ActionCodec: 从 VLA 优化视角回答「什么才是好的动作 tokenizer」¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: ActionCodec: What Makes for Good Action Tokenizers
- 作者: Zibin Dong, Yicheng Liu, Shiduo Zhang, Baijun Ye, Yifu Yuan, Fei Ni, Jingjing Gong, Xipeng Qiu, Hang Zhao, Yinchuan Li, Jianye Hao(Knowin AI、清华、复旦、天津大学、上海创智学院)
- arXiv 编号: 2602.15397(submitted 2026-02,投稿 ICML 2026 preprint)
- 关键词: action tokenization, VQ, information theory, overlap rate, vision-language alignment, token independence, RVQ post-training, soft prompt
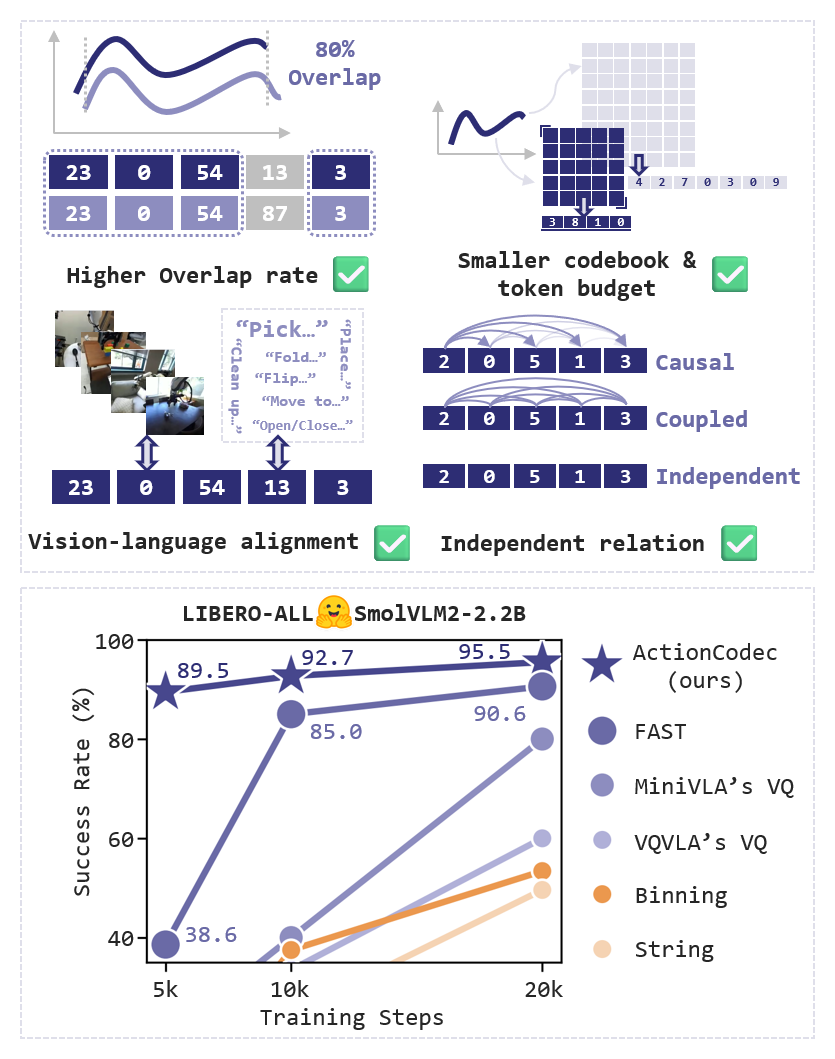 Figure 1:ActionCodec 系统梳理了影响 VLA 训练的 VQ tokenizer 设计要素,并把「最佳实践」打包。在 SmolVLM2-2.2B 上不加任何额外架构、直接自回归微调,LIBERO 训练效率与最终成功率都远超其它 tokenizer。
Figure 1:ActionCodec 系统梳理了影响 VLA 训练的 VQ tokenizer 设计要素,并把「最佳实践」打包。在 SmolVLM2-2.2B 上不加任何额外架构、直接自回归微调,LIBERO 训练效率与最终成功率都远超其它 tokenizer。
2. 文章介绍¶
2.1 解决的领域和问题¶
跟姊妹论文 FASTer 同一个圈子的问题:自回归 VLA 用离散 action token 复用 VLM 的 next-token 范式,tokenizer 是关键瓶颈。但 ActionCodec 的切入角度不同——它问一个更基础的问题:
什么才是好的 action tokenizer? —— 而且要从 VLA 优化动力学的视角回答,而不是从生成保真度(重建误差)的视角。
作者的核心批判:现有文献(包括 VQ 类方法)几乎都用「重建误差」评价 tokenizer,把它当黑盒,完全忽略它对 VLA backbone 训练动态的直接影响。这正是 VQ 方法理论上更优(少依赖启发式先验)却长期在下游任务输给简单方案的原因。
2.2 Motivation¶
把 VLA 训练的期望 NLL loss 分解:
第二项 条件熵 \(H(C|V,L)\) = supervisory ambiguity(监督模糊度):高熵 → 冲突梯度 → 模型被迫拟合随机噪声而非物理规律。最小化它等价于「给训练目标去噪」。再用互信息把它拆三块(Eq. 3):
由此推出三条可操作的设计指标(这是全文的理论骨架)。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷(从 VLA 优化视角) |
