ZPRL: Beyond Action Residuals — 用 Bottleneck Latent 强化学习 steer 真实机器人策略¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Beyond Action Residuals: Real-World Robot Policy Steering via Bottleneck Latent Reinforcement Learning
- 作者: Dongjie Yu*¹², Kun Lei*²³, Zhennan Jiang⁴, Jia Pan†¹, Huazhe Xu†²⁵(* equal contribution,† corresponding authors)
- 单位: ¹香港大学 (HKU),²上海期智研究院 (Shanghai Qizhi Institute),³上海交通大学 (SJTU),⁴中科院自动化所 (CASIA),⁵清华大学交叉信息院 (IIIS)
- arXiv 编号: 2605.19919(2026-05 提交,IEEEtran journal 模板,疑似投 RA-L / T-RO 方向)
- 项目主页: https://manutdmoon.github.io/ZPRL/
- 关键词: robot manipulation, RL post-training, offline-to-online, flow-matching policy, variational information bottleneck, latent steering, residual RL
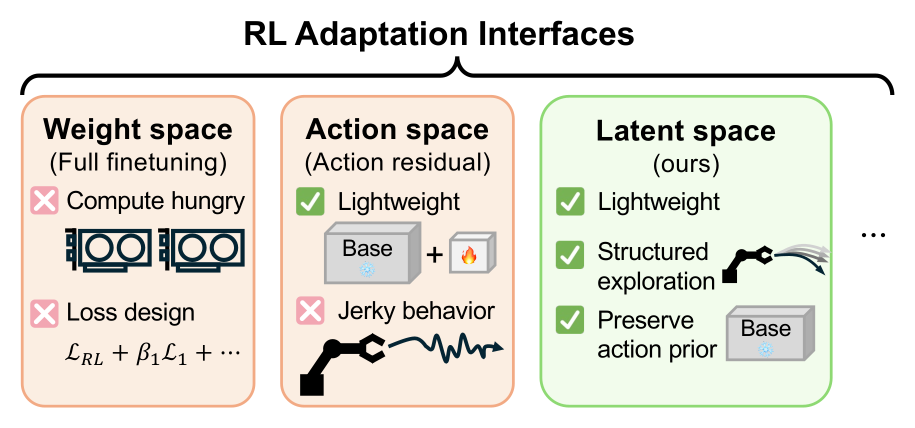 Figure 1:RL 适配 pretrained 策略的三种"介入接口"。Weight space(全参数微调)表达力强但算力贵、且和具体策略的 loss 设计纠缠;Action space(动作残差)轻量但探索抖动;ZPRL 选在 latent space —— 轻量 + 结构化探索 + 保留 action prior。
Figure 1:RL 适配 pretrained 策略的三种"介入接口"。Weight space(全参数微调)表达力强但算力贵、且和具体策略的 loss 设计纠缠;Action space(动作残差)轻量但探索抖动;ZPRL 选在 latent space —— 轻量 + 结构化探索 + 保留 action prior。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 机器人操作里 pretrained imitation policy 的 RL 后训练 (post-training) 子领域。离线模仿学习(IL)已经能从演示里克隆出相当强的视觉-运动策略,但部署时仍会因为执行误差、演示覆盖不足、部署环境失配而失败。论文要回答的核心问题不是"要不要用 RL 改进",而是 RL 应该介入 (intervene) 在 base policy 的哪个接口上 —— 是改权重、改输出动作、还是改某个内部表征?
2.2 Motivation¶
作者把 RL 适配接口拆成三类(Figure 1):
- Weight space(全参数微调):表达力最强,但随策略规模增长越来越贵,而且对 diffusion / flow 这类生成式策略往往要绑定模型特定的优化技巧(如 DPPO、ReinFlow)。
- Action space(动作残差):冻结 base policy,只学一个加在输出动作上的 corrective policy(Residual RL / Policy-Decorator)。轻量、保留预训练能力,但残差直接加在低层 motor command 上 → 探索退化成高频抖动,在机器人上容易抖、容易不安全。
- 核心 insight:有意义的行为很少来自无结构的振荡;需要的不是"不同的动作",而是"在风格上仍与预训练策略一致的不同动作"。因此理想的介入空间应同时满足两点:(1) compact —— 维度低、便于在线高效探索;(2) structured —— 让探索贴着合法行为流形走。
这就引出论文的问题:与其直接改动作,能不能让 RL 通过一个更高效、更能捕捉预训练行为结构的接口来 steer 策略?
