KV-Tracker: Real-Time Pose Tracking with Transformers¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: KV-Tracker: Real-Time Pose Tracking with Transformers
- 作者: Marwan Taher, Ignacio Alzugaray, Kirill Mazur, Xin Kong, Andrew J. Davison (Dyson Robotics Lab, Imperial College London)
- arXiv 编号: 2512.22581(2025-12 提交,模板为 CVPR 2026,作者侧 paperID 18197)
- 项目主页: https://marwan99.github.io/kv_tracker/
- 关键词: real-time 3D tracking, multi-view transformer, KV-cache, π³ adaptation, online SLAM, object-level pose, training-free inference
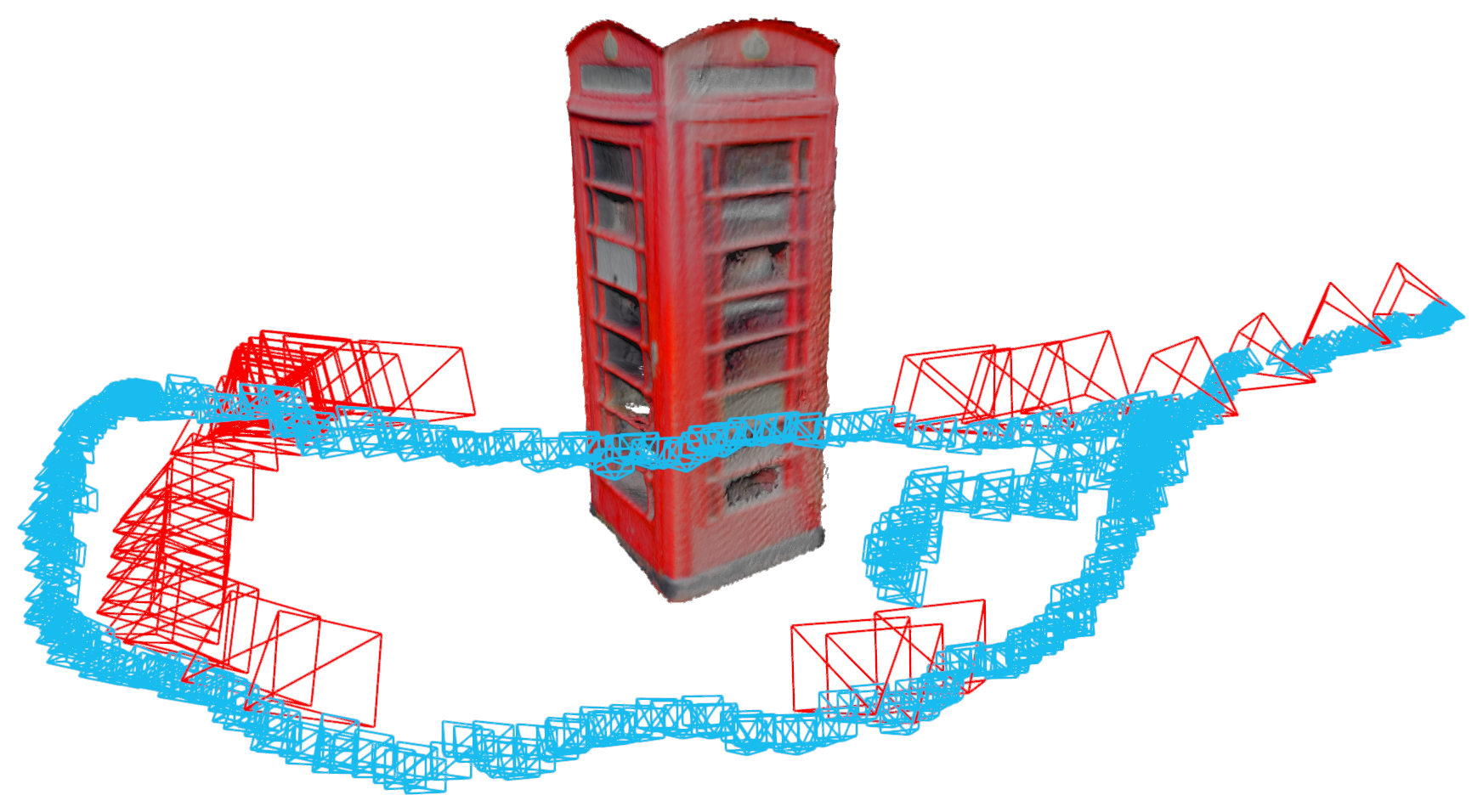 Figure 1:手持相机扫描电话亭,红色 frustum 是 mapping 阶段挑出来的 keyframe,蓝色 frustum 是被 cache 加速到 ~27 FPS 的 tracking 帧;右侧几何来自 keyframe 点云融合 —— 一句话:把 π³ 的 batch 推理拆成"建图一次 + 后续逐帧 query",实时复用 KV
Figure 1:手持相机扫描电话亭,红色 frustum 是 mapping 阶段挑出来的 keyframe,蓝色 frustum 是被 cache 加速到 ~27 FPS 的 tracking 帧;右侧几何来自 keyframe 点云融合 —— 一句话:把 π³ 的 batch 推理拆成"建图一次 + 后续逐帧 query",实时复用 KV
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 monocular 实时 3D tracking / 在线场景与物体重建 子领域。具体问题是:以 DUSt3R → VGGT → π³ 为代表的 multi-view feed-forward 几何模型在 batch 推理上效果惊人,但 global self-attention 的复杂度是 \(\mathcal{O}((NM)^2)\)(\(N\) 是输入帧数、\(M\) 是单帧 patch 数),帧数一多就掉到不可用的速度。论文要回答:怎么把这种"为离线 N 张图准备的多视图 transformer"无训练地改造成支持流式输入的实时 tracker?
