Agentic-VLA: Efficient Online Adaptation for Vision-Language-Action Models¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Agentic-VLA: Efficient Online Adaptation for Vision-Language-Action Models
- 作者: Ruofan Jin, Zaixi Zhang(Scinetics)
- arXiv 编号: 2605.22896(2026-05 提交,目标 ICML 2026)
- 关键词: VLA, online adaptation, RL fine-tuning, GRPO, adaptive reward, LLM-driven curriculum, VLM-guided exploration, weight memory, LIBERO, RoboTwin
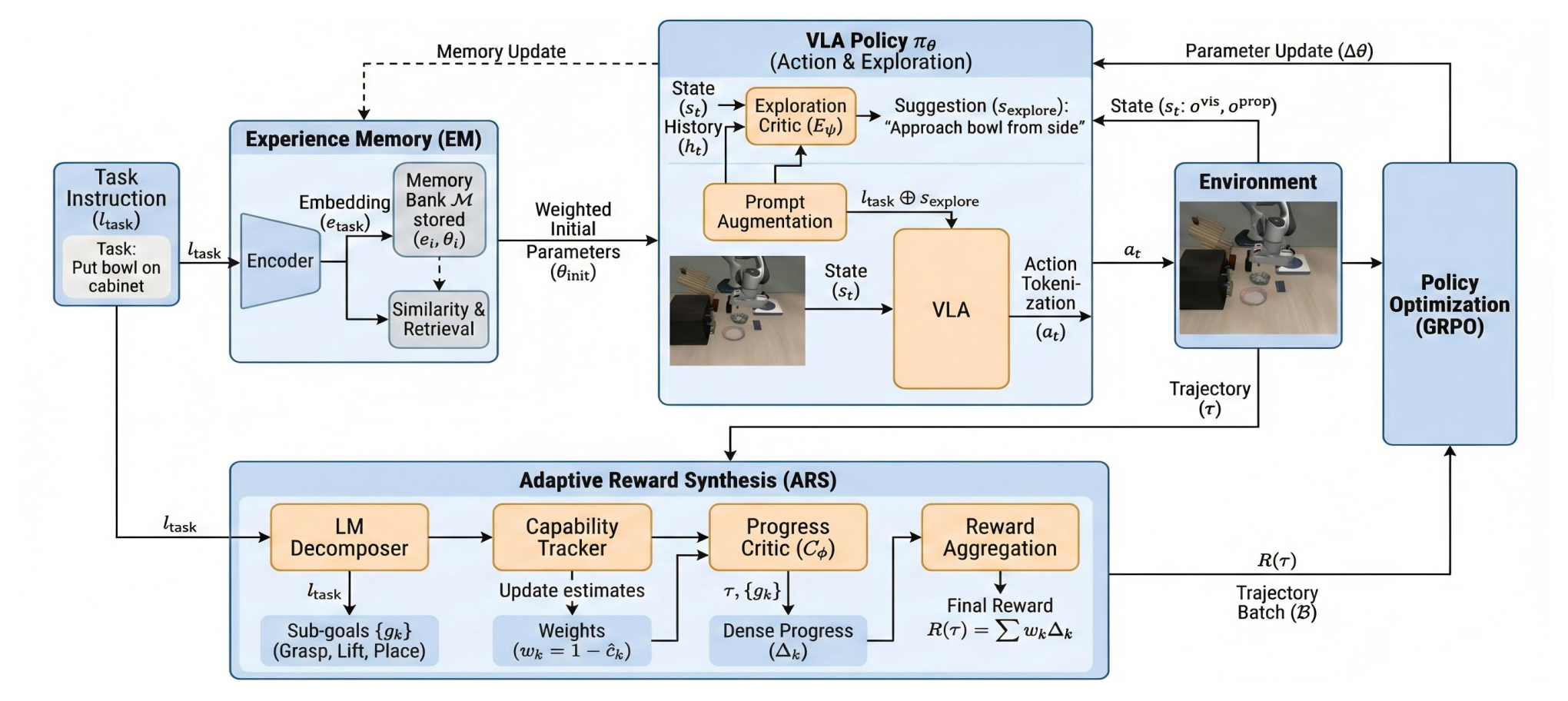 Figure 1:Agentic-VLA 把"online adaptation"包装成三件套——Experience Memory(按任务 embedding 取回历史权重做 warm start)→ Language-Guided Exploration(VLM 给自然语言提示拼到 task instruction 后引导 rollout)→ Adaptive Reward Synthesis(按当前子目标掌握度动态调权重,喂给 VLAC progress estimator 给出 dense reward)→ GRPO 更新策略。三个模块的依赖在图里没标但很重要:每一步都吊着一个独立的外部大模型。
Figure 1:Agentic-VLA 把"online adaptation"包装成三件套——Experience Memory(按任务 embedding 取回历史权重做 warm start)→ Language-Guided Exploration(VLM 给自然语言提示拼到 task instruction 后引导 rollout)→ Adaptive Reward Synthesis(按当前子目标掌握度动态调权重,喂给 VLAC progress estimator 给出 dense reward)→ GRPO 更新策略。三个模块的依赖在图里没标但很重要:每一步都吊着一个独立的外部大模型。
2. 文章介绍¶
2.1 解决的领域和问题¶
机器人 VLA(Vision-Language-Action)在 OpenVLA / \(\pi_0\) / OpenVLA-OFT 这一轮已经把 SFT 跑到瓶颈:LIBERO 上 OpenVLA-OFT ~89%、\(\pi_0\) ~94%,但长程任务(LIBERO-Long)始终卡在 60–85% 区间,对环境扰动脆弱,遇到一次失误就全程崩盘。最近的 RL 微调路线(VLA-RL / SimpleVLA-RL / EVOLVE-VLA)证明 online 反馈能进一步推高 SR,但代价是:需要可靠的 reward(仿真里的 sparse binary 或 learned progress estimator)、需要 sample-efficient 的 exploration、且每个任务都从头训练,跨任务知识完全不共享。
本文要解决的就是 "online adaptation 三块短板"——reward 噪声大、exploration 浪费、不能跨任务复用——把它们打包成一个 agentic 框架。
2.2 Motivation¶
作者的核心主张是:学习过程本身应该是 intelligent 的。与其把 reward 函数、exploration 策略、初始化这三件事写死,不如让另外几个"agent"(LLM 拆解器、VLM critic、retrieval 机制)实时干预。说白了,这是把"AI for AI training"的思路套到 VLA online adaptation 上。落到具体动机:
- Reward Hacking 与稀疏性:progress estimator (VLAC) 给出的 dense reward 噪声大且不一定对齐 VLA 当前的学习需求 → 需要按"哪个子目标还没学会"动态调权重。
- 盲目探索效率低:高维 action 空间下随机 noise 探索几乎找不到有效 trajectory → 用 VLM 把"先从左侧靠近"这种空间常识直接以自然语言注入到 task prompt。