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| Weight space 全微调 | DPPO, ReinFlow | 算力贵;和 diffusion/flow 的优化设计强耦合;大模型上需要大量系统/算法支撑 |
| Action space 残差 | Policy-Decorator (Po-Dec), Residual RL, Johannink2019 | 探索停留在低层动作;action chunk 维度随 horizon 线性增长 → 高维下探索低效;机器人上抖动、潜在不安全 |
| Latent (diffusion noise) steering | DSRL (wagenmaker2025steering) | 把 RL 介入移到初始 noise,但这个空间维度 = 动作维度,horizon / DoF 增大时效率受限 |
| Bottleneck latent for IL | SOE (jin2025soe) | 用 VIB latent 做 on-manifold 采样 + 重训 base policy,是 iterative IL 而非 RL steering |
2.4 论文解决方案(一句话)¶
离线时给 base policy 挂一个 plug-and-play 的 VIB bottleneck 模块(不干扰原 IL 路径),在线时冻结整个 base policy,只用 SAC 学习对这个 16/32 维 bottleneck latent \(\vz\) 的残差扰动 \(\Delta\vz\),扰动后的 \(\tilde{\vz}\) 经冻结的 VIB decoder 解码成条件 \(\tilde{\vc}\),再喂给冻结的 flow model 生成动作 —— 即在一个 compact、task-relevant 的 latent 接口上 steer 策略。
2.5 与前序工作的关系¶
- SOE (jin2025soe):最直接的来源。ZPRL 复用了 SOE 的 VIB bottleneck 思路与 stop-gradient plug-in 设计,但用途不同:SOE 是放大后验方差做随机采样、保留成功轨迹去重训 base policy(iterative IL);ZPRL 主张这个 latent 本身就蕴含 steering 潜力,用 RL 去扰动它而不是重训。
- Deep VIB (alemi2017deep):VIB 目标与变分上界的来源。
- DSRL (wagenmaker2025steering):最近的 latent steering 竞品(steer diffusion noise)。ZPRL 的差异是用一个维度更低、更对齐任务的 bottleneck 而非与动作同维的 noise。
- Policy-Decorator (yuan2025policy):action-residual 代表,全文最主要的对照基线(仿真 + 真机都跑)。
- Flow-matching policy (liu2023flow):base policy 的实例化(也兼容 diffusion)。代码基于 Diffusion Policy (chi2023diffusion) 改造(替换为 FM 目标 + 加在线 RL pipeline)。
- SAC (haarnoja2019soft):在线 RL 算法。
3. 方法介绍¶
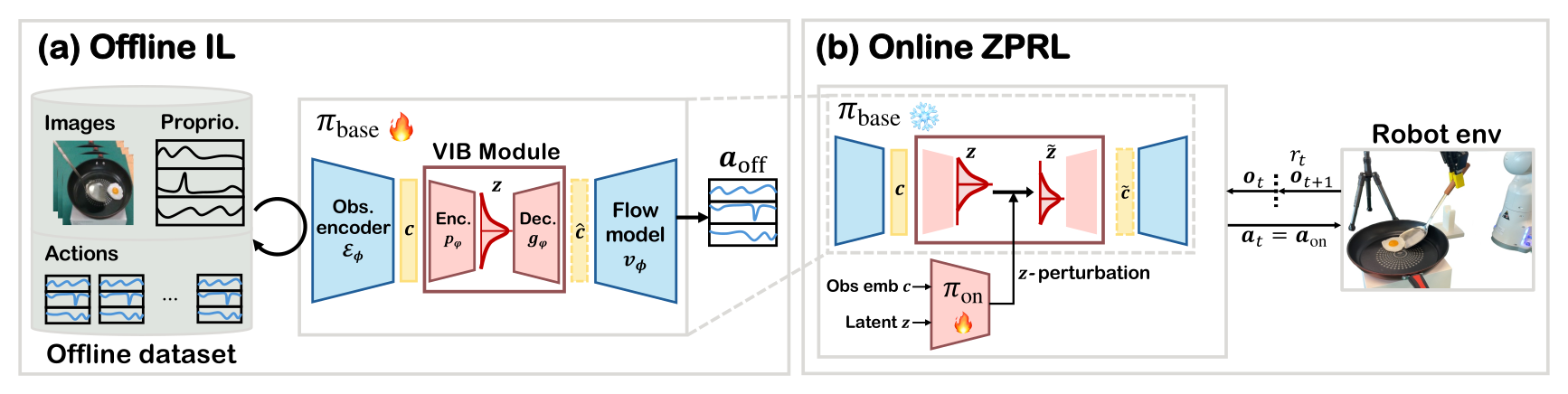 Figure 2:(a) 离线 —— flow-based 策略正常训练,同时在 observation embedding \(\vc\) 上挂一条 VIB 支路(Enc \(p_\varphi\) → 采样 \(\vz\) → Dec \(g_\varphi\) → \(\hat{\vc}\)),梯度被 stop-grad 隔离,不动 base。(b) 在线 —— 冻结整个 backbone,只有一个小 actor \(\pi_{\mathrm{on}}\) 读 \((\vc,\vz)\) 预测 \(\Delta\vz\),得 \(\tilde{\vz}=\vz+\lambda\Delta\vz\),经冻结 decoder + flow 输出 \(\va_{\mathrm{on}}\) 与环境交互。