2.2 Motivation¶
研究脉络很直白:
- 单视图 → 双视图(DUSt3R、MASt3R)已经在 MASt3R-SLAM 上验证了实时可行。
- 多视图模型(VGGT、π³、MapAnything)几何质量更好,但 attention 二次复杂度卡住了实时使用。VGGT-SLAM 这样的尝试基本是"在线场景下离线跑",FPS 不够。
- 现有 streaming 方案(Spann3R / CUT3R / TTT3R / Point3R)大多用 RNN-style 隐式 memory,但 memory 随每一帧更新 → 长序列 drift、catastrophic forgetting、回环时表现差。
- 类比 LLM 中的 KV-cache —— 既然 transformer 的注意力本身就允许"先建一份共识表示,再让新 query 来查询",那把 keyframe 当作 prompt、live frame 当作生成 query,就是天然的实时化思路。
motivation 落到一句话:让多视图 transformer 拥有"读一次、用很多次"的能力,等同于 LLM 推理里的 KV-cache 机制。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Multi-view geometry (batch) | VGGT, π³, MapAnything | \(\mathcal{O}((NM)^2)\),帧数一多就掉到几 FPS,无法 streaming |
| Pair-wise + SLAM | MASt3R-SLAM | 只能两两 view 信息交换,丢掉了多视图一致性这个最强先验 |
| Implicit memory streaming | Spann3R, CUT3R, TTT3R, Long3R, Point3R | memory 随每帧更新 → drift + catastrophic forgetting;TTT3R 即便加 confidence 门控仍需要状态重置;训练分布有上限(CUT3R 64 帧训练,超过就崩) |
| Causal attention 加速 | StreamingVGGT | 强行 causal 化但失去了"回望已知关键帧"的能力,回环失败 |
| Object pose w/ CAD | DeepIM, MegaPose, FoundationPose | 要 CAD 模型,强先验假设;render-and-compare 也依赖 depth |
| Object pose w/o CAD(最接近) | OnePose, OnePose++ | 离线扫描 + 离线建图,再加 2D-3D 匹配;预先准备好的 3D bounding box 是"特权信息" |
2.4 论文解决方案(一句话)¶
把 π³ 全模型推理拆成两步:mapping 阶段用 \(B\) 张 keyframe 跑完整双向 self-attention 并缓存每层 global block 的 \((K,V)\) 当成"场景表示";tracking 阶段对新来帧只算单帧的 \(Q_t, K_t, V_t\),让 \(Q_t\) 同时关注缓存的 \(\tilde K, \tilde V\) —— 复杂度从 \(\mathcal{O}((NM)^2)\) 降到 \(\mathcal{O}(M^2(N+1))\),~27 FPS,全程不需要再训练。
2.5 与前序工作的关系¶
- π³ (wang2025pi3):本文的 backbone。选它而不是 VGGT 是因为 π³ 去掉了 camera register token、用 permutation-invariant loss 训练,对参考视图选择不敏感 → cache 重组时更稳。
- MASt3R-SLAM (Murai 2025):双视图实时 SLAM 的最近邻 — 但本文要把"多视图"也搬上来。
- CUT3R / TTT3R / Point3R / Long3R / Kinaema / MUSt3R / Spann3R / StreamingVGGT:所有 streaming 类工作都对比;与之最大的区别在于本文的 memory 是 keyframe 锚定且只读,不在每一帧时被更新,所以没有"被坏样本污染"风险。