|---|---|---|
| Heuristic binning | OpenVLA, VLA-0 | 逐维分桶,训练效率低、忽略动作空间结构 |
| String 表示 | VLM2VLA (hancock) | token budget 爆炸(779 token)、延迟数秒、无性能收益 |
| 频域 + BPE | FAST | 固定几何先验 → 跨本体迁移弱;overlap rate 仅 19%(拓扑不稳定) |
| 朴素 VQ | VQ-VLA, MiniVLA | 当黑盒优化重建,不懂哪些 VQ 属性帮/害 VLA 优化 |
2.4 论文解决方案(一句话)¶
用信息论把「好 tokenizer」拆成 高 overlap rate(低 artifact entropy)+ 小 token budget/vocab(合适 capacity)+ 高 vision-language alignment + token 独立(无 residual grammar) 四条原则,据此造出 ActionCodec——一个不改 VLA 架构就能大幅提升训练效率与抗过拟合的 VQ tokenizer,并配 RVQ 后训练 + 本体 soft-prompt 两个工程增强。
2.5 与前序工作的关系¶
- 姊妹论文 FASTer(2512.04952,同作者群):ActionCodec 反过来 cite 了 FASTer(
liu2025faster),并把 FASTer 的 BAR 当作三个「可整合的 VLA paradigm」之一来测(ActionCodec-BAR 是它的最强变体)。FASTer 偏系统/工程,ActionCodec 偏原理/理论——两篇是同一研究线的「why」与「how」。 - 把 PD(OpenVLA-OFT 的并行解码)/ KI(π₀.₅ 的 knowledge isolation diffusion expert)/ BAR(FASTer) 三种主流范式都接进来验证 tokenizer 的通用性。
- backbone 复用 SmolVLM2(256M/500M/2.2B)、Qwen2.5VL-3B、InternVL3.5-2B。
3. 方法介绍¶
3.1 形式化与三条原则¶
策略 \(\pi_\theta(A|V,L)\),动作 \(A\in\mathbb{R}^{T\times D}\) 经 VQ tokenizer(encoder \(\mathcal{F}\) + decoder \(\mathcal{G}\) + 码本 \(\mathcal{B}\))离散成 token 序列 \(C\)。基于 Eq. 3 的熵分解,三条原则:
(a) Overlap Rate(对应 Artifact Entropy \(H(C|A)\))。 VQ encoder 数学上确定,理想下 \(H(C|A){=}0\);但真实控制有噪声,作者定义:
即「无穷小扰动诱发的 token 熵」——量化量化边界的敏感度。高 artifact entropy = 微小传感器噪声就让 token 在不同 code 间乱跳 → 给 VLA 注入 aleatoric uncertainty。用相邻 chunk 的 overlap rate (OR) 作为可观测代理:时间近邻视觉/语言几乎相同,若 token 序列却发散,说明拓扑不稳。OR 越高越好。
(b) Capacity(对应 \(I(C;A)\))。 \(I(C;A)\approx H(C)\le n\log_2 S\),由 token budget \(n\) 和 vocab size \(S\) 共同决定。够用即可——容量过剩会编码高频噪声,减小 \(n,S\) 简化 VLA 的学习流形。
(c) Perceptual Alignment vs Residual Grammar(对应 \(I(C;V,L)\))。 用链式法则拆单个 token 的信息来源:
VL alignment = 环境 grounding;residual grammar = 对自回归历史的依赖。要提高前者、抑制后者,否则模型过度依赖时间先验、忽视实时视觉反馈。
 Figure 2:ActionCodec 用 Perceiver-like transformer——可灵活建模不同 token 关系、支持变长动作序列编码。query 侧的 learnable embedding 正好用来挂 soft-prompt。
Figure 2:ActionCodec 用 Perceiver-like transformer——可灵活建模不同 token 关系、支持变长动作序列编码。query 侧的 learnable embedding 正好用来挂 soft-prompt。
3.2 三个验证实验(best practices 的来源)¶
所有验证都不看重建指标,而是直接拿 tokenizer 去微调 SmolVLM2-256M 当 VLA,看 LIBERO-Goal 成功率。
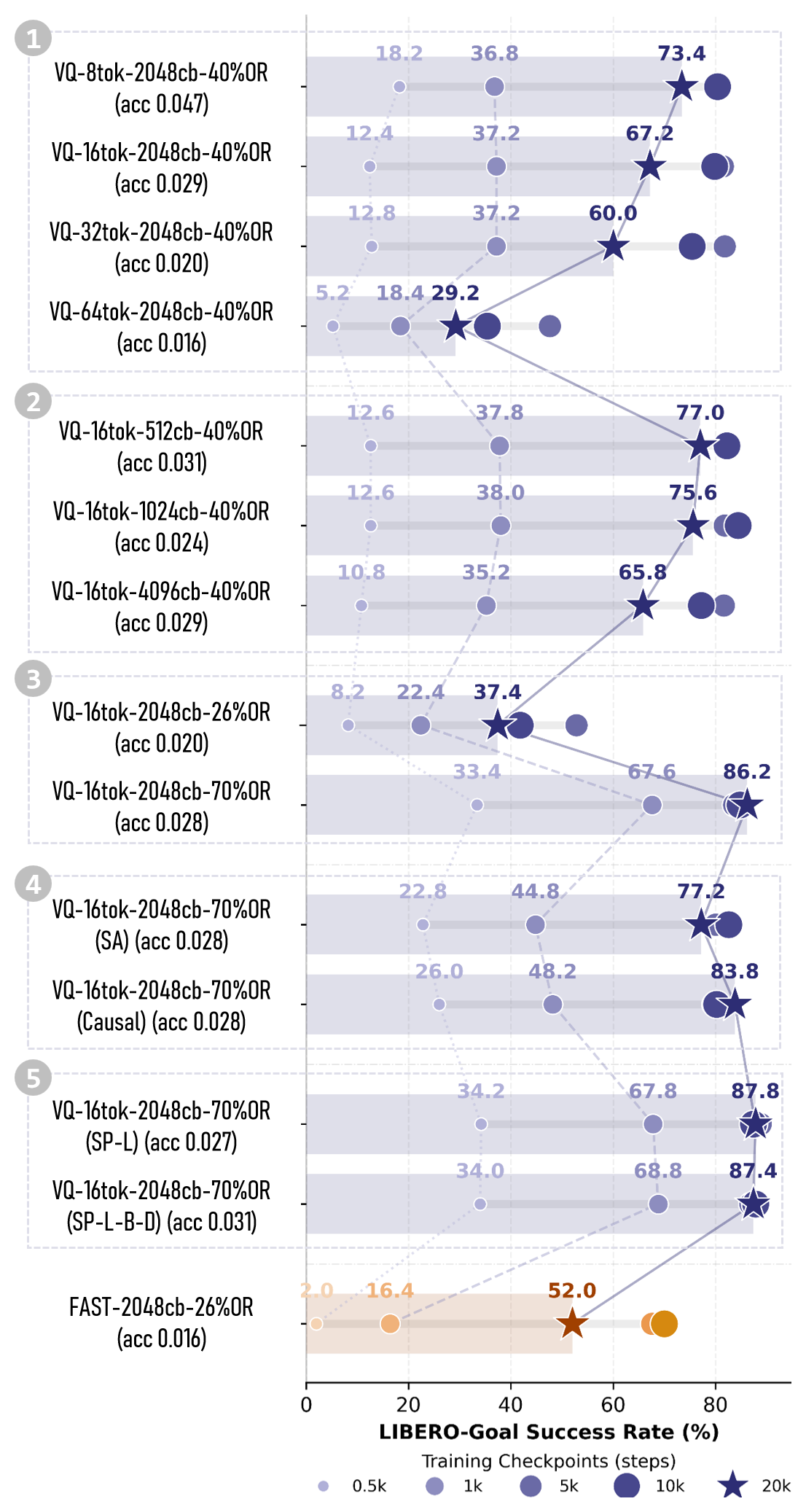 Figure 3:LIBERO-Goal 上不同设计选择的学习曲线。后缀:acc=L1 重建误差, tok=token budget, cb=vocab, OR=overlap rate, SA=self-attention, Causal=带因果 mask 的 SA, SP=soft-prompt 训练。
Figure 3:LIBERO-Goal 上不同设计选择的学习曲线。后缀:acc=L1 重建误差, tok=token budget, cb=vocab, OR=overlap rate, SA=self-attention, Causal=带因果 mask 的 SA, SP=soft-prompt 训练。
① Overlap Rate。 用对比损失合成 OR=26%/40%/70% 三个变体。OR 越高,训练效率、收敛、鲁棒性全面提升:70% OR 的 VLA 在仅 500 步就到 33.4% 成功率,而 naive VQ-VAE 8.2%、FAST 2%。t-SNE 显示高 OR 让 latent 更早形成清晰簇且训练中更稳(抗过拟合)。
