Wall-OSS-0.5: Pretrain Once, Act Anywhere¶
论文阅读笔记 — 用于后续讨论的概览
1. 基础信息¶
- 题目: Wall-OSS-0.5 Technical Report — Pretrain Once, Act Anywhere
- 作者: X Square Robot Team
- 发布: 2026 技术报告(无 arXiv 编号,PDF 文件名
wallx_2602.pdf,疑指 2026-02) - 代码: https://github.com/X-Square-Robot/wall-x(开源 weights/code/eval)
- 关键词: deployment-oriented VLA pretraining, gradient-bridged co-training, Mixture-of-Transformers, RVQ action tokenizer, flow matching, action-space supervision, zero-shot real-robot
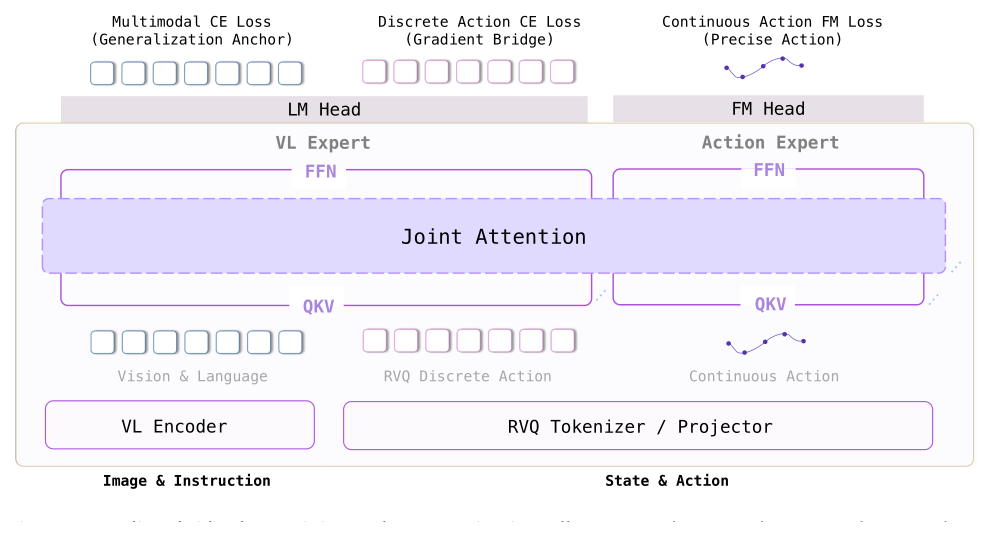 Figure 2:三个互补目标共同塑造预训练策略 —— multimodal CE 是 generalization anchor、action-token CE 是 gradient bridge(把 VLM-native 梯度灌进 backbone 让它 action-aware)、flow matching 是部署用的连续动作接口。MoT 把 VL token 路由到 VL Expert、连续动作路由到 Action Expert,joint attention 让梯度端到端跨两个 expert。
Figure 2:三个互补目标共同塑造预训练策略 —— multimodal CE 是 generalization anchor、action-token CE 是 gradient bridge(把 VLM-native 梯度灌进 backbone 让它 action-aware)、flow matching 是部署用的连续动作接口。MoT 把 VL token 路由到 VL Expert、连续动作路由到 Action Expert,joint attention 让梯度端到端跨两个 expert。
2. 文章介绍¶
2.1 解决的领域和问题¶
属于 VLA(Vision-Language-Action)预训练 子领域。论文盯住一个被普遍回避的基础问题:VLA 预训练本身到底产不产可执行的机器人行为,还是只是给下游任务学习提供一个更好的 initialization? 因为几乎所有 VLA 的"强结果"都是在 task-specific fine-tune 之后才报告的,预训练 checkpoint 的真实能力从未被直接测过。
Wall-OSS-0.5 把这个问题变成一个可在物理硬件上直接测量的目标 —— deployment-oriented VLA pretraining:预训练 checkpoint 不微调,直接当真机策略评估。这要求模型同时满足三条:开箱即用能执行操作技能、保留足够 VLM 派生的 VL 能力以保持 instruction-grounded、并提供让下游 adaptation 更省样本的先验。
2.2 Motivation¶
VLA 训练的固有张力在于 continuous vs discrete 动作表征:
- Continuous flow matching 是天然的执行接口(直接建模未量化动作),但对预训练 VLM backbone 的更新很弱;
- Discrete action-token 预测 的 next-token cross-entropy 是 VLM 原生训练接口、能强力 shape backbone,但解码出的离散动作对精细控制太粗;
- 单纯 freeze / 截断梯度能保住 VLM 先验,代价是精确动作目标无法塑造大 backbone。
作者的洞察:问题不是"连续 vs 离散"二选一,而是 如何在训练时利用离散路径、在部署时保留连续动作。
2.3 之前工作的问题¶
| 类别 | 代表工作 | 缺陷 |
|---|---|---|
| 离散动作 token VLA | RT-2 (2), OpenVLA (3) | per-dimension 朴素离散化精度受限 |