- OnePose / OnePose++:object-level 评估的 baseline。它们是离线建图 + 匹配,本文是在线建图 + 重建。
- Depth Anything V3:附录里换一个 backbone 跑相同 7-Scenes / TUM 评估,验证"模型无关"这一条。
- 数据集:TUM RGB-D、7-Scenes、ARCTIC、OnePose、OnePose Low Texture。
3. 方法介绍¶
3.1 形式化¶
给定一组输入图像 \(I_n \in \mathbb{R}^{H \times W \times 3}, n=1,\ldots,N\),π³ 预测:
- 世界系相机位姿 \(T_n \in \mathrm{SE}(3)\)
- 相机系点图 \(P^c_n \in \mathbb{R}^{H \times W \times 3}\)
- 置信度图 \(C_n \in \mathbb{R}^{H \times W}\)
ViT 把每张图编码成 \(X_n \in \mathbb{R}^{M \times d_k}\) patch tokens。\(L\) 层 decoder 在 frame-wise self-attention(单帧内部 \(\mathcal{O}(M^2)\)) 和 global self-attention(跨帧全连接 \(\mathcal{O}((NM)^2)\)) 之间交替。三个 decoder head 独立解码 \(T, P, C\) —— 这一点很关键,因为 tracking 时可以关掉点图和置信度 head 进一步提速。
注意力定义如常:
3.2 Mapping:建一份只读的 KV 表征¶
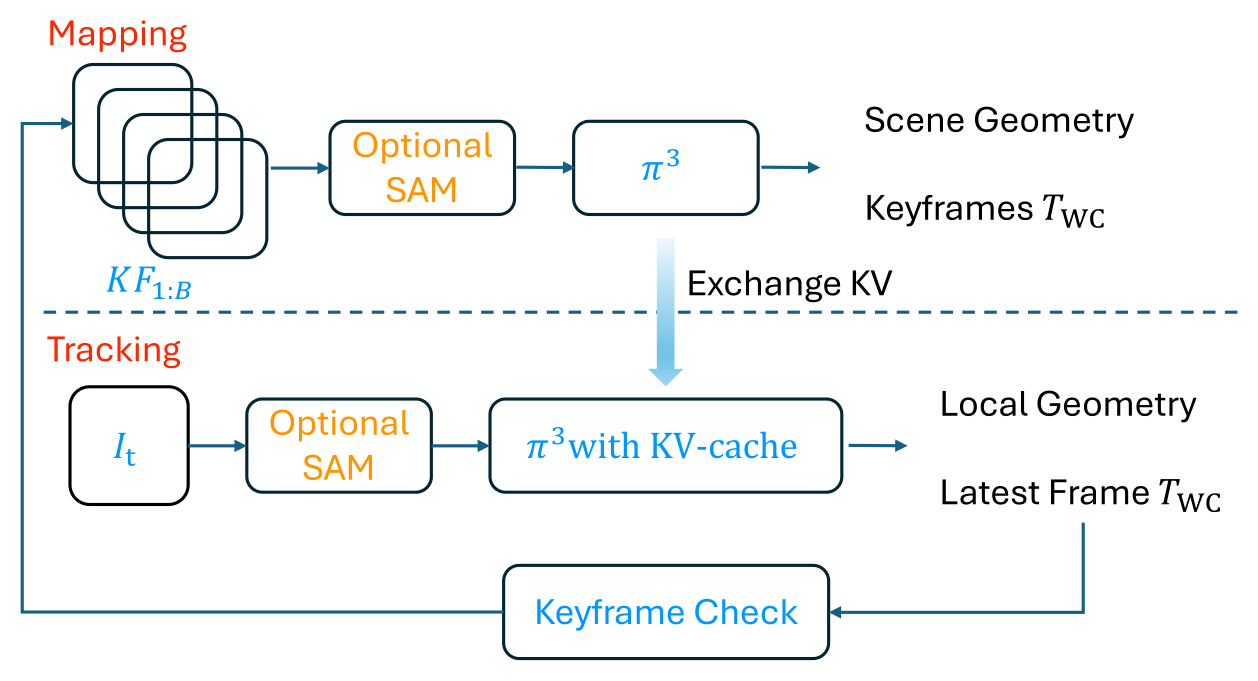 Figure 2:系统拆成 mapping(keyframe → KV-cache)和 tracking(live frame query KV-cache)两个可并行的进程,参考 PTAM 的设计。新 keyframe 触发时 cache 全量重算
Figure 2:系统拆成 mapping(keyframe → KV-cache)和 tracking(live frame query KV-cache)两个可并行的进程,参考 PTAM 的设计。新 keyframe 触发时 cache 全量重算
选定 keyframe 集合 \(KF_{1:B} \subseteq I_{1:N}\),跑 π³ 完整前向(全 bidirectional global attention),缓存每一层 global self-attention block 的:
外加每帧的 register token 对应的 KV 也缓存。memory 是 keyframe 数的线性函数,单帧 cache 大小则正比于 \(M\)(patch 数 ≈ 分辨率)。
3.3 Tracking:只算 query 帧、把缓存当 context¶
对新来一帧 \(I_t\):
- 单独编码 \(X_t = \mathrm{Enc}(I_t)\)。
- frame-wise self-attention 只跑 \(X_t\) 自己(\(\mathcal{O}(M^2)\))。
- global self-attention block:投影出 \(Q_t, K_t, V_t\),但 attention 的 keys/values 用 \([\tilde K, K_t]\) 和 \([\tilde V, V_t]\) —— 即"老 keyframes 的 cache + 当前帧的自身"。
- 注意力矩阵形状:
- tokens 经过所有 decoder 层后,按正常流程解码出 \(T_t, P_t, C_t\)。
复杂度从 \(\mathcal{O}((NM)^2) \to \mathcal{O}(M^2(B+1))\) —— 与 keyframe 数线性、与 patch 数仍二次。
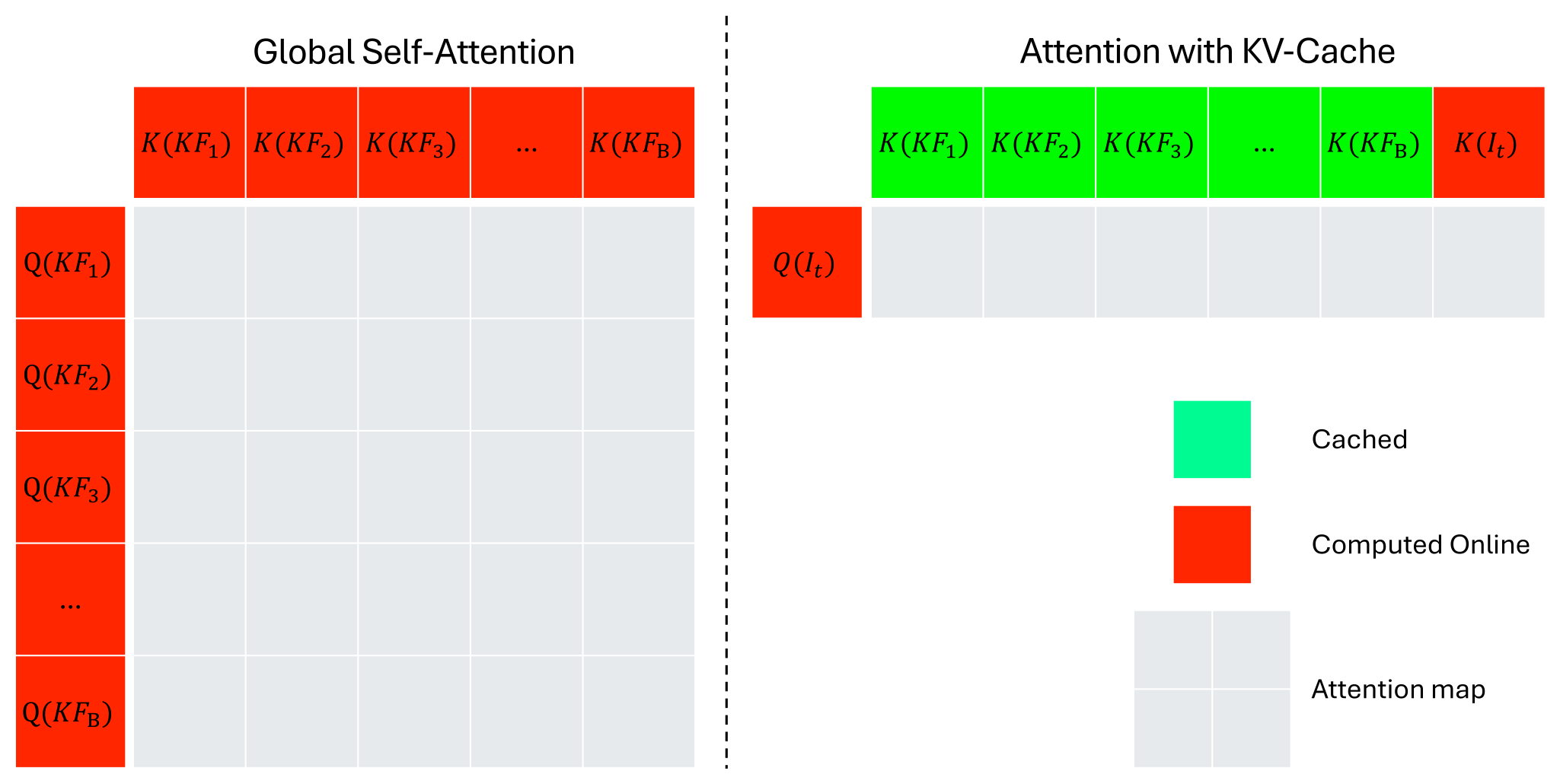 Figure 3:左为 mapping 阶段的全双向 self-attention(生成 KV-cache);右为 tracking 阶段的单向 cross-attention(live 帧 Q 查询 cache 中的 K,V),同时保留 live 帧自身的 self-attention 部分