② Vocab Size & Token Budget。 扫 \(n\in\{8,16,32,64\}\)、\(S\in\{512,...,4096\}\)。结论:这俩主要决定抗过拟合能力,且 token budget \(n\) 的影响远大于 vocab \(S\)。\(n\) 增大 → latent 簇过度分散 → 易抓高频噪声/虚假相关;\(n,S\) 太小又有重建惩罚。Sweet spot:\(S{=}2048, n{=}16\)。
③ VL Alignment vs Residual Grammar。 用 TCL(time contrastive)+ CLIP 损失提升 VL alignment:CLIP 让 VLA attention 聚焦指令相关物体,TCL 偏向数据集特定 demo pattern(如特定抓取点);两者都提升 OR 和结构性。
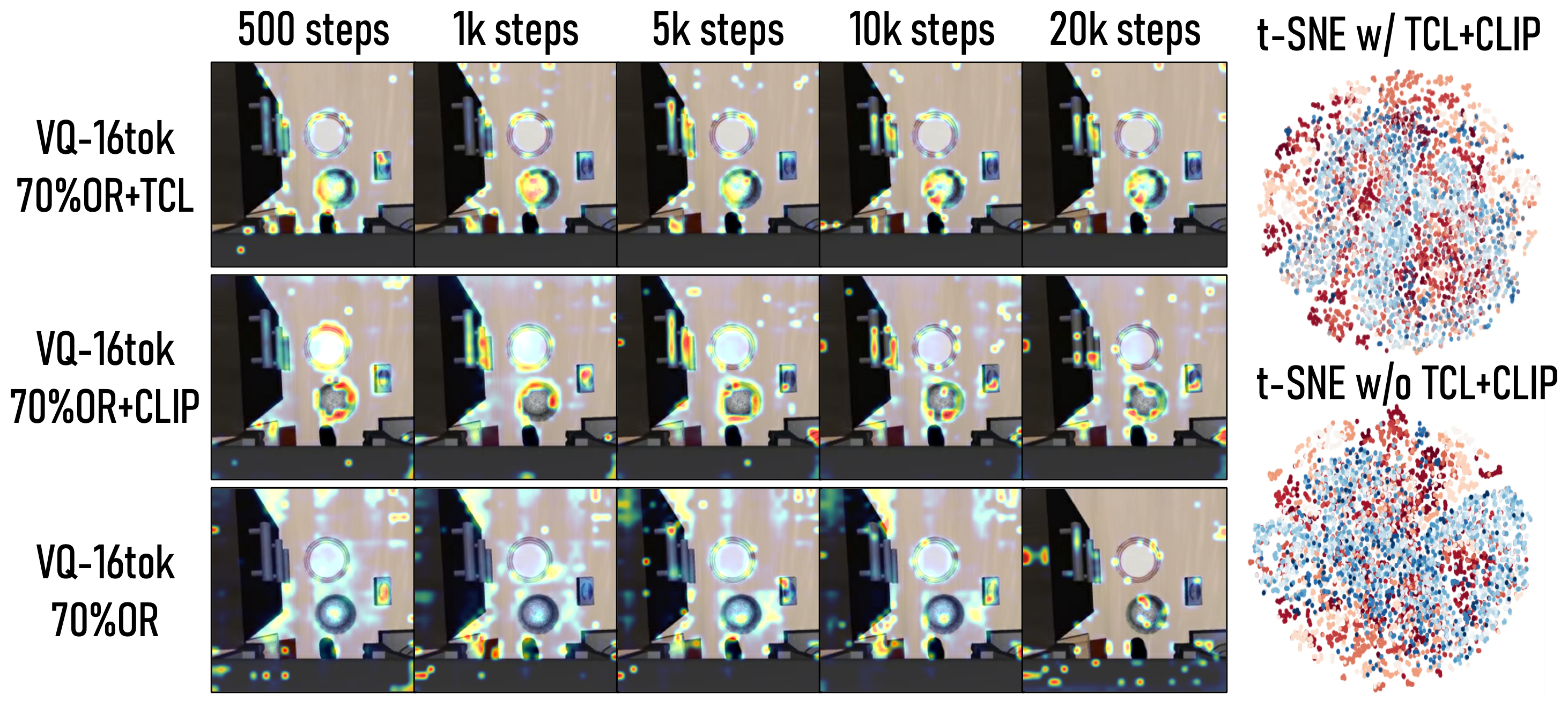 Figure 4:(左) CLIP vs TCL tokenizer 的 VLA attention map;(右) 40 个 LIBERO 任务的 latent t-SNE——TCL/CLIP 训练比单纯动作扰动产生更结构化的簇。
Figure 4:(左) CLIP vs TCL tokenizer 的 VLA attention map;(右) 40 个 LIBERO 任务的 latent t-SNE——TCL/CLIP 训练比单纯动作扰动产生更结构化的簇。
关于 residual grammar:对比 Perceiver(token 独立)、Self-Attention、Causal-SA。反直觉结论——内部 attention 虽提升 residual grammar,却损害 VLA 性能,因为它让模型过度依赖历史 token。扰动实验(Fig. 5)显示独立 token 显著更鲁棒;SA/Causal 对序列早期错误敏感 → temporal hallucination(无视实时视觉反馈)。故主张 decoupled、独立 token。
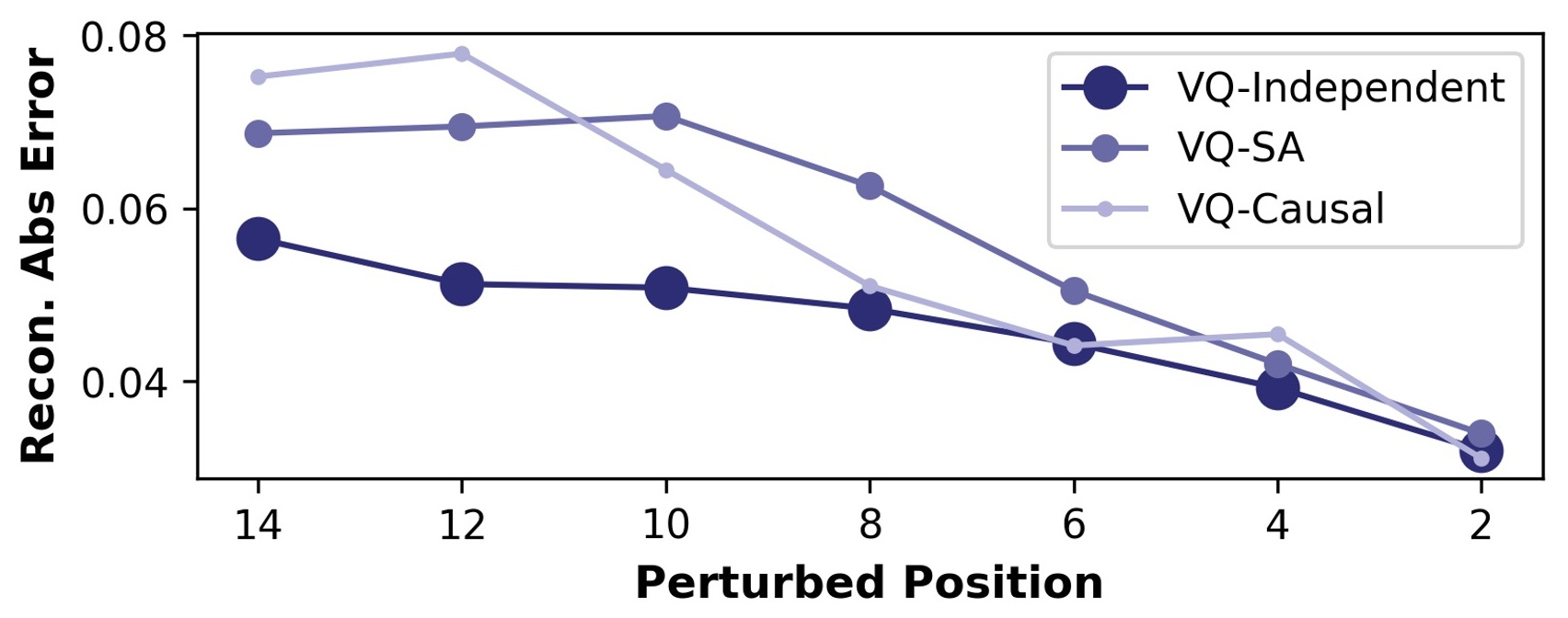 Figure 5:token 扰动下的误差传播。VQ-Independent 维持稳定低误差,SA/Causal 一旦早期 token 出错就误差爆炸——支撑「解耦 token、最小化 residual grammar」。
Figure 5:token 扰动下的误差传播。VQ-Independent 维持稳定低误差,SA/Causal 一旦早期 token 出错就误差爆炸——支撑「解耦 token、最小化 residual grammar」。
3.3 ActionCodec:两个工程增强¶
- Embodiment-specific Soft-prompts。 Perceiver 的 query 侧本就需要 learnable embedding,正好给每个本体一个专属 soft-prompt(共享全局网络蒸馏通用机器人先验,soft-prompt 捕捉各平台机械约束/控制频率),时间戳用 Fourier embedding。从而在 LIBERO/Bridge/DROID 等异构数据上做大规模预训练,并支持 zero-shot action re-targeting + 加速新平台微调。