| 规则式动作压缩 | FAST (10) | DCT+BPE 提高 token 效率,但是 rule-based compressor,承载的高层语义有限 |
| 连续策略 | Diffusion Policy (43), π0 (4) | 建模高精度动作分布自然,但对 VLM backbone 的塑造弱 |
| 最接近的 co-train | π0.5 (1) | 同样 co-train FAST 自回归路径 + flow matching,但用 stop-gradient 把 flow 梯度从 backbone 切断 |
| action-ready 架构 | CogACT (44), HPT (45) | 把 cognition/action 拆成独立模块或用 embodiment-specific stem,未做"模态-功能"路由 |
2.4 论文解决方案(一句话)¶
用 gradient-bridged co-training:单阶段联合优化三个目标 —— discrete action-token CE 当 gradient bridge 把 VLM-native 梯度灌进 backbone、multimodal CE 当 anchor 锁住 VL 理解、continuous flow matching 当部署接口;配合 MoT 路由(VL Expert + Action Expert,梯度端到端不切断)、Vision-Aligned RVQ 动作 tokenizer、Action-Space Supervision,让预训练 checkpoint 直接成为可测量的真机能力来源。
2.5 与前序工作的关系¶
- Qwen2.5-VL-3B-Instruct (11):VL Expert 的初始化(保留 3B VLM),加 Action Expert 后 >4B。
- π0.5 (1):最直接对照。Wall-OSS 三点不同 —— 学习式 RVQ tokenizer(vs FAST)、把离散路径分析为 gradient bridge、Action-Space Supervision;且保留端到端梯度流而非 π0.5 的 stop-gradient。
- π0 (4):timestep 采样偏置(Beta(1.5,1))沿用。
- FAST (10):被 RVQ tokenizer 替换的 baseline。
- 数据:Open X-Embodiment、DROID (21)、RoboMIND、AgiBot World 等做规模与多样性;自采 + XRZero-G0 免本体装置。
- 与 WALL-WM 是姊妹工作(本仓已有 WALL-WM 笔记):同属 X Square Robot,共用 Muon/DMuon、XRZero-G0、真机 Task Progress、π0.5/DreamZero baseline。Wall-OSS 是开源 4B 纯 VLA(无 video generation),WALL-WM 是 video+action 大 WAM。
3. 方法介绍¶
3.1 架构:MoT Backbone Routing¶
从 Qwen2.5-VL-3B-Instruct 初始化,扩展成 Mixture-of-Transformers:原 3B VLM 作 VL Expert,新增 Action Expert(+ 连续动作头的 action projection)提供动作生成容量。四类 token 流(vision / language / proprioception / discrete action)走 VL Expert,noisy 连续 action token 走 Action Expert。
关键:这是 routing decomposition 而非 gradient-stopping。两个 expert 共享 sequence-level joint attention,Action Expert 生成连续动作时能 attend 到视觉/语言;attention mask 让 discrete 与 continuous action token 在前向互不可见(两条动作路径可独立训练/评估),但梯度不被 flow matching → VL Expert 阻断。
3.2 Vision-Aligned RVQ Action Tokenizer¶
