OpenVLA: An Open-Source Vision-Language-Action Model¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: OpenVLA: An Open-Source Vision-Language-Action Model
- 作者: Moo Jin Kim*¹, Karl Pertsch*¹·², Siddharth Karamcheti*¹·³, Ted Xiao⁴, Ashwin Balakrishna³, Suraj Nair³, Rafael Rafailov¹, Ethan Foster¹, Grace Lam, Pannag Sanketi⁴, Quan Vuong⁵, Thomas Kollar³, Benjamin Burchfiel³, Russ Tedrake³·⁶, Dorsa Sadigh¹, Sergey Levine², Percy Liang¹, Chelsea Finn¹ — Stanford¹ + Berkeley² + TRI³ + Google DeepMind⁴ + Physical Intelligence⁵ + MIT⁶
- arXiv 编号: 2406.09246 (submitted 2024-06, CoRL 2024)
- 项目页: https://openvla.github.io
- 关键词: VLA, Llama 2, DINOv2 + SigLIP, Open-X Embodiment, LoRA, 4-bit quantization, action tokenization
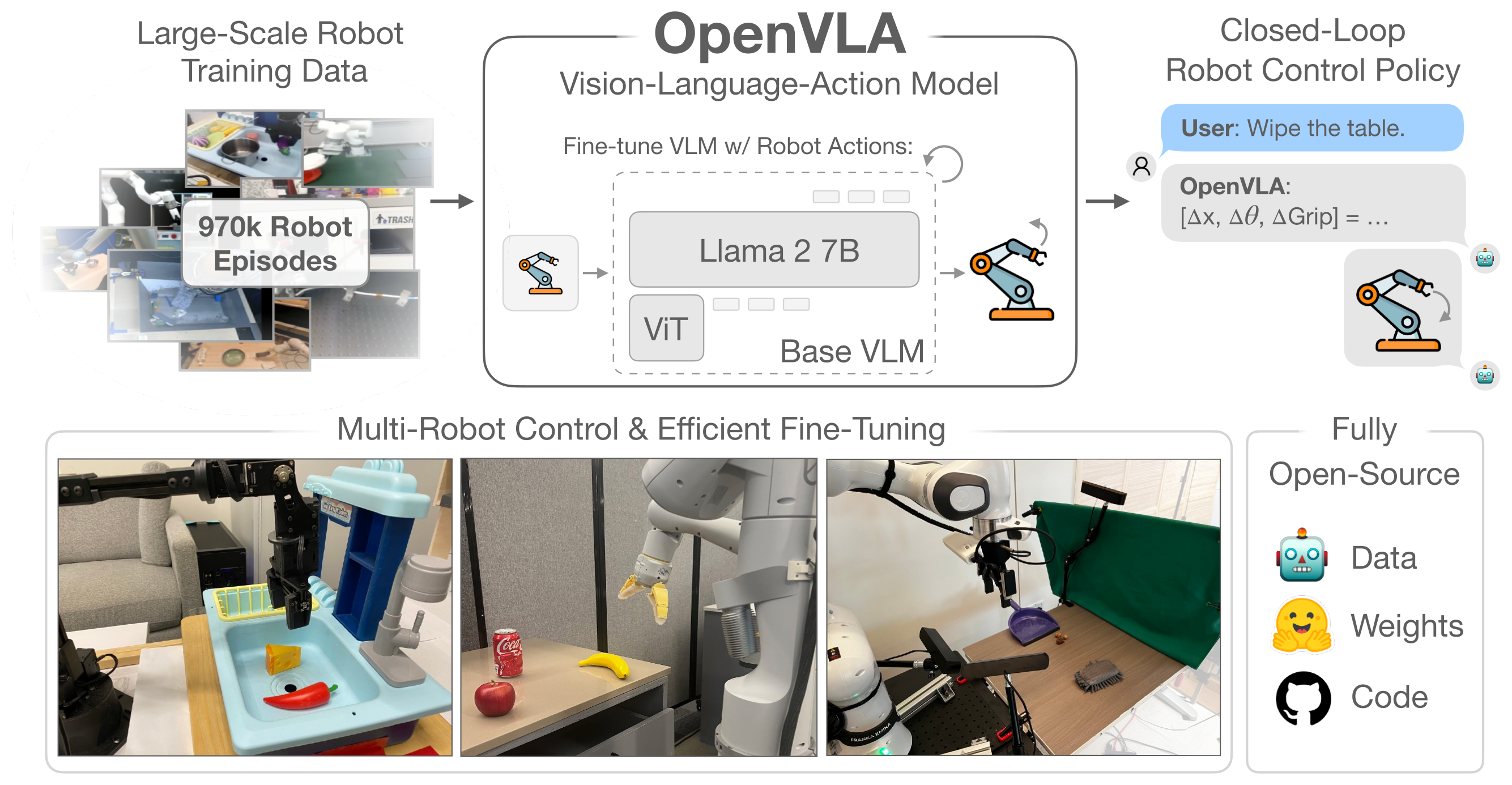 Figure 1:OpenVLA 是 7B 参数的开源 VLA,在 OXE 970K trajectory 上预训练,开箱即用控制多种机器人,且可经 LoRA 在消费级 GPU 上 finetune。所有 checkpoint + PyTorch 训练 pipeline 全部开源。
Figure 1:OpenVLA 是 7B 参数的开源 VLA,在 OXE 970K trajectory 上预训练,开箱即用控制多种机器人,且可经 LoRA 在消费级 GPU 上 finetune。所有 checkpoint + PyTorch 训练 pipeline 全部开源。
2. 文章介绍¶
2.1 解决的领域和问题¶
把「VLM + 机器人动作生成」的 RT-2 配方做成开源版本,并解决两个让 RT-2 没法被社区采纳的问题:(1) RT-2 (55B) 完全闭源——架构、训练数据、配方都不公开;(2) 大 VLA 怎么 finetune 到新机器人/任务,且能不能跑在消费级 GPU 上,完全没人系统研究过。
OpenVLA 想成为「机器人版的 Llama 2」——一个开源、可 finetune、可量化部署、文档齐全的 VLA base model,让社区不必每次都从零训。
2.2 Motivation¶
- Internet-scale 预训练对 generalization 至关重要:CLIP/SigLIP/Llama 2 这些 VLM 能跨域泛化,靠的是上 T tokens 的网页数据;而最大的机器人数据集 OXE 只有 ~1M trajectories,完全 reproduce 同等 scale 不现实。所以复用 VLM 当主干比 from-scratch 更有性价比。