Figure 2:(a) 离线 —— flow-based 策略正常训练,同时在 observation embedding \(\vc\) 上挂一条 VIB 支路(Enc \(p_\varphi\) → 采样 \(\vz\) → Dec \(g_\varphi\) → \(\hat{\vc}\)),梯度被 stop-grad 隔离,不动 base。(b) 在线 —— 冻结整个 backbone,只有一个小 actor \(\pi_{\mathrm{on}}\) 读 \((\vc,\vz)\) 预测 \(\Delta\vz\),得 \(\tilde{\vz}=\vz+\lambda\Delta\vz\),经冻结 decoder + flow 输出 \(\va_{\mathrm{on}}\) 与环境交互。
3.1 形式化¶
机器人操作建模成观察条件的 episodic MDP \(\gM=\langle \gS,\gA,T,\rho_0,\gR,\gamma\rangle\),动作是期望末端位姿。策略只看观察 \(\vo_t\)(图像 + proprioception),默认 sparse binary reward(成功 \(r_t=1\) 并终止,否则 0)。目标是最大化 \(Q^\pi(\vo,\va)=\E_\pi[\sum_t \gamma^t r_t]\)。
Base policy = encoder + 条件 flow model。给观察 \(\vo\),encoder 产生条件向量 \(\vc=\gE(\vo)\),flow model 据此生成动作。Flow-matching 训练学一个速度场 \(v_\phi\),把噪声 \(\va^1=\vw\sim\gN(\bm0,\mI)\) 沿 ODE 输运到干净动作 \(\va^0=\va\),插值点 \(\va^k=(1-k)\va^0+k\va^1\):
推理时从噪声反向积分(论文用 2 步 采样 \(1\to0.01\to0\))得到动作。注意 \(\va\) 指多步动作 chunk。
3.2 Bottleneck Task Latent(VIB 模块)¶
直接在 action space 探索随 horizon 变难(chunk 维度随时间线性增长,加高斯噪声只会产生高频抖动)。理想的接口应保留 action-relevant 结构、丢掉无关细节。论文采用 information bottleneck 目标:
其中 \(\vc=\gE(\vo)\),\(\beta\) 控制"信息量 vs 紧凑度"权衡。用变分编码器-解码器实例化得到标准 VIB 上界;在 flow 实例里,第一项就用 FM 目标实现(把重建特征 \(\hat{\vc}=g_\varphi(\vz)\) 替换原 \(\vc\) 作条件):
后验取对角高斯,先验 \(r(\rvz)=\gN(\bm0,\mI)\)。关键工程细节:\(\gL_{\mathrm{VIB}}\) 的梯度被 stop-gradient 隔离,不更新 base encoder \(\gE_\phi\) 和 flow \(v_\phi\) —— 离线总损失 \(\gL_{\mathrm{off}}=\gL_{\mathrm{IL}}(\phi)+\gL_{\mathrm{VIB}}(\varphi)\) 里 VIB 是纯 plug-in 旁路,保证 base policy 性能不受影响。
3.3 RL 在 Bottleneck Latent 上做残差扰动¶
在线时不覆盖离线学到的 \(\vz\),而是加残差:
解码 \(\tilde{\vc}=g_\varphi(\tilde{\vz})\) 替换原条件,动作由冻结 base 生成 \(\va_{\mathrm{on}}\sim\pi_{\mathrm{base}}(\cdot|\tilde{\vc})\)。