Figure 3:左为 mapping 阶段的全双向 self-attention(生成 KV-cache);右为 tracking 阶段的单向 cross-attention(live 帧 Q 查询 cache 中的 K,V),同时保留 live 帧自身的 self-attention 部分
3.4 KV-Cache 作为场景表征¶
论文把这套机制重新解读为一种implicit 场景表示:
- 传统 SLAM 用稀疏 3D 点(ORB-SLAM)或 NeRF/Gaussian Splatting 等做场景表征。
- 这里的"表征"是 transformer 全 global attention 已经 fuse 过的 KV 张量 —— 隐含了 keyframe 间的多视图一致性约束。
- query 帧"重定位"的操作就是注意力本身:让 \(Q_t\) 在这些 keyframe tokens 里找到对应 patch,并由 decoder head 解出位姿和点图。
3.5 Keyframe 管理¶
Keyframe 选择:基于相机方位/俯仰角差(azimuth \(\phi\), elevation \(\theta\))的阈值
物体跟踪用 \(\tau = 10°\)。比较的是与所有已有 keyframe 的最小角度差,所以回到旧视角不会重复加 keyframe,是天然的"反冗余"机制。
Keyframe 拒绝:新插入的 keyframe 如果预测置信度低,就丢掉并 revert 到上一版 cache。
3.6 物体级 tracking¶
- 用 SAM 2 在线传播分割 mask,背景置黑。
- 物体 50–60 个 keyframe 通常就够覆盖一个完整观察 → KV-cache 大小可控。
- mask vs 2D bounding box 两种输入都评估了,结果会在 §4 看到 bbox 反而更好。
3.7 Implementation Details¶
| 项 | 值 |
|---|---|
| Backbone | π³ (feed-forward multi-view transformer) |
| GPU | NVIDIA RTX 4090 (24 GB) |
| tracking FPS | ~27 (点图/置信度 head 关闭) |
| 评估输入分辨率 | TUM-RGBD 350×266;Arctic 308×308;OnePose 308 与 518 都试 |
| Keyframe 间隔 | 相机评估每 50 帧自动新增;物体评估按 10° 角度阈值 |
| Baseline 状态重置 | CUT3R / TTT3R 每 100 帧重置一次(防 drift) |
| 内存增长 | 线性于 keyframe 数 × 单帧 patch 数;110 keyframe @ 308 接近 24 GB 上限 |
| 双视频流 | 采集+分割与 mapping+tracking 是独立进程,类似 PTAM |
| 训练 | 无任何 fine-tune,只在推理路径上改造;附录里换 Depth Anything V3 也跑通 |
4. 结果对比¶
4.1 相机轨迹 — TUM RGB-D(ATE RMSE,米)¶
| Scene | Point3R | CUT3R | TTT3R | DPVO* | Ours |
|---|---|---|---|---|---|
| 360 | 0.200 | 0.176 | 0.110 | 0.135 | 0.166 |
| desk | 0.366 | 0.196 | 0.104 | 0.038 | 0.060 |
| desk2 | 0.321 | 0.437 | 0.147 | 0.048 | 0.083 |
| plant | 0.423 | 0.383 | 0.092 | 0.036 | 0.048 |
| room | 0.558 | 0.423 | 0.253 | 0.394 | 0.366 |
| rpy | 0.062 | 0.054 | 0.054 | 0.034 | 0.045 |
| teddy | 0.580 | 0.399 | 0.214 | 0.064 | 0.071 |
| xyz | 0.134 | 0.109 | 0.083 | 0.012 | 0.021 |