- 每任务从头训:相似任务("开炉子放壶"vs"开抽屉放碗")共享大量 manipulation primitive → 应该缓存 policy weights 按 instruction embedding 检索做 warm start。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| SFT VLA | OpenVLA / \(\pi_0\) / OpenVLA-OFT | 完全依赖示教轨迹,记忆轨迹而非任务语义;偏离训练分布即崩;无 error recovery |
| Sparse-reward RL fine-tune | VLA-RL / SimpleVLA-RL | 二元 reward 信号稀疏,长程任务几乎学不到东西;2k+ iterations 才能收敛 |
| Progress-based RL fine-tune | EVOLVE-VLA | 用 VLAC 学习 progress 但 reward 噪声未矫正,且 horizon curriculum 固定(与当前能力解耦) |
| Intrinsic-motivation exploration | RND / ICM | reward-agnostic novelty 在 VLA 这种语义任务空间里浪费 budget(消融表 5 验证) |
| 跨任务迁移 | OpenVLA / Octo 的"大规模预训" | 任务级泛化靠数据规模,没有 task-specific 适应机制;adapter / LoRA 路线也是单任务训 |
2.4 论文解决方案(一句话)¶
把 OpenVLA-OFT 当 base policy,用 LLM 拆解任务 + VLAC 给 dense reward + 按子目标掌握度动态加权(ARS)、用 Qwen3-VL-8B 在线给 prompt 提示来引导探索(LGE)、用 instruction embedding cosine 检索 + softmax 加权平均历史 task 权重做 warm start(EM),三件套接 GRPO 在 LIBERO/RoboTwin 上做 online adaptation。
2.5 与前序工作的关系¶
直接构建在 OpenVLA-OFT (Kim et al. 2025) 上做 RL fine-tune,强烈对标 EVOLVE-VLA (Bai et al. 2025)——后者用的是 progress estimator + horizon curriculum,本文把后者的 horizon 维度细化成 sub-goal 维度并加上能力感知权重;progress reward 直接复用 VLAC (Zhai et al. 2025) 而不是自己训。Policy 优化用 GRPO (DeepSeekMath) 而非 PPO。Exploration critic 用 Qwen3-VL-8B-Instruct zero-shot,不再训单独的 critic。Memory bank 的"weight averaging"思路与 ModelSoup / Task Arithmetic 有亲缘关系,但作者强调只在"同一 pretrained init + 局部 task-specific 调整"的窄区间内 interpolate。
3. 方法介绍¶
3.1 形式化¶
MDP \(\mathcal{M} = (\mathcal{S}, \mathcal{A}, P, R, \gamma)\);state \(s_t = (o_t^{\text{vis}}, o_t^{\text{prop}}, l_{\text{task}})\) 包含视觉、本体感受、任务指令。Policy \(\pi_\theta\) 是 OpenVLA-OFT 的 autoregressive action tokenizer。Key Challenge:部署期没有 oracle reward,只能用 self-generated signals。
3.2 Adaptive Reward Synthesis (ARS)¶
任务拆解:用 Llama-3-8B 对 task instruction 生成 sub-goal 序列 $\(\mathcal{G} = \{g_1, \ldots, g_K\} = \text{LM}_{\text{decompose}}(l_{\text{task}})\)$ 例:``turn on the stove and put the moka pot on it'' → approach stove → turn on → locate pot → grasp pot → place on stove(5 个 sub-goal)。