为什么 critic 定义在 \(\tilde{\vz}\) 而不是 \(\Delta\vz\):因为后验 \(p_\varphi(\vz|\vc)\) 是随机的,同一个 \(\Delta\vz\) 加到不同 \(\vz\) 上会诱导不同动作分布,所以 \(\Delta\vz\) 单独不足以确定下游动作、无法赋一个良定义的 value。实现上 actor 输入 \((\vc,\vz)\) 预测 \(\Delta\vz\),critic 评估 \((\vc,\tilde{\vz})\)。
两点效率优势:(1) 仍能影响整个 action chunk,但操作在低维空间 —— action chunk 最多约 100 维,bottleneck latent 只有 16 或 32 维;(2) 扰动作用在条件而非动作上,最终动作仍由预训练 generator 产生,被离线数据分布"结构化",更稳更安全。
3.4 在线 RL 目标与设计选择¶
用 SAC。只更新残差 actor \(\pi_\theta\) 与 latent critic \(Q_\psi\),base 全冻结。Actor / Critic loss:
几个值得注意的选择:
- Q 函数里去掉 entropy 项 以稳定训练。
- 扰动尺度 \(\lambda\):太小 steer 无力,太大则 \(\tilde{\vz}\) 跑出预训练 latent 支撑、decoder 难以可靠解码。经验法则:让 \(\mathrm{RMS}(\lambda\Delta\vz)\) 约为 \(\mathrm{RMS}(\vz)\) 的 10%–20%,再按早期学习曲线微调。每个任务一个固定 \(\lambda\)。
- UTD(update-to-data):不追求超高 UTD(10/20),因为真机瓶颈在交互而非更新;仿真用 UTD=1,真机 2 或 5。
- 为什么不用 action-space critic:那需要在 critic 优化里反复跑动作去噪/积分,即使 2 步也拖慢 wall-clock;故直接在 latent 扰动空间上训 critic。
3.x Implementation Details¶
- 代码基座:Diffusion Policy,替换为 FM 目标 + 在线 RL pipeline。
- 观察编码:每相机每步图像经从头训的 ResNet-18 → 256 维 embedding;proprioception 用原始向量(仿真为末端位姿,真机为关节角)。
- Flow backbone:沿 action-chunk 维做卷积的 1D U-Net,通道宽 128-256-512(仿真)/ 256-384-512(真机)。
- VIB 模块:encoder + decoder 各一个 4 层、宽 256、GELU 的 MLP。
- Flow schedule:离线 100 步离散化;推理 2 步(\(1\to0.01\to0\))。离线预训练 1000 epochs。
- 在线超参:batch 256,actor lr 1e-4,critic lr 3e-4,\(\gamma\)=0.99(transport 0.997,Insert Bills 0.998),target entropy \(-d/2\),初始温度 0.01,critic 个数 2(真机 5,Insert Bills 10)。
- 真机平台:xArm-6(Place Orange)、Franka Panda(Flip Egg),Robotiq 2F-85 夹爪,第三视角 + 双臂腕部相机;控制频率 10–30 Hz。VR 头显采集演示。人类监督员在每个 episode 提供 sparse reward 并复位工作区。
4. 结果对比¶
4.1 仿真:8 任务 / 3 benchmark¶