| Average | 0.331 | 0.272 | 0.132 | 0.095 | 0.108 |
* DPVO 是稀疏 patch odometry 参考,不算 baseline;与本方法平均差 0.013m。学习类 baseline 里本方法最好(比 TTT3R 改善 18%)。
4.2 相机轨迹 — 7-Scenes seq-01(ATE RMSE,米)¶
| Scene | Point3R | CUT3R | TTT3R | Ours |
|---|---|---|---|---|
| chess | 0.427 | 0.297 | 0.154 | 0.091 |
| fire | 0.280 | 0.218 | 0.124 | 0.042 |
| heads | 0.389 | 0.115 | 0.097 | 0.054 |
| office | 0.436 | 0.356 | 0.196 | 0.065 |
| pumpkin | 0.644 | 0.249 | 0.228 | 0.142 |
| redkitchen | 0.502 | 0.118 | 0.136 | 0.038 |
| stairs | 0.398 | 0.079 | 0.063 | 0.128 |
| Average | 0.439 | 0.205 | 0.143 | 0.080 |
比 TTT3R 提升 44%,7 场景中 6 个最优。stairs 是唯一弱点(楼梯小空间高频纹理 → 视角差小、keyframe 选不出来?)。
4.3 帧率对比¶
| Method | Point3R | CUT3R | TTT3R | Ours |
|---|---|---|---|---|
| FPS | ~5 | ~17 | ~17 | 27 |
注意:CUT3R/TTT3R 跑 512×384,本方法跑 350×266 —— 分辨率不完全对齐。
4.4 物体级 tracking — ARCTIC(egocentric S01,ATE RMSE,米)¶
| Scene | CUT3R | TTT3R | Ours@308 |
|---|---|---|---|
| espressomachine | 0.253 | 0.175 | 0.151 |
| ketchup | 0.369 | 0.319 | 0.249 |
| microwave | 0.181 | 0.156 | 0.135 |
| box | 0.176 | 0.207 | 0.200 |
| laptop | 0.319 | 0.305 | 0.248 |
| waffleiron | 0.336 | 0.342 | 0.204 |
| scissors | 0.237 | 0.264 | 0.188 |
| capsulemachine | 0.458 | 0.552 | 0.300 |
| phone | 0.408 | 0.399 | 0.402 |
| mixer | 0.313 | 0.309 | 0.198 |
| Average | 0.305 | 0.303 | 0.228 |
10 个序列中 8 个最优;box 给 CUT3R,phone 几乎打平。需要注意:所有方法都没在 masked image 上训练过,π³ 的先验"碰巧"泛化得不错。
4.5 物体级 pose — OnePose & OnePose Low Texture¶
| Method | Input | OnePose 1cm/1° | 3cm/3° | 5cm/5° | LT 1cm/1° | 3cm/3° | 5cm/5° | FPS |
|---|---|---|---|---|---|---|---|---|
| OnePose (offline) | 3D Bbox | 49.7 | 77.5 | 84.1 | 12.4 | 35.7 | 45.4 | 15 |
| OnePose++ (offline) | 3D Bbox | 51.1 | 80.8 | 87.7 | 16.8 | 57.7 | 72.1 | 11 |
| Ours@308 | Seg Mask | 2.25 | 47.0 | 75.7 | 1.21 | 32.2 | 62.2 | 27 |
| Ours@308 | 2D Bbox | 2.9 | 52.8 | 83.2 | 4.15 | 57.3 | 83.3 | 27 |