- RVQ Post-training。 矛盾:标准 RVQ 提保真度但把 OR 压到 <20%,破坏 VLA 训练。解法——先训单层 VQ 把 OR 和 alignment 拉满,再冻结 encoder + 主码本,加残差码本只降重建误差。第一码本的 token 与原 VQ 完全一致,只需把后训练的 RVQ decoder 权重拷回 VQ 模型,就「零代价」提保真且不动 token 化过程,还兼容 BAR。
3.x Implementation Details¶
- backbone:SmolVLM2(256M/500M/2.2B),vocab 扩展后全参数自回归微调,无额外架构改动。
- tokenizer 默认 \(n{=}16\) tokens、\(S{=}2048\)、horizon 20;RVQ 后训练残差深度 \(L{=}3\)。
- ActionCodec-BAR 用完整 RVQ tokenizer;其余模型用「VQ 版 token + 后训练 RVQ decoder」。
- 预训练数据:LIBERO + BridgeData + DROID(+ SO100 社区数据 22.9K episodes 用于 SO100 实验)。
- 真机:SO100(低成本臂,ShapeSorter 插块)、xArm(PickVeg)。
4. 结果对比¶
4.1 LIBERO 主表(成功率 %,Pt.=是否 robotics 预训练)¶
| Model | Pt. | Avg | Avg Rank |
|---|---|---|---|
| OpenVLA-OFT | Y | 97.1 | 2.5 |
| π₀.₅ | Y | 96.8 | 2.5 |
| π₀ | Y | 94.2 | 4.5 |
| π₀ FAST | Y | 85.5 | 7.4 |
| SmolVLM2-2.2B + Binning | N | 53.4 | 15.5 |
| SmolVLM2-2.2B + String | N | 49.6 | 15.5 |
| SmolVLM2-2.2B + FAST | N | 90.6 | 9.4 |
| ActionCodec (256M) | N | 92.3 | 7.5 |
| ActionCodec (2.2B) | N | 95.5 | 3.8 |
| ActionCodec-PD | N | 95.6 | 3.0 |
| ActionCodec-KI | N | 94.3 | 5.5 |
| ActionCodec-BAR | N | 97.4 | 1.0 |
核心卖点:ActionCodec-BAR 无任何 robotics 预训练就拿到 97.4% SOTA,甚至超过有大规模预训练的 π₀.₅/OpenVLA-OFT。且 256M/500M 小 backbone + ActionCodec 就能超过别家 2.2B backbone——「动作表示的质量和 VLM 规模一样关键」。训练效率上 5K step 即达 89.5%(FAST 同点 38.6%)。
4.2 效率(LIBERO)¶