- 闭源的问题:RT-2-X 是当时最强 VLA,但社区拿不到,只能从 inference API 黑盒调用——架构选择、数据配方、超参全部猜测。这导致 follow-up 工作大量依赖运气。
- finetune 是采纳的关键:用户买个 7B 模型只能 inference 是没用的,怎么用 10-150 demo 在自己机器人上 finetune 才是实际场景。RT-2 paper 完全没讨论这件事。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 闭源大 VLA | RT-2 (12B/55B)、RT-2-X | 不开源;finetune 不支持;社区无法复现/二次开发 |
| 开源跨本体 policy | Octo (93M)、RT-1-X (35M) | 没用大 LLM/VLM 主干;语义泛化和语言 grounding 弱 |
| Internet-pretrained VLM | PaLI、LLaVA、IDEFICS | 不是 policy;要自己拼 action head |
| 视觉表征 + scratch policy | R3M、VC-1 | 只 transfer 视觉,policy 主干仍要从头训 |
2.4 论文解决方案(一句话)¶
把 Prismatic-7B VLM(Llama 2 7B + 融合的 DINOv2 + SigLIP 双视觉编码器)在精心 curate 的 OXE 970K 真机数据上 full finetune,动作通过覆盖 Llama tokenizer 最末 256 个 token 实现 discrete-token autoregressive 预测;下游用 LoRA (rank 32) 在单卡 A100 10-15 小时就能 finetune 到新机器人,4-bit 量化让 inference 显存降到 7GB 而成功率不掉。
2.5 与前序工作的关系¶
- 架构基础是 Prismatic-7B (Karamcheti et al. 2024):一个标准的 VLM 三段式(vision encoder + projector + LLM backbone),最大的特色是 DINOv2 + SigLIP 双 vision encoder 通道拼接——DINOv2 提供空间几何特征、SigLIP 提供语义对齐,对机器人的空间推理特别重要。
- action tokenization 直接抄 RT-2:每维归一化到 [1, 99] percentile 之后 256-bin 均匀离散化(注意:不是 RT-2 的 min-max,是 percentile,避开 outlier);然后覆盖 Llama tokenizer 最不常用的 256 个 token(因为 Llama 只给 finetune 留了 100 special token,不够用)。Cross-entropy loss 只在动作 token 上算。
- 训练数据沿用 Octo 的混合权重:OXE 中保留单臂 EE 控制 + 至少有第三视角的数据集,套用 Octo 的「more diverse 翻倍 / 重复多的 down-weight」启发式 weighting。