任务:Robomimic(can / square / transport,官方 MH 混合质量 100 条)、Adroit(door / hammer / pen)、Metaworld(box-close / push-wall),后两个用 medium-expert 策略生成 100 条。视觉输入(图像 + proprio)。基线:DPPO、ReinFlow(全微调)、Po-Dec(action 残差)、DSRL(noise steering)。
结论:ZPRL 在全部 8 任务都达到强 final SR,且在线适配速度居前列,对平行夹爪(Robomimic / Metaworld)与灵巧手(Adroit)都成立。唯一例外是 Metaworld 两个任务早期 Po-Dec 更快 —— 因为这俩 action chunk 只有 8 维(chunk size 2 × 4 维/步),标准 action-space RL 已够用,latent 优势不明显;但后期 ZPRL 仍反超。
4.2 关键消融(Robomimic square,Table 1)¶
| Setting | Steps(×10⁶) to SR=0.9 ↓ | Final SR ↑ |
|---|---|---|
| \(\lambda=0.10\) | 2.40 | 0.86 |
| \(\lambda=0.15\) | 1.54 | 0.95 |
| \(\lambda=0.20\) | 1.16 | 0.98 |
| \(\lambda=0.25\) | 1.15 | 0.96 |
| \(\lambda=0.50\) | N/A | 0.74 |
| \(\dim(\vz)=4\) | N/A | 0.68 |
| \(\dim(\vz)=8\) | 1.23 | 0.98 |
| \(\dim(\vz)=16\) | 1.16 | 0.98 |
| \(\dim(\vz)=32\) | 1.08 | 0.99 |
| Po-Dec (\(\dim(\va)=40\)) | 1.68 | 0.92 |
| \(\dim(\vz)=64\) | 1.29 | 0.94 |
| \(\dim(\vz)=128\) | 1.90 | 0.91 |
| \(N_{\mathrm{demo}}=25\) | 2.54 | 0.86 |
| \(N_{\mathrm{demo}}=100\) | 1.16 | 0.98 |
要点:(1) ResEmb 对照(直接在高维 observation embedding 上学残差、无 VIB 压缩)一致更差更不稳 → 增益不来自"扰动任意中间特征"。(2) \(\lambda\) 控制探索-稳定权衡,0.20 最佳,0.50 直接崩。(3) 不是单纯降维:\(\dim(\vz)=64\) 已超过 Po-Dec 的动作维 40,ZPRL 仍更快更好(1.29M vs 1.68M,0.94 vs 0.92)—— 关键是 RL 是否在 task-relevant 空间里探索;\(\dim\) 太小(4)或太大(128)都伤。(4) 离线数据越少,latent manifold 覆盖越窄,两阶段都受损(但 25 条仍可用)。
4.3 平滑性(Robomimic square,Table 2)¶
末端位置的有限差分速度/加速度([Po-Dec | ZPRL],越低越平滑):
| Env Steps | Vel_EE (m/s) | Acc_EE (m/s²) |
|---|---|---|
| 0 | 0.14 | 0.15 | 3.43 | 3.74 |
| 0.8M | 0.33 | 0.22 | 10.42 | 6.35 |
| 1.6M | 0.32 | 0.21 | 9.78 | 6.03 |
| 2.4M | 0.31 | 0.22 | 9.60 | 5.79 |
2.4M 步时 ZPRL 把速度降约 29%、加速度降约 39%。机制:action 残差注入持续高频振荡,而 ZPRL 扰动 latent 后仍靠冻结 flow 生成动作 → 更平滑。
