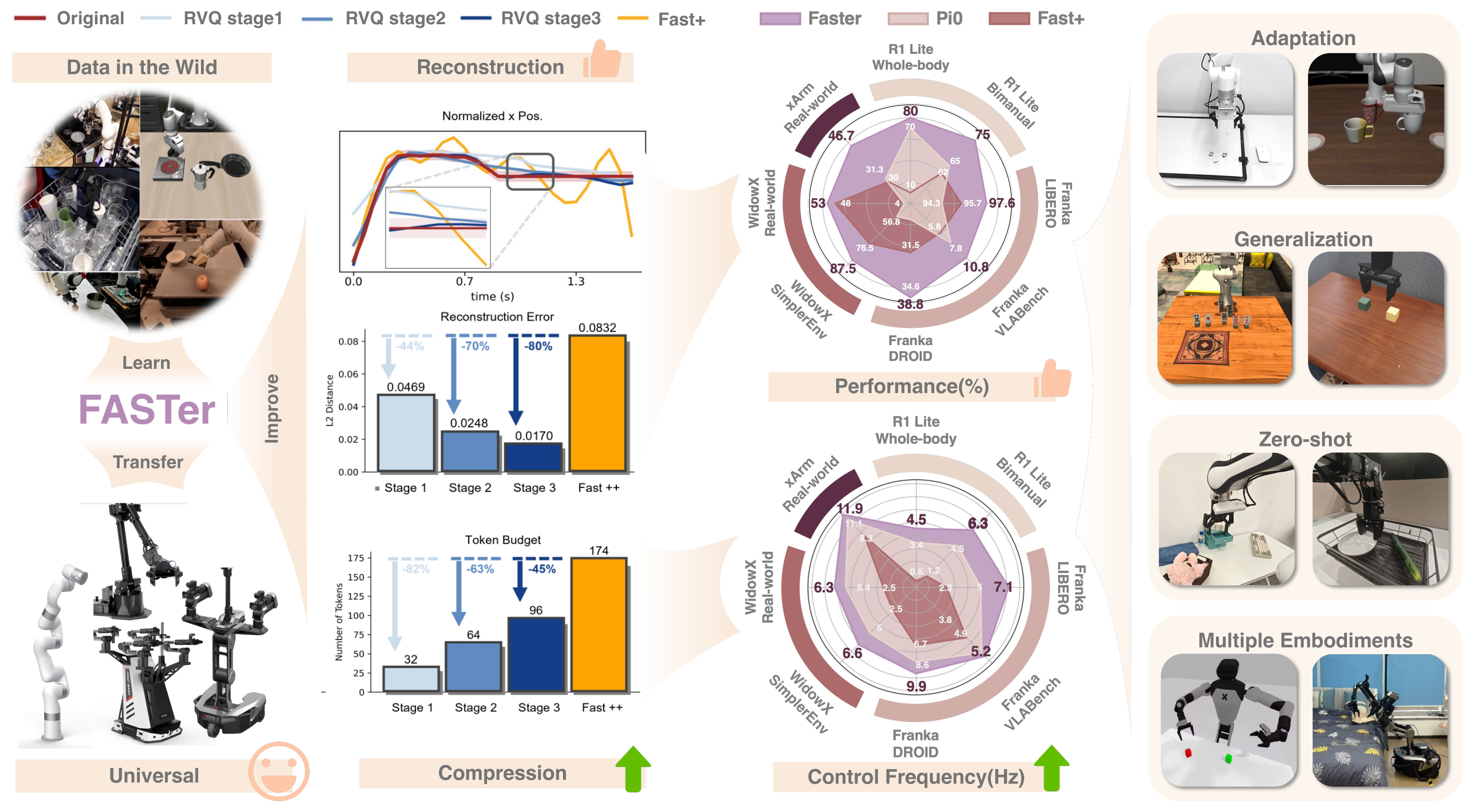 Figure 1:FASTer = 一个可学习的动作 tokenizer(FASTerVQ)+ 一个建立其上的自回归策略(FASTerVLA)。卖点是同时拿下「高压缩、快控制、强性能」,并跨 8 个真实/仿真本体验证。
Figure 1:FASTer = 一个可学习的动作 tokenizer(FASTerVQ)+ 一个建立其上的自回归策略(FASTerVLA)。卖点是同时拿下「高压缩、快控制、强性能」,并跨 8 个真实/仿真本体验证。
2. 文章介绍¶
2.1 解决的领域和问题¶
自回归(autoregressive, AR)VLA 把连续机器人动作离散化成 token,复用 VLM 的 next-token 范式。它相比 diffusion/flow-matching 路线(π₀ 类)有几个吸引人的属性:更强的指令跟随、更好的场景泛化、能迁移常识知识,而且架构上跟成功的 VLM 最相似。但 AR-VLA 长期被两件事卡住:
- tokenizer 质量:怎么把连续动作序列离散成 token 直接决定模型上限(类比 LLM/SpeechLLM 里 tokenizer 决定性能)。
- 推理慢:token 要逐个生成,每个都过一遍大 transformer,attention 复杂度让延迟随序列长度二次增长。FAST tokenizer 表示 2 秒动作要 150–200 个 token,对应约 3 秒 的推理延迟——whole-body control(高 DoF)尤其致命。
2.2 Motivation¶
作者把「好 tokenizer」拆成四条要求,并指出现有方法(尤其是 FAST = DCT+BPE)无法同时满足:
- i) 高压缩率:长序列要尽量少 token,才能快。
- ii) 强重建质量:token 少了信息空间就小,必须保证高保真,不能为压缩牺牲精度。
- iii) 2D 结构建模:动作序列天然是二维的——action 维(每个分量物理语义不同、冗余少)和 temporal/horizon 维(时间上高度冗余)。必须联合建模这两个耦合结构。
- iv) 灵活性:开箱即用地跨 backbone、任务、本体迁移。
核心洞察:FAST 这类 BPE 方案产出变长 token,作者实验发现「在变长 code 上训 VLA 比在定长表示上难得多」——这是 AR-VLA 训练不稳、学不动的隐藏元凶。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Naive binning | OpenVLA, RT-2 | 逐维均匀分桶,忽略动作空间结构,高频/灵巧数据上学不动 |
| 频域 + BPE | FAST / π₀-FAST | 变长 token(150–200/2s)→ 推理 3s;码表利用率低(48%)、有 10% 占比的 dominant token;隐含动作平滑先验;BPE 有数据集依赖 |
| 朴素 VQ | VQ-VLA, MiniVLA | 压缩比好但重建保真度差,LLM backbone 学到本就错误的 code,高精度任务受限 |
| Flow/Diffusion(非 AR 对照) | π₀, π₀.₅ | 精度高但弱在利用视觉/语言线索、指令跟随;多步采样延迟 |