- DROID 数据集放弃:尝试以 10% 权重加入但 action token accuracy 一直上不去,训练最后 1/3 移除。这是个被低估的负面结果,提示「数据规模不等于自动有效」。
3. 方法介绍¶
3.1 架构¶
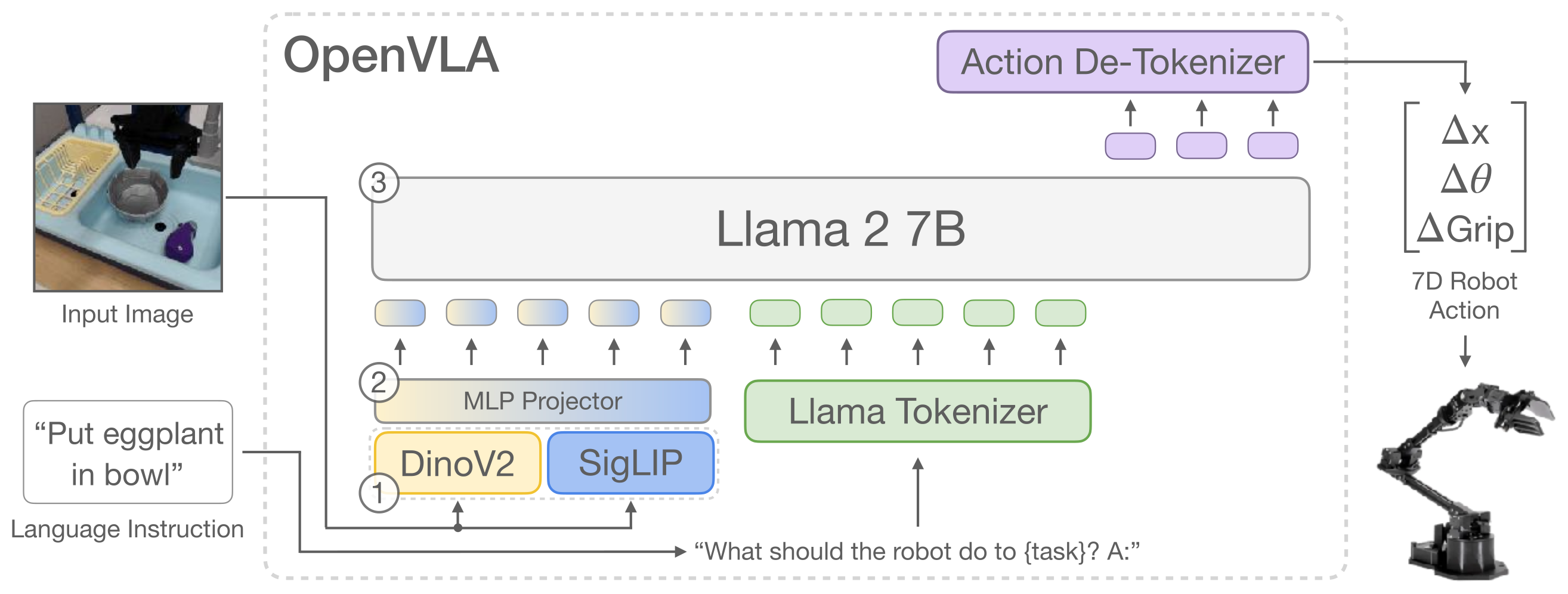 Figure 2:OpenVLA 的三段式架构。① 输入图像同时过 DINOv2(空间特征)和 SigLIP(语义特征),两路特征 channel-wise concat;② 一个 2 层 MLP projector 把视觉特征投到语言 embedding space;③ Llama 2 7B 接受 [image patches; "What should the robot do to {task}? A:"] 当 prefix,自回归产 7 个离散动作 token(3 平移 + 3 旋转 + 1 夹爪),de-tokenizer 反归一化成连续动作。
Figure 2:OpenVLA 的三段式架构。① 输入图像同时过 DINOv2(空间特征)和 SigLIP(语义特征),两路特征 channel-wise concat;② 一个 2 层 MLP projector 把视觉特征投到语言 embedding space;③ Llama 2 7B 接受 [image patches; "What should the robot do to {task}? A:"] 当 prefix,自回归产 7 个离散动作 token(3 平移 + 3 旋转 + 1 夹爪),de-tokenizer 反归一化成连续动作。
3.2 训练 procedure¶
Action discretization:每动作维度(7D = Δxyz + Δroll/pitch/yaw + gripper)独立离散到 256 bin(用 1-99 percentile 决定 bin 宽度)。这给出 N 个 [0, 255] 整数,覆盖 Llama tokenizer 最不常用的 256 个 token。训练用 next-token cross-entropy,只在 action token 位置算 loss。
Loss:标准 CE on action tokens only(image patch / prompt token 不算 loss)。
3.3 关键 design decisions(小规模 sweep 出来的)¶
四个 design choice 来自 BridgeData V2 上的预实验(不是 OXE 全集——为了加速 iteration):
- VLM backbone:Prismatic > LLaVA > IDEFICS-1。LLaVA 比 IDEFICS-1 在多物体语言 grounding 任务上高 35%;Prismatic 再超 LLaVA ~10%(双 vision encoder 的空间推理优势)。
- Image resolution:224×224 vs 384×384 没差别,但后者训练慢 3 倍——选 224。注意这跟标准 VLM benchmark 上高分辨率更好的趋势相反,作者也没解释。