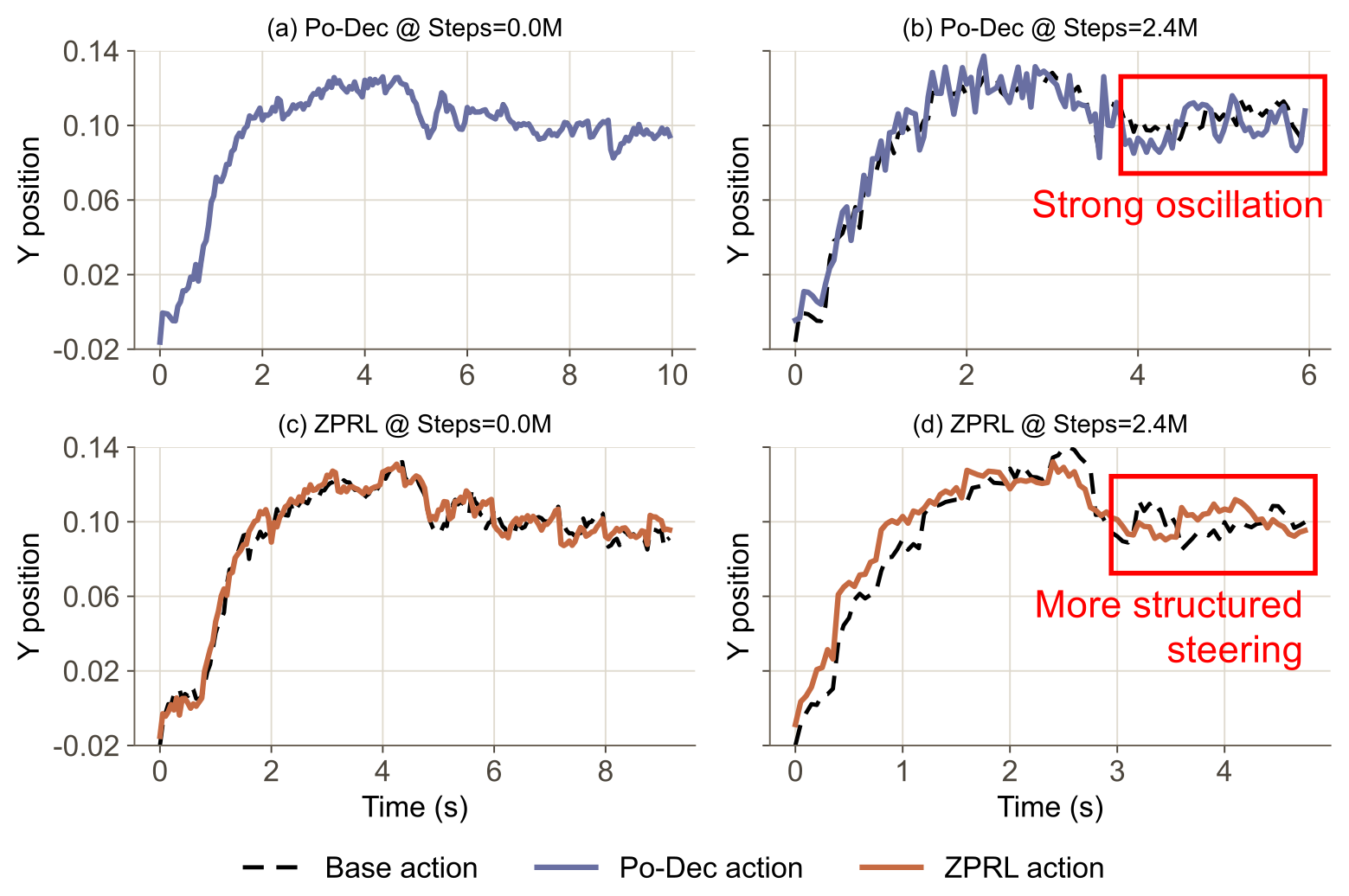 Figure 3:square 任务 y 轴期望位置随时间。两者初始都同样抖(随机初始化的 RL 策略),但在线适配后 Po-Dec 振荡越来越强(红框),ZPRL 仍保持结构化、规整的 steering。
Figure 3:square 任务 y 轴期望位置随时间。两者初始都同样抖(随机初始化的 RL 策略),但在线适配后 Po-Dec 振荡越来越强(红框),ZPRL 仍保持结构化、规整的 steering。
4.4 真机:4 任务¶
 Figure 4:(a) Place Orange 单臂抓放、(b) Flip Egg 高动态接触(末端加速度可达 6 m/s²)、(c) Open Box 双臂协调开锁、(d) Insert Bills 双臂 + 可形变纸币插入。覆盖了从 pick-and-place 到 deformable-object manipulation 的难度梯度。
Figure 4:(a) Place Orange 单臂抓放、(b) Flip Egg 高动态接触(末端加速度可达 6 m/s²)、(c) Open Box 双臂协调开锁、(d) Insert Bills 双臂 + 可形变纸币插入。覆盖了从 pick-and-place 到 deformable-object manipulation 的难度梯度。
| 任务 | 控制频率 | 对照 | ZPRL 结果 |
|---|---|---|---|
| Place Orange | 30 Hz | Po-Dec、base | 更快达高 SR;但 episode 更长(高频 + 谨慎对位) |
| Flip Egg | 10 Hz | Po-Dec、base | final SR 比 Po-Dec 高约 12.5%,episode 缩短约 6% |
| Open Box | 20 Hz | Po-Dec、base | final SR 比 Po-Dec 高约 7.5%,episode 缩短约 6% |
| Insert Bills | 20 Hz | 仅 ZPRL | base 20% → final 77.5% |
总体:ZPRL 比 imitation base policy 平均 SR 提升 33.7%。鲁棒性(zero-shot,人为扰动 / 换物体 / OOD 布局,每例 10 次)平均 SR 69%,对人为干扰、外观变化(塑料橙 1.0、不同形状/颜色蛋 0.8/0.9)尚可;最难的 Real egg(软真蛋改变接触力学)掉到 0.5,Insert Bills 在视觉干扰/人为扰动下也明显下降。
 Figure 5:各任务残留失败模式 —— PO 抓偏/撞榨汁机;FE 插太浅翻不动 / 太猛把蛋甩出锅;OB 漏掉左/右锁扣;IB 因遮挡半途卡住 / 纸币弯折撞钱包。这些正是 §5.2 里"受限于 base policy 支撑"的直接证据。
Figure 5:各任务残留失败模式 —— PO 抓偏/撞榨汁机;FE 插太浅翻不动 / 太猛把蛋甩出锅;OB 漏掉左/右锁扣;IB 因遮挡半途卡住 / 纸币弯折撞钱包。这些正是 §5.2 里"受限于 base policy 支撑"的直接证据。
附录还用 UMAP + Mahalanobis 距离 分析:ZPRL 主要是重映射 (remap) state–action 关联而非凭空创造新动作(扰动后 \(\tilde{\vc}\)、\(\va\) 的点云仍与 base 大体重叠,只是局部密度/配对被重组);并量化"必须保持 local"——\(\lambda\) 越大,\(\tilde{\vz}\) 的 OOD 程度与解码特征位移越大,经验上把 \(\tilde{\vc}\) 的平均 L2 位移控制在约 0.8 以内效果好。\(\beta\)(KL 权重,\(10^{-3}\!\sim\!10^{-5}\))对结果几乎无影响。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 接口选址精准:把 RL 介入点放在 VIB bottleneck,同时拿到 compact(16/32 维 vs action chunk 最多 ~100 维)与 structured(冻结 decoder+flow 把动作锁在流形上)两个好处,正好补上 weight-space(贵)和 action-space(抖)各自的短板。这是全文最干净的 design 论证。