2.4 论文解决方案(一句话)¶
用 transformer + RVQ 的神经动作 tokenizer(FASTerVQ)把动作 chunk 压成定长、结构化、coarse-to-fine 的离散 code,再用 block-wise 自回归(BAR)+ 轻量 action expert 的 VLA(FASTerVLA)并行解码这些 code,从而在压缩率、重建保真、推理速度、任务成功率上同时超过 FAST 与 π₀。
2.5 与前序工作的关系¶
- 直接对标 FAST / π₀-FAST(Pertsch et al. 2025,本库 FAST 笔记)——把 DCT+BPE 换成可学习的神经 VQ。
- action expert 思路来自 π₀(black2024pi_0),但这里 expert 是自回归解码 token、而非 flow matching。
- 姊妹论文 ActionCodec(2602.15397,同一作者群的 ICML 2026 投稿):FASTer 是「系统/工程」侧,ActionCodec 是「原理/理论」侧,反过来 cite 了 FASTer 的 BAR。两篇一起看才完整(见 §5.3)。
- 复用大量 off-the-shelf 组件:PaliGemma / Qwen2.5 / InternVL3.5 backbone;LIBERO、Simpler、VLABench、GalaxeaManipSim 仿真;Bridge、DROID、Galaxea 真机数据。
3. 方法介绍¶
3.1 形式化¶
策略每步收到 RGB 图像 \(I_t\)、本体状态 \(s_t\)、语言指令 \(l\),输出 horizon 长 \(H\) 的动作序列 \(A_{t:t+H}=(a_t,\dots,a_{t+H-1})\)。不直接回归连续动作,而是把每个 action chunk 表成离散 code \((z_1,\dots,z_N)\),VLA 自回归生成这些 code,再由 VQ decoder 解回连续动作。瓶颈在 token 序列长度 \(N\):逐 token 生成 → 延迟随 \(N\) 增长,且要求所有 token 都预测正确,变长时模型很脆。
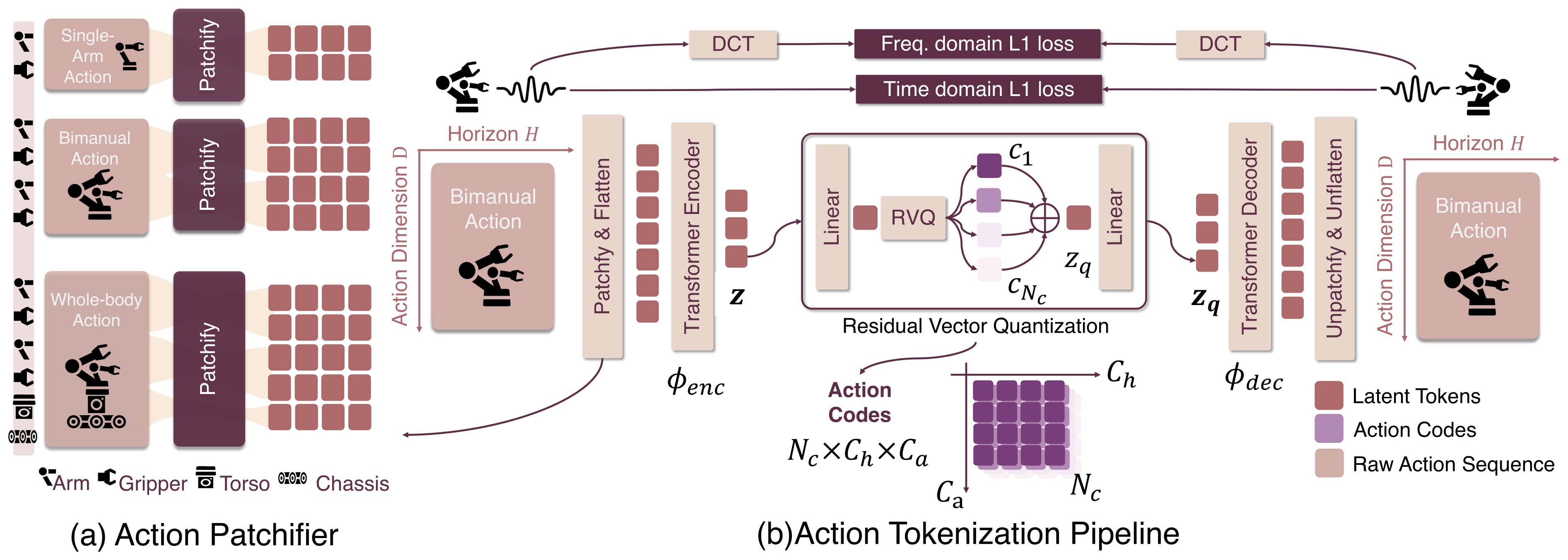 Figure 2:FASTerVQ。(a) 先按本体配置把 raw action 序列 patchify 成紧凑 token;(b) 用 DCT + L1 双重重建损失、RVQ 编成 \(N_c\) 个码本层,每层 reshape 成 \(C_h\times C_a\) 张量。
Figure 2:FASTerVQ。(a) 先按本体配置把 raw action 序列 patchify 成紧凑 token;(b) 用 DCT + L1 双重重建损失、RVQ 编成 \(N_c\) 个码本层,每层 reshape 成 \(C_h\times C_a\) 张量。
3.2 FASTerVQ:tokenizer¶
(1) Action Patchifier(非均匀分组)。 不直接把动作向量喂 transformer,而是先 patch:
- 时间维:均匀切成 \(m\) 组、每组长 \(h\)(利用动作的时间冗余/平滑性,提高每 token 信息密度)。