- Vision encoder freeze vs finetune:标准 VLM 训练里冻结 vision encoder 表现更好,但 VLA 这边必须 finetune vision encoder——预训练 vision encoder 没捕捉到机器人控制需要的细粒度空间细节。
- Training epochs:VLM 一般 1-2 epoch,VLA 需要走完整个数据集 27 epoch,直到 action token accuracy 超过 95%。这暗示 VLM→VLA 的 distribution shift 比想象的大。
3.4 训练 infra¶
- 64 A100 GPU、14 天,共 21.5K A100-小时,batch size 2048。
- 用了 FSDP、AMP、FlashAttention。
- Learning rate
2e-5固定(与 VLM 预训练一致),没用 warmup。 - Inference:bfloat16 占 15GB 显存,RTX 4090 上约 6 Hz。
3.5 Parameter-Efficient Finetune¶
| 策略 | 成功率 | 训练参数 | 显存 (batch 16) |
|---|---|---|---|
| Full FT | 69.7% | 7188M | 163 GB (2GPU FSDP) |
| Last layer only | 30.3% | 465M | 51 GB |
| Frozen vision | 47.0% | 6760M | 156 GB (2GPU) |
| Sandwich (vision + token embed + last layer) | 62.1% | 914M | 64 GB |
| LoRA rank=32 | 68.2% | 97.6M (1.4%) | 59.7 GB |
| LoRA rank=64 | 68.2% | 195M | 60.5 GB |
LoRA 拿到与 full FT 几乎相同的性能(68.2 vs 69.7%),但只用 1.4% 参数 + 单卡 A100 即可。这是 OpenVLA 论文实际最重要的一个工程贡献——把「7B VLA finetune」从「需要 server cluster」降到「需要一张 A100 或两张 4090」。
3.6 量化部署¶
| Precision | Bridge Success | VRAM |
|---|---|---|
| bfloat16 (default) | 71.3% | 16.8 GB |
| int8 | 58.1% | 10.2 GB |
| int4 | 71.9% | 7.0 GB |
int4 不掉点而显存减半——可以塞进 RTX 4080 / 3090 / 4090。int8 反而掉点的原因是吞吐量降到 1.2 Hz、远低于 BridgeData V2 的 5Hz 控制频率,系统动力学被打乱而非量化本身有损。这是个很重要的诊断:对于实时控制 policy,量化的间接代价(推理速度)可能比直接代价(数值精度)更大。
3.x Implementation Details¶
| 项目 | 数值 |
|---|---|
| 模型规模 | 7B (Llama 2) + 600M vision (DINOv2+SigLIP) ≈ 7.6B 总 |
| 训练数据 | OXE 子集 970K trajectories(Octo 的 mixture 基础 + 短暂加过 DROID) |