能力感知权重:维护每个 sub-goal 的成功率 EMA $\(\hat{c}_k^{(t+1)} = \alpha \hat{c}_k^{(t)} + (1-\alpha)\mathbb{I}[\text{success at } g_k], \quad \alpha = 0.9\)$ 权重定义为 \(w_k = 1 - \hat{c}_k\) —— 没学会的子目标拿满权重,学会的子目标权重衰减到 0,自然形成 curriculum。
Dense reward:VLAC critic 给每个 sub-goal 估算进度 $\(R(\tau) = \sum_{k=1}^K w_k \cdot \Delta_k(\tau), \quad \Delta_k(\tau) = C_\phi(o_{\text{start}}^k, o_{\text{end}}^k, g_k)\)$
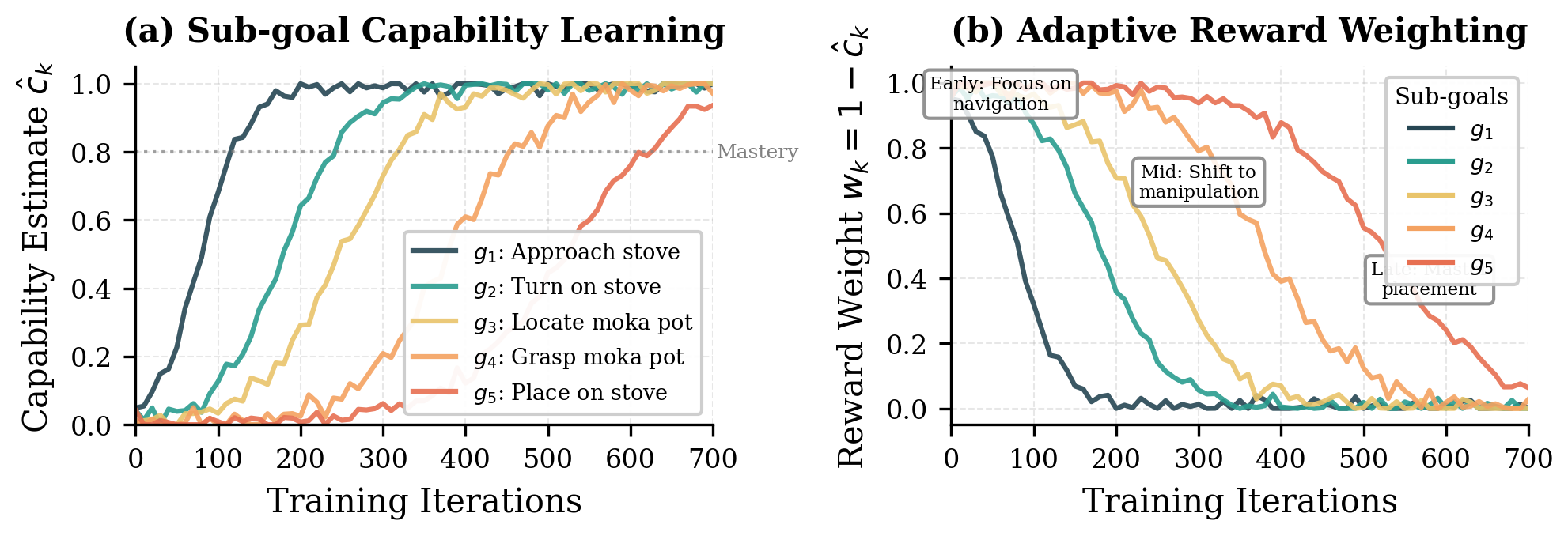 Figure 2:随训练推进,前期子目标权重("approach stove")逐渐衰减、后期子目标权重("place pot")上升 — 自动形成 stage curriculum。注意这只是一个 task 上的 single-seed 可视化,并非定量证据。
Figure 2:随训练推进,前期子目标权重("approach stove")逐渐衰减、后期子目标权重("place pot")上升 — 自动形成 stage curriculum。注意这只是一个 task 上的 single-seed 可视化,并非定量证据。
3.3 Language-Guided Exploration (LGE)¶
不训 critic,直接用 Qwen3-VL-8B-Instruct zero-shot 看当前帧 + task instruction,吐一句自然语言建议: $\(s_{\text{explore}} = \text{VLM}(o_t^{\text{vis}}, l_{\text{task}}, l_{\text{prompt}})\)$
然后通过 prompt 拼接的方式注入到 VLA: $\(a_t \sim \pi_\theta(a \mid s_t, l_{\text{task}} \oplus s_{\text{explore}})\)$
自适应触发频率: $\(p_{\text{suggest}}(t) = p_{\max} \exp(-\lambda \bar{R}^{(t)}), \quad p_{\max}=0.8, \lambda=0.5\)$ 初始每 50 步触发一次,随平均 reward 上升衰减。评估时只用 \(l_{\text{task}}\),不带 suggestion。
3.4 Experience Memory (EM)¶
Memory bank \(\mathcal{M}\) 存 \((e_i, \theta_i, m_i)\) 三元组:instruction embedding(768 维,frozen language encoder)、完整 policy 权重 \(\theta_i\)、元数据。
Warm-start 检索:cosine top-\(k\)(\(k=3\)),softmax 加权平均(温度 \(\tau = 0.1\),故几乎只取最相似那个): $\(\theta_{\text{init}} = \sum_j \frac{\exp(\cos(e_{\text{new}}, e_j)/\tau)}{\sum_{j'} \exp(\cdot)} \theta_j\)$
作者专门用一段说明"为什么 weight averaging 在这里 well-behaved":(i) 所有检索来源同一 OpenVLA-OFT init,(ii) 低温检索几乎是 single-pick 而非平均,(iii) 这只是 init,后续 online adaptation 可纠错。容量 100,超过用 diversity + success rate 策略淘汰。
3.5 Implementation Details¶
| 项目 | 值 |
|---|---|
| Base policy | OpenVLA-OFT |
| 优化器 | GRPO,lr \(1\times10^{-5}\),batch 32,group 8 |
| Max rollout horizon | 500 |