- 动作维:非均匀按物理含义分组(如末端位置、姿态、夹爪状态分开),每组 pad 到最大组长 \(d\)。原因:不同维度物理量分布极不均衡——夹爪常是二值开/关、底盘在臂操作时常为 0,混在一起训练困难。
得到 \((m\cdot h)\times(n\cdot d)\) 张量,flatten 成 \(\mathbf{a}^P\in\mathbb{R}^{(m\cdot n)\times(h\cdot d)}\) 的 patch 集合。本质是「非重叠卷积」式早期处理。
(2) Transformer Action AutoEncoder (TAAE) + RVQ。 encoder \(\phi_{\text{enc}}\) 把 patch 下采样成 latent \(\mathbf{z}\in\mathbb{R}^{C_h\times C_a}\),再做 \(N_c\) 级 Residual VQ:\(\mathbf{r}_1=\mathbf{z}\),\(\mathbf{r}_{i+1}=\mathbf{r}_i-\mathcal{Q}_i(\mathbf{r}_i)\),\(\mathbf{z}_q=\sum_i\mathcal{Q}_i(\mathbf{r}_i)\)。收集索引得离散张量 \(C\in\{1,\dots,|\mathcal{Z}|\}^{N_c\times C_h\times C_a}\)——这就是给 VLA 的 action token。RVQ 天然带 coarse-to-fine:早期层抓低频,后期层精修高频残差,既提升表示效率又稳定下游 VLA 训练。TAAE 结合 transformer 的全局感受野和卷积的局部建模/下采样,构成 information bottleneck。
(3) 训练目标(Eq. 1):
时域 \(\ell_1\)(逐步动作重建)+ 频域 DCT 上的 \(\ell_1\)(抓整体趋势)+ commitment loss。选 \(\ell_1\) 是因为对真实机器人数据里的极值噪声更鲁棒。码本用 EMA 更新 + dead code 重初始化。
3.3 FASTerVLA:策略¶
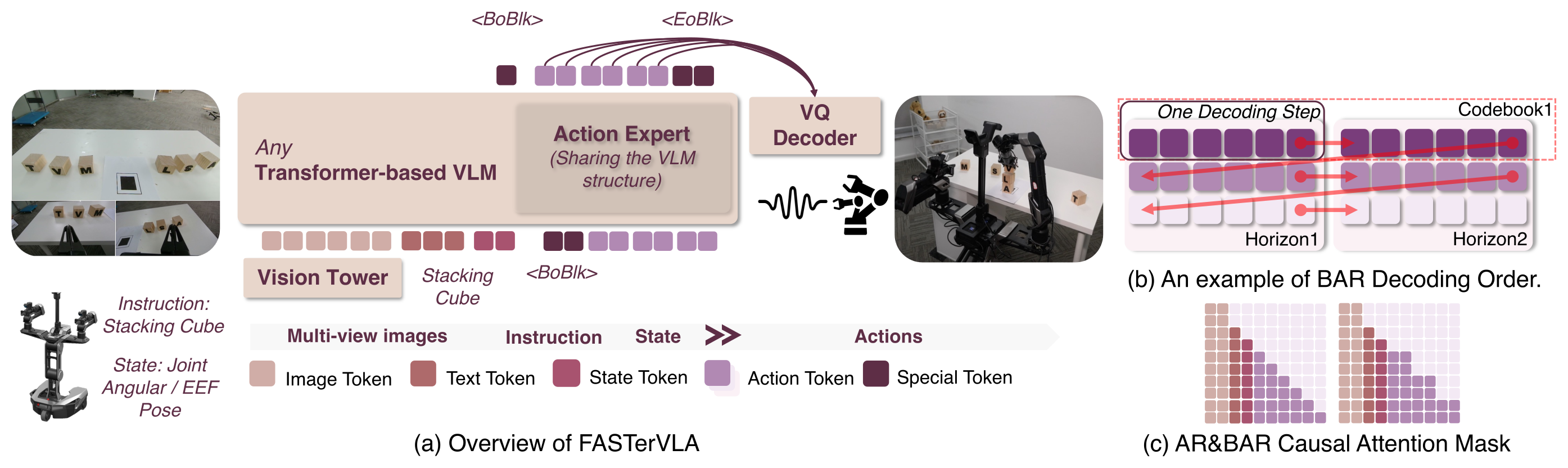 Figure 3:(a) 标准 VLM(vision tower + projector + LLM backbone)+ 轻量 action expert 自回归出离散 token,VQ decoder 解回连续动作;(b) 解码顺序——先沿 horizon、再换码本(codebook-first,红箭头),比 horizon-first 更稳;(c) block-wise causal mask:块内可互相 attend、块间因果。
Figure 3:(a) 标准 VLM(vision tower + projector + LLM backbone)+ 轻量 action expert 自回归出离散 token,VQ decoder 解回连续动作;(b) 解码顺序——先沿 horizon、再换码本(codebook-first,红箭头),比 horizon-first 更稳;(c) block-wise causal mask:块内可互相 attend、块间因果。
架构。 沿用 VLM 结构以兼容预训练 checkpoint。三个关键改动:
- Action embedding & 本体编码:embedding table 扩 \(|\mathcal{C}|\) 个 slot 装 action code;本体状态离散成整数当文本 token。
- RoPE + spacing augmentation:动作 token 是定长,naive 预测定长目标会 position overfitting。训练时给相邻 token 位置加小整数抖动 \(p_i=p_{i-1}+1+\epsilon_i\),\(\epsilon_i\sim\mathcal{U}[0,k]\)(\(k{=}2\)),推理时恢复固定间距(\(p_i=p_{i-1}+2\)),逼模型靠内容而非绝对位置。
- 轻量 action expert:仿 π₀,共享 backbone 架构但参数更少。backbone 编码 multimodal context 一次,expert 从这些特征自回归解码 token——减少对预训练权重的干扰,同时轻量高效。
Block-wise Autoregression (BAR)。 关键洞察:很多 action code 跨维度只是弱耦合(不同动作维物理语义独立、分布异构)。于是把 \(C\) 切成 \(J\) 个大小 \(B\) 的连续块,块内并行预测:
用 block-wise causal mask(块内互通、块间因果),并用 \(\langle\text{BoBlk}\rangle/\langle\text{EoBlk}\rangle\) 两个控制 token 在 block 模式与标准 AR 间无缝切换。当模型吐出 \(\langle\text{BoBlk}\rangle\) 时把它复制 \(B\) 份回喂以启动整块预测。
解码顺序。 3D code 张量 \(C\in\mathbb{Z}^{N_c\times C_h\times C_a}\) 跨码本/horizon/action 维。FASTerVLA 对每个码本先沿 horizon \(0\dots C_h-1\) 解码、再进下一码本(codebook-first),对齐 RVQ 的 coarse-to-fine 管线。每块并行 → 前向次数从 \(N\) 降到约 \(N/B\)。LIBERO 上块数 \(J\) 很小(约 3),相比 π₀ 最多 3× 加速。
3.x Implementation Details¶
- 硬件/规模:FASTerVQ 单臂版 8M 参数、全身版 13M 参数,8×H100 训练,约 300k step 收敛。码本 \(K{=}4096\)、latent 维 \(d{=}128\)、commitment \(\beta{=}0.25\)。AdamW lr=1e-4。
- FASTerVLA:AdamW lr=2.5e-5;推理 top-\(k\)=50、temperature 0.8;BAR block size = 8(WBC/双臂)/ 7(单臂);conditioning window = 1 step;动作 clip 到 \([-1,1]\)。
- 数据 mixture:三档 tokenizer——FASTer(S)/(L)/(XL),分别用于不同评测;(XL) 在更大数据上验证 scaling。
- 推理延迟(RTX 5090, PyTorch)(Table):