| Ours@518 | Seg Mask | 10.7 | 75.5 | 92.1 | 6.85 | 62.0 | 85.7 | 16 |
| Ours@518 | 2D Bbox | 5.3 | 69.3 | 92.9 | 12.1 | 80.0 | 94.4 | 16 |
LT = Low Texture。要点:
- 5cm,5° 粗阈值上显著超过 OnePose++,尤其低纹理数据集差 22 pp。
- 1cm,1° 紧阈值上显著落后(10.7 vs 51.1)。论文承认是离线建图 vs 在线建图的差距。
- 2D bbox 比 segmentation mask 一致更好 —— 因为物体在数据集里基本静止,bbox 外的背景纹理给 attention 提供了更多锚点。
4.6 关键 Runtime Analysis:KV-cache 的可扩展性¶
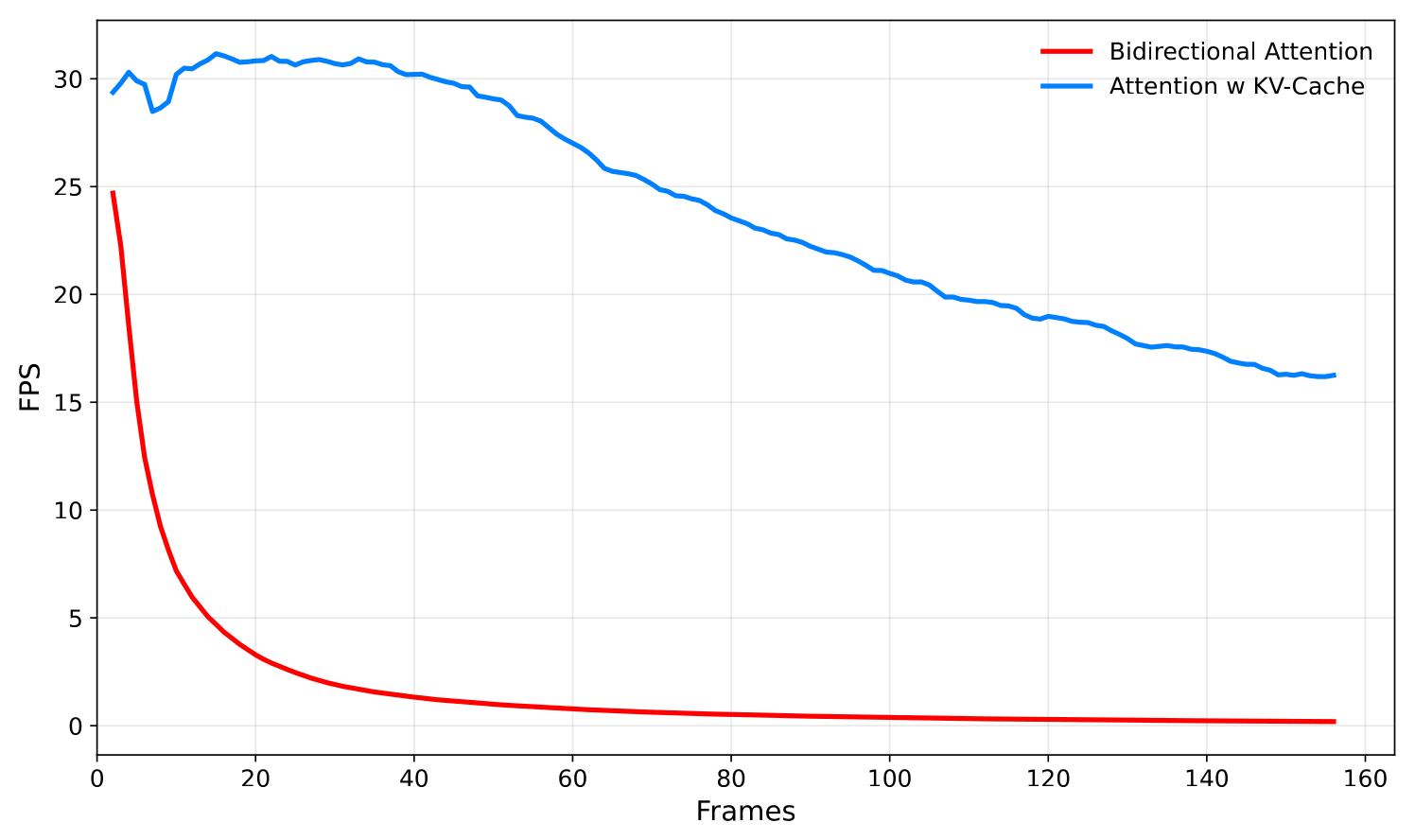 Figure 4:合成 workload(308×308),全双向 attention 跑 N 帧 vs 单帧 query + N 帧 KV-cache。bidirectional 曲线随 N 二次掉,cache 曲线在 N=50 之前几乎不掉(30 FPS),70 帧 25 FPS,110 帧 20 FPS,再往后就 24 GB 显存爆掉
Figure 4:合成 workload(308×308),全双向 attention 跑 N 帧 vs 单帧 query + N 帧 KV-cache。bidirectional 曲线随 N 二次掉,cache 曲线在 N=50 之前几乎不掉(30 FPS),70 帧 25 FPS,110 帧 20 FPS,再往后就 24 GB 显存爆掉
4.7 物体跟踪与重建定性结果¶
![]() Figure 5:ARCTIC(308×308)/ OnePose / OnePose-LT(518×518)的轨迹和重建示例 —— 物体几何来自 keyframe 的 point map fusion,相机/物体轨迹来自 tracking 分支
Figure 5:ARCTIC(308×308)/ OnePose / OnePose-LT(518×518)的轨迹和重建示例 —— 物体几何来自 keyframe 的 point map fusion,相机/物体轨迹来自 tracking 分支
4.8 附录:换 backbone 验证模型无关性¶
附录在 Depth Anything V3 (1.15B) 上重做评估,7-Scenes 平均 ATE 0.118 m / TUM 0.179 m,FPS 18。比 π³ 略差(0.080 / 0.108)但仍优于 CUT3R/TTT3R 平均,验证"KV-cache 思路可以平移到任何有 global self-attention 的多视图模型"。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 训练-free 适配是真正干净的:很多"利用 foundation model 做下游任务"的工作都要 LoRA / 适配头 / 蒸馏,本文只在推理 graph 上改一处(把 global self-attention 的 KV 从动态算改成读 cache + 拼当前帧),不动权重、不开新训练管线。可复现性和落地性都很高。
- LLM→视觉的 KV-cache 类比定得很准:LLM 的 KV-cache 是"prompt 阶段建一次 KV,后续 token 串行 query";这里"keyframes 阶段建一次 KV,后续 live 帧 query"——同构。把这层映射明确写出来,方便后续读者借鉴所有 LLM 推理优化技巧(如 paged attention、量化 cache)。
- 复杂度分析诚实:reduction 是 \(\mathcal{O}(M^2(N+1))\) 不是 \(\mathcal{O}(M^2)\) —— \(M^2\) 那项(query 自身的 self-attention 部分)保留,没有夸成"线性"。
- Keyframe 选择按角度而非时间:与"所有已有 keyframe"比最小差,回到旧视角天然不会复加,回环友好。