| Temperature (sampling) | 1.2 |
| LM decomposer | Llama-3-8B |
| Exploration VLM | Qwen3-VL-8B-Instruct |
| Reward model | VLAC(外部预训 progress estimator) |
| Memory capacity | 100 entries, \(k=3\), \(\tau=0.1\) |
| 硬件 | 4× A100 80GB;单 LIBERO suite (10 tasks) 训练 ~8 小时 |
| EVOLVE-VLA 对应耗时 | ~19 小时 |
| SimpleVLA-RL 对应耗时 | ~32 小时 |
部署时的运行依赖:Llama-3-8B(task decomposition,一次性)+ Qwen3-VL-8B(每 50 步触发一次)+ VLAC(每个 sub-goal 检查间隔,progress check interval=16)+ OpenVLA-OFT(每步 action)。论文未给单步 inference latency。
4. 结果对比¶
4.1 LIBERO 主结果(mean ± std over 5 seeds)¶
| 方法 | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| Octo | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| \(\pi_0\) + FAST | 96.4 | 96.8 | 88.6 | 60.2 | 85.5 |
| \(\pi_0\) | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| OpenVLA-OFT\(^\dagger\) | 91.3±1.0 | 90.1±1.2 | 89.8±1.3 | 85.8±1.8 | 89.2±0.9 |
| VLA-RL | 90.2 | 91.8 | 82.2 | 59.8 | 81.0 |
| SimpleVLA-RL\(^\dagger\) | 94.3 | 90.5 | 92.3 | 87.7 | 91.2 |
| EVOLVE-VLA\(^\dagger\) | 95.4±0.9 | 97.4±0.8 | 95.8±0.9 | 94.4±1.2 | 95.8±0.7 |
| Agentic-VLA\(^\dagger\) | 97.2±0.6 | 98.6±0.5 | 97.4±0.6 | 98.1±0.8 | 97.8±0.4 |
| \(\Delta\) vs SFT base | +5.9 | +8.5 | +7.6 | +12.3 | +8.6 |
| \(\Delta\) vs EVOLVE-VLA | +1.8 | +1.2 | +1.6 | +3.7 | +2.0 |
4.2 One-shot Learning(单 demo 预训)¶
| 方法 | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| OpenVLA-OFT | 65.1 | 40.1 | 57.2 | 15.1 | 43.6 |
| EVOLVE-VLA | 73.4 | 70.0 | 64.7 | 37.1 | 61.3 |
| Agentic-VLA | 79.8 | 78.4 | 72.6 | 51.2 | 70.5 |
| \(\Delta\) vs SFT | +14.7 | +38.3 | +15.4 | +36.1 | +26.9 |
4.3 跨任务迁移(Train on Long → Test on Object,无任务示教)¶
| 方法 | Success Rate (%) | Progress (%) |
|---|---|---|
| Direct Transfer (SFT) | 0.0 ± 0.0 | 12.4 ± 1.8 |
| EVOLVE-VLA | 20.8 ± 2.7 | 54.2 ± 3.9 |
| Agentic-VLA | 31.2 ± 2.3 | 68.7 ± 3.1 |
4.4 训练效率(达 90% Long SR 所需 iters / rollouts)¶
| 方法 | Iters | Rollouts | Speedup |
|---|---|---|---|
| SimpleVLA-RL | 2,450 | 78.4k | 1.0× |
| EVOLVE-VLA | 1,680 | 53.8k | 1.46× |