- critic 定义在 \(\tilde{\vz}\) 而非 \(\Delta\vz\) 的论证扎实:因为后验随机,同一 \(\Delta\vz\) 加到不同 \(\vz\) 上诱导不同动作,\(\Delta\vz\) 无法良定义 value。这是对 MDP 状态定义的正确处理,不是随手选的。
- plug-in stop-gradient 设计:VIB 旁路梯度不回传 base,保证"加了 bottleneck 不掉点",让方法对任何 encoder→decoder 式 base policy 都能挂载(在该架构假设下)。
- 平滑性是涌现的副产品而非手工正则:因为扰动 latent 后仍由冻结 flow 生成动作,速度/加速度自然更低(29%/39%),在高动态 Flip Egg 这种"既要快又要精确接触"的任务上是真正的实用优势——Po-Dec 甚至要额外加 3 步时间滤波才能上硬件。
- dim 消融直接反驳"只是降维"的质疑:\(\dim(\vz)=64>\) Po-Dec 的 40 维仍更优,把功劳归到"task-relevant 空间 + locality"而非单纯维度,实验设计有针对性。
- 真机广度可观:单臂 / 双臂 / 可形变 / 高动态接触都覆盖,Insert Bills 从 20% 拉到 77.5% 是有分量的真机结果,且补了 OOD / 人为扰动鲁棒性测试。
- 机制分析诚实:UMAP + Mahalanobis 把"remap 而非 create"和"必须 local"都量化了,没有过度神化方法。
5.2 做得不够好 / 值得质疑的地方¶
- 性能被 base policy 支撑封顶(作者自己承认):ZPRL 是"重组/重加权"已编码的行为,而非"创造"新技能。当 corner case 需要离线数据里缺失的技能(如把弯折的纸币在内袋里压平)时几乎无能为力。这是冻结 base 设计的根本天花板,意味着增益会饱和。Figure 5 的失败模式基本都属此类。
- \(\lambda\) 高度 task-specific 且靠手调:Table(附录)里 \(\lambda\) 从 transport 的 0.1 一路到 box-close/push-wall 的 1.5,跨度 15 倍;square 上 \(\lambda=0.5\) 直接把 final SR 砸到 0.74。所谓"RMS 10–20%"只是事后经验法则,没有在线自适应机制。换任务要重新试 \(\lambda\),部署成本被低估。
- 真机只对照 Po-Dec 和 base:最关键的 latent 竞品 DSRL(noise steering)和全微调(DPPO/ReinFlow)在真机上完全没跑。于是"compact latent > noise steering"的论点只在仿真成立;真机的卖点 33.7% 是相对 base、不是相对最强基线。
- headline 数字的归因偏乐观:33.7% 平均提升被 Insert Bills(20%→77.5%,+57.5pt)严重拉高,而 IB 恰恰没有任何基线对照(只跑了 ZPRL)。其余三个任务相对 base 的逐项增益没单独列表。最亮眼的数字也是最不受控的。
- 真机 RL 不是自主的:sparse reward 靠人类监督员每个 episode 手动给,外加复位工作区,单任务在线 3.5–12.5 小时。reward/reset 的人力成本与采集时长被淡化,"few hours of online interaction"的措辞掩盖了 human-in-the-loop 的重负担。