| 阶段 | Single(单臂, 7DoF/chunk20) | WBC(21DoF/chunk32) |
|---|---|---|
| image encoders | 16 ms | 23 ms |
| observation forward | 72 ms | 105 ms |
| AR forward | 6.4 ms × 21 | — |
| BAR forward | 7.4 ms × 3 | 8.51 ms × 12 |
| FASTerVQ detokenize | 2.7 ms | 7 ms |
| 总计 | 112 ms | 237 ms |
对照:同 backbone 下 LIBERO 上 FASTerVLA 112ms / π₀ 176ms / π₀-FAST 197–556ms;WBC 上 FASTerVLA≈π₀≈230ms,而 π₀-FAST 高达 1100–3000ms。瓶颈其实在 observation encoding(88–127ms),tokenizer 本身只占 2.7–7ms。
4. 结果对比¶
4.1 LIBERO + Simpler-Bridge 主表¶
| Model | LIBERO Avg | Simpler-Bridge Avg |
|---|---|---|
| Diffusion Policy | 72.4 | – |
| π₀ | 94.2 | 66.7 |
| π₀.₅ | 96.8 | – |
| OpenVLA-OFT | 97.1 | 6.25 |
| OpenVLA (AR) | 76.5 | 29.5 |
| π₀ FAST-D | 94.2 | 76.5 |
| FASTer w/o BAR | 95.4 | 81.0 |
| FASTer | 97.9 | 87.9 |
FASTerVLA 在 LIBERO 拿到 97.9% SOTA;Simpler-Bridge 87.9%,比第二名高 12.9pp(注:这里 OpenVLA-OFT 在 Simpler 上崩到 6.25 是已知的「OFT 不适配该 setting」,对比要谨慎)。
4.2 跨 backbone(LIBERO,FAST vs Ours)¶
| Backbone | FAST Avg | Ours Avg | Δ |
|---|---|---|---|
| Qwen2.5-0.5B | 84.15 | 87.00 | +2.85 |
| Qwen2.5-1.5B | 90.45 | 92.25 | +1.80 |
| Qwen2.5-3B | 91.30 | 95.45 | +4.15 |
| InternVL3.5-2B | 79.35 | 96.65 | +17.30 |
| PaliGemma2-3B | 93.50 | 94.80 | +1.30 |
最戏剧性的是 InternVL3.5-2B:用 FAST 时最弱(79.35),换 FASTerVQ 后跃居最强(96.65)。作者强调增益主要来自神经 VQ tokenizer 本身,BAR 只贡献较小增量。
4.3 关键消融¶
码表利用率(BridgeData):
| Metric | Fast | Fast+ | FASTer |
|---|---|---|---|
| \(N_{\text{vocab}}\) | 2048 | 2048 | 4096 |