| Agentic-VLA | 700 | 22.4k | 2.4× |
4.5 RoboTwin 2.0(双臂 Aloha AgileX,Easy / Hard 随机化)¶
| Task | RDT-E/H | \(\pi_0\)-E/H | Ours-E/H |
|---|---|---|---|
| Adjust Bottle | 81 / 75 | 90 / 56 | 98 / 82 |
| Beat Block Hammer | 77 / 37 | 43 / 21 | 79 / 45 |
| Blocks Ranking RGB | 3 / 0 | 19 / 5 | 24 / 9 |
| Click Bell | 80 / 9 | 44 / 3 | 91 / 19 |
| Dump Bin Bigbin | 64 / 32 | 83 / 24 | 87 / 58 |
| Grab Roller | 74 / 43 | 96 / 80 | 98 / 84 |
| Handover Block | 45 / 14 | 45 / 8 | 73 / 21 |
| Move Pillbottle Pad | 8 / 0 | 21 / 1 | 43 / 8 |
| Subset Avg | 34.5 / 13.7 | 46.4 / 16.3 | 62.5 / 34.7 |
Hard 设置上的 gap 比 Easy 更大(vs \(\pi_0\): +16.1 vs +18.4),作者归因于 memorization 在分布扰动下崩得更快。
4.6 关键消融(LIBERO-Long)¶
增量消融¶
| Configuration | SR (%) | Progress | Iters |
|---|---|---|---|
| OpenVLA-OFT (SFT only) | 85.8 | – | – |
| + Vanilla RL (binary reward) | 87.7 | 0.04 | 2,100 |
| + Progress reward (VLAC) | 91.3 | 0.20 | 1,850 |
| + ARS | 94.6 | 0.31 | 1,200 |
| + LGE | 96.2 | 0.38 | 880 |
| + EM | 98.1 | 0.42 | 700 |
移除单一组件¶
| Configuration | SR (%) | Progress | Iters |
|---|---|---|---|
| Full Agentic-VLA | 98.1 | 0.42 | 700 |
| w/o ARS (fixed reward) | 95.4 | 0.35 | 1,100 |
| w/o LGE (random explore) | 96.8 | 0.39 | 950 |
| w/o EM (cold start) | 96.4 | 0.37 | 1,050 |
Controlled Comparison(替换而非移除,matched budget)¶
| Configuration | SR (%) | Progress | Iters |
|---|---|---|---|
| Progress reward only | 91.3 | 0.20 | 1,850 |
| + Uniform sub-goal weights | 92.7 | 0.24 | 1,620 |
| + Fixed schedule curriculum | 93.4 | 0.27 | 1,480 |
| + Learning-progress sampling | 94.0 | 0.29 | 1,360 |
| + ARS | 94.6 | 0.31 | 1,200 |
| + ARS + RND | 95.0 | 0.34 | 1,080 |
| + ARS + ICM | 95.4 | 0.35 | 1,020 |
| + ARS + LGE | 96.2 | 0.38 | 880 |
| + ARS + LGE + random retrieval | 97.0 | 0.39 | 910 |
| + ARS + LGE + EM | 98.1 | 0.42 | 700 |
Task Decomposition 来源¶
| Decomposition | Avg Sub-goals | Coverage | SR (%) |
|---|---|---|---|
| No decomposition | 1.0 | – | 91.3 |
| Fixed 3-step | 3.0 | 0.68 | 93.8 |