- VIB 必须与 base 联合离线训练:无法 post-hoc 挂到现成 checkpoint 上(作者列为 limitation)。这恰恰削弱了"轻量适配"最该发力的场景 —— 直接拿开源 VLA(π0 等)来 steer;而且单一 encoder→decoder bottleneck 的架构假设不适配 cross-attention 式 VLA。
- "sample efficiency"领先有限:很多仿真任务里 ZPRL 与 DSRL 曲线相互重叠,作者措辞是"competitive"而非碾压;真正稳健领先的是 final SR + 平滑性。而且为了 wall-clock 故意压低 UTD,env-step 维度的对比口径要小心解读。
- 平滑性对比的公平性存疑:Po-Dec 需要额外 3 步时间滤波才能上硬件,文中说"即便加滤波仍不如 ZPRL",但没探索调 Po-Dec 的残差 scale 来换平滑;平滑度部分可能本就能靠 residual scale 调节,比较未必完全对等。
- 统计样本偏小:仿真 3 seeds;真机每个 checkpoint 仅 40 条评测、鲁棒性每例仅 10 次。真机 7.5% / 12.5% 的差距在 40 次试验上很可能落在噪声范围内,正文也没给真机柱状差距的置信区间。
- IB 目标本身的贡献存疑:\(\beta\) 在 \(10^{-3}\!\sim\!10^{-5}\) 几乎不影响结果。作者解读为"鲁棒",但也可能说明 information bottleneck 的压缩并没起多大作用——增益主因或许是低维 latent + locality,而非 IB 目标。ResEmb 消融只对照了"全维 embedding",缺一个"低维线性投影但无 KL/无随机后验"的对照来真正隔离 IB 的功劳。
5.3 值得继续探讨的方向¶
- post-hoc bottleneck:能否对已冻结的预训练策略,从其 embedding 蒸馏出一个 bottleneck latent 而不重训?这是把 ZPRL 推广到开源 VLA 的关键(作者自己的 open question)。
- 推广到 cross-attention VLA:π0 这类任务信息分散在多层 hidden state,哪个表征该当 steering 接口?并发工作 xu2026rl 用一个额外 transformer enc-dec 抽 task-relevant token(但它是另训 actor 加正则,而非 steer base)。
- 自适应 \(\lambda\):把固定常数换成 curriculum 或在线把 \(\lambda\) 绑到 Mahalanobis OOD 分数上,自动维持"够强但仍 local"。
- 真机补 DSRL 对照:在真机上跑 noise steering,才能让"compact latent > noise"的核心论点超出仿真。
- 与 residual-RL 技巧组合:作者指出 DICE-RL 等 action-residual 技巧可迁到 latent 空间,值得验证。
- 超出 RL 的 latent steering:用 latent 扰动做轻量 iterative IL 数据采集(每轮只补少量数据时,比每轮重训整策略更省)。
- 拆解 IB 的真实贡献:用"低维投影无 VIB" vs 完整 VIB 的对照,隔离 bottleneck 到底买到了什么。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目主页: https://manutdmoon.github.io/ZPRL/
- 关键 baseline / 相关论文: SOE (jin2025soe)、Deep VIB (alemi2017deep)、DSRL / noise steering (wagenmaker2025steering)、Policy-Decorator (yuan2025policy)、DPPO (ren2025dppo)、ReinFlow (zhang2025reinflow)、DICE-RL (sun2026dicerl)、并发工作 (xu2026rl)