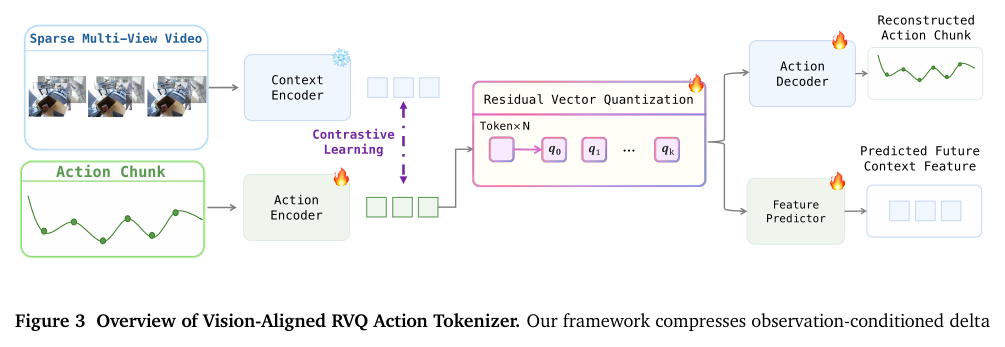 Figure 3:在 delta-action 空间用 Encoder–RVQ–Decoder 把 observation-conditioned 动作序列压成多级离散 token。RVQ 早期 codebook 抓粗运动结构、后期抓细残差;除重建外还有三个辅助目标,让 tokenizer 成为 VLM 的语义训练接口而非纯压缩器。
Figure 3:在 delta-action 空间用 Encoder–RVQ–Decoder 把 observation-conditioned 动作序列压成多级离散 token。RVQ 早期 codebook 抓粗运动结构、后期抓细残差;除重建外还有三个辅助目标,让 tokenizer 成为 VLM 的语义训练接口而非纯压缩器。
之所以用离散 token,是因为 next-token CE 是与 VLM backbone 最兼容的训练接口;但 tokenizer 必须暴露结构化动作语义而非只追求低失真重建。三个辅助目标:
- Visual-action alignment:把 action latent 拉向 VLM 视觉特征;
- Next-frame prediction:让 token 编码动作后果;
- DCT-domain 重建:抑制高频抖动。
→ 离散表征同时 reconstructable、visually aligned、physically smooth。
3.3 Gradient-Bridged Co-Training(核心)¶
单阶段联合优化(公式 1): $\(\mathcal{L} = \mathcal{L}_{\text{flow}} + \lambda_{\text{act}}\cdot\mathcal{L}_{\text{act-CE}} + \lambda_{\text{mm}}\cdot\mathcal{L}_{\text{mm-CE}},\quad \lambda_{\text{act}}=\lambda_{\text{mm}}=0.01\)$
- \(\mathcal{L}_{\text{flow}}\) 比两个 CE 项小约两个数量级,0.01 的共享权重把 CE 拉到与 flow 可比的尺度,防止语言式预测压过动作学习;
- action / multimodal 数据按 9:1 batch 比例混合控制两个 CE 的相对贡献。
梯度动力学(来自 ablation)是整篇论文的实证骨架:超过早期训练后,flow matching 对 backbone 更新的贡献稳定在 ~5% 的小份额,主导更新来自两个 CE。所以 Wall-OSS 保留端到端梯度流(vs π0.5 stop-gradient):小的 flow 残差仍对动作质量重要,但 action-token CE 才扛起大部分 backbone 塑造。推理时默认走连续 flow-matching 路径,离散路径只在训练时承载 gradient bridge。
3.4 Action-Space Supervision¶
flow matching 用线性高斯路径(公式 2),timestep 偏向高噪声(Beta(1.5,1),公式 3)。关键改动:网络仍输出 velocity,但 loss 定义在恢复出的动作上(公式 4–5): $\(\hat A = A_\tau + (1-\tau)f_\theta(A_\tau,\tau),\quad \mathcal{L}_A = \mathbb{E}\|\hat A - A\|^2\)$ 这等价于 velocity 空间的 \((1-\tau)^2\) 加权 loss(公式 6),强调高噪声步。动机来自机器人动作的频谱结构:任务相关信息集中在低频轨迹形状,高噪声步决定全局轨迹的生成天花板,低噪声步只精修残差细节 —— 不同于自然图像高低频都富含语义。与 diffusion 的 x-prediction 形式相关,但动机出自动作信号频谱而非方差。
3.5 Action Interface 与 Implementation Details¶
- 对话式序列:
[System] embodiment prompt [User] Observation/Instruction/Proprioception [Assistant] ⟨action_ar_token⟩⟨action_flow_token⟩×N。推理时离散 token 不解码,Action Expert 通过多步 flow-matching 去噪生成连续动作 chunk,两路径前向用 attention mask 解耦。 - 动作空间 26 维:每臂 relative 3D 位置 + relative 6D rotation(避免 SO(3) 不连续)+ 1D gripper(共 20D),加 3D 移动底盘速度 + 1D 升降 + 2D 头部。relative 动作,1 秒 horizon。
- 优化:Muon(各 expert 的 2D 参数)+ AdamW(视觉 embedding、LM head),DMuon 分布式把 Newton-Schulz 开销降至多 100×。effective batch 8192,bf16,LR 1e-4 cosine,FT LR 5e-5。图像长边 448、过滤静止帧。
- 推理优化:CUDA Graph 捕获整个去噪步(去掉 CPU dispatch bubble)+ 把 RoPE/RMSNorm 等小算子 fuse 成 monolithic CUDA kernel(2–10×)。RTX 5090、三视角、T=10:224×224 ~21Hz / 448×448 ~15Hz,相对 PyTorch eager 4×。
- 数据:每 epoch >1M 轨迹(~60% 自采 + ~40% 开源)、>20 本体。开源子集 RoboMIND v1/v2、AgiBotWorld Beta、RoboCOIN、RoboChallenge、Galaxea、RealOmin、DROID、BRIDGE v2、Fractal/Google Robot。动作空间统一(缺末端的用 URDF FK 恢复)、6D rotation、static frame 过滤、power sampling \(p=0.5\)(平方根采样)平衡长尾。
- Multimodal 90M:78M 开源 + 12M embodied bridge(从动作轨迹自动构造,分 object/spatial/scene/task 四级理解,引入
<box>/<point>spatial token),bridge 不只是额外 VQA,而是抵消 action-token CE 特化压力的 robot-view grounding 监督。
4. 结果对比¶
4.1 预训练零样本真机(17 任务 = 12 seen + 5 unseen,Task Progress)¶
| Checkpoint | Seen (12) | Unseen (5) | Overall (17) |
|---|---|---|---|
| 50k | 26.1 | 24.2 | 25.5 |
| 200k | 40.1 | 38.8 | 39.8 |
| 400k | 50.0 | 53.6 | 51.1 |
400k 高分任务(≥60):Block Sorting 100%、Fruit Sorting 96、Ring Stacking 86、Rope Tightening(unseen 可形变)82、Cup Grasping 64、Bean Pouring(unseen)60。三档:≥60 proficient / 40–60 partial(Switch 55、Number Ordering 54、Flower 51)/ <20 beyond reach(Towel Folding 10、Table Setting 9、Charger Plugging 9)。Semantic understanding 是最强维度(400k avg 72.6%)。作者称这种"staircase"式能力突现类似 LLM emergent abilities。
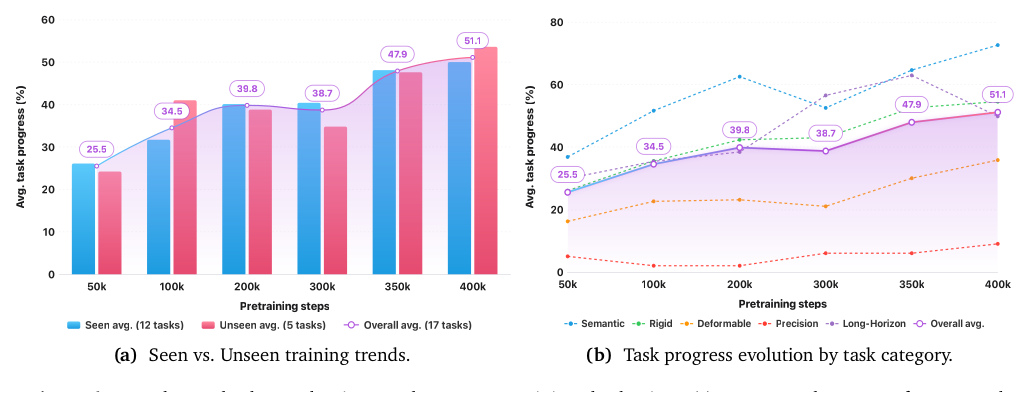 Figure 6:(a) seen/unseen 平均 Task Progress 整体上升、held-out 在 400k 达 53.6(带 checkpoint 级波动)。(b) 五个能力维度 — semantic 成为最强零样本维度,精度密集类(fine-grained/deformable)更难。
Figure 6:(a) seen/unseen 平均 Task Progress 整体上升、held-out 在 400k 达 53.6(带 checkpoint 级波动)。(b) 五个能力维度 — semantic 成为最强零样本维度,精度密集类(fine-grained/deformable)更难。