| Usage % | 48.4 | 57.4 | 100.0 |
| \(F_{\max}\) % ↓ | 9.63 | 1.82 | 1.35 |
| 归一化熵 ↑ | 0.69 | 0.77 | 0.91 |
FASTer 码表 100% 利用、分布更均匀(熵接近 1)——作者论证「均匀活跃的码表 → 更强泛化与成功率」。
Action expert(AE)+ BAR 消融:
| 设置 | LIBERO SR | simpler-widow SR |
|---|---|---|
| No AE | 95.5 | 75.6 |
| AE (no pretrain) | 94.8 | 23.6 |
| AE (with pretrain) | 97.9 | 87.9 |
| 解码策略 | SR | Latency |
|---|---|---|
| Token-wise (AR) | 95.5 | 323 ms |
| Block-wise | 96.7 | 140 ms |
| Block-wise + AE (FASTer) | 97.7 | 140 ms |
注意 AE 在 simpler-widow 上「无 robotics 预训练时崩到 23.6」——AE 的收益高度依赖预训练。BAR 把延迟从 323→140ms(2.3×)且略升精度。
TAAE / 码表大小 / 残差深度(appendix):TAAE > CNN/Transformer 变体;码表 4096 最优,8192 出现 codebook collapse;残差层 2–3 最稳。
4.4 tokenizer 重建(VRR)与泛化¶
引入 Valid Reconstruction Rate (VRR) = 重建动作落在容差 \(\sigma\) 内的比例(比纯重建 loss 更贴近功能保真,因为大量低层误差只是马达/传感器噪声)。FASTerVQ 在各 \(\sigma\) 下 SOTA 且有清晰 data-scaling 曲线;FASTerVQ-XL 在物理有意义的 \(\sigma{=}10^{-3}\) 下近无损。跨本体/跨动作表示(Droid joint-velocity、Galaxea absolute joint-pos、Agilex delta joint-pos)均保持强重建——说明归一化动作空间里不同平台 chunk 共享可迁移结构。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 把「变长 token 难训」点破并用定长 RVQ 解决:FAST 的 BPE 产出变长序列是 AR-VLA 训练不稳的隐藏根因。FASTerVQ 输出定长 3D code 张量,配合 spacing augmentation 抑制 position overfitting——这是比「压缩率」更深的贡献。
- 非均匀 action-维 patchify:按物理语义分组(位置/姿态/夹爪分开),直接对治了「夹爪二值、底盘常 0」造成的分布异构训练难题,是很接地气的工程洞察。
- RVQ 的 coarse-to-fine 与 BAR 解码顺序天然契合:codebook-first 解码顺序对齐残差量化「先低频后高频」的语义,使 block 并行不破坏 spatio-temporal 结构——架构与算法是耦合设计的,而非拼凑。