| LM-generated (Ours) | 4.2 | 0.91 | 98.1 |
| Oracle (human) | 4.5 | 0.94 | 98.4 |
LM-generated 与 oracle 仅差 0.3%,是论文比较有说服力的结果。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
-
Controlled comparison 表(Table 5)做得规矩:用 RND / ICM 替代 LGE、用 uniform / fixed-schedule / learning-progress 替代 ARS、用 random retrieval 替代 EM——这是"替换 not 移除"的消融范式,比单纯 w/o X 更能说明"是不是这个特定设计在起作用"。在 VLA RL 这片论文里属于少有的负责任的设计。
-
\(w_k = 1 - \hat{c}_k\) 简单但贴合直觉:能力感知的 curriculum 没有 hand-crafted schedule、没有额外可学参数,几乎零成本就把"难度自动跟随能力漂移"做出来。配合 progress check interval=16 的 EMA 更新粒度,避免了 capability estimate 抖动。
-
LGE 复用预训 VLM 而非训单独 critic:相比 EVOLVE-VLA 训 progress estimator、CuriousReplay 训 explorer 这条线,作者直接 prompt Qwen3-VL-8B,省了一套训练 pipeline 而且自然继承大模型的空间常识。Adaptive frequency \(p_{\text{suggest}}(t)\) 让 VLM 调用数随训练进展衰减,限制了推理成本。
-
Task decomposition 的 oracle 对比(Table 7):把 LM-generated decomposition 与 human oracle 直接 head-to-head,差 0.3% SR——说明这一块的 LLM 自动化没拖后腿,是少有的把"LLM 替代人工标注"做严肃验证的实验。
-
RoboTwin Hard 上 gap 反而拉大:Easy 上比 \(\pi_0\) +16.1,Hard 上 +18.4。这是 online adaptation 路线最该证明的事——在分布外扰动下相对 memorization-based 方法应该更稳。这个结果对论文的核心 thesis(generalization via online learning)算是切实支撑。
5.2 做得不够好的地方 / 值得质疑的地方¶
-
Experience Memory 存全权重在 VLA 尺度上不可行:OpenVLA-OFT 是 7B 参数级别的模型,full state dict 单 entry 大约 14–28 GB。容量 100 → 1.4–2.8 TB 存储/检索成本,且每次 warm-start 需要做 weight averaging 这种 GPU 内存级 reduce。论文只在 §A.2 一笔带过"future work could explore more compact representations such as adapter weights",但没给当前实现的实际 footprint 和 retrieval latency。这是核心组件的可行性硬伤。
-
Weight averaging 在 RL 微调过的 VLA 上是否 well-behaved 没有实证:§3.5 一整段都是 hand-waving:"同一 init"、"低温检索几乎 single-pick"、"作为 init 可被纠错"。但 RL 微调(GRPO)的步长比 SFT 大得多,loss landscape 的 mode connectivity 在 RL 任务空间里完全没有 ModelSoup 那种 LP-FT 的保护。Table 5 random retrieval 仍然 97.0%(接近全配置 98.1%),反而暗示EM 的增益 ~1.1% 主要来自任何 warm start 而非 similarity-based 检索——这与作者的叙事相反。
-