| 动作 token | 256 bins × 7 dims,覆盖 Llama tokenizer 末尾 256 token |
| Bin width | 1-99 percentile(不是 min-max) |
| 训练 | 64 A100 × 14 天 = 21.5K A100-hours,batch 2048,bf16,27 epoch |
| Inference | bf16 15GB,4090 上 6 Hz;int4 7GB |
| LoRA Finetune | A100 × 10-15h,rank 32,全 linear 层 |
| 控制频率 | Franka-Tabletop 5 Hz / Franka-DROID 15 Hz |
4. 结果对比¶
4.1 BridgeData V2 / Google robot zero-shot¶
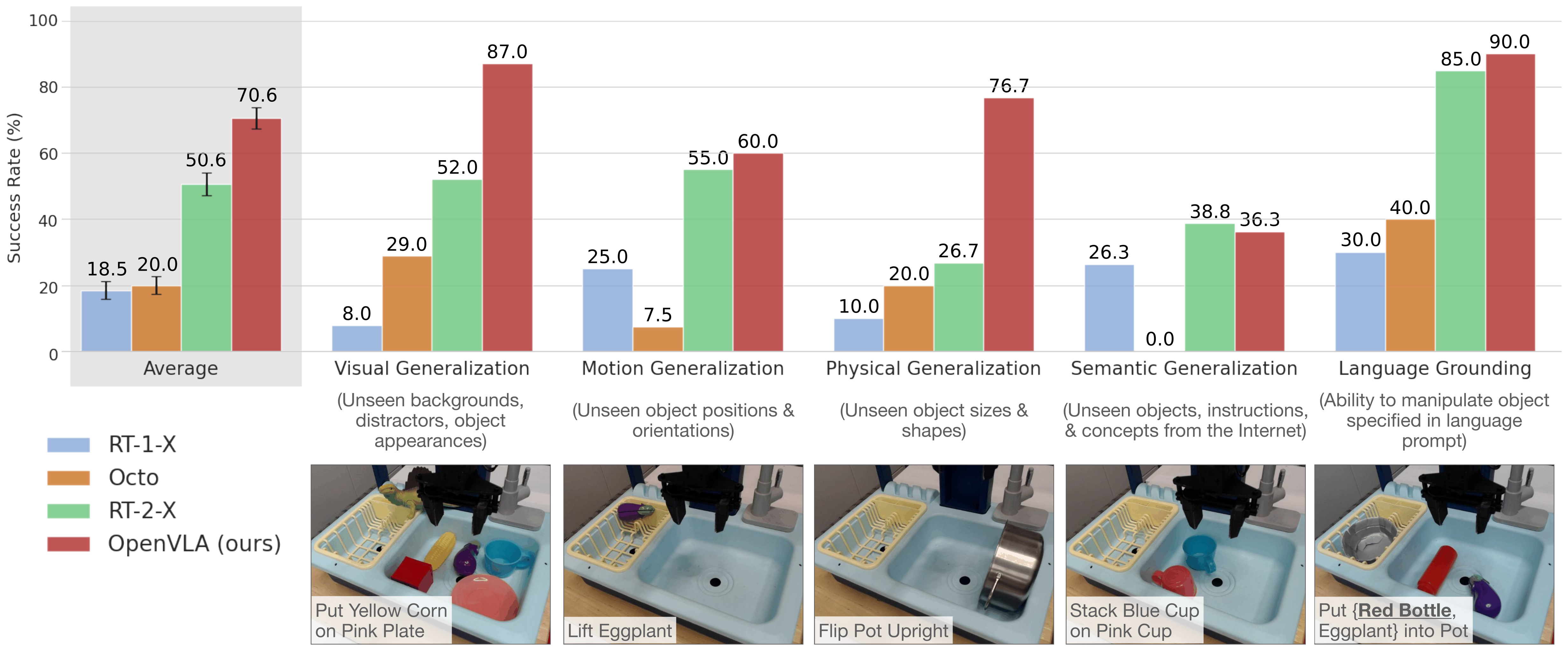 Figure 3:BridgeData V2 WidowX 上 170 rollout 的成功率。OpenVLA (7B) 在所有类别(visual / motion / physical / 语言 grounding)都超过闭源 RT-2-X (55B),唯一例外是 semantic generalization——因为 RT-2-X 用了 Internet 数据 co-finetune 而 OpenVLA 只在机器人数据上 finetune。
Figure 3:BridgeData V2 WidowX 上 170 rollout 的成功率。OpenVLA (7B) 在所有类别(visual / motion / physical / 语言 grounding)都超过闭源 RT-2-X (55B),唯一例外是 semantic generalization——因为 RT-2-X 用了 Internet 数据 co-finetune 而 OpenVLA 只在机器人数据上 finetune。
| 方法 | 参数 | Bridge V2 平均 | Google robot 平均 |
|---|---|---|---|
| RT-1-X | 35M | 显著低 | 显著低 |
| Octo | 93M | 显著低 | 显著低 |
| RT-2-X | 55B | ~55% | ~45% |
| OpenVLA | 7B | ~71% (+16.5pp) | ≈持平 RT-2-X |
OpenVLA 用 RT-2-X 的 1/7 参数赢 16.5pp,作者归因三件事:(1) 970K vs 350K 数据;(2) Bridge data 里的 all-zero action 被过滤;(3) DINOv2+SigLIP 融合视觉编码器。
4.2 Finetune 到 Franka 新任务(Octo / Diffusion Policy 同台)¶
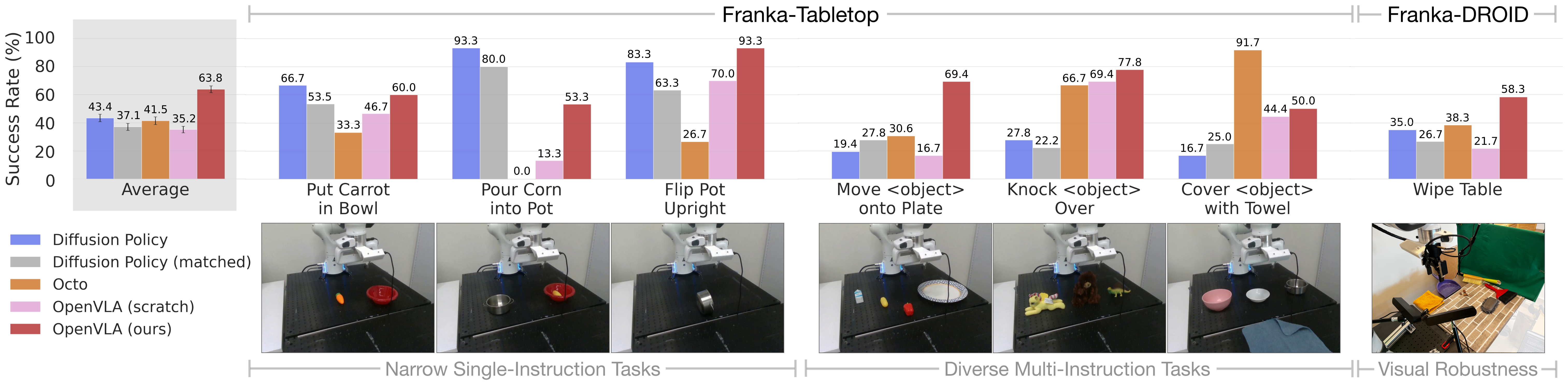 Figure 4:七个 Franka task(Tabletop 5Hz + DROID 15Hz),每个 10-150 demo。OpenVLA 是唯一一个在所有任务上都 ≥ 50% 成功率的方法。Diffusion Policy 在窄单指令任务上更精细;Octo 和 OpenVLA 在多物体语言 grounding 任务上更强。