- BAR 用控制 token 在 block / 标准 AR 间无缝切换:保留了和文本生成统一的接口,工程上优雅。
- VRR 指标:指出纯重建 loss 会被噪声主导、误导 tokenizer 选择,用容差内比例衡量「功能保真」更合理,也解释了为何 FAST 重建数字看着不差但下游崩。
- 延迟分解诚实:明确指出瓶颈在 observation encoding(88–127ms)而非 tokenizer,BAR 的加速主要在 token 多的 WBC 场景才显著——没有夸大。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 「BAR 只贡献小增量」自我削弱了一半卖点:跨 backbone 实验作者自承「增益主要来自 FASTerVQ,BAR 只加少量」。那么标题里并列的两个组件,实际是 tokenizer 唱主角;BAR 更像是为「不慢」服务的工程补丁,而非性能来源。主表 FASTer vs FASTer w/o BAR 在 LIBERO 是 97.9 vs 95.4、Simpler 87.9 vs 81.0,但 w/o BAR 在某些子项(如 LIBERO-Spatial 99.4)反而更高,BAR 的净收益其实参差。
- AE 收益严重依赖预训练,且无预训练时灾难性退化:simpler-widow 上 AE(no pretrain) 只有 23.6,远低于 No AE 的 75.6。这说明 action expert 不是「免费」的结构改进,而是高度依赖大规模 robotics 预训练 checkpoint——对没有 π₀-FAST 级别预训练资源的人不友好,也削弱了「即插即用」叙事。
- 基线对比的公平性:OpenVLA-OFT 在 Simpler-Bridge 崩到 6.25、VLABench 上的对照、π₀-FAST 的延迟数字(197–556ms 区间跨度极大)都缺乏足够的协议说明。Simpler 上把每任务 trial 从 24 提到 120「降噪」是好事,但这也意味着主表里别人引用的数字与本文重测可能不可比。
- 几乎全是「自家有利」的评测面:虽然号称 9 benchmark / 5 本体,但真正的公共可复现对照只有 LIBERO 和 Simpler;VLABench、GalaxeaManipSim、xArm/R1Lite 真机都大量是 in-house,且 FASTerVQ 的训练数据(Galaxea Open Dataset)与这些评测本体高度同源——「跨本体泛化」存在 tokenizer 预训练已见过相近分布的泄漏嫌疑。
- 码表 100% 利用 → 更强泛化是相关而非因果:Table 把「均匀码表分布」与「zero-shot 成功率」并列,但只有 Fast/Fast+/FASTer 三点,且混入了码表大小不同(2048 vs 4096)的变量。「entropy 高所以泛化好」更像事后归因。
- spacing augmentation 这类 trick 缺敏感性分析:\(k{=}2\)、推理固定间距 2 都是魔数,没给 ablation;RoPE 下定长目标的 position overfitting 究竟多严重也没量化。