- 置信度门控防 cache 污染:低置信度 keyframe 拒绝并 revert —— 这条比"无脑加 keyframe"更稳,也比 CUT3R/TTT3R 的"每帧都更新 memory"更安全(cache 一旦坏掉就坏掉了,所以严控插入更合理)。
- 附录在 Depth Anything V3 上跑通:用一个非作者训练、架构不完全一样的模型重做评估 → 把"模型无关"从口号变成证据(虽然只一个例子,但比没有强)。
- π³ 的解耦 decoder head 被用到:tracking 时关掉 point map 和 confidence head 进一步提速,这是个 small clever engineering choice。
5.2 做得不够好 / 值得质疑的地方¶
- 紧阈值下物体姿态明显落后:OnePose 1cm/1° 上本方法只有 10.71%,OnePose++ 是 51.1%。论文用"online vs offline"打圆场,但 AR/VR 和机器人抓取这两个最被引用的应用场景恰恰需要 sub-cm 精度。本质上这套方法的"实时"是用"细粒度精度"换的。
- 27 FPS 的水分:Table 1 标的 FPS 是关掉了 point map 和 confidence head 的 tracking-only 配置。要拿几何重建就得打开,论文只说"不影响 quality 只影响 runtime",没有给打开后的 FPS 数字 → headline 数字和"完整功能配置"不是同一个。
- KV-cache 的全量重算是隐性延迟尖峰:§3.5 写到"new keyframe insert 时 cache 全量重算"。50 个 keyframe 已有时再加第 51 帧,意味着要重跑 51 张全双向 attention 推理一次 —— 这是 \(\mathcal{O}(51^2 \cdot M^2)\) 的瞬时计算。论文没给"keyframe 触发频率"和"插入时是否阻塞 tracking 线程"。即便 PTAM 风格双线程也至少有个 GPU 抢占。
- 内存上限是 hard cap:24 GB GPU 在 110 keyframes @ 308 已经爆。要扩到 SLAM 级别(房间、室外场景)这是 fatal。论文 conclusion 已经承认"only spatially confined environments"。
- Baseline 强制状态重置可能不公平:CUT3R/TTT3R 每 100 帧重置一次,论文给的理由是"防 catastrophic drift"。但重置等同于把它们当成"100 帧 odometry chunks 拼接",并没把它们的全长 streaming 能力评估出来。附录里说也提供了"无重置"对比,但主表用的是有重置版本 —— 这种选择在视觉上会让对比看起来更紧。
- 分辨率不对等:TUM 上本方法跑 350×266,CUT3R/TTT3R 跑 512×384。Table 1 里说"低分辨率仍超过 baseline"是亮点,但反过来也意味着本方法的 FPS 优势部分来自低分辨率。518×518 配置在 OnePose 上跑到 16 FPS,比 baseline 更慢;那时再去比 ATE 会怎样?没说。
- ARCTIC 评估只取 S01(一个被试,10 序列):物体跟踪结论是"~38% 比 CUT3R 好",样本量小。phone scene 几乎打平、box 输给 CUT3R,说明优势不普适。
- Model-agnostic 只验证了 1 个模型:Depth Anything V3 ATE 比 π³ 差 50%;那如果换 VGGT、MapAnything 呢?尤其 VGGT 用了 camera register token,π³ 因为去掉它才显得"对参考帧不敏感"—— register token 的 KV 怎么处理论文没讲。
- 场景表示的"消融"不存在:把它叫做"scene representation",但没有任何实验证明"cache 信息越多越好/某些 keyframe 可丢"。例如:随机丢 50% 的 keyframe cache,ATE 退化多少?这是验证 representation 假说的关键实验,但缺失。
- 未表征的失败模式:相机走进 keyframe 完全没覆盖的新视角时,KV-cache 里没有相关上下文,query 应该会 hallucinate。论文里没有 reset / 探索阈值 / 失效检测 —— 真实部署时这会是大问题。