Figure 4:七个 Franka task(Tabletop 5Hz + DROID 15Hz),每个 10-150 demo。OpenVLA 是唯一一个在所有任务上都 ≥ 50% 成功率的方法。Diffusion Policy 在窄单指令任务上更精细;Octo 和 OpenVLA 在多物体语言 grounding 任务上更强。
| 方法 | 多物体 + 语言 grounding 任务 | 窄单指令任务 |
|---|---|---|
| Diffusion Policy (scratch) | 弱 | 强(轨迹平滑) |
| Octo (finetuned) | 中 | 中 |
| OpenVLA (scratch from Prismatic) | 中(弱于 finetuned) | — |
| OpenVLA (finetuned) | 强(最高聚合) | 中 |
主要 takeaway:OpenVLA 是「diverse 多任务 finetune」的最强默认选择,而 Diffusion Policy 在「单一精细任务」上仍有优势(因为它有 action chunking + temporal smoothing)。这条 limitation 直接为 OpenVLA-OFT 的诞生埋下伏笔。
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- DINOv2 + SigLIP 双视觉编码器这一选择带来 ~10% 提升(vs LLaVA 单 SigLIP)。原理是 DINOv2 的 spatial reasoning 特征对机器人控制重要——这是「VLM 直接拿来用」与「为机器人定制」之间的真正分界。
- LoRA rank 32 几乎打平 full FT(68.2 vs 69.7%),但只动 1.4% 参数 + 单卡 A100 跑完——这是论文最有持久影响的实证发现,把社区采用 VLA 的门槛从「server cluster」降到「一张 A100」。
- int4 量化不掉点(71.9 vs 71.3%)且 7GB 显存——可以塞进消费 GPU。但更宝贵的是诊断出 int8 掉点是推理慢导致系统动力学不匹配,这种因果分析对部署很有价值。
- 训练数据 curation 写得很诚实:DROID 加入失败、最后 1/3 移除——这种「负面结果」对后续团队(π₀ 后来在 DROID 上重训了 single-task fast 版本)有警示价值。
- 真·开源全栈:weights、训练代码、LoRA finetune notebook、HF AutoModel 接入、远程 inference server——一整套真能上手的工具链。社区生态(LeRobot、Karl 后来去做 π₀、Sid 去做 SmolVLA)都基于此。
- fine vision encoder 是关键发现:标准 VLM 智慧说「冻结 vision encoder 更好」,但 VLA 必须解冻——这条经验后续被 SmolVLA、π₀ 系列继承。
5.2 做得不够好的地方 / 值得质疑的地方¶