三个外部大模型的 inference 成本完全未量化:每次 rollout 期间,Qwen3-VL-8B 每 50 步触发一次(一个 500-step rollout 就是 ~10 次 VLM 调用),VLAC 每 16 步检查一次(~31 次 critic 调用),还有 OpenVLA-OFT 每步生成 action token。论文叙述"online adaptation"和"2.4× faster convergence",但没给单 iteration 的 wall-clock latency,也没给真实部署时 VLM 调用的 throughput 限制。"2.4× speedup"只算了 rollout 数,VLM 的浮点运算成本可能让 wall-clock 反而更慢。
-
Per-task 表(Table 7–10)数字异常规整:SFT 列 Spatial 是 92, 90, 94, 88, 92, 90, 94, 88, 92, 93——明显的周期模式,且全部是偶数。50 trials × 2% granularity = 每 1 trial 算 2%,理论上可以出现这些值,但十个任务恰好都落在 88–94 区间且呈周期性,多 seed 平均后还这么规整就奇怪了。同样问题出现在 Object/Goal/Long 各表。至少需要追问:这些是 5 seed 平均还是单 seed?为什么 main table 给 std 而 per-task 不给?
-
训练-评估的 instruction 分布偏移没处理:LGE 训练时 prompt 是 \(l_{\text{task}} \oplus s_{\text{explore}}\),评估时只用 \(l_{\text{task}}\)。VLA 是个语言条件策略,prompt 拼接相当于学了一个 augmented condition 下的策略,到了评估时该 condition 缺失。作者说"the suggestions are generated only during the exploration phase",但没解释 policy 在 inference 时对 prompt 缩短的 robustness,也没消融"评估时也带 suggestion"对比看是否帮助/伤害。
-
跨任务迁移其实没那么"跨":Train on LIBERO-Long → eval on LIBERO-Object,但两个 suite 共享同一个 Franka emulator、同一组 object set、同一物理引擎、同一相机配置。"31.2% on entirely new tasks without task-specific demonstrations"的措辞过强,实际上是 in-distribution physical / visual setting 下的 task instruction 切换。真正的 cross-task transfer 应该至少跨 embodiment 或跨 simulator。
-
Reward hacking 在 12% failure 中出现,被淡化处理:§A.4 承认 12% failures 是 progress estimator 给高分但 environment 不通过——这意味着 VLAC 在 12% 的情况下"看起来对了"但物理失败。这与 ARS 的设计前提(VLAC 给 dense reward)直接冲突:reward 信号本身就被自己的 policy hack 了。如果 95–98% SR 的 numerator 是 environment success(看上去是),那 reward hacking 体现为 false positive on progress 但不计入 SR;但训练阶段 hack 会污染策略更新。论文没给 reward hacking 在训练时被 ARS 衰减的证据。
-
+2.0% 相对 EVOLVE-VLA 的增量与方法复杂度不匹配:EVOLVE-VLA 已经做了 progress reward + progressive horizon。本文把 horizon-level curriculum 改成 sub-goal-level + 加上 LGE 和 EM,叠加三个独立模块换来 avg +2.0% / Long +3.7%。Table 4 ablation 显示 ARS 自己就把 SR 从 91.3% 推到 94.6%,LGE 再 +1.6%,EM 再 +1.9%——边际收益快速衰减。如果只是为了刷 SOTA,单独留 ARS 可能就够了。
-
没有真实机器人实验:所有实验都在 LIBERO + RoboTwin 仿真。论文 §A.5 自己承认"experiments are conducted in simulation"且"real-robot deployment is more involved"。考虑到三大组件(VLM critic, progress estimator, memory retrieval)都对 noisy real observation 极敏感,且 cascade failure 概率高,作者目前给的"modular structure allows incremental enabling"是个空洞 mitigation。