- 2D bbox > Seg mask 的解释牵强:论文说"bbox 边缘背景给 attention 提供更多锚点",那这等同于承认 KV-cache 学到的不只是物体几何,还吸收了与物体共现的背景纹理。如果物体放到新背景下,性能可能掉一大截 —— OnePose 数据集物体静止、相机绕物体扫,正好是背景固定的 setting,结论的可迁移性存疑。
5.3 值得继续探讨的方向¶
- KV-cache 量化与 paged-attention:LLM 那套(int4 KV、PagedAttention、FlashAttention-3)平移过来理论上能 4× 扩展 keyframe 容量,把 110 帧上限推到 ~400+,可能解锁 room-scale SLAM。
- 增量 cache 更新:新 keyframe 插入只让它与已有 keyframe attend、已有 keyframe 之间的 KV 保持不变 —— 这相当于在 mapping 阶段引入 causal mask 的弱化版,可能让 keyframe 加入从 \(\mathcal{O}(B^2)\) 降到 \(\mathcal{O}(B)\)。
- Token eviction / cache 压缩:Evict3R 思路(被论文 cite 但没用)、H2O-style 注意力得分驱动的 eviction,可以淘汰冗余 keyframe tokens。
- 失败检测与 cache 重建:当 attention map 的 entropy 异常高(query 找不到对应 keyframe)时触发新一轮 keyframe 采集,是个低成本但有用的扩展。
- 多物体并行 cache:每个物体一份 cache,attention 通过门控路由到正确 cache,避免一份大 cache 里物体表征互相干扰。
- 与显式几何融合:cache 是隐式表征,难直接编辑/调试。把 keyframe 解码出的 point maps 同时 fuse 进 Gaussian Splatting,就能做"隐式查询 + 显式细化"。
- 小 LoRA 弥补 1cm/1° 精度差:哪怕保持"基础推理 training-free",给 keyframe 之间的 attention 加一个轻量 adapter(只在 KV projection 上),可能把紧阈值上的 40 pp 差距追回来。
- 类比扩展到视频生成模型:causal video diffusion / world model 同样有"前缀建图 + 后续逐帧生成"的结构,本文的 KV-cache 思路应该可以直接搬过去(实际上 EgoExo-WM 这类 ego world model 已经在用 DINOv3 latent;如果能加 KV-cache 加速会很有意义)。
- 回环识别副产品:Q_t 对各 keyframe 的 attention 权重分布天然是 place recognition 信号 —— 高权重 keyframe 即"我现在在哪儿",可以免费拿出来做 loop closure 候选。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://marwan99.github.io/kv_tracker/
- 关键 baseline / 相关论文:
- π³ (Wang et al., 2025) — backbone
- VGGT (Wang et al., 2025)、MapAnything (Keetha et al., 2025) — 同架构候选 backbone
- CUT3R / TTT3R (Chen et al., 2025) — streaming baseline
- Point3R (Wu et al., 2025) — streaming baseline
- MASt3R-SLAM (Murai et al., 2025) — 实时双视图 SLAM 对照
- OnePose / OnePose++ (Sun 2022 / He 2022) — 物体级离线建图基线
- DPVO (Teed et al., 2023) — 稀疏 patch odometry 强参考
- Depth Anything V3 — 附录验证 backbone
- SAM 2 (Ravi et al., 2024) — 物体 mask 传播