- Autoregressive 推理太慢(6 Hz on 4090):每动作要顺序产 7 个 token,且单卡 A5000 上只跑到 1.2 Hz(int8 时)。没法上高频控制机器人(ALOHA 25-50 Hz、双臂更糟)。这个 limitation 后来被 OpenVLA-OFT(同一作者 Moo Jin Kim)证明完全可以通过 parallel decoding + 连续动作头解决——即 OpenVLA 自己的 autoregressive discrete 设计是个偏保守选择。
- 没有 action chunking / temporal smoothing:Diffusion Policy 在 narrow task 上更精细,本质是因为它一次产 K 步动作 + ensemble smoothing。OpenVLA 一次只产 1 步、没有 chunking——这在精细任务上是单点弱项,论文里也直接承认了。
- DROID 失败的根因没追究:作者说"larger mixture weight or model may be required"——但 DROID 是高质量大数据集,加进去 token accuracy 不涨是个红信号,可能反映 BPE-style discrete action 在不同夹爪/控制频率间的对齐问题,也可能是 mixture 配方的问题。这个负面结果值得更细的诊断(最终是 π₀-FAST 在 DCT+BPE 的更新 tokenizer 上重新拿下 DROID)。
- 224×224 vs 384×384 没差异这条与 VLM benchmark 趋势相反,作者没解释。猜测是机器人任务空间分辨率本身不高(夹爪状态、物体位置都是几十像素级),但缺消融。
- 27 epoch 才训完:相比 VLM 1-2 epoch 多了一个数量级,暗示 VLM → VLA 的 distribution shift 比想象大。这件事的 implication 是「从一个不那么对齐的 base model 起步代价比预期大」,但论文没深入讨论。
- Bridge 上 RT-2-X 的对比稍微不公平:作者自己列了三个原因(970K vs 350K data、Bridge 清洗、双 vision encoder),但没拆开每个因素的贡献。OpenVLA 赢 16.5pp 究竟是数据、清洗、还是架构?答案缺失。
- Franka Tabletop 5Hz 与 RT-2-X / Octo 的频率不一致:Octo 在 5Hz 训过 Bridge data,但 OpenVLA finetune 任务用的是 5/15 Hz Franka,跨频率比较会引入额外噪声变量。
- Semantic generalization 上输给 RT-2-X:这是 VLM 预训练知识保留的问题——OpenVLA 没做 co-finetune(机器人数据 + Internet 数据混训),所以语义能力在 robot finetune 中被「灾难性遗忘」掉一部分。Knowledge Insulation (KI) 后来在 π₀.₅ 的工作里专门修这件事(梯度 stop-grad + VLM data 共训)。
- 「Prismatic 是 best backbone」的结论从 Bridge 单数据集 sweep 得出,没在 OXE 全集上验证。"smaller-scale experiments" 的迁移性是问号。
5.3 值得继续探讨的方向¶