| Tokenizer | Token Budget | OR | Latency(s) | Throughput(action/s) | SR% |
|---|---|---|---|---|---|
| Binning (h=20) | 140 | 39% | 4.9 | 4.1 | 3.5 |
| String (h=20) | 779 | 28% | 33.8 | 0.6 | 20.4 |
| MiniVLA's | 7 | 40% | 0.7 | 11.1 | 82.6 |
| FAST | 24.3 | 19% | 1.5 | 13.1 | 90.6 |
| ActionCodec | 16 | 72% | 0.9 | 22.0 | 95.5 |
OR 这一列最能说明问题:FAST 仅 19%,ActionCodec 72%——直接印证「高 OR → 高 SR」的主张。
4.3 SimplerWidowX(zero-shot/OOD)¶
ActionCodec-BAR(无预训练)Avg 65.2,在「无预训练」组里 Rank 1.3(对照 MiniVLA 49.0);放进「有预训练」组也拿 Rank 2.0(仅次于 π₀ 67.9)。
4.4 真机¶
- SO100-ShapeSorter(插块,富含 recovery 行为):只有带 co-training(22.9K 社区数据) 的 ActionCodec 能学会失败后的纠正/重试策略;w/o CT 在 Place 阶段一旦错位就卡死。结论:小规模任务数据里虽有 recovery 轨迹,但需要 co-training 的多样先验才能让 VLA 真正内化这些长尾行为。
- xArm-PickVeg:w/ PT 82.5% > w/o PT 74.1% > π₀ 75.0 > π₀ FAST 72.5。预训练带来更低 L2 重建误差 + 更高 OR → 更好控制。
4.5 消融¶
| ID | Co-Train | Soft Prompt | RVQ-PT | VLM | LIBERO Avg |
|---|---|---|---|---|---|
| 0 | ✗ | ✗ | ✓ | SmolVLM2 | 92.0 |
| 1 | ✓ | ✗ | ✓ | SmolVLM2 | 92.7 |
| 2 | ✓ | ✓ | ✗ | SmolVLM2 | 95.2 |
| 3 | ✓ | ✓ | ✓ | SmolVLM2 | 95.5 |
| 4 | ✓ | ✓ | ✓ | Qwen2.5VL | 95.1 |
| 5 | ✓ | ✓ | ✓ | InternVL3.5 | 94.6 |
- Soft prompt 关键:去掉(ID1)让多样预训练收益几乎归零(92.7 vs 95.5)。
- RVQ 后训练影响很小(ID2 vs 3:95.2 vs 95.5)——坐实了核心论点:拓扑稳定性(OR)比绝对保真度更重要。
- backbone 无关:SmolVLM2/Qwen/InternVL 都稳(94.6–95.5)。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 把 tokenizer 评价从「重建保真」搬到「VLA 优化动力学」:NLL = KL + \(H(C|V,L)\) 这一步分解,把「为什么 VQ 理论好却下游差」讲清楚了——监督信号的条件熵才是元凶。这是全文最有价值的视角转换。