4.2 微调后真机(15 任务 = 10 manip + 5 reasoning,~500 demo/task)¶
| Model | Manipulation (10) | Reasoning (5) | Overall (15) |
|---|---|---|---|
| Wall-OSS-0.5 | 61.1 | 59.3 | 60.5 |
| π0.5 | 35.0 | 58.9 | 43.0 |
| DreamZero | 33.7 | 32.7 | 33.4 |
Overall +17.5 over π0.5,但几乎全部来自 manipulation 子集(+26);reasoning 上 59.3 vs 58.9 基本打平。15 任务里赢 10 个。
4.3 多任务微调 scaling(5→10→19 任务,同一预训练 checkpoint)¶
- 5 个 simple 共享子集:73.96 → 74.75 → 83.75(+9.8);
- 10 个共享子集:59.98 → 64.78(+4.8);
- 19 任务配置下 9 个 OOD 新任务也达 65.59。
→ 扩任务提升共享任务而非稀释,支持"新任务补全可复用中间能力"的假说。
4.4 具身多模态理解(相对 backbone Qwen2.5-VL-3B)¶
| Benchmark | 变化 |
|---|---|
| Embodied Grounding | +21.8 |
| Where2Place | +11.0 |
| EO-Bench | +3.9 |
| RealWorld VQA | −15.0 |
| ERQA | −5.5 |
→ co-training 产生特化效应:向 embodied perception 迁移、远离 open-domain VQA。
4.5 关键消融¶
| 消融 | 设置 | 结果 |
|---|---|---|
| Co-training 策略(5 任务,70k 步) | co-train / stop-grad→co-train / flow-only / stop-grad | 57.0 / 49.6 / 36.6 / 31.9(VQA 四者紧贴,stop-grad 在 action 最差) |
| Action-space loss(LIBERO) | vs velocity-space | peak 96.5% vs 90.3%;20k 步即 95.8% |
| RVQ vs FAST(同 co-train) | VQA / 4 任务 progress | VQA 77.5 vs 75.7;progress 48.1 vs 29.3 |
5. 引申问题 / 讨论¶
5.1 做得好的地方¶
- 重新定义评估口径:把"预训练 checkpoint 直接当真机策略 zero-shot 评估"作为一等目标,逼出 deployment-oriented 这个有价值的提问,而不是又一篇"FT 后我比你高几个点"。
- Gradient bridge 洞察清晰且有实证:梯度分析显示 flow matching 超早期后只占 backbone 更新 ~5%,主导是两个 CE。由此把 discrete action-token CE 定位成"VLM-native 且与 flow 梯度方向正相关"的桥,把训练时信号与部署接口解耦(部署连续、离散只为梯度)—— 优雅且可证伪。
- MoT 保留端到端梯度流:相对 π0.5 stop-gradient,ablation 直接显示 stop-grad 在动作上最差(31.9 vs co-train 57.0),且 stop-grad flow loss 收敛慢、终值高(Action Expert 欠拟合),证据链完整。
- RVQ tokenizer 的辅助目标真有用:visual-action alignment + next-frame prediction 不仅让离散 token 语义化,连用连续 flow 生成评估的真机 progress 都从 29.3 升到 48.1,且 VQA 还升(75.7→77.5)—— 说明更好的离散表征反哺了连续路径。
- Action-space supervision 动机扎实:\((1-\tau)^2\) 加权由机器人动作"信息集中在低频"的频谱结构推出,不是 borrow 自图像;LIBERO 控制实验干净(96.5 vs 90.3)。