- codebook collapse 在 8192 出现:意味着方法对码表大小敏感,4096 是 sweet spot 但没有给出选择的理论依据,换数据规模/本体后是否仍是 4096 存疑。
- 「whole-body control」证据偏弱:WBC 是论文反复强调的 FAST 痛点(150–200 token),但 WBC 的成功率结果主要在 R1Lite 真机 bar chart 里,缺干净的「FASTer vs π₀-FAST 在同一 WBC 任务上的 SR + 延迟」并列大表。
- 闭源依赖与可复现性:依赖 Galaxea 内部数据与真机平台,承诺「代码 upon publication」开源,但 tokenizer 预训练数据 mixture 的具体配比、真机评测协议难以独立复现。
- 与姊妹论文 ActionCodec 的张力:ActionCodec(同组)实验发现 token independence(无 residual grammar)反而更利于 VLA,而 FASTer 的核心恰恰是 RVQ + BAR 引入的 inter-block 依赖。两篇结论在「token 间该不该有依赖」上存在表面冲突(见 §5.3),FASTer 没有讨论这点。
5.3 值得继续探讨的方向¶
- FASTer 与 ActionCodec 的统一:ActionCodec 论证「高 overlap rate + 低 token budget + token 独立」最利于 VLA 优化,而 FASTer 靠 RVQ 的残差依赖 + BAR。一个干净的实验是:在同一 backbone 上比较「RVQ+BAR(有残差 grammar)」vs「单层 VQ 独立 token」的 VLA 优化曲线,看 §5.2-10 的张力到底谁对。ActionCodec 其实已把 BAR 作为一个 paradigm 接进来测了,可作为起点。
- BAR block size 与 overlap rate 的交互:FASTer 关心 block 并行,ActionCodec 关心 adjacent chunk overlap,二者是否能联合调优?
- 去掉对大规模 robotics 预训练的依赖:AE 无预训练即崩,能否设计一个 from-scratch 也稳的轻量 expert?
- 更激进的压缩 + 异步推理:源码里有一段被注释掉的 RTC-style 异步推理(overlap 执行与预测),作者最终没放进正文——这块若做实可进一步压 wall-clock。
- tokenizer 预训练数据泄漏的干净评测:真正 held-out 的本体(训练 mixture 完全没见过的机器人/动作表示)上重测 cross-embodiment,才能支撑泛化主张。
- codebook collapse 的机制:为何 8192 崩、4096 稳?是否与 RVQ 残差深度、EMA dead-code 重初始化策略耦合?
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 姊妹论文(同组,理论侧): ActionCodec (2602.15397)
- 关键 baseline / 相关论文: FAST / π₀-FAST(本库笔记), π₀(black2024pi_0), π₀.₅, OpenVLA / OpenVLA-OFT, VQ-VLA, MiniVLA