- Overlap Rate 作为可观测代理 + artifact entropy 的定义:用「相邻 chunk 的 token 重叠率」量化拓扑稳定性,既有信息论解释又能直接测、直接优化。OR 19%→72% 与 SR 的强相关是漂亮的支撑证据。
- 反直觉的 token-independence 结论:实验证明 self-attention/causal 提升了 residual grammar 却损害 VLA(temporal hallucination、对早期错误敏感),主张独立 token。这是对「更强自回归依赖更好」直觉的有力反驳,也和很多人默认的 RVQ/AR 设计相左。
- RVQ post-training 解 OR-保真度矛盾:冻结第一码本保证 token 不变、只让残差码本降误差、把 decoder 拷回——「零代价提保真且不破坏训练效率」是个干净的工程 trick。
- 无 robotics 预训练就 SOTA + 小 backbone 超大 backbone:256M+ActionCodec 超别家 2.2B,强力支撑「表示质量 ≈ 模型规模」的论点,对算力受限者有现实意义。
- soft-prompt 的统一 latent 空间:Bridge→LIBERO/DROID/xArm 的 action transfer 显示一致运动趋势,是 cross-embodiment 较有说服力的定性证据。
5.2 做得不够好的地方 / 值得质疑的地方¶
- 理论分解的「实操性」是软的:Eq. 3 的三项分解优雅,但 \(I(C;A)\)、\(I(C;V,L)\) 在高维连续动作上无法真正估计,最终全靠 OR 这一个代理 + 经验扫参。所谓「信息论指导」更像是事后给经验最佳实践套了个理论外壳——四条原则里只有 OR 真正被定量验证。
- 「token 独立更好」与姊妹论文 FASTer 直接冲突:FASTer 的核心正是 RVQ 残差依赖 + BAR 的 inter-block 依赖。同一作者群的两篇论文在「token 间该不该有依赖」上结论相反——而 ActionCodec 的解法是把 BAR 的依赖限制在「同一时间步的码本层之间、用 RVQ 后训练保持第一层 token 不变」,等于偷偷把 FASTer 的 grammar 做了阉割。这个张力没有被正面讨论,读者需要自己拼。
- OR 是被「设计」出来的,因果方向存疑:OR 三档(26/40/70%)是用对比损失人为合成的。高 OR 变体同时改变了 latent 几何,无法排除「是对比损失本身(而非 OR 数值)带来增益」。OR 与 SR 的相关,未必是 OR→SR 的因果。
- 主表的灰色行容易误导:LIBERO 表里 ActionCodec(2.2B)/BAR 在「Pt.=Y」分组里以灰色重复列出,和有真实 robotics 预训练的 π₀.₅/OFT 同框比较。虽然标了灰色和 Pt.=N,但「无预训练却排进预训练组榜首」的叙事在视觉上被刻意强化。