- Embodied bridge data 抵消特化压力:把动作轨迹自动转成 robot-view grounding/spatial 监督,针对性地补回 action-token CE 带来的具身感知掉分(Embodied Grounding +21.8),而不是泛泛加 VQA。
5.2 做得不够好的地方 / 值得质疑的地方¶
- "Unseen" 被作者自己大幅打折:明说开源预训练语料可能含语义相关操作经验,这里的泛化"主要是 cross-scene/cross-prop 技能迁移,而非从零学全新技能"。所以 headline 的 zero-shot 是真的,但 held-out 任务在技能层面并非真正 held-out。
- 零样本数字 checkpoint 敏感:unseen avg 非单调(24.2→41.0→38.8→34.8→47.6→53.6),Toy Basket 400k 是 58% 但训练中峰值 72%。报"400k"有 cherry-pick 最佳 checkpoint 的风险,应给均值/方差。
- vs π0.5 的领先全在 manipulation:reasoning 59.3 vs 58.9 实质打平,+17.5 overall 完全由 manipulation 驱动;且 π0.5 是适配到自家 embodiment 的实现,baseline 适配是否充分不透明。
- General VQA 明显回退:"anchor" 并没完全保住 VL 能力(RealWorld VQA −15.0、ERQA −5.5)。被框成"合理 trade-off",但对一个号称保留 VL 理解的模型这是实打实的退化。
- 单帧输入(作者自承):无时间记忆,导致 long-horizon zero-shot 差(Table Setting 9、Towel Folding 10)。"Pretrain once, act anywhere" 的 anywhere 其实受限于无状态跟踪。
- 平衡超参做了很多隐性工作:\(\lambda_{\text{act}}=\lambda_{\text{mm}}=0.01\) 共享权重 + 9:1 batch 比,是把三个尺度差两个数量级的 loss 硬拉平的关键,但除了高层论证外没有敏感性扫描。
- Action-space loss 只在 LIBERO 仿真验证:6.2% 的 sim 增益是否迁移到真机未测。
- 26 维固定动作空间:作者自承不支持灵巧手等高 DoF;对"act anywhere"的口号而言,动作接口其实相当受限。
- Gradient bridge 只在 3B 验证:作者明确指出 scaling 到更大 VLM 可能改变三个信号的相对几何与交互强度 —— 核心机制在规模上未必成立。
- stop-grad→co-train (49.6) 离 co-train (57.0) 不远:远好于纯 stop-grad (31.9),暗示 co-training 的大部分收益可由一个晚期 co-training 阶段补回 —— 某种程度上软化了"必须全程 co-train"的论断。
5.3 值得继续探讨的方向¶
- Scaling gradient bridge:在 7B/更大 backbone 上重测 flow vs CE 的梯度份额与正相关性,看 ~5% 的结论是否随规模漂移。
- 时间记忆:把单帧换成多帧/KV-cache history,看 Table Setting/Towel Folding 这类 long-horizon 零样本能否突破 <20 档。
- 更通用动作接口:脱离固定 26 维,支持灵巧手/高 DoF,验证 RVQ tokenizer 在更高维动作上的可扩展性。
- Checkpoint 选择协议:用均值/方差或 EMA checkpoint 报零样本,降低 cherry-pick 嫌疑。
- 离散路径能否完全退役:既然部署只用连续路径、stop-grad→co-train 也接近,能否设计一个只在训练末段注入 action-token CE 的更省方案?
- 与姊妹 WAM(WALL-WM)的取舍:纯 VLA(无 video generation)vs video+action WAM,在相同真机 suite 上的样本效率/时延/泛化对照。