-
GRPO + dense reward 的 advantage 估计被 capability weight \(w_k\) 间接污染:GRPO 用 group-relative normalization 计算 advantage,但本文的 reward \(R(\tau) = \sum_k w_k \Delta_k(\tau)\) 中 \(w_k\) 是按全局训练状态变化的非平稳量。这意味着相邻 batch 之间 reward scale 不一致,advantage normalization 可能引入额外方差。论文没讨论 \(w_k\) 漂移与 GRPO group normalization 的交互。
5.3 值得继续探讨的方向¶
- EM 改成 LoRA-bank:把全权重换成 LoRA adapter(rank 8/16),单 entry 几 MB,memory 才能真正"scale to 1000+ tasks"。作者自己提了但没做,是最 obvious 的下一步。
- LGE 用 logits-level 引导而非 prompt 拼接:避免训练-评估分布偏移;可以做 classifier-free guidance 风格的双重 forward (with / without suggestion) 再插值。
- ARS 的 capability estimate 用 Bayesian smoothing 而非 EMA:当某子目标尝试次数少时 EMA 容易给极端值,加 Beta 先验能更稳定。
- 真实机器人 + sim-to-real progress estimator:VLAC 的 sim 训练 → real 部署的 calibration 是个独立研究问题,论文里被一笔带过。
- Reward hacking 的对抗式检测:用第二个 critic(或 VLM)做 environment-state verification,与 progress 信号做一致性检查;可以借鉴 Process Reward Model 在 LLM RLHF 的思路。
- 跨 embodiment 的真正 transfer:用 LIBERO 训、RoboTwin(不同 embodiment、不同 simulator)测,看 EM 的 instruction-embedding 检索是否还有信号;目前所有"cross-task"都在同一 simulator 内部。
- Adaptive Suggestion Frequency 的副作用研究:\(p_{\text{suggest}}\) 随平均 reward 衰减——但如果 policy 因为别的原因 reward 上升(reward hacking 或一次性高分 task),suggestion 会过早关闭,反而错过应该探索的 corner case。
- GRPO group size 与 sub-goal 数量的耦合:现在 group=8、sub-goal 平均 4.2 个,long-horizon 任务里 group 内 trajectory 在不同 sub-goal 上 fail 的方差较大,是否应该按 sub-goal 内 grouping?
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 关键 baseline / 相关论文:
- OpenVLA-OFT (Kim et al. 2025) — base policy
- EVOLVE-VLA (Bai et al. 2025) — 主对比,progress curriculum
- VLAC (Zhai et al. 2025) — progress estimator
- SimpleVLA-RL (Li et al. 2025) — RL fine-tune baseline
- GRPO / DeepSeekMath (Shao et al. 2024) — 策略优化算法
- Qwen3-VL-8B-Instruct (Yang et al. 2025) — LGE 用的 VLM critic
- LIBERO (Liu et al. 2023) / RoboTwin 2.0 (Chen et al. 2025) — benchmarks