- co-training 的功劳归因:SO100 recovery 行为「只有 co-train 学得会」很吸引人,但 co-train 用了 22.9K 额外社区数据,w/o CT 只有任务数据——这其实是数据量 vs 数据多样性未解耦,把功劳全记给「ActionCodec 的先验」过强。
- RVQ 后训练「影响很小」削弱了它自己:ID2 vs ID3 只差 0.3%。作者用它论证「OR > 保真度」,但反过来也说明这个被单列一节的工程增强对最终成功率几乎无贡献,更多是为兼容 BAR 服务。
- 几乎只在 LIBERO 上做原理验证:三个核心 ablation(OR/budget/grammar)全在 LIBERO-Goal 单 suite + SmolVLM2-256M 上,「best practices」的普适性靠这一个简单仿真任务支撑,外推到真机/高 DoF 的证据薄弱。
- \(S{=}2048,n{=}16\) 这组魔数与数据集绑定:在 LIBERO 上扫出来的最优,换控制频率/DoF 差异大的本体未必成立,缺跨数据集的稳健性验证。
- 延迟仍不算低:ActionCodec 0.9s 延迟(虽优于 FAST 1.5s)对高频闭环仍偏高,throughput 22 action/s 是靠 chunk 摊薄,真实单次前向延迟没拆开给。
- SimplerWidowX 只比了极少基线:无预训练组只对 MiniVLA 一个,样本太薄。
5.3 值得继续探讨的方向¶
- 与 FASTer 的正面对决:在同一 backbone/数据上把「ActionCodec 独立 token」与「FASTer RVQ+BAR 残差依赖」做受控对比,量化 §5.2-2 的张力——到底 residual grammar 在什么 horizon/任务下才有害。
- OR 的因果消融:固定对比损失,只改 OR 数值(如不同 margin),分离「对比损失」与「OR 本身」的贡献。
- artifact entropy 的直接估计:能否不依赖 OR 代理,直接用噪声注入估 \(H(C|A)\),作为 tokenizer 选择的训练时正则?
- token budget vs 抗过拟合的理论刻画:\(n\) 比 \(S\) 影响大这一经验现象,能否用学习流形复杂度给出更紧的界?
- soft-prompt 扩到真正 in-the-wild 本体:当前只 3 个数据集,scaling 到几十种本体后 soft-prompt 是否仍能维持统一 latent。
- 把四条原则做成 tokenizer 的可微目标:现在是分别用 TCL/CLIP/对比损失拼凑,能否设计单一目标同时优化 OR + alignment + 独立性。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 姊妹论文(同组,系统侧): FASTer (2512.04952)
- 数据集: SO100-ShapeSorter, xArm-PickVeg
- 关键 baseline / 相关论文: FAST / π₀-FAST(本库笔记), π₀ / π₀.₅, OpenVLA-OFT(PD), VQ-VLA, MiniVLA, VLA-0, SmolVLA