- Parallel decoding + L1 regression:后续 OpenVLA-OFT 同作者证明这条路能在 LIBERO 上 76.5% → 97.1%、26× 速度提升(见本库 OFT 笔记)。这是 OpenVLA 的「自我修订」。
- Knowledge Insulation 抗遗忘:semantic generalization 输给 RT-2-X 这事被 π₀.₅ 的 KI 配方修了(stop-grad + VLM data co-train)。
- Action chunking + dexterity:narrow task 上输 Diffusion Policy 的根因是缺 chunking——OFT 加上了,π₀ 也加上了,这条 limitation 现已不存在。
- 离散 vs 连续 action:OpenVLA 的 discrete-token 路线 vs Octo / π₀ 的 continuous diffusion——OFT 验证了在 7B 主干上 L1 regression 就够,更复杂的 diffusion 收益边际。这条争论至今未完全 settle(FAST/ActionCodec 还在改进 discrete 路线)。
- 大规模 cross-embodiment + dual-arm pretrain:OpenVLA 完全没在 bimanual 数据上 pretrain,导致 OFT 时代必须靠 finetune 配方硬刚 π₀ / RDT-1B 这种 bimanual 出身的对手——下一代 OpenVLA 显然需要纳入双臂。
- DROID 的真正消化:直到 π₀-FAST 才用 DCT+BPE tokenizer 把 DROID 训通。OpenVLA 上「DROID 加不进来」这个负面结果值得回头做归因(是 token accuracy 评估方式不公?还是 BPE 不适合 DROID 的高频高维动作分布?)。
参考资源¶
- 论文 PDF: paper.pdf
- LaTeX 源码: source/
- 项目页: openvla.github.io
- 关键相关论文:
- RT-2 / RT-2-X (zitkovich2023rt / open_x_embodiment_rt_x_2023) — 闭源 55B VLA,OpenVLA 的主对照
- Prismatic (karamcheti2024prismatic) — OpenVLA 的 VLM backbone
- Octo (octo_2023) — 数据混合 weighting 沿用,本库有 Octo 笔记
- Llama 2 (touvron2023llama2) — LLM 主干
- DINOv2 + SigLIP — 双视觉编码器
- LoRA / QLoRA (hu2021lora, dettmers2024qlora) — 高效 finetune
- OpenVLA-OFT (kim2025oft) — 同作者后续,证明 parallel decoding + L1 regression 能让 OpenVLA 速度 26× 且性能更高,本库有 OFT 笔记
- π₀ / π₀.₅ (black2024pi0 / intelligence2025pi05) — OpenVLA 的主要竞争者;本库有 π₀ 笔记、π₀.₅ 笔记